0. 두괄식 글 핵심 요약
- 비디오 task는 아래 3가지 범주로 나눌 수 있다.
- Action Understanding Tasks
- Video-Language Alignment Tasks
- Video Open Understanding Tasks
1. Action Understanding Tasks
1.1. !Action Classification/Recognition
- https://paperswithcode.com/task/action-classification
- https://paperswithcode.com/sota/action-classification-on-kinetics-400
설명
- n초(예: 10초) 짜리 영상이 어떤 class인지 맞추는 테스크
- 1 video에 속한 class 맞추기
- 아래와 같은 metric을 사용

- top-1 accuracy를 많이 씀
데이터셋
우리의 활용 방법
- 풋살 영상을 매우 짧게 잘라서(10초), 거기에 있는 클래스들을 전부 추출해내기 (goal/ 슛팅 등)
- clip간 앞뒤를 조금씩 겹치게 10초를 짜르면, 골 장면을 놓치는 것도 없을 듯.
- 골 하이라이트 추출에 매우 접합해보임.
1.2. Action Spotting
설명
특정 action이 일어나는 명확한 시각을 찾는 task- soccer-net 챌린지에서 정의된 task로, 축구 분야 외 범용적 field에서 쓰이는 용어는 아님
1.3. Temporal action localization
설명
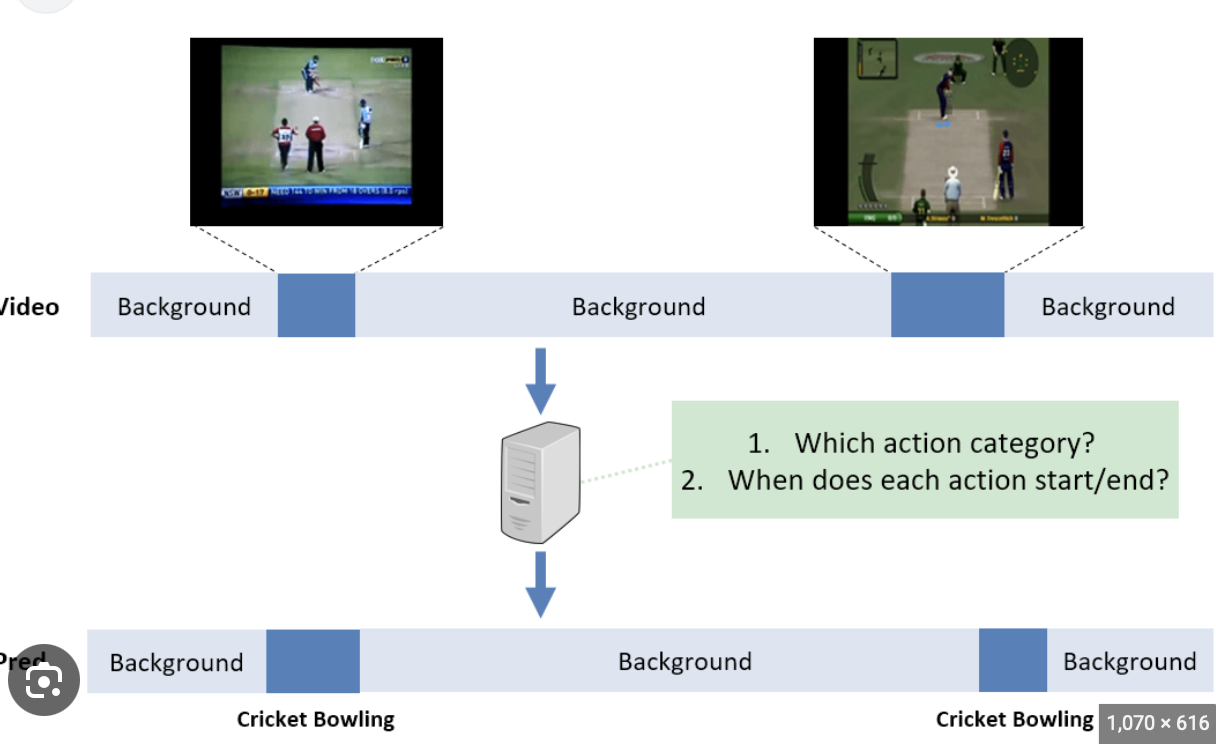
- 전체 video에서,
start and end frame of an action찾는 분야 (특정 class에 대한)
데이터셋
- https://velog.io/@hsbc/Temporal-Action-Localization-데이터셋-모음
- THUMOS-14, ActivityNet-v1.3, HACS segment, FineAction
평가 metric
- mean Average Precision을 쓴다고 함
- 각 action 카테고리에 대해, Average Precision을 계산
- it is computed under different tIOU thresholds.
