개요
비디오 요약의 종류
- 비디오 요약은 크게 비디오 스토리보드(Video Storyboard)와 비디오 스킴(Video Skim) 종류로 나눠볼 수 있습니다.
비디오 스토리보드(Video Storyboard)
- 비디오의 각 구간에서 대표적인 단일 프레임을 추출해 비디오 요약을 구성하는 방식입니다.
비디오 스킴(Video Skim)
- 비디오의 각 구간에서 대표적인 프레임 집합들을 추출해 비디오 요약을 구성합니다.
- 비디오 스킴은 음성과 영상을 포함하며, 비디오 스토리보드에 비해 연속성이 있어 보다 다양한 정보를 제공할 수 있습니다.
전통적 방식
- 사람이 직접 특정한 기준을 설계
- 인접 프레임간 움직임 정보의 변화량(면접, 위치, 분산 등)을 시간적으로 누적하여 계산하는 움직임에 대한 정보량
- 인접 프레임 간의 화소값 차이의 변화 패턴
딥러닝 이용
- multi modality가 대세
- video / text / audio / object 등
논문 조사
Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
- 2023 CVPR
- 8회 인용
- paper: https://openaccess.thecvf.com/content/CVPR2023/papers/Moon_Query-Dependent_Video_Representation_for_Moment_Retrieval_and_Highlight_Detection_CVPR_2023_paper.pdf
- code: https://github.com/wjun0830/QD-DETR
abstract
- 최근 비디오 이해에 대한 수요가 급격히 증가함에 따라 비디오 순간 검색 및 하이라이트 감지(MR/HD)가 주목을 받고 있습니다. MR/HD의 주요 목표는 주어진 텍스트 쿼리에 대해 순간을 지역화하고 클립 별 일치 수준, 즉 중요도 점수를 추정하는 것입니다.
- 최근 트랜스포머 기반 모델들이 일부 진전을 가져왔지만, 이러한 방법들이 주어진 쿼리의 정보를 완전히 활용하지 못한다는 것을 발견했습니다. 예를 들어, 순간과 그 중요도를 예측할 때 텍스트 쿼리와 비디오 콘텐츠 간의 관련성이 때때로 무시됩니다. 이 문제를 해결하기 위해, 우리는 MR/HD를 위해 맞춤형된 검출 트랜스포머인 Query-Dependent DETR (QD-DETR)을 소개합니다. 트랜스포머 아키텍처에서 주어진 쿼리의 중요성이 미미하다는 것을 관찰함에 따라, 우리의 인코딩 모듈은 텍스트 쿼리의 맥락을 비디오 표현에 명시적으로 주입하기 위해 크로스-어텐션 레이어로 시작합니다. 그런 다음, 모델이 쿼리 정보를 활용하는 능력을 향상시키기 위해, 비디오-쿼리 쌍을 조작하여 관련 없는 쌍을 생성합니다. 이러한 부정적(관련 없는) 비디오-쿼리 쌍은 낮은 중요도 점수를 내도록 훈련되며, 이는 모델이 쿼리-비디오 쌍 간의 정확한 일치를 추정하도록 격려합니다. 마지막으로, 주어진 비디오-쿼리 쌍에 대한 중요도 점수의 기준을 적응적으로 정의하는 입력 적응형 중요도 예측기를 제시합니다. 우리의 광범위한 연구는 MR/HD를 위한 쿼리 의존적 표현을 구축하는 것의 중요성을 검증합니다. 특히, QD-DETR은 QVHighlights, TVSum, Charades-STA 데이터셋에서 최신 방법들을 능가합니다.
Hierarchical Multimodal Attention for Deep Video Summarization
abstract
- 이 논문은 프로 축구 경기를 필드에서 수집된 앞서 언급한 이벤트 스트림 데이터와 TV에서 방송된 콘텐츠를 모두 사용하여 가능한 한 자동으로 요약하는 문제를 탐구
- 우리는 이를 위한 아키텍처를 설계했으며,
- (1)
사건들 간의 순차적 의존성을 고려하는 다중 인스턴스 학습 방법과 - (2)
각 이벤트의 중요성을 파악하는 계층적 멀티모달 주의 레이어를 도입
- (1)
- 우리는 두 개의 유럽 프로 축구 리그에서의 경기를 대상으로 접근 방식을 평가했으며,
- 인간 운영자가 만든 실제 요약과 비교하여 자동 요약을 위한 최고의 행동을 식별할 수 있는 능력을 보여줍니다.
