0. 3가지 방법 표로 비교
| 방식 | 핵심 아이디어 | 장점 | 단점 | 단점을 어떻게 다른 방식이 보완/극복했는지 |
|---|---|---|---|---|
| Absolute Positional Embeddings | - 문장 내 각 토큰 위치 (i)에 대해 ‘절대 위치’ 임베딩 pᵢ를 부여 - 일정 길이(예: 최대 시퀀스 길이)까지 pᵢ를 미리 정의(학습형 또는 사인/코사인 기반) | - 구현이 단순하고 직관적 - (특히 학습형의 경우) Transformer 아키텍처에 바로 결합 가능 - 기존 Transformer(Attention Is All You Need)에서 성능 검증 | - 시퀀스 길이가 달라지면(더 긴 문장 등) 일반화가 어려움 - 문장 재배치나 중간 일부 제거 시, 절대 위치 번호가 달라져 학습 시점과 괴리 발생 - ‘상대적 거리’가 중요한 패턴(예: 인접 단어)을 직접 포착하기 어려움 | - Relative 방식이 (j - i) 기반 임베딩으로 ‘길이 변화’와 ‘상대적 관계’ 문제를 개선 - Rotary 방식도 시퀀스 길이 확장이나 토큰 재배치에서 좀 더 유연하게 적응 가능 |
| Relative Positional Embeddings | - 토큰 쌍 (i, j)의 상대 위치(j - i)에 따라 임베딩을 달리 부여 - 키/밸류 계산 시 aᵏᵢⱼ, aᵛᵢⱼ을 더해 점곱에 반영 | - (i, j)의 떨어진 거리에 대한 직접적이고 일반화된 패턴 학습 - 시퀀스 길이 변화, 부분적 잘림, 재배치 등에 강함 - 인접 토큰이나 몇 칸 떨어진 토큰처럼 “문맥적 거리” 정보를 명시적으로 반영할 수 있음 | - 절대 위치 정보를 완전히 배제하면(설계에 따라) 특정 과제에서 보완이 필요할 수 있음 - (j - i)가 크게 벌어지는 장거리 상황에서는 상대 임베딩 테이블 크기가 커질 수 있음 | - Rotary는 벡터 자체를 회전시키므로 대규모 길이에도 부드러운 확장이 가능 - Rotary는 (j - i) 테이블을 두지 않으므로, Relative 대비 메모리나 파라미터 증가 부담이 적으며 장거리 확장에도 유리 |
