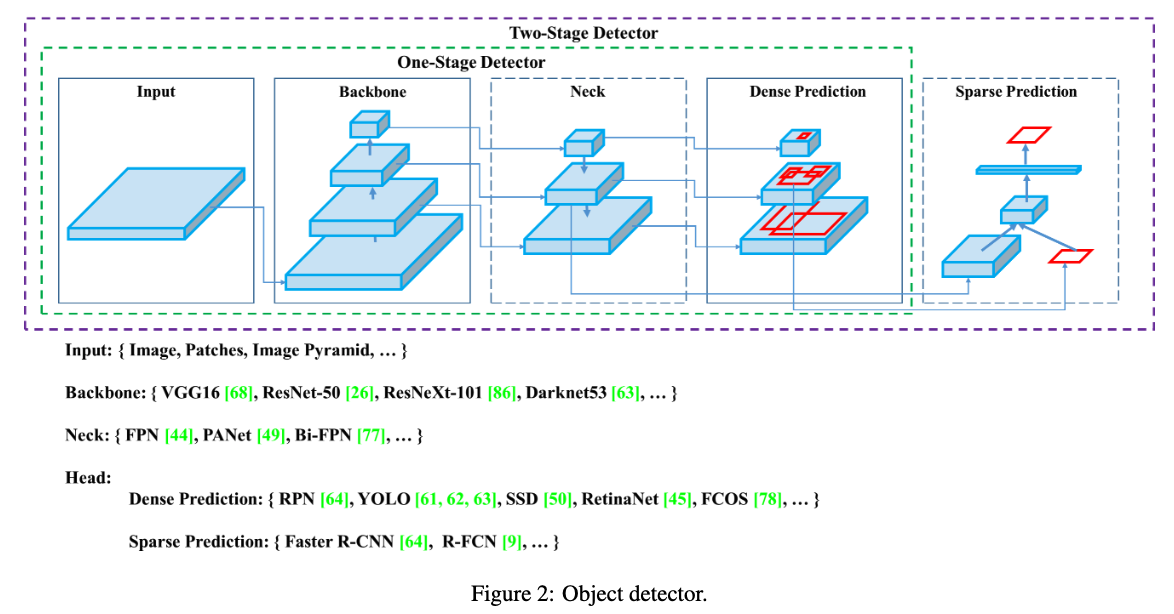
[2025 NeurIPS] YOLOv12: Attention-Centric Real-Time Object Detectors
[Paper Review] 2D Object Detection
Paper Info.
- 현재 NeurIPS 2025 main conference에 poster로 accept되었지만, 아직 publish 전이라 ArXiv에 있는 technical report로 리뷰.

Abstract
(배경)
-
YOLO framework의 the network architecture 향상은 오랜 시간 중요해졌고,
modeling capabilities에서 the proven (입증된) superiority of attention mechanism (attention mechanism의 우월함)에도 불구하고, CNN-based improvements에 집중되어 왔다. -
이는 attention-based model이 the speed of CNN-based models을 만족시키지 못하기 때문이다.
(제안)
- 이 paper에서는 YOLOv12이라는 an attention-centric YOLO framework를 제안한다.
YOLOv12은 attention mechanism의 performance benefits를 해치지 않으면서도 the speed of previous CNN-based ones를 만족시킨다.
(실험)
- YOLOv12는 all popular real-time object detectors에 대해 competitive speed를 유지하면서 accuracy를 능가한다.
(YOLOv10, v11, RT-DETRv1, RT-DETRv2)
요약
그동안의 object detector(YOLO series)들은 빠른 detection speed를 위해서 attention mechanism의 model capability의 우월함을 충분히 이용하지 못하고,
CNN-based mechanism을 사용했다.
우리는 attention 중심의 YOLO framework인 YOLOv12를 제안하는데, YOLOv12는 model capability가 뛰어난 attention 연산을 활용하면서도 CNN-based mechanism의 속도와 비슷하다.
1. Introduction
(배경: RT-OD에서 YOLO)
- Real-time object detection(RT-OD)은 low-latency 특성으로 인해 상당한 관심을 받고 있다.
그들 중에, YOLO series는 latency and accuracy 사이의 optimal balance를 효과적으로 설립해 왔고, RT-OD 분야를 지배하고 있다.
(배경: YOLO에 대한 최근 연구 동향)
- 비록 YOLO에 대한 개선들이 loss functions, label assignment에 집중이 되어왔어도,
network architecture design은 a critical research priority로 계속 여겨져 온다.
비록 attention-centric ViT architectures가 small models에서도 stronger modeling capabilities을 갖추고 있음이 입증되었지만,
most architectural designs는 주로 CNN 중심으로 이루어지고 있다.
(위 말에 동의.
최근에는 loss function, label assignment와 같은 training strategies에 대한 연구가 집중되었고
전체적인 network architecture design에 대한 연구는 이전보다 뜸해진듯 함.
전체적으로 표준적이고 이미 정해진 network architecture에 세부 모듈만 약간의 수정을 가하는 연구만 지속되어 와서, 전체적인 개선이 더 필요하지 않을까? 생각했었음...)
(문제 제기)
-
이러한 상황에 대한 주 원인은 attention mechanism의 inefficiency이다.
attention mechanism의 주요한 두 inefficiency는 다음과 같다.-
quadratic computational complexity
-
inefficient memory access operations of the attention mechanism
(inefficient memory operations은 FlashAttention에 의해 완화되었던 main issue이다.)결과적으로, similar computational budget 내애서,
CNN-based architectures는 attention-based architectures보다 약 3배 정도 더 뛰어난 성능을 보이며,
high inference speed가 중요한 YOLO systems에서 attention mechanism의 adoption을 크게 제한해 왔다.
-
(제안)
- 본 논문은 이러한 challenges를 해결하고, attentino-centric YOLo framework인 YOLOv12를 제안한다.
우리는 three key components를 도입하였다.a simple yet efficient area attention module (A2)을 제안한다.
A2 module은 large receptive field를 유지하면서,
아주 간단한 방식으로 attention의 computational compleixty를 낮추어 speed를 향상시킨다.Residual Efficient Layer Aggregation Networks (R-ELAN)을 도입하여,
특히 large-scale models에서 attention이 야기하는 optimization challenges를 해결한다.
R-ELAN은 기존 ELAN 구조를 기반으로 two improvements를 포함한다.- scaling techniques를 결합한 block-level residual design
- a redesigned feature aggregation method
vanilla attention에서 벗어나 YOLO system에 적합한 architectural improvements를 추가하였다.- FlashAttention을 도입하여 attention의 the memory access issue를 해결
- fast and clean(단순성)을 위해 positional encoding 제거
- attention과 FFN의 computation balance를 맞추기 위해 MLP ratio를 4에서 1.2로 조정
(왜 balance를 맞춰야 하는데?) - optimization을 용이하기 위해 stacked blocks의 depth를 감소
- 가능한 한 convolution operators를 많이 이용하여 computational efficiency를 가능하게 함.
(5.는 이해가 안감...
attention mechanism-centric framework라면서 왜 갑자기 convolution operators을 많이 사용?
이게 vanilla attention의 architectural 개선과 무슨 연관이 있지?)
(실험)
- 위에서 말한 designs을 기반으로, 우리는 5 model scales를 갖는 new family of real-time detectors를 개발했다.
YOLOv11 without any additional tricks에 따라 standard OD benchmarks에 대해 extensive experiments를 진행했다.
(요약)
- 요약해서, the contributions of YOLOv12은 two-fold이다:
- YOLOv12는 attention-centric이면서도 simple yet effective YOLO framework를 구축하였으며,
methodological innovation and architectural improvements를 통해 YOLO series에서 CNN models이 차지해 온 dominance (지배적인 위치)를 넘어섰다. - pretraining과 같은 additional techniques에 의존하지 않고, YOLOv12는 fast inference speed and higher detection accuracy를 달성하며, SOTA 성능을 입증하고 its potential을 보여준다.
- YOLOv12는 attention-centric이면서도 simple yet effective YOLO framework를 구축하였으며,
2. Related Work
Real-time Object Detectors
- Real-time object detectors는 그 상당한 practical value로 인해 community의 관심을 유발하고 있다.
YOLO series는 real-time object detection의 a leading framework로 부상해왔다.- 초기 YOLO system들은 주로 a model design persepctive에서 YOLO series를 위한 framework를 구축했다.
YOLOv4 and YOLOv5는 framework에서 CSPNet, data augmentation,
그리고 multiple feature scales를 추가하였다.
YOLOv6는 backbone and neck에 BiC and SimCSPSPPF modules을 도입하고,
anchor-aided training을 적용하여 이를 더욱 발전시켰다.
