[2021 ICLR] TRAINING BATCHNORM AND ONLY BATCHNORM: ON THE EXPRESSIVE POWER OF RANDOM FEATURES IN CNNS
Paper Info.

OpenReview
Abstract
-
DL techniques은 training affine transformations of features를 학습하는데 의존한다.
이러한 것들 중 가장 prominent한 것은 feature normalization technique BatchNorm이다.
BN은 activations을 normalize한 후, 그 다음으로 a learned affine transform을 적용한다. -
이 연구에서,
우리는 affine parameters의 role and expressive poser를 이해하는 데 중점을 둔다.
the learned features가 transform하는 것의 contribution을 분리하기 위해,
우리는 BN의 affine parameter만 training하고, network의 나머지 weights는 random initializations했을 때의 성능을 분석했다. -
이와 같은 설정은 training 방식에 significant limitations을 부과함에도 불구하고, 놀라울 정도로 높은 성능을 보인다.
예를 들어, sufficiently deep ResNets은 CIFAR-10에 대해 82%, ImageNet에 대해 32%의 top-5 acc를 도달했다.
이는 Network의 다른 위치에서 동일한 수의 randomly chosen parameters를 학습했을 때보다 훨씬 높은 성능이다. -
BN이 이러한 성능을 달성할 수 있는 이유 중 하나는,
학습 과정에서 random features의 약 1/3을 자연스럽게 disable하는 효과를 학습하기 때문이다.
이러한 결과는 DL에서 affine parameter가 가지는 expressive power를 보여줄 뿐만 아니라,
random features를 simply shifting and rescaling함으로써 구성된 neural networks의 expressive power를 characterize(특성화)한다는 점에서 의미를 갖는다.- 질문: random feature를 일부분 disable하는 것과 꽤 괜찮은 성능을 달성하는게 어떤 연관성이 있는데?)
- GPT 답변: random feature를 disable하는 것은 그나마 유용한 feature를 선택해서 쓴다는 말임.
즉, BN의 affine parameter는 random feature 중 classification에 쓸모없는 것을 자동으로 제거할 수 있도록 학습한다. - 질문: 아직도 이해할 수 없어. BN parameter를 제외한 나머지 weight들이 random initialize되었는데 어떻게 그 중에 유용한 feature만 able시킬 수 있다는거야?
1. Introduction
- 딥러닝 전반에 걸친 기존 연구들을 보면,
다양한 techinque들이 feature에 대한 affine transformation을 학습하는 데 의존하고 있다.
이는 각 feature에 learned coefficient 를 곱하고, a learned bias 를 더하는 형태로 이루어 진다.
이러한 방식은 광범위하게 활용되고 있다.
이와 같은 affine parameter의 대표적인 exampels은 BatchNorm과 같은 feature normalization techniques에서 찾아볼 수 있다.
이러한 parameter들은 실용적으로 매우 중요하며 거의 모든 현대 neural networks에 포함되어 있음에도 불구하고,
feature를 transform하는 데 사용되는 affine parameter의 expressive power에 대해서는 상대적으로 알려진 바가 없다.
- 이 질문에 대한 insight를 얻기 위해, 본 연구에서는 BN에 포함된 and parameters에 집중한다.
BN은 CV에서 거의 모든 deep CNN에서 사용되고 있으며, 이는 researchers and practitioners들이 매일 학습시키는 수많은 model에
이러한 affine parameter가 기본적으로 포함되어 있음을 의미한다.
BatchNorm의 and 에 대해 우리가 알고 있는 한 가지 사실은,
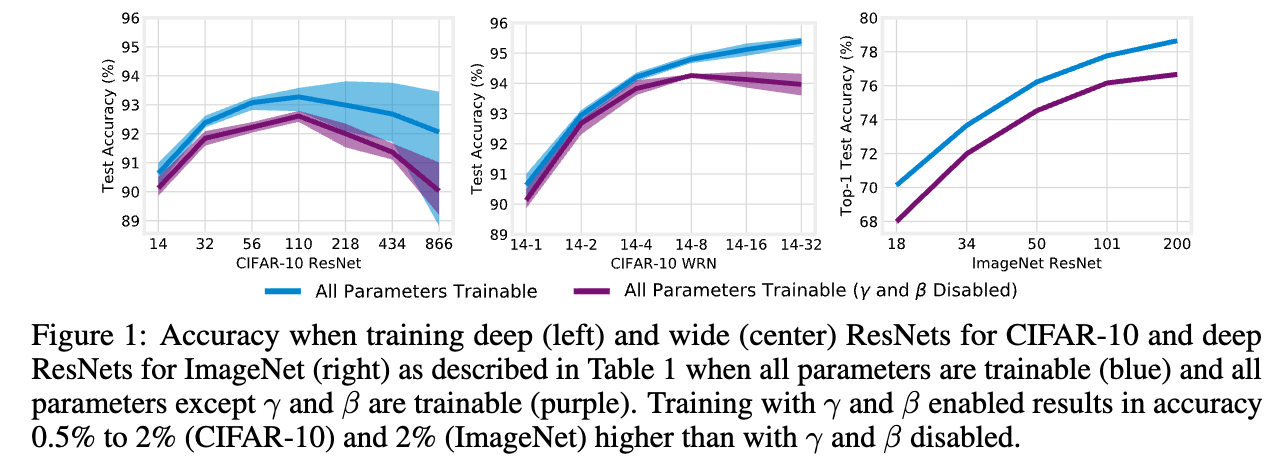
이들이 ResNet의 성능에 meaningful effect를 미친다는 점이다. (Figure 1)
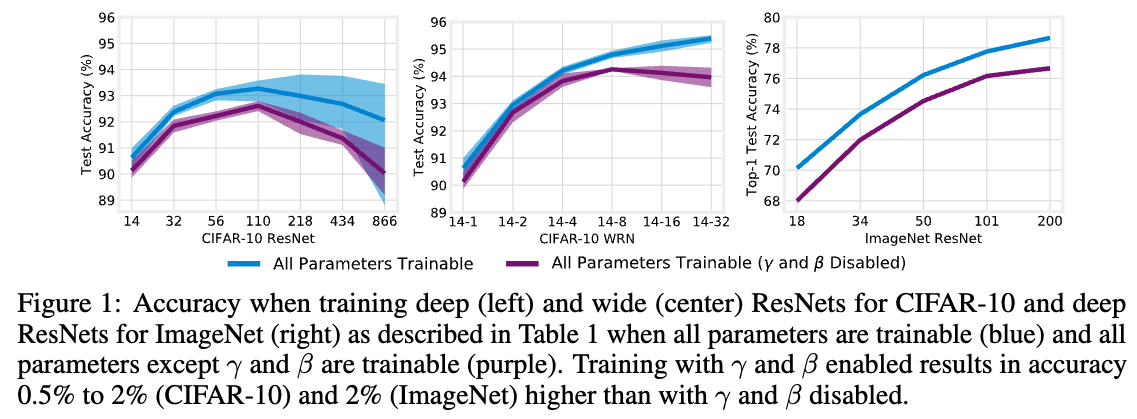 하지만 향상 and 가 정확히 어떤 역할을 수행하는지 분리하여 분석하기는 쉽지 않다.
하지만 향상 and 가 정확히 어떤 역할을 수행하는지 분리하여 분석하기는 쉽지 않다.
- 보다 일반적으로, per-feature affine parameters를 과학적으로 분석하는 데 있어 central challenge는
이들이 transform하는 feature 자체의 contribution과
affine parameter의 contribution을 구분하는 것이다.
실제 환경에서는 이러한 affine parameter가 BN의 경우처럼 feature와 함께 jointly trained되거나,
feature 학습 이후에 학습된다.
본 연구에서는 이 parameter들을 독립적으로 분석하기 위해,
a network composed entirely of random features에서 and parameters in BN만을 학습한다.
- 비록 network는 the same number of features를 유지하지만,
only a small fraction of parameters (at most 0.6%)에 불과하다.
이 실험 설정은 모든 학습이 and 에서만 이루어지도록 강제하며,
그 결과 random feature를 단순히 scaling and shifting 하는 것만으로 구성된 network의 expressive power를 평가할 수 있게 한다.
- 우리는 본 연구의 목적이 SOTA를 달성하는 데 있지 않음을 강조한다:
본 연구의 목표는 과학적인 관점에서,
이와 같이 limited capacity가 meaningful functions을 어떻게 represents하는지,
그리고 어떤 mechanism을 통해 그러한 성능을 내는지 분석하는 데 있다.
