vision
1.clip-retrieval

이 글에서는 CLIP 임베딩을 계산하고, 그걸 이용해서 검색 시스템을 만드는 방법에 대해 설명하고 있어. 아래 모든 과정을 통틀어, 기본적인 의미 기반 검색 시스템을 만들 수 있어. 의미 기반 검색에 대해 더 배우고 싶다면, 내 미디엄 포스트를 읽어보는 것도 좋아.ht
2.bounding box 내에서, 조끼 색 구분하기
이러한 분류 작업을 수행하기 위한 가장 합리적인 방법을 몇 가지 제시컬러 히스토그램 분석: 각 bounding box 내의 이미지에 대한 컬러 히스토그램을 계산하고, 빨간색과 노란색의 비율을 분석합니다. 조끼의 색상이 더 많이 나타나는 쪽으로 분류할 수 있습니다.컬러
3.CLIP 코드 사용법
\[Blog] \[Paper] \[Model Card] \[Colab]CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs.
4.open_clip
https://github.com/mlfoundations/open_clip?tab=readme-ov-fileOpenAI의 CLIP(Contrastive Language-Image Pre-training)을 개방형 소스 구현체로 만나볼 수 있어요. 이 코드베이
5.grounded SAM 사용
이 Makefile은, Docker 환경에서 CUDA를 활용해 특정 소프트웨어 빌드와 실행을 관리하기 위한 설정들을 포함CUDA 버전 확인 및 활성화:"Get version of CUDA and enable it for compilation if CUDA > 11.0"
6.WASB-SBDT 써보기
Docker 이미지를 빌드하기docker build -t sports-ball-detection .Docker 컨테이너 실행하기docker run -it --gpus all sports-ball-detectionFor Soccer, we provide a setup
7.YOLO fine tuning
Dataset formatYOLO detection dataset format can be found in detail in the Dataset Guide.https://docs.ultralytics.com/datasets/detect/To convert y
8.YOLO Object Detection dataset 만들기
YOLO model 과 호환되는 다양한 format의 dataset을 소개소개하는 다양한 format datasets의 구조, 사용법, 그리고 각 포멧간 전환 방법을 소개
