0. 들어가기 전에
- TODO: 블로그 글도 추가로 공부해보기?
- https://arxiv.org/pdf/2304.08485
- https://github.com/haotian-liu/LLaVA
- 20000 star
0.0. reference
0.1. Instruction Tuning?
0.2. 심화: llava-1.5
0. 논문 7줄 요약
- visual instruction tuning: 이미지(또는 비디오)와 언어 정보를 동시에 처리하는 대규모 멀티모달 모델에, ‘사용자의 지시(Instruction)’를 이해하고 수행하도록 학습을 추가로 시키는 단계
LLM(GPT-4)를 사용하여,멀티모달 언어-이미지 instruction-following 데이터를 생성하는 방법을 제시함. 데이터 종류는 3가지- Conversation 형태 데이터 (이미지 내 시각적 요소 자체에 대한 질문 답변)
- Detailed Description 형태 데이터 (이미지에 대한 상세한 설명을 원하는 질문 및 답변)
- Complex Reasoning 형태 데이터 (심층적인 추론을 하는 질문 및 답변)
- 학습 단계는 총 2단계
- 기본적
이미지-text pair dataset으로 linear projection layer(W) 만 학습 - 논문에서 생성한
instruction-following dataset으로 linear projection layer(W)와 LLM model fine tuning
- 기본적
1. 본문
- visual instruction tuning
- 이미지(또는 비디오)와 언어 정보를 동시에 처리하는 대규모 멀티모달 모델(예: Flamingo, BLIP 계열 등)에, ‘사용자의 지시(Instruction)’를 이해하고 수행하도록 학습을 추가로 시키는 단계
