[2021 ICCV] FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
Paper Info.

Abstract
-
most existing approaches들은 simplicity를 위해 the issue of feature alignment를 간과하고 있다.
upsampled feature maps과 local feature maps 간의 direct pixel addition은
misaligned contexts를 초래하여,
특히 object boundaries에서 mis-classifications in prediction으로 이어진다. -
이 논문에서는
(1) upsampled higher-level features를 contextually align하기 위해
transformation offsets of pixels을 학습하는 feature alignment module을 제안한다.
또한, (2) the lower-level features with rich spatial details을 강조하기 위해
featur selection module을 제안한다. -
그런 다음,
이 두 module을 top-down pyramid architecture에 통합하여,
Feature-aligned Pyramid Network (FaPN)을 제안한다.
1. Introduction
- Dense prediction은
object location을 위한 rich spatial details와
object classification을 위한 strong semantics를
모두 필요로 한다.
일반적으로 이 문제를 해결하기 위한 two common practices가 존재한다.- different atrous rates를 가진 atrous (=dilated) convolution을 사용하여 spatial resolution 감소 없이
long-range information (i.e. semantic context)을 효과적으로 포착하는 것이다. - ConvNet의 default bottom-top pathway를 기반으로
top-down feature pyramid를 구축하는 것이다.
구체적으로,
(higher-level) spatially coarser feature maps을 upsampled한 후,
이에 대응하는 bottom-up path-way에서 나온 feature map과 merging한다.
- different atrous rates를 가진 atrous (=dilated) convolution을 사용하여 spatial resolution 감소 없이
(문제 제기)
- 그러나 일반적으로 사용되는 upsampling operations (e.g. nearest neighbor)의 non-learnable nature (특성)과
the repeated applications (반복되는 적용) of downsampling and upsampling으로 인해
inaccurate correspondences (i.e. feature misalignment) between bottom-up and upsampled features가 발생한다.
이러한 misaligned features는 이후 layers에서 학습에 부정적인 영향을 미쳐, 특히 object boundaries에서 final predictions이 mis-classification되는 결과를 초래한다. (?)- (?) 나의 해석: object boundary에 있는 pixel의 feature가 흐릿하게 섞여 정확하게 예측하지 못하거나 배경으로 잘못 prediction할 수 있다는 말인듯.
(제안)
-
feature misalignment 문제를 해결하기 위해,
우리는 a learned offset으로 convolution kernel의 각 sampling location을 조정하여
upsampled feature maps을 a set of reference feature maps에 align하도록 학습하는
feature alignment module을 제안한다. (?) -
또한, accurate location을 위해
excessive (많은) spatial details을 포함하는 bottom-up feature maps을 adaptively 강조할 수 있는
feature selection module을 제안한다.
- 위 두 module을 top-down pyramidal architecture에 통합하여
Feature-aligned Pyramid Network (FaPN)을 제안한다.
(실험 및 기여)
-
개념적으로, FaPN은 기존의 bottom-up ConvNet backbones에 쉽게 통합되어 a pyramid of features at multiple scales을 생성할 수 있다.
FaPN은 특히 small objects and on object boundaries에서 a siginificant improvement in dense prediction performance을 보였다. -
Our key contributions are:
- (1) upsampled (higher-level) features를 contextually align 하기 위해
a feature alignment module that learns transformation offsets of pixels과,
(2) (lower-level) features with rich spatial details을 강조하기 위해 feature selection module
을 개발했다. - (1), (2)를 통합하여, multi scale features를 생성하기 위한 FPN의 enhanced drop-in replacement (대체품)으로서
Feature-aligned Pyramid Network (FaPN)을 제안한다. 
- (1) upsampled (higher-level) features를 contextually align 하기 위해
2. Related Work
Feature Pyramid Network Backbone
- 기존의 dense image prediction methods는 크게 two groups으로 나눌 수 있다.
- The first group은
capturing long-range information without reducing resolutions을 위해
the receptive field of conv filters를 enlarge하기 위한 atrous convolutions을 사용한다.- DeepLab은 semantic segmentation을 위해 atrous conv를 사용한 초기 모델.
Atrous Spatial Pyramid Pooling module (ASPP)를 제안함.
ASPP를 기반으로, a family of methods [4-6]이 개발됨. - 하지만, multiple scales의 feature maps을 생성하는 능력 부족으로 인해
this type of methods는 semantic segmentation 이외의 other dense prediction tasks에 적용하는 데에 한계가 있다.
- DeepLab은 semantic segmentation을 위해 atrous conv를 사용한 초기 모델.
- The second group은
an encoder-decoder network, 즉 bottom-up and top-down pathways를 구축하는 데 중점을 둔다.
top-down pathway는 step-by-step upsampling을 통해 high-level semantic context를 low-level features로 backpropagate하는 데 사용된다.
다양한 dense image prediction tasks를 위해 제안된 encoder-decoder methods는 다수 존재한다.- DeconvNet은 upsample operations with learnable parameters 즉, deconvolution을 사용하자고 제안한 the earliest works이다.
- ..
- The first group은
Feature Alignment
- step-by-step downsampling으로 인해 loss of boundary detail이 증가하는 문제를 해결하기 위해,
- SegNet [2]은 encoder에서 max-pooling indices를 저장하고, decoder에서 해당 저장된 max-pooling indices를 사용하여 feature map을 upsampling한다.
- SetNet처럼 encoder에서 spatial information을 미리 기억하는 대신, GUN [34]는 decoder에서 upsampling 이전에 guidance offsets을 학습하고, 이후 이 offsets을 따라 feature map을 upsample한다.
- RoIPool에서 quantization으로 인해 발생하는 RoI와 extracted features 간의 misalignment를 해결하기 위해,
RoI Align [13]은 quantization을 피하고 각 RoI 값을 linear interpolation을 통해 계산한다 - ....