9.[python] 동영상 화질 개선

bgr, bt2020nc"(BT.2020 비정규 색 공간)특정한 방법으로 색상을 생성하고 조합하는 색상 모델을 사용가장 일반적인 색상 모델로는 RGB (빨강, 초록, 파랑), CMYK (청록, 자홍, 노랑, 검정), YCbCr (밝기와 색차 정보), HSV (색상, 채
10.Vision Transformer
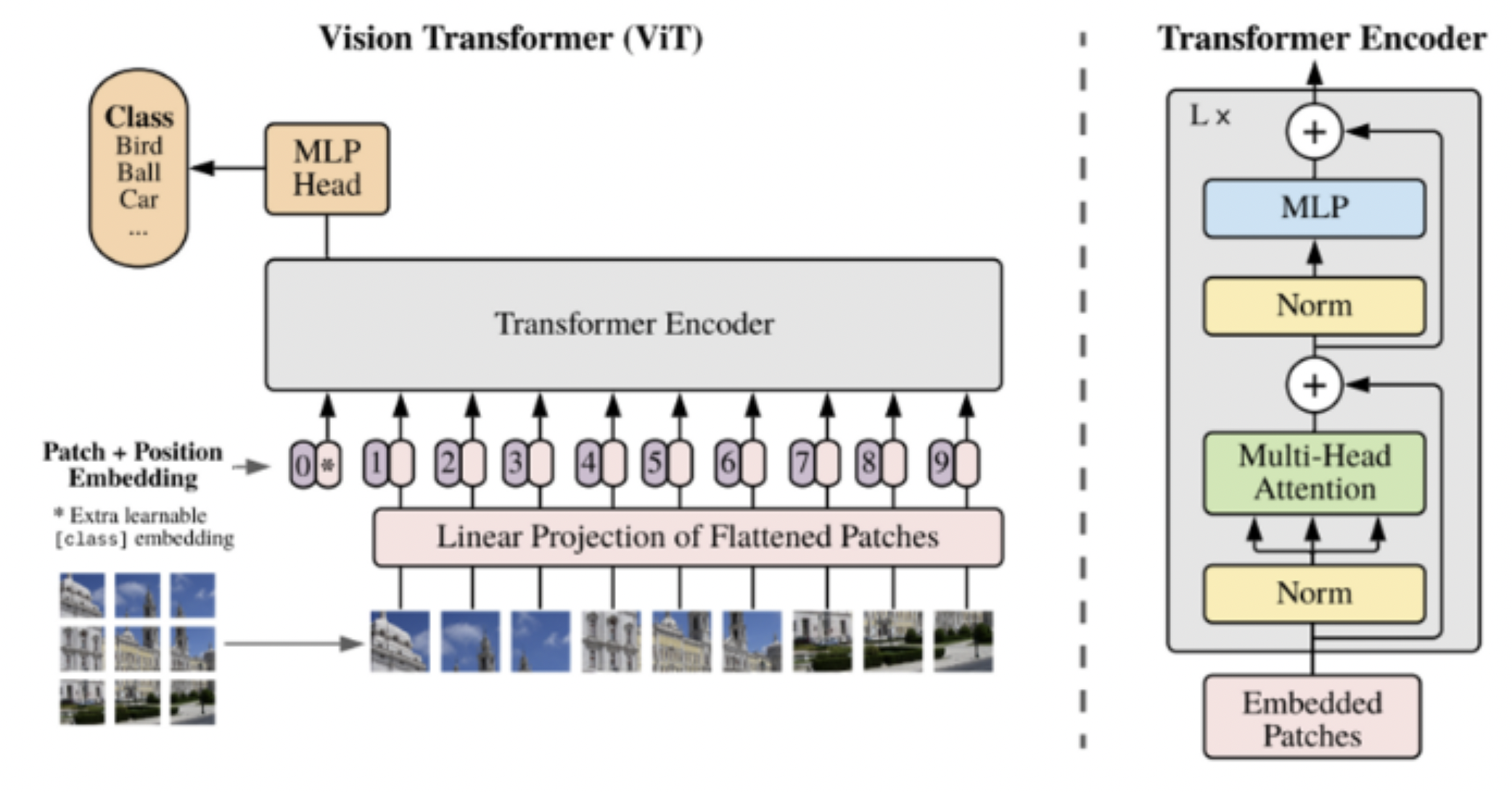
https://daebaq27.tistory.com/108https://velog.io/@choonsik_mom/Vision-TransformerViT-논문-리뷰image 분야의 TransformerCNN 기반 image classification 모
11.Segment Anything Model(SAM)

연산량 많음Masked Autoencoder(MAE) pre-trained ViT를 사용Masked Autoencoder(MAE)https://velog.io/@hsbc/MAE-Masked-Auto-Encoding-are-scalable-Vision-Learn
12.swin transformer
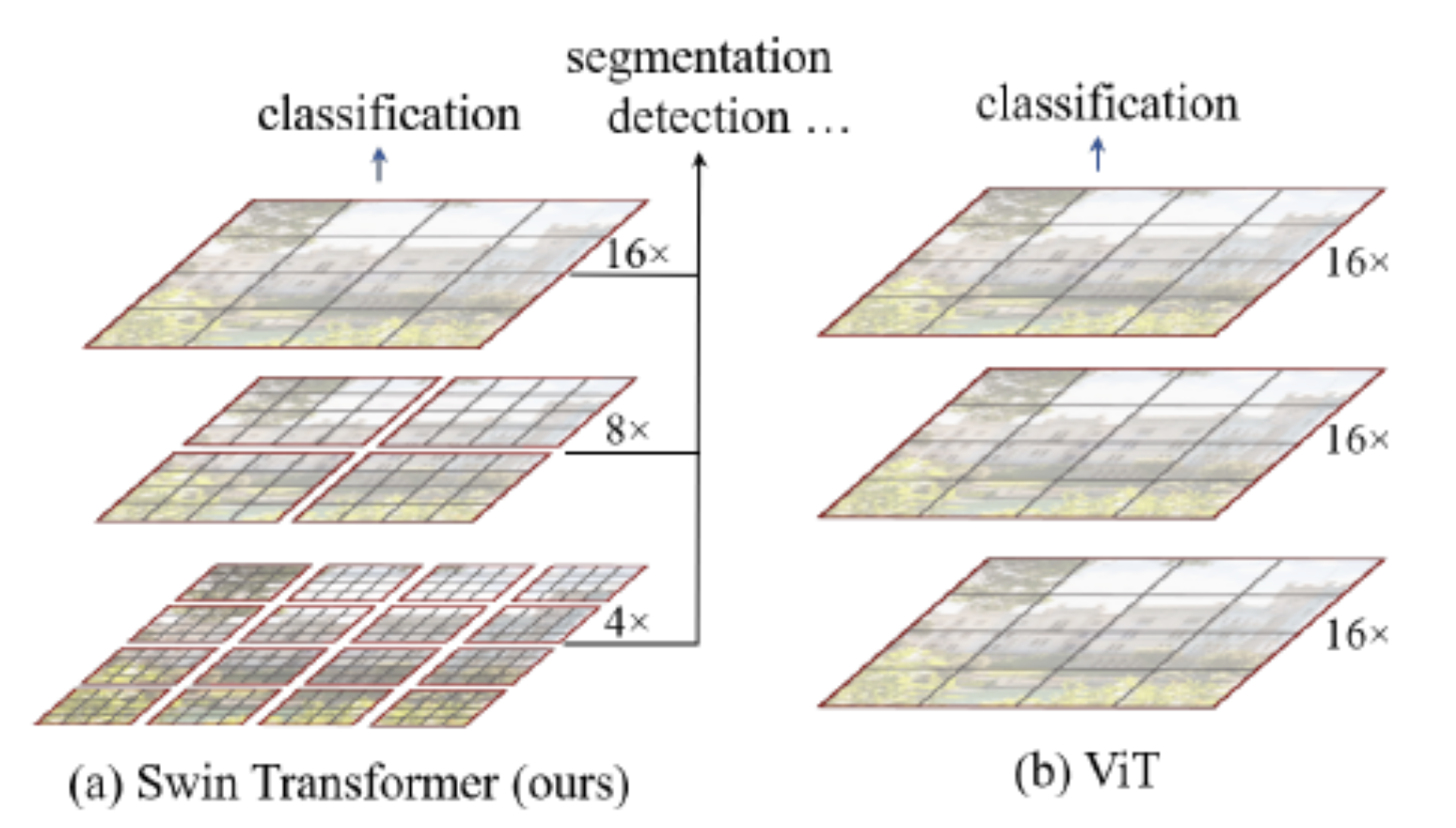