We make the following findings:

2. RELATED WORK
BatchNorm
- BN은 deeper networks를 학습 가능하게 하고 SGD를 sooner converge하게 한다.
하지만 어떤게 그것을 가능하게 하는지에 대한 underlying mechanism이 debated되고 있다.- BN의 저자들은 BN이 internal covariate shift (ICS)를 줄인다고 주장했다.
ICS는 "training 동안 각 layer's input이 변화하여, lower learning rates를 필요로 하게 되는 현상"을 의미한다.(Ioffe & Szegedy, 2015) - 그러나 Santurkar et al. (2018)은 BN 이후에 인위적으로 ICS를 유발하더라도 training time에 거의 변화가 없음을 보임으로써 이러한 설명에 의문을 제기하였다.
- emprical evidence에 따르면,
BN은 optimization landscape를 smoother하게 만들며 divergence를 초래할 수 있는 activations exploding(폭주)를 방지하는 "safety precaution"로 작동하고 (Santurkar et al., 2018),
network가 neuron을 더 효율적으로 활용할 수 있도록 한다 (Balduzzi et al., 2017; Morcos et al., 2018). - 이론적 연구에 따르면, BN은 weight magnitude and direction에 대한 optimization을 decouple하며 (Kohler et al., 2019),
이는 weight normalization이 명시적으로 수행하는 역할과 유사하다 (Salimans & Kingma, 2016).
또한 BN은 gradient magnitudes가 equilibrium (평형) 상태에 도달하도록 유도하고 (Yang et al., 2019),
새로운 형태의 regularization 효과를 유발한다고 주장한다 (Luo et al., 2019).
- BN의 저자들은 BN이 internal covariate shift (ICS)를 줄인다고 주장했다.
-
본 논문은 이러한 BN의 overall effect를 다루는 기존 연구들과 달리,
특히 affine parameters의 role and expressive poser에 초점을 맞춘다.
관련 연구들은 일반적으로 BN의 normalization 측면을 강조하며,
일부 연구에서는 or 중 하나, 혹은 둘 모두를 생략하기도 한다.
또 다른 연구들은 and 를 별도로 고려하지 않고 BN을 하나의 black-box로 다룬다. -
주목할 만한 예외로는 Luo et al. (2019)의 연구가 있는데,
이들은 BN이 decay를 유도한다는 것을 이론적으로 보였다.
이는 data-dependent L2 penalty가 에 적용되는 효과로,
본 논문에서 이를 Section 5에서 더 자세히 discuss한다.
Exploiting the expressive power of affine transformations
-
DL literature에서는 feature에 대한 affine transformation의 expressive power를 활용하는 다양한 technique들이 존재한다.
Mudrakarta et al. (2019)은 특정 task에 대해 trained된 a shared network를 고정한 채,
서로 다른 task에 대해 separate sets of per-task BN parameters만을 학습하는
parameter-efficient approach를 제안했다. -
유사하게, Rebuffi et al. (2017)은 하나의 task에서 학습된 network backbone이
다른 task에 adapt할 수 있도록,
BN과 a convolution으로 구성된 residual module을 network에 추가하는 방식을 제안하였다. -
...
Training only BatchNorm
- 우리 연구와 가장 가까운 연구로 Rosenfeld & Tsotsos (2019)는
network의 여러 parts를 initialization 상태로 Freeze하는 실험을 수행하면서
and 만을 학습하는 경우를 살펴봤다.
그러나 이 논문과 우리 연구 사이에는 몇 가지 중요한 차이가 존재한다.- 그들은 단지 "mostly-random networks도 성공적으로 train될 수 있다"는 일반적인 결론만 내린 반면,
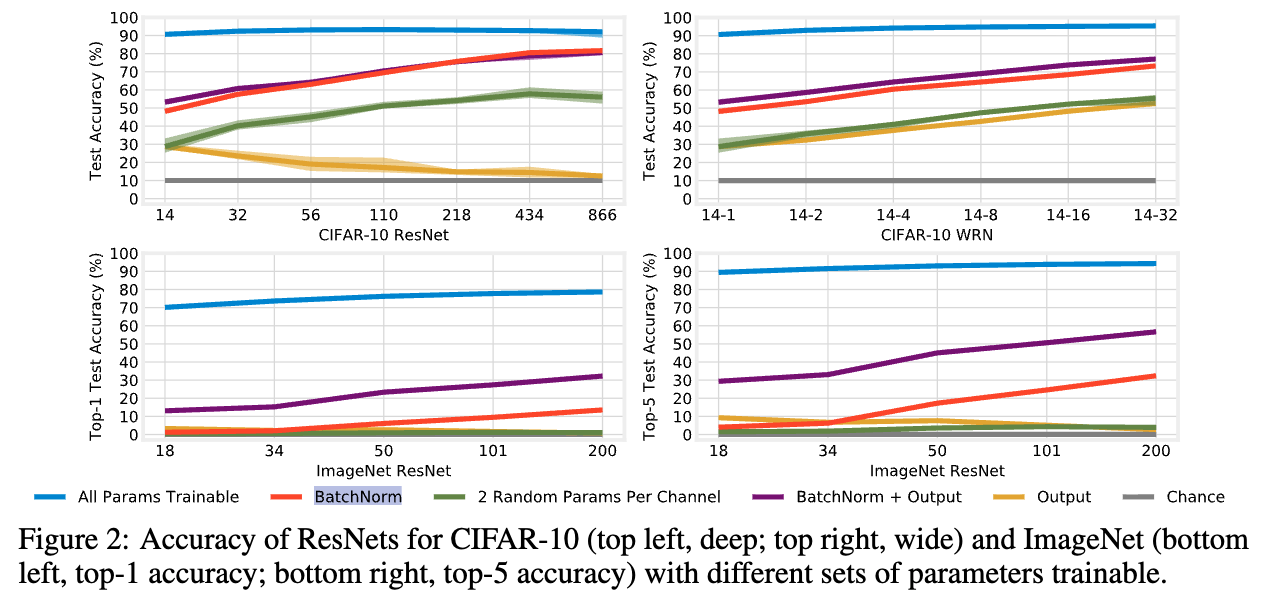
우리는 BN parameter가 다른 parameter들보다 greate expressive power를 가진다는 점을 발견하였다 (Figure 2, green).
사실 그들의 experiments에서는 이러한 차이를 구분해내는 것이 불가능하다.
- 그들은 단지 "mostly-random networks도 성공적으로 train될 수 있다"는 일반적인 결론만 내린 반면,
- Rosenfeld & Tsotsos는 CIFAR-10에서 두 개의 network (DenseNet and an unspecified Wide ResNet)에 대해,
단 10 epoch만 (vs. the standard 100+) BN만을 학습하여 각각 61%와 30%의 accuracy를 얻었다.
반면, 유사한 parameter 수를 기준으로 우리의 방법은 80% and 70%의 accuracy를 달성한다.
이러한 성능 차이는 우리의 결론에 본질적인 영향을 미친다.
즉, 우리는 BN만을 학습하는 것이 동일한 수의 randomly chosen parameter를 학습하는 것보다 명확히 더 높은 accuracy를 낸다는 점을 판단할 수 있었지만,
Rosenfeld & Tsotsos의 결과는 accuracy가 너무 낮아 그러한 distinction을 만들 수 없다.
더 나아가, 우리는 이러한 성능이 BN parameter가 underlying representations을 어떻게 형성하는지를 분석함으로써 그 mechanism을 examining한다. - 마지막으로, Mudrakarta et al. (2019) 역시 a single randomly initialized MobileNet에 대해
BN and a linear output layer만을 학습하는 실험이 있었는데
그들은 이 setting이 "can achieve non-trivial accuracy"는 점을 관찰하는 데 그쳤다.
Random features
-
random features를 기반으로 하는 model을 구성해온 long history가 있다.
perceptron(Block, 1962)은 input and a random vector의 inner product로 정의되는 associator들의 a linear combination을 학습한다.
보다 최근에는 Rahimi & Recht (2009)가 random feature의 linear combination이 당시 표준이던 SVM이나 AdaBoost와 거의 유사한 성능을 낼 수 있음을 이론적, 실험적으로 보였다. -
reservoir computing (Schrauwen et al., 2007)은 echo state networks나 liquid state machines으로도 알려져 있으며,
randomly connected RNN 위에 linear readout만을 학습한다. -
overparameterized networks에서 SGD의 동작을 이론적으로 분석하기 위해,
최근 연구들은 first layer가 충분히 넓어서 학습 중 거의 변하지 않는 two layer models을 사용한다(예: Du et al., 2019). -
이러한 모든 연구 흐름의 공통점은,
random nonlinear features 위에 a trainable linear layer 하나를 얹은 model을 다룬다는 것이다.