YOLOv7은 ELAN(efficient layer aggregation networks)를 도입하여 gradient flow를 개선하고, 다양한 bag-of-freebies 기법을 적용하였다.
YOLOv8은 a efficient C2f block을 통합하여 feature extraction 성능을 향상시켰다. - 최근에는,
YOLOv9가 GELAN을 동비하여 architecture optimization을 달성하고, PGI(Programmable Gradient Information)를 통해 training improvement를 이끌었다.
YOLOv10은 efficiency gains을 위해 NMS-free training과 dual assignments를 적용했다.
YOLOv11은 C3K2 모듈(GELAN의 일종)과 lightweight depthwise separable convolution을 detection head에 도입하여 latency를 줄이고 accuracy를 향상시켰다.
최근에는 RT-DETR 이라는 end-to-end object detection method가 제안되었다.
RT-DETR은 efficient encoder and an uncertainty-minimal query selection mechanism을 설계하여
traditional end-to-end detectors를 real-time requirements를 충족시키도록 개선하였다.
또한 RT-DETRv2는 이에 bag-of-freebies를 추가하여 성능을 더욱 향상시켰다.
- 초기 YOLO system들은 주로 a model design persepctive에서 YOLO series를 위한 framework를 구축했다.
- 이 연구는 이전의 YOLO series와 달리, attention mechanism의 superiority(우수성)을 활용하기 위해 attention 중심의 YOLO framework를 구축하는 것을 목표로 한다.
Efficient Vision Transformers
- global self-attention 연산에서 발생하는 computational costs를 줄이는 것은 vision transformers를 다양한 downstream tasks에 효과적으로 적용하기 위해 매우 중요.
- PVT는 multi-resolution stages and downsampling을 사용하여 이를 해결.
SwinT는 self-attention을 local windows로 제한하고, window partitioning style을 조정하여 non-overlapping window 간의 연결을 가능하게 함으로써 communication needs와 memry and computation demands 간의 균형을 맞췄다. - 다른 방법들로는,
axial self-attention과 criss-cross attention이 있으며,
각각 horizontal and vertical windows 내에서 attention을 계산한다.
CSWin Transformer는 이를 기반으로 cross-shaped(십자형) window self-attention을 도입하여, horizontal and vertical stripes에서 parallel로 attention을 계산한다. - 또한, local-global relations을 확립하여 global self-attention에 대한 의존도를 줄임으로써 efficiency를 향상.
Fast-iTPN은 token migration 및 token gathering mechanism을 통해 downstream task inference speed를 개선하였다. - 일부 approaches들은 linear attention을 사용하여 attention의 complexity를 낮췄다.
Mamba-based vision models은 linear complexity를 목표로 하지만, 여전히 real-time speeds에는 미치지 못한다. - FlashAttention은 high-bandwidth memory bottlenecks이 inefficient attention computation을 유발하는 문제를 확인하고,
I/O optimization을 통해 이를 해결하여 memory access를 줄이고 computational efficiency를 높였다.
- PVT는 multi-resolution stages and downsampling을 사용하여 이를 해결.
- 본 연구에서는 complex designs을 버리고, attention의 complexity를 줄이기 위해
a simple area attention mechanism을 제안한다.
또한 FlashAttention을 사용하여 attention mechanism의 inherent memory accessing problems을 극복한다.
3. Approach
- 이 section에서는 YOLOv12, network architecture with attention mechanism의 관점으로부터 YOLO famework에 대한 혁신을 소개한다.
3.1. Efficiency Analysis
- attention mechanism은 convolution neural networks (CNN)에 비해 inherently slower 하다.
Two primary factors가 this discrepancy in speed에 원인이 된다.- Complexity
- Computation
Complexity
-
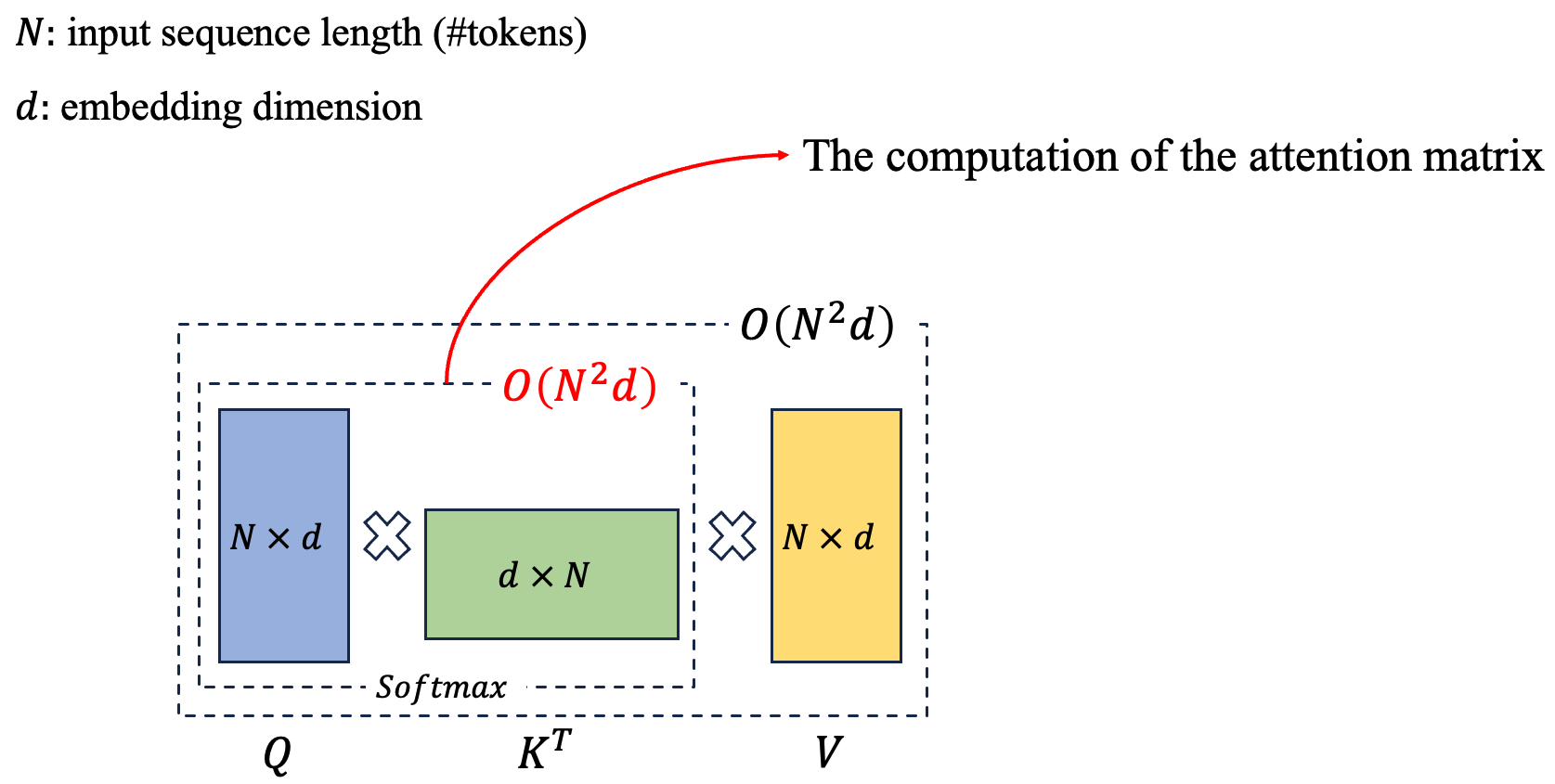
첫 번째로, self-attention operations의 computational complexity는 input sequence length 에 대해 quadratically로 커진다.
구체적으로, an input sequence with length and feature dimension 인 경우,
each token은 every other tokens을 attend해야 하기 때문에,
the computation of the attention matrix는 operations을 요구한다.
반면에, the complexity of convolution operations in CNNs은 the spatial or temporal dimension에 대해 linearly 확대된다.
즉, 이고, 는 kernel size를 의미하고 보다 훨씬 작다. (CNN 예제에서 은 무엇을 의미하는지 명확하게 하지 않았지만, 내 생각에는 stride에 따른 sliding 횟수를 로 취급한 것 같다. 그리고 는 kernel size이므로 이 맞지 않은가? 그리고 input channel dimension과 output channel dimension도 고려해야 하는데... 왜 이렇게 단순히 라고 썼는지 모르겠다.. 일단 attention 연산이 quadratic complexity를 갖는다는게 핵심이니까 넘어감)
따라서 self-attention은 특히 large inputs such as high-resolution images or long sequences에서
computationally prohibitive하다.