Hierarchical Multimodal Transformer to Summarize Videos
- 2022
- 31회 인용
- paper: https://arxiv.org/pdf/2109.10559.pdf
그림
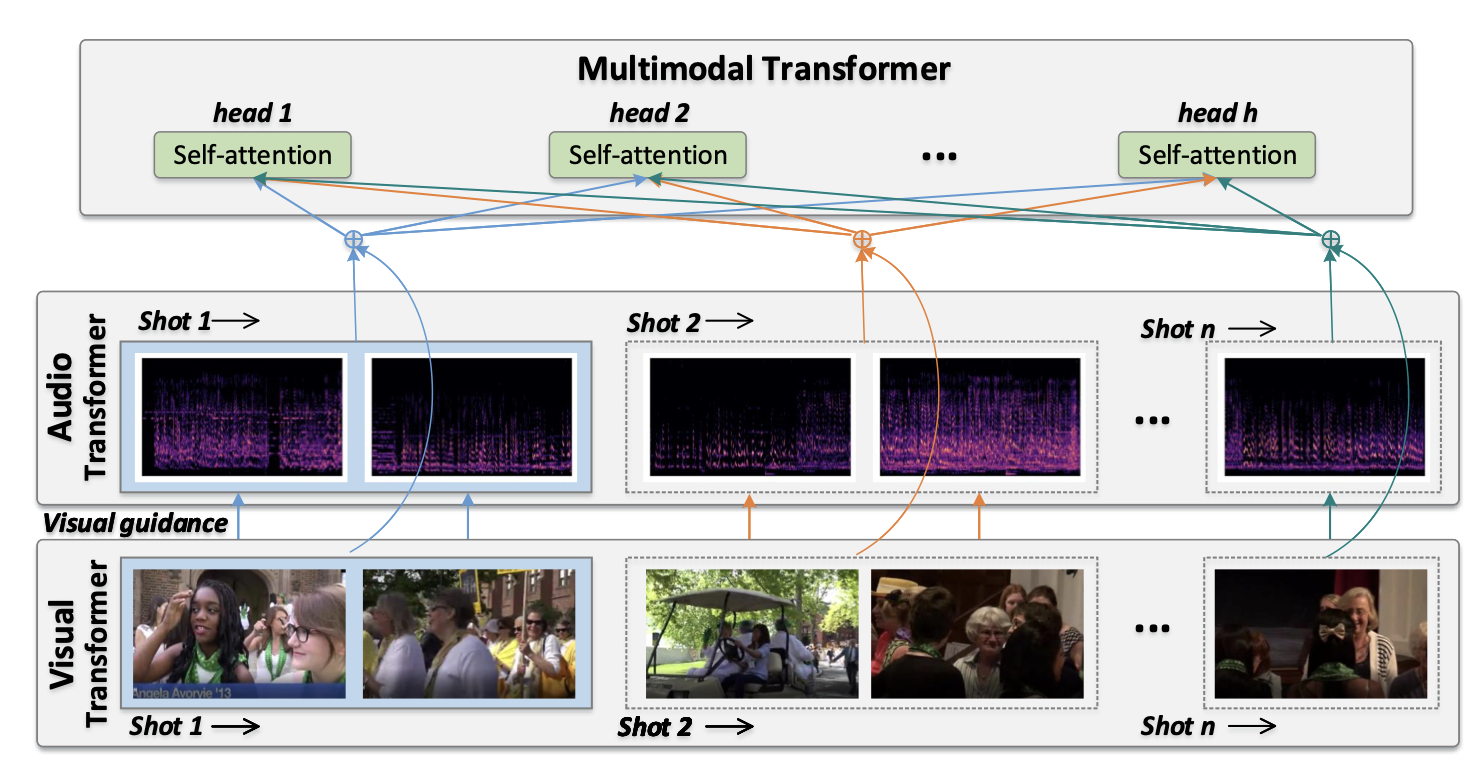
abstract
- 트랜스포머의 큰 성공과 비디오의 자연스러운 구조(프레임-샷-비디오)에 동기를 얻어,
- 프레임과 샷 간의 의존성을 포착하고, 샷에 의해 형성된 장면 정보를 활용하여 비디오를 요약할 수 있는 계층적 트랜스포머가 개발.