| Rotary Positional Embedding (RoPE) | - 입력 벡터(x)를 위치에 따라 복소 평면에서 회전하는 방식 - 주로 Q, K 벡터에 각도(θ)를 적용해 dot-product 시 위치 정보 반영 | - sin, cos 기반 회전으로 위치 증가 시에도 연속적 변화 보장 - 최대 시퀀스 길이를 초과해도 비교적 유연하게 일반화 가능 - 별도의 룩업 테이블 없이 수식만으로 구현 가능해 파라미터 증가가 적음 - 대규모 언어 모델에서 효율적 | - “회전(순환) 특성”을 가정하기 때문에, 매우 극단적으로 긴 시퀀스(학습 범위 밖)에선 성능 저하 가능 - 특정 거리 자체를 명시적 파라미터로 다루지 않아, 세밀한 제어가 필요한 태스크에는 부족할 수 있음 | - 상대 거리별 파라미터가 필요한 경우에는 Relative 방식이 유리 - 반면 Rotary는 Absolute/Relative의 시퀀스 길이 제약 문제를 더욱 완화해, 다양한 길이 확장에 대해 상대적으로 유연한 편 |
1. Positional Embeddings
1.1. Absolute Positional Embeddings
non-trainable vector 이용하는 방법
- 장점: extrapolation 성능이 높음
- 단점: 전반적 성능이 떨어짐
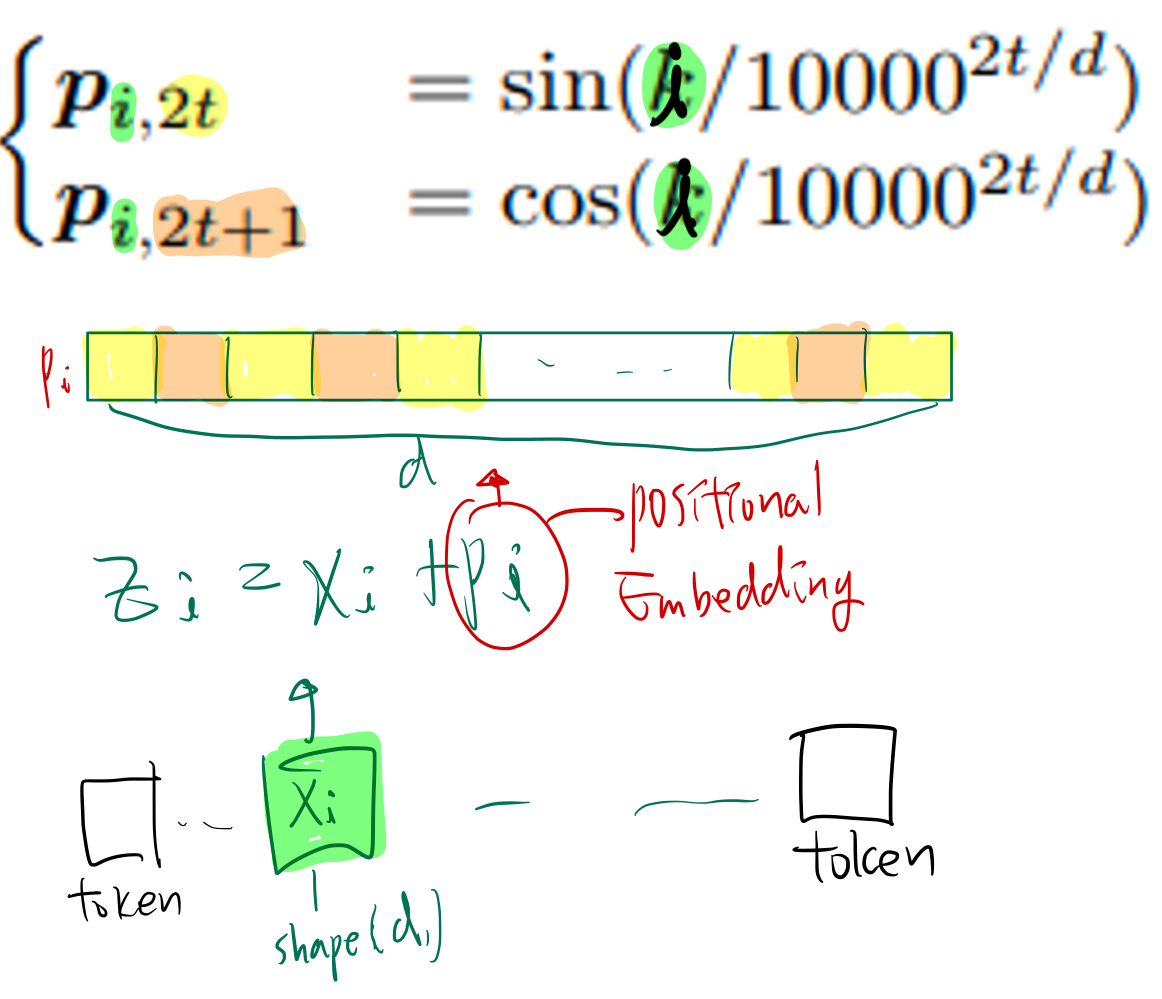
trainable vector 이용하는 방법
- 문장의 최대길이 ()를 설정하고, () vector을 학습
- 장점: 데이터에 맞춰 최적화가 가능해서 성능이 높음
- 단점: 학습 길이보다 긴 문장에 대해서 성능이 떨어짐 (extrapolation 성능이 낮음)
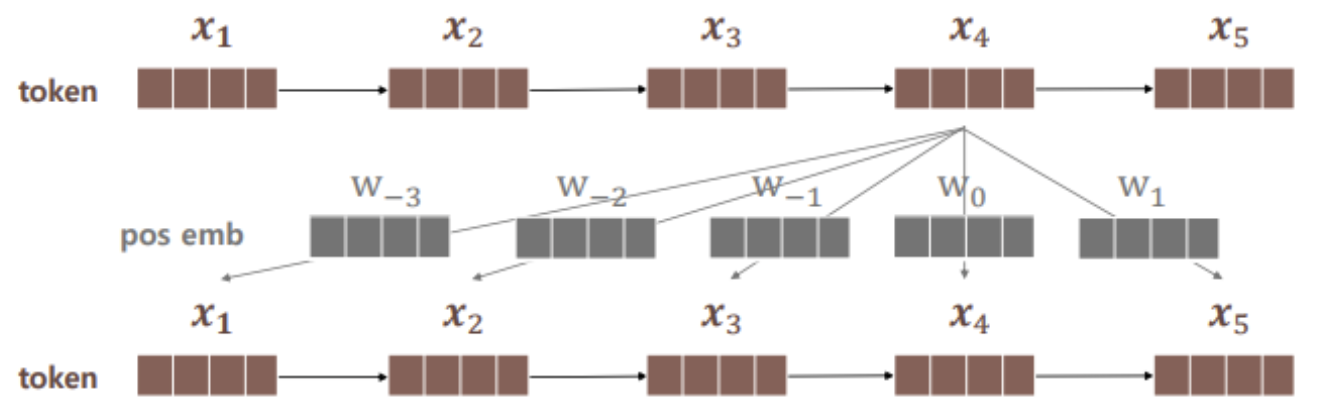
1.2. relative positional embeddings
- self-attention의 key와 query 사이의 거리에 따라 학습된 embedding을 생성
- 길이 5짜리 토큰의 예시를 들어서 설명하겠다.