- AlignSeg [17]과 SFNet [21]은 우리의 방식과 유사한 motivation을 가진 two concurrent (동시) 연구로, 둘 다 flow-based alignment methods이다.
특히, AlignSeg는 a two-branched bottom-up network를 제안하고, feature aggregation 전에 two types of alignment modules을 사용하여 feature misalignment 문제를 완화한다.
반면, 우리는 bottom-up network를 기반으로 top-down path를 구성하고, the coarest (거친) resolution (top)부터 the finest (세밀한) resolution (bottom)까지 점진적으로 feature를 align하는 방식을 제안한다.
구체적으로, 우리는 2x upsampled features를 해당하는 bottom-up feature와 align하는 데 집중하며,
AlignSeg는 다양한 배율 (i.e. 1/4, 1/8, 심지어 1/16로 upsampled된 feature)을 직접 align하려고 시도한다.
이는 복잡하고 not always be feasible하다.
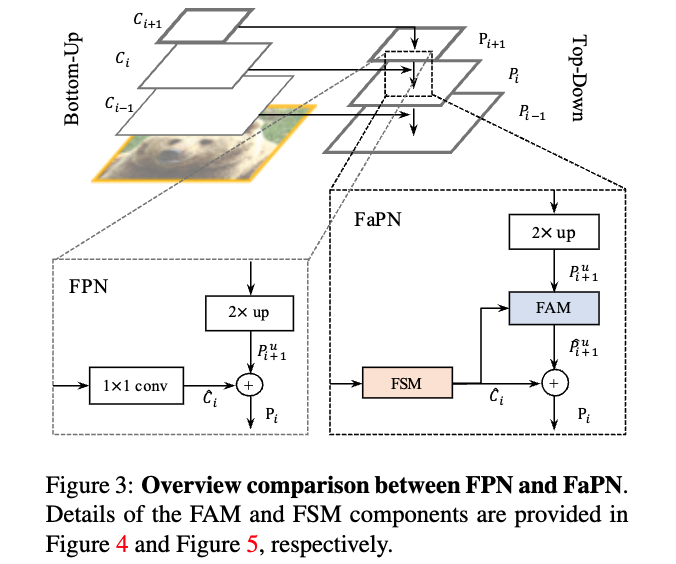
3. Feature-aligned Pyramid Network
- we present the general framework of our method,
comprised ofa Feature Selection Module (FSM)anda Feature Alignment Module (FAM),

3.1. Feature Aligment Module (FAM)
다시 한 번 문제 제기
-
the recursive use of downsampling operations 때문에,
the upsampled feature maps 와 그에 해당하는 bottom-up feature maps 사이에 spatial misalignment가 있다.
그러므로, element-wise addition or channel-wise concatenation에 의한 feature fusion은
the prediction around object boundaries를 해칠 것이다. -
feature aggregation하기 전에,
을 그 reference 에 aligning하는 것이 필수적이다.
(즉, 이 제공하는 spatial location information에 대해 적절하게 를 조정해야 한다.)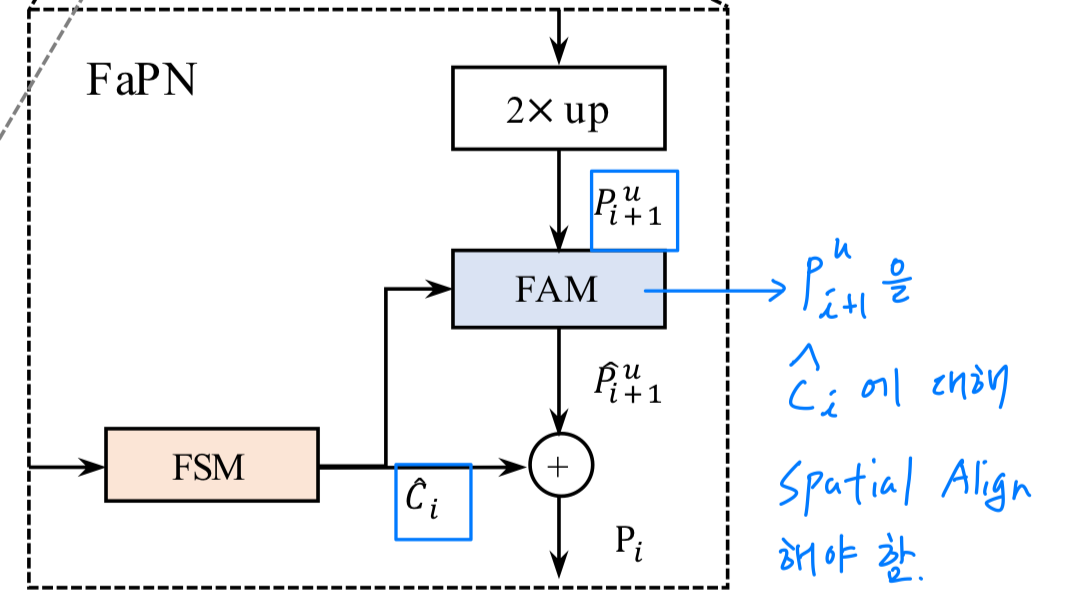 이 논문에서,
이 논문에서,
the spatial location information은 2D feature maps으로 표현되며,
각 offset value는 의 각 point와 그에 해당하는 의 point 사이의 2D space에서의 the shifted distances (이동 거리)로 볼 수 있다.
