딥러닝 기초
1.modality / multi-modal / VQA

딥러닝에서, modality란 입력 데이터의 종류 또는 유형을 의미합니다.보통 비전, 음성, 텍스트 등과 같은 다양한 유형의 모달리티가 있으며, 이러한 모달리티는 서로 다른 형식의 입력 데이터를 나타냅니다.예를 들어, 이미지 모달리티는 픽셀 값으로 구성된 이미지 데이터
2.pre-training / fine-tuning / transfer learning / prompt-tuning
먼저 큰 데이터셋에서 모델을 사전 학습시키는 과정을 말합니다. 일반적으로 pre-training에는 대량의 데이터셋이 필요하며, 이를 통해 모델은 데이터의 패턴과 특징을 파악하고 일반적인 지식을 학습합니다. 이러한 사전 학습을 통해 모델은 새로운 작업에 대해 더 잘 일
3.BERT
2018년 구글에서 발표한 사전 학습(pre-training) 방식의 언어 모델입니다.BERT는 Transformer라는 모델 구조를 사용하며, 입력 문장의 좌우 문맥을 모두 참고하는 양방향(bidirectional) 학습을 수행합니다.이를 통해 문장 안의 각 단어들이
4.stable diffusion
"Stable Diffusion"은 주로 이미지 생성 및 변환에 사용되는 인공지능 모델인 "Diffusion Models"의 안정성을 개선하기 위해 개발된 기술입니다.Diffusion Models은 이미지의 생성, 수정, 압축, 복원 등에 적용되며, 주로 머신 러닝과
