정보
-
오리지널 데이터셋
- https://groups.csail.mit.edu/vision/datasets/ADE20K/
- 수량: 25,574 / 2,000 / No
- 1828개의 categories
- github: https://github.com/CSAILVision/ADE20K (215 *)
-
ADE20K scene parsing dataset
-
수량: 20,210 / 2,000 / 있는데 몇장인진 모르겠음.
-
150개의 categories
-
https://github.com/CSAILVision/semantic-segmentation-pytorch (4700 *)
-
오리지널 데이터셋보다 더 범용적으로 사용되는 것으로 보인다.
-
-
-
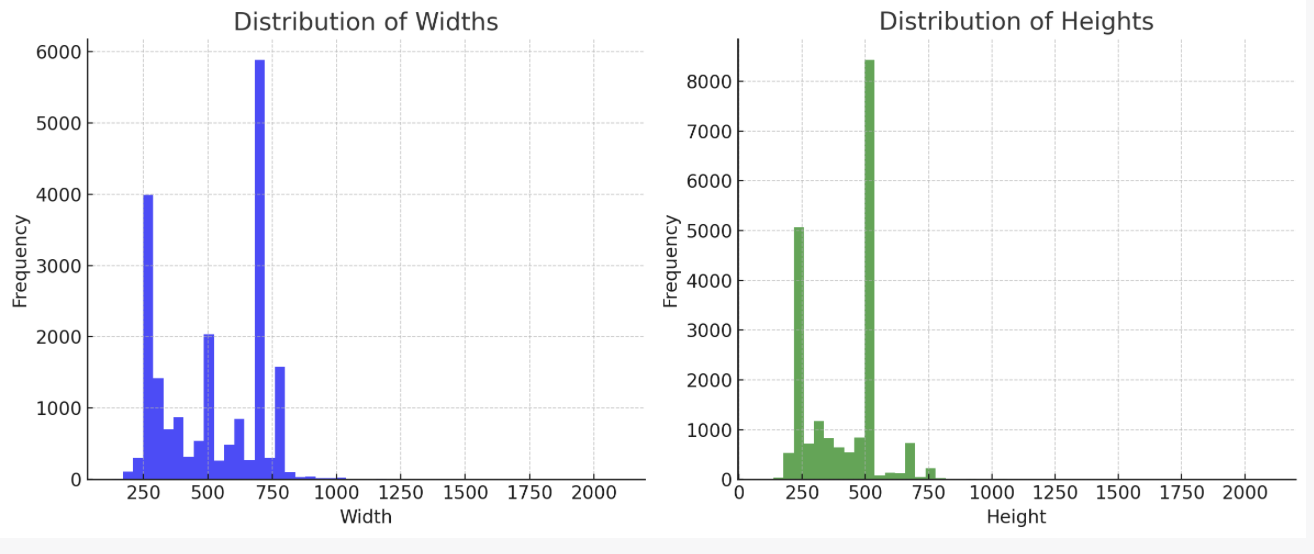
첫 번째 높은 빈도수 구간: (233.3 ~266.7, 233.3 ~266.7)
-
두 번쨰: (666.7 ~ 700, 500 ~533.3)
-
width 범위: 130 ~ 2100
-
height 범위: 96 ~ 2100
-
(width+height) 범위 : 226 ~ 4200
-
평균 width & height : (516, 417)
데이터 분포
training
- 총 이미지 수: 20210
- 잔디/사람/공이 있는 이미지 수: 6906
- 잔디: 2421 12%
- 사람: 5069 25%
- 공: 136 0.67%
Validation
- 총 이미지 수: 2000
- 잔디/사람/공이 있는 이미지 수: 706
- 잔디: 227 11.35%
- 사람: 532 26.60%
- 공: 25 1.25%
ADE20K scene parsing dataset
dataset 전처리
- 데이터셋 shuffle
- 처음 실행 + cursor가 전체 데이터셋을 다 훑으면 실행
- sub_batch 꺼내는 법
height > width인 경우와,height < width인 경우를 나눠서, 둘 중batch_per_gpu가 먼저 차는 경우 -> sub_batch로 가져옵니다.- 이 sub_batch들의 raw images는 size가 전부 다르다.
- resize 하는 법
- height와 width 중 작은 쪽에 대한 resize hyperparameter
imgSizes가 (300, 375, 450, 525, 600) 으로 주어짐. - height와 width 중 큰 쪽에 대한 resize max hyperparameter
imgMaxSize가 1000으로 주어짐 - 위 2가지 조건으로 모든 batch 내 이미지를 resize 한 뒤, resize한 모든 이미지들 중, 가장 큰 height/width를 최종 사이즈로 통일합니다.
- 최조 사이즈를 ->
self.padding_constant의 배수가 되게끔(여기서는 8), padding을 붙여줍니다.
- height와 width 중 작은 쪽에 대한 resize hyperparameter
- downsampling (segms만)
- batch_images: (b, 3, h, w)
- batch_segms: (b, h//8, w//8) (8=
self.segm_downsampling_rate)
- flip left right (50% 확률)
- downsampling
- batch_segms가
self.segm_downsampling_rate의 배수가 되도록 변경해줍니다. - 커진 부분은 검은색으로 칠해줍니다. (왼쪽 상단부터 원래 이미지이고, 오른쪽 아랫부분 쪽이 검은색이 생길 수 있음)
- 그런 후, downsampling (
self.segm_downsampling_rate)
- batch_segms가
- img_transform
- (3, H, W)로 바꾸고 normalize.
- segm_transform
- 0 ~ 150을 -> -1 ~ 149가 되도록 바꿈
DataLoader

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것