
Unsupervised Domain Adaptation for Monocular 3D Object Detection via Self-Training
- 2022 ECCV
- 9회 인용
- good
- opensource labelled dataset + unlablled target dataset을 이용하여, source와 target 의 성능 차이가 적은 모델 학습하기.
- opensource 에서 먼저 학습
- target dataset에서 pseudo label 생성
- target dataset에서 fine-tuning
- nuScenes→KITTI / Lyft→KITTI / Lyft→nuScenes 에서 잘되는지 보자!
- 코드 공개 안함
abstract
- However, drastic performance degradation remains an unwell-studied challenge for practical cross-domain deployment as the lack of labels on the target domain.
- Investigate factor of the domain gap in Mono3D,
depth-shift issuecaused by thegeometric misalignment of domains.
- Then, we propose STMono3D, a new self-teaching framework for unsupervised domain adaptation on Mono3D.
- target 도메인의 레이블이 없는 데이터를 활용하여 모델이 자체적으로 pseudo 레이블을 생성하고 이를 활용하여 훈련하는 방식
- To mitigate
the depth-shift,- we introduce the
geometry-aligned multi-scale training strategy- to
disentangle(분리하다) the camera parametersand guarantee the geometry consistency of domains. geometry-aligned multi-scale training strategy- 전략의 핵심은 도메인 간의 기하학적인 불일치를 해결하기 위해 입력 이미지를 변형하거나 보정하는 것
- 예를 들어, 도메인 A와 도메인 B 간의 객체의 크기와 위치 차이가 있을 경우, 카메라 파라미터를 조정하여 객체를 동일한 크기와 위치로 맞추거나 보정하는 작업을 수행
- Based on this, we develop a teacher-student paradigm to generate adaptive pseudo labels on the target domain.
- to
- we introduce the
- Benefiting from the end-to-end framework that provides richer information of the pseudo labels,
- we propose the quality-aware supervision strategy to take instance level pseudo confidences into account and
quality-aware supervision- 의사 레이블의 신뢰도를 고려하여 모델의 훈련에 가중치를 부여하거나,
- 훈련 과정에서 의사 레이블을 조정하는 방법을 사용
- 예를 들어, 의사 레이블의 신뢰도가 높은 샘플에 대해서는 더 큰 가중치를 부여하여 모델이 이러한 샘플에 더 집중하도록 유도할 수 있습니다.
- 또는 의사 레이블의 신뢰도를 고려하여 훈련 과정에서 의사 레이블을 보정하거나 필터링하는 방법을 사용하여 노이즈를 줄일 수 있습니다.
- we propose the quality-aware supervision strategy to take instance level pseudo confidences into account and
- Moreover, the
positive focusing training strategyanddynamic thresholdare proposed to handle tremendous FN and FP pseudo samples.긍정적인 초점 전략은 양성 클래스의 샘플에 대해 가중치를 부여하거나, 오분류된 양성 샘플에 더 큰 페널티를 적용하는 방법을 사용하여 양성 클래스에 대한 훈련을 강화합니다.dynamic threshold는 분류 문제에서 모델의 출력을 기준으로 양성과 음성으로 분류하기 위한 임계값을 동적으로 조정하는 전략을 말합니다.- 일반적으로 분류 모델은 출력값과 미리 정의된 임계값을 비교하여 양성과 음성으로 분류합니다.
- 그러나 임계값을 고정하여 사용할 경우, 데이터 분포나 클래스 간의 불균형으로 인해 모델의 성능이 저하될 수 있습니다.
- 동적 임계값 전략은 이러한 문제를 해결하기 위해, 모델의 출력 분포나 클래스 비율에 따라 임계값을 동적으로 조정합니다.
Introduction

- 원인
- different types of sensors.
- weather conditions.
- geographical locations.
- 2D image setting에 관한 UDA(Unsupervised Domain Adaptation)
- light, color, texture를 다루는데에 집중
- 관련 논문: ([12, 26, 19, 9, 35, 15] )
- 3D ojbect detection의 경우는, geometry alignment가 매우 중요.
- depth-shift가 일어나는 이유?
- 모델과 camera parameters가 학습시 강하게 묶여있기 때문.
- target 도메인에서 돌리면, 2D 이미지 상에서의 물체의 의치는 정확하게 판단하지만, depth는 심각한 shift가 일어난다.
geometry-aligned multi-scale(GAMS) training- domain에서의 geometry consistency 보장
- pixel-size depth를 예측
mean teacher paradigm- the exponential moving average of the student model and updated at each iteration.