5.Atrous depth-wise separable convolution
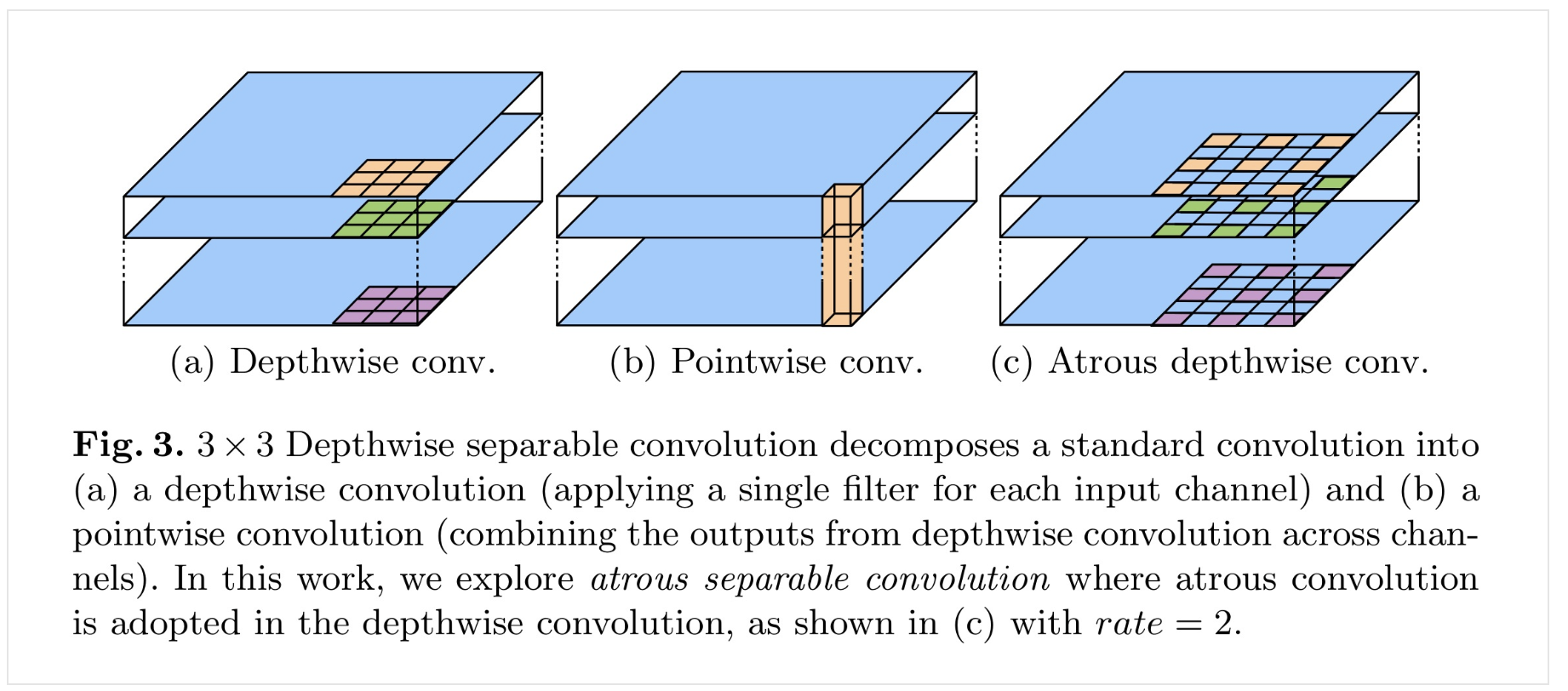
depthwise convolution 왜 쓰는데?계산량 줄일 수 있어.채널 correlation 을 피할 수 있다. (RGB 채널을 예로 들면, R채널만의 공간적 특징을 추출할 수 있다.)Depthwise separable convolution 왜 쓰는데?기존 CNN
6.reparameterized convolution
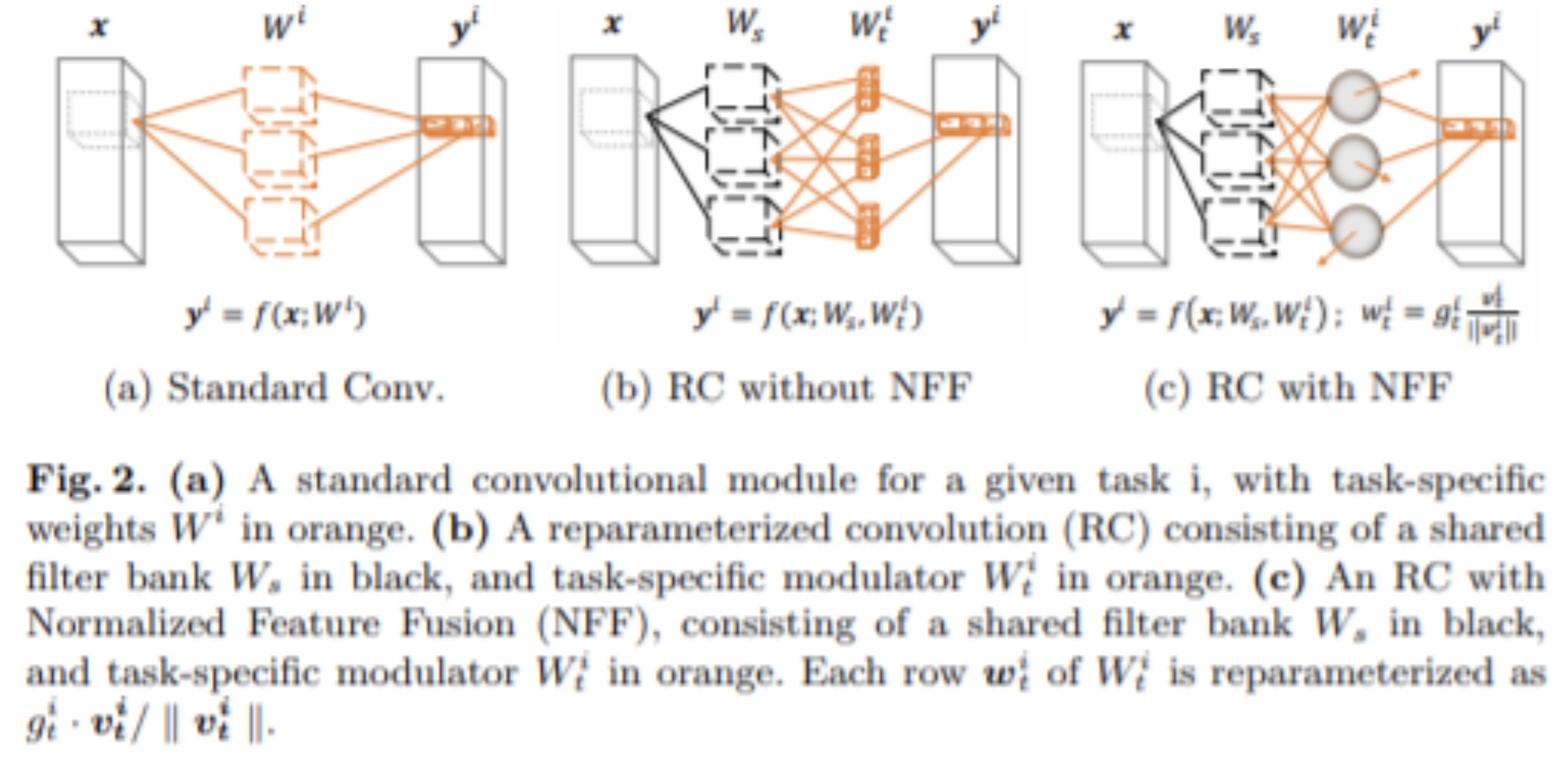
7.normalization layers
"normalization 효과"는 딥러닝 모델의 과적합(overfitting)을 방지하거나 완화학습 데이터에서의 성능과, inference시 다른 데이터에서의 성능 차이가 적게 하기 위함. (generalization 성능 업)물체 인식 분야에서는 대부분의 경우 Ba
8.Atrous Convolution
다양한 receptive field를 가져가면서도, 계산량을 줄이고 싶음.다양한 receptive field를 가져가면 좋은 점?이미지로부터, 큰 그림을 도출할 수 있으면서도,이미지로부터, 디테일도 놓치지 않을 수 있다.
