1. Introduction
1.1. self-supervised learning : 여러가지 방식들 존재
- GPT: auto-gressive
- auto: 스스로의 이전 상태에 의존한다.
- regressive: 과거의 데이터를 바탕으로, 미래를 예측한다.
- BERT: MAE
- Masked Language Model (MLM):
• 정의: Masked Language Model은 입력 텍스트에서 일부 단어를 마스킹(masking)하고, 모델이 이 마스킹된 단어들을 예측하도록 학습하는 모델 - Auto-Encoding:
• 정의: Auto-Encoding은 입력 데이터를 인코딩한 후, 이 인코딩된 정보를 바탕으로 원래 데이터를 복원하는 과정. BERT는 마스킹된 단어를 예측하는 과정에서 입력 문장의 의미와 구조를 인코딩합니다.
• 양방향성: BERTs는 마스킹된 단어의 왼쪽과 오른쪽 문맥 모두를 사용하여 예측을 수행. 따라서 BERT는 문장의 전체 문맥을 고려하여 보다 정확한 예측을 할 수 있음
- Masked Language Model (MLM):
1.2. NLP와 Computer vision 차이
- 텍스트 1개가 가지는 semantic 의미는 크지만, 픽셀 1개가 가지는 semantic 의미는 작다.
- 그러므로, MAE를 이미지에 적용할때는, 픽셀 마스킹 비율을 75% 정도로 가져가야, 모델이 충분이 학습된다.
- MAE 디코더 관점에서, mask된 픽셀 1개를 맞추는 난이도는, mask된 텍스트 1개를 맞추는 난이도에 비교했을 때, 더 쉽다.
- 그러므로, 이미지 인풋 MAE 디코더를 text 인풋의 디코더와 같은 크기로 가져가면, 이미지 MAE 인코더가 충분히 학습되기 어렵다.
- 그러므로, 이미지 인풋 MAE 디코더는 보다 light-weight 하게 설계하였다.
2. Approach
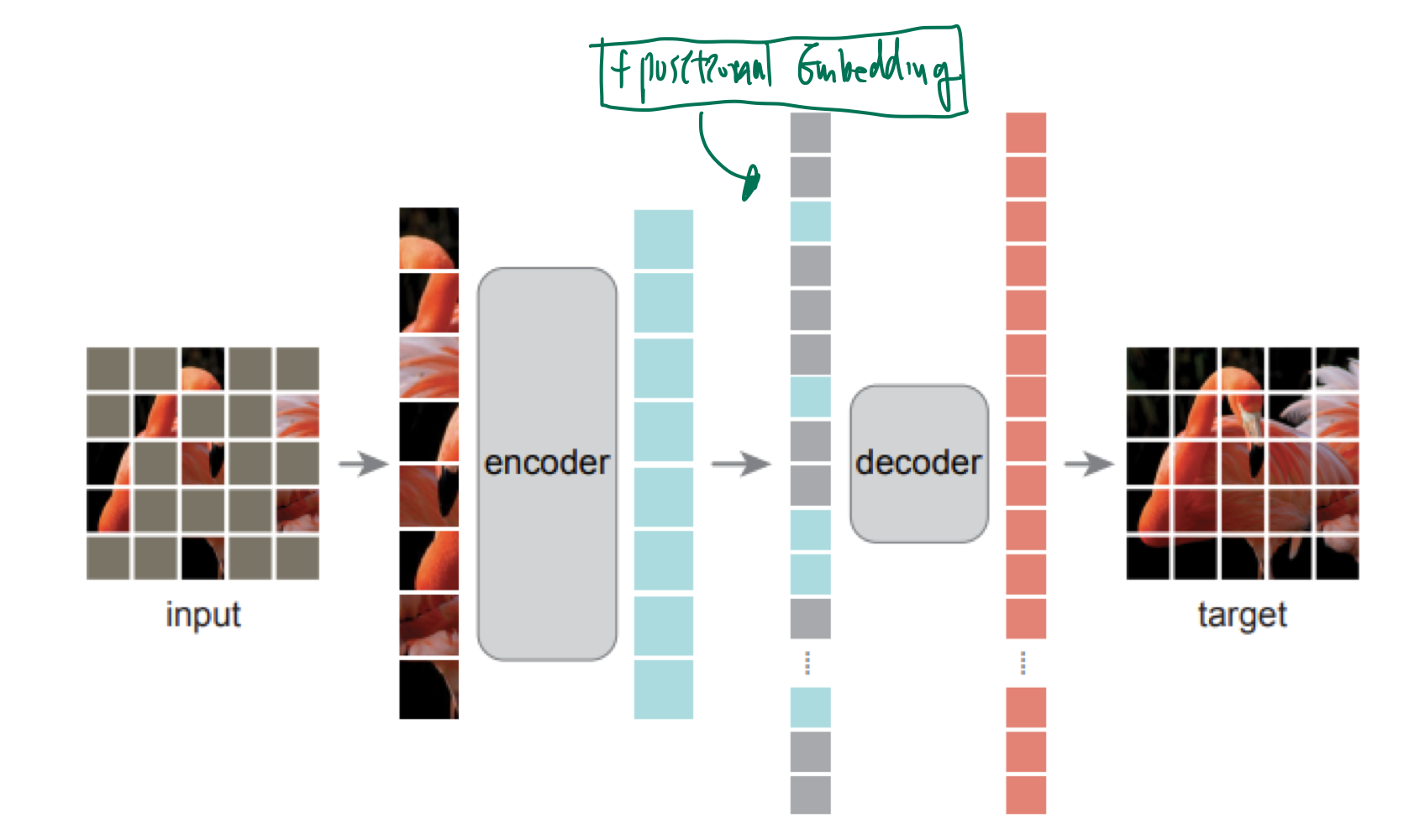
- 마스킹된 패치 영역에 대해서만, MSE Loss를 계산함. (pixel level)
- MAE의 디코더는 pre training 단계에서만 사용이 되고, 그 후에는 encoder만이 image representation 생성을 위해 사용됨.