- 예: “이 이미지를 보고 어떤 상황인지 설명해줘.”, “이 사진 속 개체를 찾아서 레이블링해줘.” 등의 자연어 지시를 모델이 수행하도록 고안된 데이터(Instruction-Finetuning Dataset)로 모델을 재학습.
- 논문에서는
LLM(GPT-4)를 사용하여,멀티모달 언어-이미지 instruction-following 데이터를 생성하려는 첫 시도를 제시- 그리고 이렇게 생성한 데이터셋을 기반으로 model을 fine-tuning 시켜서 성능이 좋아짐을 확인함
- 이 모델은
시각 인코더(CLIP)와언어 모델(Vicuna 언어 디코더)을 가져다 쓰고, 거기에- 시각적 특징과 언어 임베딩을 정렬하는 투영 행렬(W) 사용. (linear layer)
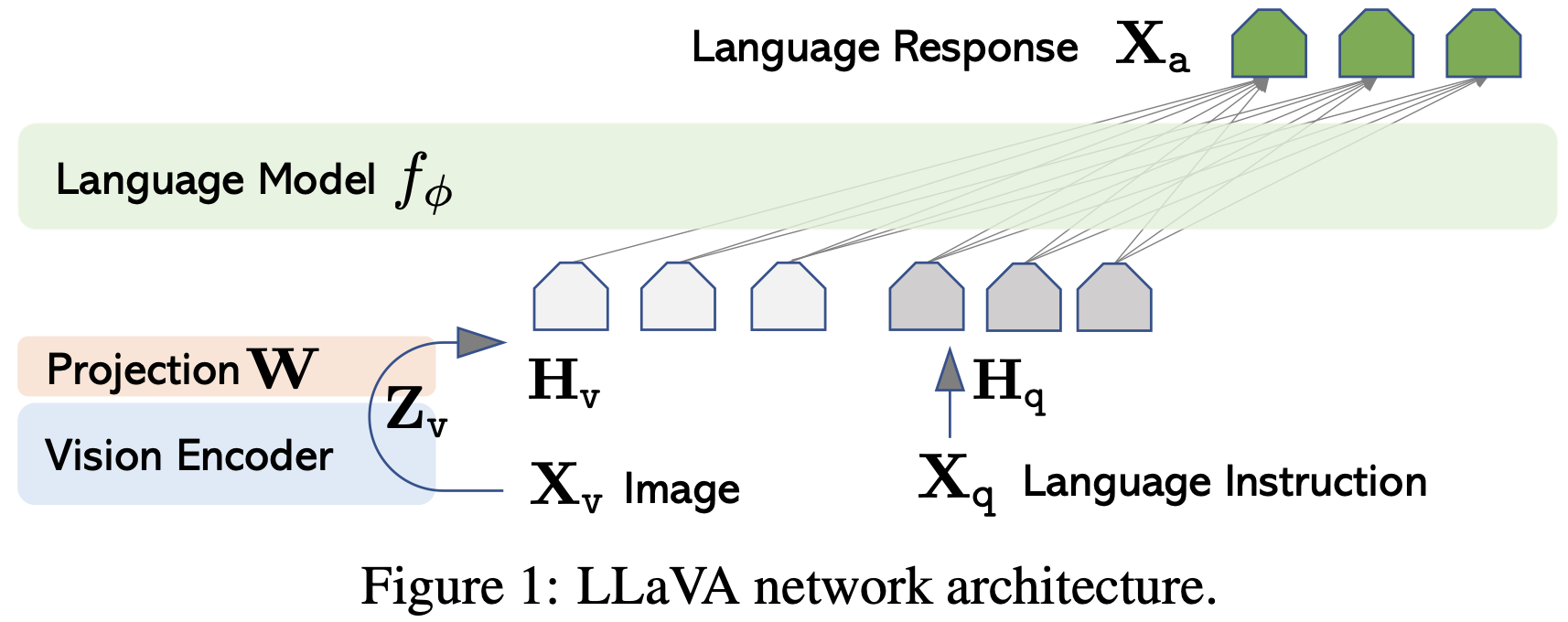
1.0. Visual Instruction Tuning의 효과
- Visual Instruction Tuning 데이터 기반 학습은 VLM이
- 다양한 지시에 대한 직관적이고 상황에 맞는 응답 가능해짐
- 도메인 전이 능력과 커뮤니케이션 능력 향상
- 장점:
1)사용자 의도 정렬(Alignment) 강화
2)범용 멀티모달 태스크 확장
3)일반화 능력(Generalization) 향상
4)Curriculum Learning 효과
5)Zero/Few-shot 성능 우수 및 파인튜닝 비용 절감
1.1. instruction-following dataset 만들기
1.1.0. 간단한 방법: image captioning dataset 그대로 활용하기
이미지(Xv)-caption_text(Xc) pair(image captioning dataset)을 이용해서,instruction following dataset생성- instruction following dataset
- input:
이미지(Xv)+Text prompt for question (Xq) - ouput:
caption_text(Xc)
- input:
