[2021 CVPR] A2-FPN: Attention Aggregation based Feature Pyramid Network for Instance Segmentation
Paper Info.

Abstract
(문제점)
- 다양한 scales의 object instances를 인식하는 데 있어서 pyramidal feature representations은 매우 중요함.
FPN은 high-level semantics를 바탕으로 pyramid를 구축하는 classic architecture이다.
그러나 feature extraction and fusion에서의 intrinsic defects (내재적 결함)가 FPN이 더 많은 discriminative (구별 가능한) features의 aggregating하는 데에 방해가 된다.
(제안)
- 본 연구에서는 Attention Aggregation based FPN (-)을 제안하여 attention-guided feature aggregation을 통해
multi-scale feature learning을 개선하고자 한다.- Feature extraction에서는,
multi-level global context features를 collecting-distributing (수집-분배)함으로써 discriminative features를 추출하고,
급격히 줄어든 channels로 인한 semantic information loss를 완화한다. - Feature fusion에서는,
adjacent features에서 complementary (보완적인) information를 aggregating하여 location-wise reassembly kernels을 생성하고,
content-aware sampling을 수행하며, channel-wise reweighting을 통해 element-wise addition 전에 semantic consistency를 강화한다.
- Feature extraction에서는,
(결과)
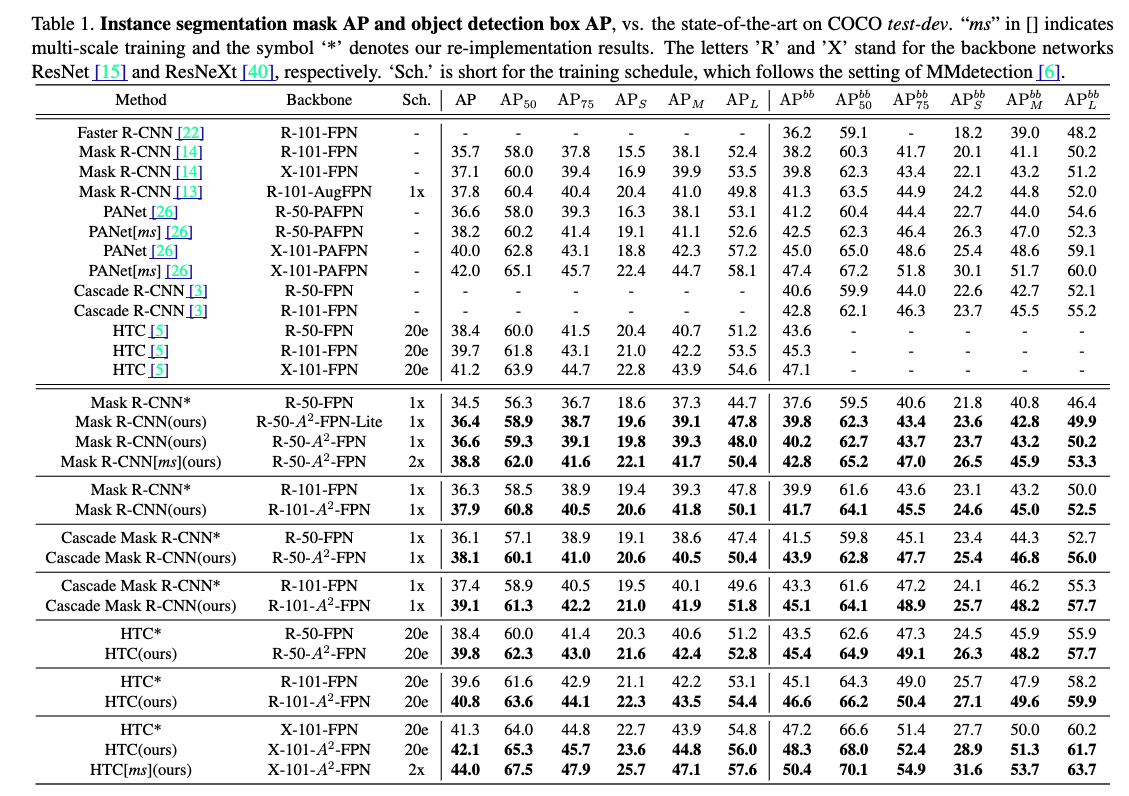
- -FPN은 다양한 instance segmentation framework에서 일관된 성능 향상을 보여주며,
FPN을 Mask R-CNN에 적용하여 ResNet-50과 ResNet-101을 backbone으로 사용할 때 성능이 각각 2.1%와 1.6% 향상된 mask AP를 기록했다.