Figure 4에서 보여지듯이, feature alignment는 수학적으로 다음과 같이 formulated될 수 있다:
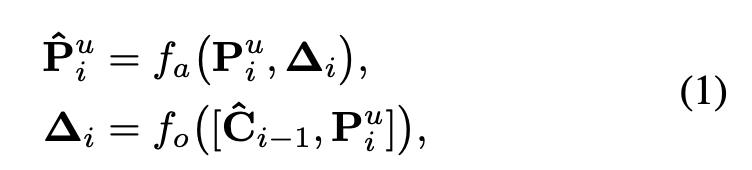 는 the concatenation of and 이고,
는 the concatenation of and 이고,
이는 upsampled features와 그에 해당하는 bottom-up features 간의 spatial difference를 제공한다.
는 the functions for learning offset from the spatial differences,
는 aligning feature with the learned offfsets을 의미한다.
이 논문에서, and 는 deformable conv + activation + standard conv of the same kernel size로 구현된다.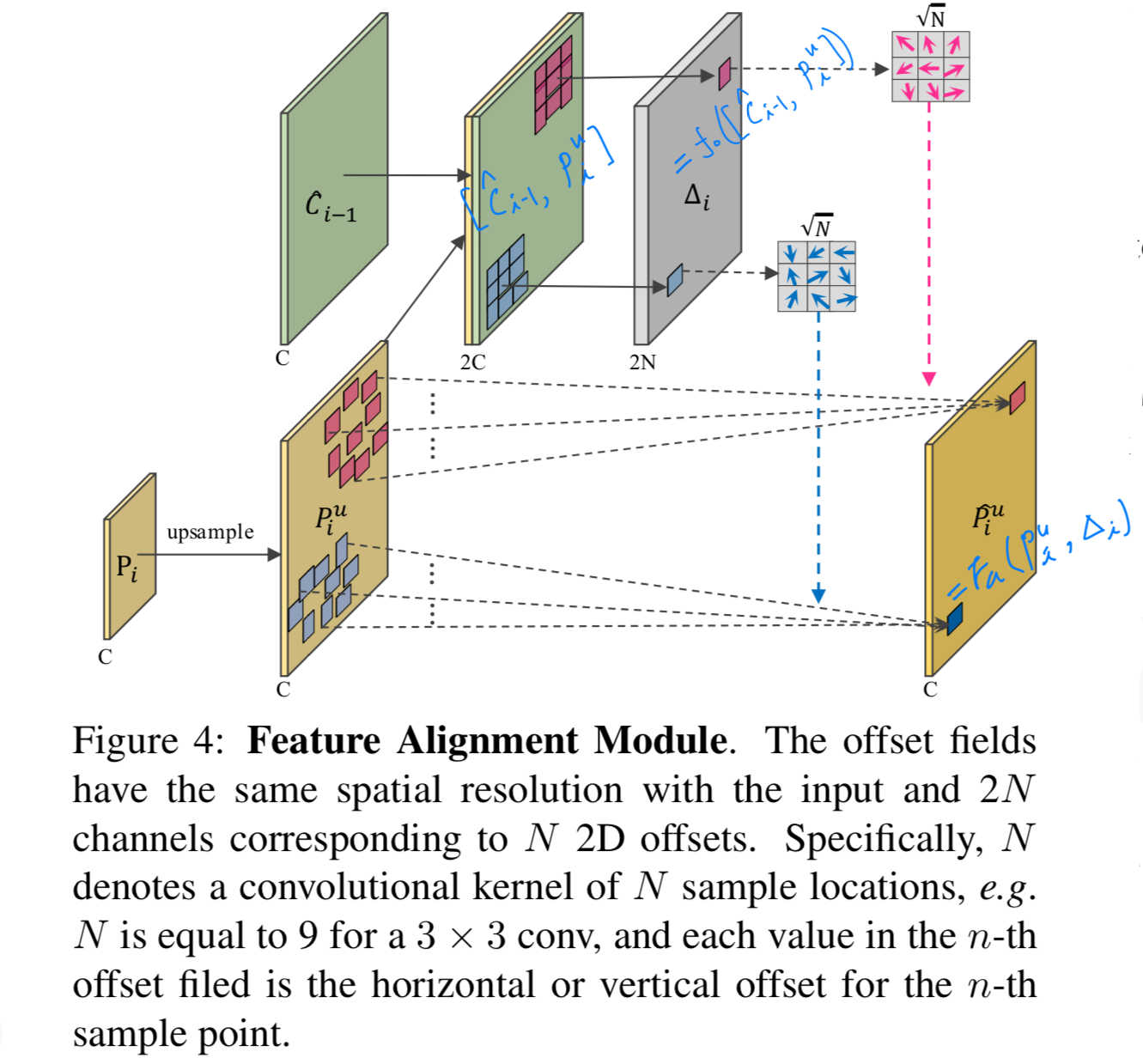
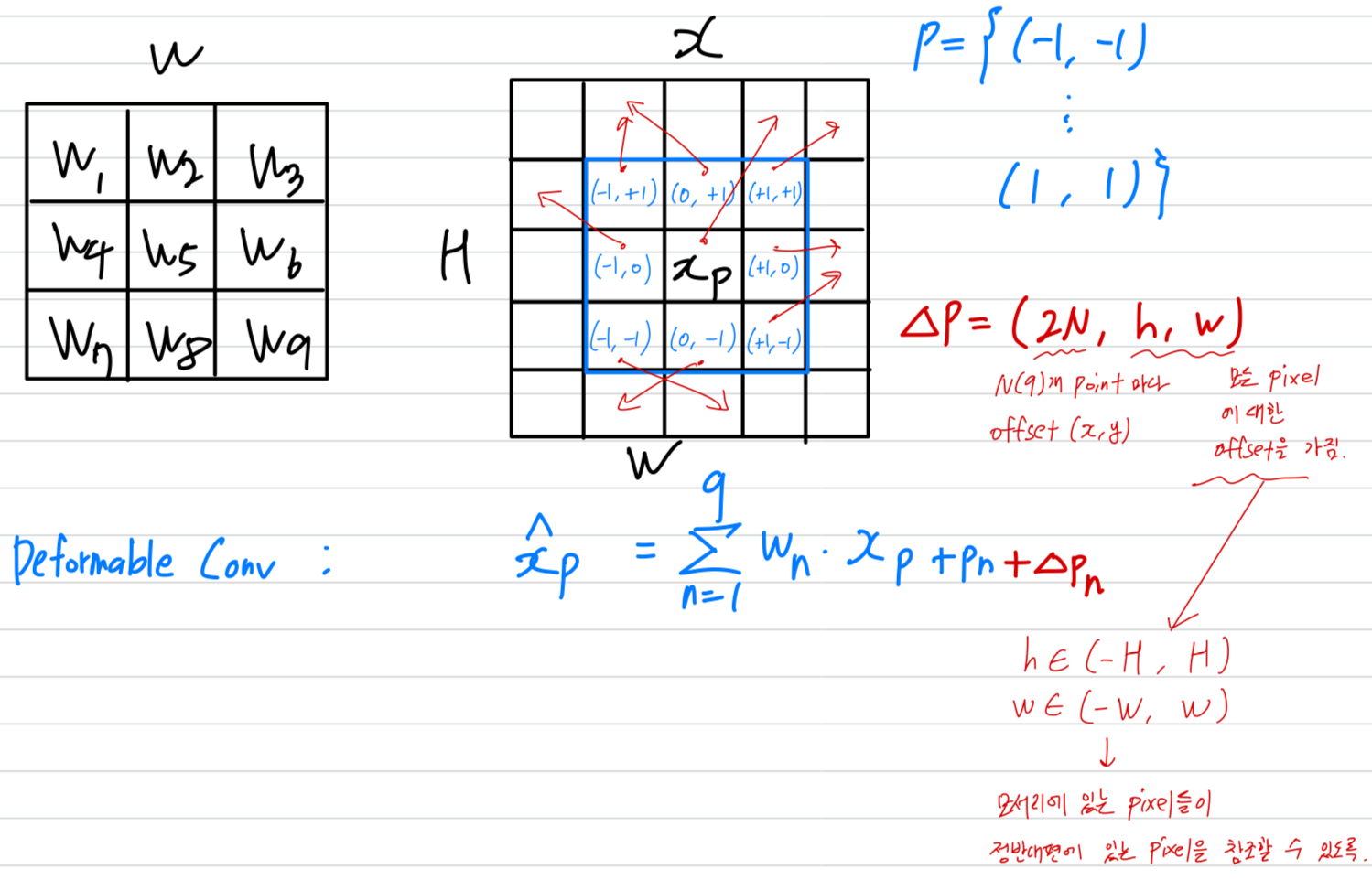
deformable conv review
- 여기서, 우리는 deformable convolution을 간략히 review하고,
왜 deformable conv가 our feature alignment function에 사용되었는지와 some important implementation details를 설명할 것이다.
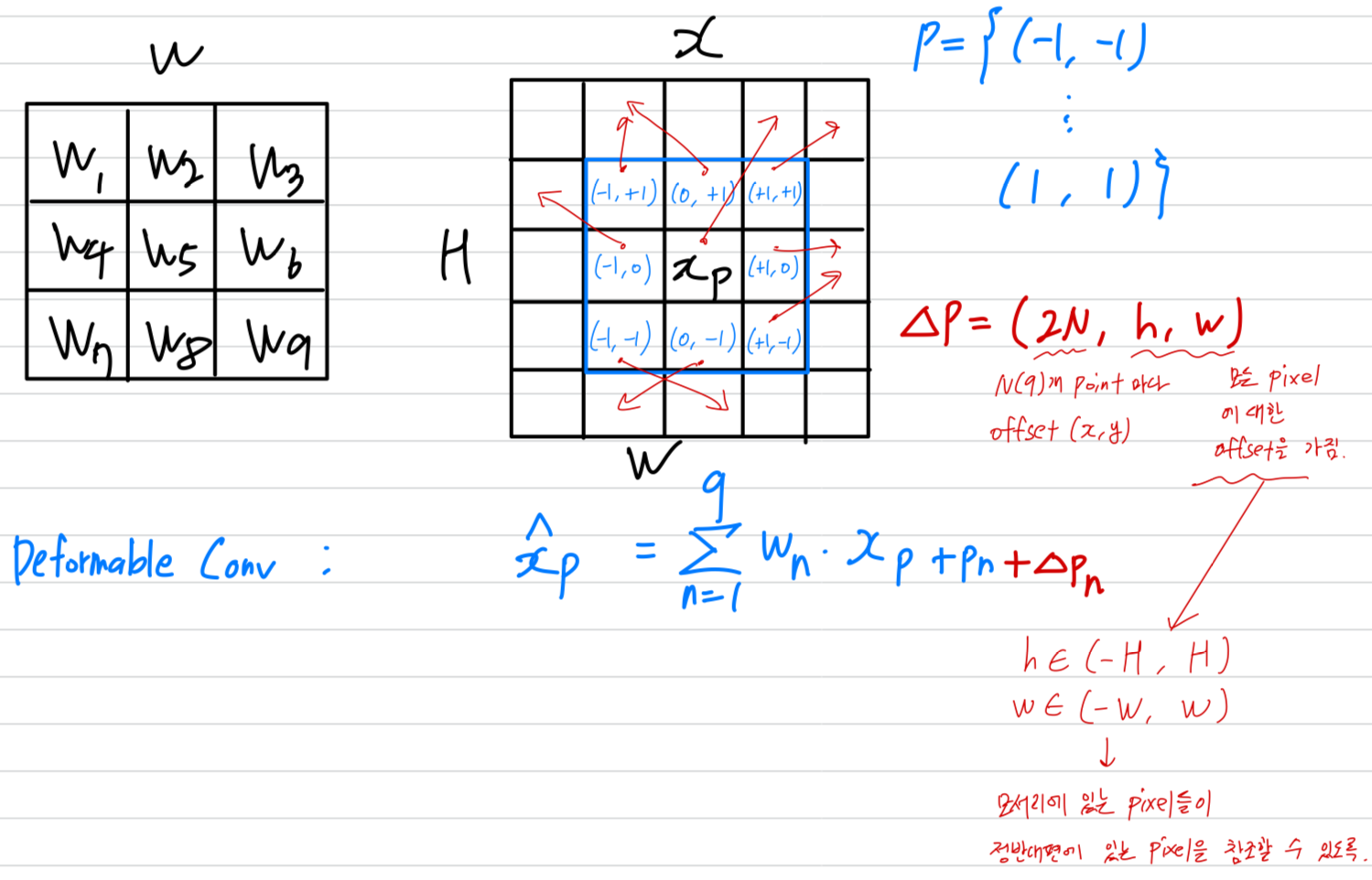
우선, input feature map 와 conv layer를 정의한다.