-
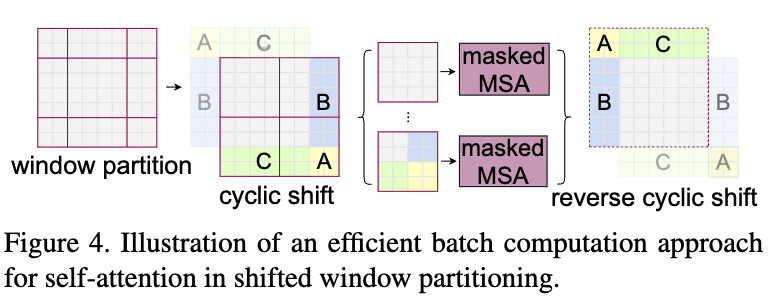
또한 most attention-based vision transformers는 their complex designs (window partitioning/reversing in SwinT)와 the introduction of positional encoding으로 인해 CNN architectures보다 더 slower speed를 유발한다.
(내 생각: CNN의 scale invariant & locality bias의 특성과 같은 inductive bias를 보충해주기 위한 여러 technique들이 speed를 더 느리게 한다.)- window partitioning / window reversing
- positional embedding
초기에는 sine & cosine absolute pos embedding을 했었는데, learnable pos embed 등 여러 pos embed 기법들이 제안됨.
이로 인해 더 느린 speed를 유발
- window partitioning / window reversing
-
이 논문에서 제안된 modules은 attention을 수행하기 위해 simple and clean operations를 활용.
Computation
- 두번째로, attention computation process에서는 CNNs과 비교했을 때 memory access patterns이 less efficient하다.
구체적으로, self-attention 수행 시, attention map()와 softmax map() 등의 intermediate maps을
high-speed GPU SRAM(실제 계산이 이루어지는 위치)에서 high bandwidth GPU memory (HBM)로 저장한 뒤, 다시 연산을 위해 불러와야 한다.
이때, SRAM의 read/write 속도는 HBM보다 10배 이상 빠르기 때문에, 이러한 data 이동은 상당한 memory accessing overhead를 발생시키고 wall-clock time(실제 경과 시간)을 증가시킨다.- SRAM은 GPU CUDA core와 on-chip(동일한 칩)에 직접 내장된 초고속 memory이며, L1/L2 cache 또는 shared memory가 여기에 해당함.
- HBM은 GPU의 main memory로 사용되는 고성능 DRAM.
GPU chip 외부에 있어 memory access(read/write) 속도가 SRAM access 속도에 비해 10배 이상 느리지만, 넓은 통로로 연결되어 대량의 데이터를 주고받을 수 있음. - 기존의 self-attention은 sequence length ()이 길어질수록 크기의 attention matrix를 만드는데,
이 matrix는 너무 커서 매우 빠르지만 매우 작은 SRAM에 모두 올릴 수 없고, 어쩔 수 없이 느린 HBM에 저장하고 계속 read/write 작업을 반복해야 헀음.
이 과정에서 GPU core는 연산을 멈추고 data가 오기를 기다리는 memory bottleneck 현상이 발생했음.
FlashAttention은 거대한 matrix를 HBM에 통째로 만들지 않고, 대신 Tiling 기법을 사용함.- 분할: Q, K, V matrix를 작은 block (tile) 단위로 나눔.
- SRAM 내 연산: HBM에서 작은 block 하나씩을 SRAM으로 가져옴. attention 계산의 모든 중간 과정을 SRAM 내에서 한 번에 끝냄.
- 결과만 저장: 최종 계산된 작은 block만 HBM에 다시 저장.
- 반복: 모든 block에 대해 이 과정을 반복하면서, softmax 계산을 위한 정규화 값을 유지.
여기서, Q의 각 block들은 K의 모든 block들과 dot product를 수행해아 완전한 attention score를 계산할 수 있는 거 아닌가?
그래서 FlashAttention은 이 문제를 outer loop와 inner loop 구조 및 지능적인 통계값(논문에서 ) 관리를 통해 해결함.
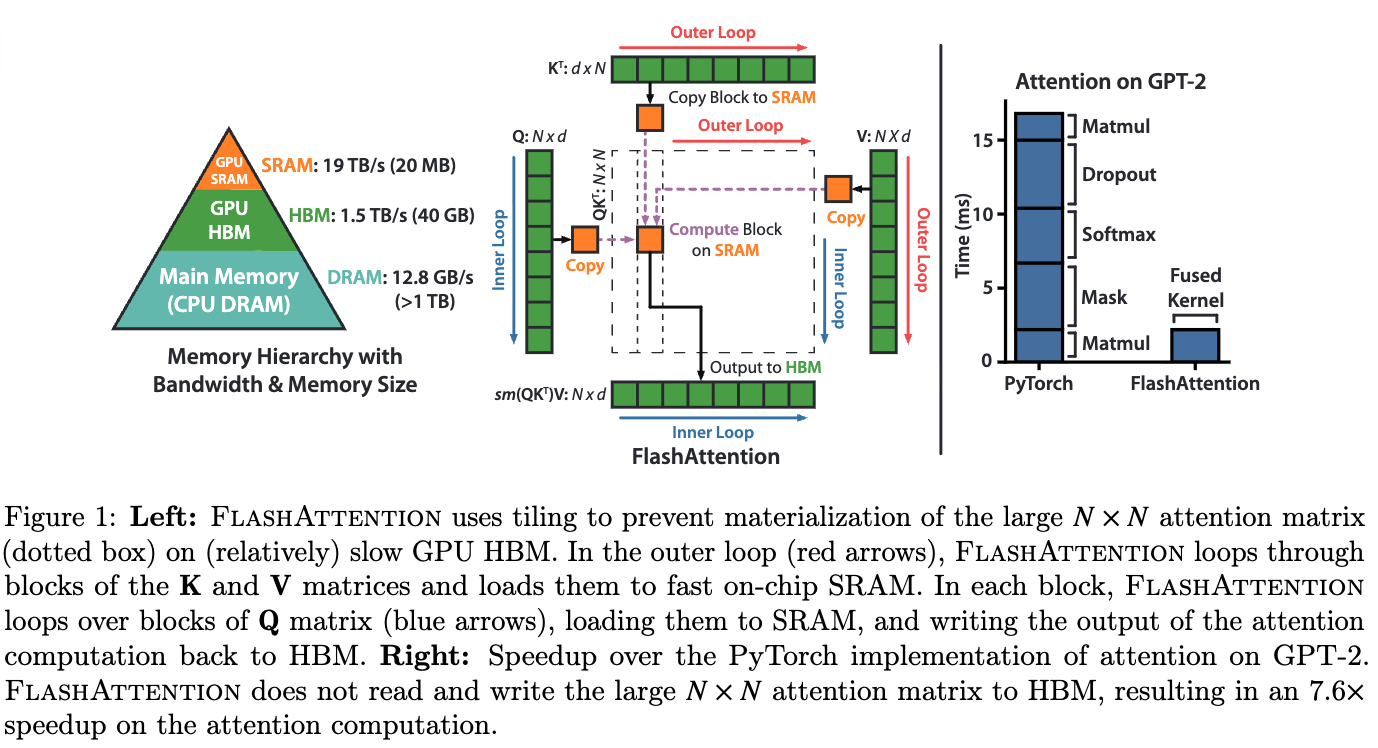
-
추가로, attention의 irregualr memory access patterns은 CNNs에 비해 further latnecy를 초래한다.
CNN은 spatially constrained kernels을 사용하기 때문에, efficient memory caching이 가능하고, fixed receptive fields와 sliding-window 연산 덕분에 latency가 줄어드는 이점을 가진다. -
위 two factors, quadratic computational complexity and inefficient memory accessing은 CNNs보다 느리게 한다.
이러한 limitations을 해결하기 위해 sparse attention mechanisms and memory-efficient approximation같은 critical area of research가 떠오르고 있다.
3.2. Area Attention (A2)
-
vanilla attention의 computationalal cost를 줄이는 가장 간단한 방법은 linear attention mechanism을 사용하는 것이다.
하지만, lienar attention은
global dependency degradation, instability, and distribution sensitivity로부터 문제를 겪는다.
게다가, low-rank bottleneck 때문에, input resolution 으로 YOLO에 적용하면, 제한된 speed 이점을 제공한다.- 문제 1: global dependency degradation
linear attention은 모든 token 간의 relation을 approximation하는 것이기 때문에,
sequence 내에서 멀리 떨어진 token들 간의 복잡한 global dependency를 standard attention만큼 완벽하게 capture하지 못하는 성능 저하가 발생할 수 있다. - 문제 2: instability
training 과정에서 수치적으로 불안정해져 학습이 제대로 수렴하지 않거나 어려워지는 경향이 있다. - 문제 3: distribution sensitivity
input data의 statistical distribution에 따라 성능이 크게 달라질 수 있다. - 문제 4: low-rank bottleneck
standard attention은 크기의 attention matrix 를 직접 계산하기 때문에,
이론적으로 의 rank를 가질 수 있음. high-rank matrix를 활용함.
linear attention은 similarity 를 직접 계산하는 대신 로 approximation하기 때문에 최대 rank는 임. row-rank matrix.
