1. 기초 설명 (roboflow)
- SAM 2는 객체가 무엇인지 이해하지 못하지만, Florence-2라는 멀티모달 모델과 결합하면 텍스트 프롬프트로 이미지 내 특정 영역에 대한 세분화 마스크를 생성할 수 있습니다.
- 예를 들어, 나사(screw) 데이터셋이 있다고 가정하고, "screw"라는 레이블을 제공할 수 있습니다.
- Florence-2는 나사가 포함된 모든 영역을 식별한 후, SAM은 각 나사에 대한 세분화 마스크를 생성할 수 있습니다.
- 이 가이드에서는 SAM 2와 Florence-2를 결합한 Grounded SAM 2를 사용하여 컴퓨터 비전 데이터를 라벨링하는 방법을 안내
- 이 모델은 Autodistill 프레임워크를 사용하며,
- 이를 통해 대규모 기본 모델을 사용하여
- 더 작고 세밀하게 조정된 모델(i.e. YOLOv8, YOLOv10)을 학습시키기 위한 데이터를 자동으로 라벨링할 수 있습니다.
- 이 튜토리얼을 Grounded SAM 2 Colab Notebook을 사용하여 따라할 수 있습니다.
1.1. Step #1: 데이터셋 준비
- 시작하려면 이미지 데이터셋이 필요합니다.
- 이 가이드에서는 해상 컨테이너 데이터셋을 라벨링할 예정입니다.
- 다음 명령어를 사용하여 데이터셋을 다운로드할 수 있습니다:
wget https://media.roboflow.com/containers.zip- 우리의 데이터셋은 여러 해상 컨테이너가 있는 야드의 이미지를 포함하고 있습니다. 다음은 이미지의 예시입니다:
- 여기서는 Florence-2(grounding 모델)와 SAM 2(세분화 모델)의 조합인 Grounded SAM 2를 사용하여 데이터셋의 각 나사에 대한 세분화 마스크를 생성할 예정입니다.
1.2. Step #2: Autodistill Grounded SAM 2 설치
- 데이터셋을 준비한 후, Grounded SAM 2를 설치할 수 있습니다.
- 이 모델은 Autodistill 생태계에서 사용할 수 있습니다.
- Autodistill을 사용하면 대규모 기본 모델을 사용하여 데이터를 자동으로 라벨링하고, 이를 통해 더 작고 세밀하게 조정된 모델을 학습시킬 수 있습니다.
- 다음 명령어를 실행하여 Autodistill Grounded SAM 2를 설치하세요:
pip install autodistill-grounded-sam-2- 모델을 설치한 후에는 데이터셋에 어떤 프롬프트가 가장 잘 맞는지 테스트할 준비가 되었습니다.
1.3. Step #3: 프롬프트 테스트
- Grounded SAM 2를 사용하면 텍스트 프롬프트를 제공하고 해당 프롬프트와 일치하는 모든 객체에 대한 세분화 마스크를 생성할 수 있습니다.
- 그러나 데이터셋 전체에 대해 자동 라벨링을 하기 전에, 관심 있는 객체를 정확하게 식별하는 프롬프트를 찾는 것이 중요
- 우선 "shipping container"(해상 컨테이너)라는 프롬프트를 테스트해봅시다.

- 새 Python 파일을 생성하고 다음 코드를 추가하세요:
from autodistill_grounded_sam_2 import GroundedSAM2
from autodistill.detection import CaptionOntology
from autodistill.utils import plot
import cv2
import supervision as sv
base_model = GroundedSAM2(
ontology=CaptionOntology(
{
"screw": "screw"
}
)
)
results = base_model.predict("image.png")
image = cv2.imread("image.png")
mask_annotator = sv.MaskAnnotator()
annotated_image = mask_annotator.annotate(
image.copy(), detections=results
)
sv.plot_image(image=annotated_image, size=(8, 8))- 위 코드에서는 필요한 종속성을 가져온 후 GroundedSAM2 모델의 인스턴스를 초기화합니다.
- "screw"(나사)를 프롬프트로 설정하고 결과를 "screw"라는 클래스 이름으로 저장합니다.
- 프롬프트를 맞춤화하려면 첫 번째 "screw" 텍스트를 변경하세요.
- 최종 데이터셋에 저장될 레이블을 맞춤화하려면 두 번째 "screw"를 변경하세요.
