CLIP code 사용법
[Blog] [Paper] [Model Card] [Colab]
- CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs.
- It can be
instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3.
Approach
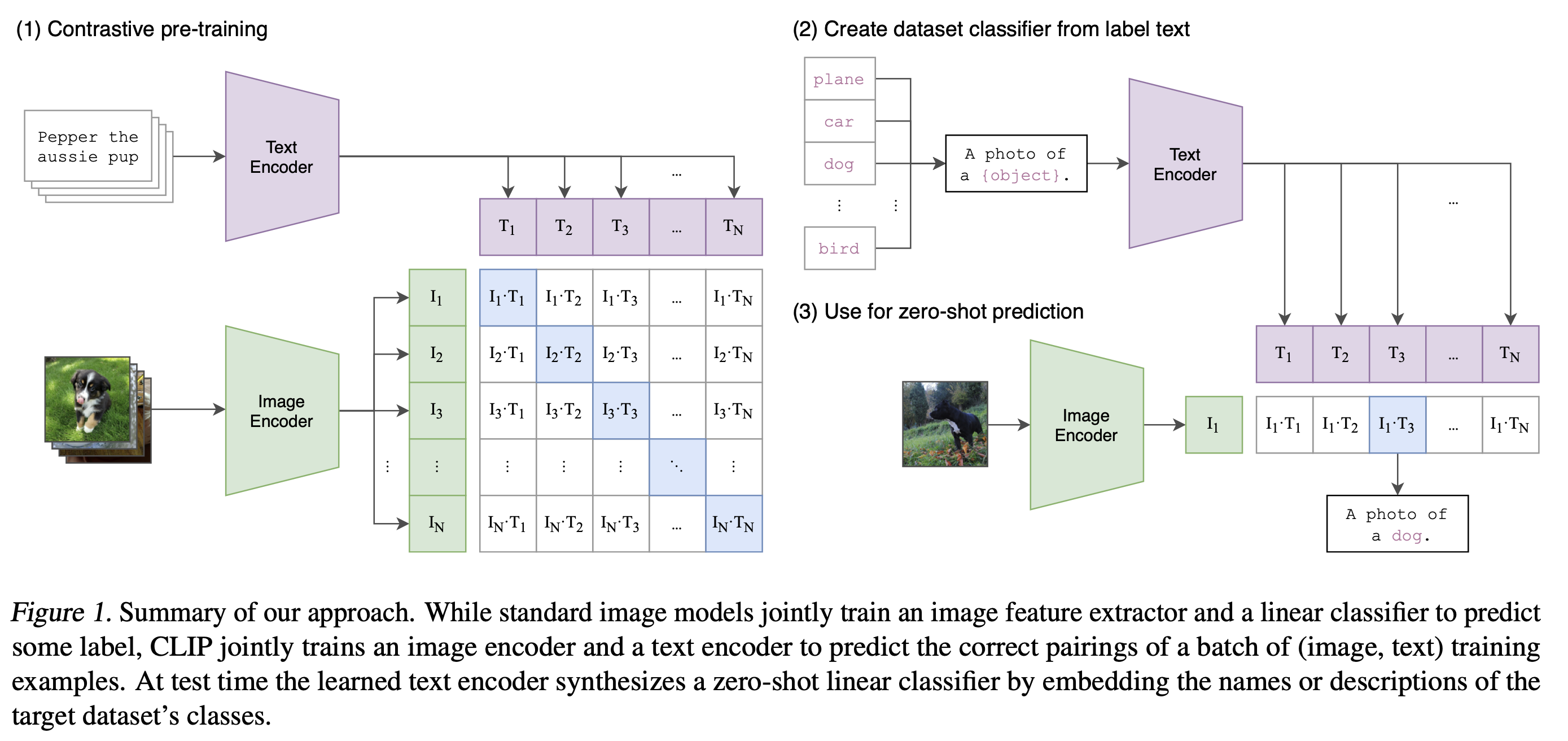
Usage
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]API
- The CLIP module
clipprovides the following methods:
model, preprocess = clip.load(name, device=..., jit=False)
- Returns the model and the TorchVision transform needed by the model.
- preprocess (= TorchVision transform )
- 이미지 데이터에 대한 전처리 및 변환(transform)을 수행하기 위한 도구
- https://velog.io/@hsbc/torchvision
- The
nameargument can also be a path to a local checkpoint. - The device to run the model can be optionally specified, and the default is to use the first CUDA device if there is any, otherwise the CPU.
- When
jitisFalse, a non-JIT version of the model will be loaded.
clip.tokenize(text: Union[str, List[str]], context_length=77)
- Returns a LongTensor containing tokenized sequences of given text input(s).
- This can be used as the input to the model.