9.Encoder/decoder 깊이의 영향
encoder가 깊어질수록 더 큰 물체만을 잡아낼 수 있습니다.decoder가 깊어질수록 디테일이 점점 더 복구됩니다.encoder + decoder 을 쓰면, 선명한 물체간 경계를 확보할 수 있다
10.Cross-sample augmentation

두 개 이상의 샘플을 결합하여 새로운 훈련 샘플을 생성하는 방법을 의미합니다. 이러한 기법은 일반적으로 과적합을 방지하고 모델의 일반화 성능을 향상시키는 데 도움을 줍니다.MixUp과 CutMix는 대표적인 Cross-sample augmentation 기법들입니다:M
11.Contrastive Learning

Contrastive Learning은 딥러닝, 특히 비지도 학습(unsupervised learning) 분야에서 중요한 개념으로, 데이터 포인트들 사이의 유사성과 차이를 학습하는 방법론레이블이 없는 대규모 데이터셋을 활용할 수 있게 해줌이 접근 방식은 주로 특징 추
12.Similarity Contrastive Estimation(SCE)
"Similarity Contrastive Estimation (SCE)"과 "Contrastive Learning"은 둘 다 데이터의 표현(representation)을 학습하는 데 사용되는 방법론이 두 개념은 서로 밀접하게 관련되어 있으며, 데이터 포인트들 간의 유
13.Masked Modeling

딥러닝 분야에서 "Masked Modeling"은 주로 자연어 처리(NLP) 분야에서 사용되는 학습 기법입니다. 이 방법은 특히 비지도 학습(unsupervised learning)의 형태로, 텍스트 데이터에서 일부 단어나 토큰을 '마스킹(가리기)'한 후, 이 마스킹된
14.Knowledge Distillation

1. 개념
15.MoCO: Momentum Contrast for Unsupervised Visual Representation Learning
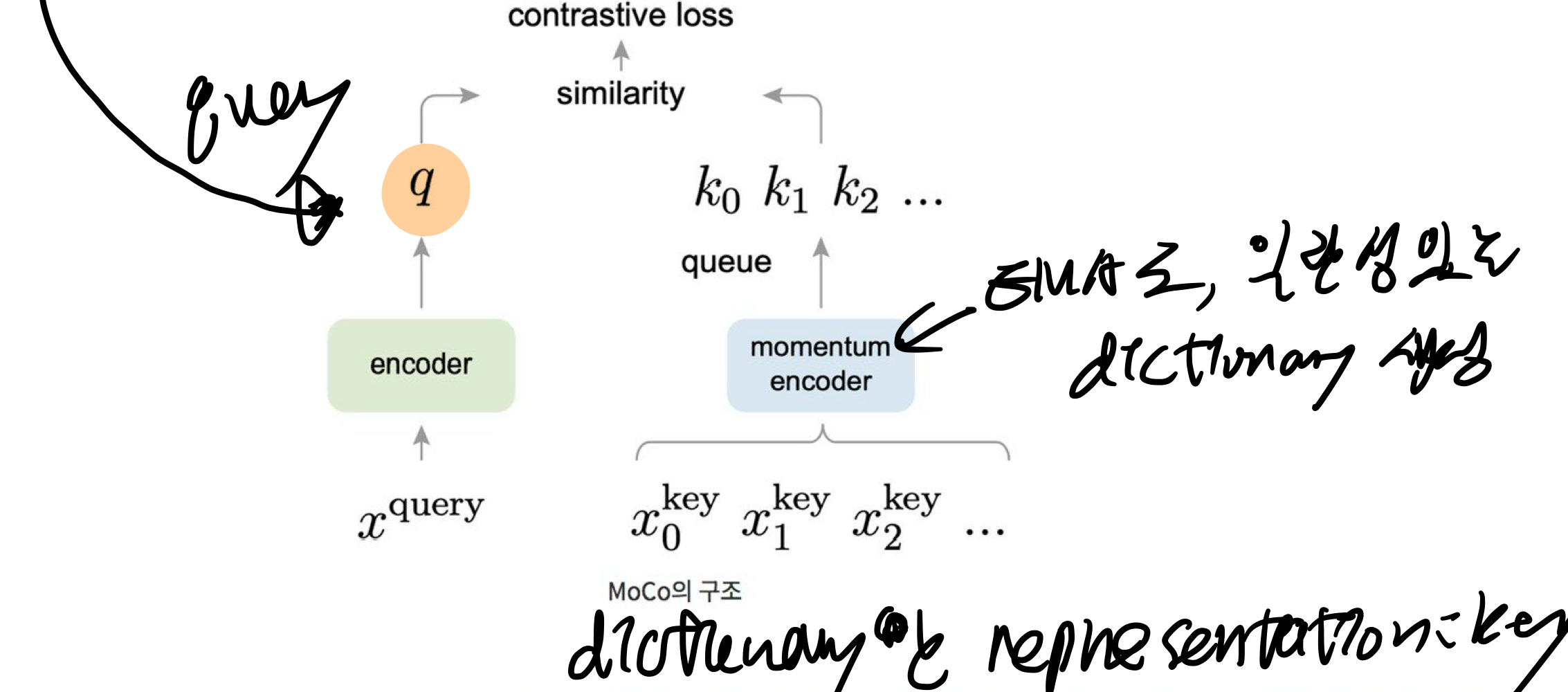
