abstract
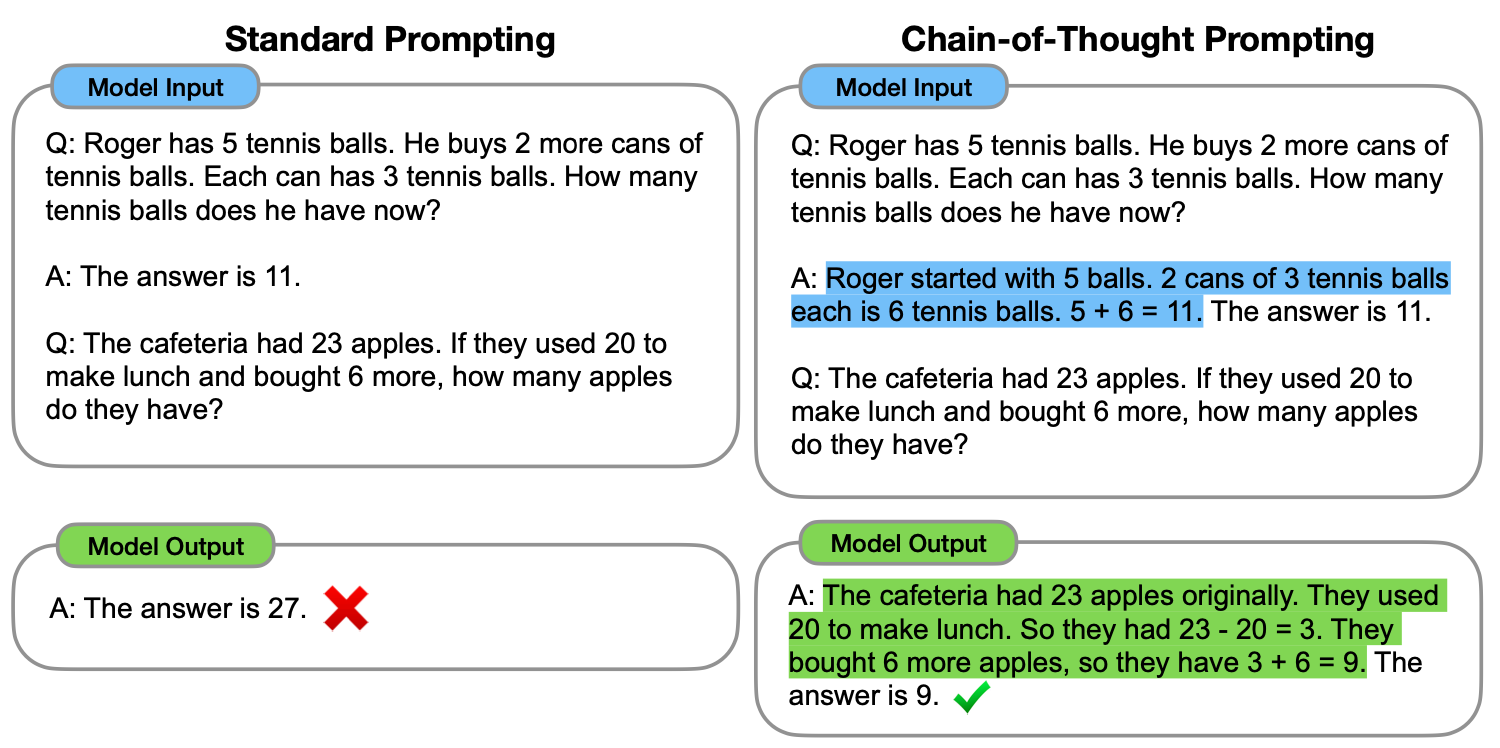
- 이 논문에서는, "중간 추론 단계의 연속인 -> 사고 과정 체인"을 생성하는 것이
- 대형 언어 모델이 복잡한 추론을 수행하는 능력을 크게 향상시키는 방법이 될 수 있다는 것을 탐구합니다.
- 특히, 우리는 사고 과정 체인을 몇 가지 교시로 지시하는 간단한 방법인 체인-오브-사고 프롬프팅(chain-of-thought prompting)을 사용하여 이러한 추론 능력이 충분히 큰 언어 모델에서 자연스럽게 발생하는 방법을 보여줍니다.
- 세 가지 대형 언어 모델 실험에서, 체인-오브-사고 프롬프팅은 산술, 상식, 기호 추론 작업의 성능을 향상시키는 것으로 나타났습니다.
- 경험적 이득은 상당합니다.
- 예를 들어, PaLM 540B 모델에 단지 8개의 체인-오브-사고 예시를 프롬프팅 함으로써, 수학 문제 단어 벤치마크인 GSM8K에서 GPT-3에 근접한 최고의 정확도를 달성합니다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것