이에 반해, 우리의 model은 각 layer의 각 random feature 뒤에 affine parameter가 network 전반에 걸쳐 존재하며, 이 parameter들이 학습된다.
더 나아가, BatchNorm을 activation function 앞에 두는 일반적인 관행(He et al., 2016) 때문에,
우리의 affine parameter들은 nonlinearity 이전에 위치한다는 점에서 기존의 random feature 기반 model들과 본질적으로 다르다.
Freezing weights at random initialization.
-
neural networks는 randomly initialized되며, 이 상태에서의 성능은 우연(chance)에 부로가하다.
그럼에도 불구하고, 이 weights 중 일부 혹은 전부 유지한 채로도 high accuracy에 도달하는 것이 가능하다. -
Zhang et al. (2019a)는 trained CNNs에서 많은 individual layers를 random i.i.d initialization 상태로 되돌려도 accuracy에 거의 영향이 없음을 보였다.
또한 Zhou et al. (2019)와 Ramanujan et al. (2019)은 individual weights를 remove할지만 학습하는 것만으로도 CIFAR-10 and ImageNet에서 high accuracy를 달성했다.
3. Methodology
ResNet architectures
-
의도적으로 (1) optimization에 방해하지 않으면서 increasing depth and (2) increasing width를 할 수 있기 때문에
ResNet architecture를 사용했다. -
일반적으로 deep ResNet을 학습하려면 BN이 필수적이므로, 이는 본 연구의 실험을 수행하기에 natural setting이다.
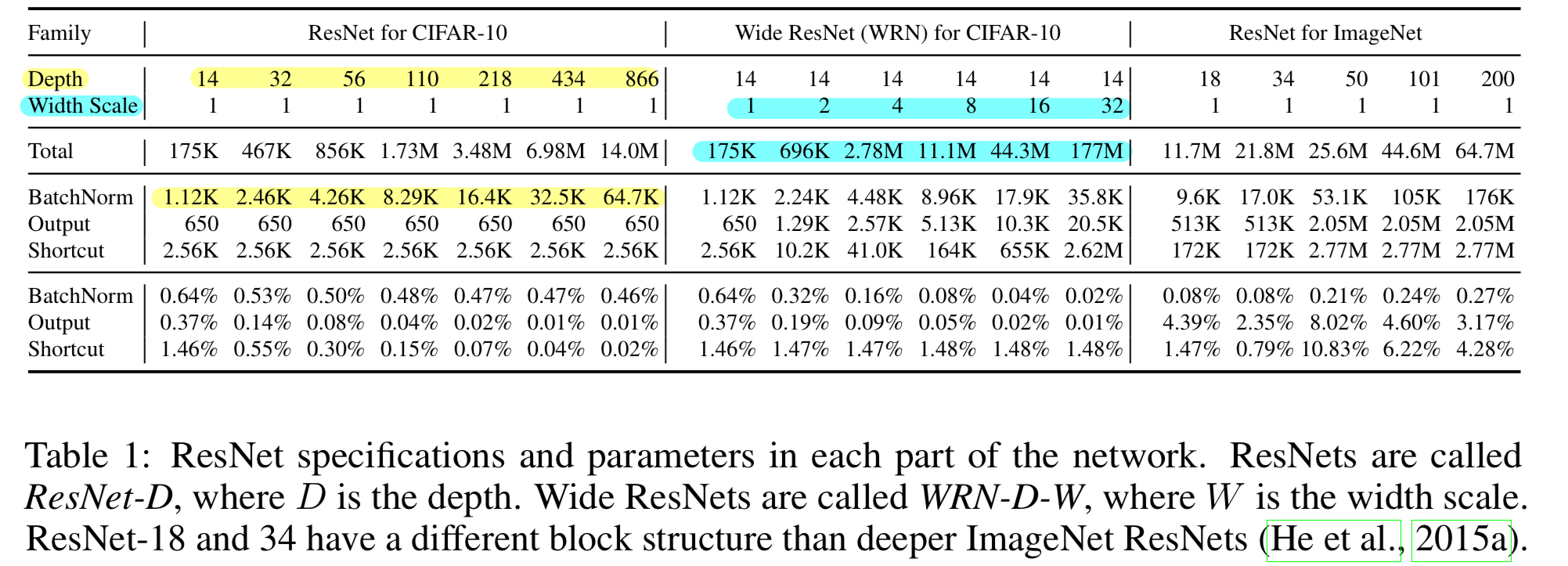
우리는 He et al. (2015a)가 design한 CIFAR-10 및 ImageNet용 ResNet을 사용한다.
깊이는 He et al. (2015a)의 방식에 따라 조절하고, width는 각 layer의 channel 수를 multiplicatively increasing 한다.- depth가 증가할수록,
network는 동일한 수의 shortcut parameter와 output parameters를 유지하지만,
더 많은 feature를 가지게 되므로 BN parameter 수는 증가한다. - 반면 width가 증가하면,
BN parameter와 output parameter 수는 linearly 증가하고,
convolutional and shortcut parameter 수는 input channel과 output channel 모두 증가하기 때문에 quadratically 증가한다.
- depth가 증가할수록,
BatchNorm
-
He et al. (2016)에서 BN을 activation 이후에 배치하는게 better performance를 보인다고 했기 때문에,
우리도 BN을 activation 이전에 배치함. -
We initialize to 0 and sample uniformly between 0 and 1.
이 initialization에 대한 고려는 Appendix E에 있음. -
Appendix E.2: 우리는 BN initialization을 three alternatives에 대해 연구했다.
- standard practice for BN (, )
- centering around (~, )
- ReLU activation을 통과한 normalized features의 a greater fraction을 보장하기 위한 (, )
3. 방식이 BN-only exp에서 가장 좋은 성능을 보였지만,
all parameters are trainable exp에서는 성능이 낮았다.
이는 전체적으로 많은 runs to fail을 유도한다는 것이다.
-
우리는 다음과 같은 결론을 지었다.
- BN-only 상황에서의 BN parameters를 위한 ideal initialization schemes와
standard senarios에서의 initialization은
다르다는 것. - standard training regime이 BN initializations 선택에 indeed (확실히) sensitive하다.
