- https://openaccess.thecvf.com/content/ICCV2021/papers/Arnab_ViViT_A_Video_Vision_Transformer_ICCV_2021_paper.pdf
- https://openaccess.thecvf.com/content/ICCV2021/supplemental/Arnab_ViViT_A_Video_ICCV_2021_supplemental.pdf
- 2021: 2600회 인용
-1. 3줄 요약
- 이 논문은, video input data를 받아, 어떤 class인지를 판별하는 task를 transformer 기반으로 처리하는 논문.
- video dataset (예: kinetics 400) 을 어떤 방식으로 model input으로 넣는지를 배웠고, 어떤 transformer 구조를 써야 계산량과 메모리 소모를 줄일 수 있는지 배웠다.
- self-supverised learning 이나 foundation model 논문은 아니고, 각 dataset task별로 별도로 학습해서 처리하는 논문이었다.
0. Abstract
- video domain은 데이터셋 크기가 작은데, transformer은 데이터셋이 많을수록 잘됨. 이를 극복하기 위해, 우리는 2가지 방법을 제시함
- 학습 시 성능을 높일 수 있는 방법
- 그리고, Pretrained Image model로부터 시작해서 학습하는 방법
1. Input 처리에 대해
data pre-processing
slow-fast 논문
학습 시
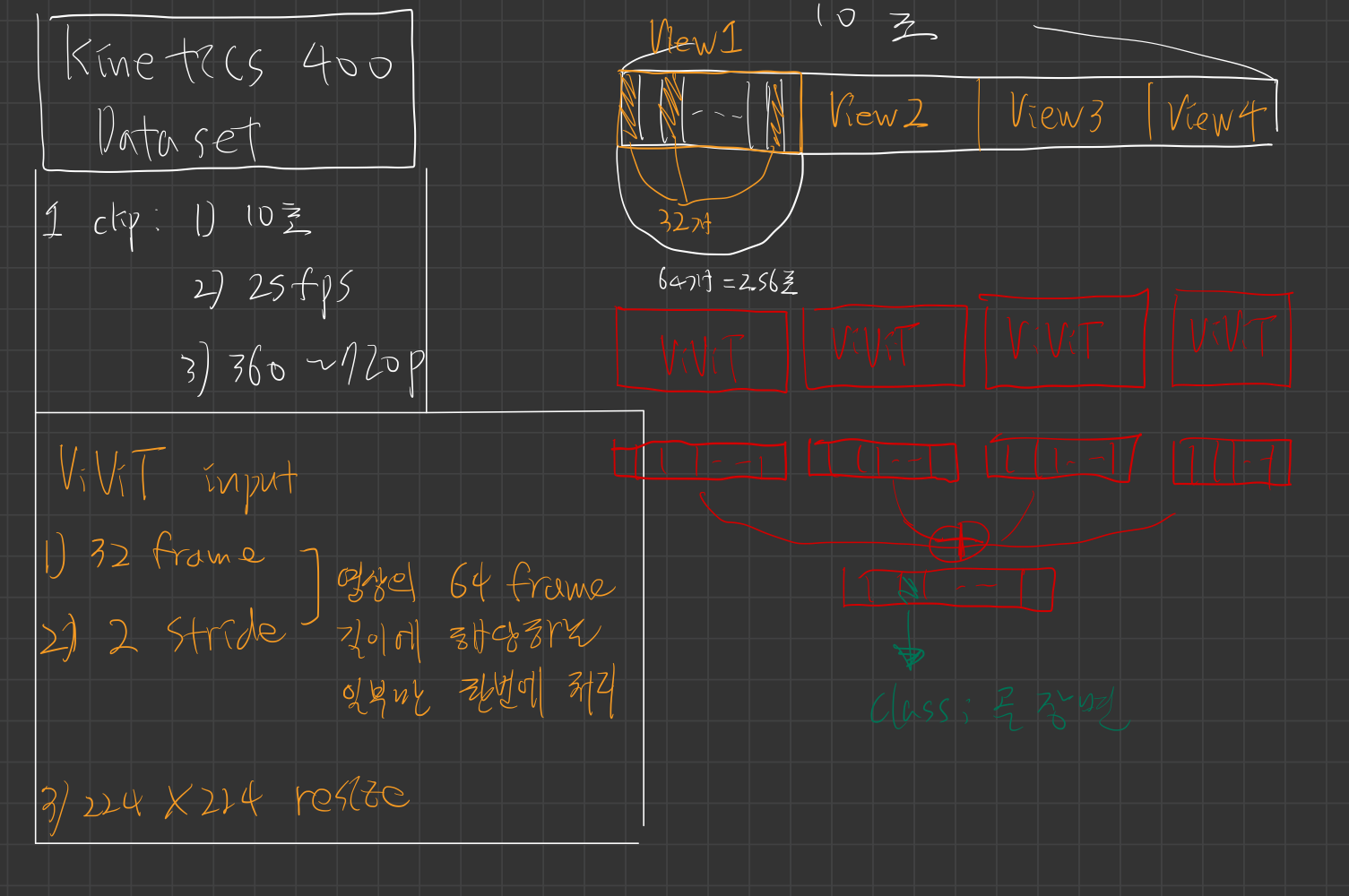
- 10초 길이의 영상에서 (
10*30 = 300 frame) -> 연속적인 64 frame(2.56초) 짜리 view(클립) 1개를 랜덤하게 골라냄 - 프레임의 짧은 쪽(가로 또는 세로)을 256~320 픽셀 사이의 크기로 무작위로 리사이징
720 by 1080->256 by 384or320 by 480
- 리사이징 후, 해당 프레임의 중심 부분 또는
임의의 영역을 224×224 크기로 잘라(crop)input으로 입력
- 리사이징 후, 해당 프레임의 중심 부분 또는
추론 시
- 일반적인 방식에 따라 비디오의 시간 축에서 10개의 클립을 균일하게 샘플링합니다.
- 10초 길이의 영상에서 (
10*30= 300 frame) -> 연속적인 64 frame(2.56초)짜리 view(클립) 4개를 샘플링 한다는 뜻
- 10초 길이의 영상에서 (
- 각 클립에 대해 짧은 공간 측면을 256 픽셀로 스케일링하고 공간 차원을 커버하기 위해 256×256 크기의 3개의 크롭을 사용합니다. (좌, 중앙, 우)
- 우리는 소프트맥스 점수를 평균 내어 예측을 수행합니다.
- 우리의 경우 추론 시
- 공간 크기는 256²이고(학습에서는 224²),
4개의 시간 클립각각에 대해3개의 공간 크롭을 사용하므로 총12개의 뷰가 사용됩니다.
ViViT
학습 시
- 아래 내용은 학습시와 추론 시 같은 내용
- 모델은 10초 클립을 받아, 4번의 ViViT을 통과시킨 뒤(네트워크는 한번에 2.56초를 보도록 학습됨), loss를 계산하여 학습하는 방식
