1. 설명
- Cross Entropy Loss는 주로 분류 문제에서 모델의 예측이 실제 레이블과 얼마나 잘 일치하는지를 측정
- 이는 모델의 예측 확률 분포와 실제 레이블의 확률 분포 사이의 차이를 측정
- 예측된 확률 분포가 실제 분포를 얼마나 "잘" 표현하는지를 측정
1.1. 이진 분류(Binary Classification)
- 아래 식을 최소화하는 것이 목표!

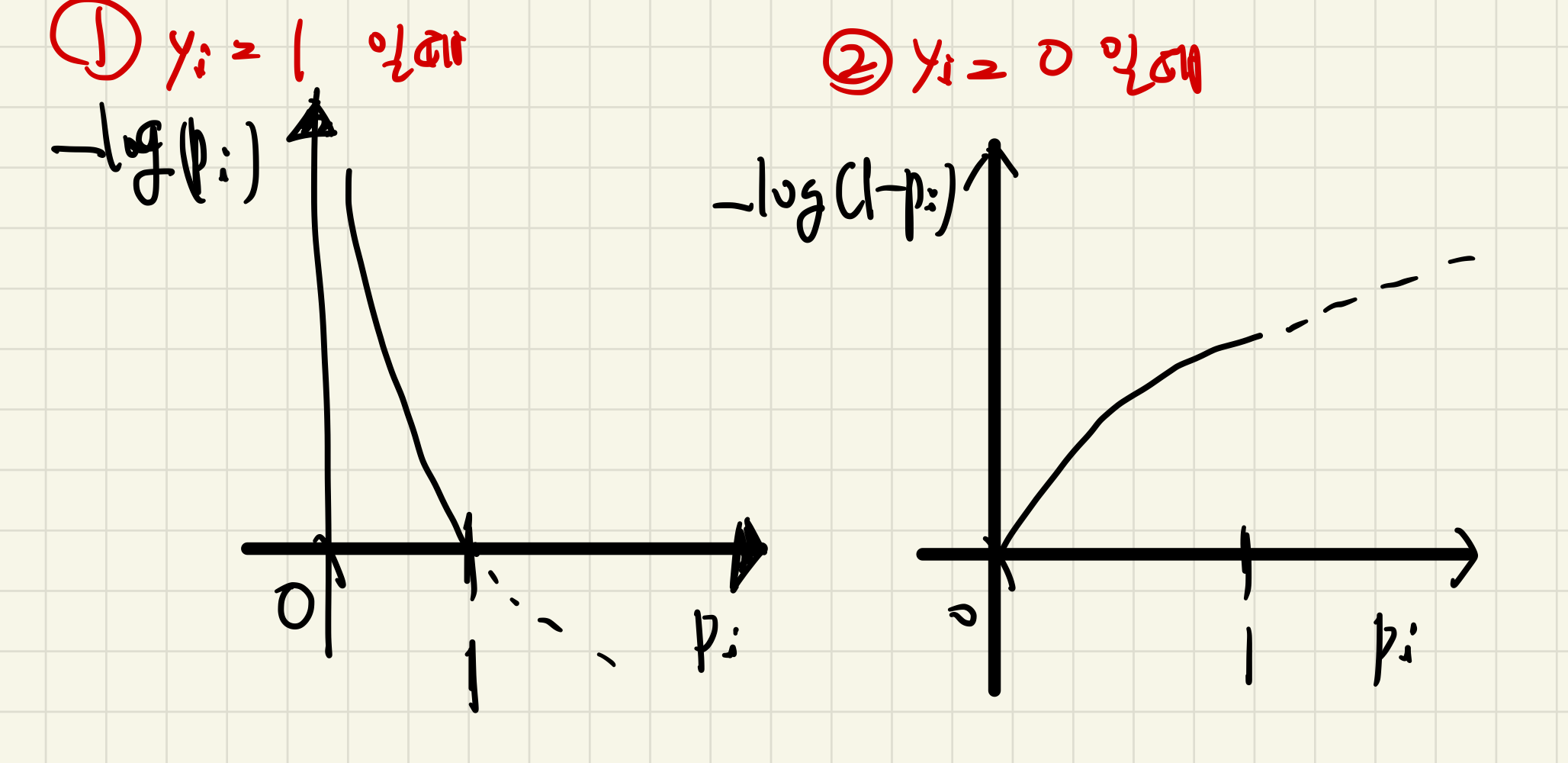
1.2. 다중 클래스 분류(Multi-class Classification)
- 아래 식을 최소화 하는 것이 목표!

