[2016 ICIP] (SORT) SIMPLE ONLINE AND REALTIME TRACKING

Paper Info.
- Bewley, Alex, et al. "Simple online and realtime tracking." 2016 IEEE international conference on image processing (ICIP). Ieee, 2016.
https://arxiv.org/pdf/1602.00763
1. Introduction
(Background)
-
이 논문은 multiple object tracking (MOT) 문제를 해결하기 위한 tracking-by-detection framework의 간결한 implementation을 제시한다.
각 frame에서 object를 detect하고 bounding box 형태로 표현한다. -
본 연구는 online tracking을 primarily target으로 하며, Tracker에는 previous frame과 current frame에서의 detection 결과만 제공된다.
또한, realtime tracking을 가능하게 하기 위해 efficiency에 a strong emphasis를 두었으며, autonomous vehicles과 같은 applications에서의 활용을 촉진하는 것을 목표로 한다. -
MOT 문제는 video sequence에서 서로 다른 frames 간에 detection들을 associate (연결)시키는것을 목표로 하는 data association problem으로 볼 수 있다.
(Related works, motivation)
-
data association process를 돕기 위해, trackers들은 motions and appearance를 modeling하는 다양한 방법들을 사용한다.
본 논문에서 활용한 방법들은 최근에 구축된 visual MOT benchmark에 의해 관찰된 몇 가지 observations에 의해 motivated되었다.- Multiple Hypothesis Tracking (MHT) and Joint Probabilistic Data Association (JPDA)와 같은 mature data association techniques들이 다시 주목받으며 MOT benchmark에서 top positions을 차지했다.
- Aggregate Channel Filter (ACF) detector를 사용하지 않는 유일한 tracker가 오히려 top rank를 기록했다.
이는 다른 tracker들의 성능이 detection quality 성능의 한계에 의해 제약될 가능성을 시사한다. - 또한, the trade-off between accuracy and speed가 뚜렷하게 나타난다.
the speed of the most accurate trackers는 realtime applications을 위해서는 너무 느리다.
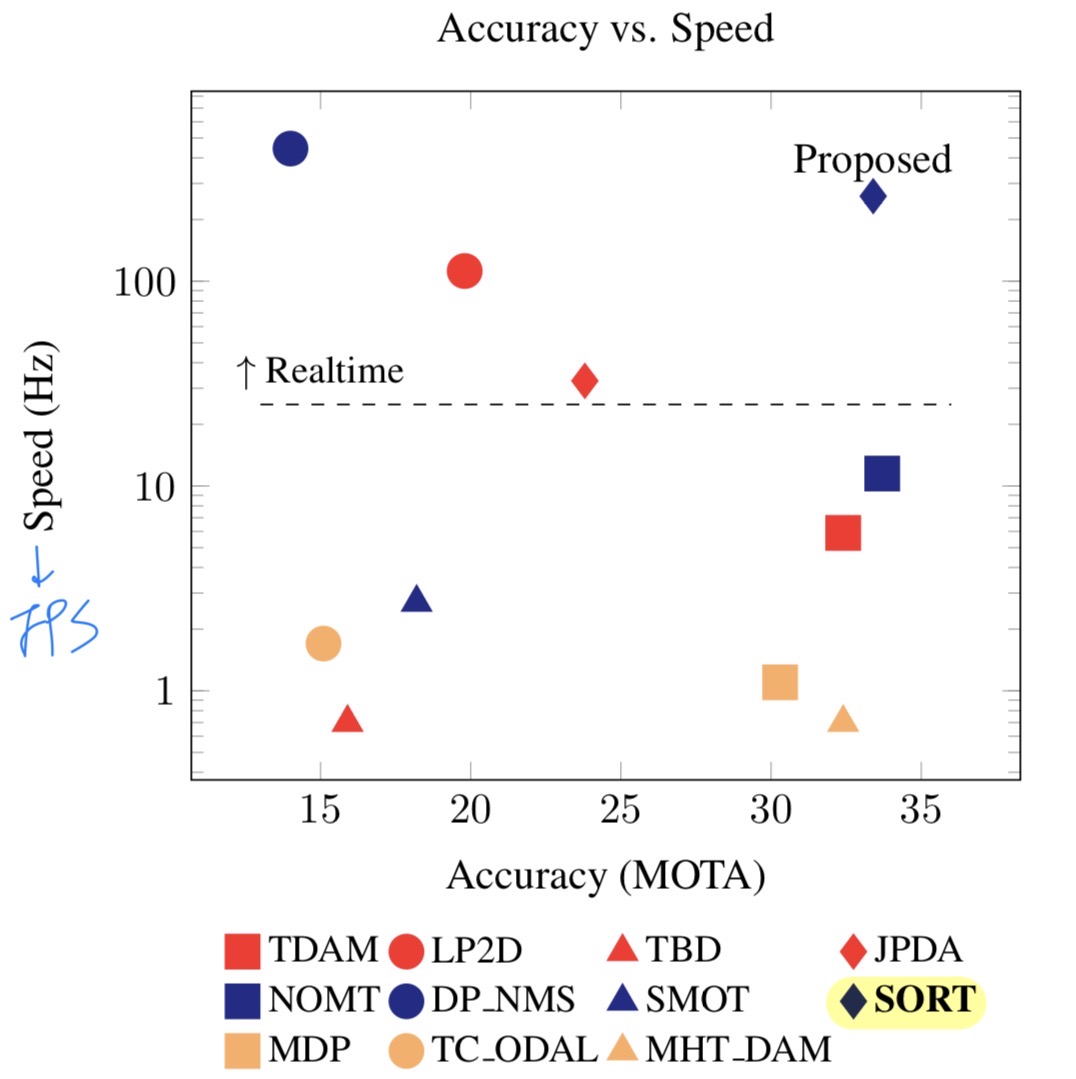
-
