[영진닷컴 X BDA 빅분기 실기 스터디] 1주차
[1유형] 데이터 전처리 학습 (교재 64p ~ 99p)
[2유형] 데이터 분석 - 빅데이터 분석 과정 학습 (교재 102p ~ 111p)
과제
- 1주차 학습 내용 업로드
- 모의고사 1회 문제의 제1유형 문제 풀이 (교재 222p)
https://github.com/hscrown/bigdata/blob/main/%EB%AA%A8%EC%9D%98%EA%B3%A0%EC%82%AC_1%ED%9A%8C_1%EC%9C%A0%ED%98%95.ipynb- 모의고사 2회 문제의 제1유형 문제 풀이 (교재 236p)
https://github.com/hscrown/bigdata/blob/main/%EB%AA%A8%EC%9D%98%EA%B3%A0%EC%82%AC_2%ED%9A%8C_1%EC%9C%A0%ED%98%95.ipynb
[1유형] 데이터 전처리 학습
01. 데이터 전처리 탐색
1) EDA
-
EDA란? 수집한 데이터를 다양한 방법을 통해서 자료를 관찰하고 이해하는 과정. 데이터 분석 전에 자료를 직관적으로 통찰하는 과정
- EDA 방법: 요약정보, 기초통계, 시각화
- EDA 필요성: 문제점 발견, 새로운 양상이나 패턴 발견, 초기 가설 수정 또는 새로운 가설 설립 가능 -
분석 과정 및 절차:
분석 목적과 변수 확인 > 문제성(결측치,이상치) 확인 > 분포 확인(head나 tail) > 데이터 개별 속성값의 분포 확인(기초통계량) 이용 > 데이터 사이 관계 확인(상관관계 등) -
결측치와 이상치 처리:
결측치 확인(관찰,함수사용,상관관계) | 대치(단순대치,다중대치)
이상치 확인(관찰,통계값,시각화,ML기법) | 처리(제거,대체,유지) -
속성 분포값 확인:
통계지표:
중심 - 평균,중앙값,최빈값
분산 - 범위, 분산, 표준편차, 사분위범위(IQR) 활용
시각화:
확률밀도함수, 히스토그램, 박스플롯, 산점도, WC, 시계열차트, 지도 등 -
데이터 속성관 관계파악: 상관관계분석(선형적관계가 있냐 없냐)
2) 데이터탐색
- 타이타닉 데이터 탐색
# 데이터 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 데이터 불러오기
df = pd.read_csv("titanic.csv")
# 데이터 프레임 살펴보기
df
df.info() # 데이터 셋 전체 구조와 특징, 변수 타입, 변수 개수, 전체 관측치(count)
df.head(10)
df.describe(include='all') # 기초 통계량 # 범주형 변수(unique,top,freq) 포함
df.describe() 숫자형 변수만 통계와 분포
# 변수 타입 변환
## 변수 Survived와 PClass는 숫자(int64) ➡️ object 타입으로 변환한다
## 범주형 데이터로 처리하기 위함
df['Survived'] = df['Survived'].astype(str) # 사망자 0 , 생존자 1
df['PClass'] = df['PClass'].astype(str) # 1 1등급 객실 2 2등급 3 3등급
# PClass 분석 - 어느 등급에 손님이 많이 탔나
grouped = df.groupby("PClass")
grouped.size()
# Fare 시각화하기
## Histogram
plt.hist(df['Fare'])
plt.show()
## 데이터 분리
fare0 = df[df['Survived']==0]['Fare'] # 사망자의 요금 데이터
fare1 = df[df['Survived']==1]['Fare'] # 생존자 요금 데이터
## boxplot 그리기 - Survived 값에 따른 Fare 분포
fig, ax = plt.subplots()
ax.boxplot([fare0,fare1])
plt.show()
# Sex 변수
## male 또는 female의 범주형 피처
## 빈도수 계산
grouped = df.groupby("Sex")
grouped.size()
## 성별 생존자 수
df_male = df[df["Sex"]=="male"]
grouped = df_male.groupby("Survived")
print(grouped.size())
# 여성 데이터를 필터링하고, 'Survived' 기준으로 그룹화하여 크기를 확인
df_female = df[df["Sex"] == "female"]
grouped = df_female.groupby("Survived")
print(grouped.size())02 데이터 전처리 개요
-
데이터 전처리 = 데이터 가공(manipulation) = 데이터 핸들링(handling) = 데이터 클리닝(cleaning)
-
데이터 전처리란? 원시적인 형태의 데이터를 내가 원하는 형태로 변환하는 과정, 작업
-
데이터 전처리의 필요성: 데이터를 분석하기 좋게 오류를 걸러내고 바꿈
-
데이터 전처리 예시
처리하기 편하게 문자로된 범주형 데이터를 수자로 표현
데이터 인코딩(월요일은 1, 화요일은 2...)
