Deep Residual Learning for Image Recognition
Abstract
더 깊은 신경망은 훈련하기 어렵습니다. 우리는 이전보다 훨씬 더 깊은 네트워크 훈련을 용이하게 하기 위해 잔차 학습 프레임워크(residual learning framework)를 제시합니다. 기존의 층을 학습할 때 입력을 참고하지 않는 함수를 학습하는 대신, 층 입력을 참조하는 잔차 함수(residual functions)를 학습하도록 명시적으로 재구성했습니다. 이러한 잔차 네트워크가 최적화하기 쉬우며 깊이가 크게 증가해도 정확도가 향상된다는 종합적인 실험적 증거를 제공합니다. 우리는 ImageNet 데이터셋에서 깊이 152층에 달하는 잔차 네트워크를 평가했으며, 이는 VGG 네트워크보다 8배 더 깊지만 복잡성은 더 낮습니다. 이러한 잔차 네트워크 앙상블은 ImageNet 테스트 세트에서 3.57% 오류율을 기록했으며, 이 결과는 ILSVRC 2015 분류 작업에서 1위를 차지했습니다. 또한, CIFAR-10 데이터셋에서 깊이 100층과 1000층을 가지는 네트워크에 대한 분석을 제시합니다.
표현의 깊이는 많은 시각 인식 작업에서 매우 중요한 요소입니다. 우리의 매우 깊은 표현만으로 COCO 객체 탐지 데이터셋에서 상대적으로 28%의 성능 향상을 달성했습니다. 깊은 잔차 네트워크는 ILSVRC & COCO 2015 대회 제출작의 토대가 되었으며, 여기서 ImageNet 탐지, ImageNet 위치 지정, COCO 탐지 및 COCO 분할 작업에서 1위를 차지했습니다.
1. Introduction
깊은 합성곱 신경망(Convolutional Neural Networks, CNN)은 이미지 분류에서 중요한 돌파구를 이끌어냈습니다 [LeCun et al., Krizhevsky et al.]. 이러한 깊은 네트워크는 저/중/고수준의 특징을 [Zeiler and Fergus] 층을 쌓아가며 통합하는 특성이 있으며, 층의 깊이에 따라 특징의 "레벨"을 더욱 풍부하게 할 수 있습니다. 최근 연구들은 네트워크의 깊이가 매우 중요하다는 것을 밝혀냈으며, ImageNet 데이터셋에서 우수한 성능을 기록한 모델들은 모두 깊이 16~30층의 "매우 깊은" 구조를 활용했습니다 [VGG 논문, Szegedy et al., He et al.]. 또한, 복잡한 시각 인식 작업에서도 매우 깊은 모델이 큰 이점을 제공했습니다 [Girshick et al., He et al.].
네트워크의 깊이의 중요성에 따라, 자연스레 떠오르는 질문은 더 나은 네트워크 학습이 단순히 더 많은 층을 쌓는 것으로 가능한가입니다. 그러나 이를 해결하는 데는 소위 기울기 소실/폭발 문제(vanishing/exploding gradients) [Bengio et al., Glorot and Bengio]라는 문제가 있었으며, 이는 네트워크가 수렴하지 못하게 했습니다. 하지만 이는 정규화된 초기화 [LeCun et al., Glorot and Bengio, Saxe et al., He et al.]와 중간 정규화 층(Batch Normalization) [Ioffe and Szegedy]으로 인해 대부분 해결되어, 깊은 네트워크들이 확률적 경사 하강법(SGD)과 역전파로 수렴할 수 있게 되었습니다 [LeCun et al.].
그러나 더 깊은 네트워크가 수렴하기 시작하면서 성능 저하 문제(degradation problem)가 나타났습니다: 네트워크의 깊이가 증가함에 따라 정확도가 포화 상태에 도달하고, 예상치 못하게도 정확도가 급격히 떨어지게 됩니다. 이는 과적합(overfitting) 때문이 아니며, 오히려 층을 더 추가할수록 학습 오류가 증가하는 현상이 나타났습니다 [He and Sun, Srivastava et al.].
이 논문에서는 이러한 성능 저하 문제를 해결하기 위해 잔차 학습(residual learning) 프레임워크를 도입합니다. 우리는 각 층이 단순히 목표한 함수를 직접 학습하는 대신, 잔차 함수를 학습하도록 합니다. 이를 수식으로 나타내면, 원하는 함수 H(x)에 대해 각 층이 F(x) := H(x) - x를 학습하게 하고, 이를 통해 원래 함수는 F(x) + x로 재구성됩니다. 이러한 방식은 잔차 함수를 최적화하는 것이 원래 함수를 최적화하는 것보다 더 쉽다는 가정을 기반으로 합니다.
이 잔차 함수 F(x) + x는 단축 연결(shortcut connections)을 활용하여 구현할 수 있으며 [Bishop, Ripley, Venables and Ripley], 이는 일부 층을 건너뛰어 학습하는 구조입니다. 이 경우 단축 연결은 추가적인 파라미터나 계산 복잡도를 증가시키지 않으며, 일반적인 라이브러리(e.g., Caffe)에서도 쉽게 구현할 수 있습니다 [Jia et al.].