Occam's Razor 원칙에 따라, tracking 과정에서는 detection component 이외의 appearance features를 사용하지 않으며,
motion estimantion and data association 모두에 대해 bbox의 position and size만 사용한다.
또한 short-term and long-term occlusion 역시 고려하지 않았따.
이러한 상황은 실제로 very rarely 발생하며, 이를 명시적으로 처리할 경우 tracking framework에 undesirable copmlexity를 도입하기 때문이다.
우리는 object re-identification과 같은 complexity를 추가하는 것이 tracking framework에서 significant overhead를 초래하며, 결과적으로 realtime applications에서의 활용을 제한할 가능성이 있다고 주장한다. -
이러한 re-identification 없는 design philosophy와 달리, many proposed visual trackers들은 various edge cases and detection errors를 handle하기 위한 무수한 components들을 도입한다.
우리 연구는 그 대신에 efficient and reliable handling of the ommon frame-to-frame associations에 집중한다.
detection errors에 robust하게 이것저것 component들을 추가하는 것 대신, 우리는 detection problem을 즉시 해결할 수 있는 recent advances in visual object detection을 도입한다.
이는 common ACF pedestrain detector와 a recent CNN based detector를 비교함으로써 입증되었다.
추가로, two classical yet extremely efficient methods인 Kalman filter and Hungarian method는
각각 motion prediction and data association components를 다루기 위해 사용되었다. -
contributions

정리:
SORT는 tracking-by-detection 기반 MOT 방법으로, 최근(2016년 당시) CNN 기반 detector의 높은 detection 성능이 tracking 성능 향상에 중요한 역할을 한다는 점에 주목.
기존 tracker들이 occlusion handling, appearance modeling, re-identification 등 복잡한 구성 요소를 포함하여 높은 computational overhead를 가지는 것과 달리,
SORT는 이러한 요소들을 제거하고 Kalman filter와 Hungarian algorithm만을 사용한 단순한 motion prediction과 data association 구조를 사용한다.
이를 통해 높은 detection accuracy (MOTA)를 달성하면서도 빠른 tracking speed(FPS)를 달성.