32 frames using a stride of 2를 Input으로 한번에 받음- 위 그림을 보면 이해가 쉬움
- slow-fast 방법과 유사하다고 함
추론 시
- 각 view마다 3개의 spatial crop(left, centre, right) 를 수행 (slow-fast와 같음)
- 그럼 총
4*3=12input을 넣은 후, 각 output을 평균하여 최종 class 구분을 한 것임
- 그럼 총
- 각 클립에 대해 짧은 공간 측면을 224 픽셀로 스케일링하고 공간 차원을 커버하기 위해 224×224 크기의 3개의 크롭을 사용합니다. (좌, 중앙, 우)
pre-processing
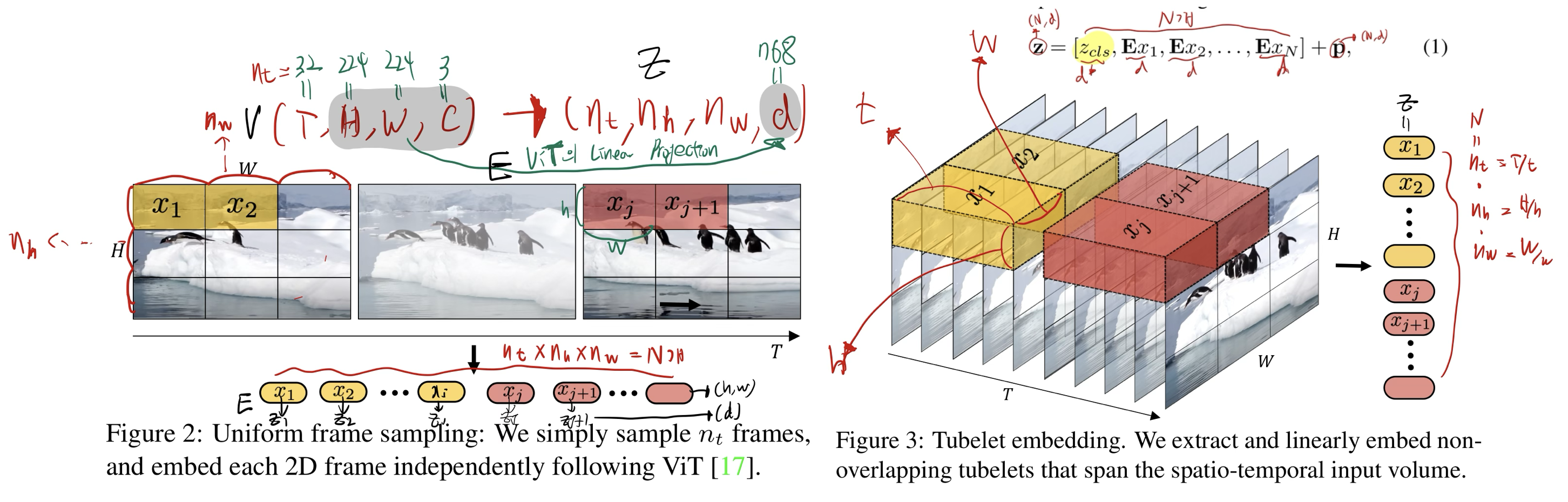
- tublet으로 time을 압축할수록, 성능과 계산량이 동시에 떨어진다고 함
2. Video Vision Transformer
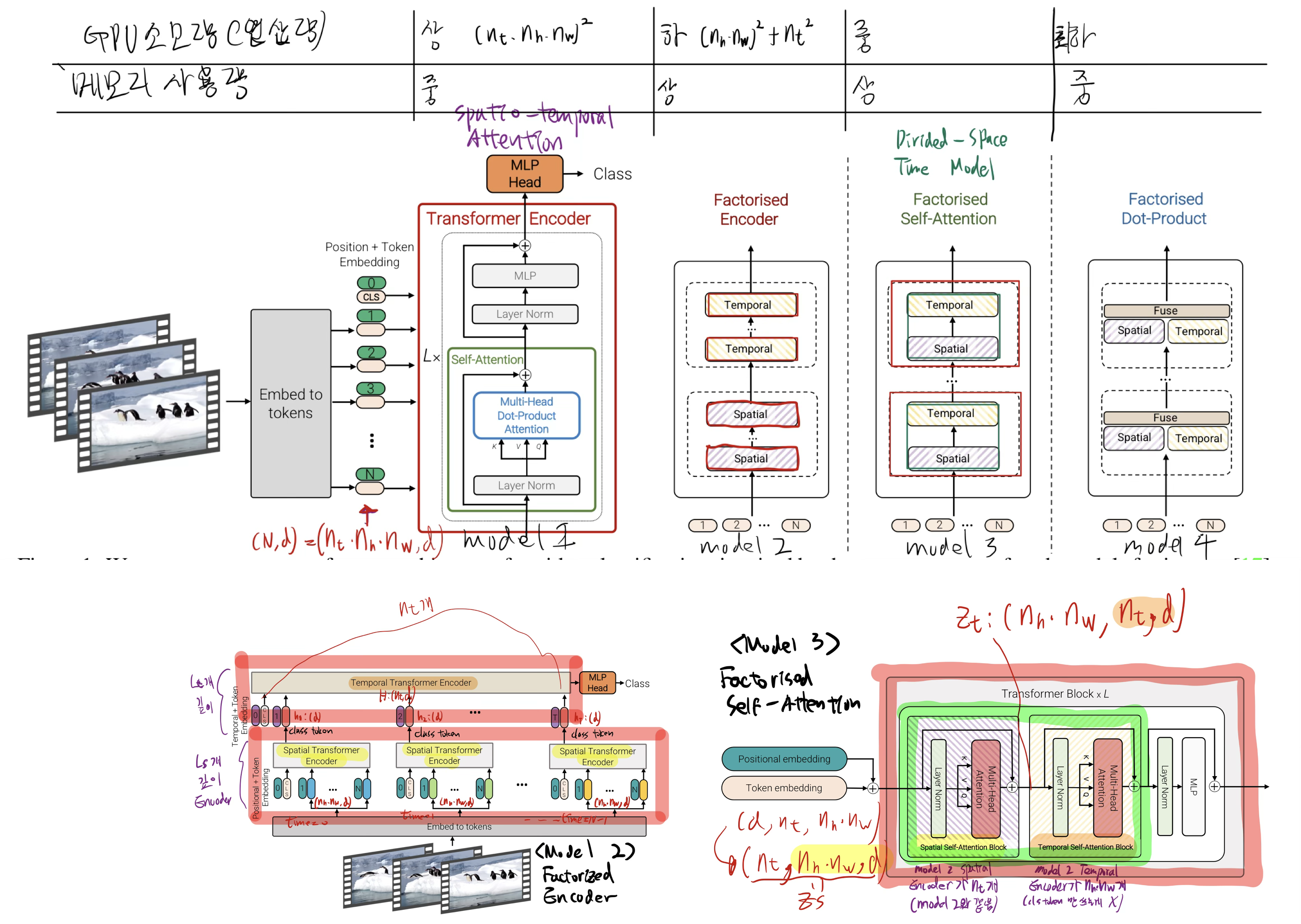
2.1. transformer models for video
model 3
- 공간 -> 시간 을 하던, 시간 -> 공간을 하던 성능은 비슷했다.
model 4
- 완벽히는 이해 못했다.
2.2 Initialization by image pretrained model
Positional Embedding
- 학습된 Positional Embedding을 가져와서 초기화
- 방식: 같은 위치의 patch인데, 시간이 다른 경우 -> 같은 weight로 초기화
Embedding weights, E