- 그런 다음 "image.png"라는 이미지에서 추론을 실행합니다.
supervisionPython 패키지를 사용하여 모델이 반환한 세분화 마스크를 시각화합니다.- 다음 이미지를 사용하여 스크립트를 실행해봅시다:

- 보라색 색상은 컨테이너가 식별된 위치를 나타냅니다. 시스템이 두 개의 컨테이너를 모두 성공적으로 식별했습니다!
- 프롬프트가 데이터에 맞지 않으면, 위의 "shipping container" 프롬프트를 변경하고 다양한 프롬프트를 시도해보세요.
- 데이터에 맞는 프롬프트를 찾기까지 몇 번의 시도가 필요할 수 있습니다.
- Grounded SAM 2는 일부 객체를 식별하지 못할 수도 있습니다. Grounded SAM 2는 일반적인 객체에서 가장 잘 작동합니다.
- 예를 들어, 모델은 컨테이너를 식별할 수 있지만, 컨테이너 ID의 위치를 찾는 데는 어려움을 겪을 수 있습니다.
1.4. Step #4: 데이터 자동 라벨링
- 프롬프트가 성공적으로 객체를 식별한 경우, 이제 전체 데이터셋을 라벨링할 수 있습니다.
- 새 폴더를 만들고 라벨링하려는 모든 이미지를 폴더에 추가하세요.
- 다음 코드를 사용하여 이를 수행할 수 있습니다:
base_model.label("containers", extension="jpg")- 위 코드에서 "containers"는 라벨링하려는 이미지가 있는 폴더 이름으로 대체하고, "jpg"는 폴더 내 이미지의 확장자로 대체하세요.
- 준비가 되면 코드를 실행하세요.
