[video] foundation model
1.[22, 12/317] InternVideo: General Video Foundation Models via Generative and Discriminative Learning

0. 들어가기 전에 0.1. 논문 정보 https://arxiv.org/pdf/2212.03191 2022/12, 317회 인용 internvideo 2: https://arxiv.org/pdf/2403.15377 2024, 63회 인용 https://github.com/OpenGVLab/InternVideo 1500 stars 0. 논문 4줄...
2.Awesome video github repo
https://github.com/OpenGVLab/InternVideohttps://github.com/InternLM/InternLM-XComposerhttps://github.com/ShareGPT4Omni/ShareGPT4Videoht
3.[24,3][110] INTERNVIDEO2: SCALING FOUNDATION MODELS FOR MULTIMODAL VIDEO UNDERSTANDING
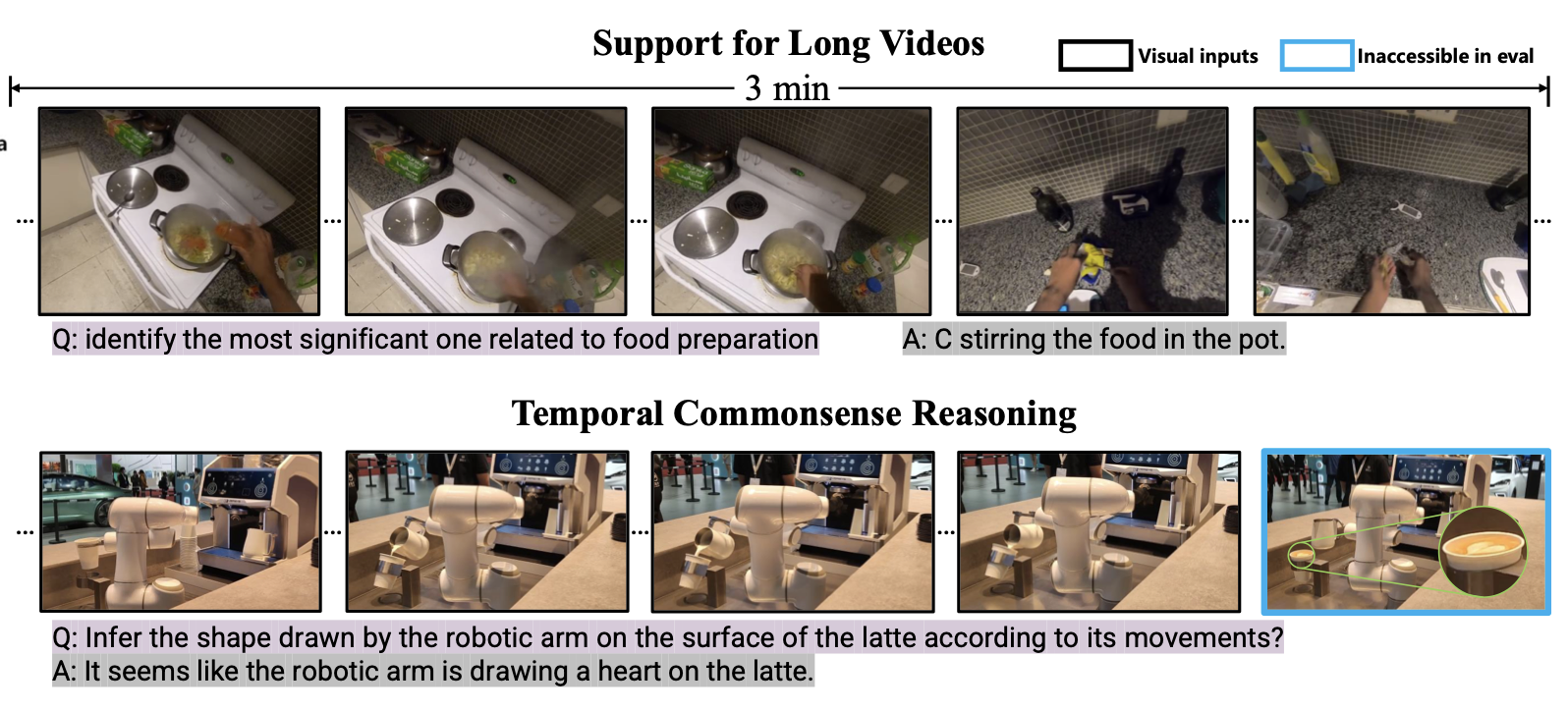