- The model returned by
clip.load()supports the following methods:
model.encode_image(image: Tensor)
- Given a batch of images, returns the image features encoded by the vision portion of the CLIP model.
model.encode_text(text: Tensor)
- Given a batch of text tokens, returns the text features encoded by the language portion of the CLIP model.
model(image: Tensor, text: Tensor)
Given a batch of images and a batch of text tokens, returns two Tensors, containing the logit scores corresponding to each image and text input.The values are cosine similarities between the corresponding image and text features, times 100.
More Examples
Zero-Shot Prediction
- The code below performs zero-shot prediction using CLIP, as shown in Appendix B in the paper.
- This example takes an image from the CIFAR-100 dataset, and predicts the most likely labels among the 100 textual labels from the dataset.
import os
import clip
import torch
from torchvision.datasets import CIFAR100
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# Prepare the inputs
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")- The output will look like the following (the exact numbers may be slightly different depending on the compute device):
Top predictions:
snake: 65.31%
turtle: 12.29%
sweet_pepper: 3.83%
lizard: 1.88%
crocodile: 1.75%- Note that this example uses the
encode_image()andencode_text()methods that return the encoded features of given inputs.
Linear-probe evaluation
- "Linear probe"는 사전 훈련된 신경망 모델의 특정 층에서 추출된 특징(feature)이 얼마나 유용한지를 평가하는 방법
- 이 방법은 특히 사전 훈련된 모델의 전이 학습(transfer learning) 능력을 평가할 때 사용됩니다.
- Linear probe 접근법은 다음과 같은 단계로 구성됩니다:
- 특징 추출:
- 사전 훈련된 모델을 고정(freeze)하고, 모델의 한 층(예: 마지막 컨볼루션 층)에서 출력되는 특징을 데이터셋의 모든 샘플에 대해 추출
- 이렇게 추출된 특징은 일반적으로 고차원 벡터로 표현
- 선형 분류기 훈련:
- 추출된 특징을 입력으로 사용하여, 간단한 선형 분류기(예: 로지스틱 회귀, 선형 SVM 등)를 훈련
- 이 분류기는 원래 모델이 훈련되지 않았던 새로운 작업(예: 다른 분류 문제)에 대한 예측을 수행
- 성능 평가:
- 선형 분류기의 성능(예: 정확도, F1 점수 등)을 평가하여, 사전 훈련된 모델에서 추출된 특징의 유용성을 평가
- 좋은 성능을 달성한다면, 이는 추출된 특징이 해당 작업에 대해 유의미하고 유용한 정보를 포함하고 있음을 의미
- The example below uses scikit-learn to perform logistic regression on image features.
import os
import clip
import torch
import numpy as np
from sklearn.linear_model import LogisticRegression
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR100
from tqdm import tqdm
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Load the dataset
root = os.path.expanduser("~/.cache")
train = CIFAR100(root, download=True, train=True, transform=preprocess)
test = CIFAR100(root, download=True, train=False, transform=preprocess)
def get_features(dataset):
all_features = []
all_labels = []
with torch.no_grad():
for images, labels in tqdm(DataLoader(dataset, batch_size=100)):
features = model.encode_image(images.to(device))
all_features.append(features)
all_labels.append(labels)
return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()
# Calculate the image features
train_features, train_labels = get_features(train)
test_features, test_labels = get_features(test)
# Perform logistic regression
classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1)
classifier.fit(train_features, train_labels)
# Evaluate using the logistic regression classifier
predictions = classifier.predict(test_features)
accuracy = np.mean((test_labels == predictions).astype(float)) * 100.
print(f"Accuracy = {accuracy:.3f}")- https://velog.io/@hsbc/Logistic-Regression
- Note that the
Cvalue should be determined via a hyperparameter sweep using a validation split.
See Also
- OpenCLIP: includes larger and independently trained CLIP models up to ViT-G/14
- Hugging Face implementation of CLIP: for easier integration with the HF ecosystem

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것
https://blog.libero.it/wp/bothbestbamboo/2025/09/06/choosing-the-right-bamboo-flooring-for-family-home/
https://zybuluo.com/bothbest/note/2621882
https://www.hentai-foundry.com/user/bothbest/blogs/20379/Top-Bamboo-Flooring-Styles-Dominating-Modern-Interiors
https://qualityherb.livepositively.com/7-key-reasons-builders-are-choosing-bamboo-over-hardwood-flooring
https://www.edufex.com/forums/discussion/general/why-bamboo-flooring-is-changing-the-face-of-modern-interior-design
https://www.chambers.com.au/forum/view_post.php?frm=2&pstid=107269
https://zybuluo.com/bothbest/note/2621968
https://www.hentai-foundry.com/user/bothbest/blogs/20384/Tools-and-Techniques-for-Flawless-Bamboo-Flooring-Installation
https://qualityherb.livepositively.com/what-sets-premium-bamboo-flooring-apart/
https://blog.libero.it/wp/bothbestbamboo/2025/09/07/color-trends-bamboo-flooring-from-blonde-tones-to-rich-espresso/
https://filmfreeway.com/FlooringBamboo
https://rebrickable.com/users/bothbest/