Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
video summarization
목록 보기
3/9
- 2023, 86회 인용
- https://velog.io/@hsbc/QD-DETR-코드-돌리기
- QD-DETR 논문 이해 쉬운 버전: https://velog.io/@hsbc/QD-DETR-쉬운-버전
- https://github.com/wjun0830/QD-DETR
- 206 stars
개념 정리
video moment retrieval(MR)
주어진 video에서, 주어진 text와 관계가 있는 순간을 찾는 것- 1, 12, 13, 30
- text query-video pair간 corss-modal interaction을 모델링한 접근법들
- 32, 54, 56
- video clips간 temporal relation의 문맥을 이해하는 접근법
- 1, 59
- inference spped를 향상시킨 접근법
- FVMR: 14
Video highlight detection(HD)
주어진 video에서, clip-wise importance level을 측정하는 것- 4, 33, 47, 57, 41, 52
- Supervised HD
- 15, 41, 49, 50
- weakly supervised HD
- 5, 36, 49
- unsupervised HD
- 4, 22, 33, 38
- multi-modal (i.e. audio)
- 3, 51
의문점 정리
- 너의 개인 video와 queries로 돌려보고 싶으면,
run_on_video/run.py의run_example함수를 공부해라. - 오디오 파일은 어떤 포멧일까?
- 오디오 파일은 비디오로부터 어떻게 추출할 수 있는가?
prepare feature files
비디오 feature 추출
- 논문을 보니, 비디오로부터,
매 2초 마다feature 추출하여 network input으로 넣어줌. 아래 2개 network를 통과시킨 후 concat했음.- SlowFast [5]: https://velog.io/@hsbc/SlowFast
- video encoder (ViT-B/32) of CLIP [31]: https://velog.io/@hsbc/CLIP-mhj682jc
- github 래포를 보니, https://github.com/linjieli222/HERO_Video_Feature_Extractor 를 통해, features를 추출함.
n초 길이로 영상을 잘라, 각 segment마다 feature을 추출할 수 있도록 만들어놓은 repository.
- 만약 너가 video features를 너 스스로 추출하고 싶으면, raw video(https://nlp.cs.unc.edu/data/jielei/qvh/qvhilights_videos.tar.gz) 를 다운받아서 추출해라!
text feature 추출
- CLIP text encoder 사용.
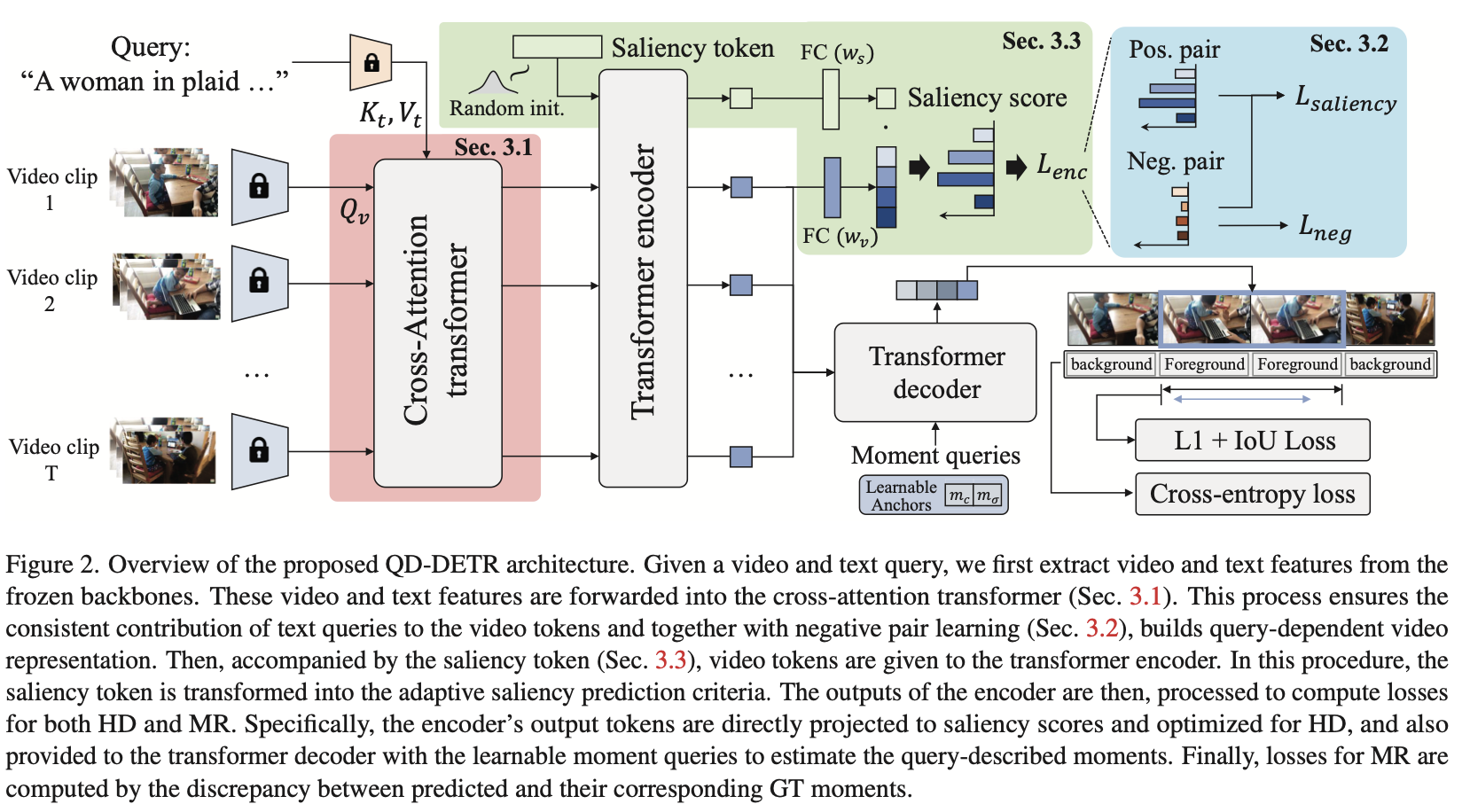
input
- 여러개의 영상 clips
- 영상 1개를
2초 길이의 clip여러개로 잘라서 인풋으로 넣습니다. (L개)- 예: 1분짜리 영상 -> 30개 클립을 인풋으로