관련 연구
- ActionFormer
- TCANet
- 관련 논문 모음: https://velog.io/@hsbc/Temporal-Action-Localization
1.3.5. 활용 방법 (애매)
- 어떤 action에 대한
시작~끝 시각을 정확하게 찾고 싶을 떄도움이 됨- 골이나 슛 같이, 명시적인 action 시점이 있는 것을 찾는 데에는 과한 접근법일수도
쿼터 시작~끝이런걸 찾을 때는 도움이 되나?- 시작
선수들이 경기장 밖에서 안으로 확 들어옴- 중앙선에서 공이 시작 (득점 후에도 중앙선으로 갈 수 있는데, 이 case와 어떻게 구분하는가)
- 사람들이 정적인 움직임에서, 동적인 움직임으로 확 바뀜
- 각자의 진영에 5명, 5명 분리되어 있다가, 섞이는 그 전환 과정 어딘가
- 소리가 달라짐 (화이팅! 화이팅!)
- 끝
- 사람들이 전부 경기장 밖으로 나가기 시작함.
- 수고하셨습니다! 와 같은 멘트
- 시작
1.4. Spatiotemporal Action Localization (Action Detection)
1.4.1. 설명
- video 에서, 특정 action이 언제 어디서 일어났는지 찾고, 어떤 action인지 분류
- 특히, 결과가
action tublets로 출력됨- action tublets: action bounding boxes linked across time in the video
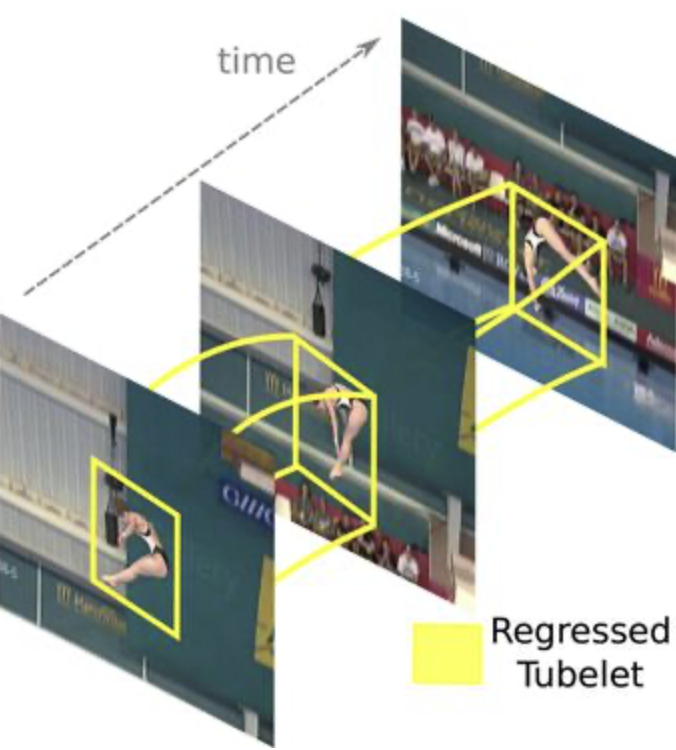
1.4.2. 데이터셋
- AVA 2.2
- 각 비디오는 15분 길이
- 매 초마다 keyframe이 제공되고, keyframes에만 annotation이 있음
- AVA-Kinetics
1.4.3. 활용 방법
- 득점자/어시스트자가 누구인지 파악하는데에 용이한 분야인듯.
2. Video-Language Alignment Tasks
2.1. !Video Retrieval
- 언어로 비디오를 검색하는 것
- 짧은 길이의 여러 비디오 클립을 저장해놓고, "득점 장면" 을 입력하면 비디오가 찾아준다.