- 시각적 정보와 오디오 정보를 통합하기 위해, 두 스트림 체계로 인코딩되고,
- 계층적 트랜스포머를 기반으로 한 다중모달 융합 메커니즘이 개발.
Align and Attend: Multimodal Summarization with Dual Contrastive Losses
- 2023 CVPR
- 9회 인용
- paper: https://arxiv.org/pdf/2303.07284.pdf
- code: https://arxiv.org/pdf/2303.07284.pdf
그림
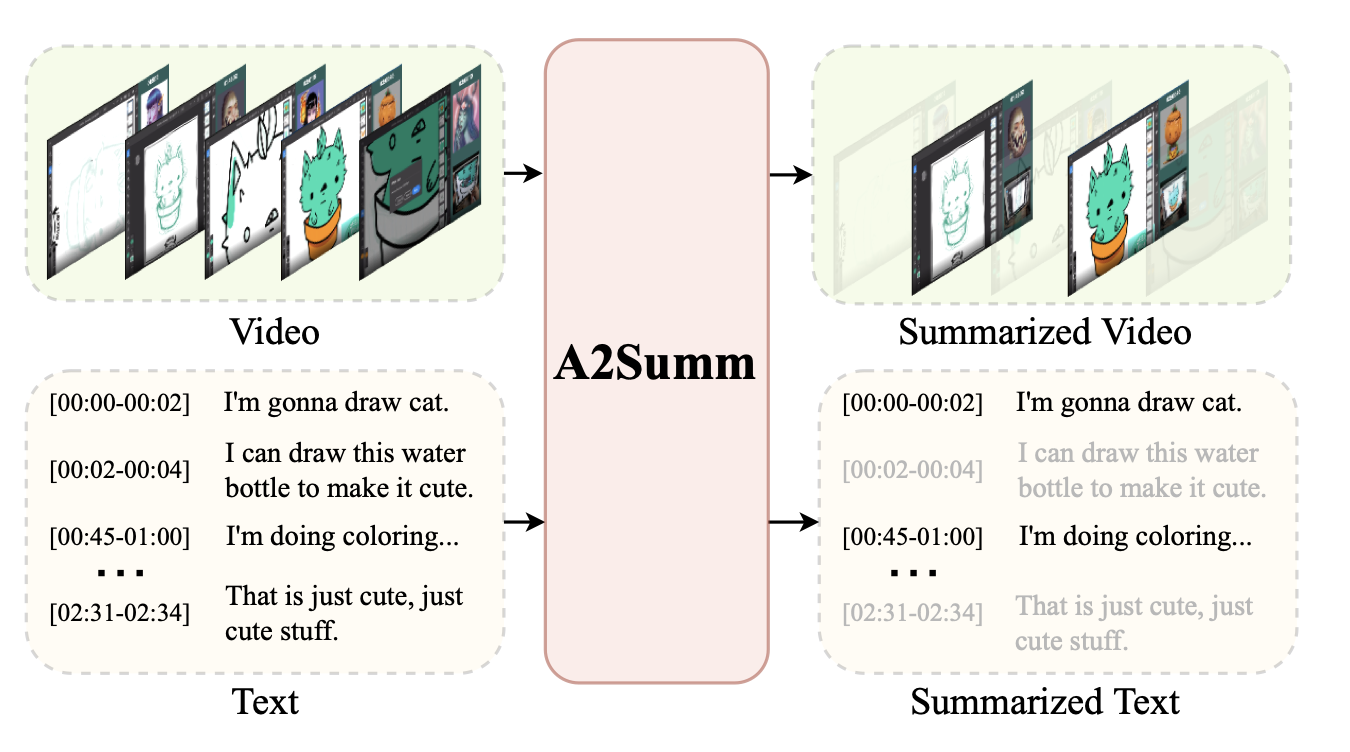
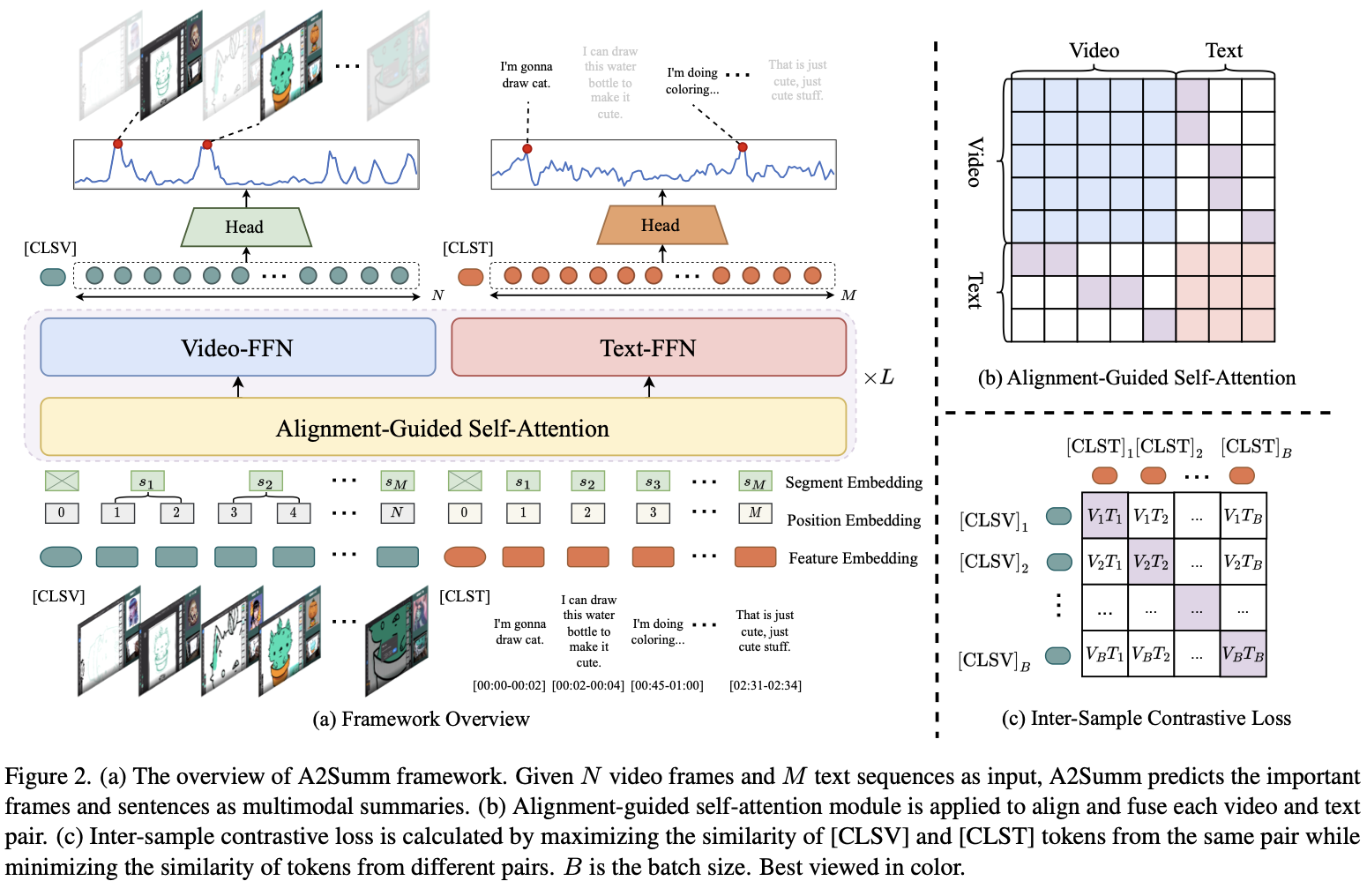
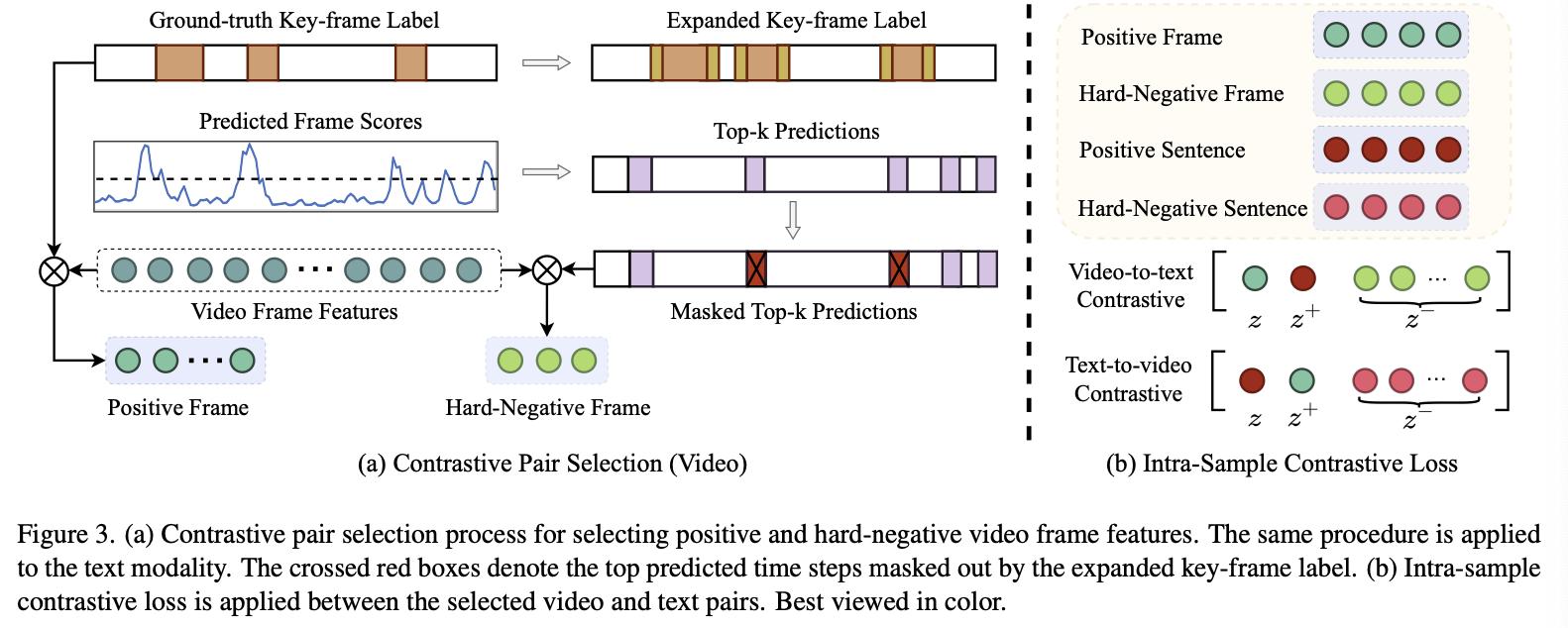
abstract
- 기존의 방법들은 다양한 모달리티 간의 시간적 일치를 활용하지 못하고, 서로 다른 샘플 간의 본질적인 상관관계를 무시
- 이를 해결하기 위해,
다양한 멀티모달 입력을 효과적으로 정렬하고 주목할 수 있는 통합된 멀티모달 트랜스포머 기반 모델제안 샘플 간 및 샘플 내 상관관계를 모델링하기 위한 두 가지 새로운 대조 손실을 제안
