[230707] A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View
segmentation
목록 보기
1/14

- 56회 인용
- 2020
- ITSC journal
- https://arxiv.org/pdf/2005.04078.pdf
이 논문을 왜 봐야하는데?
- Multiple vehicle-mounted 카메라를 BEV segmented image로 잘 변환할 수 있는 방법을 제안함.
- 두 개의 네트워크 구조를 비교하여, 2개의 제안한 구조중 특히 1개가 BEV segmentation에 더 적합하다는 것을 보임.
- 시뮬레이션 데이터만으로 학습하여 manual labeling이 필요없도록 함,
- 실 환경 테스트에서도 sim-to-real gap 없이 잘 적용되는 것을 보임
method
- BEV segmentation 네트워크의 입력으로 camera의 semantic map을 주어 Sim-to-real gap을 최소화
- RGB 이미지를 이용하여 end-to-end로 BEV segmentation을 하는 것은 다음과 같은 문제가 있음.
- 실 환경에서는 매칭되는 BEV 이미지 (RGB, segmentation 모두)를 얻기 어려움.
- 시뮬레이터 데이터로 학습할 수는 있지만, RGB 이미지는 Sim-to-real gap이 커서 성능이 매우 떨어짐.
- 위와 같은 문제를 해결하기 위해 Synthetic data만을 이용하여 학습함.
- "road plane을 가정하여 만들어진 homography 영상에서, 늘어진 부분들을 보정하는 문제"로 단순화할 수 있음.
- RGB 이미지를 이용하여 end-to-end로 BEV segmentation을 하는 것은 다음과 같은 문제가 있음.
- Groudtruth BEV를 만들 때, Occulsion 처리하기
- 우리 application의 경우
Occulsion 처리필요없음
- 우리 application의 경우