우리는 ImageNet 데이터셋을 통해 성능 저하 문제를 분석하고, 제안한 방법을 평가하는 종합적인 실험을 제시합니다 [ImageNet 논문]. 결과는 다음과 같습니다: 1) 매우 깊은 잔차 네트워크는 최적화가 용이하지만, 단순히 층을 쌓은 “plain” 네트워크는 깊이가 증가할수록 학습 오류가 더 높게 나타납니다. 2) 잔차 네트워크는 깊이를 크게 증가시켜도 높은 정확도를 쉽게 얻을 수 있으며, 이전 네트워크들보다 훨씬 우수한 성능을 보입니다.
유사한 현상은 CIFAR-10 데이터셋에서도 나타나며, 최적화의 어려움과 제안 방법의 효과가 특정 데이터셋에 국한되지 않음을 시사합니다 [CIFAR-10 논문]. 이 데이터셋에서 우리는 100개의 레이어 이상의 모델을 성공적으로 훈련했으며, 1000개의 레이어 이상의 모델도 탐구했습니다.
ImageNet 분류 데이터셋에서, 우리는 152개의 레이어를 가진 잔차 네트워크로 뛰어난 성능을 달성했습니다. 이는 ImageNet에서 발표된 가장 깊은 네트워크이며, 여전히 VGG 네트워크보다 복잡도가 낮습니다 [VGG 논문]. 이 네트워크의 앙상블은 ImageNet 테스트 세트에서 3.57%의 top-5 오류율을 기록하여 ILSVRC 2015 분류 대회에서 1위를 차지했습니다. 이처럼 매우 깊은 표현은 다른 인식 작업에서도 뛰어난 일반화 성능을 보이며, ImageNet 탐지, ImageNet 위치 지정, COCO 탐지, COCO 분할 등 ILSVRC 및 COCO 2015 대회에서 1위를 차지하게 해 주었습니다. 이러한 강력한 증거는 잔차 학습 원칙이 범용적임을 보여주며, 이는 컴퓨터 비전 문제와 그 외의 문제에도 적용될 수 있을 것으로 예상합니다.
2. Related Work
Residual Representations: 이미지 인식에서는 VLAD라는 방법 [Jégou et al.]이 자주 사용됩니다. 이 방법은 이미지 속 특징들을 미리 만들어 둔 “사전(dictionary)”과 비교해 차이(잔차)를 계산해 기록합니다. 여기서 사전은 기준이 되는 여러 지점들의 모음입니다. 이미지 속 특징들이 사전의 각 기준점들과 얼마나 다른지를 잔차 벡터로 기록하는 것이죠. Fisher Vector라는 또 다른 방법 [Perronnin and Dance]은 VLAD를 좀 더 확장한 것으로, 확률 개념을 사용해 정보를 표현합니다. 이 두 방법 모두 이미지 검색과 분류 작업에서 성능이 좋은 간단한 표현 방식으로 널리 쓰이고 있습니다 [Chatfield et al., Vedaldi and Fulkerson].
또한, 벡터 양자화(vector quantization) 과정에서 원래 벡터 대신 잔차 벡터를 사용해 정보를 기록하는 것이 더 효과적이라는 연구 결과도 있습니다 [Jégou et al.]. 이는 원래의 벡터 대신 사전과의 차이만 기록하는 것이 성능 면에서 유리하다는 것을 의미합니다.
이미지 처리와 컴퓨터 그래픽스 분야에서는 Multigrid라는 방법 [Briggs and McCormick]이 복잡한 수학 문제를 여러 단계로 나누어 해결하는 데 자주 사용됩니다. 이 방법은 문제를 더 큰 스케일에서 먼저 대략적으로 풀고, 점점 더 작은 세부 사항으로 들어가면서 남은 차이(잔차)를 조정하는 방식입니다. 마치 큰 그림을 먼저 맞춘 후 점차 세밀한 부분을 맞춰 나가는 것과 비슷합니다. 계층적 기저 전처리(hierarchical basis preconditioning) [Szeliski]라는 방법도 있으며, 이 역시 스케일 간 남은 차이를 이용해 문제를 점진적으로 해결하는 방식입니다.
연구에 따르면, 문제를 여러 단계로 나누고 잔차를 고려해가며 해결하는 방식이, 복잡한 문제를 더 빠르고 쉽게 해결하는 데 유리하다는 것을 보여줍니다.
Shortcut Connections:
Shortcut Connections의 개념은 오랫동안 연구되어 왔습니다 [Bishop, Ripley, Venables and Ripley]. 초기 다층 퍼셉트론(MLP) 학습 방법 중 하나로, 네트워크의 입력에서 출력으로 직접 연결된 선형 레이어를 추가하는 방식이 있었습니다 [Ripley, Venables and Ripley]. 또한, 사라지는 기울기/폭발하는 기울기 문제를 해결하기 위해, 중간 층을 보조 분류기와 직접 연결하는 방법이 제안되기도 했습니다 [Szegedy et al., Lee et al.]. 다른 연구에서는 레이어의 출력값, 기울기, 역전파 오류를 중심으로 맞추는 방법을 Shortcut Connections를 통해 구현하기도 했습니다 [Schraudolph 1998, Schraudolph 1998, Raiko et al., Vatanen et al.].