2. Cross Entropy와 Cross Entropy Loss의 관계
- Cross Entropy는 이론적으로 두 확률 분포 사이의 차이를 측정하는 개념
- Cross Entropy Loss는 이 개념을 실제 모델 학습에 적용하여, 모델의 예측이 실제 레이블과 얼마나 잘 일치하는지를 평가하는 손실 함수
- 모델 학습의 목표는 Cross Entropy Loss를 최소화함으로써, 모델의 예측 분포를 실제 분포에 가능한 가깝게 만드는 것
Cross Entropy

- Cross Entropy는 두 확률 분포 (P)와 (Q) 사이의 차이를 측정
- 예를 들면,
- (P)는 실제 분포(레이블 분포), (Q)는 예측 분포(모델 출력)
로그 소프트맥스 (LogSoftmax)
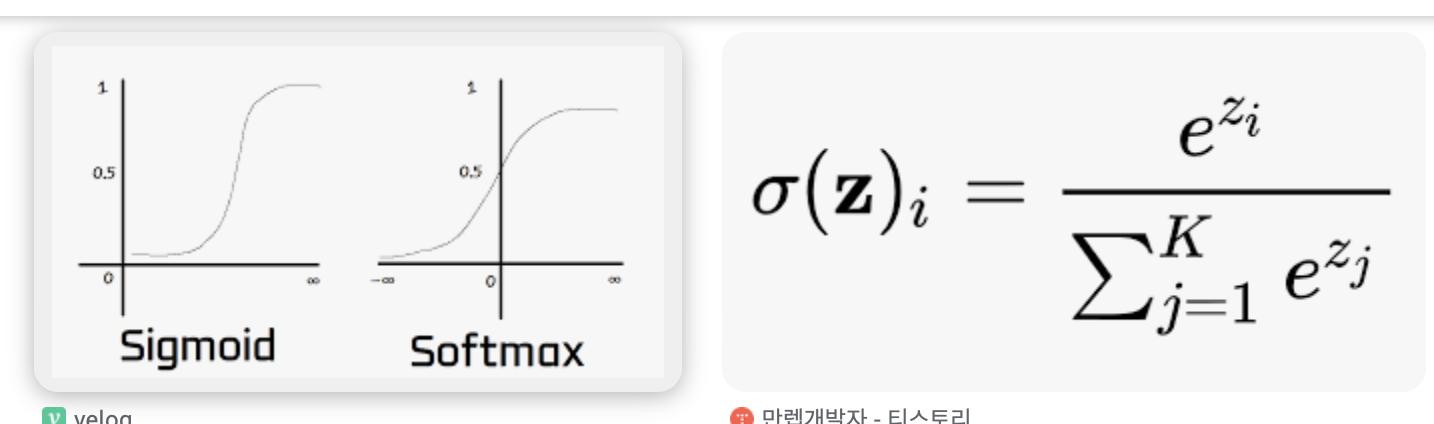
- 로그 소프트맥스 함수는 소프트맥스 함수에 자연 로그를 취한 것으로, 다중 클래스 분류 문제에서 출력 레이어에 사용
- 소프트맥스 함수는 입력 벡터를 정규화하여 출력값의 합이 1이 되도록 만들며, 각각의 출력값을 클래스에 속할 확률로 해석할 수 있습니다.