수치데이터 분포 정규화
분표 변환 -
데이터 전처리 형태:
데이터 필터링(filtering) - 필요한 데이터만 추출
데이터 변환(transformation) - 데이터 형식 변경
데이터 통합(intergration) - 여러 소스에서 온 데이터를 합친다. -
결측치 처리 방법 3가지
삭제
대체(평균값,인접한 값 등등)
NaN으로 표시하여 다음 분석단계에서 처리
주의* 급여데이터는 평균치나 0으로 대체하면 안됨. 데이터의 특성에 따라 처리하자.
-
틀린(invalid)값 처리 방법
삭제
대체
분석 단계로 넘김 -
이상치(outlier)처리
값이 범위가 일반적인 범위를 벗어난 값
이상치 검출(detection) 이라고 함. -
데이터 변환 : 데이터를 분석하기 좋은 형태로 바꾸는 작업
- 수치데이터를 범주형으로 변환 (출생년도를 10,20,30대로...)
- 일반 정규화(8/10점만점인 영어점수와 20/50점 만점인 수학점수 > 각각 0.8점, 0.4점으로 정규화)
- Z-Score 정규화
- Z-Score transfrom 이용
- 평균을 0으로 표준편차를 1로
- 로그 변환:어떤 - 수치 값에 로그를 취한 값 사용
- 데이터에 로그를 취하면 그 분포가 정규분포에 가깝게 변환됨(로그정규분포)
- 국가별 수출액 분포 그래프, 값이 범위가 너무 큰 경우, 숫자의 증가가 덧셈보다 곱셈으로처리하기 편한 경우
- 역수 변환:어떤 변수를 역수를 사용하면 선형적인 특정을 가지게 되어 의미를 해석하기 쉬워지는 경우
- 데이터 축소(reduction):같은 정보량을 가지면서 데이터의 크기를 줄임
- 데이터 축소의 예로 PCA가 있음. 기존 데이터의 특징을들 대표하는 새로운 값을 추출
- 몸무게와 허리둘레가 같은 패턴이면 허리둘레 하나만 사용
- 여러 데이터를 대표하는 새로운 변수를 만들 수도 있음.
- 샘플링:구한 전체데이터 중 분석에 필요한 데이터만 취하는 것.