self-supervised 방식으로 visual encoder를 학습시키는 방법을 소개대량의 이미지를 가지고도 모델 학습이 가능key를 뽑아내는 encoder에는, 이미지가 들어갈 수도 있고, 이미지의 일부인 패치가 들어갈 수도 있음dictionary란, 이미지들을
16.Sharpness-Aware Minimization(SAM) / Weight Decay /

Sharpness-Aware Minimization (SAM):SAM은 모델의 일반화 능력을 향상시키기 위한 최적화 기법입니다.전통적인 훈련 방식은 데이터에 대한 모델의 예측 오차(손실)를 최소화하는 것에 중점을 둡니다. 그러나 SAM은 손실 함수의 '날카로움'도 고려
17.Adam Optimizer

Adam (Adaptive Moment Estimation) optimizer는 경사 하강법의 변형으로, 각 매개변수에 대해 학습률을 적응적으로 조정하면서 최적화를 수행합니다. Adam optimizer는 모멘텀(momentum)과 RMSprop의 개념을 결합하여, 1
18.Mixup Data Augmentation
Mixup은 두 개의 서로 다른 훈련 샘플(예: 이미지나 텍스트 데이터)을 섞어서 새로운 샘플을 만드는 방법구체적으로, Mixup은 두 샘플을 일정 비율로 섞습니다. 예를 들어, 한 이미지를 70% 비율로, 다른 이미지를 30% 비율로 섞어 새로운 이미지를 만듭니다.이
19.[torch] cross entropy loss

Cross Entropy Loss는 주로 분류 문제에서 모델의 예측이 실제 레이블과 얼마나 잘 일치하는지를 측정이는 모델의 예측 확률 분포와 실제 레이블의 확률 분포 사이의 차이를 측정예측된 확률 분포가 실제 분포를 얼마나 "잘" 표현하는지를 측정아래 식을 최소화하는
20.Epoch, Batch Size, Iteration
Epoch은 주어진 데이터셋을 기반으로 한 학습 과정에서, 모델이 전체 데이터셋을 한 번 전부 사용하여 학습을 완료한 단계를 의미즉, 모든 학습 데이터가 네트워크를 한 번 통과하는 과정을 하나의 epochEpoch: 전체 데이터셋이 네트워크를 한 번 통과하여 모든 배치
21.Non Maximum Suppression (NMS) + Soft NMS