그러면 conv kernel을 거친 후의 any position 에서 output feature는 다음과 같다.
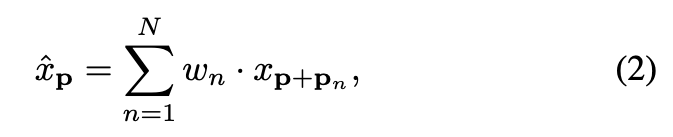 은 the size of the conv layer (즉. ),
은 the size of the conv layer (즉. ),
과 은 각각 -th conv sample location에 대한 weight and the pre-specified offset을 나타낸다.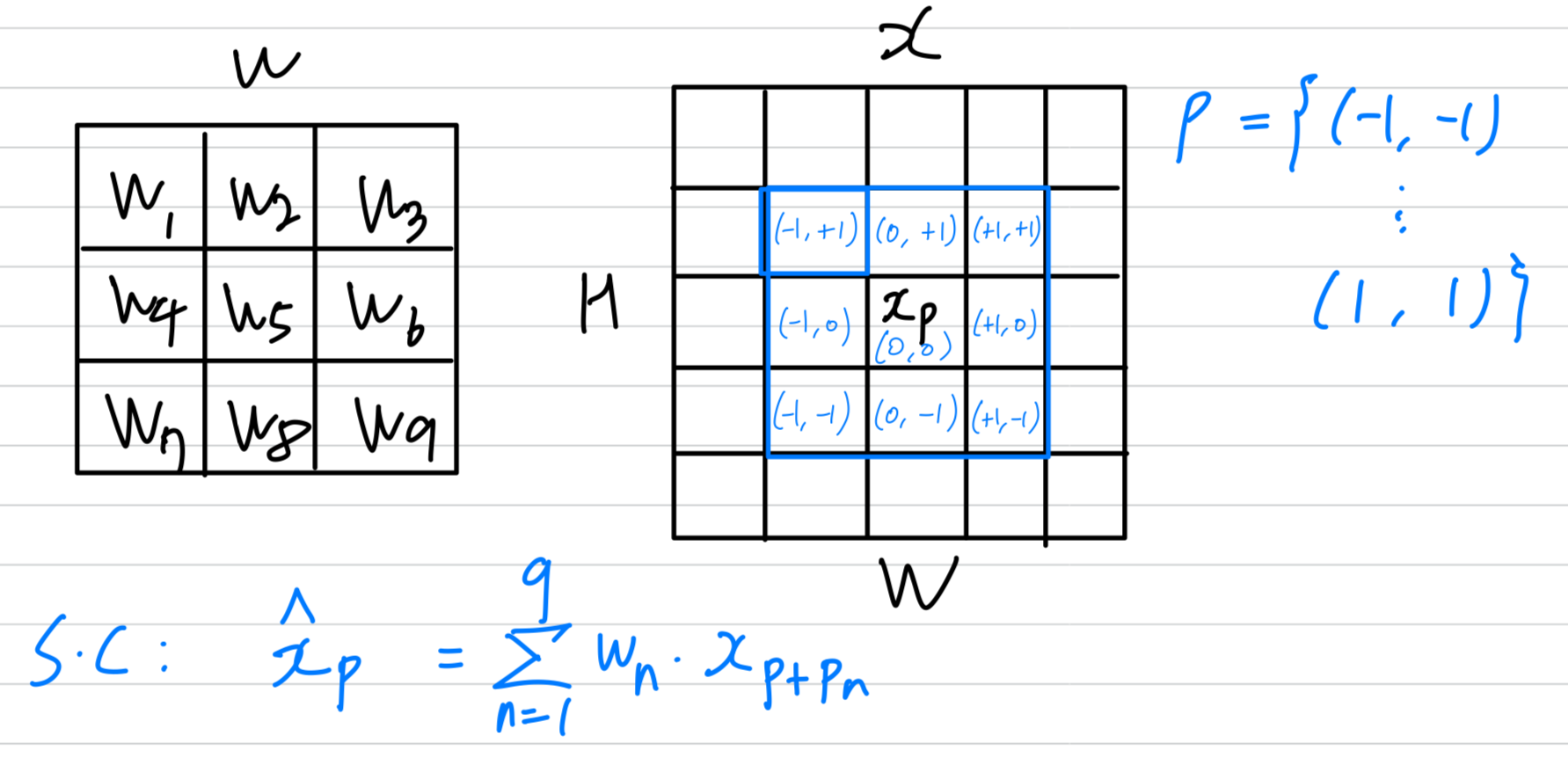
기존의 pre-specified (사전 정의된) offsets 외에도, deformable conv는 sample locations마다 적응적으로 additional offsets 을 학습하려고 시도하며,
위의 Equation (2)은 다음과 같이 다시 표현할 수 있다:
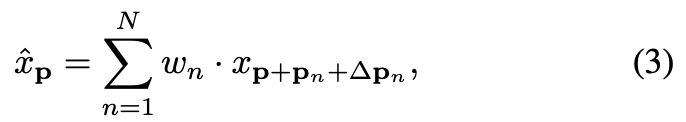 where each is a tuple , with ,
where each is a tuple , with , 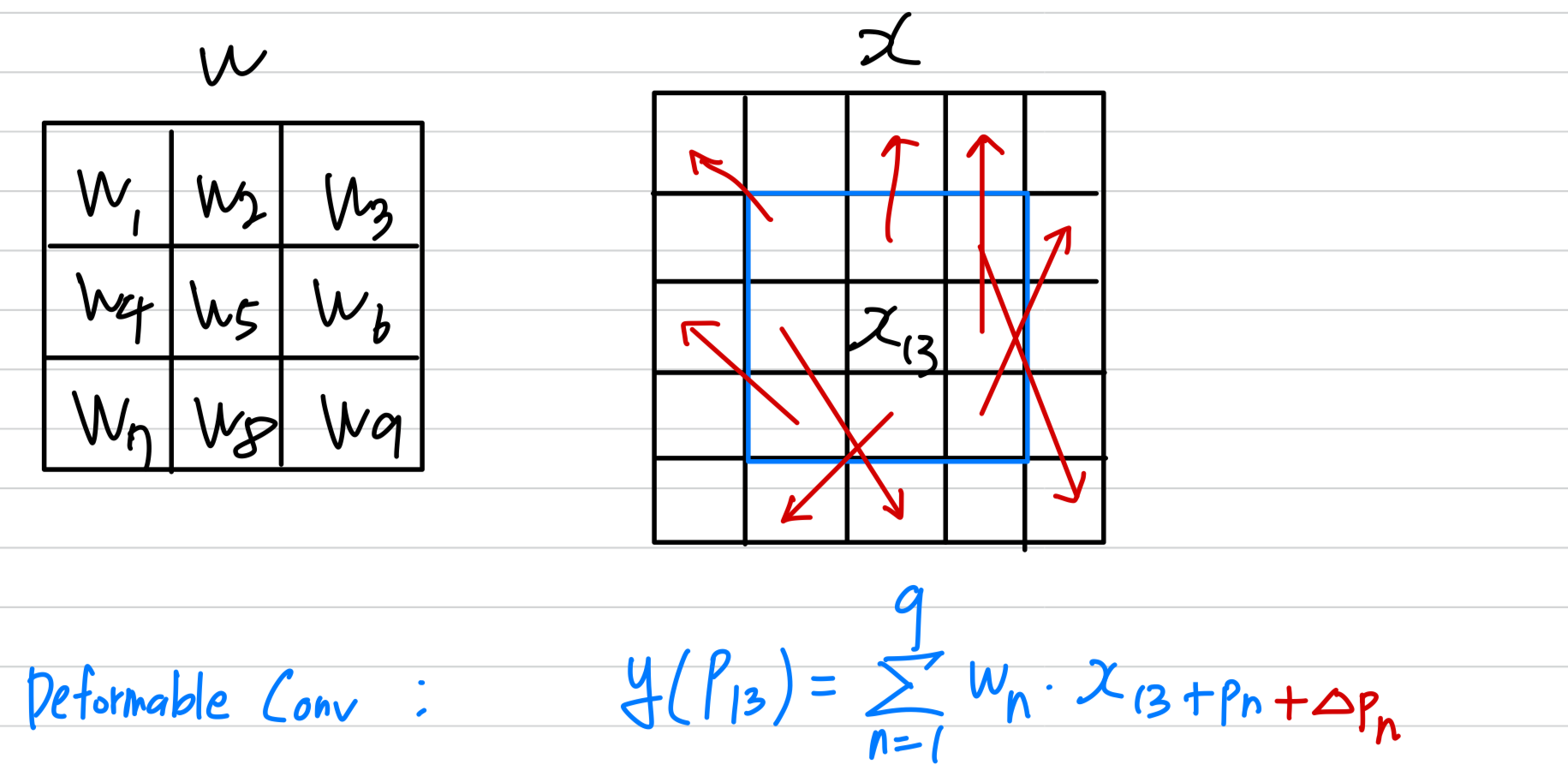
저자가 deformable conv를 사용한 구체적인 방법
- 우리가 deformable convolution을 에 적용하고, 과 의 concatenation을 reference으로 사용할 때,
(즉, offset fields ,
deformable convolution은 Equation (1)을 따르는 offsets에 따라 그 convolutional sample locations을 조정할 수 있으며,
결과적으로 와 간의 spatial distance에 따라 를 aligning할 수 있게 된다.