- 로그 소프트맥스는 이를 로그 공간으로 변환합니다.
- 주어진 벡터 (z)에 대한 소프트맥스 함수의 (i)번째 요소는 다음과 같습니다:
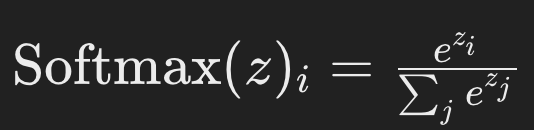
- 여기서 (z)는 모델의 로짓(소프트맥스 적용 전의 원시 출력값),
- (i)는 특정 클래스의 인덱스,
- (j)는 가능한 모든 클래스의 인덱스입니다.
- 로그 소프트맥스는 위의 식에 로그를 적용한 것입니다:

Negative Log Likelihood Loss, (NLLLoss)
- Negative Log Likelihood Loss은 모델이 실제 라벨에 할당한 확률의 로그에 음수를 취한 것
- 이 손실 함수는
로그 소프트맥스 출력을 입력으로 사용하며, 실제 라벨에 대한 모델의 예측 확률의 로그에 대한 평균 음수 값을 계산 - 주어진 실제 라벨 (y)와 모델 예측의 로그 확률 (\log(p))에 대해, 네거티브 로그 우도 손실은 다음과 같이 정의됩니다:
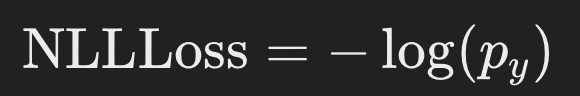
- 여기서 (p_y)는 실제 라벨 (y)에 해당하는 모델 예측의 확률
CrossEntropyLoss: 결합 사용
CrossEntropyLoss는 내부적으로 로그 소프트맥스와 NLLLoss를 결합하여 사용합니다. 이는 다음 단일 수식으로 표현될 수 있습니다:
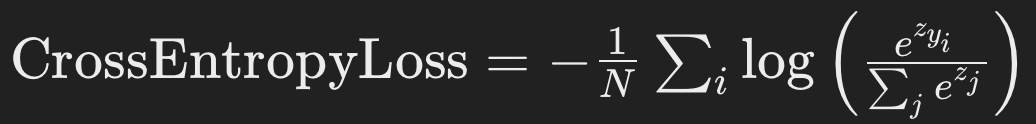
- (N)은 배치 내의 샘플 수,
- (y_i)는 (i)번째 샘플의 실제 클래스 라벨,
- (z_{y_i}): 모델이 (i)번째 샘플의 실제 라벨에 할당한 로짓 값
- 이 손실 함수는 모델이 정확한 라벨에 높은 확률을 할당하도록 유도하며, 분류 문제에서 널리 사용됩니다.
torch.nn.CrossEntropyLoss
- 소프트맥스 함수를 통한 확률 분포와 실제 라벨 간의 차이를 측정합니다.
- 내부적으로는 로그 소프트맥스(LogSoftmax)와 네거티브 로그 우도(Negative Log Likelihood Loss, NLLLoss)를 결합한 것과 동일
사용 예시:
import torch
import torch.nn as nn
# 예시 데이터: 3개의 클래스에 대한 배치 크기 5의 예측값 및 실제 라벨
input = torch.randn(5, 3, requires_grad=True)
target = torch.empty(5, dtype=torch.long).random_(3)
# CrossEntropyLoss 함수 초기화
loss_fn = nn.CrossEntropyLoss()
# 손실 계산
loss = loss_fn(input, target)
# 손실 출력 및 역전파
print(loss.item())
loss.backward()- 이 예시에서는 3개의 클래스를 가진 분류 문제에 대해, 배치 크기가 5인 예측값과 실제 라벨을 사용하여 교차 엔트로피 손실을 계산
CrossEntropyLoss는 모델의 예측값과 실제 라벨 사이의 손실을 계산하고, 이를 통해 모델 학습 시 그라디언트를 업데이트하는 데 사용할 수 있음
Parameters:
- weight (Tensor, optional):
- 각 클래스에 대한 가중치를 지정하는 1D Tensor
- 주로 클래스 불균형이 있는 경우 사용됩니다. 기본값은
None
- ignore_index (int, optional):
- 손실 계산에서 무시할 타겟(label) 인덱스
- 주로 특정 라벨을 무시하고 싶을 때 사용
- 기본값은
-100
- reduction (string, optional):
- 출력 손실을 계산하는 방법
'none'은 각 요소의 손실을 반환하고,'mean'은 배치에 대한 손실의 평균을, (기본값)'sum'은 손실의 합을 반환합니다.