파란색(초록색 형광펜): 제안 기술 1 patch merging주황색: 제안 기술 2 shift windows transformerCNN은 계층적으로 깊어지면서, 이미지의 해상도는 줄어들고 receptive field(네트워크의 특정 뉴런이, 입력 이미지에서 영향을 받
13.DUSt3R: Geometric 3D Vision Made Easy

기존에는 dense 3D reconstruction을 SfM-MVS pipeline 위주로 진행했음input: 여러 각도에서 촬영된 이미지들output:camera parameter (extrinsic + intrinsic)3d pointcloud 좌표방법론두 이미지에
14.3D Gaussian Splatting

Gaussian Splatting은 3D 장면을 2D 이미지로 렌더링할 때 사용이 기법은 각 3D 포인트를 2D 이미지 평면에 가우시안 분포로 변환하여 표현하는 방식이를 통해 부드럽고 자연스러운 이미지를 생성할 수 있음3D 포인트의 표현:Gaussian Splattin
15.[240627] 3D Gaussian Splatting
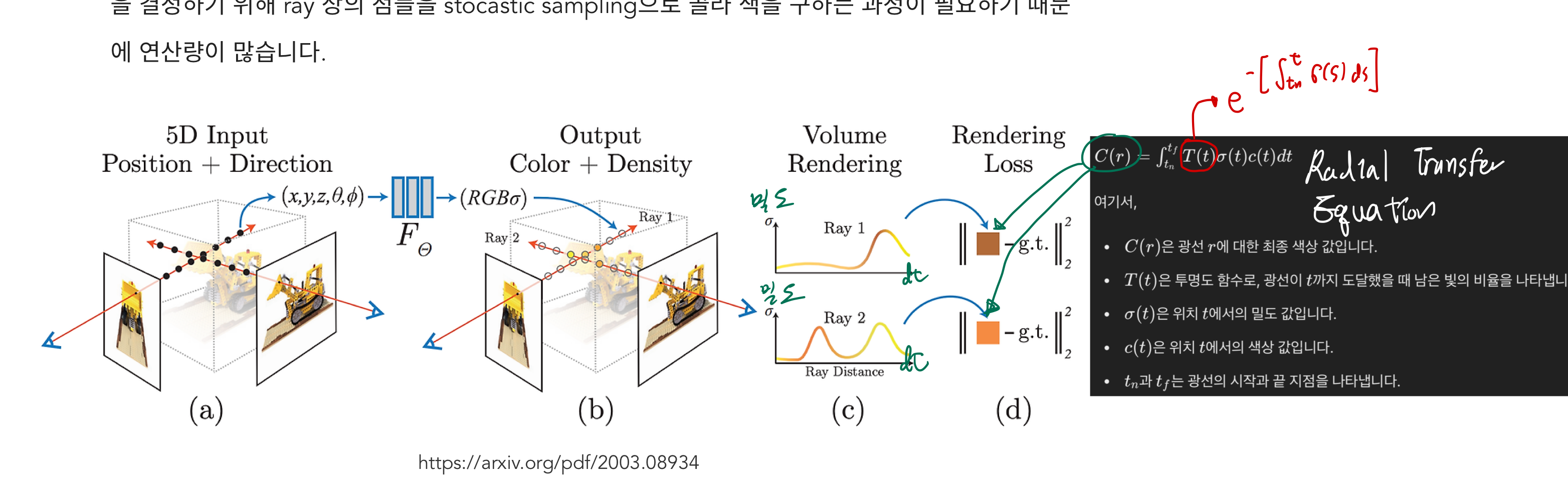