- instruction following dataset

Text prompt for question (Xq):- 위 그림의 왼쪽 질문들은, 연구자들이 임의로 생성한 text들로, 랜덤하게 1개 샘플된다.
- 이 데이터셋을 통해 통해 W를 pre-training 시킵니다.(첫번째 학습 단계)
이미지 token을text token과 align 시키기 위해
구체적 학습 방법

한계점과 고퀄리티 데이터 셋의 필요성
- 고퀄리티(
conversation/detailed description/complex reasoning등을 전부 포함한)의 데이터가 추가로 필요!language only GPT로 데이터를 만들어보자!- but, language only GPT는 사진을 input으로 넣을 수 없는데...?

1.1.1. language-only GPT4를 이용하여 고퀄리티 instruction-following dataset을 생성
한계점 1 (이미지 인식 못하는 GPT4)에 대한 해결책
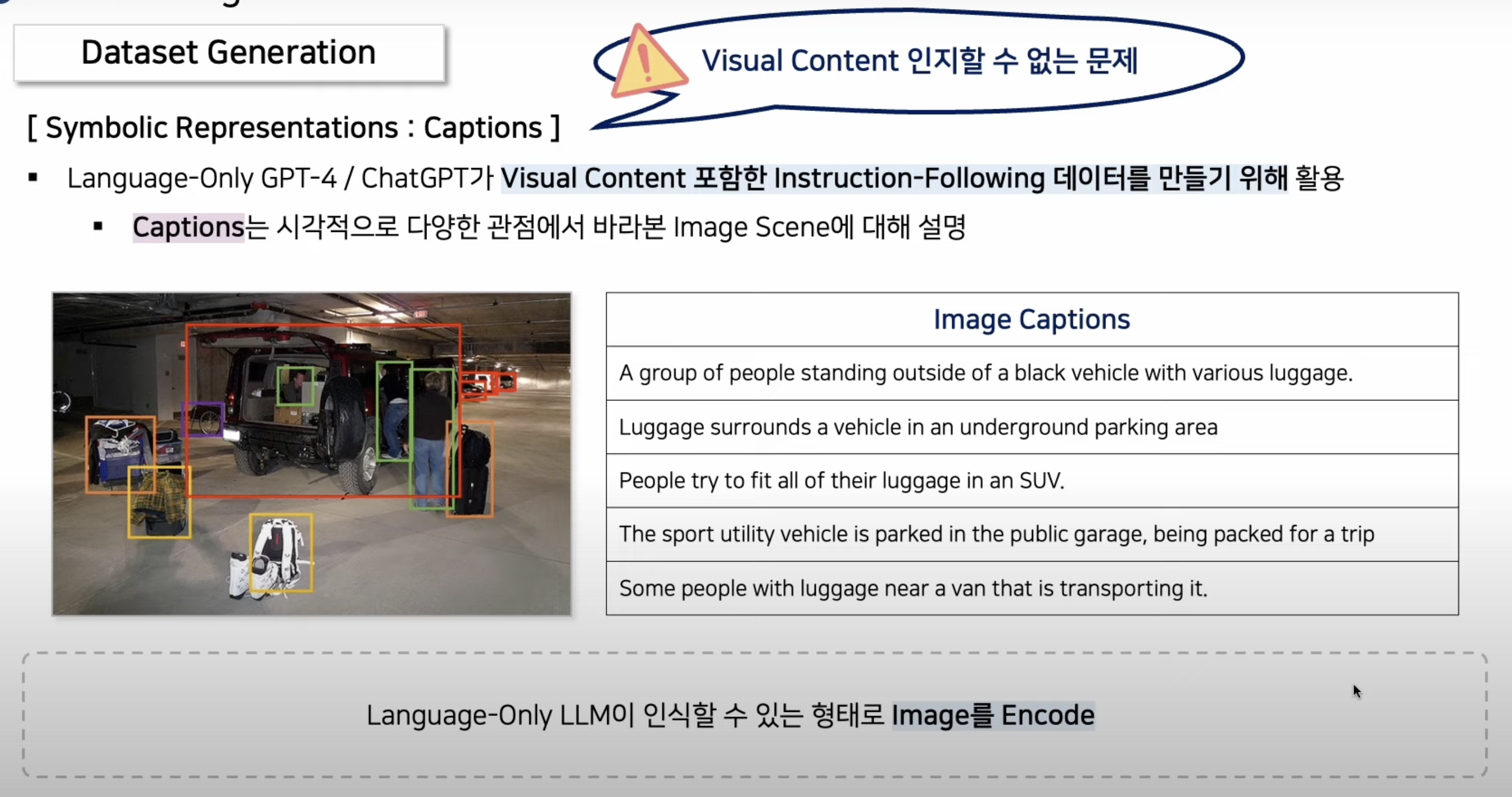
이미지에 대한 여러 캡션이 있는 데이터셋을 활용하여 -> Language-only GPT4가 데이터를 생성하도록 해보자.- language only GPT 는 이미지를 인식하지 못하므로,
이미지를 text형태의 설명으로 대체하여 넣어줍니다.- (기존 captioning datasets의 GT output인)
image에 대한 여러 captions를 사진의 설명으로 GPT에 넣어줍니다.
- (기존 captioning datasets의 GT output인)
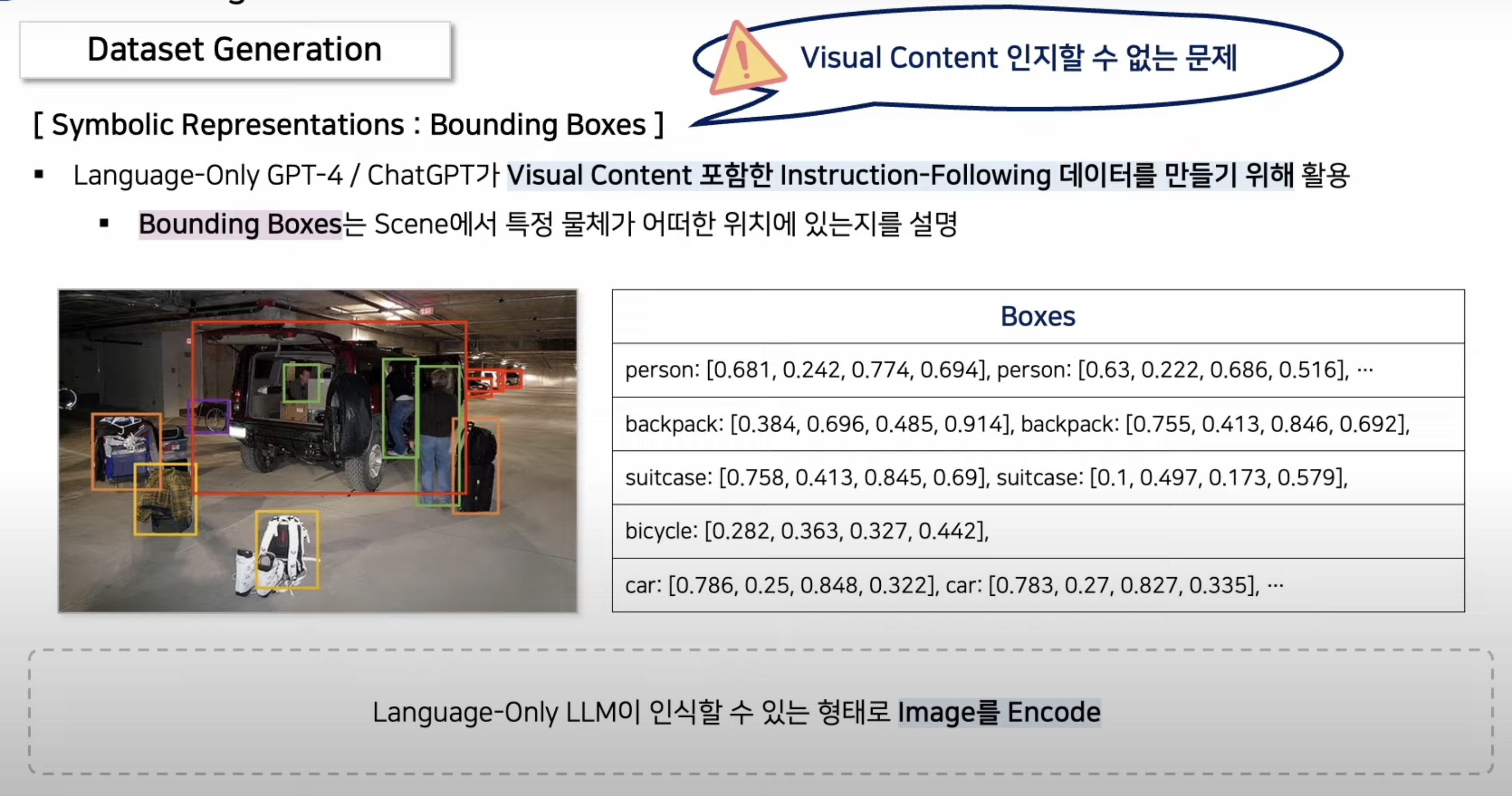
- 뿐만 아니라, 이미지를 prompt에 넣을 수 없는 문제를 추가적으로 해결하기 위해,
- 여러 class와 bounding box에 대한 정보도, 아래와 같이 text로 넣어줍니다.