(행렬 이론에 따라, 두 행렬을 곱한 결과 행렬의 rank는 두 행렬의 rank 중 더 작읍 값보다 클 수 없음)
- 문제 1: global dependency degradation
-
또 다른 approach는 Figure 2에 보이는 것처럼 local attention mechanism (e.g., Shift window, criss-cross attention, and axial attention)을 사용해서,
global attention을 local로 transforms하여, computational costs를 줄이는 것이다. -
하지만, feature map을 windows로 partitioning하는 것은 overhead를 유발하거나 receptive field를 줄이게 되어 speed and accuracy에 영향을 미치게 된다.
이 연구에서, 우리는 simple yet efficient area attention module을 제안한다.
Figure 2처럼, the feature map with the resolution of 을 개의 segments of size 또는 로 나눈다.
이 과정은 explicit window partitioning을 제거하고, only a simple reshape operation만 요구하므로, faster speed를 도달할 수 있다.
우리는 경험적으로 the default value of 을 4로 하여 the original의 receptive field를 로 줄였고, 이는 여전히 a large receptive field를 유지한다.
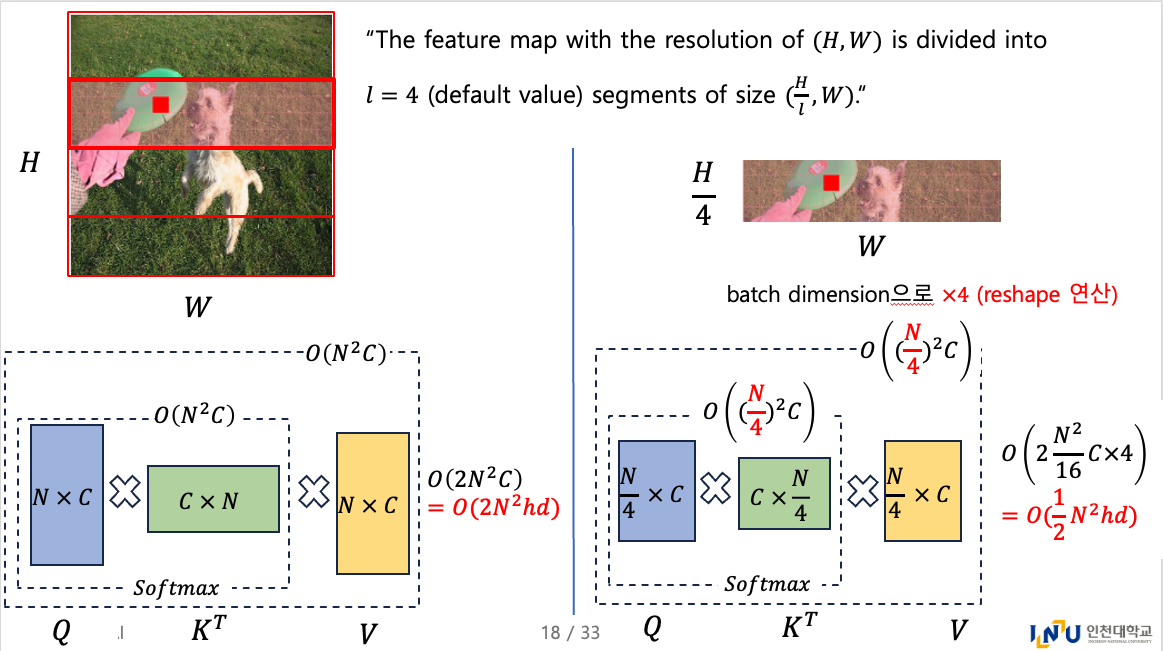

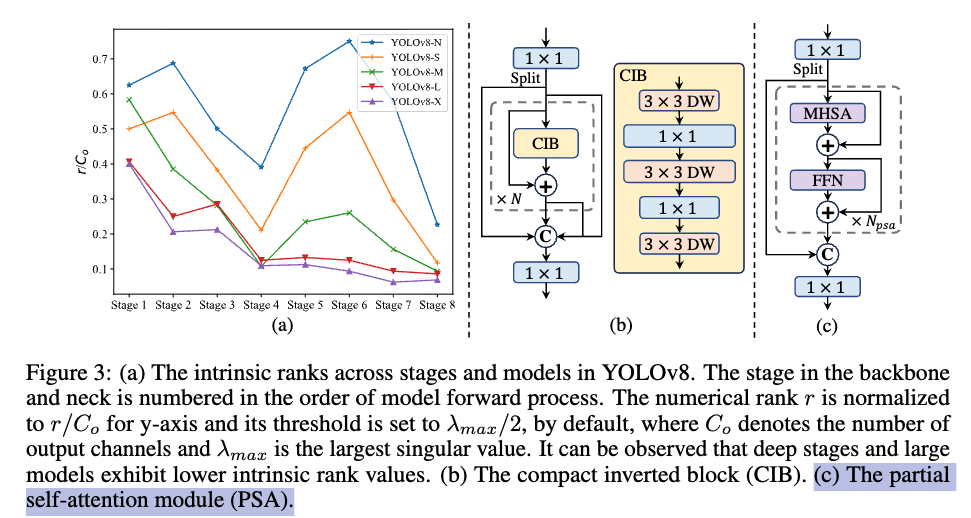
3.3. Residual Efficient Layer Aggregation Networks (R-ELAN)
-
Efficient layer aggregation networks (ELAN)은 feature aggregation을 향상시키기 위해 design되었다.
Figure 3(b)에서 보이는 것처럼, ELAN은 a transition layer ( convolution)의 output을 split항여,
one split은 multiple modules로 처리하고 나서 all the outputs를 concat하고
dimension을 align하기 위해 또 다른 transition layer (a convolution)를 적용한다.
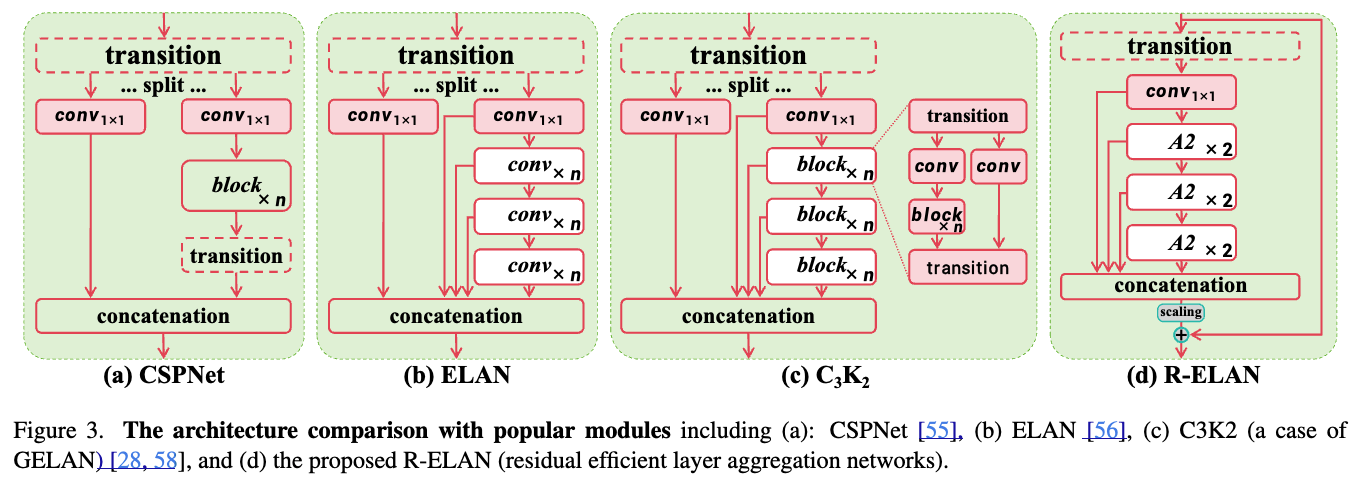
-
하지만 YOLOv7에서 분석한 대로, this architecture는 instability를 유발할 수 ㅇ있다.
우리는 이러한 ddesign은 gradient blocking으로부터 유발되고
from input to output으로의 residual connections이 없기 때문이라고 주장한다.
또한, 우리는 attention mechanism으로 network를 설계하면서, additional optimization challenges를 발견했다.