2.2. Video Question Answering
- 비디오에 대한 문답
활용 방법
- 누가 득점했고, 누가 도움했는지 찾아줘
2.3. Moment Retrieval
- https://paperswithcode.com/task/moment-retrieval
- 설명
영상 내에서 특정 텍스트 쿼리에 해당하는 순간을 찾아내는 작업- 예:
- "축구 영상" + text: "goal이 들어간 장면"
- 결과: 3분 3초 ~3분 10초 / 24분 5초 ~ 24분 12초
2.4. Highlight Detection
각 비디오 클립이 주어진 쿼리에 얼마나 부합하는지를 점수로 나타내는 작업- 주어진 비디오의 각 클립의 중요도 수준을 측정하는 작업
- 예
- "축구 영상" + text: "goal이 들어간 장면"
- 결과: clip 1 -> 1점 , clip 2 -> 0.8점, ... , clip N -> 0.1점
- 여기서 clip은 전체 비디오를 n초 단위로 자른 개념을 의미한다.
예시
- 비디오 클립들:
- 클립 A: 사람들이 밤하늘을 바라보는 장면 (살리에인시 점수 높음)
- 클립 B: 낮에 사람들이 공원을 걷는 장면 (살리에인시 점수 낮음)
- 클립 C: 불꽃놀이가 하늘에서 터지는 장면 (살리에인시 점수 매우 높음)
3. Video Open Understanding Tasks
3.1. !Zero-shot Action Recognition
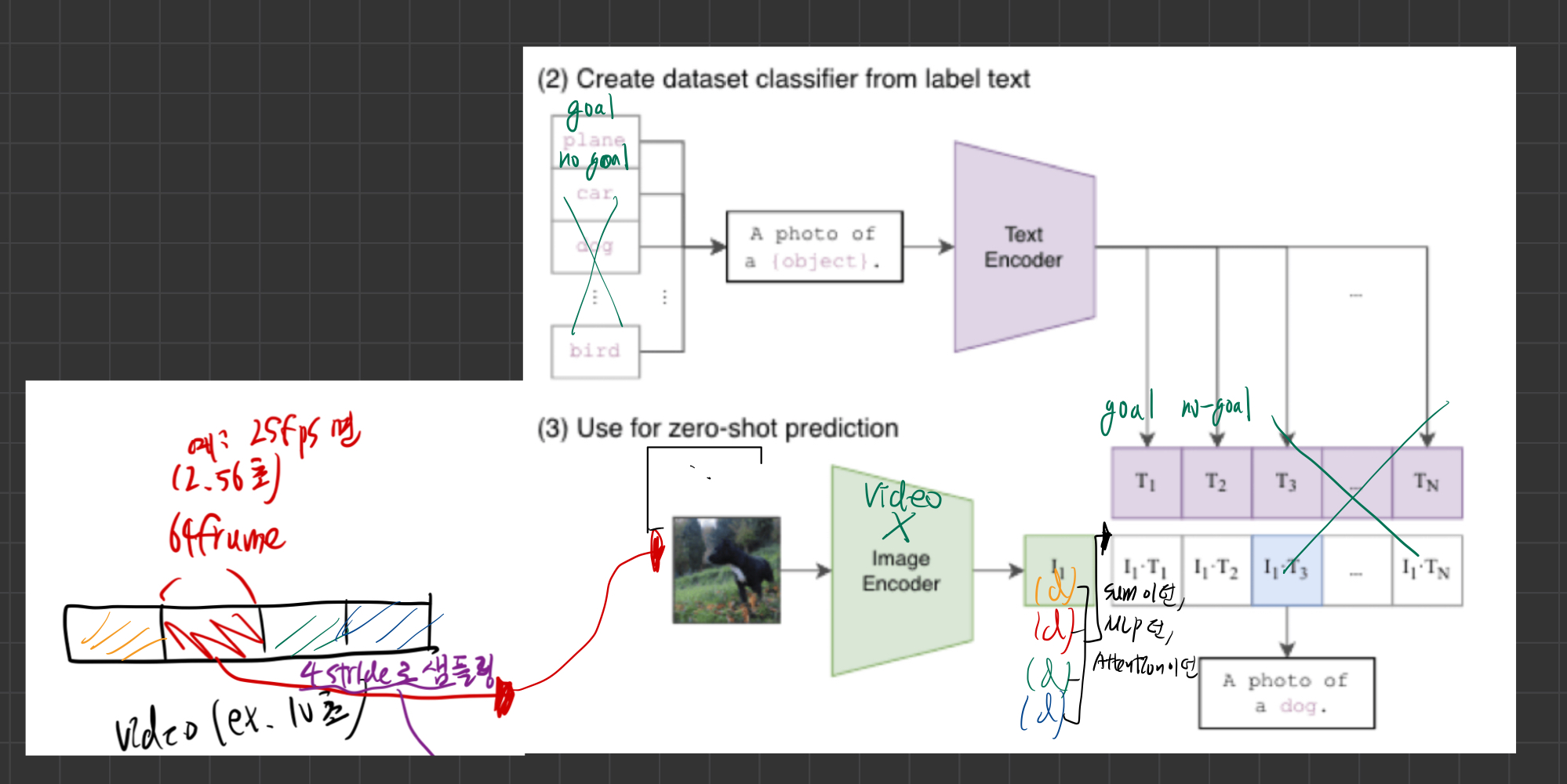
테스크 정의
- 주어진 비디오 클립에서 사전에 학습하지 않은 행동 클래스(action class)를 인식하는 작업
- 행동 클래스는 자연어 설명으로 제공되며, 모델은 비디오와 텍스트 설명 간의 유사도를 기반으로 행동을 분류
- VideoCLIP 같은 거임
Input / Output
-
Input:
- 비디오 클립: 행동이 담긴 비디오.
- 텍스트 기반 행동 클래스 설명: 모델이 학습하지 않은 행동 클래스의 자연어 설명.
예: ["a person riding a horse", "a person playing basketball"].
-
Output:
- 각 행동 클래스(텍스트)에 대해 비디오와 매칭될 확률/유사도를 출력.
- 최종적으로 가장 높은 확률을 가진 행동 클래스가 선택됨.
- 예: [horse riding: 0.85, basketball: 0.15].
3.2. Open-set Action Recogntion
3.2.1. 정의