Soft-NMS의 기본 개념:Soft-NMS는 기존의 'Non-Maximum Suppression (NMS)' 알고리즘을 발전시킨 것입니다.표준 NMS는 겹치는 탐지 중 신뢰도가 높은 탐지를 제외하고 모두 제거합니다. 즉, 여러 탐지 중 가장 확실한 하나만 남기고 나머
22.InfoNCE (Information Noise-Contrastive Estimation)

InfoNCE (Information Noise-Contrastive Estimation) 손실은 대조 학습(contrastive learning)에서 널리 사용되는 손실 함수로, 비지도 학습 방식에서 데이터의 유용한 표현을 학습하기 위해 설계되었습니다. InfoNCE
23.MAE (Masked Auto Encoding) are scalable Vision Learner
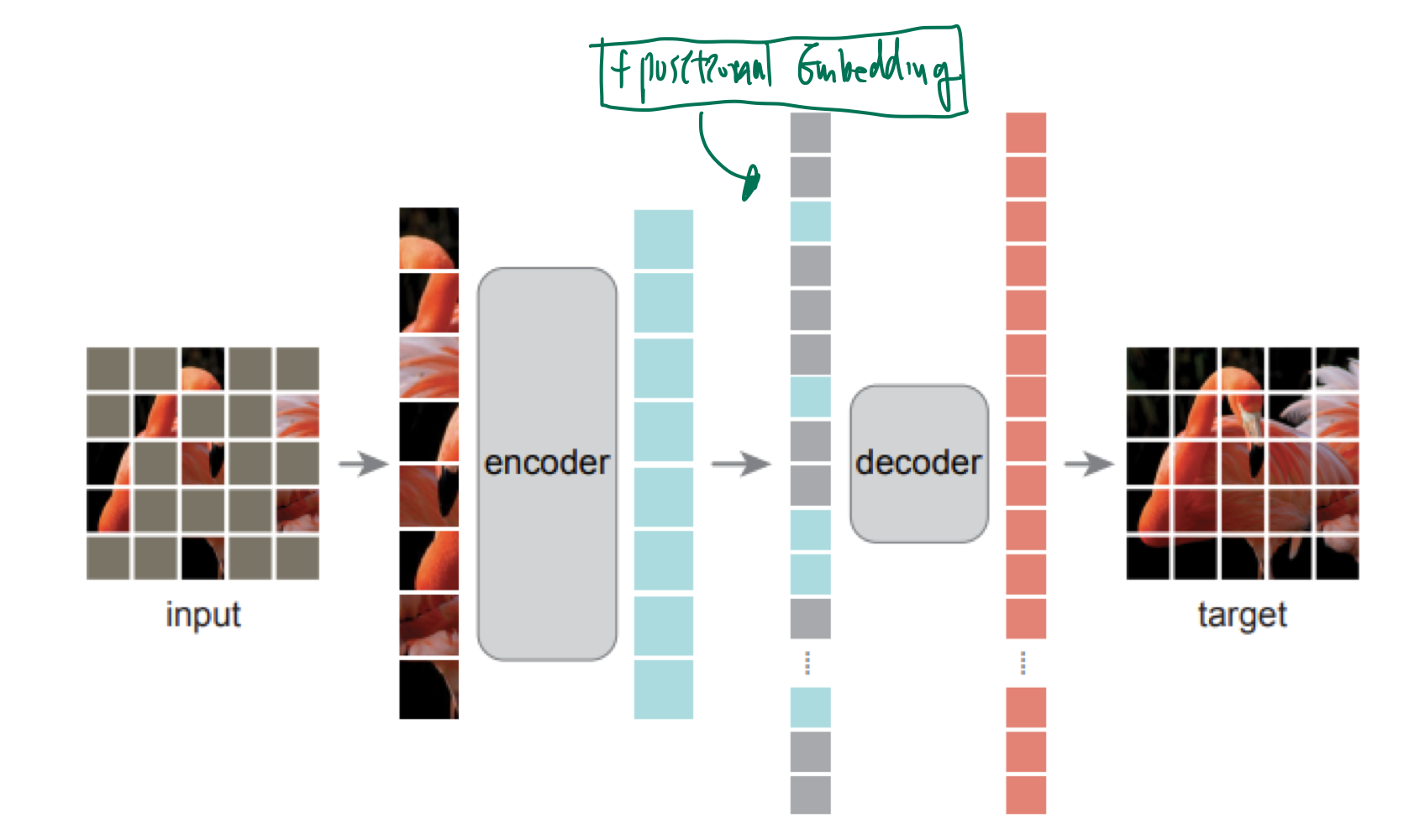
GPT: auto-gressiveauto: 스스로의 이전 상태에 의존한다.regressive: 과거의 데이터를 바탕으로, 미래를 예측한다.BERT: MAE텍스트 1개가 가지는 semantic 의미는 크지만, 픽셀 1개가 가지는 semantic 의미는 작다.그러므로, M
24.linear probing VS fine-tuning
Linear Probing과 Fine Tuning은 둘 다 사전 훈련된 모델을 사용하여, 특정 작업에 적용하기 위한 방법사전 훈련된 모델의 가중치를 고정시키고, 모델의 마지막에 새로운 선형 분류기(보통은 단일 계층의 신경망)를 추가하여 학습하는 방법이 방식은 계산 비용
25.Intermediate fine tuning
이 방식은 일반적인 fine tuning 과정과 유사하지만, 중간 단계에서 특정 작업이나 데이터셋에 대해 모델을 미세 조정 이 과정은 최종 작업에 모델을 적용하기 전에, 모델이 특정 도메인이나 중간 작업에 더 잘 적응할 수 있도록 도움이미지 도메인에서 intermedi
26.FLOPs(Floating Point Operations Per Second)