Szegedy et al.의 “인셉션” 층은 Shortcut Connection을 포함한 간단한 가지(branch)와 더 깊은 가지들로 구성되어 있습니다 [Szegedy et al.].
이와 동시에 진행된 연구로, 하이웨이 네트워크(highway networks) [Srivastava et al.]는 게이트 함수(gating functions)를 사용하는 Shortcut Connections를 도입했습니다 [Hochreiter and Schmidhuber]. 하이웨이 네트워크의 게이트는 데이터에 따라 열리거나 닫히며, 이를 조절하는 파라미터를 포함합니다. 반면, 우리의 identity Shortcut Connections는 파라미터 없이 항상 열려 있어 모든 정보가 통과하며, 추가적인 잔차 함수만 학습합니다. 게이트가 “닫히면”(0에 가까워지면) 하이웨이 네트워크의 레이어는 잔차 함수가 아닌 일반 함수를 학습하게 됩니다. 반대로, 우리의 방식에서는 항상 잔차 함수만 학습하며, 정보가 항상 통과되도록 되어 있습니다.
또한, 하이웨이 네트워크는 층의 깊이를 크게 늘렸을 때(예: 100개 이상의 레이어) 정확도가 향상되는 것을 보여주지 못했습니다.
3. Deep Residual Learning
3.1. Residual Learning
잔차 학습(residual learning)을 이해하기 위해, 먼저 목표로 하는 함수를 생각해보겠습니다. 여기서 H(x)는 네트워크의 몇 개 층이 학습해야 하는 목표 함수라고 할 수 있고, x는 그 층들이 받는 입력 값입니다. 이때 네트워크의 여러 층이 함께 작용해 복잡한 함수를 근사할 수 있다고 가정해봅시다. 만약 여러 층이 함께 원래의 목표 함수 H(x)를 근사하기 어렵다면, 잔차 함수(residual function)라는 개념을 사용해 문제를 조금 더 쉽게 만들 수 있습니다.
잔차 함수는 목표 함수와 입력값의 차이(잔차)를 나타내는 함수입니다. 예를 들어, 우리가 H(x) - x를 잔차 함수로 두고, 네트워크가 이 차이만 근사하도록 만드는 것입니다. 이를 통해 네트워크가 학습할 함수는 F(x) := H(x) - x가 되며, 이렇게 되면 원래의 목표 함수는 F(x) + x로 나타낼 수 있습니다. 즉, 층들이 직접 H(x)를 학습하는 대신, 목표 값과 입력 값의 차이인 잔차만 학습하게 됩니다. 이렇게 하면 학습이 더 쉬워질 수 있습니다.
이 방식은 성능 저하 문제(degradation problem)에서 영감을 얻은 것입니다 (그림 1, 왼쪽). 앞서 설명한 것처럼, 층을 추가하면 더 깊은 네트워크가 만들어지지만, 만약 추가된 층들이 아무런 변화를 주지 않고 항등 함수(identity function)처럼 입력을 그대로 출력한다면, 더 깊은 모델의 성능은 얕은 모델보다 나빠지지 않아야 합니다. 그러나 실제로는, 더 깊은 네트워크가 항등 함수처럼 입력을 그대로 출력하는 데 어려움을 겪는 경우가 많아 성능이 저하되는 문제가 발생합니다.
잔차 학습(reformulation) 방식에서는, 항등 함수가 최적의 답이라고 가정할 때, 네트워크가 여러 층의 가중치를 0에 가깝게 만들어 항등 함수에 가까워질 수 있습니다.
실제 상황에서는 항등 함수가 최적의 답이 아닐 가능성이 높지만, 이 방식은 문제를 사전 조정(preconditioning)하는 데 도움이 됩니다. 만약 목표 함수가 0에 가까운 함수보다는 항등 함수에 더 가깝다면, 네트워크가 완전히 새로운 함수를 학습하는 것보다 항등 함수에서 약간의 변화를 주는 것이 더 쉬울 수 있습니다. 실험 결과(그림 7)에서도 알 수 있듯이, 학습된 잔차 함수의 출력값은 대체로 작게 나타나며, 이는 항등 함수가 학습을 위한 좋은 출발점이 될 수 있음을 시사합니다.
3.2. Identity Mapping by Shortcuts
우리는 몇 개의 층마다 잔차 학습(residual learning)을 적용합니다. 하나의 빌딩 블록(building block)이 그림 2에 나와 있습니다. 수식으로 나타내면, 이 빌딩 블록은 다음과 같이 정의됩니다:
여기서 와 는 해당 층들의 입력 벡터와 출력 벡터입니다. 함수 는 학습해야 하는 잔차 함수를 나타냅니다. 예를 들어, 그림 2의 두 개 층으로 이루어진 경우 로 표현되며, 여기서 는 ReLU 활성화 함수입니다 [Nair and Hinton]. 표기를 단순화하기 위해 바이어스 항은 생략했습니다. 연산은 Shortcut Connection과 요소별 덧셈을 통해 수행됩니다. 덧셈 후에 두 번째 활성화 함수(예: )를 적용합니다 (그림 2 참고).
