- Contrastive Captioners are Image-Text Foundation Models
- 2022년 6월 arXiv
- https://arxiv.org/pdf/2205.01917.pdf
- 1283회 인용
- https://github.com/lucidrains/CoCa-pytorch
- 1100 star
- https://github.com/mlfoundations/open_clip
- FSA와의 연계: https://velog.io/@hsbc/CoCa-FSA와의-연계
0. 들어가기 전에 - 기본적 VLM 학습 방법 설명
글 3줄 요약
image-text contrastive pre-training&image-to text captioning(generative) pre-training학습을 end-to-end로 한번에 처리 가능한 모델 아키텍쳐 및 학습법을 제안함- 이렇게 학습된
Image Encoder은Video Action Recognition테스크를 위해 사용될 수 있음
1. Introduction
- 최근 BERT, T5, GPT-3와 같은
기본 언어 모델(foundation language model) 성장 비전과 비전-언어 문제의 경우에 대해 연구해보자.
1.4. 논문의 제안
- 본 논문에서는 단일 인코더, 이중 인코더, 인코더-디코더 패러다임을 통합하고, 세 가지 접근 방식 모두의 능력을 포함하는 하나의 이미지-텍스트 기반 모델을 학습
Contrastive loss와captioning (generative) loss모두에 대해 end-to-end로 pre-train 가능한,- 수정된 인코더-디코더 아키텍처를 가진 Contrastive Captioners (CoCa)라는 간단한 모델을 제안