경험적으로, L- and X-scale models은 converge에 실패하거나 Adam or AdamW optimizers를 사용할 때도 unstable하게 남는다. -
이를 해결하기 위해, 우리는 residual efficient layer aggregation networks (R-ELAN)을 제안한다.
우리는 block 전체에 걸쳐 residual shortcut from input to output을 추가하고,
여기에 scaling factor (default 0.01)을 적용했다.
이 design은 deep vision transformer를 구축하기 위해 도입된 Layer scaling과 유사하다.
(layer scaling은 network가 deeper해질 때, 학습 초기에 random initialization된 layer들이 전체 information flow를 망가뜨리는 것을 방지하기 위해 새로운 layer에 대한 영향력을 초기에 매우 작게 만들고, 학습이 진행됨에 따라 점차적으로 역할을 찾아가도록 하여 optimization과 convergence 문제를 완화함.) -
그러나 각 Area Attention마다 Layer scaling을 적용하는 것은 optimization challenge를 해결하지 못할 뿐 아니라 latency를 지연시킨다.
이는 convergence 문제의 원인이 단순히 attention mechanism 때문이 아니라 ELAN architecture 그 자체임을 보여주며, 우리의 R-ELAN 설계의 근거를 뒷받침 한다.
또한 우리는 Figure 3(d)에 제시된 것처럼 새로운 aggregation 방식을 고안하였다.
기존 ELAN 레이어는 input을 먼저 transition layer를 통해 처리한 뒤 두 부분으로 나누었다.
그중 한 부분은 subsequent block에서 추가로 처리되고, 마지막에 두 부분을 concat하여 output을 생성한다.
반면 우리의 설계에서는 transition layer로 channel dimension을 조정한 뒤 feature map을 생성하고,
이를 subsequent blocks을 거친 뒤 concat하여 bottleneck structure를 형성한다.
3.4. Architectural Improvements
Related Works에 대한 간단한 사전 지식 공부
YOLOv1~v10
- YOLOv1 ~ v3는 single-scale + fully convolution network로 object detection 연구
(출처: https://arxiv.org/pdf/2408.09332)YOLOv1:
an input image first passes through CNN for feature extraction,
and then passes through two fully connected layers to obtain global features. (not full CNN)
Then, the aforementioned global features are reshaped back to the two-dimensional space for per grid
prediction.- Two import features:
- One-Stage Object Detector
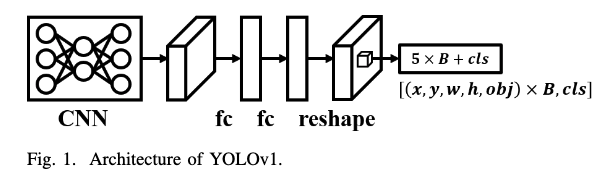
- Anchor-free BBox Regression

: image gride를 개의 grid로 나눌 때, 예측을 담당하는 특정 grid cell의 왼쪽 상단 모서리 좌표. 이 값은 이미지 전체 크기에 대해 정규화되어 있으며(0~1), 예측 과정에서 기준점 역할
: model이 직접 예측하는 출력값. 예측된 BBOX의 중심점이 grid cell의 로부터 얼마나 떨어져있는지를 나타내는 offset.
: model이 직접 예측하는 출력값. 예측된 BBOX의 width and height를 결정하는 scaling factor.
: 최종적으로 계산된 BBOX의 실제 좌표와 크기. 이 값들도 역시 image 전체 크기에 대해 정규화됨.
예를 들어, yolov1은 최종 output 출력이 이라고 했는데
#(grid cells) ,
#(BBOXs) ,
Pascal VOC #classes 이므로
최종 출력이 이 되는 것.
- One-Stage Object Detector
YOLO9000 (YOLOv2):
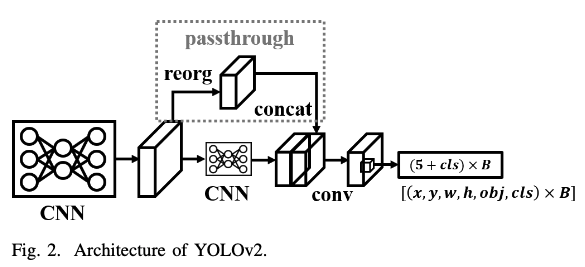
- architecture 관점
They converted the entire object detection architecture to full convolutional network.
They then combined high-resolution and low-resolution features, and finally use anchor-based for prediction. - training 관점
기존처럼 사람이 직접 anchor에 대해 a set of aspect ratio를 설정하는 방식은 BBox prediction 학습을 어렵게 만들었었음.
이를 해결하기 위해 IoU distance를 기준으로 ground-truth bounding box에 k-means clustering을 적용하여 anchor를 얻는 방법을 제안.
dataset에 가장 적합한 anchor box를 자동으로 찾기 위해 k-means clustering을 이용.
일반적인 k-means clustering은 Euclidean distance를 사용했는데, box의 크기가 클수록 Euclidean distance가 커지는 경향이 있어, IoU를 거리 측정 기준으로 사용.
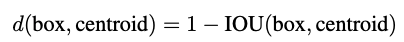
clustering 대상은 dataset에 있는 모든 GT bbox의 width and height를 대상으로, k-means clustering을 실행하여 모든 BBOX들을 개의 cluster로 나눔.
각 cluster의 centroid가 바로 dataset의 object size 분포를 가장 잘 나타내는 anchor box의 dimension이 됨.
즉, dimension priors를 만드는 과정.
데이터에 적합한 초기 anchor 값을 사용하므로, anchor-free 방식보다 모델의 학습이 더 안정적이며 빠르게 수렴.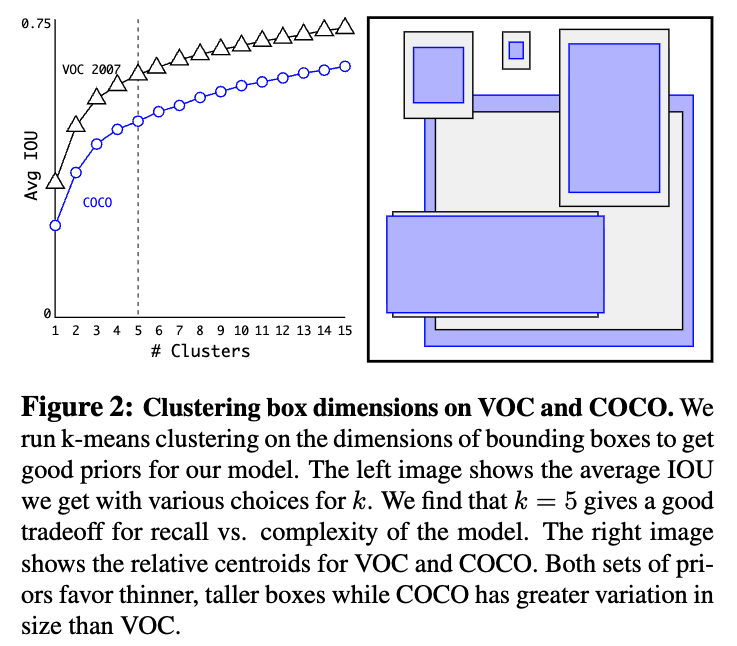
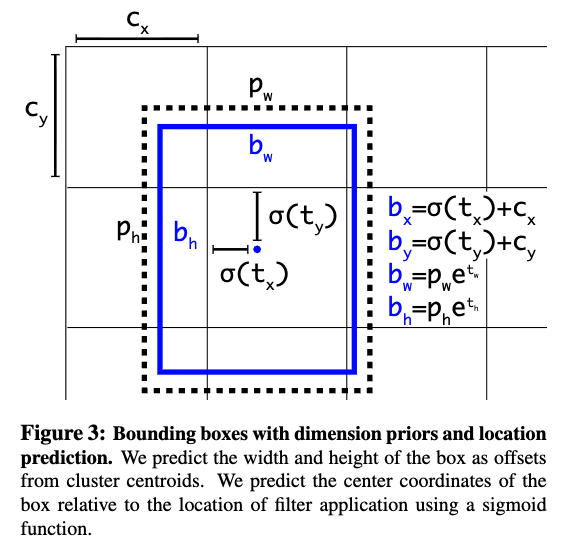
- architecture 관점
YOLOv3:
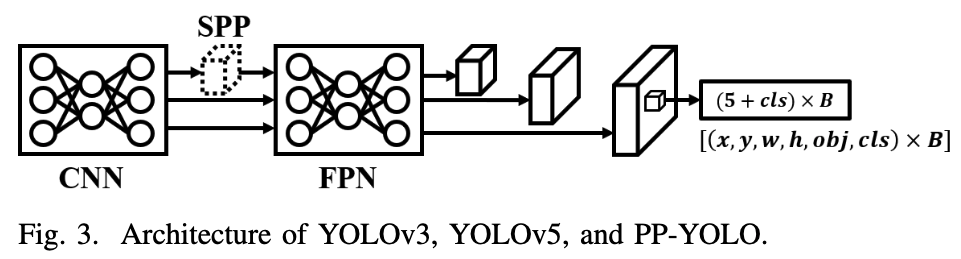
- architecture 관점:
architecture 관점에서, YOLOv3는 FPN을 사용해서 동시에 prediction of multiple scales을 가능하게 함.