- 이미지는 Grounded SAM 2를 사용하여 라벨링되고 새 폴더에 저장됩니다.
- 라벨링 과정이 완료되면, 데이터를 Roboflow에 가져올 수 있습니다.
1.5. Step #5: 모델 학습
- 라벨링된 데이터셋이 준비되면, 다음 단계는 라벨의 품질을 검사하고 모델을 학습하는 것
- Roboflow에는 이 두 가지 작업을 위한 유틸리티가 있습니다.
- Roboflow를 사용하면 주석을 검토하고 수정한 후, 데이터셋을 사용하여 모델을 학습시킬 수 있습니다.
- 데이터셋을 검사하고 모델을 학습시키려면 먼저 무료 Roboflow 계정을 생성하세요.
- 그런 다음, Roboflow 대시보드에서 "Create Project"(프로젝트 생성)를 클릭하세요.
- 프로젝트 이름을 설정한 후, 프로젝트 유형으로 "instance segmentation"(인스턴스 세분화)을 선택하세요.
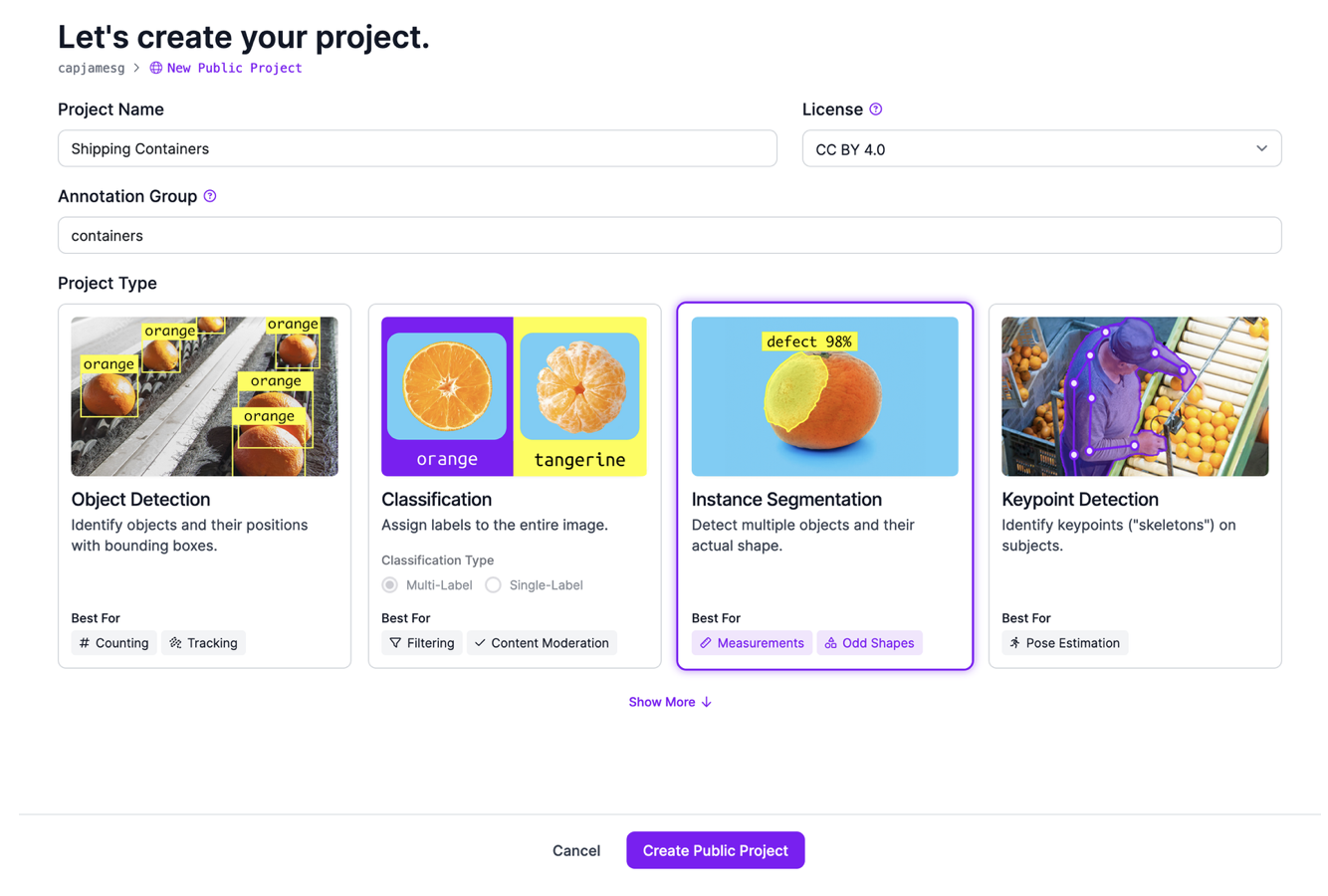
- 이미지를 검토할 수 있는 페이지로 이동합니다.
- Grounded SAM 2가 생성한 라벨링된 이미지 폴더를 해당 페이지에 드래그 앤 드롭하세요.
- 이미지는 브라우저에서 처리됩니다.
- 이미지가 업로드 준비가 되면, "Save and Continue"(저장하고 계속)를 클릭하세요.
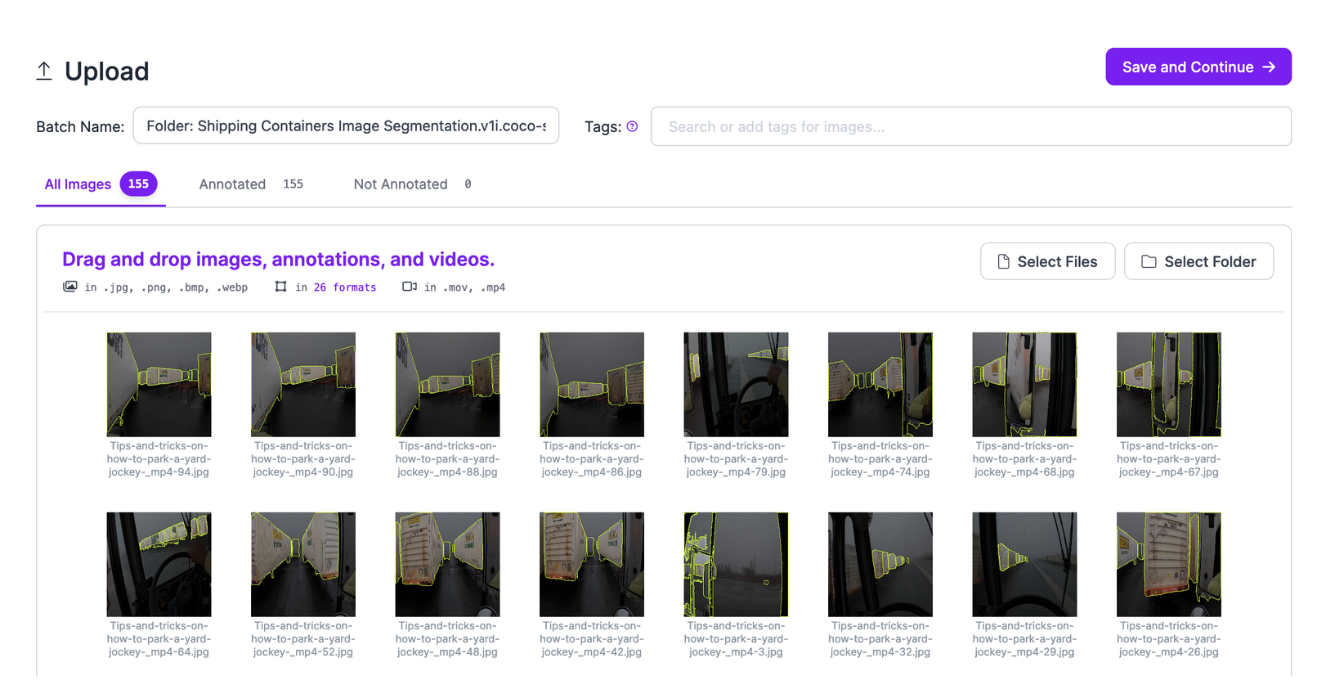
-
이제 이미지를 검토하고 주석을 수정할 수 있습니다. 업로드한 데이터셋 배치를 클릭한 다음, 주석을 검사하고 수정할 이미지를 선택하세요.