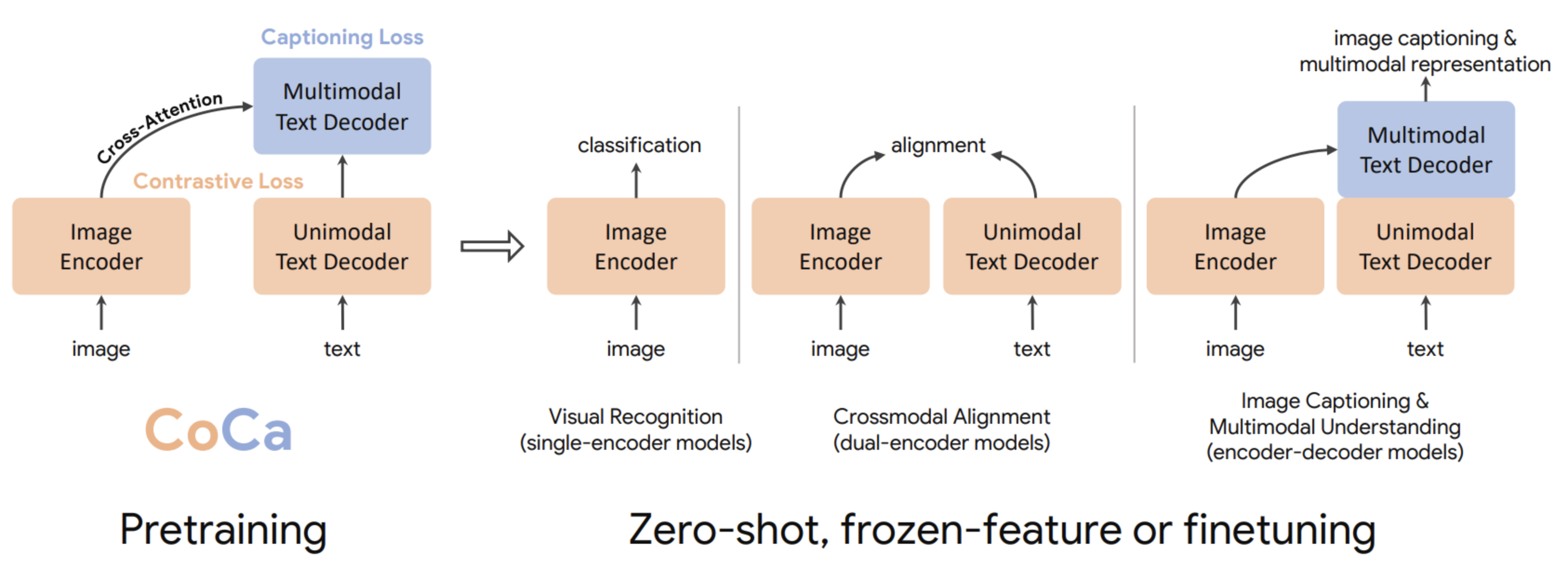
- CoCa의 디자인은 아래 이유로,
세 가지 카테고리 모두에서 도움이 된다.글로벌한 표현을 학습하기 위한 contrastive learning과세분화된 영역 레벨 feature를 위한 captioning을 활용하므로
2. Method
2.1. Constrative Captioners Pre-training
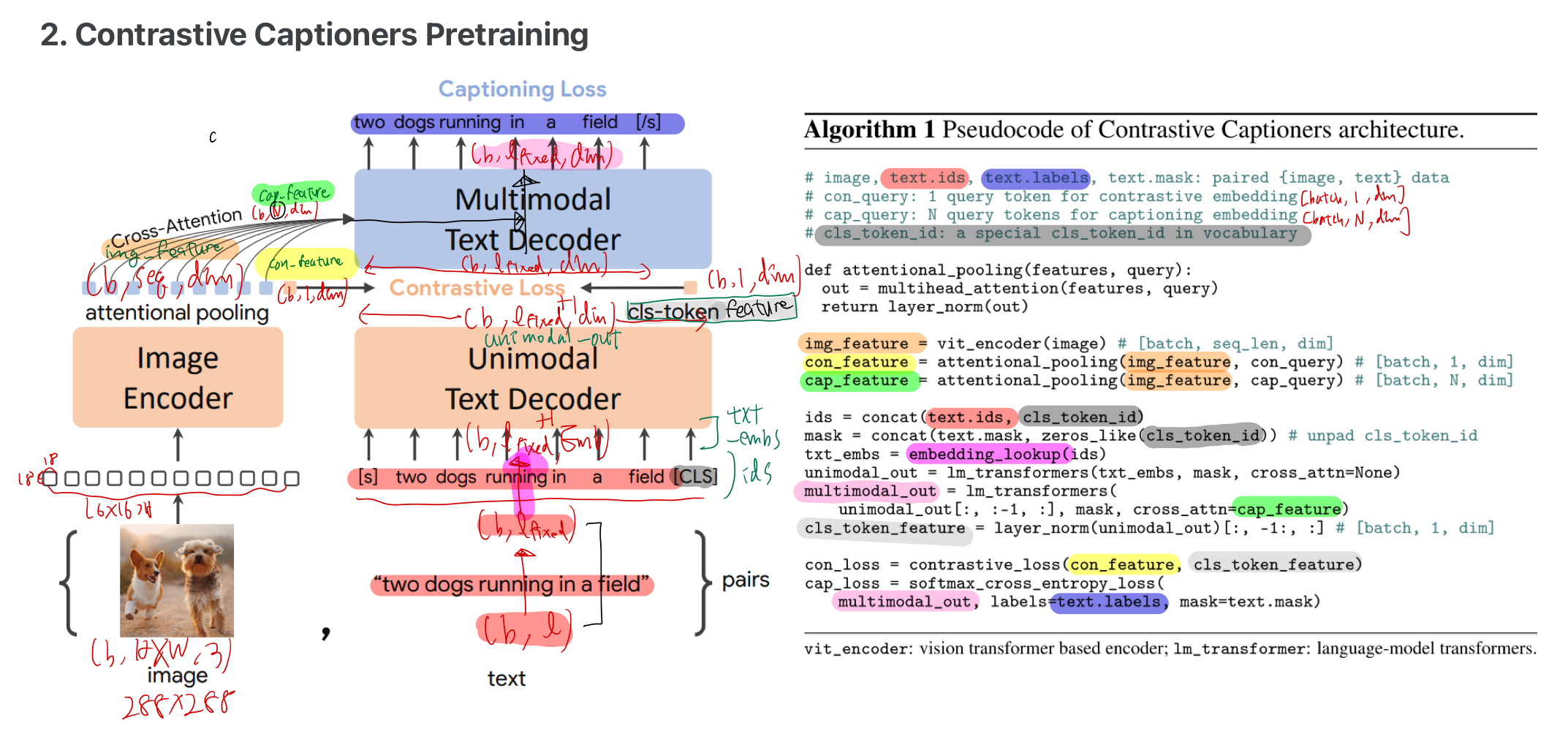
2.1.1. 용어 정리
2.1.2. 설명
- 인코더: causally-masked self-attention
- 디코더: causally-masked self-attention + cross-attention
attentional pooling- 위 그림에 알고리즘 설명 나와있음
모델은 두 목적 함수에 대해 서로 다른 길이의 임베딩을 풀링하는 방법을 학습할 수 있음- Task별 pooling을 사용하면
다양한 task에 대한 다양한 요구 사항을 해결할 뿐만 아니라pooler를 자연스러운 task adapter로 도입 가능
3. 3. Contrastive Captioners for Downstream Tasks
3.1. Zero-shot Transfer
- 전통적인 zero-shot 학습
- 모델이 특정 작업에 대한 사전 지식 없이, 즉 학습 과정에서 본 적 없는 새로운 카테고리나 도메인에 대해 예측을 수행할 수 있어야 함
- 이는 모델이 학습 과정에서 얻은 지식을 일반화하여,
전혀 본 적 없는 새로운 상황에 적용할 수 있음을 의미
- 여기서 말하는 "zero-shot" 학습