또한, global context features를 얻는 부분에서 YOLOv1은 fc layer를 사용했고 YOLOv2는 passthrough layer를 사용해서 multiple resolution features를 결합했음.
YOLOv3는 multiple maximum pooling layers with a stride of 1 for kernel size from local to global을 design함.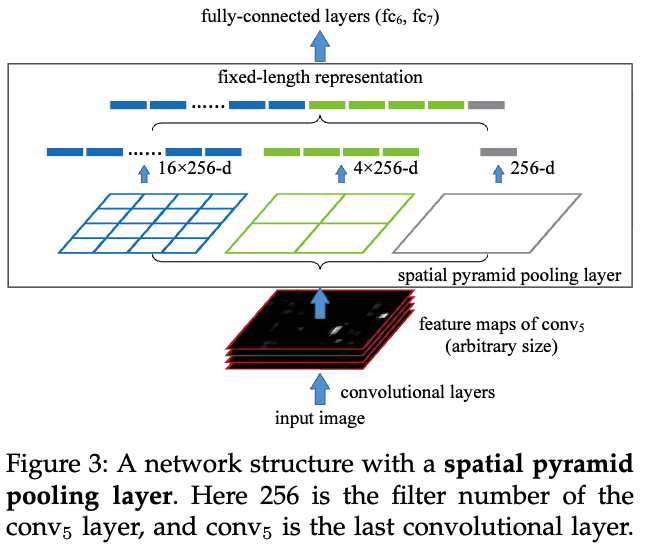
Feature Extractor로 Darknet-19에 대해서 1x1 conv, 3x3 conv로 deeper feature extraction network를 만들기 위해 shortcut connection을 추가하여 Darknet-53을 제안.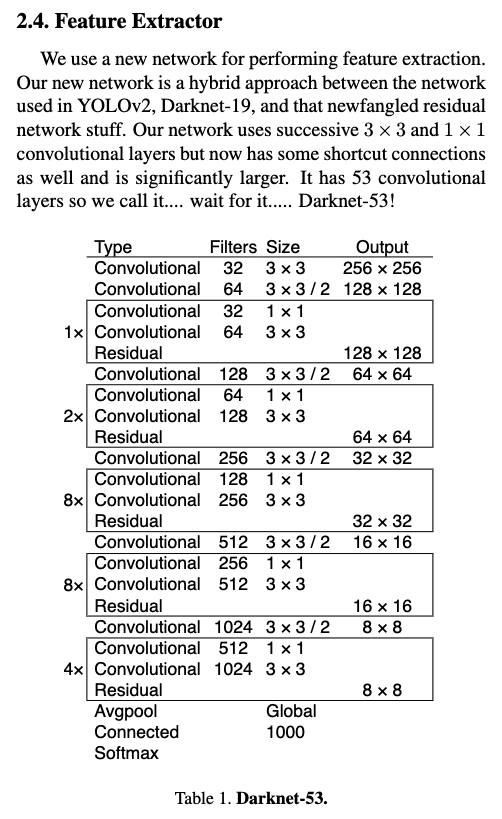
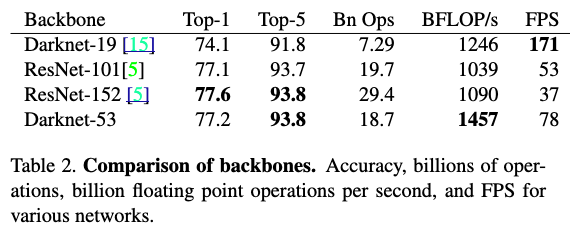
- training 관점:
YOLOv3 also made significant changes to the label assignment task.
The first change is that a ground truth will only be assigned to one anchor, while the second change is to change from soft label to hard label for IoU aware objectness.
- architecture 관점:
-
YOLOv4:
Bag of freebies(BoF)와 Bag of specials(BoS)를 자세히 분석하여, 아래와 같은 개선을 일궈냄.
BoF는 단지 loss function, regularization methods, data augmentation, and label assignment methods와 같이 inference time에는 영향을 주지 않고 training time만 증가시키지만 성능을 높힐 수 있는 방법들.
BoS는 inference time을 약간 증가시키지만 상당한 accuracy 향상을 이끌어내는 방법들.


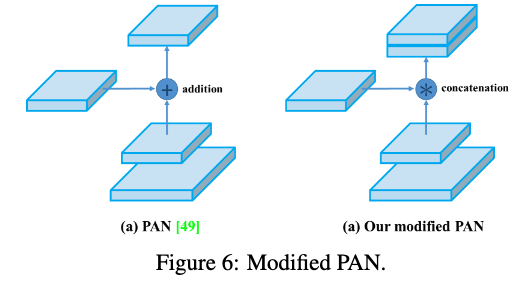
- architecture 관점:
FPN을 PAN으로 바꿈.
CSPNet을 backbone으로 도입.
YOLOv4부터 최근의 YOLOv12까지의 전체적인 구조가 확립됨.
hierachy 구조 도입, backbone + neck + head 구조를 명확히 함
- architecture 관점:
-
YOLOv5-
training strategies 관점:
training stability를 높이기 위해 Power-based decoder를 도입.
하지만 이 방식은 예측값의 범위를 제한하기 때문에, 이론적으로 model이 탐지할 수 있는 객체의 최대치, 즉 recall에 한계가 생기는 부작용이 있음.
recall은 model이 실제 존재하는 모든 object 중에서 얼마나 많이 찾아냈는지를 나타내는 지표.
recall이 낮음 = 실제 object를 탐지하지 못하는 경우가 많음

그래서 recall을 높이기 위해와 Neighbor Positive Samples라는 방법 도입.
기존에는 object의 center가 포함된 단 하나의 grid cell만이 해당 object를 detection할 responsibility(positive sample)을 가짐.
만약 이 cell이 object를 놓치면, 그 object는 탐지되지 못함.
그래서 object의 center가 있는 cell뿐만 아니라, 그 주변의 neighbor cell까지 positive sample로 지정.
즉, object 하나를 여러 gride cell이 detection할 수 있도록 기회를 늘려주는 효과.
-
-
YOLOv6 3.0
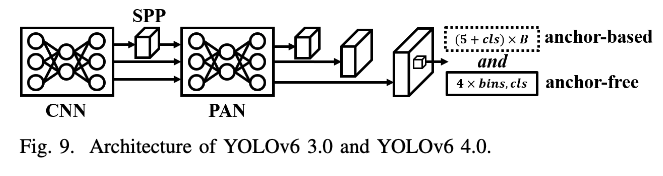
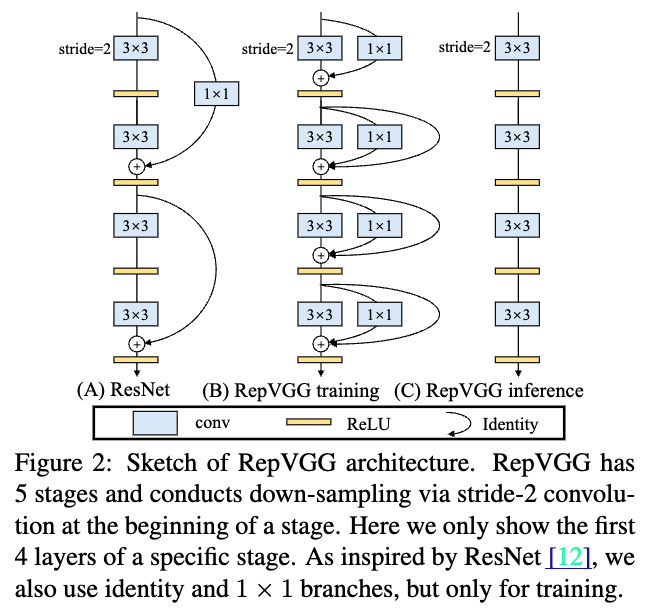
YOLOv6는 industry를 위해 특수 제작된거라 초기 version의 YOLOv6는 RepVGG를 main backbone architecture로 사용했음.
v2.0에서는 CSPNet을 backbone으로 사용함.