3. Methodology
- proposed method는 다음의 key components들로 설명된다:
detection,
propagating object states into future frames,
associating current detections with existing objects,
and managing the lifespan(생존 기간) of tracked objects
3.1. Detection
-
우리는 Faster Region CNN (FrRCNN) detection framework를 사용했다.
With default parameters learnt for the PASCAL VOC challenge.
우리는 pedestrains에만 관심이 있기 때문에 all other classes를 ignore하고
output probabilities가 50% 넘는 person detection results만 tracking framework에 pass하였다. -
our experiments에서, FrRCNN detections과 ACF detections를 비교했을 때
detection quality가 tracking performance에 significant impact를 미친다는 것을 확인하였다.
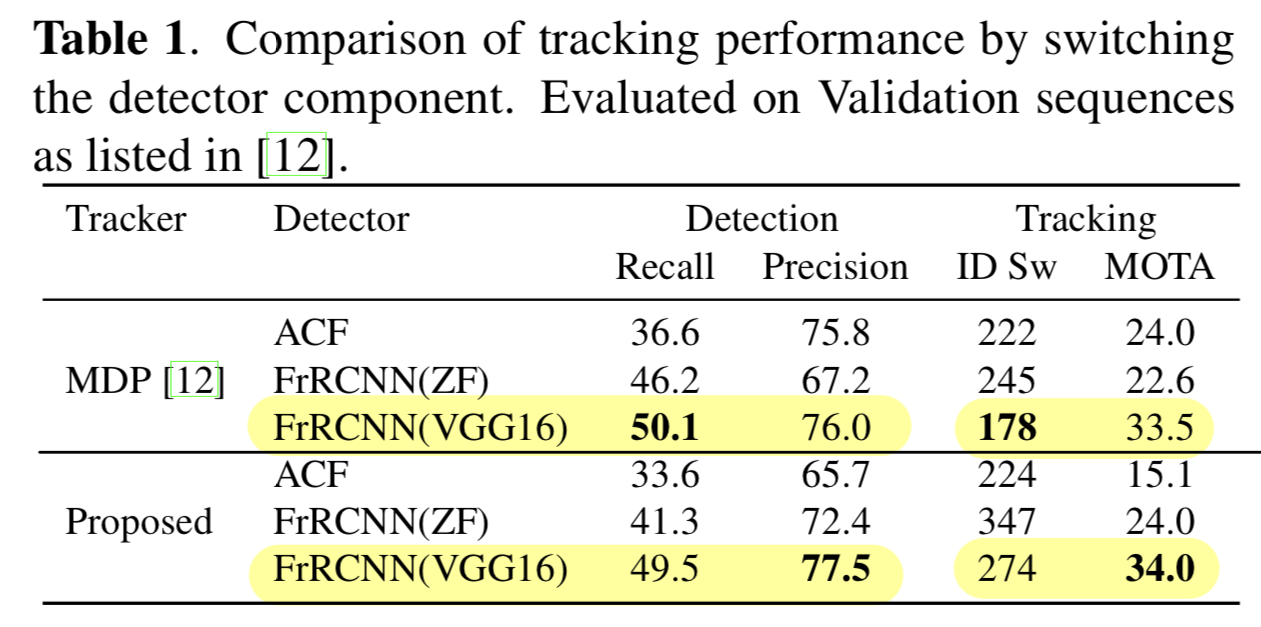
이 결과는 validation set of sequences를 사용하여 기존의 online tracker MDP와 본 논문에서 제안한 tracker에 동일하게 적용함으로써 확인되었다.
Table 1은 the best detector FrRCNN(VGG16)이 MDP와 proposed method 모두에서 the best tracking accuracy를 달성한다는 것을 보여준다.
3.2. Estimation Model ~ 3.3. Data Association
- object model, 즉 object의 representation 방식과 next frame으로 target's identity (=kalman prediction)를 propagate하기 위해 사용되는 motion model을 설명한다.