디코더가 인코더의 10% 수준으로 computation이 소모됨.- 계산량이 매우 적음
- 인코더:
25% 에 해당하는 visible token만 처리 - 디코더: 애초에 연산량이 별로 없음.
- 인코더:
3.Experiments
Masking ratio
- https://velog.io/@hsbc/linear-probing-VS-fine-tuning
- 위 2가지 task 모두 75% 정도의 높은 비율 추천
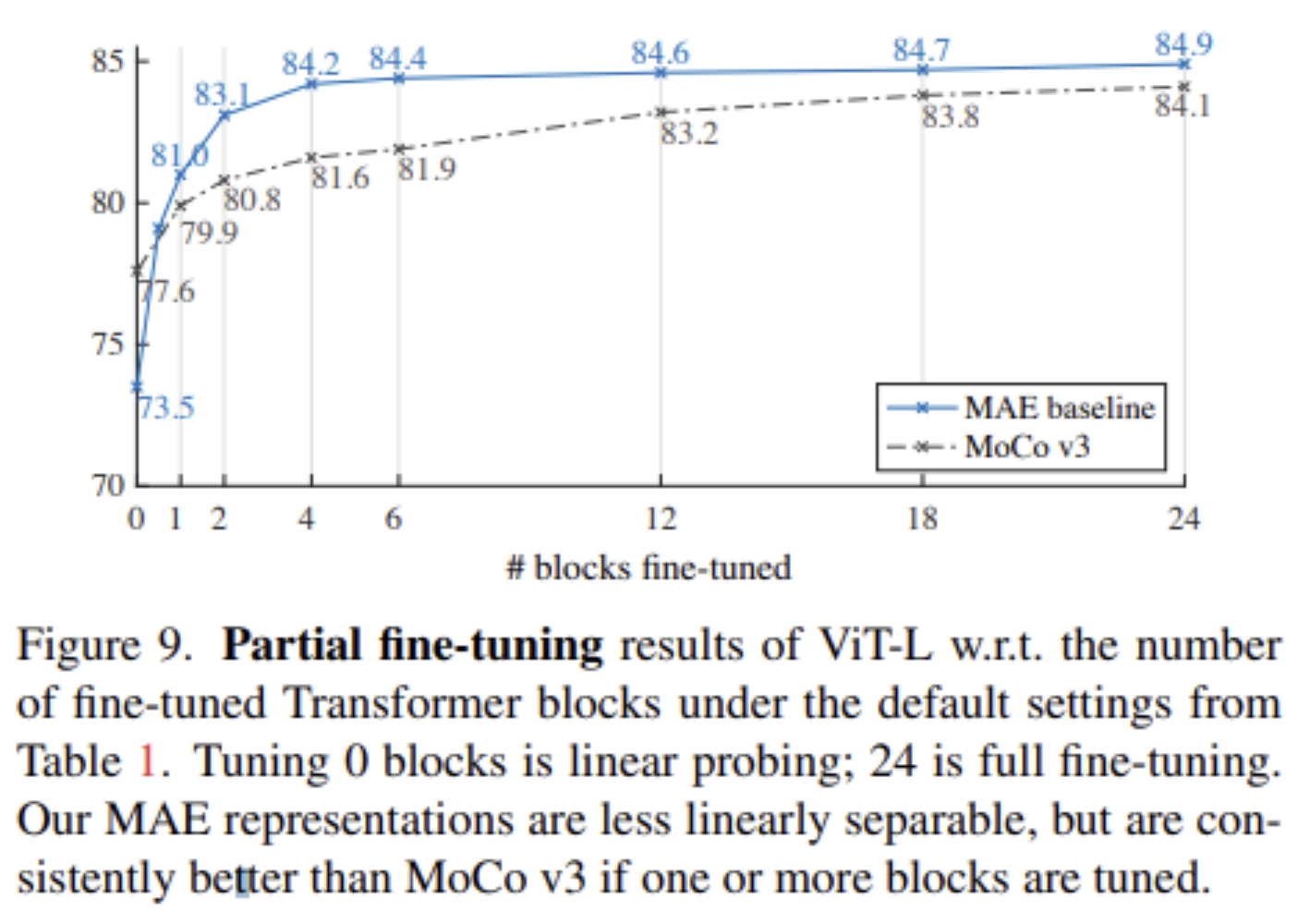
Partial FIne Tuning

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것