input: 몇몇 각도에서 찍은 RGB 사진output보고 싶은 카메라 view의 카메라 parameter만 정해주면, 그 view에서 보이는 RGB 이미지 도출 가능알고리즘input을 이용하여, 3D 공간 상에 여러 gaussian distribution을 만듭니다.
16.Dyhead module
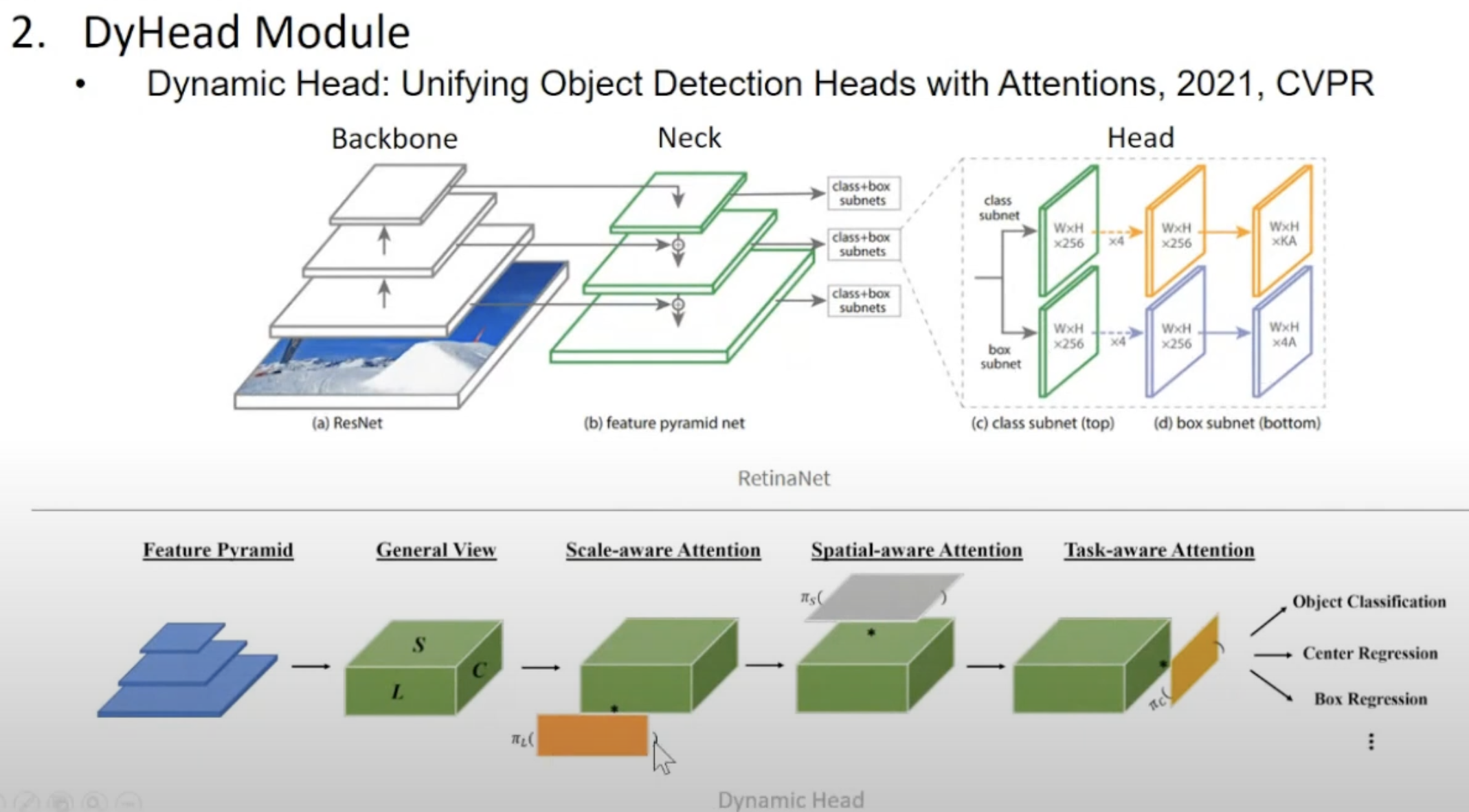
"backbone", "neck", "head"는 각각 다른 역할을 수행하며, 함께 동작하여 복잡한 이미지 기반 태스크를 수행하는 데 필수적인 요소이 구조적인 분할은 모델의 모듈성을 높여 다양한 설정과 태스크에 쉽게 적용할 수 있게 만들어 줍니다.Backbone은 모델
17.pseudo labelling
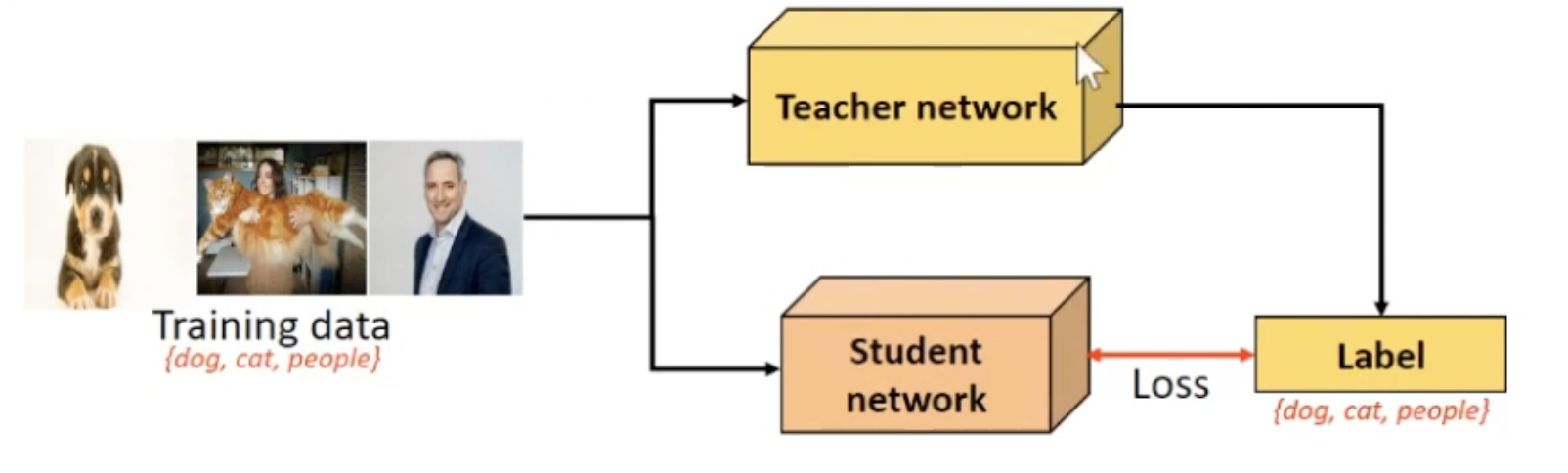
Pseudo labelling: 학습된 모델을 사용하여 레이블이 없는 데이터에 대해 예측을 수행하고, 이 예측값을 마치 실제 레이블인 것처럼 활용하여 모델을 다시 학습시키는 것이 과정에서 생성된 가짜 레이블을 'pseudo label'이라고 함초기 모델 학습: 레이블이
18.Grounding Image Matching in 3D with MASt3R