또한, Cascade Mask R-CNN과 Hybrid Task Cascade와 같은 strong basleines에 통합했을 때도 -FPN은 각각 2.0%와 1.4%의 mask AP 향상을 달성했다.
1. Introduction
(배경)
-
Instance segmentation은 CV에서 the most challenging task이다.
이는 individual objects를 pixel-wise instance mask로 categorize and localize하는 것을 목표로 한다. -
Deep ConvNets의 급속한 발전에 힘입어, Mask R-CNN, PANet, HTC 같은 instance segmentation framework들은 SOTA를 지속적으로 향상시켜 왔다.
high-performance instance segmentation을 위해서는 다양한 크기와 위치에 있는 수많은 object를 인식해야 하므로, multi-scale feature representation 학습이 매우 중요하다.
(문제 제기)
- multi-scale processing을 처리하기 위해, FPN이 기존 instance segmentation framework에서 널리 사용되고 있다.
FPN은 기본적인 feature hierarchy 구조를 활용하고, adjacent features를 lateral connection과 top-down pathway를 통해 결합하여 모든 scale에서 strong semantics을 갖춘 feature pyramid를 구축한다.
...
비록 FPN과 PAFPN이 multi-scale feature representations 학습에는 효과적이지만, simple designs으로 인해 feature pyramid가 더욱 discriminative feature를 aggregating하는 데 한계가 있다.
우리는 feature pyramid의 구축을 feature extraction과 feature fusion으로 분해하고, 각각의 step이 갖고 있는 instrinsic defects를 발견했다.
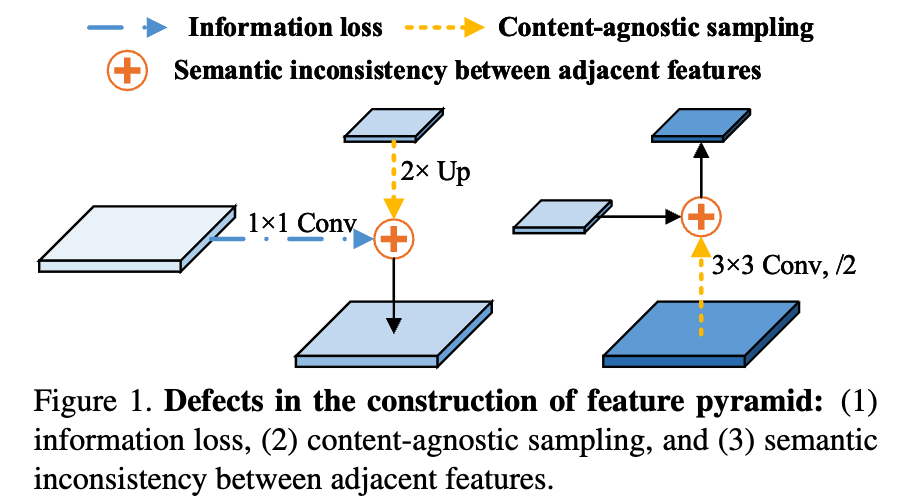
- Feature extraction 과정에서는,
1x1 conv layer로 동일한 channel 수를 갖는 feature를 생성하는데,
이렇게 생성된 feature map은 (특히 high-level feature일수록) drastic dimension reduction으로 인해 serious information loss를 겪는다. - Feature fusion의 첫 번째 step에서는,
feature map을 interpolation을 통해 upsampling하건, strided conv를 통해 downsampling한다.
하지만 interpolation은 pixel 간 상대 위치를 기반으로 하여 sub-pixel neighborhood에서 upsampling을 수행하므로, rich semantic information을 capture하지 못한다.
stride conv는 content-agnostic (무관한) downsampling kernel을 image 전체에 적용하기 때문에, feature의 실제 content를 고려하지 못한다. - Feature fusion의 두 번째 step에서는,
서로 인접한 두 feature를 element-wise addition으로 합친다.
하지만 이는 서로 다른 depth에서 오는 semantic gap을 무시하는 방식이다.
- Feature extraction 과정에서는,
(제안)
- 이러한 문제를 해결하기 위해, 우리는 Attention Aggregation based Feature Pyramid Network (-FPN)을 제안한다.
-FPN은 attention-guided feature aggregation을 통해 multi-scale feature 학습을 향상시키는 것을 목표로 한다.