Combining Global and Local Attention with Positional Encoding for Video Summarization
- 2021
- 40회 인용
- 논문: https://www.iti.gr/~bmezaris/publications/ism2021a_preprint.pdf
- 코드: https://github.com/e-apostolidis/PGL-SUM
그림
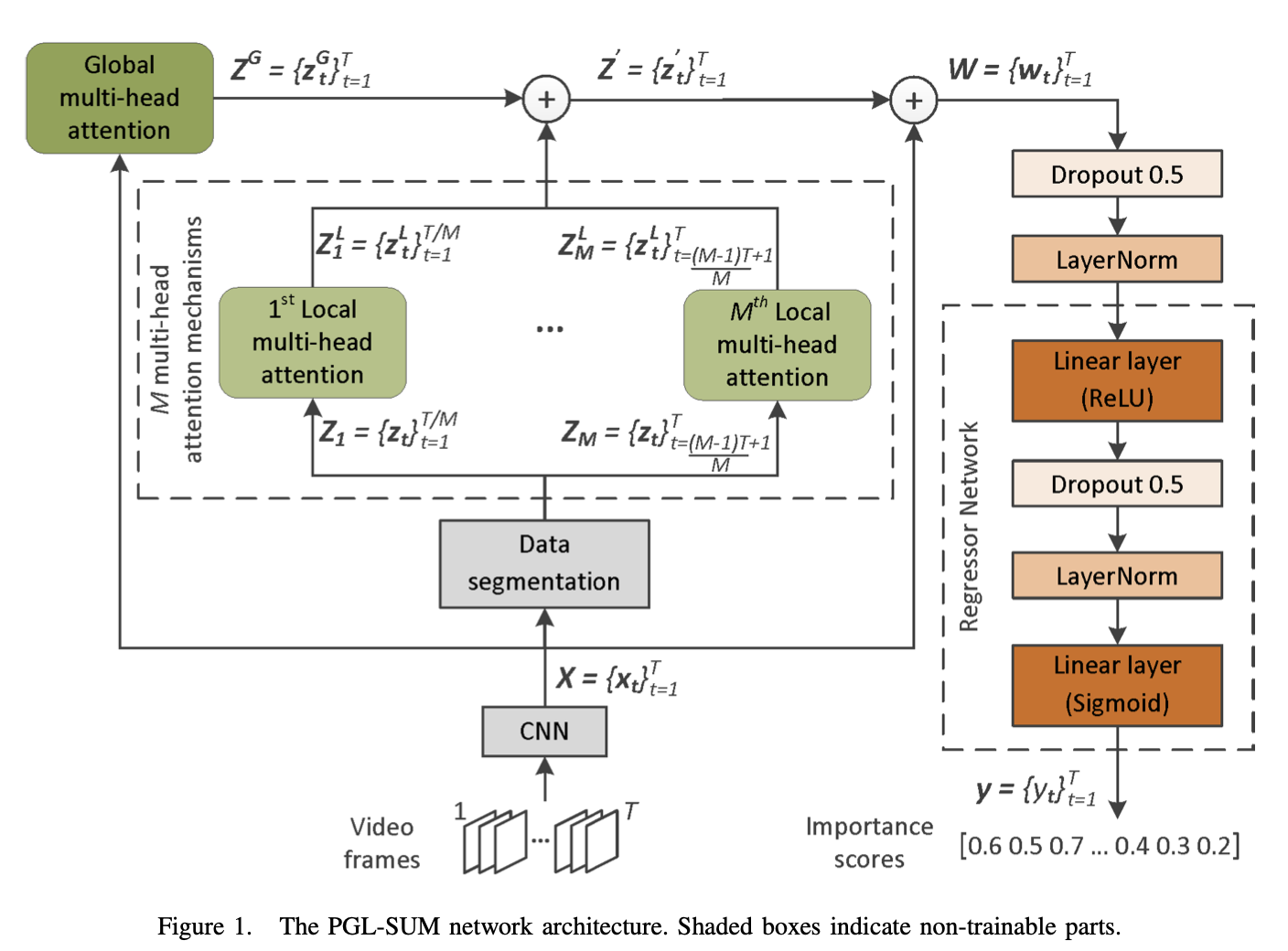
abstract
- supervised video summarization
- 주의 기반 요약 접근 방식들이 전체 프레임 시퀀스를 관찰함으로써 프레임의 의존성을 모델링하는 것과는 달리,
- 우리의 방법은
전역 및 지역 멀티-헤드 주의 메커니즘을 결합하여다양한 세분성 수준에서 프레임 의존성의 다른 모델링을 발견 - 사용된 주의 메커니즘은 비디오 요약을 생성할 때 중요한 비디오 프레임의 시간적 위치를 인코딩하는 구성 요소를 통합.