한계점 2 (instruction following dataset의 복잡성 부족)에 대한 해결책
1. Conversation 형태 데이터 생성

- Input의 왼쪽 아래 글이, (이미지 내의 시각적 요소 자체에 대한) 대화 형태의 dataset을 만들기 위한, 특수한 input text.
Ask diverse questions and give corresponding answers.가 포인트!
- Language-only GPT4가 답변한 오른쪽 ouput의
Question-Answer pair가, 우리가 모은 데이터셋이다!- VLM Fine-tuning 할 때, input: 사진 + Question(사진 오른쪽 output)
- VLM Fine-tuning 할 때, gt output: Answer (사진 오른쪽 output)
2. Detailed Description 형태 데이터 생성

- 왼쪽 Input의 많은 질문들 중 하나를, 매번 Random sample하여 input으로 넣어줌
- 우리가 생성한 데이터셋
- VLM Fine-tuning 할 때(두번째 학습 단계), input: 사진 + Question(사진 왼쪽 하단)
- VLM Fine-tuning 할 때, gt output: Answer (사진 오른쪽 output)
3. Complex Reasoning 형태 데이터 생성

- Language-only GPT4가 답변한 오른쪽 ouput의
Question-Answer pair가, 우리가 모은 데이터셋!- VLM Fine-tuning 할 때, input: 사진 + Question(사진 오른쪽 output)
- VLM Fine-tuning 할 때, gt output: Answer (사진 오른쪽 output)
1,2,3에 대한 예시
- 1.1.2. Table 1
- 아래의 예시는, GPT를 프롬프트하는 데 사용되는
캡션 및 박스와 같은 상황을 보여주며, 세 가지 유형의 응답을 제시 - 시각적 이미지는 GPT를 프롬프트하는 데 사용되지 않지만, 독자의 이해를 위해 참조용으로 제공됩니다.

- 아래의 예시는, GPT를 프롬프트하는 데 사용되는
2. Architecture
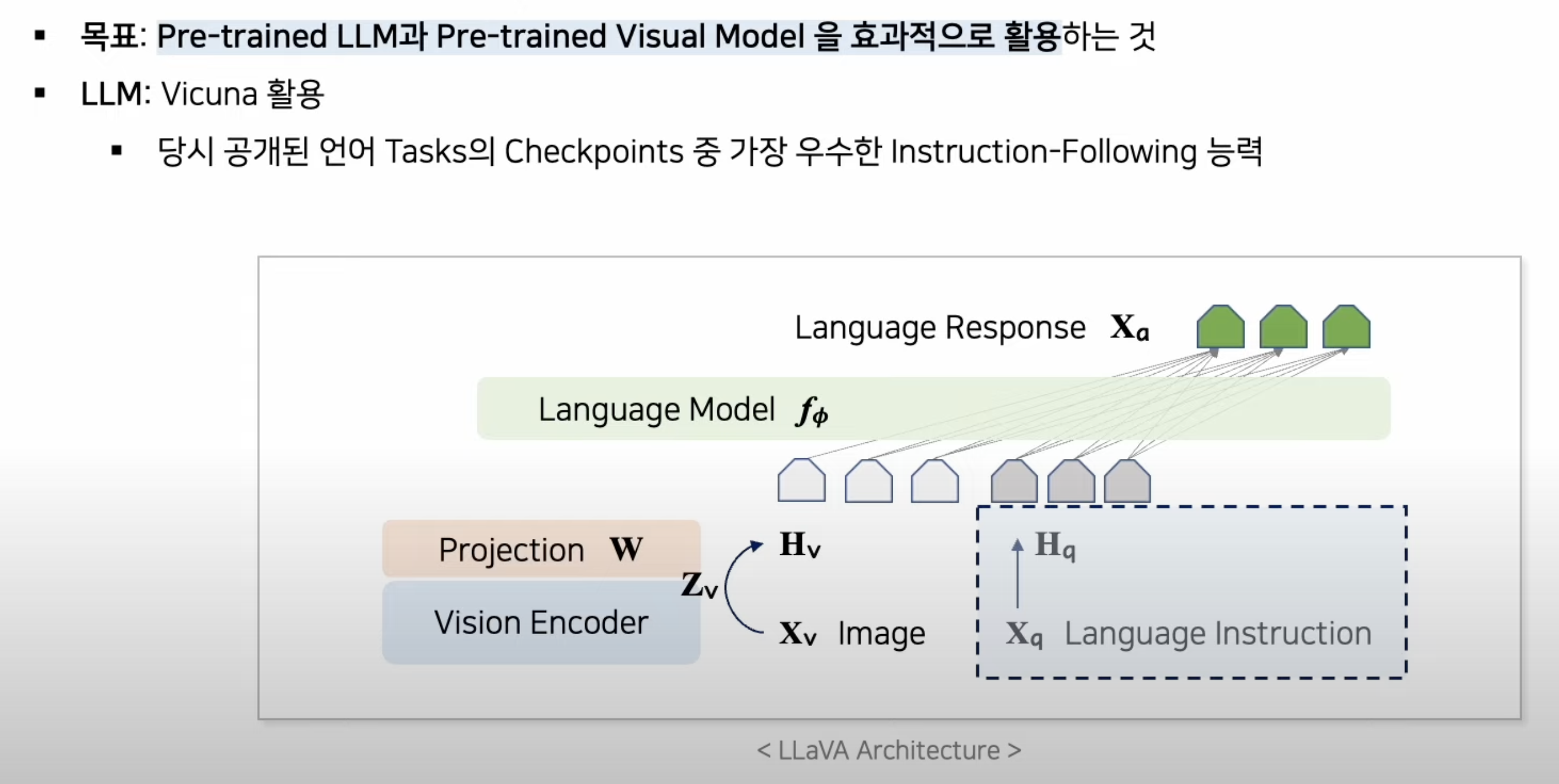
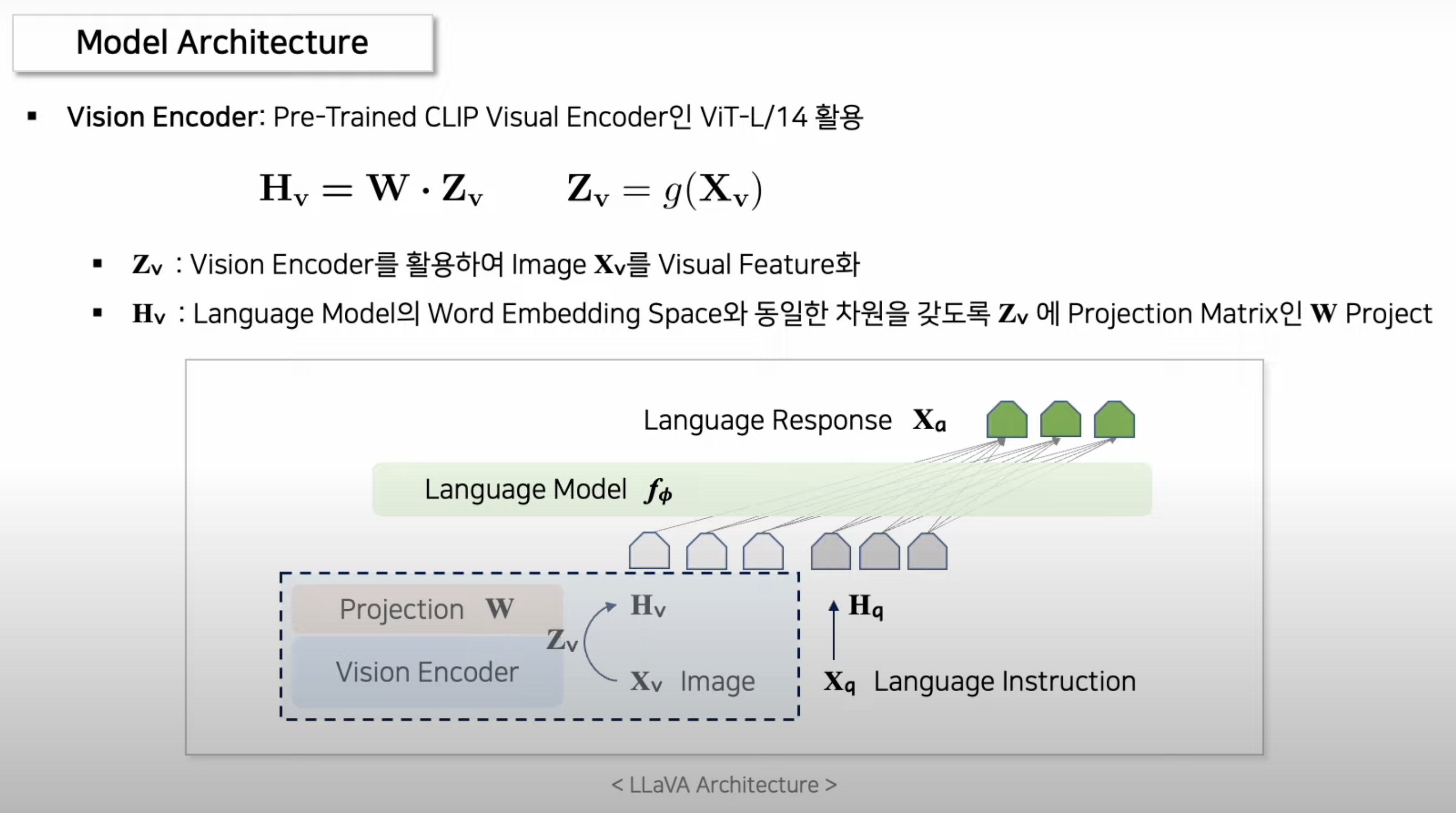
3. Training
3.1. 학습 데이터 format에 대한 설명

- 표 2: 모델 학습에 사용된 입력 시퀀스.