식 (1)에 있는 Shortcut Connections는 추가적인 파라미터나 계산 복잡도를 증가시키지 않습니다. 이는 실용적인 면에서도 매력적일 뿐만 아니라, plain 네트워크와 residual 네트워크를 공정하게 비교하는 데도 중요한 요소입니다. 이 방식으로 파라미터 수, 깊이, 너비, 계산 비용(무시할 수 있는 정도의 요소별 덧셈 제외)을 동일하게 맞춰서 비교할 수 있습니다.
식 (1)에서 와 의 차원이 같아야 합니다. 만약 그렇지 않은 경우(예: 입력과 출력 채널이 다를 때), Shortcut Connection에서 선형 사영(linear projection) 를 통해 차원을 맞출 수 있습니다:
식 (1)에서 를 정방 행렬(square matrix)로 사용할 수도 있지만, 실험 결과 항등 맵(identity mapping)만으로도 성능 저하 문제를 해결하는 데 충분하고 효율적이라는 것을 보여줍니다. 따라서 는 차원을 맞출 때만 사용합니다.
잔차 함수 의 형태는 유연합니다. 본 논문의 실험에서는 두 개 또는 세 개 층으로 이루어진 를 사용했으며 (그림 5 참고), 더 많은 층도 가능합니다. 하지만 가 단일 층으로만 이루어진 경우 식 (1)은 선형 층 와 유사해지며, 이 경우의 장점은 관찰되지 않았습니다.
또한, 위의 표기는 간단히 설명하기 위해 완전 연결 층(fully-connected layer)을 기준으로 했지만, 합성곱 층에도 적용할 수 있습니다. 함수 는 여러 합성곱 층을 나타낼 수 있으며, 요소별 덧셈은 채널별로 수행됩니다.
3.3. Network Architectures
우리는 여러 가지 plain 네트워크와 residual 네트워크를 테스트한 결과, 일관된 현상을 관찰했습니다. 논의를 위해 ImageNet 데이터셋에 사용된 두 가지 모델을 다음과 같이 설명합니다.
Plain Network: 우리의 plain 네트워크 기준 모델(Fig. 3, 중간)은 VGG 네트워크 [VGG 논문] (Fig. 3, 왼쪽)의 철학에서 주로 영감을 받았습니다. 합성곱 층은 대부분 3x3 필터를 사용하며, 두 가지 간단한 설계 규칙을 따릅니다: (i) 동일한 출력 특징 맵 크기에서는 동일한 수의 필터를 사용하고, (ii) 특징 맵 크기가 절반으로 줄어들면 필터 수를 두 배로 늘려 층당 시간 복잡도를 유지합니다. 다운샘플링은 스트라이드(stride)가 2인 합성곱 층을 통해 직접 수행합니다. 네트워크는 글로벌 평균 풀링(global average pooling) 층과 소프트맥스(softmax) 함수를 갖춘 1000차원 완전 연결 층으로 끝납니다. 가중치가 있는 층의 총 수는 Fig. 3(중간)에서 34개입니다.
주목할 점은, 우리의 모델이 VGG 네트워크 [VGG 논문] (Fig. 3, 왼쪽)보다 필터 수가 적고 복잡도가 낮다는 것입니다. 우리의 34층 기준 모델은 36억 FLOP(곱셈-덧셈 연산)를 가지며, 이는 VGG-19의 196억 FLOP 중 18%에 불과합니다.
Residual Network: 위에서 설명한 plain 네트워크를 기반으로 Shortcut Connection을 추가하여 (Fig. 3, 오른쪽) 해당 네트워크를 residual 네트워크로 변환합니다. 입력과 출력의 차원이 동일한 경우에는 (식 (1)의 항등 맵(Identity Shortcut)) 직접 연결을 사용할 수 있습니다 (Fig. 3의 실선으로 표시된 shortcut). 반면에, 차원이 증가하는 경우(Fig. 3의 점선으로 표시된 shortcut) 두 가지 옵션을 고려합니다:
- 옵션 A: Shortcut이 항등 맵을 수행하되, 차원을 늘리기 위해 추가 0을 채워 넣는 방식입니다. 이 옵션은 추가 파라미터를 필요로 하지 않습니다.
- 옵션 B: 차원을 맞추기 위해 식 (2)의 사영 Shortcut을 사용합니다 (1x1 합성곱을 통해 수행됩니다).
두 가지 옵션 모두, Shortcut이 두 가지 다른 크기의 특징 맵을 가로지르는 경우 stride를 2로 설정하여 적용합니다.
3.4. Implementation
ImageNet에 대한 구현은 [He et al., Simonyan and Zisserman]의 방식을 따릅니다. 이미지는 짧은 변의 길이가 [256; 480] 사이에서 무작위로 선택된 크기로 조정되며, 이를 통해 스케일 증대(scale augmentation)를 수행합니다 [Simonyan and Zisserman]. 이후 224x224 크기의 영역을 이미지나 수평 반전 이미지에서 무작위로 선택하여 잘라내고, 픽셀별 평균 값을 빼줍니다 [Krizhevsky et al.]. 색상 증대는 [Krizhevsky et al.]의 표준 방식을 사용합니다. 각 합성곱 뒤와 활성화 함수 적용 전에 배치 정규화(batch normalization, BN) [Ioffe and Szegedy]를 적용하며, 가중치 초기화는 [He et al.]의 방법을 따르고 모든 plain/residual 네트워크를 처음부터 학습합니다.