또한, quantization issues에 대한 많은 노력들이 있었음.
RepOPT를 사용하여 quantized model을 더 stable하게 만들고, QAT와 knowledge distillation을 사용해서 quantized model의 accuracy를 늘리고 하는 등.
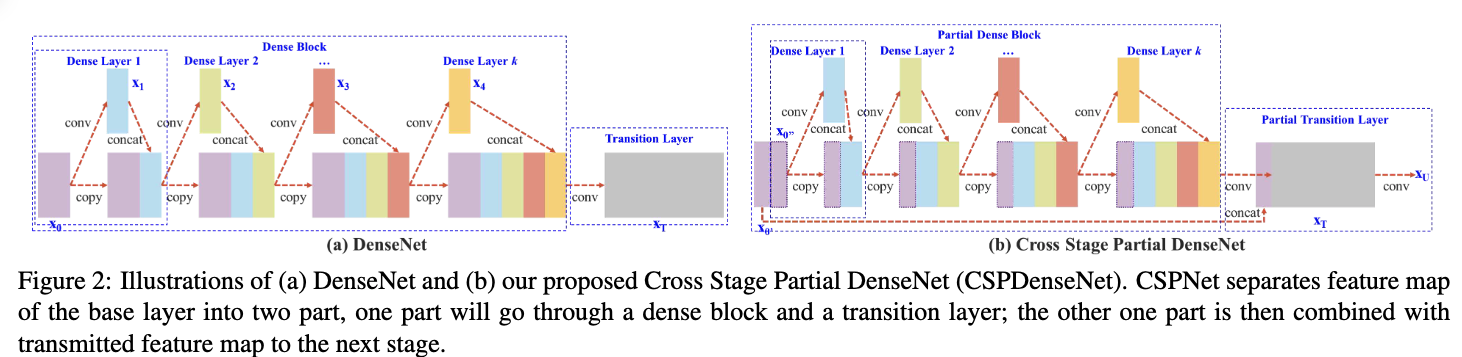
v3.0에서는 anchor-aid training이라는 개념을 제안하면서 system의 accury를 향상시킴.
Anchor-aid training은 anchor-free head learning을 보조하기 위해 anchor-based head를 사용하여 학습.
inference 시에는 anchor-free head만 사용 -
YOLOv7:
YOLOv7에서는 inference stage 동안에 제거되거나 계속해서 사용될 수도 있는 trainable auxiliary architectures를 제안함.
예를 들어, RepVGG와 additional auxiliary losses.
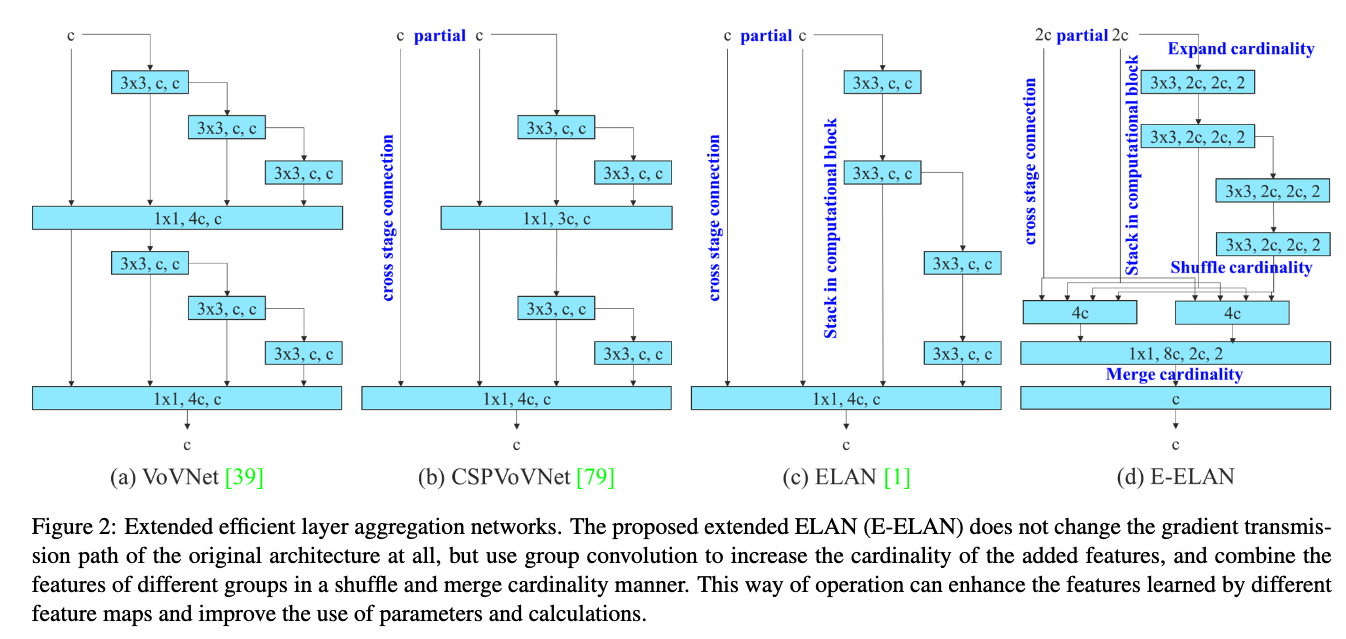
architecture 관점에서, YOLOv7은 기존의 YOLOv4 backbone CSPNet을 대체하기 위해 ELAN을 사용했고, large models을 설계하기 위해 E-ELAN을 제안함.
-
YOLOv8:
YOLOv5의 refactored version.
the overall AIP를 update하고 underlying code optimization을 진행.
architecture적으로는 YOLOv7's ELAN + additional residual connection + decoder는 YOLOv6 v2.0 유지
그래서 그렇게 새로운 YOLO version은 아님. -
YOLOv9:
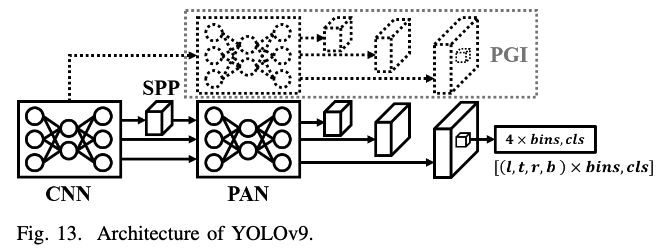
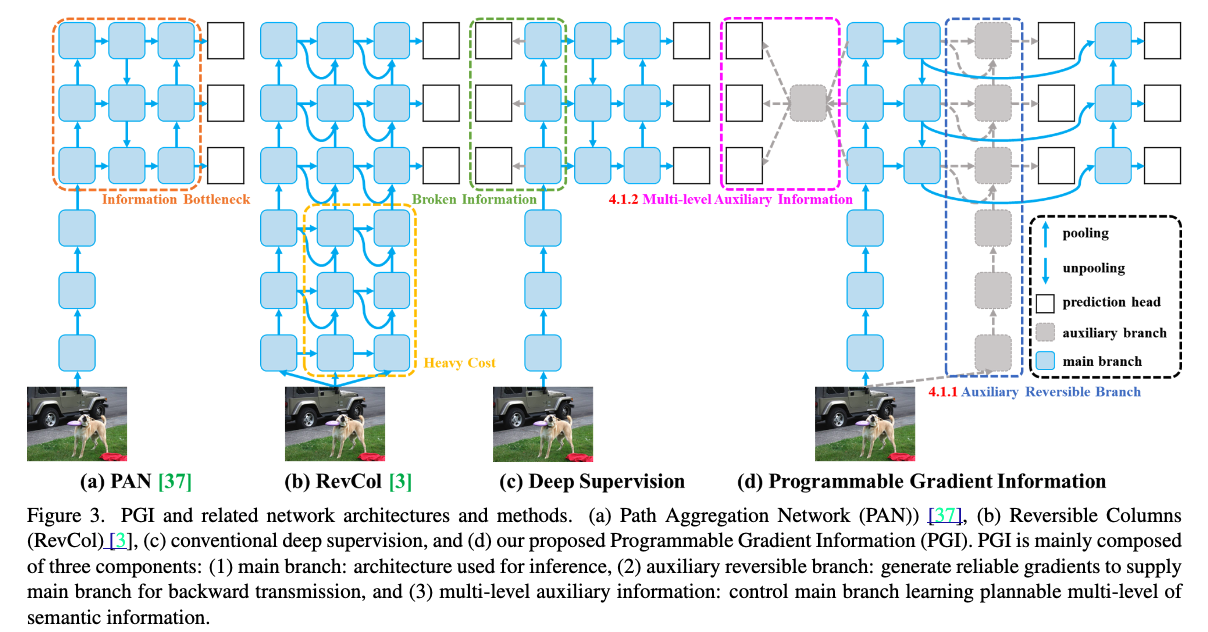
YOLOv9에서는 Progammable Gradient Information (PGI)를 제안함.
model이 깊어지면서 발생할 수 있는 information bottleneck을 해결하기 위한 기술.