- It produces stable supervision for the student model without prior knowledge of the target domain.
- we utilize
the readability of each teacher-generated prediction- to dynamically reweight the supervision loss of the student model,
- which takes instance-level qualities of pseudo labels into account,
- avoiding the low-quality samples interfering the training process.
- positive pseudo labels만 학습에 이용하고, negative sample은 이용하지 않는다.
- It avoids excessive FN pseudo labels at the beginning of the training process impairing(손상시키다.) the capability of the model.
- In synchronization with training, we utilize a dynamic threshold to adjust the filter score, which stabilizes the increase of pseudo labels.
- to dynamically reweight the supervision loss of the student model,
Related work
Unsupervised Domain Adaptation
- ome methods [28, 36, 5] employ the statistic-based metrics to model the differ- ences between two domains.
- Other approaches [34, 50, 21] utilize the self-training strategy to generate pseudo labels for unlabeled target domains.
- adversarial learning was employed to align feature distributions [38, 13, 14]
- [23, 41] alleviated the domain shift on batch normalization layers by modulating the statistics in the BN layer before evaluation or special- izing parameters of BN domain by domain.
STMono3D
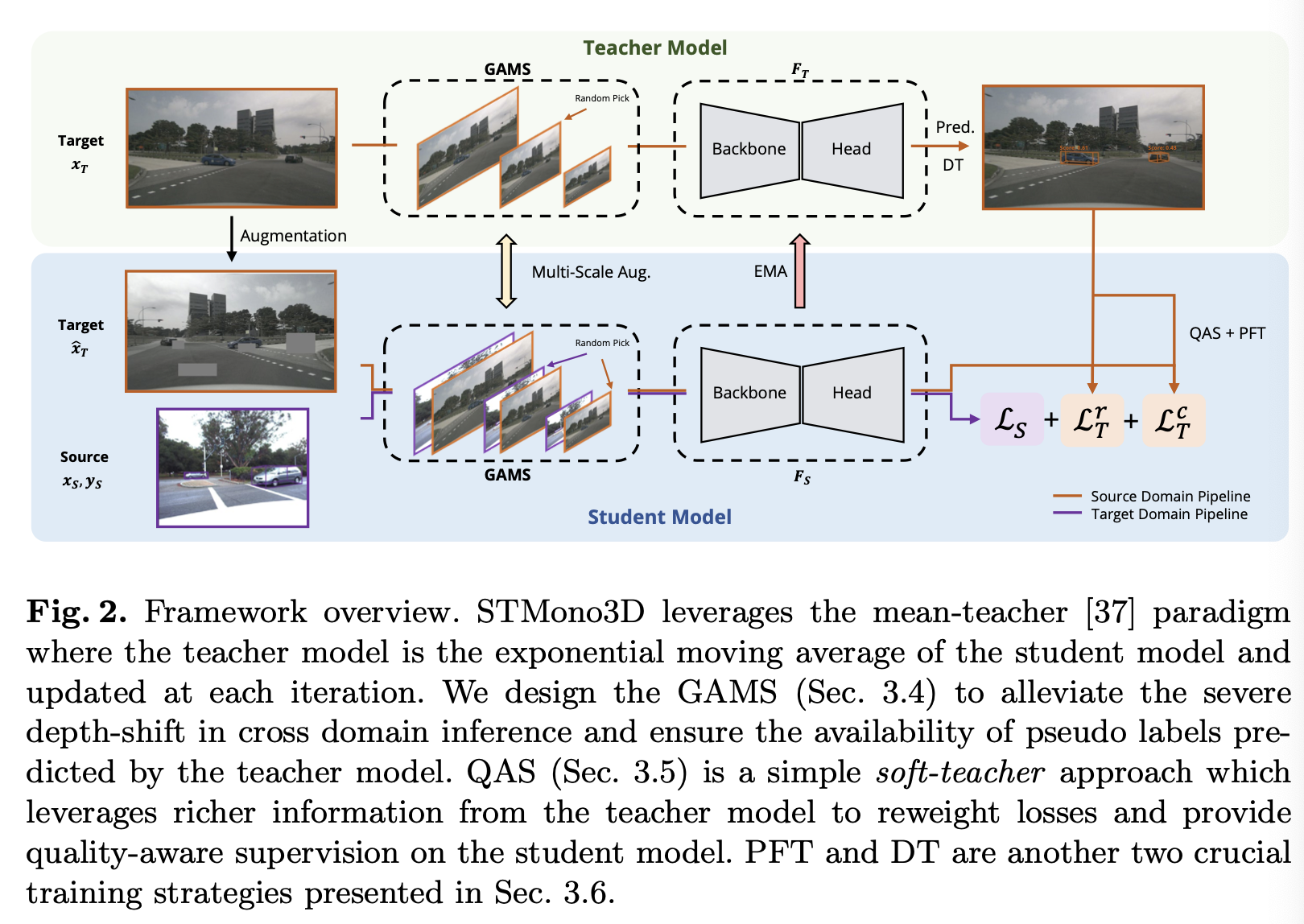
- GAMS(geometry-aligned multi-scale)
- 목적: 도메인 간 추론에서 심각한 깊이 변화를 완화하고, teacher 모델이 예측한 가짜 레이블을 사용할 수 있도록 보장
- QAS(quality-aware supervision)
- simple soft-teacher approach which leverages richer information from the teacher model
- to reweight losses and provide quality-aware supervision on the student model.