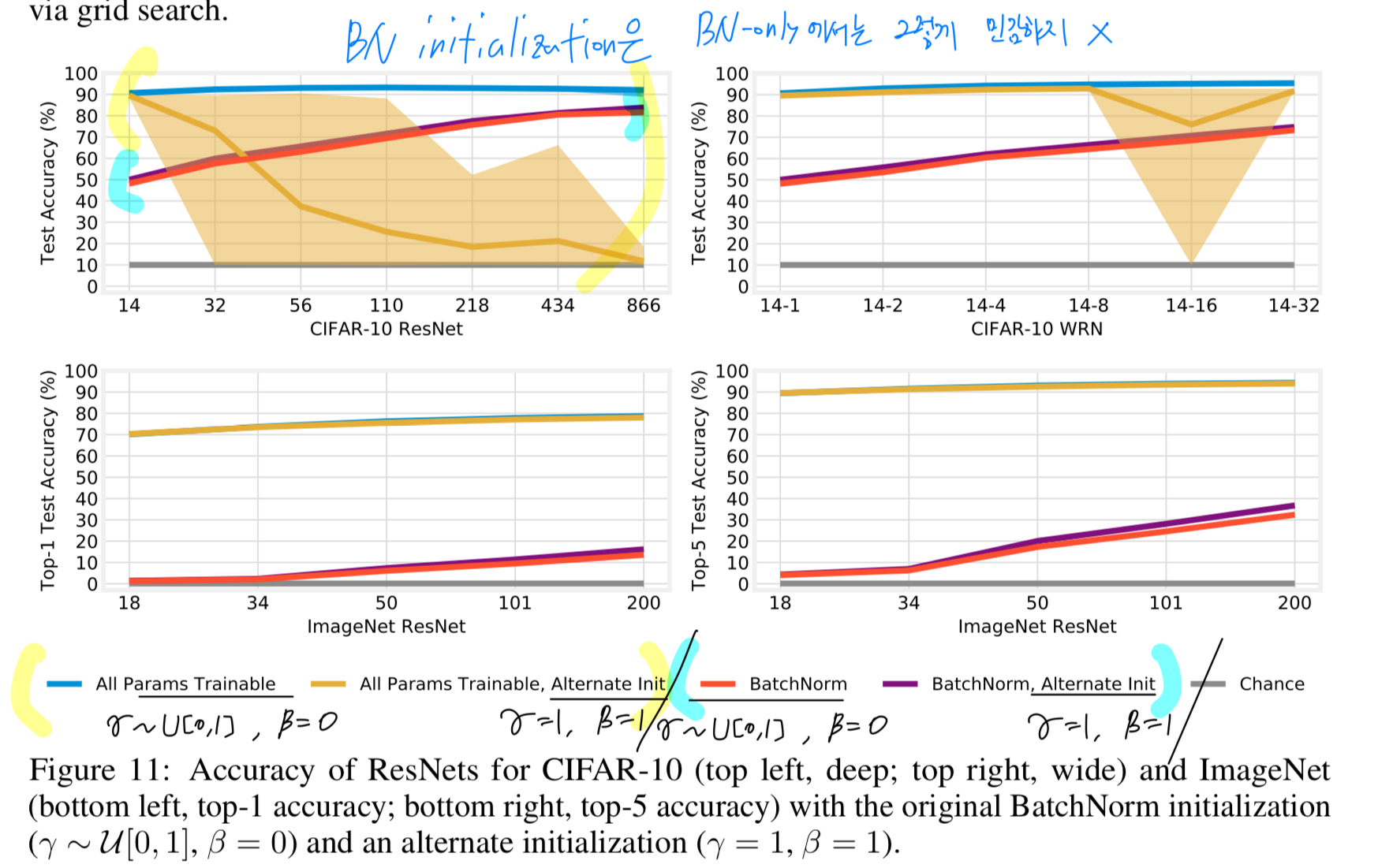
- BN-only 상황에서의 BN parameters를 위한 ideal initialization schemes와
Replicates
- "All experiments are shown as the mean across five (CIFAR-10) or three (ImageNet) runs
with different initializations, data orders, and augmentation.
Error bars for one standard deviation from the mean are present in all plots;
in many cases, error bars are too small to be visible."
4. TRAINING ONLY BATCHNORM
- In this section, we study freezing all other weights at initialization and train only and .
These parameters comprise no more than 0.64% of all parameters in networks for CIFAR-10 and 0.27% in networks for ImageNet.
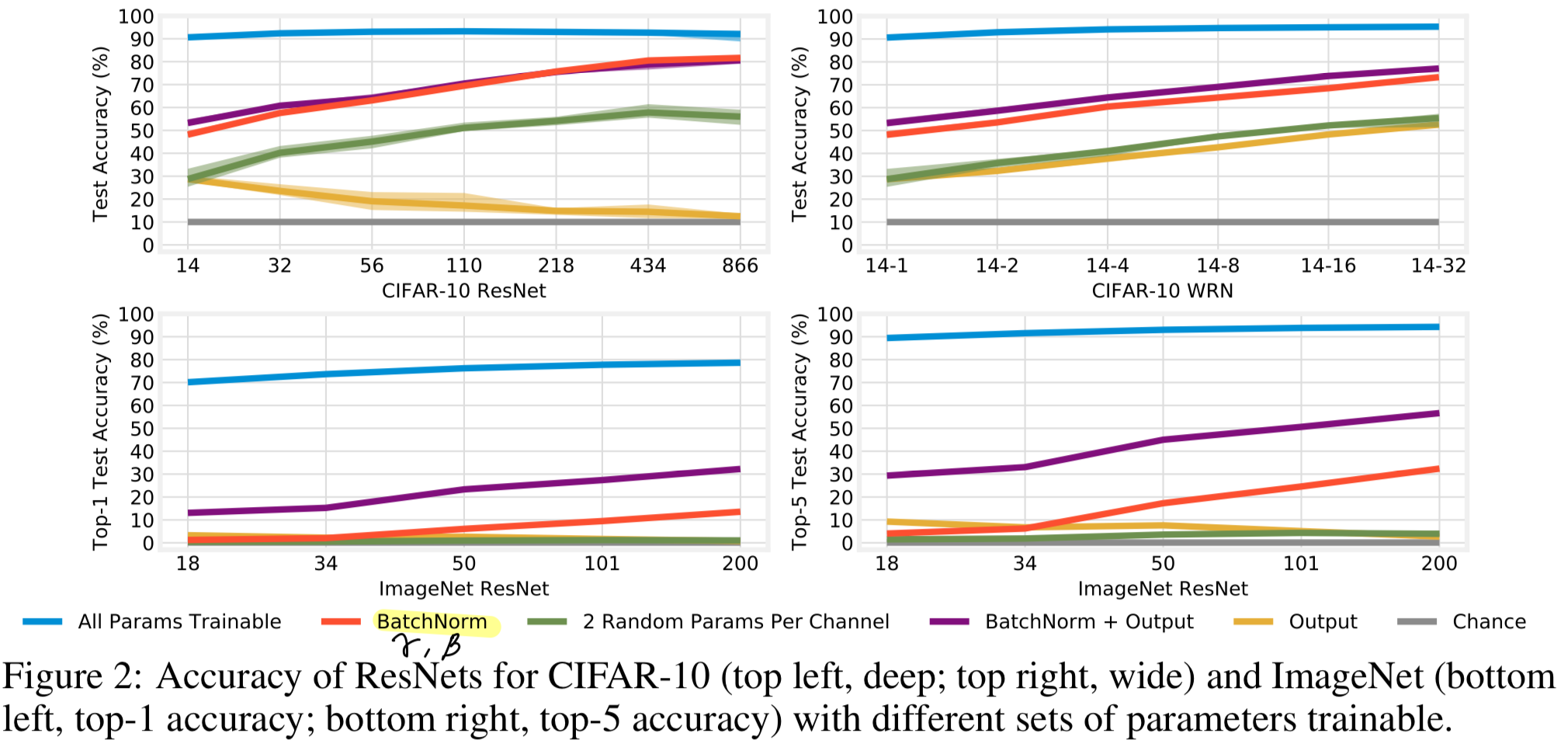
Case study: ResNet-110
-
먼저 CIFAR-10에서의 ResNet-110을 고려한다.
all 1.7M parameters를 모두 학습하는 경우 (blue), network는 93.3%의 test acc를 달성.
CIFAR-10은 10개의 class를 가지므로, chance performance는 10%이다.
반면, random feature를 only shift and rescale할 수 있는 8.3K (0.48%)개의 affine parameters만 학습했을 때,
network는 놀랍게도 69.5%의 test acc를 달성한다.
이는 affine parameter들이 noteworthy representational capacity를 가지고 있음을 시사한다. -
비록 본 연구의 motivation은 affine parameter의 역할을 분석하는 데 있지만,
이 결과는 random feature로 구성된 NN의 expressive power에 대해서도 중요한 implications을 가진다.
affine parameter는 각 layer에서 random feature들이 만들어내는 normalized activation map을 shift and scale하는 것만 가능하니까
다시 말해, 이 실험은 random feature의 shift and rescaling만으로 parameterized된 NN을 training하는 과정으로 볼 수 있다.
이러한 관점에서 보면, 본 결과는 initialization 시점에 주어진 random feature만을 사용하더라도 CIFAR-10에서 high acc를 달성할 수 있음을 보여준다.