최적화는 SGD 방식으로 진행하며, 미니배치 크기는 256입니다. 학습률은 0.1에서 시작하며 오류가 일정해지면 10으로 나눕니다. 모델은 최대 60만 번의 반복(iterations) 동안 학습됩니다. 가중치 감소(weight decay)는 0.0001, 모멘텀(momentum)은 0.9로 설정합니다. 드롭아웃(dropout) [Hinton et al.]은 사용하지 않습니다 [Ioffe and Szegedy].
테스트 시 비교 연구를 위해 10-crop 테스트 [Krizhevsky et al.] 방식을 사용합니다. 최상의 결과를 위해, 완전 합성곱 형태 [Simonyan and Zisserman, He et al.]를 채택하고 여러 스케일에서 점수를 평균합니다 (이미지는 짧은 변이 {224, 256, 384, 480, 640} 크기에 맞춰 조정됨).
4. Experiments
4.1. ImageNet Classification
우리는 1000개의 클래스가 포함된 ImageNet 2012 분류 데이터셋 [Russakovsky et al.]에서 우리의 방법을 평가합니다. 모델들은 128만 개의 학습 이미지로 학습되며, 5만 개의 검증 이미지로 평가됩니다. 또한, 테스트 서버에서 제공하는 10만 개의 테스트 이미지에 대한 최종 결과도 얻어집니다. 우리는 top-1 및 top-5 오류율을 평가합니다.
Plain Networks: 먼저 18층과 34층으로 이루어진 plain 네트워크를 평가했습니다. 34층 plain 네트워크는 Fig. 3(중간)에 나와 있으며, 18층 plain 네트워크는 이와 비슷한 구조입니다. 자세한 아키텍처는 Table 1을 참고하세요.
Table 2의 결과에서, 더 깊은 34층 plain 네트워크는 얕은 18층 plain 네트워크보다 검증 오류가 높다는 것을 확인할 수 있습니다. 이유를 파악하기 위해, Fig. 4(왼쪽)에서 학습 과정 동안의 학습/검증 오류를 비교했습니다. 여기서 성능 저하 문제(degradation problem)가 나타났음을 관찰했으며, 34층 plain 네트워크가 전체 학습 과정 동안 18층 네트워크보다 높은 학습 오류를 보였습니다. 이로 인해 학습 과정에서 최적화에 어려움이 발생하는 원인은 향후 연구할 계획입니다.
Residual Networks: 다음으로, 18층과 34층 Residual Network (ResNet)를 평가했습니다. 기본 아키텍처는 앞서 설명한 plain 네트워크와 동일하나, 각 3x3 필터 쌍에 Shortcut Connection이 추가되었습니다 (Fig. 3, 오른쪽 참조). 첫 번째 비교(Table 2 및 Fig. 4, 오른쪽)에서는 모든 Shortcut에 항등 맵(identity mapping)을 사용하고, 차원이 증가할 때는 0으로 채워넣는 방법(옵션 A)을 사용했습니다. 따라서, 추가적인 파라미터는 없습니다.
Table 2와 Fig. 4에서 세 가지 주요 관찰을 얻을 수 있습니다:
-
Residual Learning의 효과: residual learning을 적용한 결과, 34층 ResNet이 18층 ResNet보다 성능이 우수했습니다 (2.8% 개선). 특히, 34층 ResNet은 학습 오류가 크게 낮으며, 검증 데이터에 대해 일반화되는 특성을 보였습니다. 이는 성능 저하 문제가 잘 해결되었음을 나타내며, 깊이를 증가시킴으로써 정확도가 향상될 수 있음을 보여줍니다.
-
Plain Network와의 비교: 34층 ResNet은 plain 네트워크보다 top-1 오류율을 3.5% 낮췄습니다 (Table 2 참조). 이는 학습 오류가 성공적으로 줄어든 결과이며 (Fig. 4의 오른쪽 vs. 왼쪽), residual learning이 매우 깊은 네트워크에서 효과적임을 입증합니다.
-
빠른 수렴 속도: 18층 plain 네트워크와 18층 ResNet은 유사한 정확도를 보이지만(Table 2 참조), 18층 ResNet은 더 빠르게 수렴했습니다 (Fig. 4의 오른쪽 vs. 왼쪽). 네트워크가 "너무 깊지 않은" 경우(여기서는 18층), 현재의 SGD 솔버가 plain 네트워크에서도 좋은 해를 찾을 수 있었습니다. 이 경우 ResNet은 초기 학습 단계에서 더 빠른 수렴을 제공하여 최적화를 쉽게 만들어줍니다.