-
폴리곤을 추가, 조정 및 제거할 수 있습니다. Roboflow Annotate 문서를 참조하여 Roboflow에서 주석 작업 및 사용 가능한 기능에 대해 더 알아보세요.
-
새 폴리곤을 빠르게 추가하는 방법은 Segment Anything 기반 라벨링 도구를 사용하는 것입니다. 이 도구를 사용하면 이미지의 특정 영역을 클릭하여 폴리곤을 할당할 수 있습니다.
-
이 기능을 활성화하려면 오른쪽 작업 표시줄의 마법봉 아이콘을 클릭한 다음, "Enhanced Smart Polygon"(향상된 스마트 폴리곤)을 클릭하세요. 그러면 Segment Anything 기반의 스마트 폴리곤 주석 도구가 활성화됩니다. 이 도구를 사용하면 이미지의 일부에 마우스를 올려 어떤 마스크가 생성될지 확인한 후, 클릭하여 마스크를 생성할 수 있습니다.
-
이미지를 라벨링한 후에는 Roboflow의 "Generate"(생성) 탭에서 데이터셋 버전을 생성할 수 있습니다. 이 탭에서 데이터셋에 대한 증강 및 전처리 단계를 적용할 수 있습니다. 전처리 및 증강을 통해 모델 성능을 향상시키는 방법에 대한 가이드를 참조하세요.
-
참고: 데이터셋에 테스트 세트 이미지가 0개인 경우, Train/Test Split(학습/테스트 분할)을 클릭하고 데이터셋을 재조정하여 테스트 세트에 이미지가 포함되도록 하세요. 모델을 학습시키려면 테스트 세트에 이미지가 있어야 합니다.
-
준비가 되면 "Create"(생성) 버튼을 클릭하여 데이터셋 생성을 완료하세요. 선택한 전처리 및 증강 단계를 적용하여 데이터셋 버전을 생성합니다. 생성이 완료되면 데이터셋 페이지로 이동하여 모델을 학습시킬 수 있습니다.
-
"Train with Roboflow"(Roboflow로 학습) 버튼을 클릭하여 모델 학습을 시작하세요. 학습 작업을 사용자 정의할 수 있습니다. 첫 학습 작업에서는 "Recommended"(권장) 옵션을 선택하세요: 빠른 학습 및 COCO 체크포인트에서 학습 시작.
-
학습이 시작되면, Roboflow 대시보드에서 학습 진행 상황을 모니터링할 수 있습니다.
1.6. 다음 단계
-
학습된 모델이 있으면 Roboflow 대시보드의 "Visualize"(시각화) 탭에서 미리볼 수 있습니다. 다음은 데이터셋에서 해상 컨테이너를 감지하는 모델의 예시입니다:
-
모델이 데이터셋 내 컨테이너의 위치를 성공적으로 식별했습니다.
-
모델이 학습되면 다음 단계는 모델을 배포하는 것입니다. Roboflow API를 사용하여 모델을 클라우드에 배포하거나, 직접 하드웨어에서 모델을 배포할 수 있습니다. 직접 하드웨어에서 모델을 배포하려는 경우, Roboflow Inference를 사용하여 배포할 수 있습니다. Inference는 고성능 자가 호스팅 컴퓨터 비전 추론 서버입니다.
-
Inference는 NVIDIA Jetson 장치, Raspberry Pi, 자체 클라우드 GPU 서버, AI PC 등에서 배포할 수 있습니다.
-
세분화 모델을 Inference로 배포하는 방법에 대해 자세히 알아보려면 Inference 문서를 참조하세요.