IPM을 통해 Homography를 만들어주는 이유: spatial consistency
단순 concat의 문제점
- In order to fuse images from multiple cameras mounted on a vehicle,
- a single-input network could take as input multiple images concatenated along their channel dimension.
- However, for the task at hand, this would result in spatial inconsistency between input and output images.
- Convolutional layers operate locally,
- i.e. information in particular parts of the input are mapped to approximately the same part of the output.
해결책: IPM을 통해 Homography를 만들어주기
- IPM certainly introduces errors, but the technique is capable of producing an image at least similar to a ground truth BEV image.
- Due to this similarity, it seems reasonable to incorporate IPM as a mechanism to provide better spatial consistency between input and output images.
아래 2개의 모델 제안. (후자가 더 좋음)
model 1: Single-input Model (DeepLab Xception)
- Homography image를 입력으로 받아 BEV segmentation 결과 도출
- DeepLab v3+ 사용
- With MobileNetV2 [16] and Xception [17], two different network backbones are tested.
- The resulting neural networks have approximately 2.1M and 41M trainable parameters.
model 2: Multi-input Model (uNetXST)
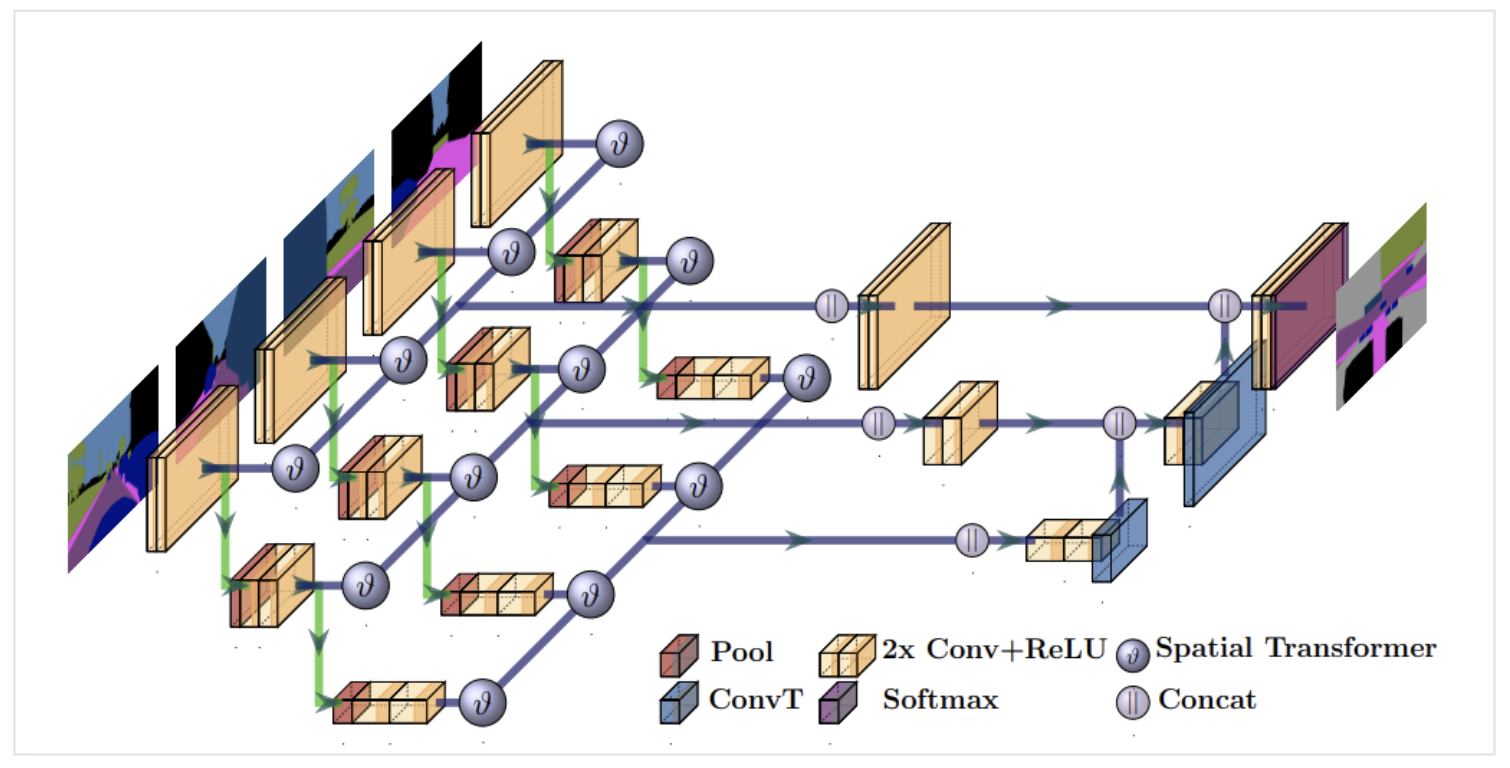
- Non-transformed image들을 입력으로 받아 processing하는 부분까지 포함된 네트워크
- Spatial inconsistency 문제를 막기 위해, 네트워크에 projective transformation을 통합함.
- Spatial inconsistency : https://velog.io/@hsbc/spatial-inconsistency
- we choose the popular semantic segmentation architecture U-Net [18]
- uNetXST contains approximately 9.6M trainable parameters.
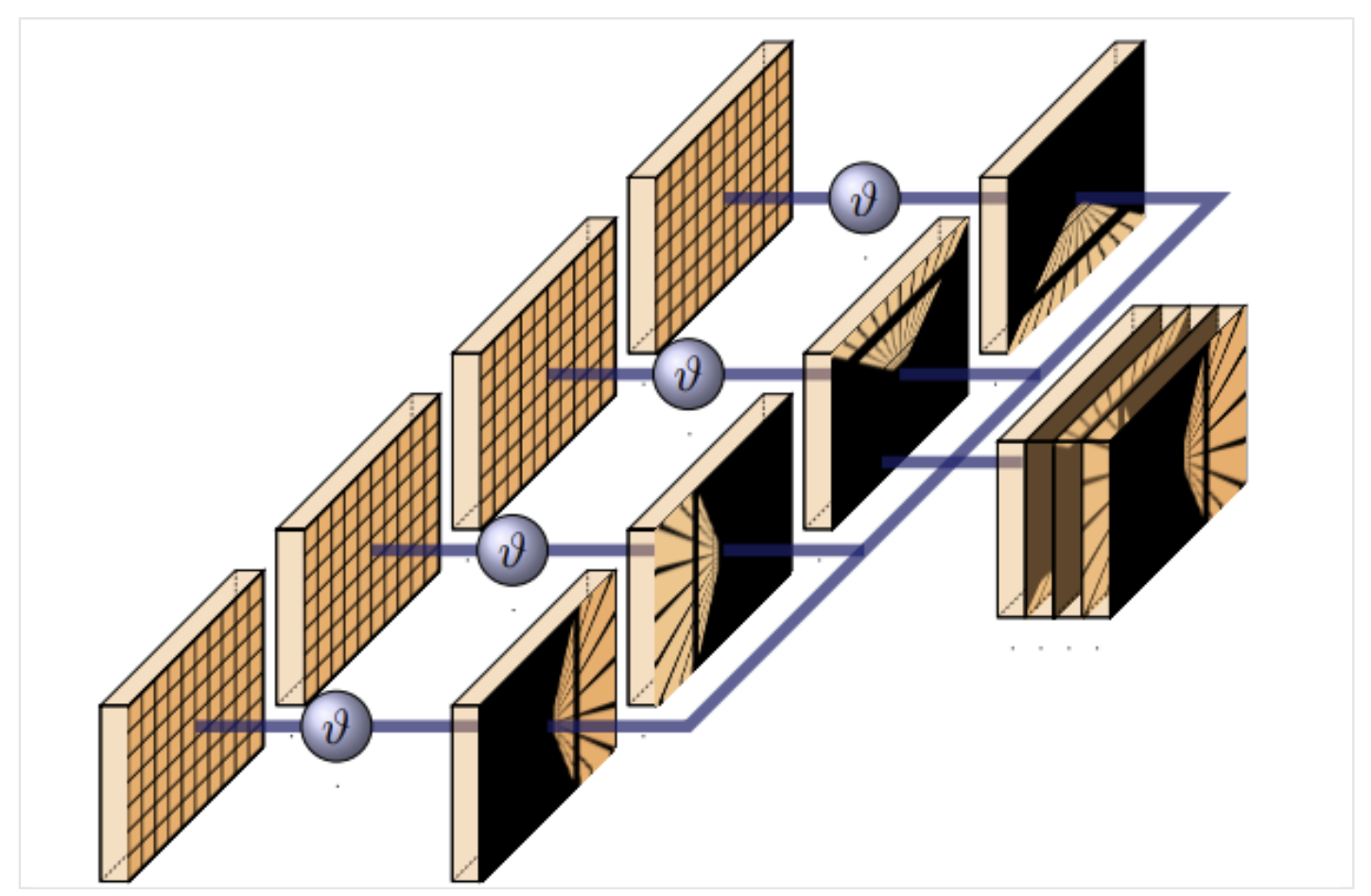
- Multi-input에 대한 feature들을 concat 하기 전에, Spatial transformer를 통해 fixed homography 기반으로 projectively transform 수행
Experiments
학습 detail
Occulsion 처리?
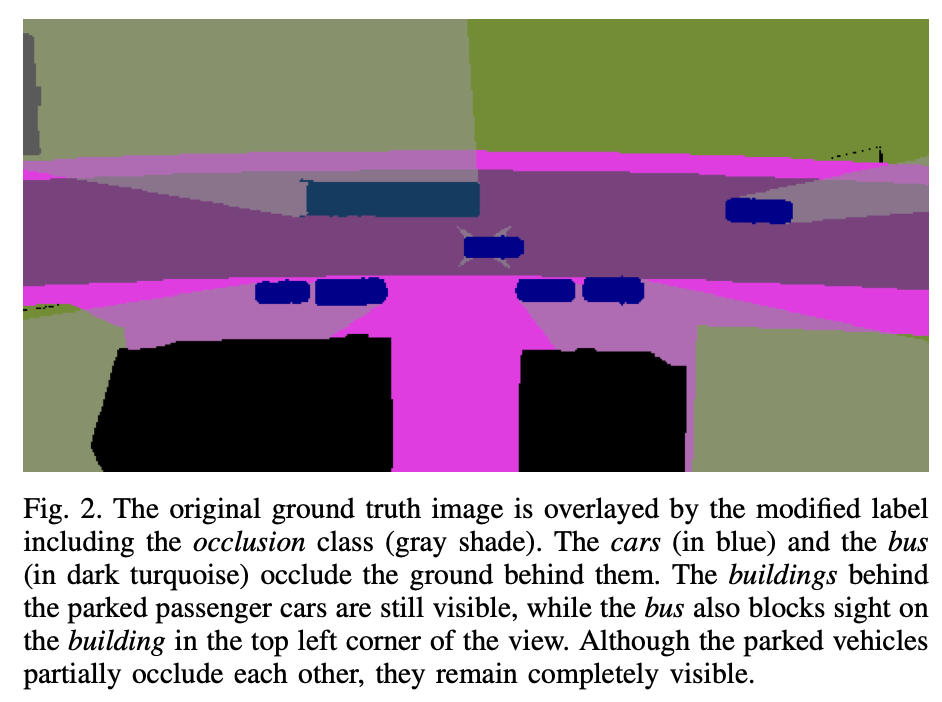
- 일부 class들을 항상 시야를 가림 (e.g. building, truck)
- 일부 class들은 절대 시야를 가리지 않음. (e.g. road)
- 자동차들은 그 뒤에 있는 높은 물체를 제외한 모든 시야를 가림. (e.g. truck, bus)
일부가 가려진 물체들은 모두 보이도록 남겨둠. - 모든 카메라 뷰에서 가려진 물체는 occluded로만 labeling함.