- 모델이
사전 학습 중에는 관련 supervision 정보(즉, 정답 레이블이나 지시사항 등)를 볼 수 있음- 이는 모델이 다양한 데이터로부터 지식을 습득할 수 있도록 하지만,
- 실제로 새로운 작업을 수행할 때는 그 작업에 대한 구체적인 예제나 지도 정보 없이 작업을 수행해야 함
- 모델이
- 중복 제거 절차
사전 학습 데이터를 준비할 때, 다운스트림 작업과 관련된 "가까운 도메인"의 예제를 제외하기 위해 엄격한 중복 제거 절차를 따릅니다.- 이는 모델이 특정 작업에 대한 지나치게 구체적인 정보를 미리 학습하는 것을 방지하고, 모델이 보다 일반화된 지식을 학습하도록 하는 데 목적
- 즉, 모델이 실제 작업 수행 시에도 넓은 범위의 상황에 대해 유연하게 대응할 수 있도록 학습 데이터에서 관련된 데이터를 사전에 제거하는 것
3.2. Frozen-feature Evaluation
- CoCa 모델은 다양한 시각적 작업에 대해
고정된 image 인코더 feature을 사용하면서도,- 작업별로 최적화된 attentional pooling 방법(얘만 따로 학습)을 통해 뛰어난 성능을 달성할 수 있음을 보여줌
- 이 접근 방식은 모델의 유연성을 크게 향상시키며, 다양한 작업에 적용 가능한 모델을 구현할 수 있도록 함
3.2.1. Linear Evaluation과 Attentional Pooler의 효용성
- Linear Evaluation:
- 학습된 표현의 품질을 측정하는 방법 중 하나로, 간단한 선형 분류기를 학습된 특징 위에 적용하여 성능을 평가
- 이 방법은 학습된 표현의 질을 정확하게 반영하지 못할 수 있음
- Attentional Pooler의 실용성:
- Linear evaluation에 비해, attentional pooler를 사용하는 것이 현실 세계의 애플리케이션에 더 적합할 수 있음
- 이는 pooler가 이미지로부터 추출된 특징을 작업별로 더 효과적으로 조정할 수 있기 때문
3.3. CoCa for Video Action Recognition
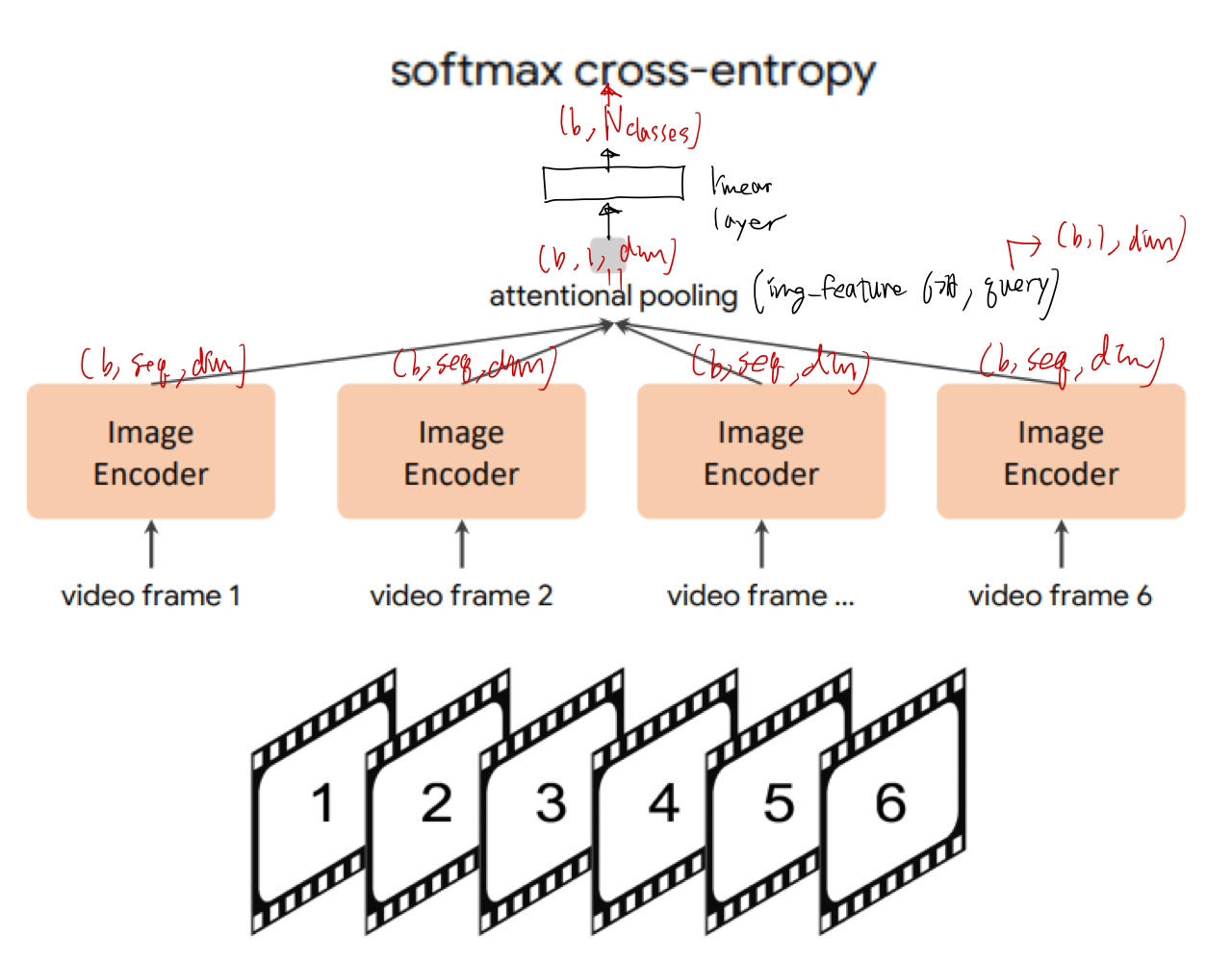
- 먼저 동영상의 여러 프레임을 가져와, 위 그림과 같이 각 프레임을 공유 이미지 인코더에 개별적으로 공급
Pooler에는 하나의 query 토큰이 있으므로, 모든 공간적 및 시간적 토큰에 대한 pooling 계산 비용이 많이 들지 않는다.공간 패치의 모든 토큰의 출력을 가중하는 단일 쿼리 토큰이 학습
- 학습 방식
- pre-train 은, 이미지 인식 벤치마크로서 ImageNet[9]에서 수행되며,
- 이 때,
attentional pooling과softmax cross-entropy loss layer이 학습되고, image encoder은 frozen 하는 것으로 보인다. - TODO: 아마 1장의 frame만 가지고 imageNet으로 사전-학습한 뒤, 바로 비디오 데이터셋을 넣어서 결과 돌려봤는데, 성능이 괜찮았다는 뜻 같음. (근데, 이미지 class 종류가 다르지 않나?)
- 이 때,
- fine tuning
- 이 때도,
attentional pooling과softmax cross-entropy loss layer이 학습되고, image encoder은 frozen 하는 것으로 보인다. - 이때 비디오 데이터셋을 쓰는 것으로 보인다.
- 이 fine tuning이 없어도, 성능이 잘 나온다는게 논문의 주장이다.