여기서는 두 개의 대화 턴만 예시로 들었지만, 실제로는 지침 준수 데이터에 따라 턴의 개수가 달라집니다. 현재 구현에서는 Vicuna-vO [9]를 따라 시스템 메시지(system-message)를 설정하고, «STOP>은 ###로 설정합니다.
모델은 assistant의 답변과 종료 위치를 예측하도록 학습되며, 따라서 초록색으로 표시된 시퀀스/토큰만 오토리그레시브(auto-regressive) 모델에서 손실(loss)을 계산하는 데 사용됩니다. 

3.2. 구체적 학습 방법
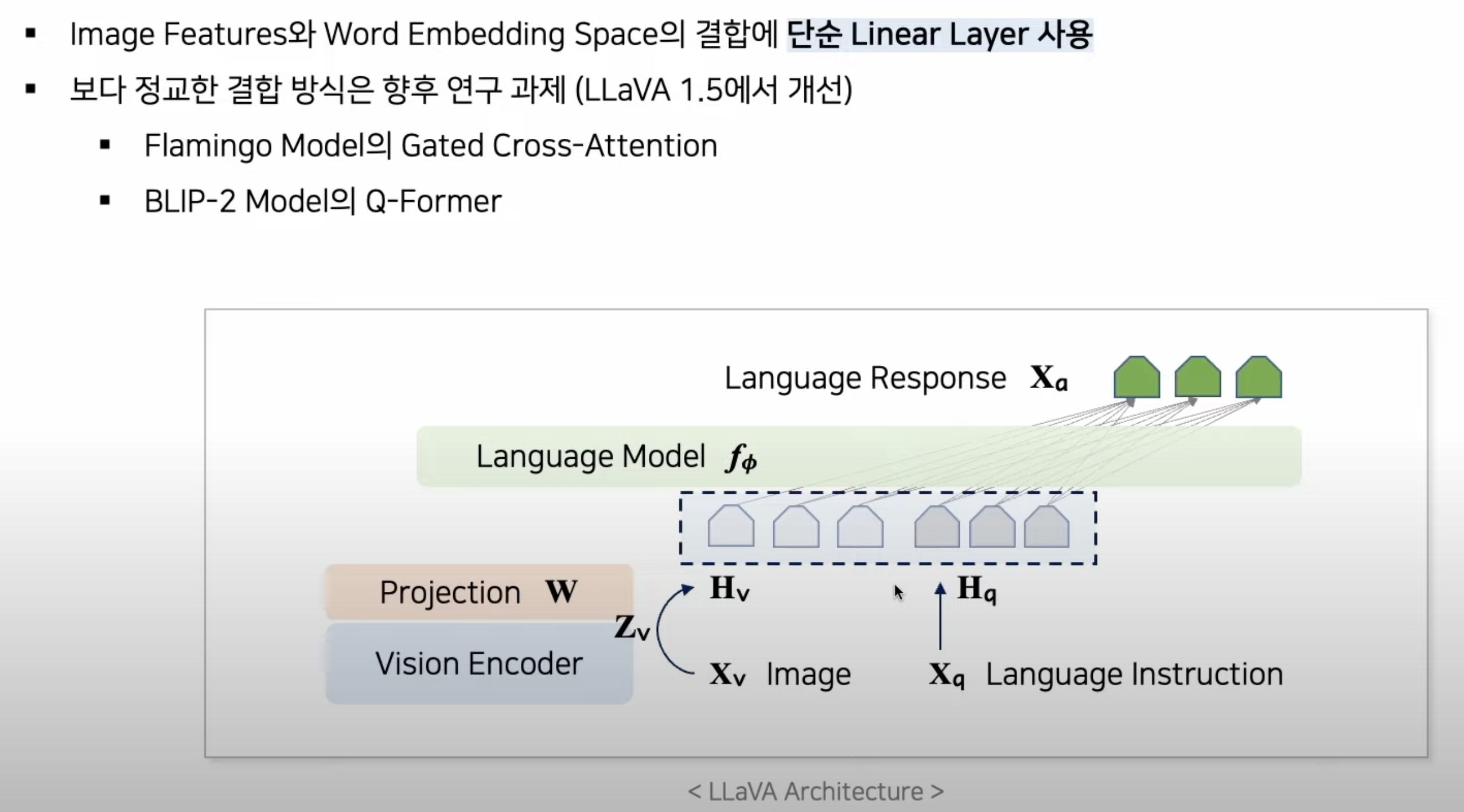

- 위 마지막 수식이 말하는 바는, 첫번째 지시어 때만 image(Xv)를 같이 넣어준다는 뜻이다.