Data Acqusition
- The BEV ground truth image has field of view of
70m×44m.(FSA: 40m* 20m, 우리는 1/4배) - Both input and ground truth images are recorded at a resolution of
964 px × 604 pxwith2Hz- where each sample is a set of multiple input images and one ground truth label.
dataset 1: 사방 카메라 4개
- 9개의 클래스 사용 (road, sidewalk, person, car, truck, bus, bike, obstacle, vegetation)
- Training : Validation = 33,000 : 3,700 사용
dataset 2: single front camera 만
- Evaluation을 위한 실제 데이터는 front-view-only, 3개 클래스만 사용 (road, vehicle, occupied space)
- For this reason, the ground truth images are left-aligned with the ego vehicle.
- Training : Validation = 33,000 : 3,200 사용
Training Setup
- input images는 2:1 비율(center-cropped)을 적용한 512 x 256로 resize
- The input images are converted to a one-hot representation.
- In order to counter class imbalance in the dataset,
the loss function is modified to weigh semantic classes according to the logarithm of their relative occurrence.
Evaluation Metrics
- MIOU
Results and Discussion
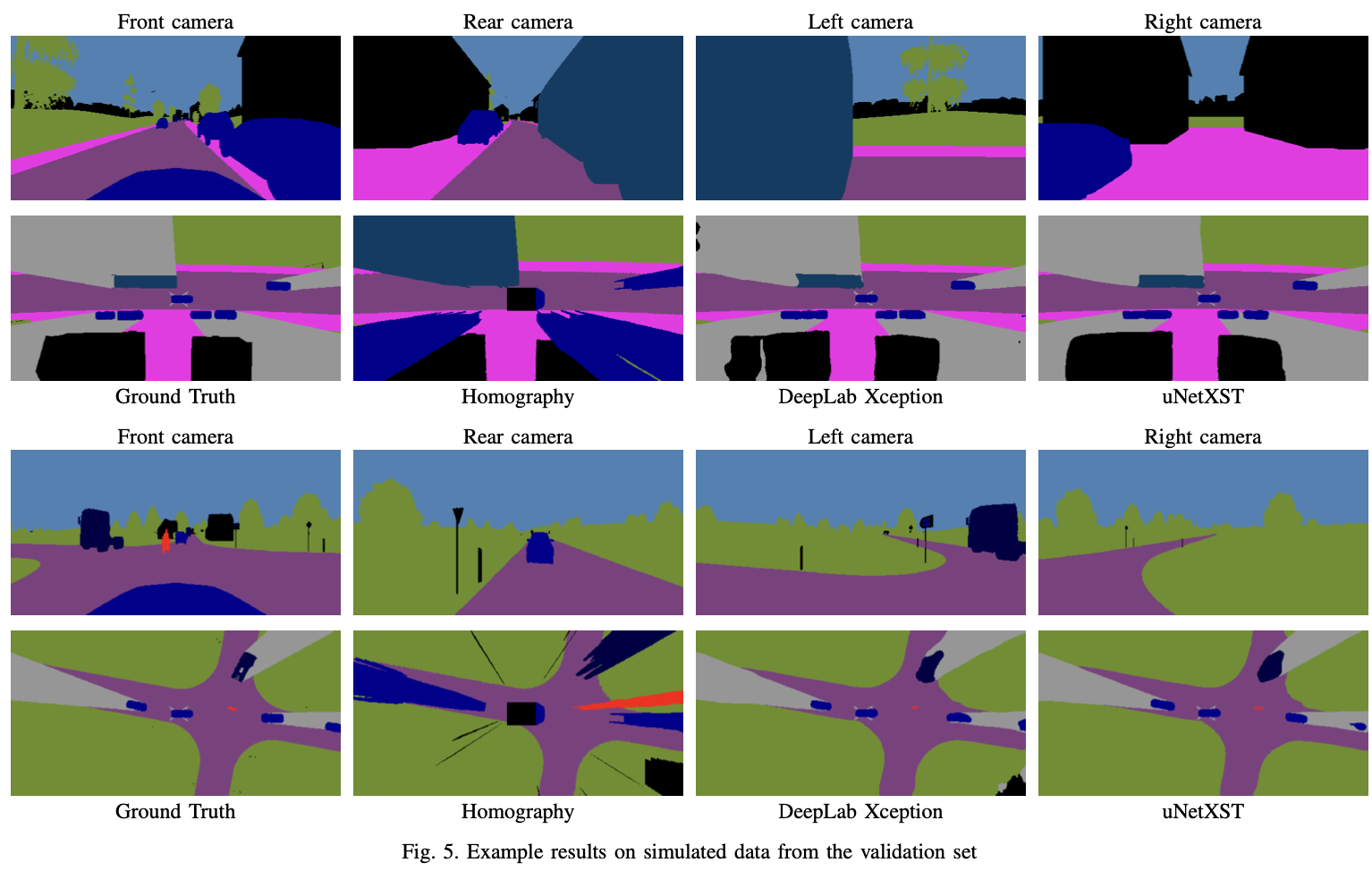
Results on synthetic data
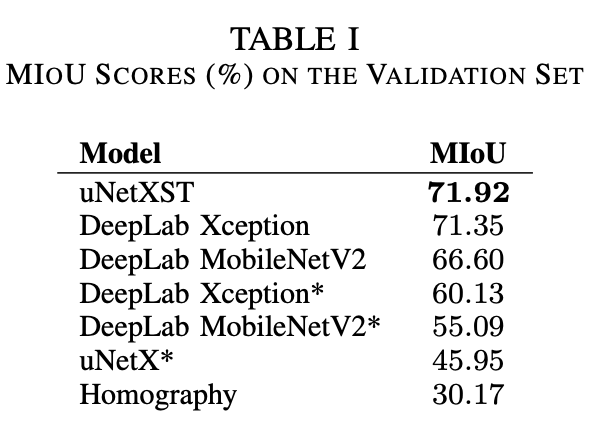
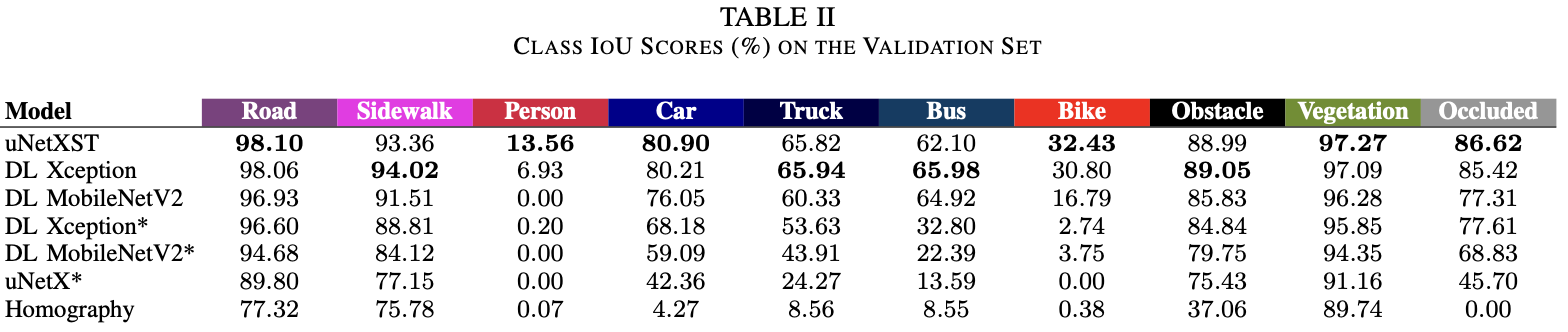
- uNetXST benefits from being able to extract features from the non-transformed camera images, before perspective errors are introduced by IPM.
- IPM 적용도 많은 도움이 되더라.
- 사람 결과가 박살났는데, 논문에서는, class imbalance 때문이 아닐까라고 언급하였다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것