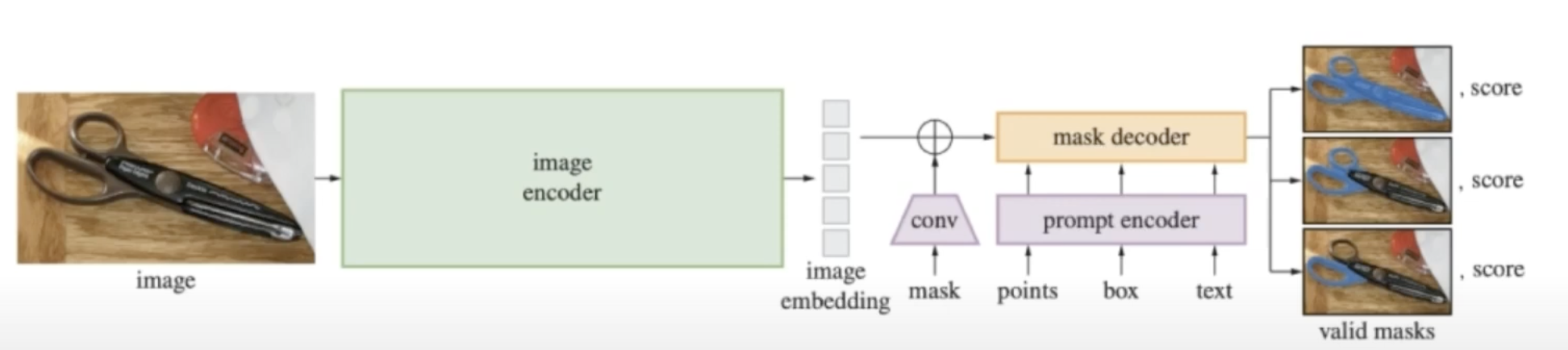
image encoder
- MAE(Masked Auto-encoder) 방식으로 학습시킨 Vision Transformer
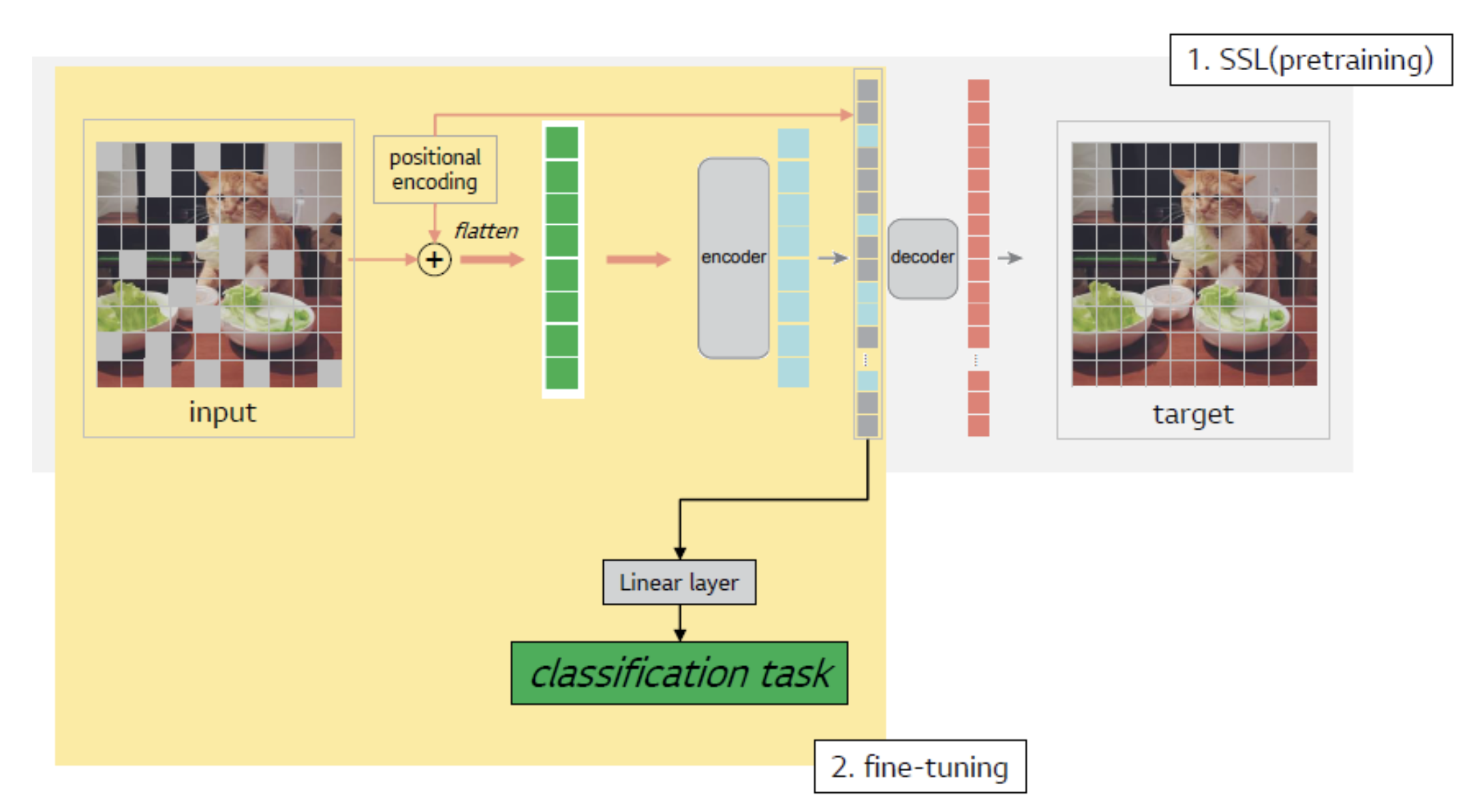
- MAE
- masked patch를 복원(reconstruction)하는 task로 학습한 것을 pretrained weight로 삼아서,
- downstream task로 finetuning을 했을 때 예측 성능이 더 좋다.