-FPN은 기존 방법들과 세 가지 측면에서 차이를 갖는다:- 전체 feature hierarchy로부터 global context feature를 collecting하고,
이를 각 level에 distribute하여 discriminative feature를 extracts한다. - adjacent features 간의 complementary information을 aggregates하여,
context-aware up/down sampling을 위한 location-wise reassembly kernel을 생성한다. - channel-wise reweighting을 적용하여, element-wise addition 전에 semantic consistency를 강화한다.
- 전체 feature hierarchy로부터 global context feature를 collecting하고,
2. Related Work
Instance Segmentation
- Current instance segmentation은 대략 두 가지 categories로 나눌 수 있다: detection-based and segmentation-based.
- Detection-based methods를 사용하여 region proposals or bounding boxes를 생성하고,
그런 다음 각 instance에 대해 pixel-wise mask를 생성한다.
예를 들어, DeepMask, SharpMask, MultiPathNet은 discriminative ConvNets을 사용하여 object segments를 predict하고 점진적으로 개선한다.- MNC는 instance segmentation을 three sub-tasks로 분해한다: instance differentiation, mask estimation, object categorization.
- FCIS는 InstanceFCN을 기반으로 instance mask를 fully convoluitonally predict하기 위해 제안되었다.
- Mask R-CNN은 Faster R-CNN을 확정하여 기존의 classification and bbox regression branch와 parallel로 mask prediction branch를 추가했다.
- PANet은 FPN에서 정보를 aggregates하는 path를 단축시키기 위해 an extra bottom-up pathway를 추가하고, adaptive feature pooling을 통해 모든 levels에서 feature를 aggregating한다.
- ...
- HTC는 multi-stage cascade manner로 bbox regression과 mask prediction을 엮어 instance segmentation에 cascade를 통합하고,
semantic segmentation branch를 추가하여 contextual information을 통합한다.
- Segmentation-based methods는 먼저 image 전체에 대해 pixel-wise segmentation map을 활용하고,
그 후 다른 instances들의 pixel들을 group화하여 instance mask를 형성한다.- InstanceCut은 semantic segmantion과 boundary detection을 결합하여 instance segmentation을 수핸한다.
...
- InstanceCut은 semantic segmantion과 boundary detection을 결합하여 instance segmentation을 수핸한다.
- Detection-based methods를 사용하여 region proposals or bounding boxes를 생성하고,
Feature Pyramid
-
Pyramidal feature representations은 multi-scale problems을 해결하는 데 중요한 basis를 형성한다.
SSD는 pyramidal features에서 object detection을 시도한 최초의 방법이다.
FPN은 lateral connections과 top-down pathway를 통해 strong semantics를 갖는 feature pyramid를 구축한다.
FPN을 기반으로 한 PAFPN은 정보를 원활하게 흐르게 하기 위해 bottom-up path를 추가하여 information flow를 촉진한다.
EfficientDet은 more high-level feature fusion을 위해 bidirectional path를 여러 번 반복한다.
NAS-FPN은 neural architecture search를 이용해 더 강력한 feature pyramid structure를 찾아낸다. -
이전 작업들이 다양한 cross-scale connections으로 구성된 topological structure에 집중한 것과 달리, 이 연구에서는 feature를 aggregate하기 위한 node operations을 탐구한다.
Attention Mechanism
- Self-attention은 처음에 machine translation을 위해 제안되었으며, 여기서 scaled dot-product attention이 채택되었다.
non-local 연산의 effectiveness는 CV task에 대해 탐구되었다.
그러나 detectors에서 multi-level global context modeling은 거의 탐구되지 않았다.
channel attention은 [16]에서 channel 간의 interdependecies (상호 의존성)을 명시적으로 modeling하는 데 사용된다.
DANet과 GCNet은 self-attention과 channel attention을 결합하여 rich contextual dependencies를 capture한다.
3. Methodology
- -FPN의 overall framework는 Figure 2에 나타나 있다.