우리는 각 object의 inter-frame 간 이동을, other objects나 camera motion과 독립적인 linear constant velocity model로 approximate한다.

- 내가 이해한 내용:
현재 시점 (current frame)에서 object에 대한 State vector 가 주어졌을 때, 그 다음 시점 (next frame)에서의 object state 을 어떻게 예측할 것인가?

Step 1. Kalman Filter (Prediction) = Target BBox라고 부르는 듯
Kalman Filter (Prediction)

Step 2. Object Detection (Measurement) = Detection BBox라고 부르는 듯
Object detection via FrRCNN (Measurments)

Step 3. Data Associatoin (Hungarian Algorithm)
Data association (Hungarian matching)
Kalman preidctions에 detection을 할당하기 위해, 먼저 각 kalman prediction의 bbox location을 current frame에서의 new location으로 예측한다.
그 다음 기존 kalman predictions bbox와 모든 detection bbox 사이의 IoU distance 거리를 계산하여 assignment cost matrix를 구성한다.
이 assignment는 Hungarian algorithm이 사용된다.
또한 detection과 target 사이의 IoU가 minimum IoU 보다 작은 경우에는 해당 assignment를 Reject하도록 제한한다.

Step 4. Kalman Update (Correction = Prediction + Measurement)
Kalman Update (Prediction + Measurement을 통한 Correction)더 안정적인 tracking

- Kalman update가 어떻게 되는지는 paper에 설명되어 있지 않고, 알아보니 kalman filter에 대해 더 깊게 공부해야 하는 듯함.
시간관계상 공부는 생략하고.. 직관적으로 Kalman update는 마치 weighted average 처럼 이전 update들을 누적하여 현재의 state를 더 안정적이게 estimation하도록 update해나가는 듯함.
3.4. Creation and Deletion of Track Identities
-
object가 Image에 새로 enter and leave할 때,
이에 따라 Unique identities를 created or destroyed해야 한다. -
trackers를 생성하기 위해, 우리는 IoU가 보다 작은 detection을 untracked object의 존재로 간주한다.
tracker는 bbox의 bbox with the velocity set to zero의 geometry 정보를 이용하여 initialized된다.
이 시점에서는 velocity를 observed할 수 없기 때문에, velocity component의 covariance는 큰 값으로 초기화하여, 이러한 uncertainty를 반영할 수 있기 때문이다.
(zero로 초기화하면 velocity component의 covariance가 큰 값으로 초기화되는 건가? 이 부분은 Kalman filter 원리와 관련되어 있는 듯) -
또한 new tracker는 probationary period (수습 기간)을 거친다.
이 기간 동안 target(kalman preds)은 여러 frame에서 detection과 지속적으로 matching되어 enough evidence를 accumulate해야 하며,
이를 통해 false positives를 tracking하는 것을 방지한다. -
tracks는 frames 동안 detection과 matching되지 않으면 terminated된다.
(1) 이는 tracker의 수가 무한히 증가하는 것을 방지하고, (2) detector(FrRCNN)의 corrections 없이 오랜 시간 prediction (kalman)만 수행하면서 발생하는 Localization errors를 막기 위함이다.- 모든 실험에서 로 설정하였고, 그 이 유는 두 가지이다.
- constant velocity model은 실제 object의 dynamics에 대한 a poor predictor이다.
- 본 연구는 frame-to-frame tracking에 초점을 맞추고 있으며 Object re-identification은 the scope of this work에 포함되지 않는다.
또한, early deletion of lost targets은 efficiency에 도움이 된다.
만약 object reappear된다면, tracking은 a new identity로 다시 시작된다.
- 모든 실험에서 로 설정하였고, 그 이 유는 두 가지이다.
4. Experiments
4.1. Metrics
- MOTA (): Multi-object tracking accuracy
- MOTP (): Multi-object tracking precision
- FAF (): number of false alarms per frame
- MT (): number of mostly tracked trajectories. (i.e., target has the same label for at least 80% of its life span.)