- 분석의 타당성을 조사하거나 분석 모델의 큰 방향을 정할때도 필요
- 샘플링된 데이터가 전체 데이터의 특징을 계속 유지하는 것이 중요
- 여러 측면에서 고르게 샘플링하기
- 훈련 데이터와 테스트 데이터
- 데어터 분석의 두 단계 : 모델을 만드는 과정(훈련,training)과 모델을 검증하는 과정(test)
- 데이터도 훈련단계에서 사용하는 training data와 test data(hold-out data)로 나뉨
- 데이터를 준비할때 중요한점 > 랜덤한 성질을 보장
- 변수를 별도로 하나 정하고 여기 랜덤한 숫자를 배정하는 방법 사용 가능
- 데이터 변환
- 데이터 스케일링:데이터의 범위가 같아지도록 변수별로 값을 비례적으로 조정하는 과정. 변수들의 측정단위나 값 범위가 다를 때 적용
표준정규화(표준화)
Min-Max 정규화
## 정규분표를 따르는 데이터 생성
## random.randn(n) 함수 사용: 평균0, 표준편차1을 갖는 난수 n개 생성
import numpy as np
import pandas as pd
data = np.random.randn(1000) ##평균이0 표준편차가 1인 표준정규분포
data2 = 5*np.random.randn(1000)+53.9 ## 표준편차가 5, 평균이 53.9 인 정규분포
## 히스토그램
hist(x,bins=10.range[10,10],label="title")
## x:데이터, bins:나눌 칸 수,range:표시할 값의 범위,label:범례
plt.hist(data)
plt.xlabel("한국인 육류 소비량")
plt.show()- Z-표준화
# Z-표준화 구현하는 3가지:numpy,scipy,sklearn
## df['중간점수'] 표준화하기
### numpy >> z=x-mean(x)) / std(x)
df['중간Z점수'] = (df['중간점수']-np.mean(df['중간점수']))/ np.std(df['중간점수'])
### scipy.stats 이용
import scipy.stats as ss
df['중간Z점수'] = ss.zscore(df['중간점수'])
### 사이킥런 스케일러 이용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['중간Z점수'] = scaler.fit_transform(df[['중간점수']])주의
사이킥런의 fit_transform 메서드는 numpy 배열이나 2차원 배열을 기대하기때문에 scaler.fit_transform(df[['중간점수']]) 와 같이 시리즈가 아닌 데이터프레임 형식으로 넣어야한다.
- MinMax 스케일링