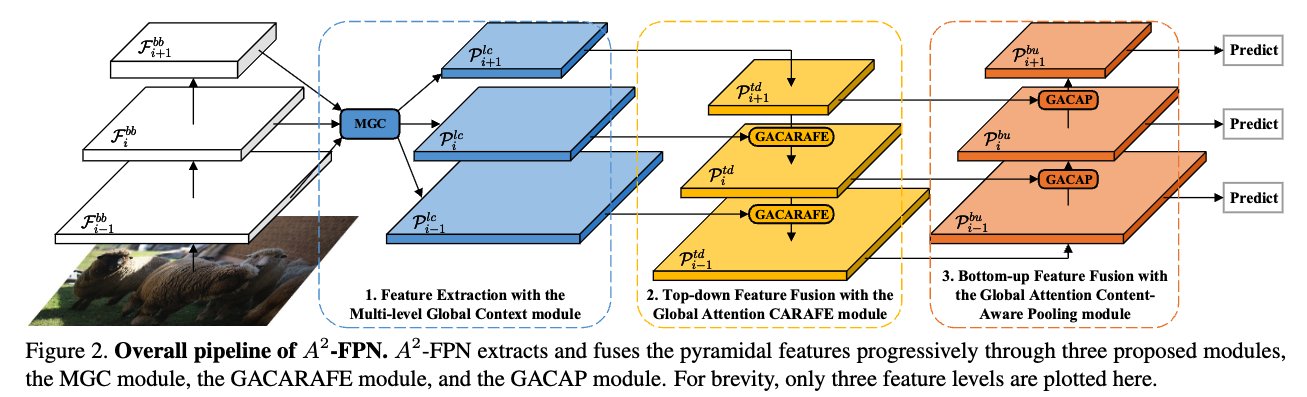 우리는 FPN과 마찬가지로 ResNet을 backbone으로 사용하며, feature hiearchy 로 표기한다.
우리는 FPN과 마찬가지로 ResNet을 backbone으로 사용하며, feature hiearchy 로 표기한다.
또한 로부터 stride 2인 3x3 conv layer를 적용하여 를 만든다.
(the pyramidal features는 the input image에 대해 strides of 를 갖는다.)
(bb는 backbone의 준말인듯)- 는 Section 3.1.의 Multi-level Global Context (MGC) module의 feature hierarchy로부터 추출된 context-rich features이다.
(lc는 lateral connection의 준말인듯) - 는 top-down path augmentation with the Global Attention CARAFE (GACARAFE) module로부터 나온 features.
- 는 bottom-up path augmentation with the Global Attention Content-Aware Pooling (GACAP) module로부터 나온 features.
(td는 top-down, bu은 bottom-up의 준말인듯)
- 는 Section 3.1.의 Multi-level Global Context (MGC) module의 feature hierarchy로부터 추출된 context-rich features이다.
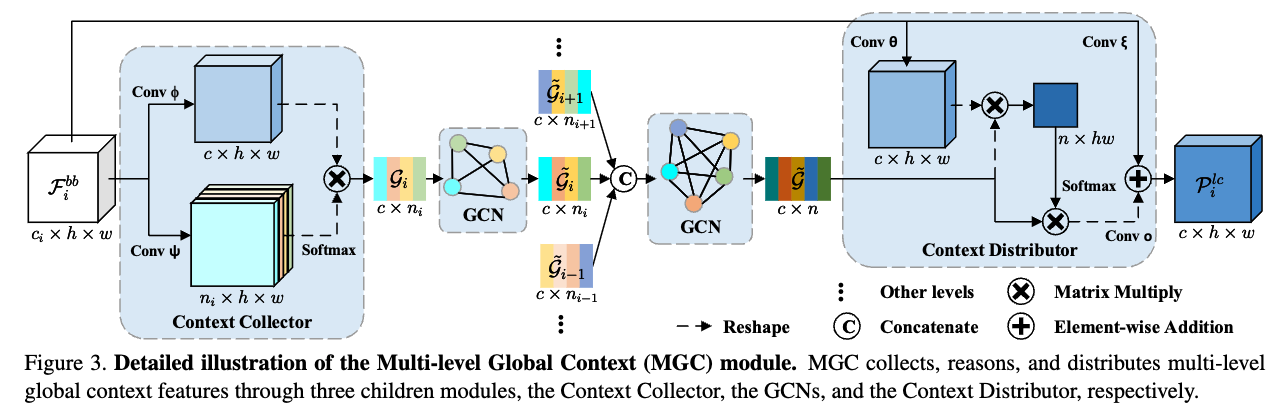
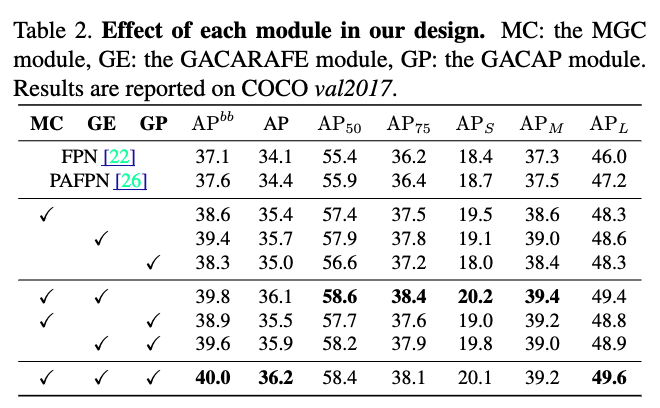
3.1. Multi-level Global Context
- backbone output feature 에 대한 global context를 collecting하기 위해,
각각의 feature map을 GCN 1에 보냄.