3.2.1. pretraining
- image captions(
간단한 방법: image captioning dataset 그대로 활용참고)를 활용하여, visual tokenizer을 LLM에 호환 가능하도록 W 만 학습 - 위 1.1.0. 에서 설명했었음
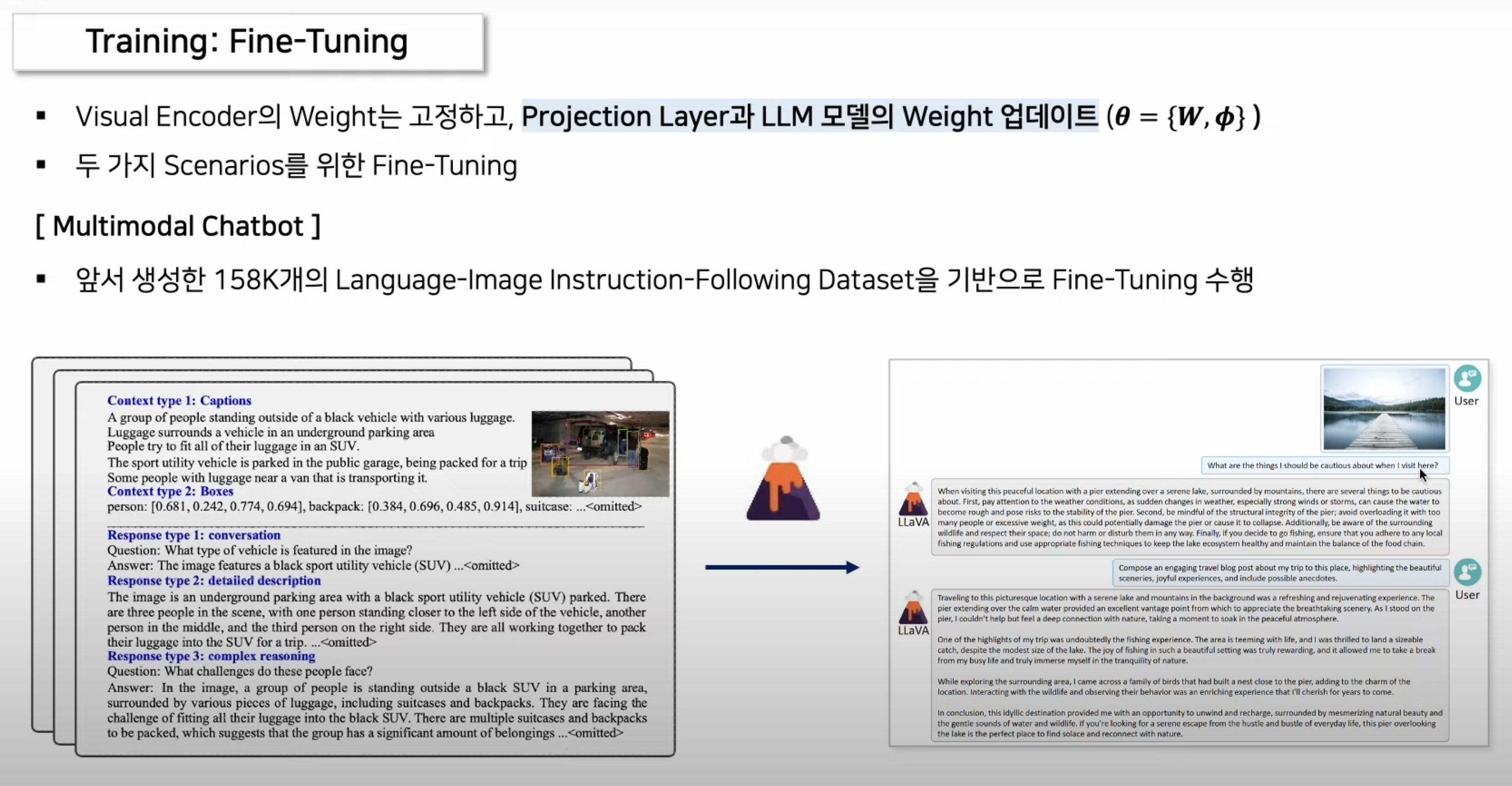
3.2.2. Fine-tuning
- 위에서 언급한
language-only GPT4를 이용하여 만든 instruction-following dataset로 학습!