- simple soft-teacher approach which leverages richer information from the teacher model
- PFT(Positive Focusing Training)
- DT(Dynamic Threshold)
Experiment
Experimental Setup

- nuScenes→KITTI / Lyft→KITTI / Lyft→nuScenes 에서 잘되는지 보자!
- We first train a model (with GAMS) on the source domain,
- then generate pseudo labels for the target domain,
- and finally fine-tuning the trained model on the target domain.
Towards Domain Generalization for Multi-view 3D Object Detection in Bird-Eye-View
- CVPR 2023
- 1
- MV3D-Det 문제에서, Nuscenes 에서 학습한걸 waymo dataset에서 돌렸을 때의 성능저하를 막기 위한 논문.
- 우리는 아예 extrinsic이 크게 달라져버리는데, 의미가 있을까?
- BEVHEIGHT의 dataset으로 학습된 네트워크를 가져오면, 의미가 있을수도 있겠다.
abstract
-

-
most of them may risk drastic performance degradation when the domain of input images differs from that of training.
-
we first analyze the causes of the domain gap for the MV3D-Det task.
-
Based on the
covariate shift assumption, we find that the gap mainly attributes(기인하다) to thefeature distribution of BEV, which is determined by the quality of both depth estimation and 2D image’s feature representation. -
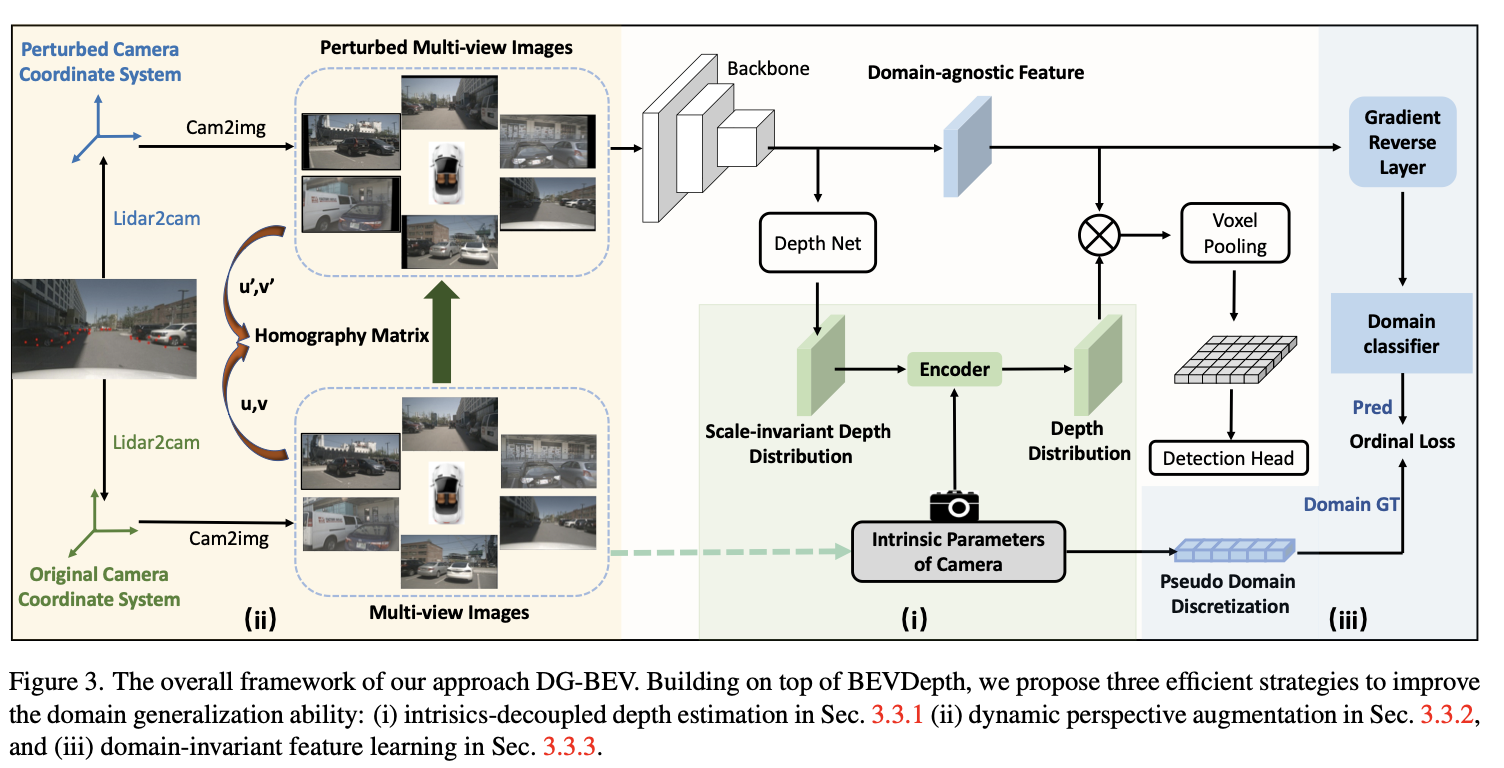
견고한 깊이 예측을 위해,
- decouple the depth estimation from the intrinsic parameters of the camera (i.e. the focal length)
- through converting the prediction of metric depth to that of scale-invariant depth.
- perform dynamic perspective augmentation