- 4번째 토큰의 positional embedding은 아래와 같다.
- 모든 토큰의 positional embedding은 아래와 같다.
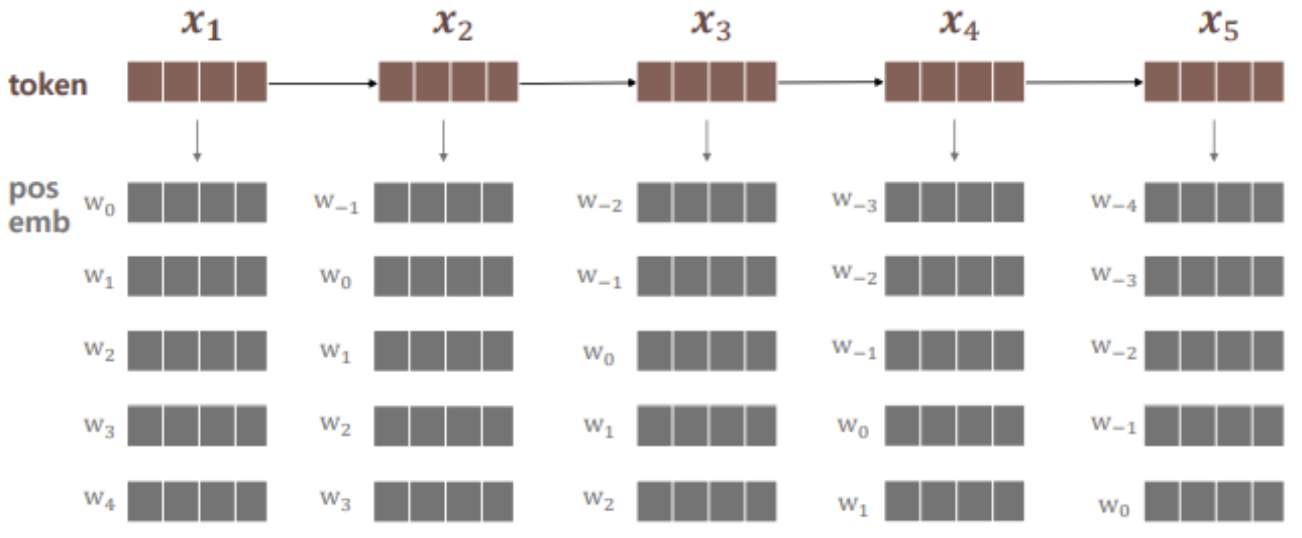
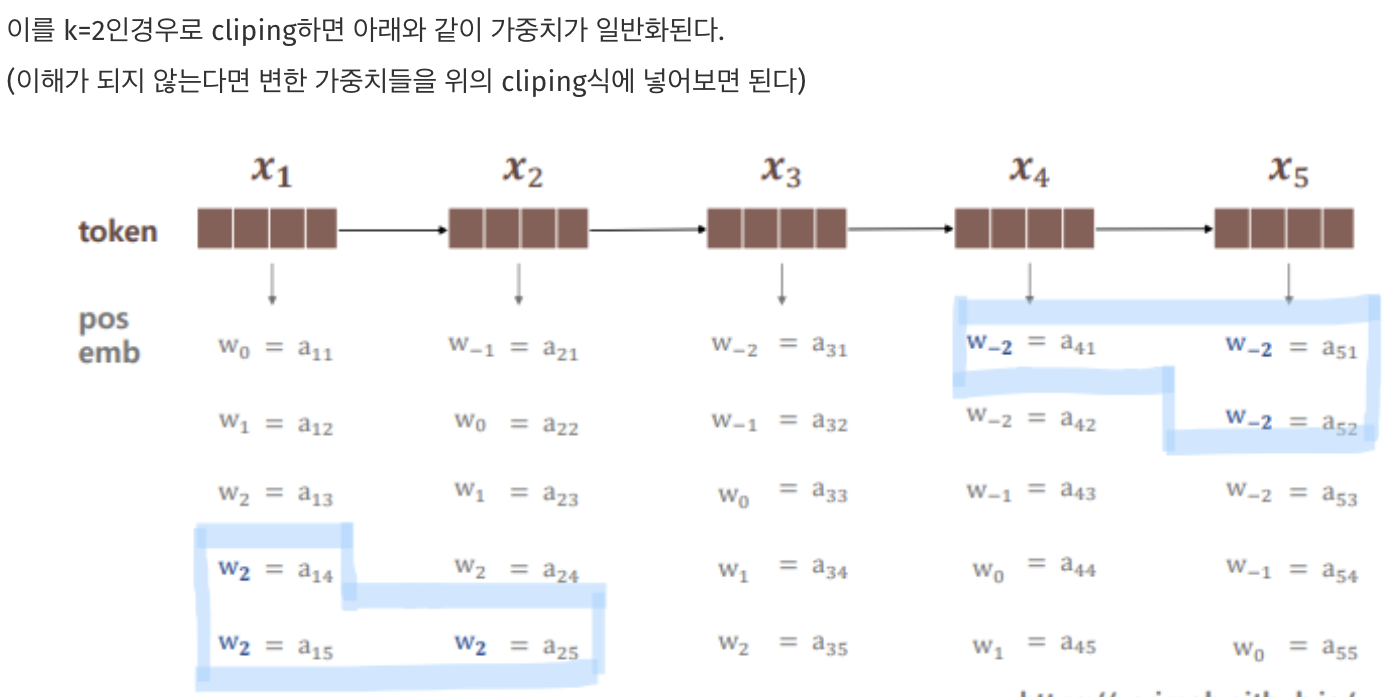
clipping?
- 즉 특정 거리 후에 위치 임베딩이 동일한 값을 얻는다.
-
- 심화 (T5 논문) 같은 경우에는 단순 clip이 아니라, 아래와 같음

적용
- 들어가기 전에 참고: 기본 transformer 수식 (알파와 e의 관계 복습)
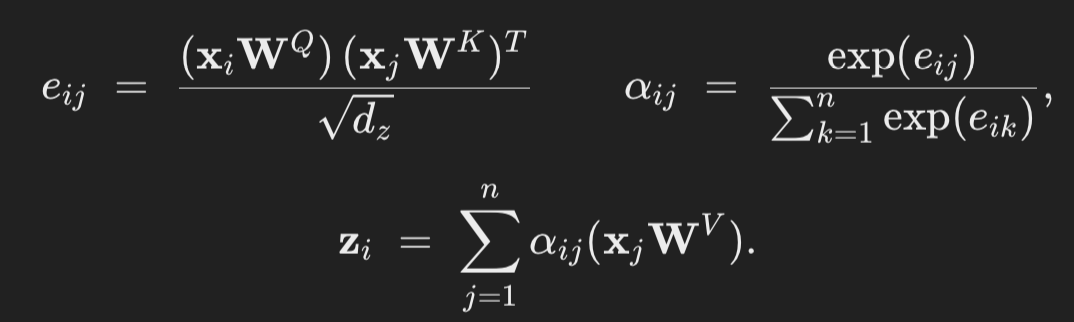
- 본문


better RPE
- 아래 내용을 완전 디테일하게 이해하진 않았음!

- transformer-XL
- positional encoding 하는 요소: key, value
- DeBERTa
- positional encoding 하는 요소: Query, key, value
2. rotary positional Embeddings
- 사실상의 표준 방법
2.1. 들어가기 전에

2.2. 기본 RoPE 설명
- 임베딩 자체를 수정하지 않고, self-attention 과정에서 rotation을 적용하자!
- query와 key 계산 과정에서 위치 정보를 반영하자!