Increasing available features by varying depth and width
-
random features의 관점에서, the expressivity of the network는 affine parameter가 결합할 수 있는 feature의 개수에 의해 제한된다.
feature의 수를 늘리면 acc가 향상될 것이라 기대할 수 있으며, 이는 두 가지 방식으로 가능하다:
(1) increasing the netowkrs'depth or (2) increasing its width
(질문: random feature 개수를 늘리는게 아니라 affine parameter 수를 늘리는게 acc 향상을 기대할 수 있는게 아닌가?) -
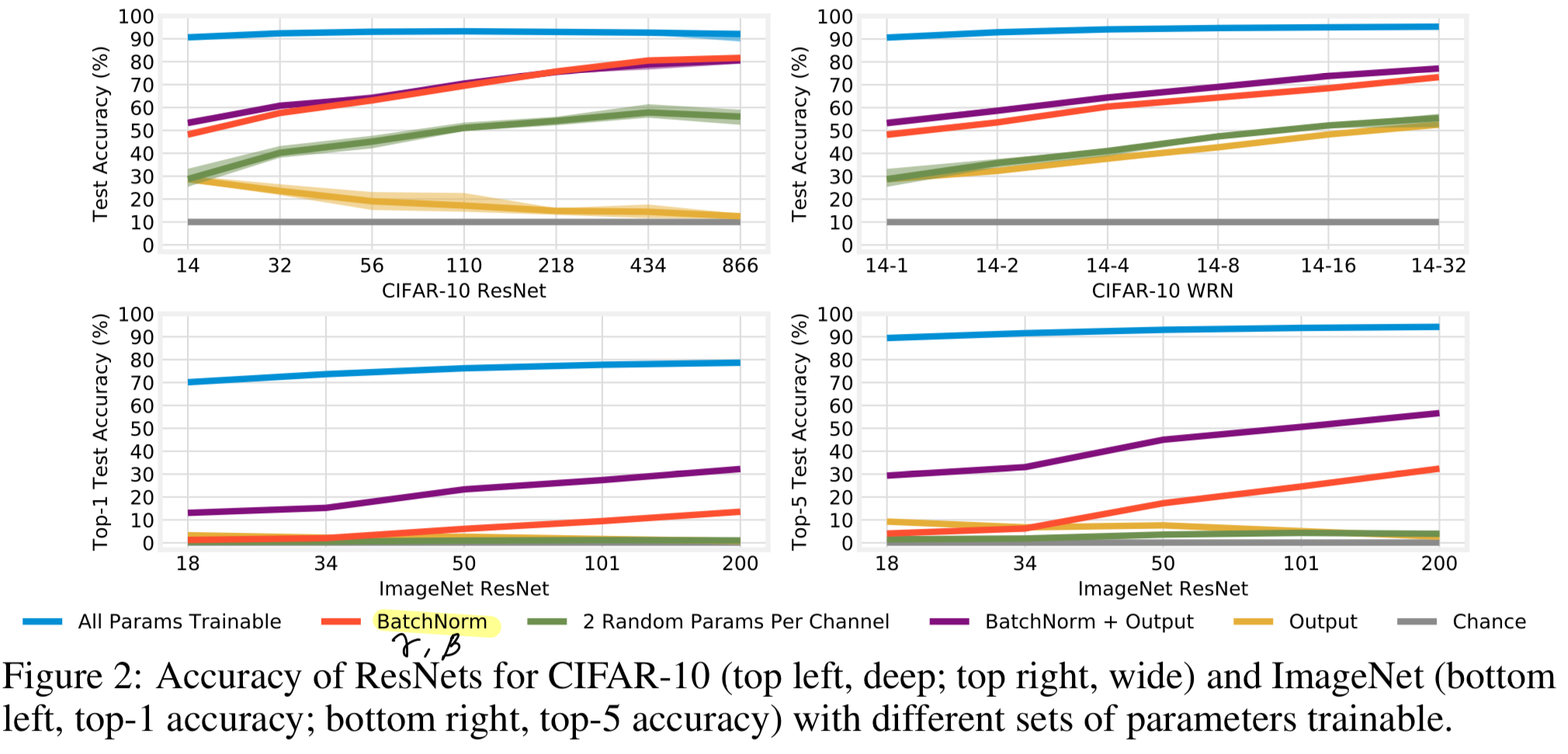
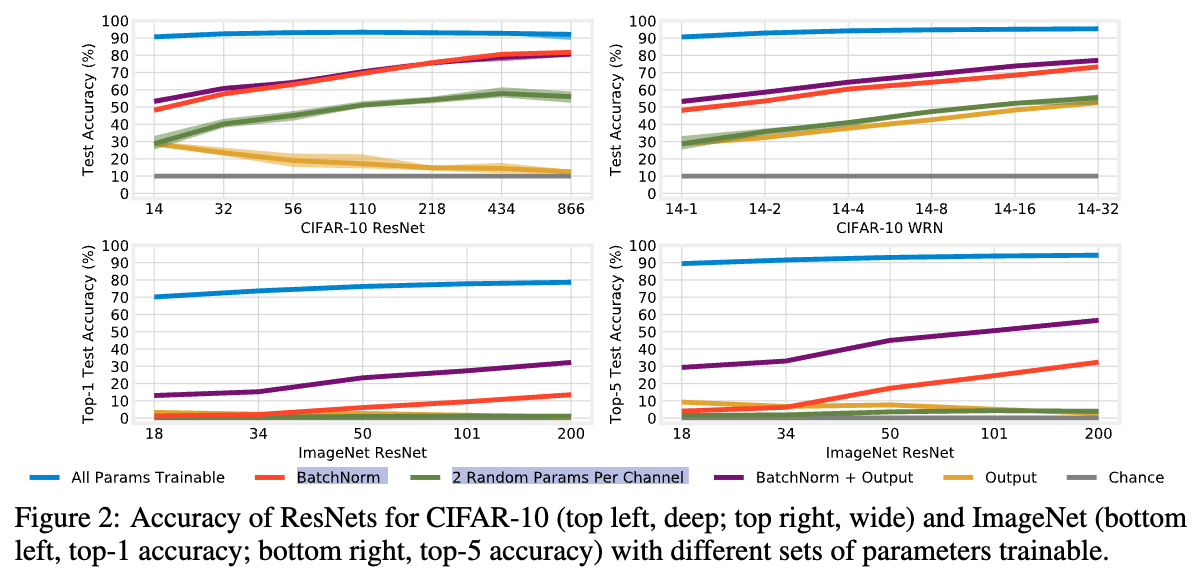
Figure 2는 CIFAR-10 ResNet에서 increasing the depth (top left)와 the width (top right),
그리고 ImageNet에서의 increasing the depth (bottom)에 따른
test acc를 보여준다.
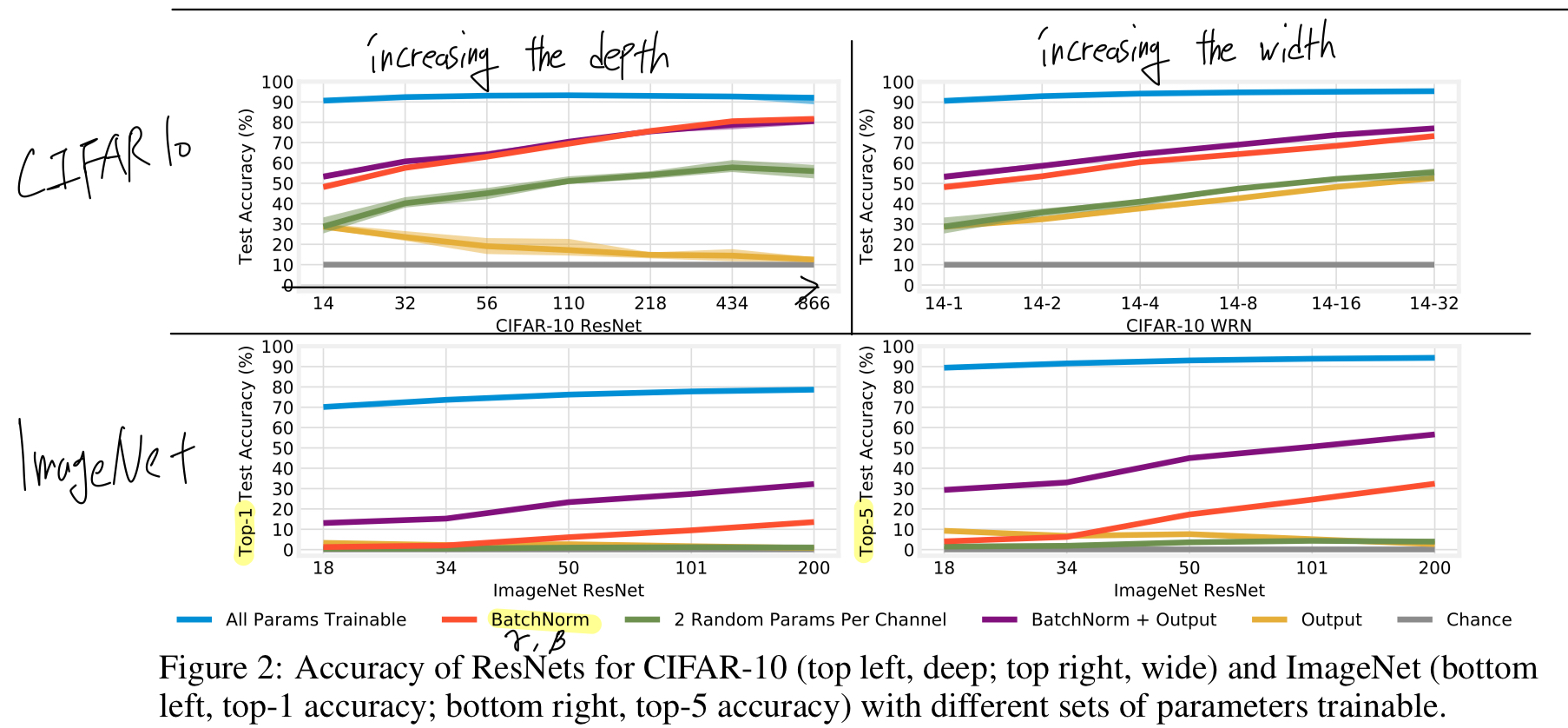
- 예상한 대로, training only BN의 경우에도 network를 deepen or widen할수록 acc가 향상된다.