- 영상 1개를
- query를 넣습니다.
- 예: A family is playing basketball together on a green court outside. (N개)
Output
center coordinate (m_c)와 width (m_6)찾아내기- saliency score for each clip. {s1, s2, ..., sL}
Abstract
video moment retrieval(MR)과video highlight detection(HD)를 동시에 해결- 주어진 text query에 대해, 중요도 점수를 측정하는게 목표
- 문제정의: 과거 transformer 기반 연구들은, 주어진 text query와 video contents간 상관관계를 적절히 고려하지 않았습니다.
- Query-Dependent DETR(QD-DETR) 개발
- encoding module이 cross-attention으로 시작
- query: video
- key, value: text
negative (irrelevant) video-query pairs를 적용하여,low saliency scores 가 출력되야 하는 곳에선, 출력되도록 학습- 중요도 점수 기준을, 주어진 video-query에 따라 adaptive하게 정의하기 위해,
input-adaptive saliency predictor개념을 도입
- encoding module이 cross-attention으로 시작
Introduction
- Moment-DETF [23] :
- video moment retrieval(MR) 과 , Video highlight detection(HD)을 둘 다 다룰 수 있는 데이터셋인
QVHighlights를 제안함. - DETR 네트워크를 변형하여, text와 video token을 동시에 입력으로 받을 수 있게 함.
- video moment retrieval(MR) 과 , Video highlight detection(HD)을 둘 다 다룰 수 있는 데이터셋인
- UMT [31]
- video와 audio의 멀티모달 입력을 처리하는 transformer architectures를 제안
- text queries는 transformer decoder에서 다룸.
- 위 두 논문의 문제점: text query의 역할을 간과했다.
- 제안 논문
- text query의 역할을 중시하는 구조
- negative video-query pairs를 추가로 이용하였다. (original pair에서 mixing해서 생성했음)
- To apply the dynamic criterion to mark highlights for each instance, we deploy a saliency token to represent the entire video and utilize it as an input-adaptive saliency criterion.
- transformer decoder에서 positional queries의 사용을 가능하게 한다.
Dataset

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것