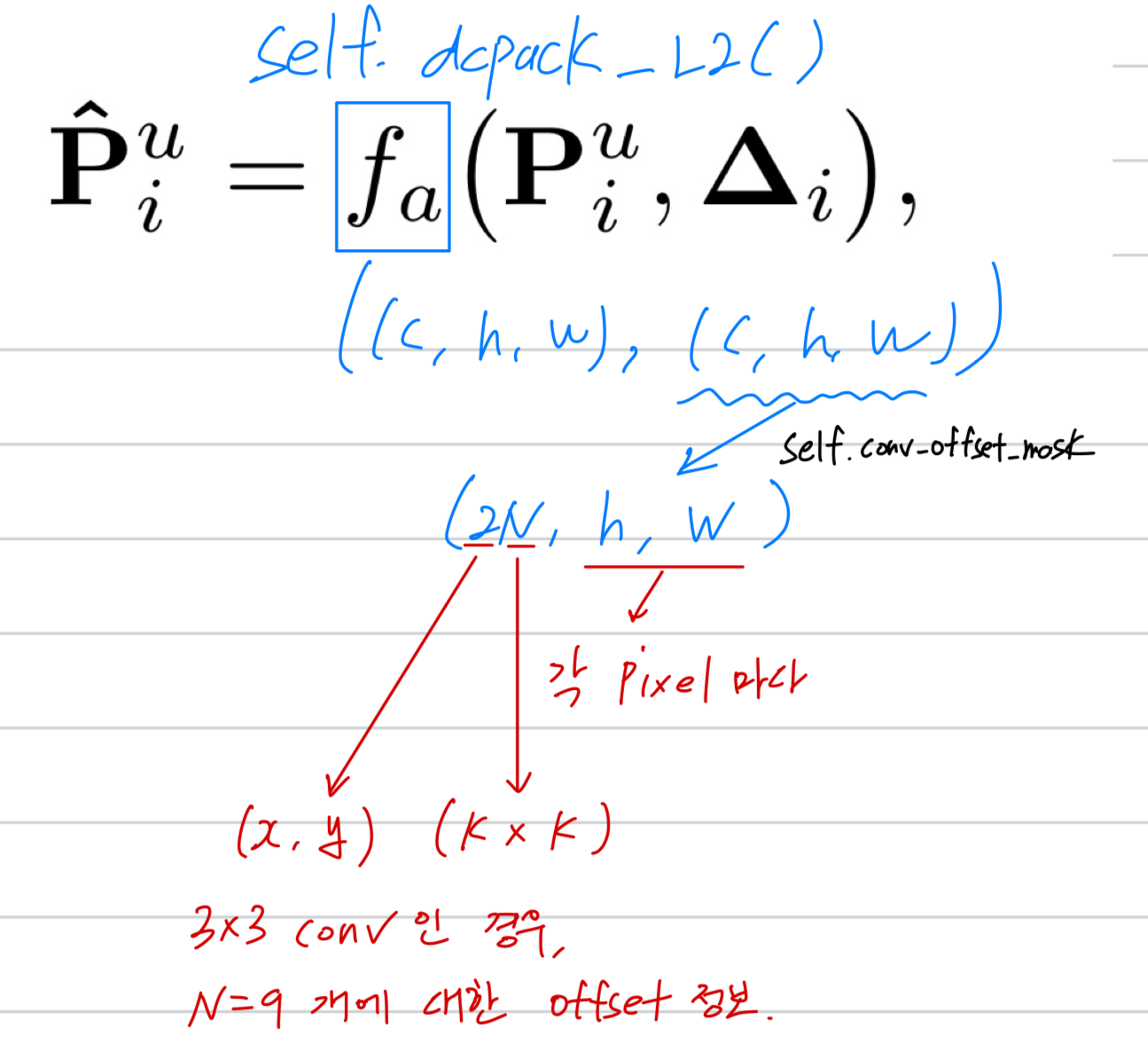

3.2. Feature Selection Module
-
detailed features에 대해 channel reduction하기 이전에,
accurate allocations을 위해 excessive spatial details을 포함한 the important feature maps을 강조하고,
redundant feature maps은 supressing하는 것이 중요하다.
단순히 conv를 사용하는 대신, 우리는 feature maps의 importance를 명시적으로 modeling하고 그에 따라 re-calibrate할 수 있는 Feature Selection Module (FSM)을 제안한다. -
FSM의 dataflow은 Figure 5.에 그려져 있다.
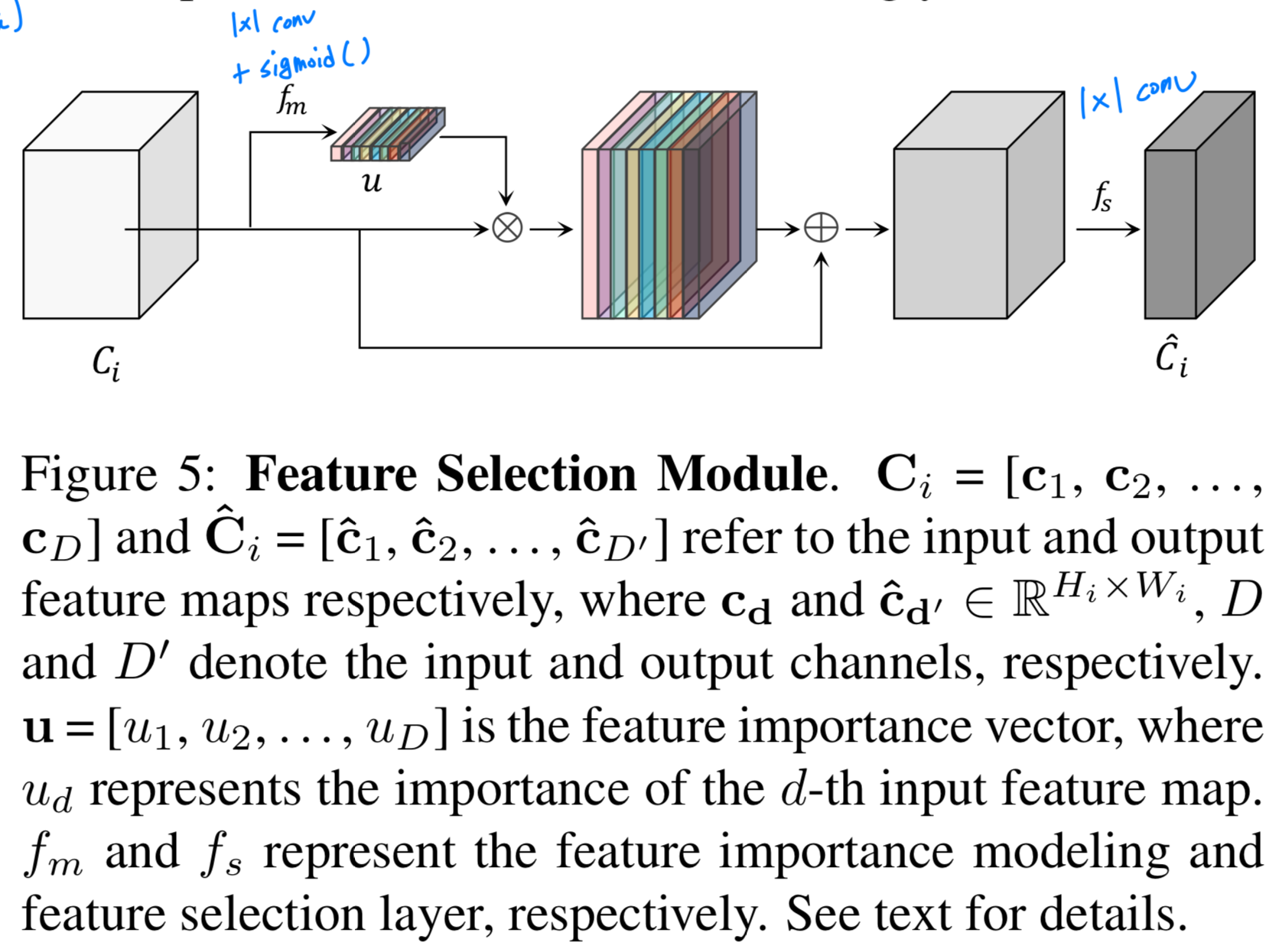 먼저, 각 input feature map 에 대한 global information 은 global average pooling을 통해 추출되며,
먼저, 각 input feature map 에 대한 global information 은 global average pooling을 통해 추출되며,
를 바탕으로 각 feature map의 importance를 modeling하는 layer 은 (즉, 1x1 conv + sigmoid activation)은 importance vector 를 출력한다.
그 다음,. 원래의 input feature map은 importance vector와 곱해져 scaled되며,
이 scaled feature maps에 original feature maps을 더해 rescaled feature maps을 생성한다.
마지막으로, rescaled feature map에 1x1 cvonv로 구성된 feature selection layer 을 적용하여,