예를 들어, CIFAR-10에서 ResNet-14는 BN만 학습했을 때 48% acc를 달성하지만,
866 layer까지 깊게 만들면 82%, width를 32배로 늘리면 73%까지 acc가 상승한다.
마찬가지로, ImageNet에서는 ResNet-50이 17%의 top-5 acc를 보이지만, 이를 200 layers로 늘리면 32%까지 상승한다. - ImageNet은 1000개의 class를 가지므로, linear output layer를 freeze한 상태에서는 acc가 인위적으로 제한될 가능성이 있다.
즉, network가 class 간의 fine-grained distinctions을 학습할 수 없기 때문이다.
이를 검증하기 위해, 우리는 output layer의 0.5M ~ 2.1M 개 Parameter를 trainable하게 설정했다 (Figure 2, purple).
그 결과 BN + Output layer를 함께 training하면 top-5 acc는 약 25%p 증가하여 최대 57%, top-1 acc는 12~19%p 증가하여 최대 32%에 도달한다.
이 성능에는 affine parameter가 필수적이다: output layer만 학습하는 경우에는 ResNet-200에서 top-5 2.7%, top-1 0.8%에 불과했다 (yellow).
반면, CIFAR-10은 class 수가 10개에 불과하기 때문에, 동일한 수정이 큰 차이를 만들진 않았다. - 마지막으로, ResNet-434(deeper)는 WRN-14-32(wider)보다 약 7%p 높은 acc를 보이는데,
두 model의 BN params 수가 겅의 동일하다 (32.5K vs. 35.8K).
이는 다음과 같은 추가적인 질문을 제기한다: BN parameter budget이 고정되어있을 때 (즉, a fixed number of random features일 때), width를 늘리는 것보다 depth를 늘리는 것이 항상 더 좋은가?
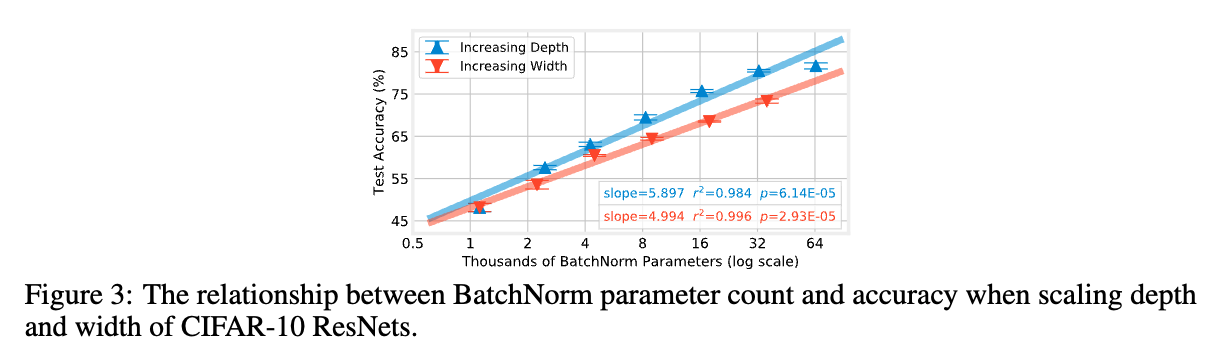
Figure 3은 ResNet-14를 공통 starting point로 삼아,
depth를 늘리는 경우(blue)와 width를 늘리는 경우(Red)에 대해
BN params 수 (x-axis)와 CIFAR-10 test acc (y-axis)의 관계를 나타낸다.
두 경우 모두 BN params 수가 두 배로 증가할 때 linearly 증가한다.
그러나 depth를 증가시켰을 때의 trend가 width 증가 대비 약 18% 더 steeper하다.
이는 본 연구에서 고려한 network에 대해, 동일한 BN parameter budget 하에서 width를 늘리는 것보다 depth를 늘리는 것이 higher acc를 제공함을 의미한다.
- 예상한 대로, training only BN의 경우에도 network를 deepen or widen할수록 acc가 향상된다.
Are affine parameters special?
-
training only BN일 때의 high acc는
and 가 전체 feature를 scaling and shifting하는 unusal position이기 때문일까?
아니면 단순히 a substantial number of parameters가 여전히 trainable하기 때문일까?
예를 들어, ResNet-866의 65K BN parameters는 ResNet-14의 전체 175K parameters의 약 1/3에 해당하므로,
임의로 선택한 이 정도 개수의 parameter를 학습해도 비슷한 성능이 나올 수 있을까? -
이를 검증하기 위해, 우리는 각 convolutional channel마다
and 를 대체하는 임의의 두 개의 parameter를 학습하도록 설정했다 (Figure 2, green)
만약 acc가 BN만 학습했을 때와 유사하다면, 이는 our observations이 and 에 특유한 것이 아니라,
Rosenfeld & Tsotsos (2019)가 제안한 것처럼 임의의 subset of parameters를 학습하는 효과에 불과하다는 의미가 될 것이다.
그러나 실제로는 CIFAR-10에서 17~21%p 낮은 acc를 보였고, ImageNet에서는 top-5 acc가 4%를 넘지 못했다.
이는 and 가 다른 parameters보다 acc에 훨씬 큰 영향을 미친다는 것을 시사한다.
즉, feature 자체를 axis-aligned(미세하게 조정)하는 것보다,
전체 random feature를 corase-grained control하는 능력이 훨씬 더 중요하다는 결론에 도달한다.
Summary
-
본 연구의 목표는 trained features를 transform하는 weights들이 존재하지 않는 상황에서,
affine parameters and 의 role and expressive power를 독립적으로 분석하는 것이었다.
실험 결과, BN을 포함한 ResNet에서 이 parameter들만 학습하더라도 놀랄 만큼 high acc를 달성할 수 있음을 확인했다.
또한, 이 parameter들의 개수와 이들이 결합할 수 있는 random feature의 수를 증가시키면 acc를 더욱 향상시킬 수 있음을 보였다. -
이러한 acc는 단순히 learnable params 수가 많기 때문만은 아니며, 이는 와 가 각 feature에 작용하는 coefficient and bias라는 형태로서 특별한 expressive power를 가진다는 점을 시사한다.
and
5. EXAMINING THE VALUES OF AND
- 이전 Section에서, and 만 학습시켜 surprisingly high acc를 달성함을 보였다.
이제 어떻게 network가 이 performance를 달성할 수 있는지 볼 것이다.
즉, and 의 values and role을 all parameter를 학습하는 경우와 비교해 어떻게 달라지는지를 분석한다.
Examining
- initial case study로, CIFAR-10에서의 ResNet-110과 ImageNet에서의 ResNet-101에 대해,
all parameters를 학습한 경우 (blue)와 and 만 학습한 경우 (red)의 the distribution of 를 Figure 4에 나타냈다.