Identity vs. Projection Shortcuts
우리는 파라미터가 없는 항등(shortcut)이 학습에 도움이 된다는 것을 보여주었습니다. 다음으로, Projection Shortcut (식 (2))을 조사합니다. Table 3에서는 세 가지 옵션을 비교합니다: (A) 차원이 증가할 때 0을 추가하는 zero-padding shortcuts을 사용하며, 모든 shortcuts은 파라미터가 없는 항등으로 유지 (Table 2 및 Fig. 4의 오른쪽과 동일); (B) 차원이 증가할 때만 projection shortcuts을 사용하고, 나머지는 항등으로 유지; (C) 모든 shortcuts을 projection으로 설정.
Table 3에 따르면, 세 가지 옵션 모두 plain 네트워크보다 성능이 훨씬 뛰어납니다. B는 A보다 약간 더 좋은 성능을 보였는데, 이는 A의 zero-padding된 차원이 실제로 잔차 학습에 참여하지 않기 때문이라고 볼 수 있습니다. C는 B보다 조금 더 성능이 좋지만, 이는 projection shortcuts이 많이 포함되어 (13개) 추가된 파라미터 덕분입니다. 하지만 A/B/C 간의 성능 차이가 크지 않다는 것은 projection shortcut이 성능 저하 문제를 해결하는 데 필수적이지 않다는 것을 의미합니다. 따라서 메모리/시간 복잡도와 모델 크기를 줄이기 위해 나머지 실험에서는 옵션 C를 사용하지 않았습니다.
특히, 아래에서 설명할 병목 아키텍처(bottleneck architectures)에서는 복잡도를 증가시키지 않기 위해 항등 shortcut이 중요합니다.
Deeper Bottleneck Architectures
이제 ImageNet을 위한 더 깊은 네트워크 구조를 설명합니다. 학습 시간의 효율성을 고려하여, 빌딩 블록을 병목(bottleneck) 형태로 설계했습니다. 각 잔차 함수 는 2개의 층 대신 3개의 층으로 구성됩니다 (Fig. 5 참조). 이 세 개의 층은 1x1, 3x3, 그리고 1x1 합성곱으로 이루어져 있으며, 1x1 층은 차원을 줄였다가 복원하는 역할을 합니다. 이렇게 하여 3x3 층이 입력/출력 차원이 작아진 병목 구간을 담당하게 됩니다. Fig. 5에서는 이 두 가지 디자인이 유사한 시간 복잡도를 가짐을 보여줍니다.
파라미터가 없는 항등 Shortcut은 병목 아키텍처에서 특히 중요합니다. 만약 Fig. 5(오른쪽)의 항등 shortcut이 Projection Shortcut으로 대체된다면, shortcut이 두 고차원 끝단에 연결되어 시간 복잡도와 모델 크기가 두 배로 증가합니다. 따라서 병목 디자인에서 항등 shortcut은 모델을 더 효율적으로 만듭니다.
- 50-layer ResNet: 34층 네트워크의 각 2층 블록을 이 3층 병목 블록으로 대체하여, 50층 ResNet을 구성했습니다 (Table 1 참조). 차원이 증가할 때는 옵션 B를 사용하였으며, 이 모델의 계산량은 3.8억 FLOP입니다.
- 101-layer 및 152-layer ResNets: 더 많은 3층 블록을 사용해 101층 및 152층 ResNet을 구성했습니다 (Table 1 참조). 특히, 깊이가 크게 증가했음에도 152층 ResNet (11.3억 FLOP)은 VGG-16/19 네트워크(15.3억/19.6억 FLOP)보다 계산 복잡도가 낮습니다.
50/101/152층 ResNet은 34층 모델보다 상당히 높은 정확도를 보여줍니다 (Table 3 및 4 참조). 성능 저하 문제는 발생하지 않았고, 깊이가 크게 증가함에 따라 정확도가 현저히 향상되었습니다. 깊이가 늘어날수록 모든 평가 지표에서 성능이 향상됨을 확인했습니다 (Table 3 및 4 참조).
최신 방법들과의 비교: Table 4에서 기존의 최고 단일 모델 결과들과 비교했습니다. 우리의 기본 34층 ResNet은 매우 경쟁력 있는 정확도를 달성했습니다. 152층 ResNet의 단일 모델 top-5 검증 오류는 4.49%로, 이전의 모든 앙상블 결과를 능가합니다 (Table 5 참조). 다양한 깊이의 모델 6개를 결합하여 앙상블을 구성한 결과 (152층 모델 2개 포함), 테스트 세트에서 top-5 오류율 3.57%를 달성했습니다 (Table 5 참조). 이 결과는 ILSVRC 2015에서 1위를 차지했습니다.