특정 알고리즘, 모델이 초당 수행할 수 있는 부동 소수점 연산의 수그러나, 컴퓨팅 분야에서 FLOPs는 종종 단순히 '부동 소수점 연산의 총 수'를 의미하기도 함특히, 딥러닝과 같은 컴퓨터 비전 분야에서 FLOPs는 모델이나 알고리즘이 처리하는데 필요한 계산량을 측정하
27.Optical Flow

Optical Flow는 비디오 또는 이미지 시퀀스에서 물체의 움직임을 추적하는 방법구체적으로, Optical Flow는 연속된 두 프레임 사이에서 각 픽셀의 움직임을 벡터 형태로 나타낸 것이 벡터는 픽셀의 이동 방향과 속도를 나타냄Optical Flow를 계산하는 기
28.Generative Pre-training / Language Modeling (LM) Loss / PrefixLM

Generative Pre-training은 자연어 처리(NLP)와 컴퓨터 비전 분야에서 사용핵심 아이디어대규모 unlabeled 데이터를 사용하여 모델을 사전 학습시켜, 이후 특정 작업에 대한 미세 조정(fine-tuning) 과정에서 모델의 성능을 향상시키는 것"G
29.이미지 도메인 task 정리
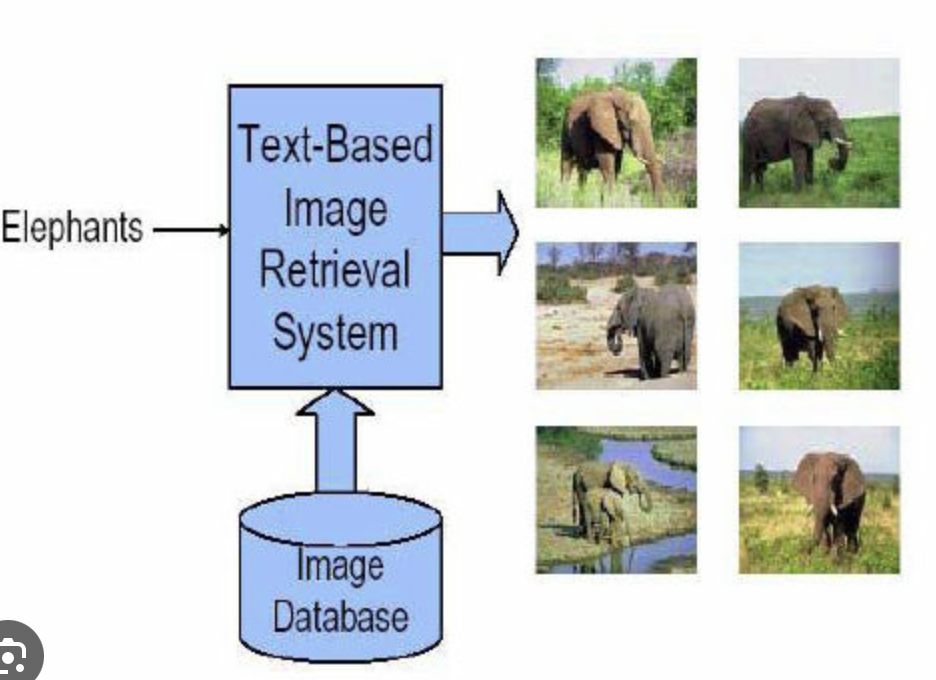
image-text retrieval 텍스트 쿼리를 사용하여 관련 이미지를 검색하거나, 반대로 이미지를 사용하여 관련 텍스트(설명, 태그 등)를 찾는 문제
30.[CoCa] dual encoder for visual Foundation model
CLIP(http://proceedings.mlr.press/v139/radford21a/radford21a.pdf), ALIGN, Florence 논문들해당 모델들은 image encoder와 text encoder가 있고, web에서 수집한 거대 image
31.[CoCa] Encoder-Decoder for visual Foundation model

https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Vinyals_Show_and_Tell_2015_CVPR_paper.pdfhttps://arxiv.org/pdf/2108.10904.