Input:
- input (Tensor):
- 모델의 예측값으로,
[batch_size, C](C는 클래스 수)의 크기를 가진 Tensor입니다. logits형태로, 즉 소프트맥스 함수를 적용하기 전의 원시 점수
- 모델의 예측값으로,
- target (Tensor):
- 실제 라벨을 나타내는 Tensor로,
[batch_size]의 크기 - 각 요소는
0에서C-1사이의 값입니다.
- 실제 라벨을 나타내는 Tensor로,
Return:
- loss (Tensor):
- 지정된
reduction방식에 따라 계산된 손실 값 'mean'또는'sum'이 선택된 경우 스칼라 Tensor로 반환되며,'none'이 선택된 경우 요소별 손실을 담은 Tensor가 반환
- 지정된

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것
https://www.globhy.com/article/buying-horizontal-carbonized-bamboo-flooring-from-china-while-living-in-new-york
https://www.globhy.com/article/why-bamboo-flooring-is-the-eco-friendly-champion-of-sustainable-homes
https://www.hentai-foundry.com/user/bothbest/blogs/20350/Choosing-Bamboo-Flooring-for-My-London-Home
https://yamap.com/users/4784209
https://forum.iscev2024.ca/member.php?action=profile&uid=1357
https://my.usaflag.org/members/bothbest/profile/
https://myliveroom.com/bothbest
https://forum.geckos.ink/member.php?action=profile&uid=642
https://competitorcalendar.com/members/bothbest/profile/
https://www.fruitpickingjobs.com.au/forums/users/bothbest/
https://thefwa.com/profiles/bamboo-flooring
https://chanylib.ru/ru/forum/user/9508/
https://greenteam.app/bothbest
http://www.v0795.com/home.php?mod=space&uid=2304271
https://wearedevs.net/profile?uid=201358
https://www.templepurohit.com/forums/users/chinahousehold/
https://tutorialslink.com/member/FlooringBamboo/68089
https://www.tkaraoke.com/forums/profile/bothbest/
https://www.aipictors.com/users/bothbest
https://forum.index.hu/User/UserDescription?u=2129081
http://programujte.com/profil/75582-chinabamboo/
https://lamsn.com/home.php?mod=space&uid=1290622
https://nexusstem.co.uk/community/profile/chinabamboo/
https://brain-market.com/u/chinabamboo
https://malt-orden.info/userinfo.php?uid=414587
https://www.halaltrip.com/user/profile/255692/chinabamboo/
https://goodgame.ru/user/1698091
https://vcook.jp/users/42177
https://library.zortrax.com/members/china-bamboo/
https://aprenderfotografia.online/usuarios/chinabamboo/profile/
https://plaza.rakuten.co.jp/chinabamboo/
https://plaza.rakuten.co.jp/chinabamboo/diary/202508270000/
https://plaza.rakuten.co.jp/chinabamboo/diary/202508270001/
https://eternagame.org/players/538402
https://www.slmath.org/people/82724
https://www.aipictors.com/users/chinabambooflooring
https://vocal.media/authors/china-bamboo-bfc
https://www.giantbomb.com/profile/chinabamboo/
https://www.keedkean.com/member/44724.html?type=profile