- to increase the diversity of the extrinsic parameters (i.e. the camera poses) by utilizing homography.
- decouple the depth estimation from the intrinsic parameters of the camera (i.e. the focal length)
-
Moreover, we modify the focal length values to create multiple pseudo-domains and
- construct an
adversarial training lossto encourage the feature representation to be more domain-agnostic.
- construct an
-
다양한 실험 결과로 Waymo, nuScenes, Lyft에서 우리의 접근 방식인 DG-BEV가 보이지 않는 대상 도메인에서의 성능 저하를 성공적으로 완화시키면서 소스 도메인의 정확성을 손상시키지 않음을 입증하였습니다.
introduction
-
그러나 대부분의 탐지기는 훈련 및 테스트 데이터가 동일한 도메인에서 얻어진 것으로 가정하며, 현실적인 상황에서 이를 보장하기 어렵습니다.
-
따라서 입력 이미지의 도메인이 변화할 때 성능 저하가 발생할 수 있습니다.
-
예를 들어, nuScenes [3]와 Waymo [34]는 3D 객체 탐지의 인기 있는 두 가지 벤치마크이며, 이들은 데이터 수집 장치가 동일하지 않습니다.
- 즉, 내재 및 외재 매개변수 모두 다릅니다.
- 그림 1에 제시된 경험적 결과에서는 nuScenes에서 훈련된 탐지기가 Waymo 데이터셋에서 객체를 예측할 때 위치 편향이 발생함을 보여줍니다.
-
도메인 일반화(Domain Generalization, DG) [8, 18, 26]
- 보이지 않은 대상 도메인에서 잘 일반화하는 모델을 학습하는 것을 목표로 하며, 앞서 언급한 편향을 완화하기 위한 타당한 해결책이 될 수 있습니다.
- 문헌에서 이러한 작업 대부분은 여러 소스 도메인이 사용 가능한 경우에 대해 설계되었으며, 이는 자율주행 시나리오에서 현실 세계의 다양성으로 인해 현실적으로 실현하기 어렵습니다.
-
본 논문에서는 MV3D-Det의 도메인 간 격차의 원인을 이론적으로 분석합니다.
-
공변량 변화 가정 [4]을 기반으로, 이러한 격차가 주로 BEV의 특징 분포에 기인하며, 이는 깊이 추정과 2D 이미지 특징에 의해 결정됩니다.
-
이를 바탕으로 우리는 BEV에서의 MV3D-Det을 위한 도메인 일반화 방법인 DG-BEV를 제안합니다.
-
구체적으로, 도메인이 변화할 때 깊이 추정이 부정확해지는 이유에 대해 철저한 분석을 수행하고, 다양한 도메인에서 사용되는 카메라의 내재 매개변수가 동일하게 보장되기 어렵다는 핵심 요인을 발견합니다 (이해를 돕기 위해 그림 2를 참조하십시오).