4.2. CIFAR-10 and Analysis
우리는 10개의 클래스에 대해 5만 개의 학습 이미지와 1만 개의 테스트 이미지로 구성된 CIFAR-10 데이터셋 [Krizhevsky]에서 추가 연구를 수행했습니다. 이 실험은 학습 세트에서 훈련되고 테스트 세트에서 평가되었습니다. 우리의 목표는 극도로 깊은 네트워크의 동작을 분석하는 것이며, 최첨단 성능을 추구하는 것이 아니기 때문에 의도적으로 간단한 아키텍처를 사용했습니다.
plain/residual 아키텍처는 Fig. 3(중간/오른쪽)의 형태를 따릅니다. 네트워크의 입력은 32x32 크기의 이미지이며, 픽셀별 평균 값을 빼줍니다. 첫 번째 층은 3x3 합성곱으로 시작합니다. 이후에는 3x3 합성곱으로 이루어진 6n 개의 층을 사용하며, 이 층들은 각각 특징 맵 크기 {32, 16, 8}에서 2n 층씩 적용됩니다. 필터 개수는 각각 {16, 32, 64}입니다. 다운샘플링은 스트라이드 2를 갖는 합성곱으로 수행됩니다. 네트워크는 글로벌 평균 풀링(global average pooling) 층과 10개의 출력을 가진 완전 연결 층, 그리고 softmax로 마무리됩니다. 총 6n+2개의 가중치를 가지는 층이 쌓여 있습니다. 아래 표는 이 아키텍처를 요약합니다.
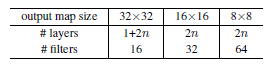
Shortcut Connection을 사용할 때는, 3x3 층 쌍마다 연결하여 총 3n 개의 shortcut이 만들어집니다. CIFAR-10 데이터셋에서는 모든 경우에 항등 shortcut(옵션 A)을 사용했기 때문에, residual 모델은 plain 네트워크와 깊이, 너비, 파라미터 수가 완전히 동일합니다.
학습에는 weight decay 0.0001과 momentum 0.9를 사용하고, [He et al.]의 가중치 초기화와 배치 정규화(BN) [Ioffe and Szegedy]를 적용했지만 dropout은 사용하지 않았습니다. 모델은 두 개의 GPU에서 미니배치 크기 128로 학습됩니다. 초기 학습률은 0.1로 시작하고, 32k와 48k 반복(iteration)마다 학습률을 10배씩 줄여주며, 64k 반복에서 학습을 종료합니다. 학습 종료 시점은 학습 데이터 45k와 검증 데이터 5k로 나눈 구성을 기준으로 결정했습니다. 학습 시에는 [Lee et al.]의 간단한 데이터 증강 방식을 사용하여, 이미지의 각 변에 4 픽셀을 패딩한 후, 32x32 크기로 잘라내거나 수평으로 뒤집어 무작위로 선택합니다. 테스트에서는 원본 32x32 이미지의 단일 뷰만 평가합니다.
우리는 값을 사용하여 각각 20층, 32층, 44층, 56층 네트워크를 구성했습니다. Fig. 6 (왼쪽)에서 볼 수 있듯이, 깊이가 깊어진 plain 네트워크는 학습 오류가 더 커지며 성능이 저하되는 현상을 보입니다. 이러한 현상은 ImageNet (Fig. 4, 왼쪽) 및 MNIST 데이터셋에서도 유사하게 관찰되었으며, 이는 최적화의 어려움이 근본적인 문제임을 시사합니다.
Fig. 6 (중간)은 ResNet의 동작을 보여줍니다. ImageNet 실험 결과와 유사하게 (Fig. 4, 오른쪽), ResNet은 이러한 최적화 문제를 극복하며, 깊이가 증가할수록 정확도가 향상되는 결과를 나타냅니다.
추가로 을 사용하여 110층 ResNet을 구성했습니다. 이 경우, 초기 학습률 0.1은 학습을 시작하기에 다소 큰 값이었습니다. 따라서 학습 오류가 80% 이하로 떨어질 때까지 (약 400번 반복) 학습률을 0.01로 워밍업(warm-up)한 후, 다시 0.1로 조정하여 학습을 이어갔습니다. 이후의 학습 스케줄은 이전과 동일하게 유지했습니다. 이 110층 네트워크는 잘 수렴했으며 (Fig. 6, 중간), 다른 깊고 얇은 네트워크들(FitNet [Romero et al.], Highway [Srivastava et al.])보다 파라미터 수는 적으면서도 최첨단 수준의 정확도(6.43%, Table 6)를 달성했습니다.
Analysis of Layer Responses
Fig. 7은 층의 응답에 대한 표준 편차(std)를 보여줍니다. 여기서 응답은 각 3x3 층의 출력으로, BN 적용 후 비선형 활성화(ReLU 또는 덧셈) 전의 값을 의미합니다. ResNet의 경우, 이 분석은 잔차 함수(residual function)의 응답 강도를 나타냅니다.
Fig. 7을 통해 ResNet이 일반적으로 plain 네트워크보다 응답 크기가 작다는 것을 확인할 수 있습니다. 이러한 결과는 잔차 함수가 비잔차 함수(non-residual function)보다 대체로 0에 가깝다는 우리의 기본 가설(Sec.3.1)을 뒷받침합니다. 또한, 더 깊은 ResNet이 더 작은 응답 크기를 가지는 경향이 있음을 확인할 수 있는데, 이는 Fig. 7에서 ResNet-20, ResNet-56, ResNet-110을 비교함으로써 알 수 있습니다. 층이 많아질수록 ResNet의 개별 층은 신호를 덜 수정하는 경향이 있습니다.