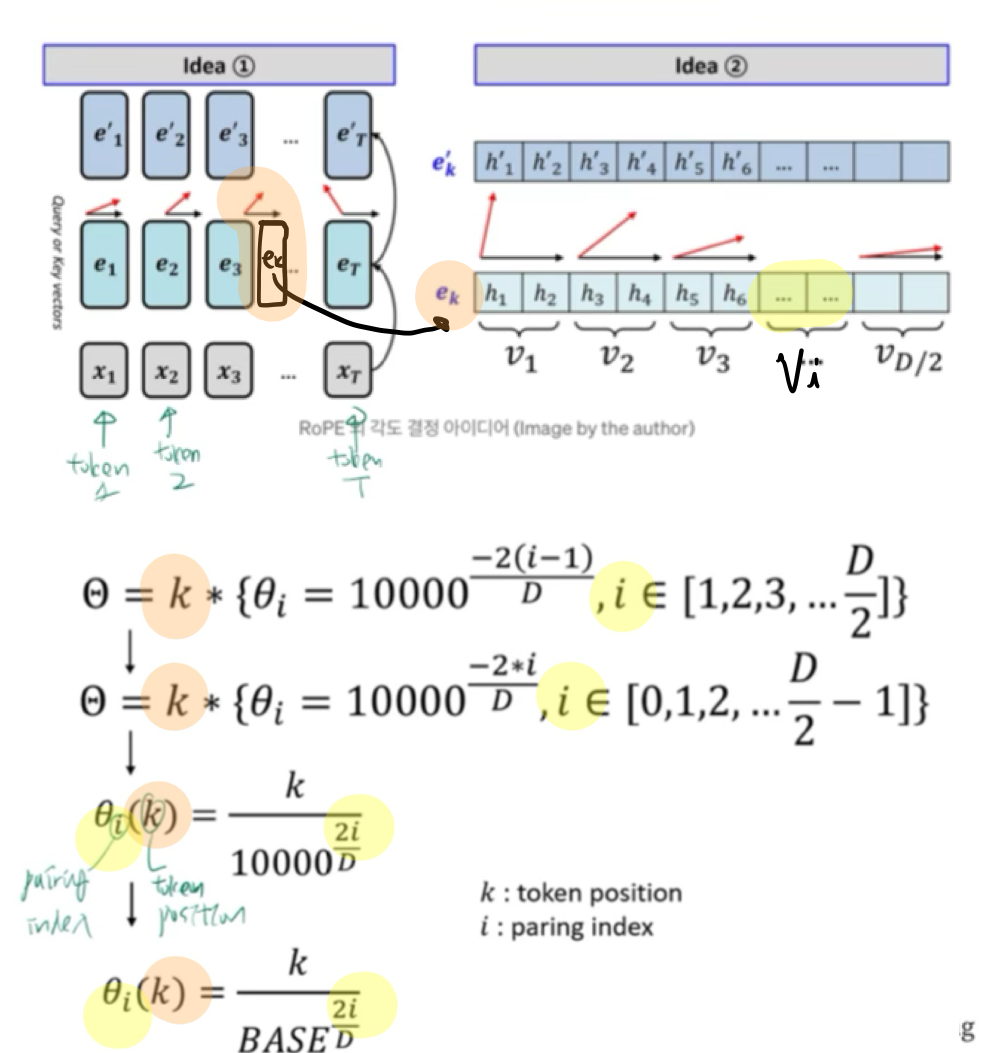
2.3. 개선된 RoPE 설명
- RoPE 스케일링 1 :
Base 값 조정- 10000으로 썼었는데, 1,000,000 혹은 500 으로 조정했을 떄 성능이 더 안정적이었다고 한다.
- RoPE 스케일링 2 :
상황별 Wavelength 조정
RoPE 스케일링 2 : 상황별 Wavelength 조정
- dimension D 내의 pair위치를 고정시켜놓고, token index를 바꿔보면서 cosine value 값을 구해보면 아래와 같다.