-
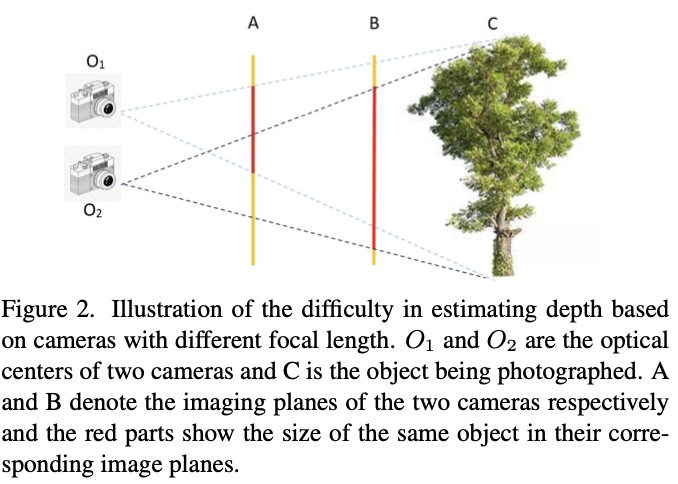
-
위 문제를 완화하기 위해, 미터 단위 깊이 예측을 크기 불변 깊이 예측으로 변환함으로써 깊이 추정을 내재 매개변수에서 분리하는 방법을 제안합니다.
-
또한, 카메라의 외재 매개변수 (예: 카메라 포즈)도 카메라 기반 깊이 추정에서 중요한 역할을 하지만 이전의 작업에서는 주로 무시되었습니다.
-
we introduce homography learning to dynamically augment the image perspectives
- by simultaneously adjusting the imagery data and the camera pose.
-
또한, 더 나은 일반화를 위해
도메인에 구애받지 않는 특징 표현이 선호되므로,- 소스 도메인의 카메라 내재 매개변수의 초점 거리 값을 수정하여 여러 가상 도메인을 구축하고,
- 적대적인 훈련 손실을 구성하여 특징 표현의 품질을 더욱 향상시킵니다.
-
요약하면, 본 논문의 주요 기여는 다음과 같습니다:
- MV3D-Det에서 도메인 간 격차의 원인에 대한 이론적 분석을 제시합니다. 공변량 변화 가정을 기반으로, 격차가 깊이 추정과 2D 이미지 특징의 특징 분포에 기인한다는 것을 발견