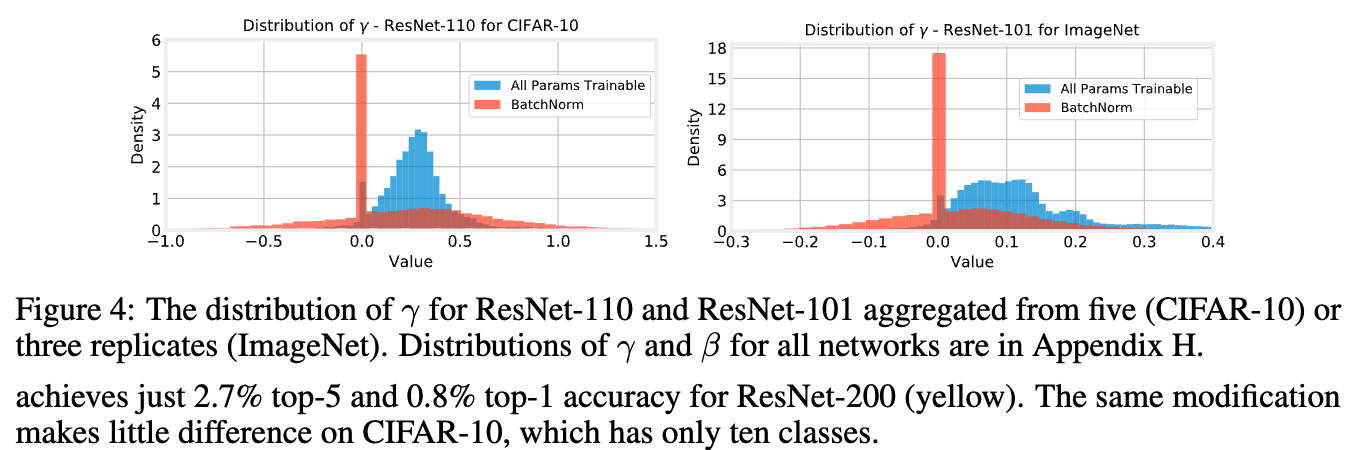
- all parameters를 학습할 때 ResNet-110(CIFAR-10)의 the distribution of 는
mean of 0.27, stddev of 0.21인 normal distribution에 가깝고,
값의 95%가 positive이다.
반면, BN만 학습할 경우,
의 mean은 비슷한 수준 (0.20)이지만 stddev가 훨씬 커져 (0.48),
값의 25%가 negative가 된다. - ResNet-101(ImageNet)에서도 유사한 경향이 나타나며,
의 mean은 0.14에서 0.05로 감소하고,
stddev는 0.14에서 0.26으로 증가한다. - 주목할 만한 점은, BN만 학습할 때 근처에 spike가 나타난다는 것이다.
ResNet-110에서는 27%, ResNet-101에서는 33%의 값이 에 해당한다.
(all params training에서는 각각 4%와 5%에 불과)
전체 feature의 약 1/4 ~ 1/3을 사실상 disable하는 법을 학습한 것으로 보인다.
(내 생각: 값이 0이라면 위 주장을 그나마 동의할 수도 있겠지만, 값이 0근처에 있다고 해서 disable한다는 것은 아니라고 생각.
값에 따라 0인 activation이 값을 갖게 되니까 이는 0이라는 표현이 아니라 다른 의미의 표현임.
이 내용을 뒤에서 저자들도 언급하고 있었음...)
이러한 sparsity를 유도하기 위해 standard weight decay 외에 어떠한 추가적인 제약을 두지 않았음에도, 이 현상은 자연스럽게 발생한다.
이는 network's representation의 중요한 한 부분이 the set of random features를 ignore할지를 학습하는 것임을 시사한다.
all params training 경우에도 0 근처 Smaller spike가 존재하지만,
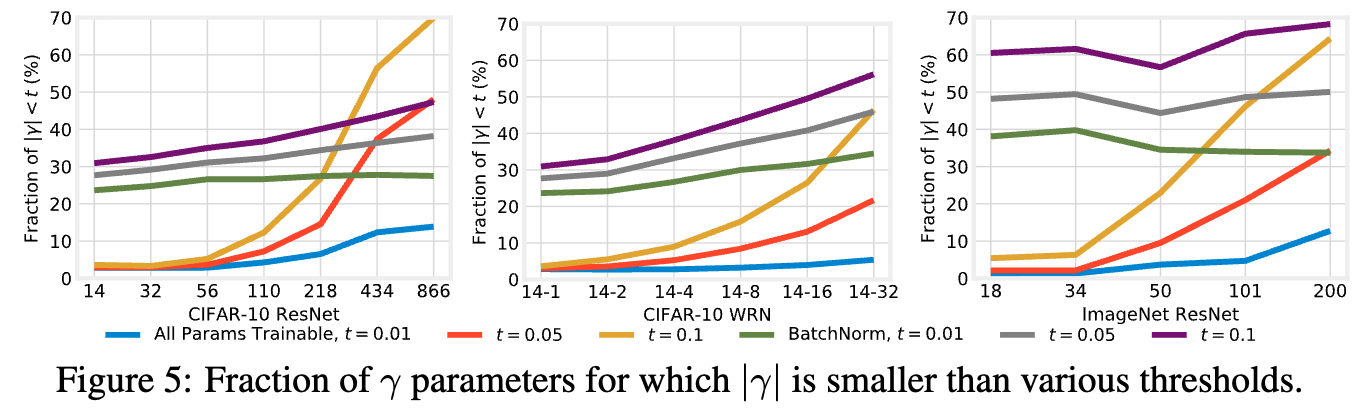
and 만 학습할 때 이 현상이 훨씬 더 exaggerated하게 나타난다. - 이러한 경향은 모든 depth and width 에서 일관되게 나타나며,
BN만 학습할 경우 전체 feature의 상당 부분이 disabling된다. (Figure 5, green)
반면, all params training의 경우 the deepest ResNets을 제외하면 이 ratio는 5%에 불과하다. (Figure 5, blue)
또한 network가 deeper and wider일수록, all params를 학습할 때 값은 전반적으로 더 작아지는 경향을 보인다.
우리는 activation이 exploding하는 것을 방지하기 위해 값이 작아지는 경향이 나타난다고 가설을 세운다.
(내 생각: 위 가설은 아닌 것 같음. network가 activation이 exploding하는지 마는지는 의식하며 학습할 수 없음.)
- all parameters를 학습할 때 ResNet-110(CIFAR-10)의 the distribution of 는
Small values of disable features
"disabled feature라고 주장하는 근거 1: small value 를 0으로 해도 Acc에 영향 X"
- 단지 값이 0에 가깝다고 해서 들이 features를 disables한다고 단정할 수는 없다.
이 값들이 여전히 representation에서 중요한 역할을 하고 있을 가능성도 있다.
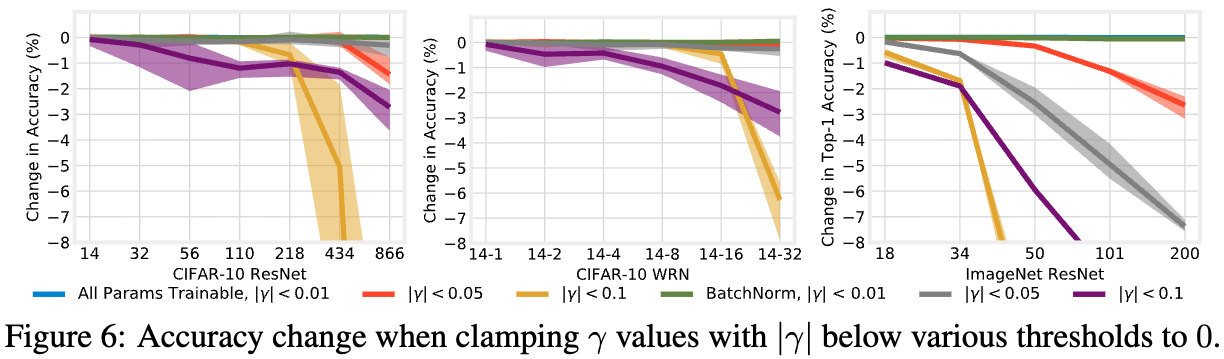
우리는 어떠한 small 값이 실제로 feature를 제거하고 있는지를 평가하기 위해,
우리는 이러한 parameter들을 명시적으로 0으로 clamping한 뒤 그 결과 Network의 acc를 측정하였다 (Figure 6).
인 모든 값을 0으로 고정해도 acc에는 영향을 미치지 않았고, 이러한 feature들은 실제로는 expendable(불필요)하다는 것을 시사한다.
이러한 현상은 all params training 경우 뿐만 아니라 BN only training 경우에도 동일하게 관찰되었다.
특히 후자의 경우, 전체 feature의 약 24%에서 38%가 disabled될 수 있음을 의미한다.
이는 값이 0에 가장 가까운 feature들이 network representation에서 중요하지 않은 feature임을 반영한다는 우리의 hypothesis를 뒷받침한다.
다만 threshold를 0.05로 설정한 경우에는 결과가 다소 mixed하게 나타나있다.
all params training 설정에서는, the deepest and widest networks를 제외하면 acc가 원래 값과 거의 동일하게 유지되었다.