- ML (): number of mostly lost trajectories. (i.e., target has the same label for at least 80% of its life span.)
- FP (): number of false detections.
- FN (): number of missed detections
- ID sw (): number of times an ID switches to a different previously tracked object
- Frag (): number of fragmentations where a track is interrupted by miss detection.
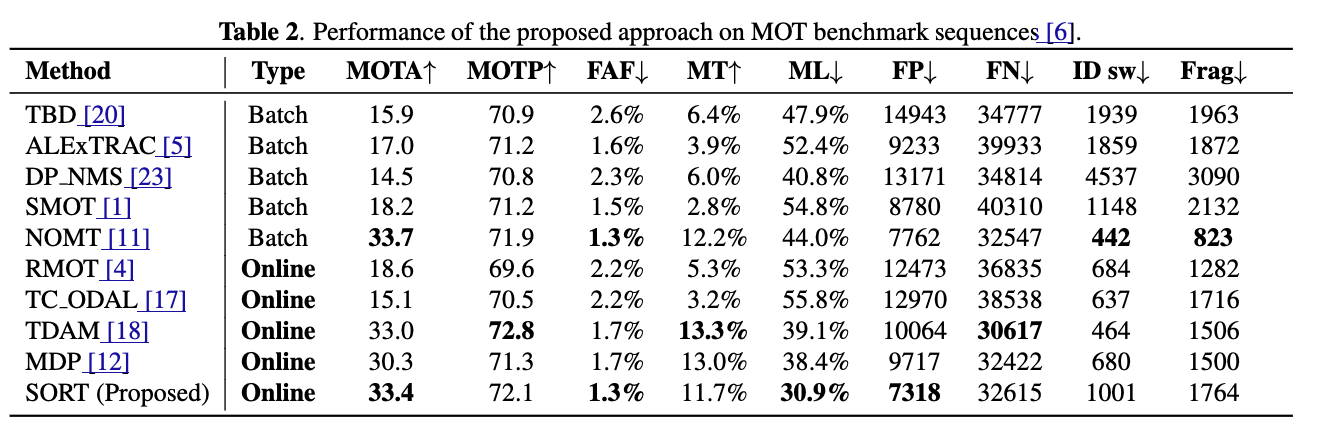
4.2. Performance Evaluation
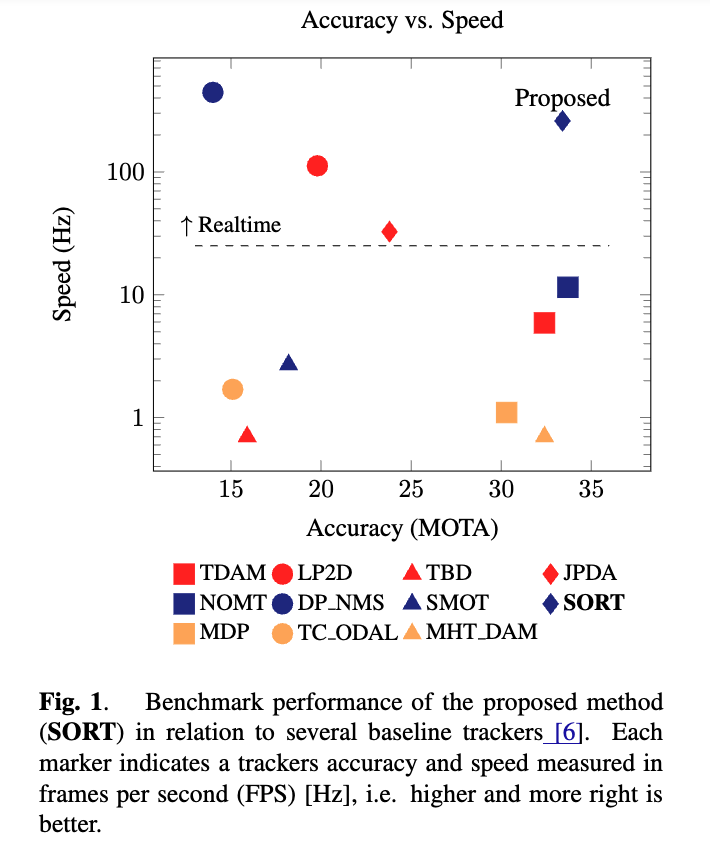
4.3. Runtime
몰랐던 개념 -----
Occam's Razor(면도칼):
철학과 과학에서 널리 쓰이는 원칙으로, "같은 현상을 설명할 수 있는 여러 가설이 있다면, 가장 단순한 설명을 선택하라." 라는 의미
Tracking-by-Detection vs. Joint Detection and Tracking- Tracking-by-Detection:
전통적이고 널리 쓰이는 방식 (이 논문, SORT도 이 방식)
구조: object detector bboxes tracker (association) trajectories.