- 우리는 DG-BEV를 제안하여 위에서 언급한 두 가지 측면에서 도메인 간 격차를 완화하는 도메인 일반화 방법을 제시합니다.
- Waymo, nuScenes, Lyft를 포함한 다양한 공개 데이터셋에서의 광범위한 실험을 통해 우리의 접근 방식의 일반화 및 효과를 입증합니다.
- 우리의 지식에 따르면, 이는 다중 시점 3D 객체 탐지에 대한 도메인 일반화 방법을 체계적으로 연구하는 첫 번째 연구입니다.
Method
A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View
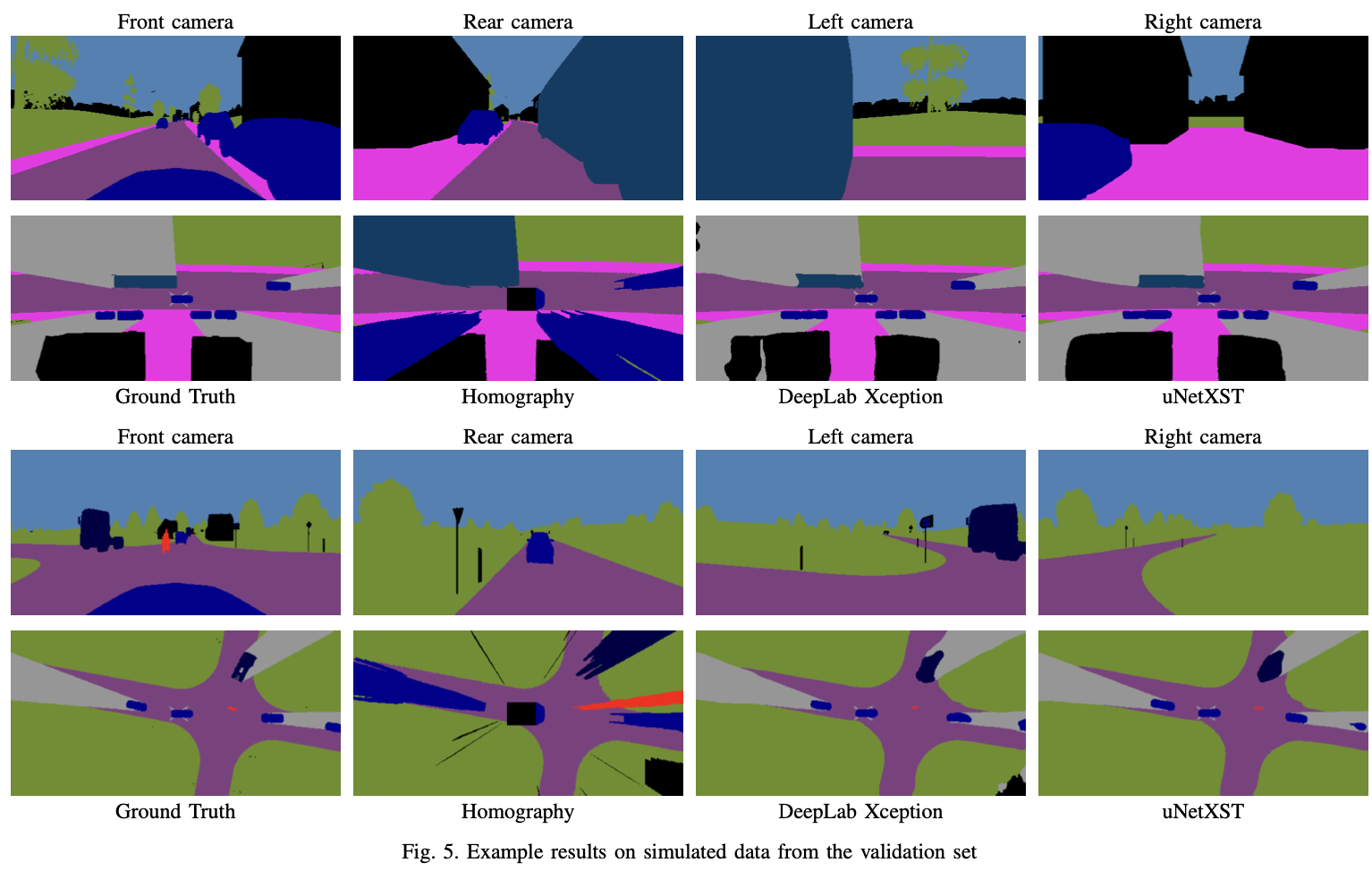
abstract
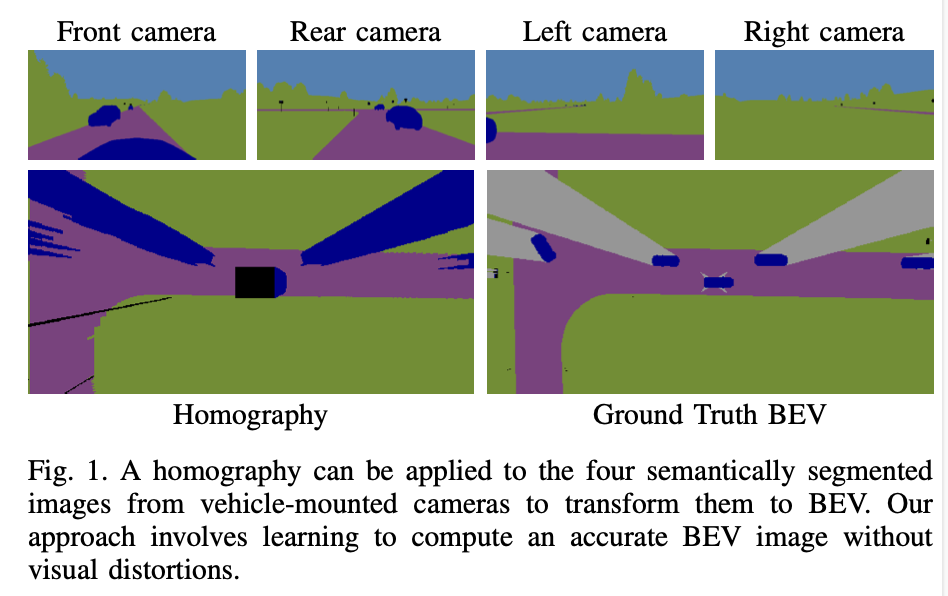
-
Distances can be more easily estimated when the camera perspective is transformed to a bird’s eye view (BEV).
-
For flat surfaces, Inverse Perspective Mapping (IPM) can accurately transform images to a BEV.