# MinMax 스케일링 구현하는 2가지: numpy, sklearn
## df['중간점수'] MinMax 스케일링하기
### numpy 이용
min_val = np.min(df['중간점수'])
max_val = np.max(df['중간점수'])
df['중간MinMax'] = (df['중간점수'] - min_val) / (max_val - min_val)
### 사이킷런 스케일러 이용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['중간MinMax'] = scaler.fit_transform(df[['중간점수']])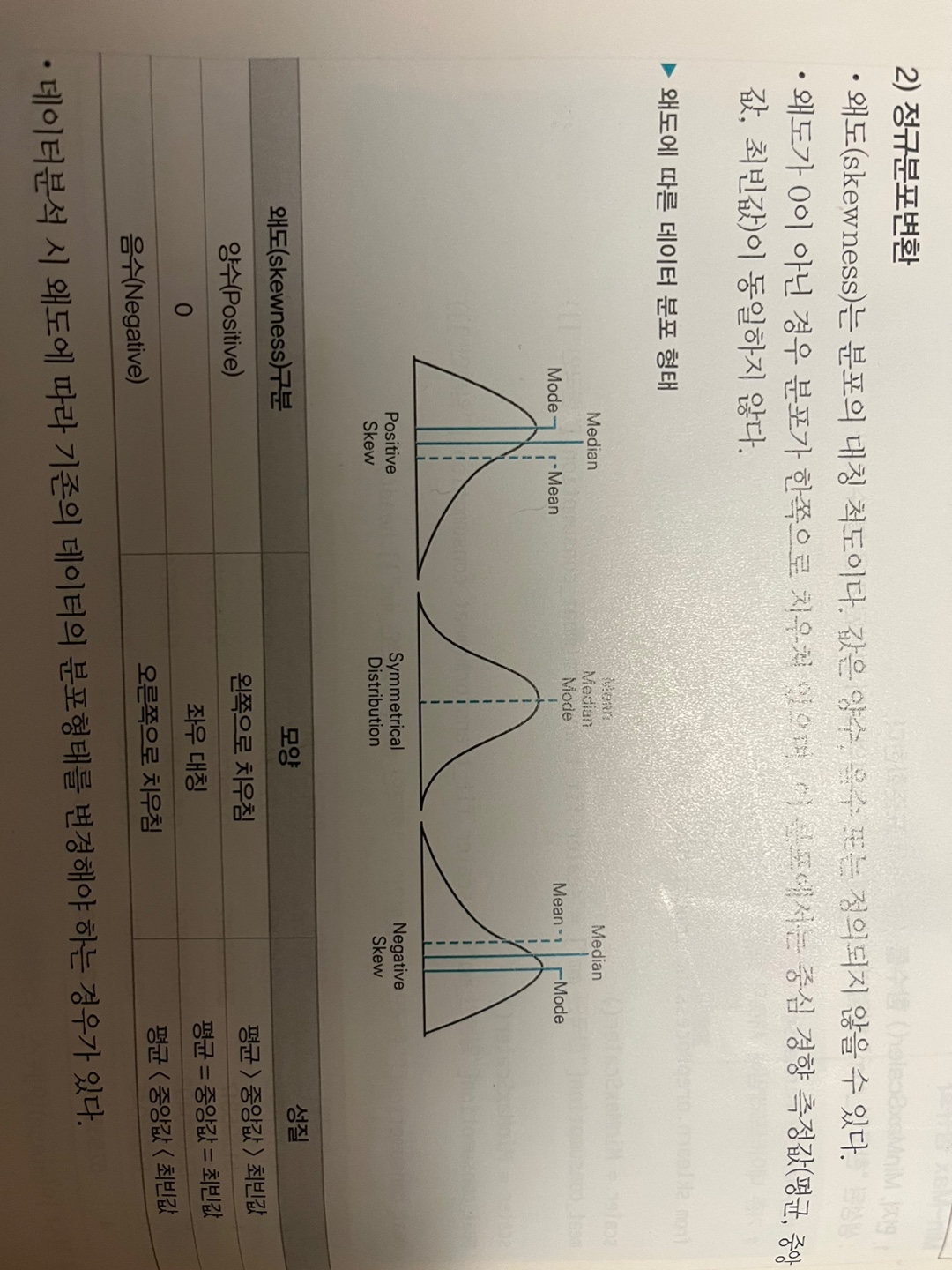
- 왜도(skewness)
- 분포의 대칭 척도
- 왜도가 0 : 평균=중앙값=최빈값
import scipy.stats as ss
# 특정 칼럼의 왜도 계산
print(ss.skew(df['CONT'])-
정규화 변환
- 독립변수의 값이 증가함에 따라 종속변수가 더 빠르게 변화하는 상황에서는 로그 변환을 시도
로그 변환을 사용할 때는 변환 전 모든 값을 양수로 만들기 위해 모든 값에 상수를 추가해야 한다.
- 독립변수의 값이 증가함에 따라 종속변수가 더 빠르게 변화하는 상황에서는 로그 변환을 시도
-
범주화, 이산형화
-
연속형 변수를 변수로 변환하는 작업
-
조건문, cut(). qcut() 등 사용
-
조건문 사용(시험 점수를 A,B,C,D,F로)
-
cut() : include_lowest는 각 구간의 낮은 경계값을 포함
pd.cut(x=데이터, bins=경계값리스트, labels=bin이름, include_lowest=True)
-
-
차원축소(PCA)
- 주성분 분석이란 여러 변수들의 변량을 주성분 이라고 불리는, 서로 상관성이 높은 여러 변수들의 선형 조합으로 만든 새로운 변수들로 요약, 축소하는 기법이다.
# iris 데이터로 PCA분석하기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris = pd.read_csv('iris.csv')
# 연속형 변수만 분리
df = iris.drop(['species'], axis=1)
# PCA분석 수행
## 변수간의 스케일 차이가 나면 표준화나 정규화 시켜준다.
## n_components는 PCA로 변환할 차원의 수를 의미한다. 변수가 4개일때 4개로 PCA분석을 수행하면 각 변수의 기여도를 살펴볼 수 있다.
## 각 변수의 기여도를 보고 최종으로 줄일 차원의 수를 설정할 수 있다. (기여도가 큰 변수만 남김)