각각의 결과들을 concat하여 GCN 2에 보냄.
최종적으로 얻어진 multi-level global context를 현재의 에 distribute함.
global context가 embedding된 , 즉 를 얻음.
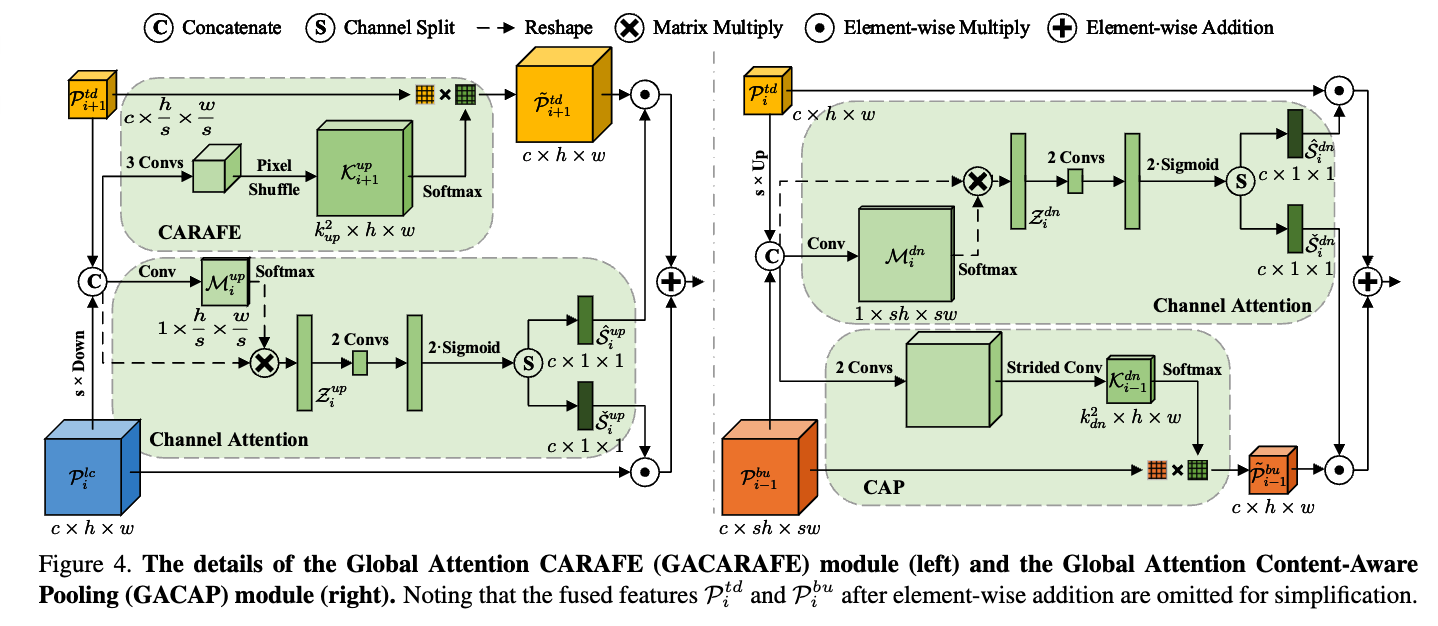
3.2. Global Attention CARAFE
3.3. Global Attention Content-Aware Pooling
4. Experiments
critique
구조가 너무 복잡함.
왜 저렇게 만들었는지에 대한 설명(당위성)이 많이 떨어짐.
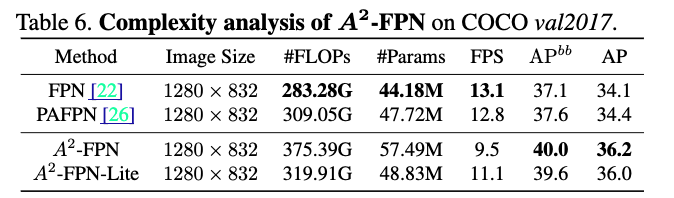
Table 6에서 볼 수 있듯이, #FLOPs, #Params가 매우 많이 늘어남. 그에 따라 FPS도 느려짐.
efficient한 A2-FPN Lite가 있긴 있던데, 전체적으로 efficiency는 무시하고 layer만 마구마구 때려넣은 느낌.
문제 제기는 좋았으나, 제안 방법이 아쉬움...