-
Three-dimensional objects such as vehicles and vulnerable road users are distorted by this transformation making it difficult to estimate their position relative to the sensor.
-
This paper describes a methodology to obtain a corrected 360◦ BEV image given images from multiple vehicle-mounted cameras.
-
The corrected BEV image is segmented into semantic classes and includes a prediction of occluded areas.
-
The neural network approach does not rely on manually labeled data, but is trained on a synthetic dataset in such a way that it generalizes well to real-world data.
-
By using semantically segmented images as input, we reduce the reality gap between simulated and real-world data and are able to show that our method can be successfully applied in the real world.
-
Extensive experiments conducted on the synthetic data demonstrate the superiority of our approach compared to IPM.
-
Multiple vehicle-mounted 카메라를 BEV segmented image로 잘 변환할 수 있는 방법을 제안함.
-
두 개의 네트워크 구조를 비교하여 제안한 구조가 BEV segmentation에 더 적합하다는 것을 보임.
-
시뮬레이션 데이터만으로 학습하여 manual labeling이 필요없도록 함,
-
실 환경 테스트에서도 sim-to-real gap 없이 잘 적용되는 것을 보임.
Introduction
-
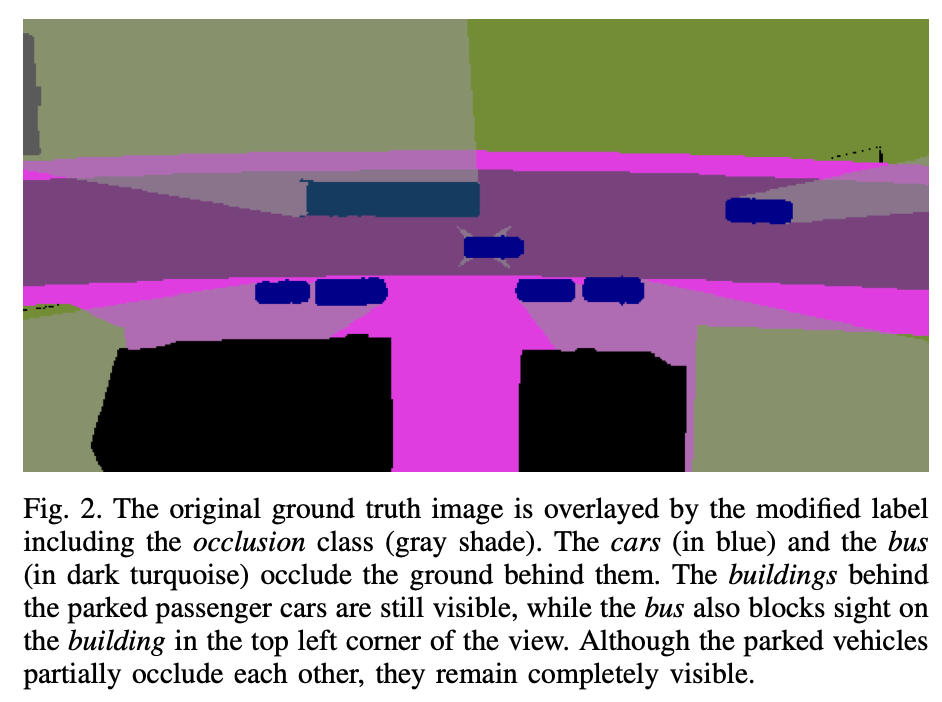
-
일부 class들을 항상 시야를 가림 (e.g. building, truck)
-
일부 class들은 절대 시야를 가리지 않음. (e.g. road)
-
자동차들은 그 뒤에 있는 높은 물체를 제외한 모든 시야를 가림. (e.g. truck, bus)
일부가 가려진 물체들은 모두 보이도록 남겨둠. -
모든 카메라 뷰에서 가려진 물체는 occluded로만 labeling함.
-
RGB 이미지를 이용하여 end-to-end로 BEV segmentation을 하는 것은 다음과 같은 문제가 있음.
-
실 환경에서는 매칭되는 BEV 이미지 (RGB, segmentation 모두)를 얻기 어려움.
-
시뮬레이터 데이터로 학습할 수는 있지만, RGB 이미지는 Sim-to-real gap이 커서 성능이 매우 떨어짐.
-
위와 같은 문제를 해결하기 위해 Synthetic data만을 이용하여 학습함.
-
BEV segmentation 네트워크의 입력으로 camera의 semantic map을 주어 Sim-to-real gap을 최소화함.
BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs
abstract
Introduction
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
- 2022
- 137회 인용
- 애매
- GTA에서 학습한게, Cityscape 데이터셋에서 잘 되는지?
abstract
- 실체 분할을 위해 실제 세계 이미지의 픽셀별 주석을 확보하는 것은 비용이 많이 드는 과정이므로, 모델은 대신 더 접근 가능한 합성 데이터로 훈련하고 주석 없이 실제 이미지에 적응시킬 수 있습니다.
- 이러한 과정은 비지도 도메인 적응 (UDA)에서 연구되고 있습니다.
- 새로운 적응 전략을 제안하는 방법은 많이 있지만, 대부분이 오래된 네트워크 아키텍처를 기반으로 합니다.
- 최근의 네트워크 아키텍처의 영향은 체계적으로 연구되지 않았기 때문에,
- 우리는 먼저 UDA를 위해 다른 네트워크 아키텍처를 벤치마킹하고, UDA 시맨틱 분할에 대한 Transformers의 잠재력을 새롭게 밝힙니다.
- 이러한 결과를 바탕으로 우리는 새로운 UDA 방법인 DAFormer를 제안합니다.
- DAFormer의 네트워크 아키텍처는
Transformer 인코더와multi- level context-aware feature fusion decoder로 구성됩니다. - 이 방법은 세 가지 간단하지만 중요한 훈련 전략을 통해 훈련을 안정화하고 소스 도메인에 과적합을 피할 수 있도록 지원됩니다.
- (1) 소스 도메인에서의 희귀 클래스 샘플링은 pseudo 레이블의 품질을 향상시키고 일반적인 클래스로의 자기 교사의 확인 편향을 완화합니다. (Rare Class Sampling on the source domain improves the quality of the pseudo-labels by mitigating(완화하다) the confirmation bias of self-training toward common classes,)
- (2) a Thing-Class ImageNet Feature Distance and
- (3) a learning rate warmup promote feature transfer from ImageNet pretraining.
- DAFormer는 UDA에서 큰 진보를 나타냅니다.
"A Thing-Class ImageNet Feature Distance"
- "사물 클래스 ImageNet 특징 거리"를 의미합니다.
- 이는 UDA (Unsupervised Domain Adaptation)에서 사용되는 방법 중 하나로,
- ImageNet에서 사전 훈련된 모델의 특징 벡터 간의 거리를 활용하여, 모델의 특징 전달을 촉진하는 방법을 나타냅니다.
- 일반적으로, ImageNet은 대규모의 이미지 데이터셋으로 다양한 사물 클래스를 포함하고 있습니다.
- ImageNet에서 사전 훈련된 모델은 이러한 다양한 클래스의 이미지에 대한 특징을 학습하고 갖추고 있습니다.
- 이 특징은 이미지의 고수준 표현을 나타내며, 사물의 시각적인 속성과 특징을 포착하는 데 도움이 됩니다.
- "Thing-Class ImageNet Feature Distance"는 UDA에서 소스 도메인과 타겟 도메인 간의 특징 전달을 장려하기 위해 사용됩니다.
- 이 방법은 소스 도메인과 타겟 도메인의 이미지에 대해 ImageNet에서 사전 훈련된 모델로부터 추출된 특징 벡터를 비교하고, 두 도메인 간의 특징 거리를 측정합니다.
- 이를 통해 소스 도메인과 타겟 도메인 간의 유사성을 파악하고, 특징 전달을 촉진하기 위해 모델의 학습을 조정하거나 가중치를 적용할 수 있습니다.
a learning rate warmup
- 학습률 웜업은 훈련 초기에 학습률을 작은 값으로 설정하고, 일정 기간 동안 점진적으로 증가시키는 전략입니다.
- GTA→Cityscapes의 mIoU에서 10.8 향상 및 Synthia→Cityscapes의 mIoU에서 5.4 향상을 통해 최신 기술 수준을 개선하며, 열차, 버스, 트럭과 같은 어려운 클래스의 학습을 잘 수행할 수 있습니다.
- 구현은 https://github.com/lhoyer/DAFormer에서 사용할 수 있습니다.
Introduction
Continual Test-Time Domain Adaptation
- CVPR
- 89회 인용
- 2022
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
- 2022
- 47
- ECCV
Sepico: Semantic-guided pixel contrast for domain adaptive semantic segmentation
- 2023
- 43회 인용
- Next Generation Deep Learning Based on Simulators and Synthetic Data
- Continual Test-Time Domain Adaptation
- HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
- Parallel Learning: Overview and Perspective for
Computational Learning Across Syn2Real and Sim2Real