- masking을 random하게/덩어리로/규칙적으로 실험하는 세가지 세팅으로 했는데 random한 게 가장 성능이 좋다고 합니다.
- masking ratio를 75%로 한 것이 성능이 제일 좋았다고 합니다. BERT에서 통상 15%정도를 masking한 것과 비교하면 dramatic하게 차이가 있습니다.
- Language는 인간이 만든 signal로 문장을 이루는 word token 하나하나가 의미론적으로 정보가 굉장히 dense하다.
- 그렇기 때문에 단어 한 두개만 빼도 이것을 예측하는 것이 쉽지 않고 더 high-level의 추론능력으로 학습하는 것을 필요로 한다.
- 하지만, Image의 자연적인 signal로 정보가 비교적 sparse하다. 그래서 patch 조금 빼는 것은 주변 patch로부터 interpolation해도 적당히 될만큼 쉬운 task이다.
- 그렇기 때문에, high-level의 추론능력을 갖게 하기 위해서는 language에서보다 더 높은 masking ratio를 필요로 한다.
- pretrain(reconstruction) 때 사용하는 decoder의 design에 따라 finetuning task 성능이 다르다고 합니다(decoder는 finetuning에서 사용하지 않음에도).
- data augmentation을 하는게 아무 것도 안한 것보다 성능이 좋지만, data augmentation 기법에 따른 성능 차이가 적다. (robust)