Video Summarization through Reinforcement Learning with a 3D Spatio-Temporal U-Net
- 2022
- 44회 인용
- paper: https://arxiv.org/pdf/2106.10528.pdf
그림
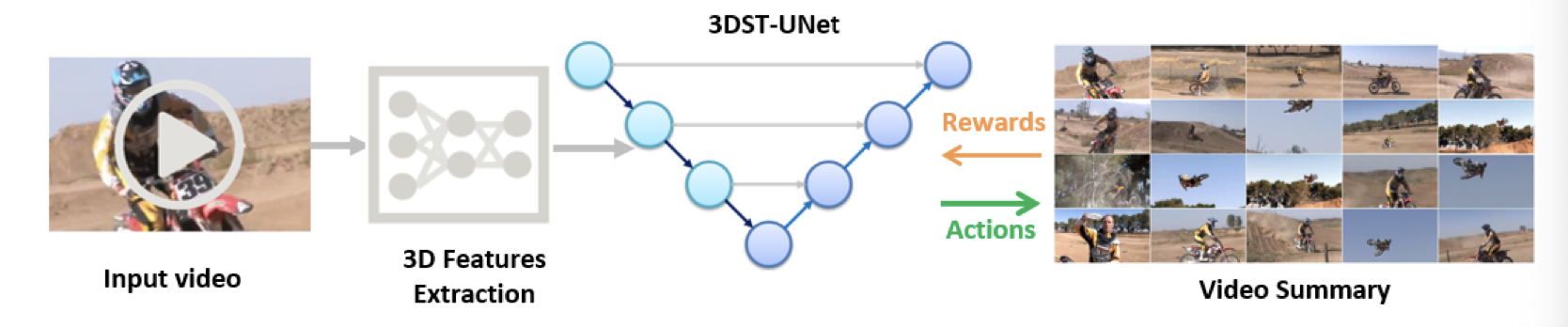
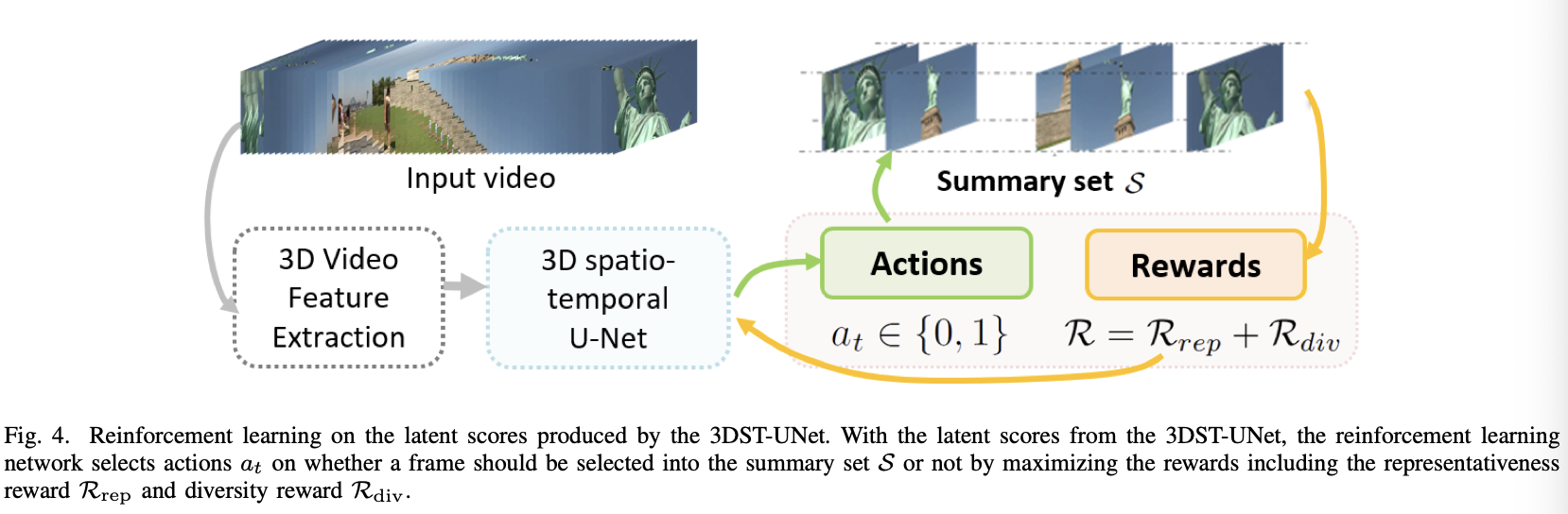
abstract

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것