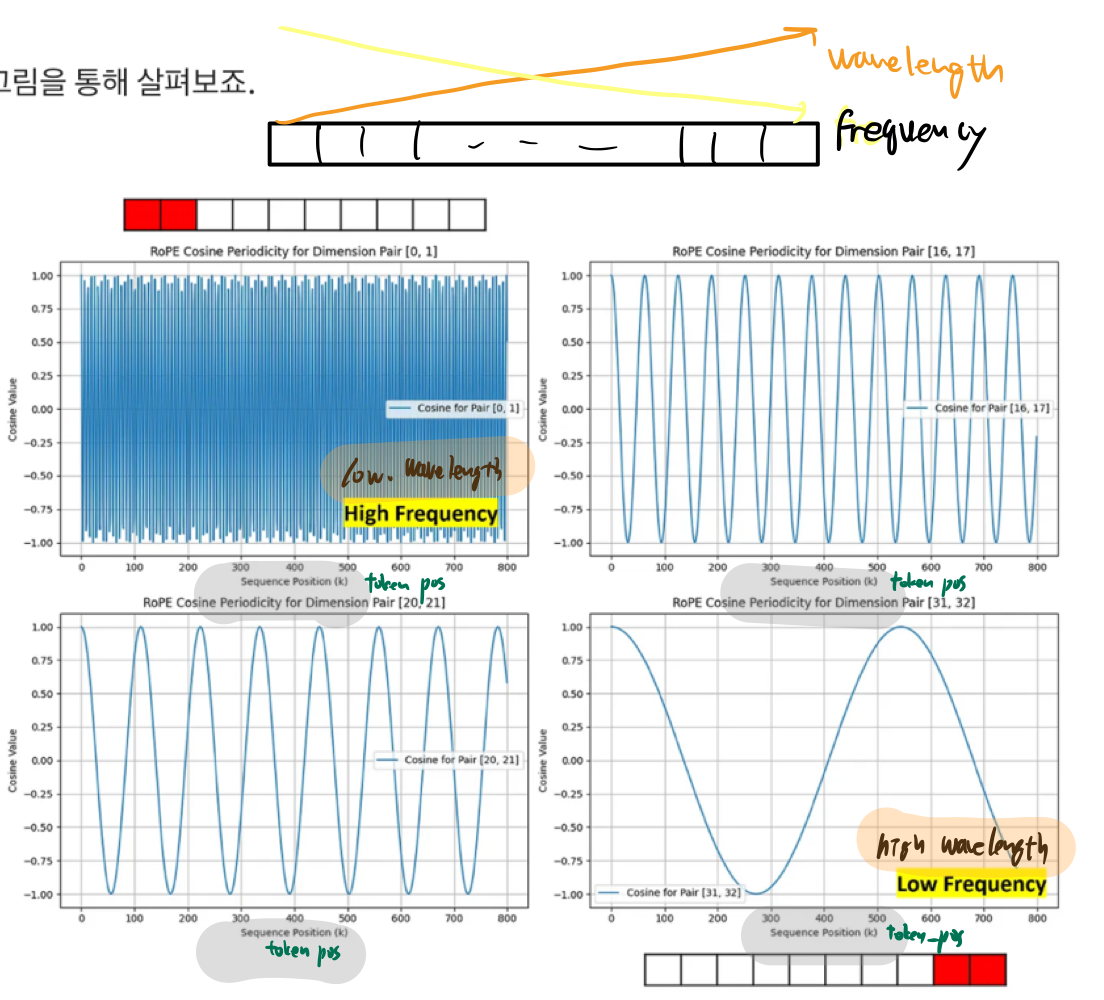
- 좌측영역 (high frequency / low wavelength)
- 바로 옆 token과의 값도 차이가 큼
- local positional 정보(가까운 token끼리의 세밀한 상대적 위치)를 정확하게 반영
- 좌측영역 (low frequency / high wavelength)
- 바로 옆 token과의 값과의 차이가 작음
- global positional 정보를 잘 반영
- 개선사항: 좌측영역의 wavelength를 좀 더 크게 조정하자!
- input sequence의 길이가 너무 길면, 회전의 특성상 아주 멀리 떨어진 token인데도 global positional 정보를 유사하게 반영해버리는 문제가 발생할 수 있으므로
구체적으로: llama3 에서의 rotary embedding 구현
- 아래의 방식을 이용해, 더 긴 input sequence도 처리할 수 있게 했음
- 먼저 기준점이 되는 Frequency를 하나 정합니다.
- 이를 기반으로 wavelength를 세 구간(high, medium, low frequency)으로 나누어 처리합니다.
- High frequency 영역은 그대로 두고, low frequency 영역은 wavelength를 늘리며, 중간 영역은 부드러운 보간법을 적용하여 자연스러운 전환을 만듭니다.
- 자세한건 추가 공부 필요!

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것