- image patch를 embedding 하는 과정을 의미
- tublet embedding의 경우, 아래의 방식으로 처리함.
- (9)
- 위 방식이 성능 젤 좋다고 함
2.3. model regularization
- 트랜스포머 기반 비디오 모델(ViT 계열)은 데이터가 적을 때 과적합이 심하기 때문에, Epic Kitchens나 SSv2 같은 작은 데이터셋에선 추가적인 정규화 기법이 필수적이다.
- Kinetics 등의 대형 데이터셋에선 기본적인 정규화만으로도 충분해, 별도의 추가 정규화 없이도 최신 성능을 달성했다.
- 토큰 수가 늘어날수록(튜블릿을 더 작게 쪼개거나, spatial crop을 키우거나, 더 많은 프레임을 사용) 정확도는 상승하지만, FLOPs도 증가한다.
- Factorised Encoder(모델 2)는 더 많은 토큰을 처리해도 비교적 효율적이라, 큰 해상도나 긴 시퀀스에서도 성능과 연산량 간 균형을 잘 맞춘다.
- Kinetics 같은 경우, 여러 짧은 뷰를 평균하는 것이 관행이며, 128프레임을 단일 뷰로 처리하는 모델은 이미 전체 영상을 모두 커버한다.
- Model 1(비팩터라이즈) 대비 Model 2는 더 적은 FLOPs로도 더 많은 프레임을 처리하며, 결국 정확도를 높이는 데 유리하다.
- 프레임 수를 늘리면 모델이 더 많은 시간 정보를 활용해 정확도가 올라가지만, 정규화 전략과 하드웨어 한계를 고려해 적정 프레임 수와 뷰 개수를 선택한다.

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것