- Contrastive learning 기반 실험 기법들은 성능이 data augmentation 설계에 심하게 좌우되는데, MAE는 data augmentation 유무에는 성능이 robust하다.
- 그 이유는 random masking이 어느 정도 data augmentation의 역할을 간접적으로 해주기 때문이다.
- masked patch를 복원(reconstruction)하는 task로 학습한 것을 pretrained weight로 삼아서,
Prompt Encoder
- Mask
- convolution으로 차원 맞춰준 뒤, image embedding에 pixel wise sum.
- point & bounding box
- positional encoding으로 표현
- Text
- Clip 모델의 text encoder을 가져와 임베딩
- Clip
- 이미지를 입력, 자연어를 supervision으로 주어 학습
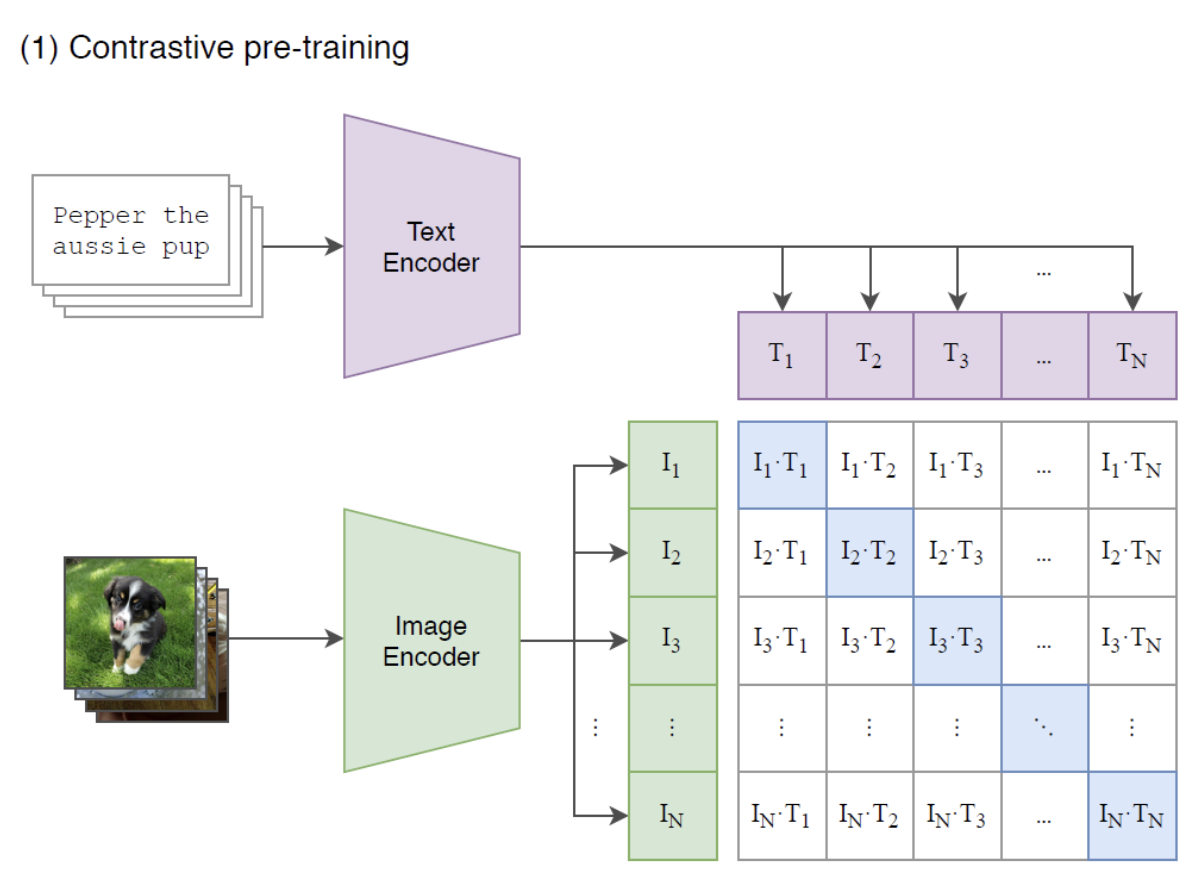
- 방법
- image와 text를 하나의 공통된 space로 보낸 다음
- positive pair에서의 유사도(cosine similarity)는 최대화하고
- negative pair에서의 유사도는 최소화하도록
- CE loss를 사용하여 학습한다.
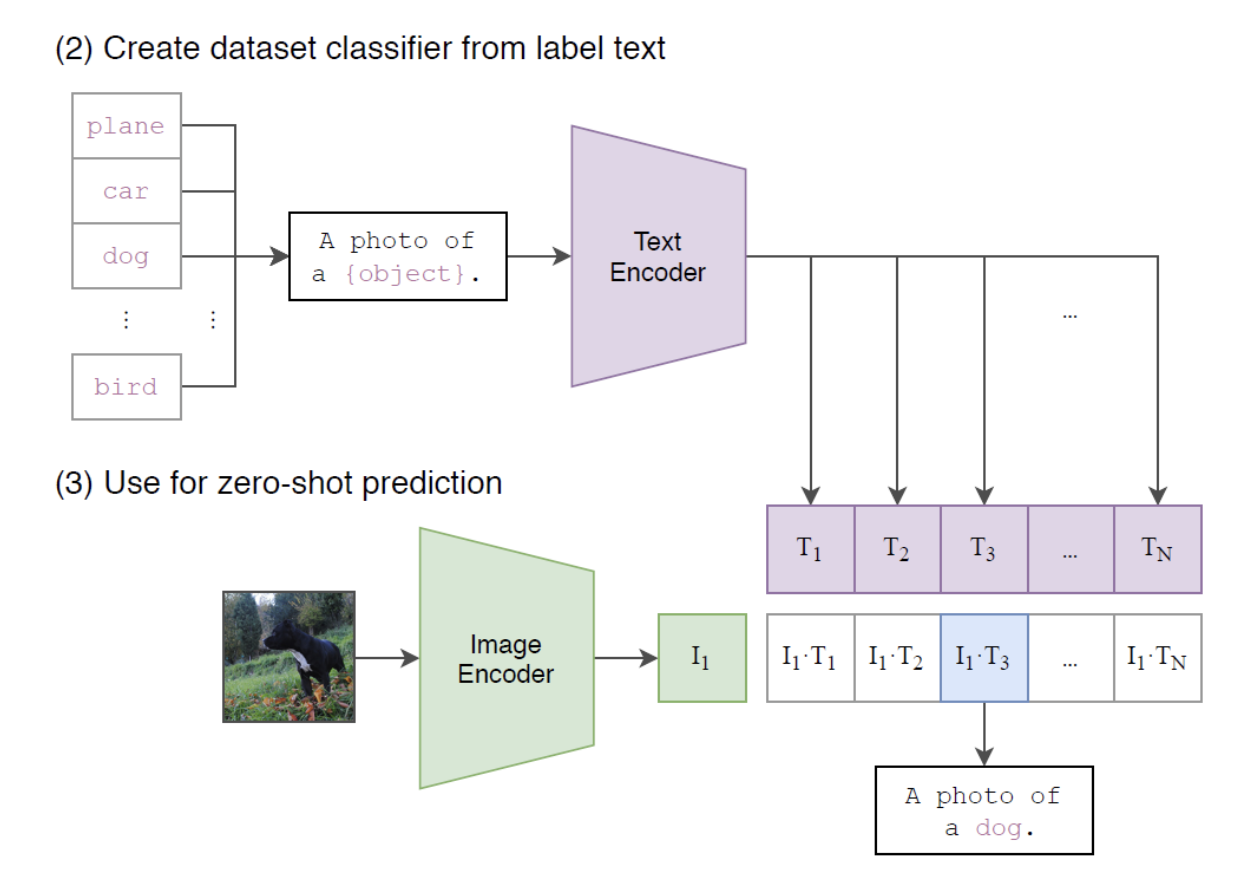