Dense Correspondences. MASt3R extends DUSt3R as it predicts dense correspondences, even in regions where camera motion significantly degrades the visu
19.Gaussian Filter
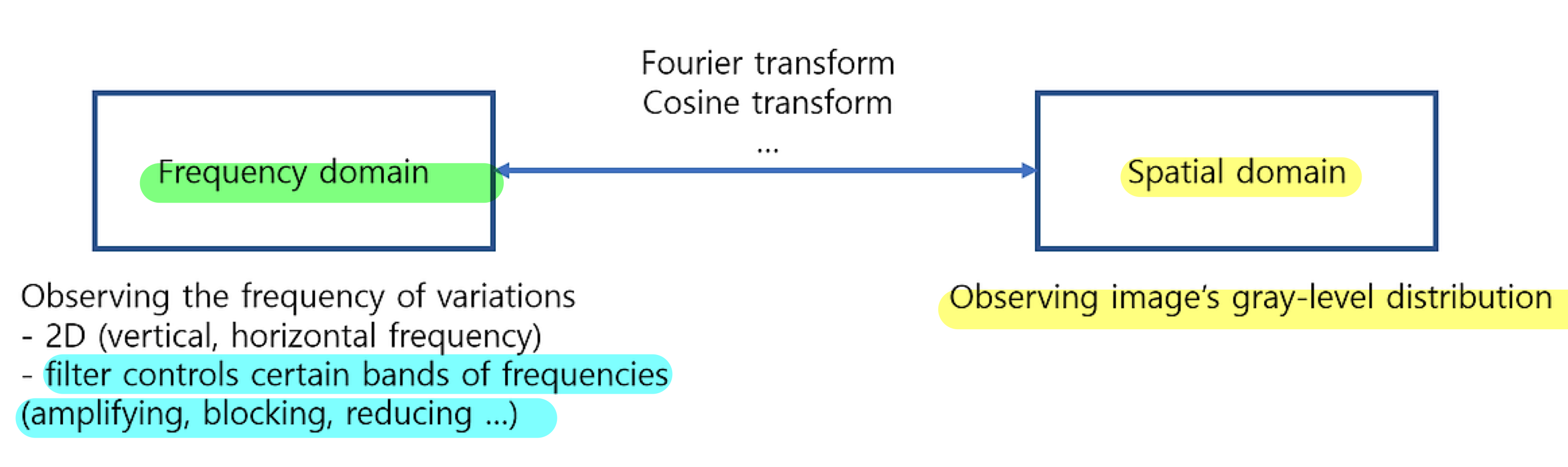
우선 filtering에 앞서 신호 및 시스템의 관점에서 frequency와 spatial domain이 무엇인지 살펴보자. 영상의 픽셀은 0 ~ 255(8bit, gray scale 기준)의 밝기로 이루어져 있다. 이것의 모임이 우리가 보는 영상이 되는 것인데, 신호
20.SIFT 알고리즘

Scale-Invariant-Feature Transform이미지에서, 특징점을 추출하는 알고리즘이미지의 scale(크기), Rotation(회전)에 불변하는 특징점을 추출하는 알고리즘이미지의 크기를 다양하게 변화시켜, 극대점/극소점 detection 이를 통해 ->
21.SfM(Structure from Motion) of COLMAP
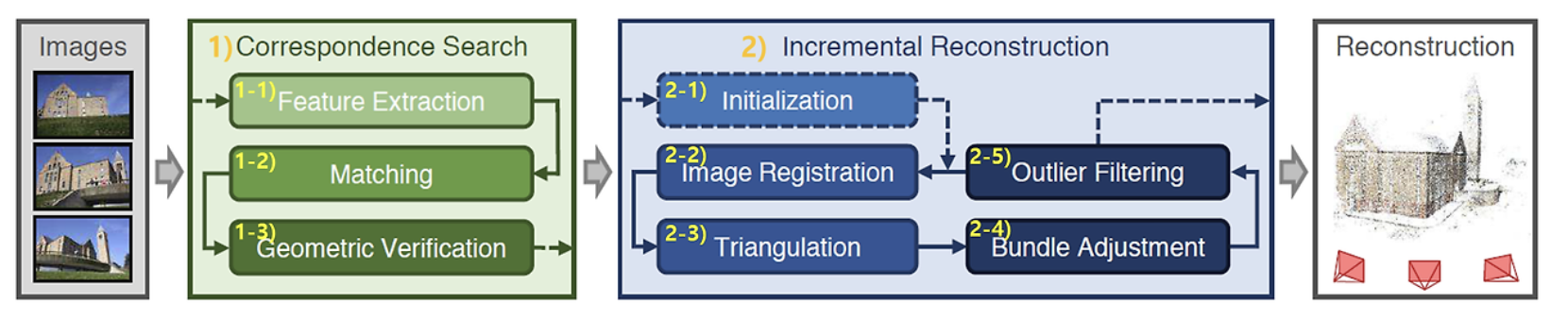
COLMAP은 SfM(Structure from Motion)과 MVS(Multi-View Stereo)를 범용적으로 사용 할 수 있게 만든 라이브러리https://github.com/colmap/colmaphttps://openaccess.thecv