32.[CoCa] 용어 정리
text.ids: batch, sequence_lengthsequence_length는 각 텍스트의 토큰 수(또는 고정된 시퀀스 길이)이는 각 텍스트 토큰(단어)에 대응하는 정수 ID자연어 처리에서는 단어를 모델이 이해할 수 있는 형태로 변환하기 위해 단어를 정수 인덱
33.casual masking transformer
"Causal masking transformer"는 Transformer 아키텍처에서, 시퀀스 생성 태스크에서 모델이 오직 현재 및 이전 위치의 정보만을 참조하도록 제한하는 방법이는 시퀀스를 autoregressive하게, 즉 한 번에 한 요소씩 순차적으로 생성할 때
34.linear probing VS fine-tuning
Linear Probing과 Fine Tuning은 둘 다 사전 훈련된 모델을 사용하여 특정 작업에 적용하기 위한 방법입니다. 그러나 각각의 접근 방식에는 중요한 차이점이 있습니다. Linear Probing Linear Probing은 사전 훈련된 모델의 가중치를
35.GFLOP

GFLOP(Giga Floating-point Operations Per Second)는 수십억(10^9) 개의 부동 소수점 연산을 의미하며, 초당 수행할 수 있는 부동 소수점 연산의 수를 나타냅니다.부동 소수점 연산에는 덧셈, 뺄셈, 곱셈, 나눗셈과 같은 실수 연산이
36.with torch.cuda.amp.autocast()
with torch.cuda.amp.autocast():자동 혼합 정밀도(Automatic Mixed Precision, AMP) 연산을 사용하기 위한 문법torch.cuda.amp: PyTorch에서 자동 혼합 정밀도를 지원하는 모듈입니다.혼합 정밀도는 부동 소수점
37.In-context learning
인컨텍스트 학습은 대형 언어 모델(LLM, Large Language Model)에서 관찰되는 고유한 능력으로, 명시적인 모델 재훈련 없이 주어진 컨텍스트(문맥)만으로 새로운 작업을 수행할 수 있는 방식간단히 말해, 사용자가 제공한 입력 예시(컨텍스트)를 통해 모델이
38.in context learning - 메모리 메커니즘
1. 기초 설명 대형 언어 모델(LLM)에서의 인컨텍스트 학습은 주어진 입력 내의 컨텍스트를 활용하여 새로운 작업을 수행하는 능력 이를 이해하기 위해서는 모델의 내부 작동 원리, 특히 Transformer 아키텍처와 Self-Attention 메커니즘에 대한 이해가 필