- Text encoder로는 Transformer를 사용했다.
- distribution shift(training & test set의 차이)를 극복 -> effective robustness
- domain 분포에 불변한 특징을 잘 추출하기 떄문
- relative robustness: out-of-distribution에서의 정확도 개선
- clip의 한계점
- 이 baseline은 현재 SOTA에 비하면 많이 낮은 성능을 가지는 모델이다.
- zero-shot CLIP이 전반적으로 SOTA 성능에 도달하려면 계산량이 1000배는 증가해야 할 것이라고 말하고 있다.
- CLIP은 고품질의 OCR representation을 학습하지만, MNIST에서 88%의 정확도밖에 달성하지 못한다. 매우 단순한 logistic regression 모델보다 낮은 이 성능은 사전학습 데이터셋에 MNIST의 손글씨 이미지와 유사한 example이 거의 없기 때문일 것이며, 이러한 결과는 CLIP이 일반적인 딥러닝 모델의 취약한 일반화(generalization)라는 근본적인 문제를 거의 해결하지 못했음을 의미한다.
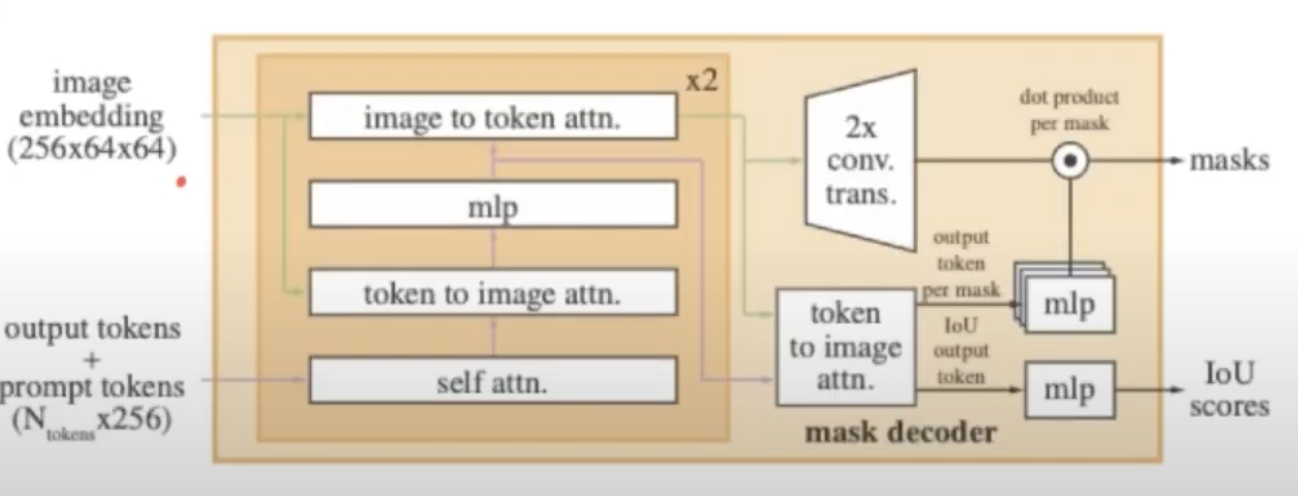
Mask Decoder 구조

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것
좋은 글이네요. 공유해주셔서 감사합니다.