- Open-set Action Recognition은 모델이 사전에 학습한 행동 클래스(known actions)와 학습하지 않은 행동 클래스(unknown actions)를 구분하는 작업
- 학습하지 않은 행동(unknown)은 분류하지 않고 "알 수 없는 행동(unknown)"으로 처리하는 것이 목표
- 이 작업에서는 불확실성 추정(uncertainty estimation) 기술을 활용하여 학습된 클래스와 학습되지 않은 클래스를 구별합니다.
3.2.2. Input
- 비디오 클립: 예를 들어, "한 사람이 말을 타고 있는 비디오" 또는 "한 사람이 매우 독특한 춤을 추는 비디오".
- 훈련된 행동 클래스 레이블:
- 예: "walking", "jumping", "riding a bike" 등.
3.2.3. Output
- 알려진 행동 클래스라면 해당 클래스에 대한 예측.
- 예: "riding a bike".
- 알 수 없는 행동(unknown)일 경우 "unknown"으로 처리.
3.3. !Zero-shot Video Retrieval
3.3.1. 테스크 정의
- 텍스트나 비디오를 쿼리로 사용하여, 후보군(candidate)에서 그에 해당하는 비디오나 텍스트를 검색하는 작업
- 이 작업은 텍스트-비디오 간 매칭 능력을 평가하는 데 중점을 둠
- Zero-shot Action Recognition 이랑 거의 유사해보임
3.3.2. Input / Output
-
Input:
- 쿼리(Query):
- 텍스트 쿼리: 비디오를 찾기 위한 자연어 설명.
- 예: "A person is playing basketball."
- 비디오 쿼리: 텍스트를 찾기 위한 비디오 클립.
- 텍스트 쿼리: 비디오를 찾기 위한 자연어 설명.
- 후보군(Candidates):
- 검색해야 하는 비디오 또는 텍스트의 집합.
- 예: 여러 비디오 클립 또는 텍스트 설명 후보군.
- 검색해야 하는 비디오 또는 텍스트의 집합.
- 쿼리(Query):
-
Output:
- 후보군에서 쿼리와 가장 잘 매칭되는 비디오 또는 텍스트.
- 예:
- 텍스트 쿼리 "A person is playing basketball." → 비디오 클립 "농구 경기 장면".
- 비디오 쿼리 "농구 경기 장면" → 텍스트 "A person is playing basketball."

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것