- 이 때도,
- test시, 비디오 액션 인식을 위한 테스트 베드로서 Kinetics-400[57], Kinetics-600[58], Kinetics-700[59], Moments-in-Time[60] 등의 여러 비디오 데이터셋을 포함
- 주목할 만한 점은 CoCa가 이미지 데이터만을 사전 학습하며, 추가적인 비디오 데이터셋에 접근하지 않는다는 것 (오디오 신호 역시 없이 )
- pre-train 은, 이미지 인식 벤치마크로서 ImageNet[9]에서 수행되며,
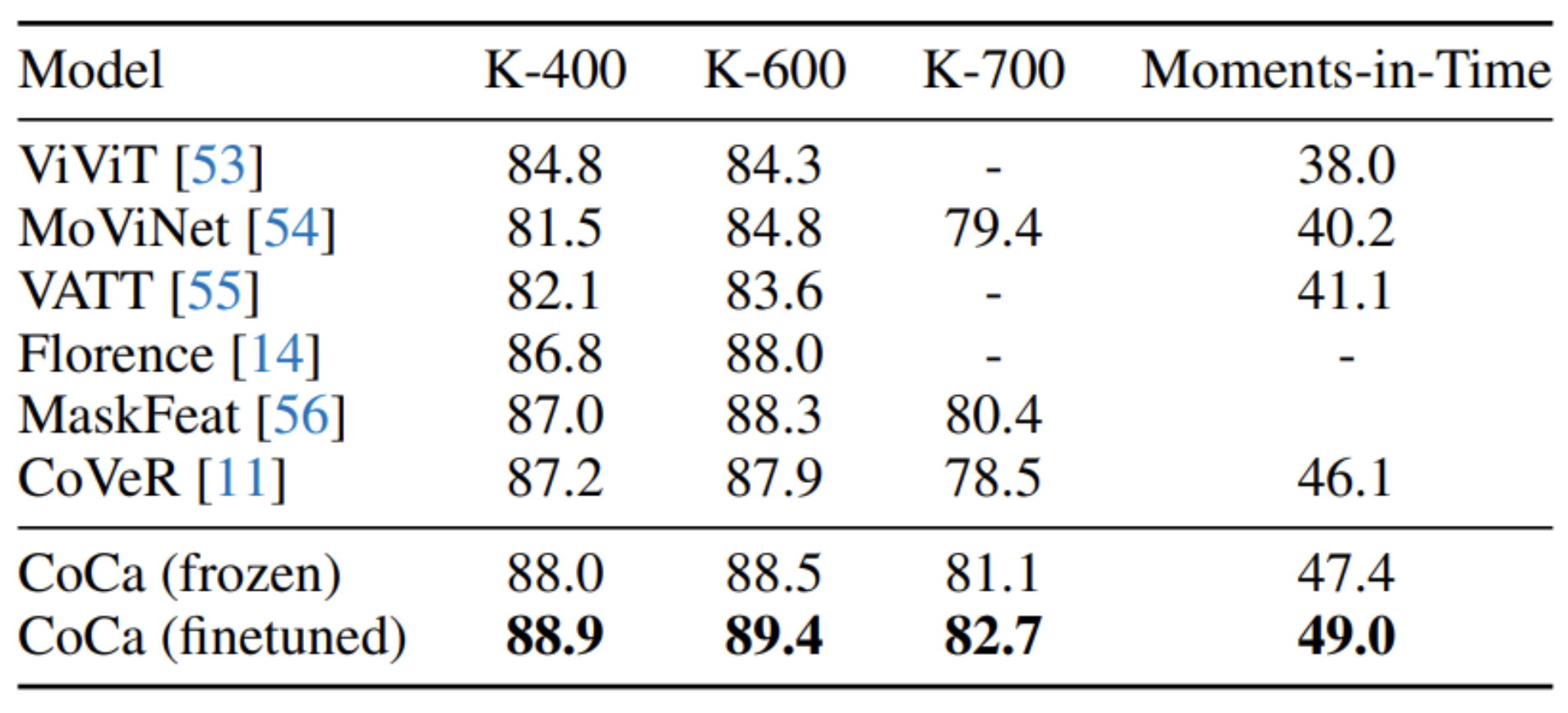
- 시간적 정보의 초기 결합 없이도, 결과적으로 CoCa-for-Video 모델은 많은 시공간적 초기 결합 비디오 모델들보다 더 나은 성능을 보입니다.
- Frozen-feature.
- 인코더만 사용되며, 디코더는 안씀
- CoCa 인코더로부터 나온 임베딩 출력 위에
attentional pooling과softmax cross-entropy loss layer이 학습 - 우리는 attentional pooler와 softmax 모두에 대해 5 × 10−4의 학습률, 128의 배치 크기, 그리고 Cosine Learning Rate Schedule 을 설정(세부 사항은 부록 A 참조).
- 위 표에 나타나 있듯이, 전체 인코더를 미세조정하지 않고도 CoCa는 비디오 작업에 있어서 이전 최고 수준의 전문화된 방법들을 능가
- Finetuning.
- 비디오 데이터셋에서 1 × 10−4의 더 작은 학습률로
CoCa 인코더를 더욱 미세조정 - 미세조정된 CoCa는 이러한 작업들에서 성능이 향상
- 특히, CoCa는 최근의 비디오 접근 방식들과 비교해 더 나은 비디오 액션 인식 결과를 보여줌
- 이러한 결과들은 제안된 프레임워크가 텍스트 훈련 신호를 효율적으로 결합하여, 전통적인 단일 인코더 접근법보다 더 높은 품질의 시각적 표현을 학습할 수 있다는 것을 시사
- 비디오 데이터셋에서 1 × 10−4의 더 작은 학습률로

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것