important feature maps은 유지하고 useless feature maps은 제거함으로써 channel reduction을 수행한다.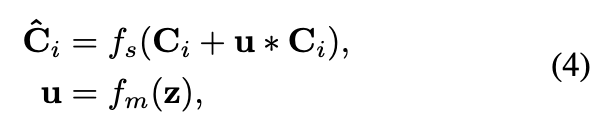
-
FSM의 design은 Squeze-and-Excitation module에서 영감을 받았다.
주요 차이점은 input과 scaled feature map 사이에 skip connection을 추가한 점이다.
실험적으로, 이 skip connection을 통해 scaled feature map을 lower bounding하는 것이 중요하다는 것을 발견했는데,
이는 특정 channel response가 over-amplified되거나 over-suppressed되는 것을 방지한다. -
FSM에서 선택되고 scaled된 feature들은 FAM에 공급되어 alignmente offsets 학습을 위한 references로 활용된다.
4. Experiments
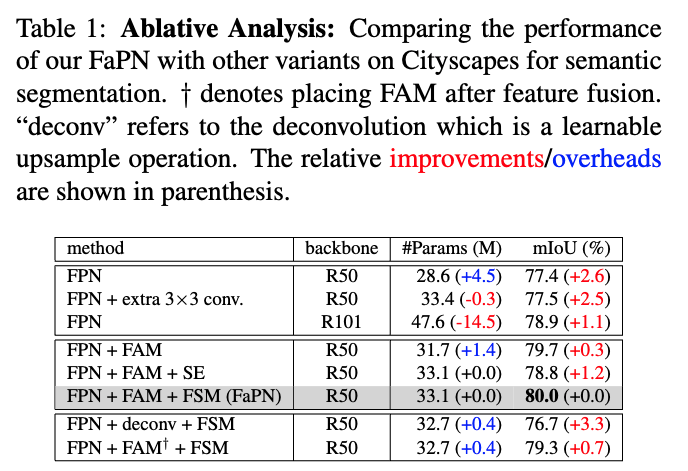
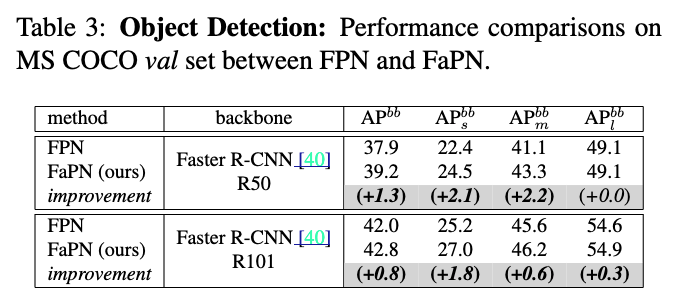
내 생각
- 1.에 대한 문제 제기:
- higher-level features를 align하기 위해 lower-level features에 맞추어 transformation하는 것은 higher-level feature의 semantic 정보 손실을 초래할 수 있음.
따라서 lower-level features를 higher-level features에 맞춰야 한다고 생각함.- 더 중요한 점은 high-level features와 low-level features의 receptive field 관점에서 생각해봐야 함.
high-level features는 low-level features보다 raw image에 대해 receptive field가 훨씬 큼.
이러한 특성을 갖는 high-level features를 upsampling한다면