22.Feature Matching
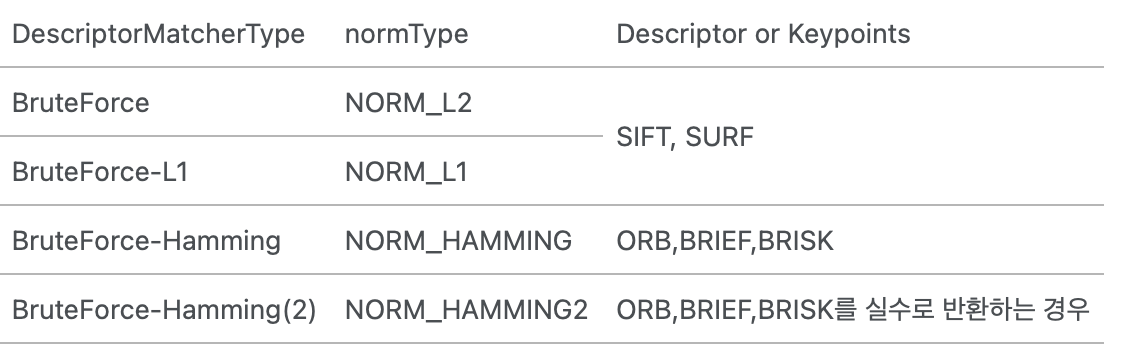
특징 매칭이란 서로 다른 두 이미지에서 특징점과 특징 디스크립터들을 비교해서 비슷한 객체끼리 짝짓는 것https://bkshin.tistory.com/entry/OpenCV-28-특징-매칭Feature-Matchinghttps://alpaca-gt.t
23.[code] Grounding Image Matching in 3D with MASt3R

MASt3R를 클론하세요.conda를 사용하여 환경을 만드세요.옵션으로, RoPE의 CUDA 커널을 컴파일하세요 (CroCo v2에서와 같이).체크포인트는 두 가지 방법으로 얻을 수 있습니다:huggingface_hub 통합 기능을 사용하여 모델을 자동으로 다운로드합니
24.grounded SAM 1, 2 사용
https://github.com/IDEA-Research/Grounded-Segment-Anything?tab=readme-ov-file- environment variable 설정 (local GPU environment)Install Segment Any