이 예외적인 경우는 해당 threshold 이하의 parameter 비율이 급격히 증가하는 구간과 일치한다.
Training only BatchNorm sparsifies activations
"disabled feature라고 주장하는 근거 2: ReLU activation의 sparsity가 증가"
-
지금까지, 우리는 의 역할에만 집중했다.
하지만 는 와 함께 작동하여 normalized pre-activations의 분포를 변화시킨다.
는 additive 역할을 하기 때문에 그 효과를 명확히 설명하기가 어렵다.
예를 들어 BN-only training의 경우 많은 값들이 0에 가까워지지만 (Appendix H), 이것이 곧바로 feature를 disable한다는 의미는 아니다. -
and$ 의 joint role을 이해하기 위해, 우리는 activation 자체의 behavior를 분석한다.
Figure 7에는 test example 전체와 해당 activation map의 모든 pixel에 대해 을 만족하는 ReLU activation의 fraction을 시각화했다.
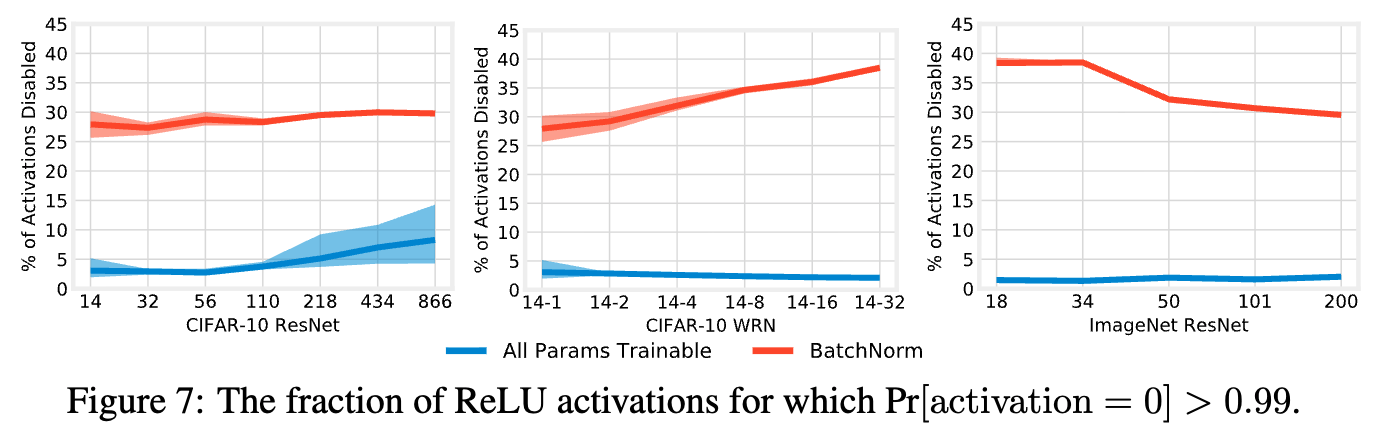
- BN-only training의 경우, 28%에서 39%의 activation이 disabled되었는데,
이는 and 가 실제로 activation을 sparsify한다는 것을 의미한다.
반면, all params training의 경우, 이 heuristic 기준에 따라 disabled된 few activations의 비율이 CIFAR-10에서는 10% 이하, ImageNet에서는 2% 이하에 불과하다. - 이러한 결과는 두 training settings에서 the small values 가 수행하는 역할이 다르다는 우리의 hypothesis를 지지한다.
BN-only training의 경우에는 값이 작아지면서 전체 activation이 실제로 disabled된다.
all params training의 경우에는 deeper and wider networks에서 값이 작아지는 비율이 높음에도 불구하고 disabled되는 activation은 거의 없으며,이는 and parameters가 여전히 learned representations에서 중요한 역할을 수행하고 있음을 시사한다.
- BN-only training의 경우, 28%에서 39%의 activation이 disabled되었는데,
Context in the literature
skip..
Summary
- 이 section에서, 우리는 training all params와 training only BN에 대해
internal representations를 비교했다.- When training only BN, 우리는 가 a larger variance를 갖고 0에서 spike를 갖는다는 것을 발견했다.
그리고 는 entire features를 disable하도록 학습되고 있었다. - When all params were trainable, 우리는 values가 wider and deeper networks에서 smaller하게 되지만 activations은 not disabled되는 것을 발견했다.
이는 all params training에서 parameter가 여전히 중요한 역할을 하고 있음을 시사한다.
- When training only BN, 우리는 가 a larger variance를 갖고 0에서 spike를 갖는다는 것을 발견했다.
6. Discussion and Conclusions
- 우리의 실험 결과는 BN에 연관된 affine parameter만 학습하고 나머지 모든 params를 initialization된 상태로 freezing하더라도,
놀랄 만큼 high acc를 달성할 수 있음을 보여준다.
research question에 대한 답으로, 우리는 feature를 변환하는 affine parameter가 learned feature와 결합하지 않더라도 그 자체만으로 substantial expressive power를 가진다는 결론을 내린다.
이러한 결과가 갖는 의미에 대해 몇 가지 observations을 제시한다.
BatchNorm
- 비록 research community는 일반적으로 BN의 normalization 측면에 초점을 맞춰 왔지만,
우리의 결과는 affine parameter 자체가 주목할 만한 역할을 한다는 점을 강조한다.
이 parameter들의 존재는 performance를 실질적으로 향상시키며, 특히 deeper and wider networks에서 그 효과가 두드러진다.
이러한 현상은 network가 깊어질수록 값이 더 작아진다는 observation과 연결된다.
and 만으로도, 다른 parameter의 subsets을 학습하는 것과 비교해도 놀라울 정도로 high acc를 달성할 수 있는데,
이는 전체 activation의 1/4 이상을 disable하기 때문일 수도 있고, 오히려 그 덕분일 수도 있다.
Random Features
-
다른 관점에서 보면, 우리의 실험은 random feature로 구성된 network를 학습하는 novel way로 볼 수 있다.
기존 연구들은 random nonlinear feature 위에 linear output layer만 학습하는 방식을 고려했지만,
우리는 각 layer의 각 feature 뒤에 affine parameter를 network 전반에 걸쳐 배치한다.
이러한 configuration은 output layer만 학습하는 것보다 greater expressive power를 network에 부여하는 것으로 보인다 (Figure 2)
경험적으로, 우리의 결과는 Zhou et al. (2019), Ramanujan et al. (2019)과 함께 random initialization 상태에서 performant networks를 구성할 수 있는 충분한 material이 존재한다는 증거를 추가로 보인다.
이러한 configuration의 theoretical capabilities를 더 깊이 이해하는 것 역시 intersting하다.
-
Rahimi & Recht의 접근과 달리, 우리의 방법은 training costs를 실질적으로 줄여주지는 않는다.
deep BN parameters를 update하기 위해 여전히 전체 network에 대한 backpropagation이 필요하기 때문이다.
그러나 본 연구는 inference-time에서의 model storing cost를 줄일 가능성을 제시한다.
즉, network의 모든 parameter를 저장하는 대신, network weights를 생성하기 위한 random seed와 trained BN parameters만 저장할 수 있다.
더 나아가 Mudrakarta et al. (2019)와 유사하게, 하나의 random seed와 여러 task에 대응하는 multiple sets of BN parameters를 저장하는 multi-task fashion도 가능하다.
Limitations and future work
-
본 연구의 confidence and generality를 높이기 위해 확장할 수 있는 방향은 여러 가지가 있다.
우리는 CIFAR-10과 ImageNet에서 학습된 ResNet만을 고려했는데, 다른 architecture families and tasks (CV에서 Inception, NLP에서 Transformer)로 확장하는 것이 의미있을 것이다.
또한 우리는 standard hyperparameters를 사용했으며, BN-only training에 특화된 hyperparameters는 search하지 않았다. -
follow-up work에서는, random feature와 affine parameter가 학습하는 representation 간의 관계를 더 깊이 탐구하고자 한다...
Critique
* BatchNorm의 $\gamma$ and $\beta$를 trainining하는 것과 2 Random Params Per Channel을 trainining하는 것이 올바르지 않다고 생각함.
어떤 BN layer에 입력되는 feature의 channel이 $C$개라고 가정했을 때,
이 BN layer의 $\gamma$ and $\beta$ shape은 각각 $(1,C,1,1)$이 될 것임.
다른 말로, 한 channel 당 2개의 parameter $\gamma_c, \beta_c$가 존재함.