39.SigLIP
2023, 3700회 인용https://openaccess.thecvf.com/content/ICCV2023/papers/Zhai_Sigmoid_Loss_for_Language_Image_Pre-Training_ICCV_2023_paper.pdfCLIP: 기
40.rotary positional embedding
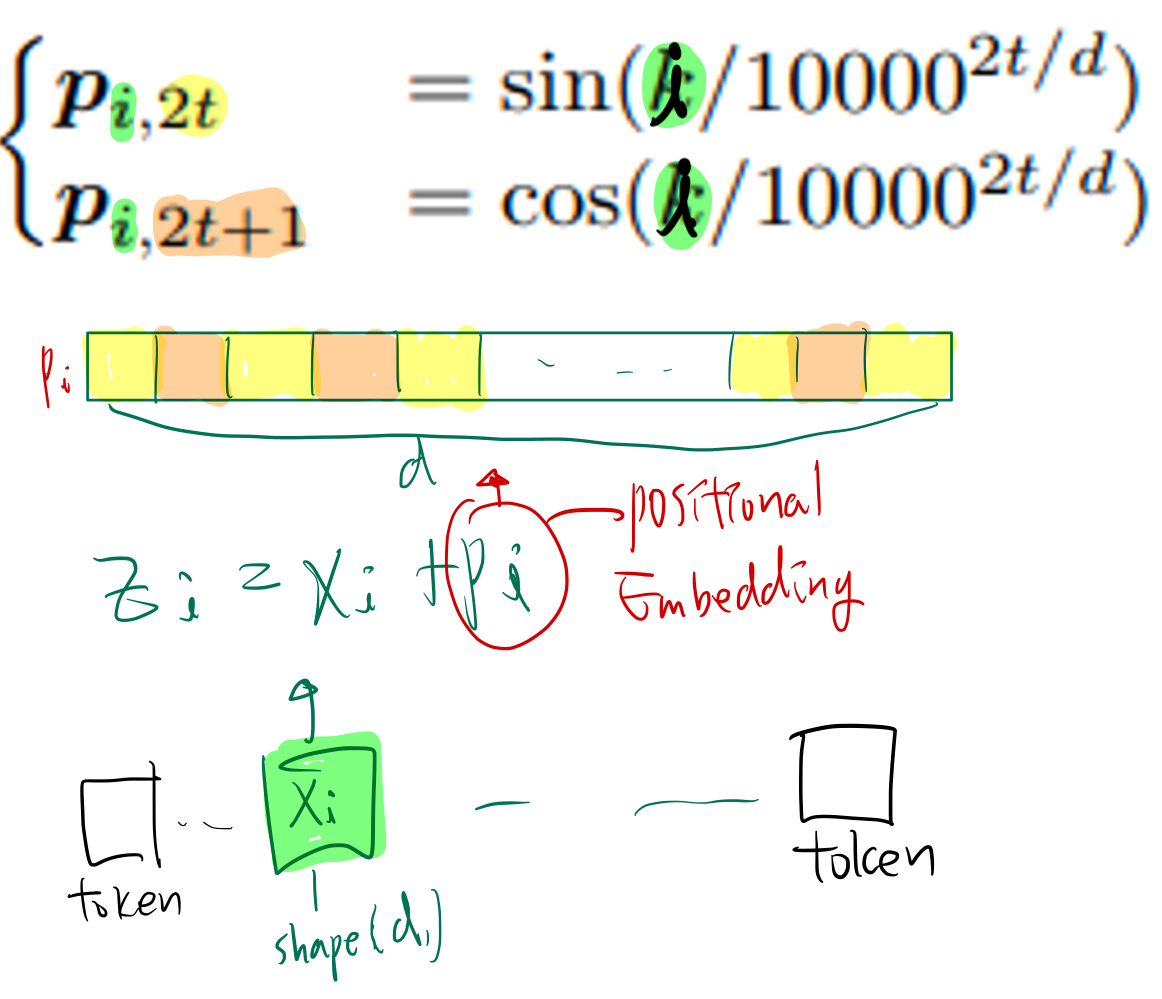
장점: extrapolation 성능이 높음단점: 전반적 성능이 떨어짐문장의 최대길이 ($N{max}$)를 설정하고, ($N{max}, d$) vector을 학습장점: 데이터에 맞춰 최적화가 가능해서 성능이 높음단점: 학습 길이보다 긴 문장에 대해서 성능이 떨어짐 (e
41.Grouped Query Attention
Grouped Query Attention (GQA)는 Transformer 기반 모델에서 self-attention 메커니즘의 효율성을 높이기 위해 고안된 기법KV 캐시 최적화: GQA는 입력 쿼리들을 그룹으로 묶어, 동일한 키(key)와 값(value) 정보를 공
42.Mixture of Experts (MoE)
MOE(Mixture of Experts)는 한 마디로 "전문가들의 조합"을 의미합니다. 여기서 각각의 전문가(Expert)는 작은 신경망 모델로, 특정 유형의 문제나 입력에 대해 특화되어 학습됩니다. 고등학생도 이해할 수 있도록 좀 더 자세히 설명하면:기본 개념:
43.Flash Attention
"attn_implementation" 파라미터는 모델이 어텐션(attention) 연산을 수행할 때 사용할 구체적인 구현 방식을 지정"attn_implementation='flash_attention_2'" 옵션은 최신 GPU 최적화 기법을 적용한 FlashAtten
44.[transformers]AutoModelForCausalLM, AutoProcessor
1. AutoModelForCausualLM 1.1. AutoModelForCausualLM 의 목적? Transformers 라이브러리에서 AutoModelForCausalLM 클래스를 별도로 제공하는 이유는 모델의 사용 목적과 아키텍처에 따라 "적절한 헤드(he