즉, detection + tracking 과정을 분리- 장점:
detector 성능 활용 가능
module 구조, 구현 쉬움
real-time 가능 - 단점:
detector 오류에 매우 민감
occlusion 처리 어려움
ID switch 발생
- 장점:
- Joint Detection and Tracking:
detection + tracking 과정을 하나의 network에서 동시에 수행
구조: video frames single neural network detection + Track ID
특징: model이 시간 정보를 직접 학습- 장점:
tracking 정보를 feature level에서 학습
occlusion 대응 가능
end-to-end training - 단점:
학습 어려움
data 많이 필요
real-time 어려움
구현 복잡
- 장점:
- Tracking-by-Detection:
metrics in MOT
-
MOT benchmark에서 사용하는 metric들은 GT trajectory와 tracker가 만든 trajectory를 frame 단위로 matching한 뒤 계산함.
보통 와 같은 기준으로 GT prediction을 matching한 후 FP / FN / ID= 등을 집계함. -
MOTA(): Multi-object tracking accuracy- tracking에서 발생하는 모든 error를 합친 metric
- ex) GT objects = 1000, FN = 100, FP = 50, IDsw = 20
-
MOTP(): Multi-object tracking precision- matching된 bbox들의 평균 localization accuracy
- ex) IoU: 0.7, 0.8, 0.6,
-
FAF(): number of false alarms per frame- frame당 평균 False Positives
- ex) FP = 300, frames = 1000
-
MT(): number of mostly tracked trajectories. (i.e., target has the same label for at least 80% of its life span.)- 어떤 GT object가 life span의 80% 이상 추적되면 MT라고 판단.
- ex) GT object가 100개 frames에 존재, tracker는 90개 frames에서 tracking 성공
90/100=90%
MT
-
ML(): number of mostly lost trajectories. (i.e., target has the same label for at least 80% of its life span.)- 어떤 GT object가 life span의 20% 이하만 추적되면 ML이라고 판단..
- ex) GT object가 100개 frames에 존재, tracker는 10개 frames에서만 tracking 성공
10/100=10%
ML
-
FP(): number of false detections.- GT에 없는데 tracker가 있다고 detection한 경우.
- ex) GT: [person1, person2], preds: [person1, person2, person3]
FP=1 (person3)
-
FN(): number of missed detections- GT object가 있는데 detection을 못한 경우.
ex) GT: [person1, person2, person3], preds: [person1, person3]
FN=1 (person2)
- GT object가 있는데 detection을 못한 경우.
-
IDsw(): number of times an ID switches to a different previously tracked object- 같은 object인데 tracking ID가 바뀌는 경우
- ex) GT object A (frame1 frame2 frame3 frame4),
tracker (ID 5 ID 5 ID 8 ID 8)
IDsw=1 (ID 5 ID 8)
-
Frag(): number of fragmentations where a track is interrupted by miss detection.- tracking이 중간에 끊겼다가 다시 시작되는 경우
- ex) GT object는 frame1 ~ frame10에 존재하지만, tracker는
frame1 ~ frame3 tracked,
frame4 ~ frame6 lost,
frame7 ~ frame 10 tracked
fragmentation=1
Kalman Filter