1000개 이상의 층 실험
우리는 1000개가 넘는 매우 깊은 모델을 실험해 보았습니다. 으로 설정하여 1202층 네트워크를 구성했고, 앞서 설명한 방식으로 학습했습니다. 이 방법은 최적화 문제를 일으키지 않았으며, 1202층 네트워크는 학습 오류 0.1% 미만(Fig. 6, 오른쪽)을 달성했습니다. 테스트 오류도 상당히 양호한 결과(7.93%, Table 6)를 보였습니다.
그러나 이렇게 매우 깊은 모델에서는 여전히 해결해야 할 문제가 남아 있습니다. 1202층 네트워크의 테스트 결과는 110층 네트워크보다 오히려 낮은 성능을 보였으며, 이는 두 네트워크가 유사한 학습 오류를 가지고 있음에도 불구하고 발생한 현상입니다. 우리는 이를 과적합(overfitting) 때문이라고 판단합니다. 1202층 네트워크는 이 작은 데이터셋에 대해 불필요하게 큰 규모(19.4M 파라미터)를 가지기 때문일 수 있습니다. 이 데이터셋에서 최상의 성능을 얻기 위해서는 maxout [Goodfellow et al.]이나 dropout [Hinton et al.] 같은 강한 정규화가 필요합니다 [Goodfellow et al., Romero et al.].
Analysis of Layer Responses
Fig. 7은 층의 응답에 대한 표준 편차(std)를 보여줍니다. 여기서 응답은 각 3x3 층의 출력으로, BN 적용 후 비선형 활성화(ReLU 또는 덧셈) 전의 값을 의미합니다. ResNet의 경우, 이 분석은 잔차 함수(residual function)의 응답 강도를 나타냅니다.
Fig. 7을 통해 ResNet이 일반적으로 plain 네트워크보다 응답 크기가 작다는 것을 확인할 수 있습니다. 이러한 결과는 잔차 함수가 비잔차 함수(non-residual function)보다 대체로 0에 가깝다는 우리의 기본 가설(Sec.3.1)을 뒷받침합니다. 또한, 더 깊은 ResNet이 더 작은 응답 크기를 가지는 경향이 있음을 확인할 수 있는데, 이는 Fig. 7에서 ResNet-20, ResNet-56, ResNet-110을 비교함으로써 알 수 있습니다. 층이 많아질수록 ResNet의 개별 층은 신호를 덜 수정하는 경향이 있습니다.
1000개 이상의 층 실험
우리는 1000개가 넘는 매우 깊은 모델을 실험해 보았습니다. 으로 설정하여 1202층 네트워크를 구성했고, 앞서 설명한 방식으로 학습했습니다. 이 방법은 최적화 문제를 일으키지 않았으며, 1202층 네트워크는 학습 오류 0.1% 미만(Fig. 6, 오른쪽)을 달성했습니다. 테스트 오류도 상당히 양호한 결과(7.93%, Table 6)를 보였습니다.
그러나 이렇게 매우 깊은 모델에서는 여전히 해결해야 할 문제가 남아 있습니다. 1202층 네트워크의 테스트 결과는 110층 네트워크보다 오히려 낮은 성능을 보였으며, 이는 두 네트워크가 유사한 학습 오류를 가지고 있음에도 불구하고 발생한 현상입니다. 우리는 이를 과적합(overfitting) 때문이라고 판단합니다. 1202층 네트워크는 이 작은 데이터셋에 대해 불필요하게 큰 규모(19.4M 파라미터)를 가지기 때문일 수 있습니다. 이 데이터셋에서 최상의 성능을 얻기 위해서는 maxout [Goodfellow et al.]이나 dropout [Hinton et al.] 같은 강한 정규화가 필요합니다 [Goodfellow et al., Romero et al.]. 본 논문에서는 maxout이나 dropout을 사용하지 않았으며, 단순히 깊고 얇은 아키텍처를 통해 정규화를 적용하였습니다. 그러나 강한 정규화 기법을 결합하면 결과가 향상될 수 있으며, 이는 향후 연구에서 다룰 예정입니다.
4.3. Object Detection on PASCAL and MS COCO
우리의 방법은 다른 인식 작업에서도 좋은 일반화 성능을 보입니다. Table 7과 8은 PASCAL VOC 2007 및 2012 [Everingham et al.]와 COCO [Lin et al.] 데이터셋에서 객체 탐지에 대한 기본 결과를 보여줍니다. 탐지 방법으로 Faster R-CNN [Ren et al.]을 사용했습니다. 여기서는 VGG-16 [Simonyan and Zisserman]을 ResNet-101로 대체할 때의 성능 향상에 주목합니다. 두 모델을 사용하는 탐지 구현 방식(부록 참고)은 동일하므로, 성능 향상은 네트워크 구조의 개선에서만 기인합니다.
특히 어려운 COCO 데이터셋에서, COCO의 표준 지표(mAP@[.5, .95])에서 6.0% 향상, 즉 28%의 상대적인 성능 향상을 얻었습니다. 이 성능 향상은 오직 학습된 표현 덕분입니다.
깊은 잔차 네트워크(ResNet)를 기반으로, 우리는 ILSVRC & COCO 2015 대회의 여러 트랙에서 1위를 차지했습니다: ImageNet detection, ImageNet localization, COCO detection, 그리고 COCO segmentation. 자세한 내용은 부록에 있습니다.
(이후생략)