Video Encoder가 비디오의 시공간적 특징을 포착하는 능력을 학습하도록 하는 단계Video Encoder는 마스킹되지 않은(unmasked) 비디오 토큰을 입력받아, Expert Encoder의 출력과 유사한 (여러개의) 토큰을 생성하도록 학습두 개의 Exper
4.[21][2600]ViViT: A Video Vision Transformer
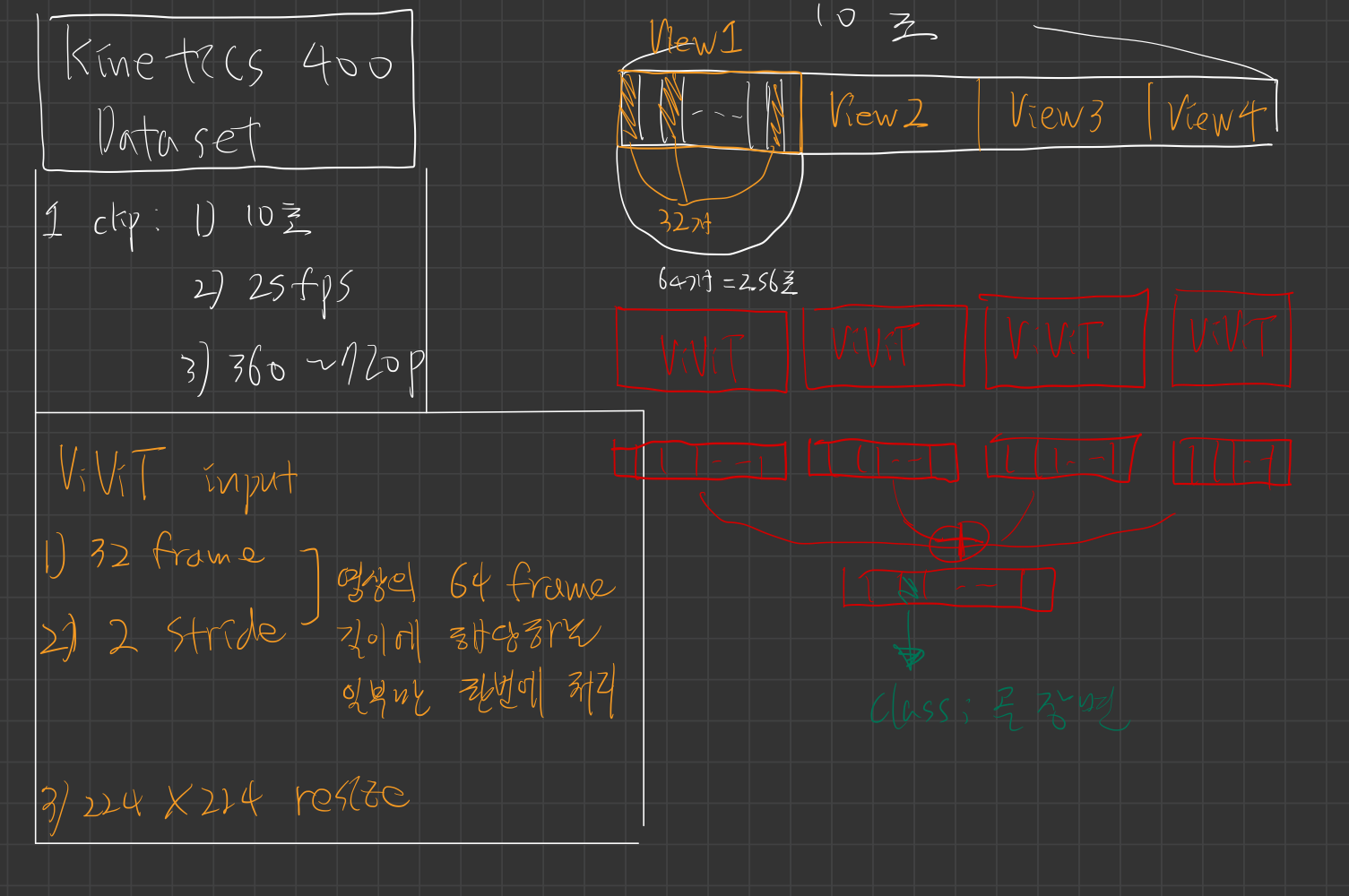
https://openaccess.thecvf.com/content/ICCV2021/papers/Arnab_ViViT_A_Video_Vision_Transformer_ICCV_2021_paper.pdfhttps://openaccess.thecvf.co
5.[25,1] VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
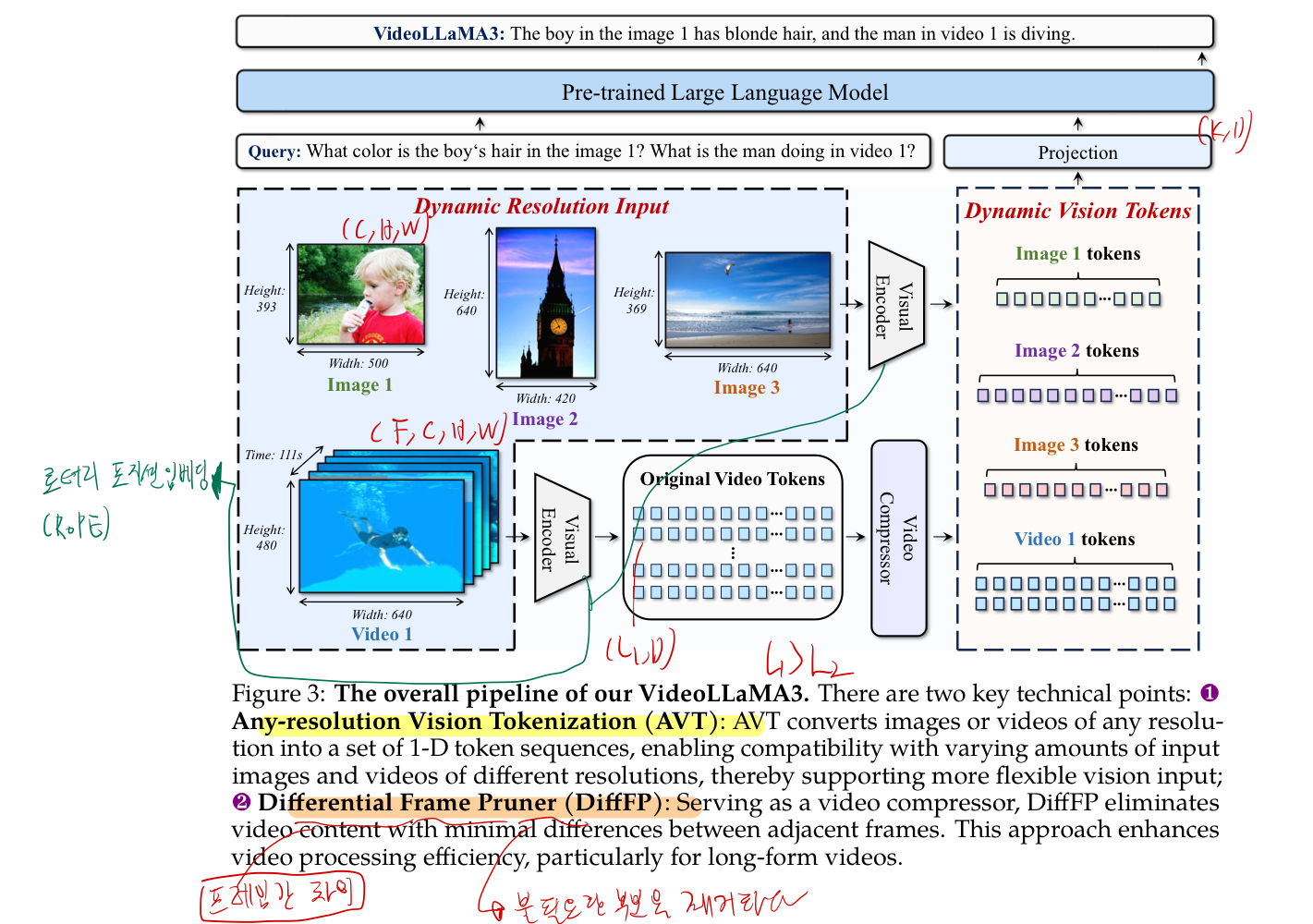
https://arxiv.org/pdf/2501.13106 25, 1 https://github.com/DAMO-NLP-SG/VideoLLaMA3 384 stars 왜 internVL로 captioning? 아래는 두 논문이 re-captioning에 활용될 수
6.Videollama 3 돌려보는 목적과 계획
video LLM 코드로 사용하는 법 배우기video LLM 코드 분석하기video LLM을 축구 골 장면에서 fine-tuning 하는 좋은 방법 없는지 생각해보기video LLM의 pre-trained vision encoder만 가져오기action recognit
7.VideoLLaMA 3 README
https://github.com/DAMO-NLP-SG/VideoLLaMA3requirementsPython >= 3.10Pytorch >= 2.4.0CUDA Version >= 11.8transformers >= 4.46.3inference-onlyTrain
8.[VideoLLaMA 3][processor] load_video
요약하면, load_video 메서드는 ffmpeg 기반의 강력한 비디오 전처리 파이프라인을 구현하여, 사용자가 원하는 구간, 해상도, 프레임 속도에 맞추어 비디오를 로드하고, 모델에 적합한 형태의 프레임 데이터와 타임스탬프를 제공하는 역할을 수행load_video 메
9.[VideoLLaMA 3] action recognition
[3/16] videoencoderexamplewremark.py 의 Videollama3VisionEncoderModel 부터 다시 시작! (Visual Encoder 분석할 차례) 1. 해결해야할 의문점 Video Language Model과 Video encode