- 위에서 언급한
- 과학 QA 데이터인 "Science QA" 데이터로 학습!
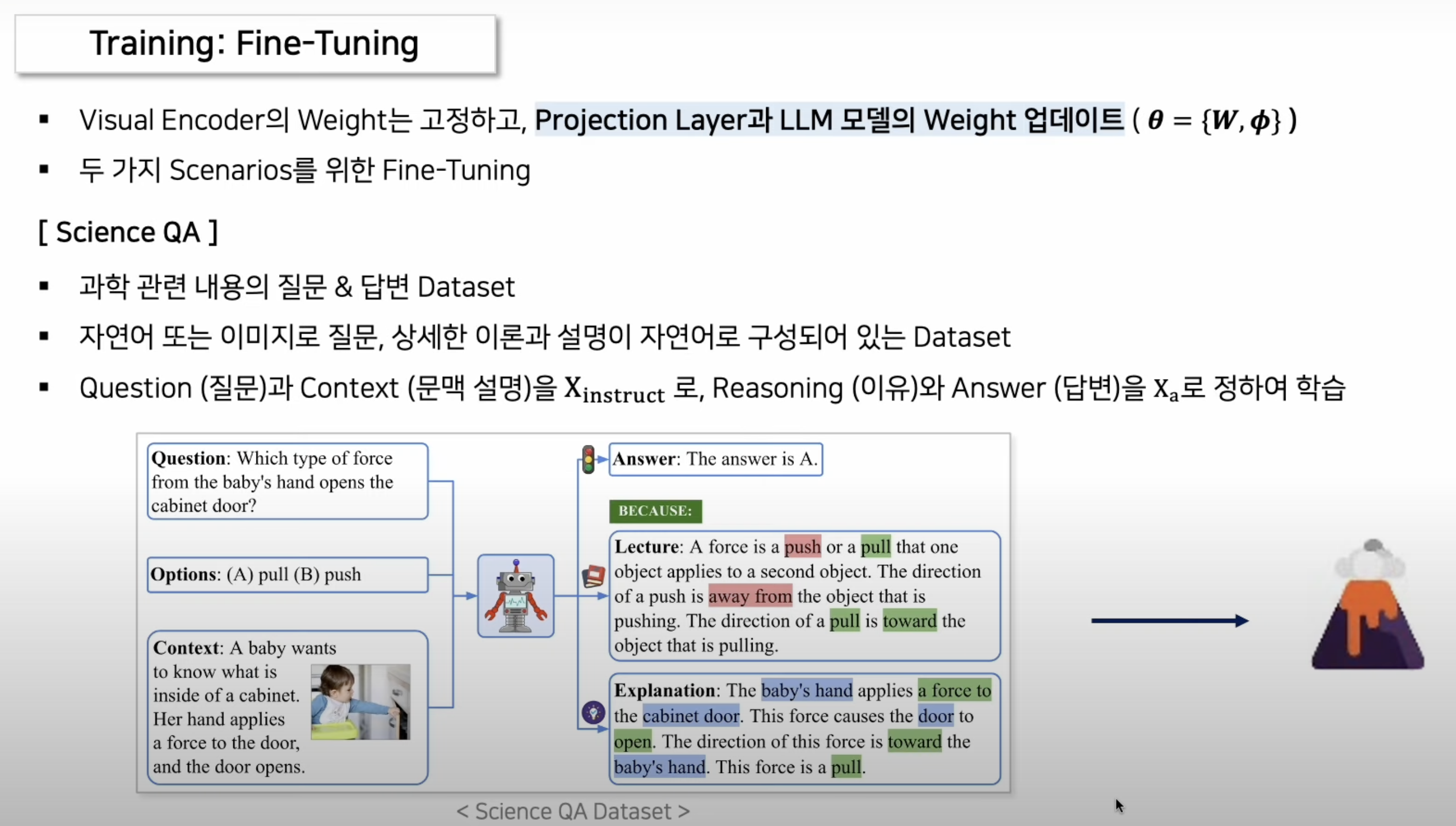
- 이는 모델의 제로샷 능력(새로운 작업을 학습 없이 수행하는 능력)을 크게 향상
4. 그 외
- 새로운 벤치마크(LLaVA-Bench)를 제시하고 모델과 데이터를 공개
visual instruction following에 대한 향후 연구를 촉진하기 위해 -> 다양한 응용 지향 작업을 포함하는 두 가지 evaluation benchmarks를 구성
- 성능
- Science QA에서 최첨단 성능 달성.
- 멀티모달 GPT-4와 비교 가능한 강력한 멀티모달 채팅 능력.
6. Appendix


모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것