원본 data의 정보를 최대한 보존하면서, 동시에 task performance를 위해 필요한 정보를 놓치지 않도록 하는 것이 설계 목표.
Auxiliary Reversible Branch와 Multi-level Auxiliary Information을 이용하여 위 목표 달성.
Auxiliary Reversible Branch로 reversible architecture의 특성을 활용하여 information loss 최소화.
이 reversible branch를 통해 보존된 정보는 main branch에 auxiliary information 형태로 공유되어 information bottleneck 현상을 해결.
Multi-level Auxiliary Information은 network의 shallow level에서 중요한 정보가 손실되는 것을 막기 위해 도입.
이를 통해 network의 모든 layer가 최종 목표에 필요한 정보를 최대한 유지할 수 있도록 함.
-
YOLOv10:
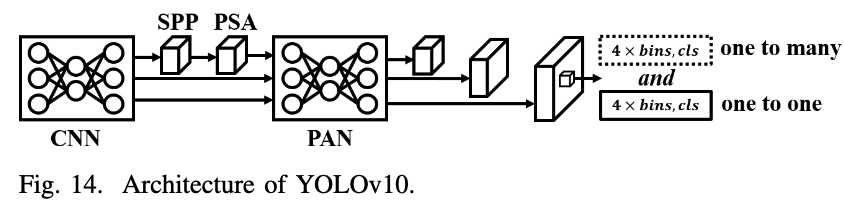
YOLOv6 3.0과 유사하지만, global feature를 extraction하기 위해 transformer-based module, Partial Self-Attention (PSA)이 추가됨.
그리고 YOLOv6 3.0의 dual head(anchor-free and anchor-based)를 각각 one-to-one and one-to-many matching으로 바꿈.
이를 통해, DETR-based method처럼 post-processing을 없애서 end-to-end object ddetection results를 얻을 수 있도록 함.
partial self-attention (PSA)
channel을 반으로 나눠, 반만 attention하겠다.
나머지 반은 attention 결과에 그대로 concat
FlashAttention
(참고: https://www.youtube.com/watch?v=ktpbVgQKy0g)
- attention mechanism의 inherent memory accessing problems을 극복하기 위해 제안된 attention.
YOLOv12에서 FlashAttention을 사용
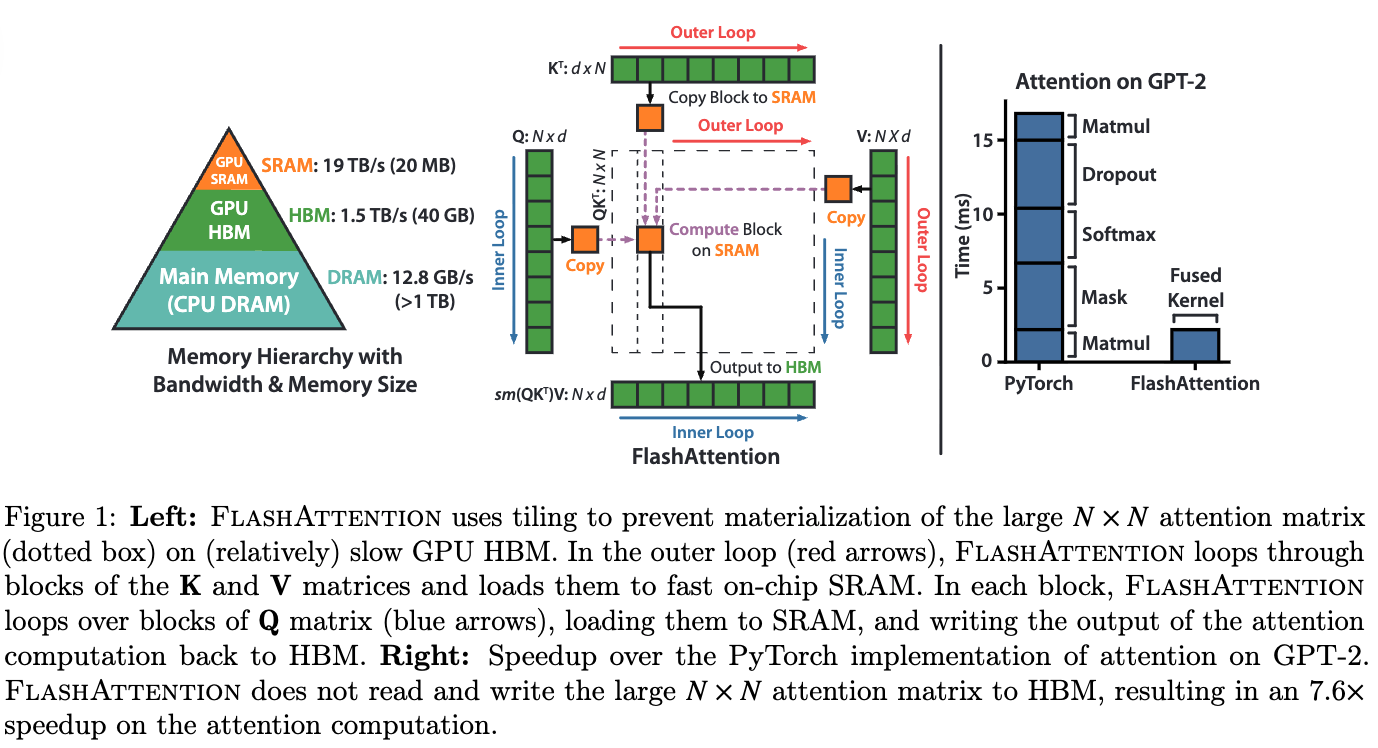
- HBM은 tensor들을 저장하고 있는 layer = .to('cuda')
- SRAM: HBM에서 tensor들을 read하여 실질적인 연산을 수행. 수행된 결과를 HBM write
Preliminary
- GPU memory
- HBM은 tensor들을 저장하고 있는 layer = .to('cuda')
- SRAM: HBM에서 tensor들을 read하여 실질적인 연산을 수행. 수행된 결과를 HBM write
y=Ax 예제
0. A, x 선언
1. y 선언
2. A, x, y를 HBM으로 Load # .to('cuda')
3. A, x를 HBM에서 SRAM으로 read
4. SRAM에서 A @ x
5. SRAM에 있는 결과 4.를 HBM의 y로 write- Arithmetic Intensity
- Compute-bound 연산
- computation(FLOPs)가 HBM SRAM의 IO(HBM)에 비해 더 bottleneck인 연산
- 예: Matmul. 큰 tensor를 read하는 시간 소요에 비해 연산도 꽤 걸림.
- memory-bound 연산
- HBM SRAM의 IO(HBM)가 computation(FLOPs)에 비해 더 bottleneck인 연산
- 예: Elem-wise ops. 큰 tensor를 read하는 시간 소요에 비해 연산은 금방 끝남.
- Compute-bound 연산
- 현재 HW적으로 GPu는 FLOPs보다 IO가 더 느린 상황.
Pipeline의 가속을 위해서는, FLOPs를 줄이는 것이 유리한지, IO를 줄이는 것(FlashAttention)이 유리한지 판단해야 함.
critique
불공정한 비교일 수도 있다
yolov10은 500 epoch,
yolov12는 600 epoch을 돌린 것 같은데... 공정한 비교가 맞는가?
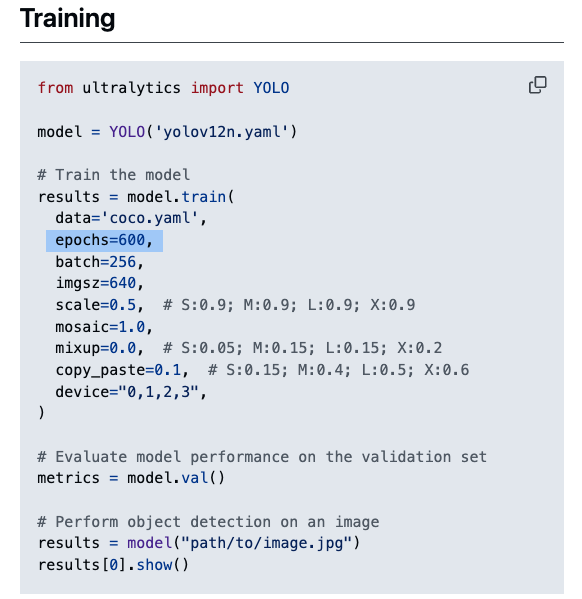
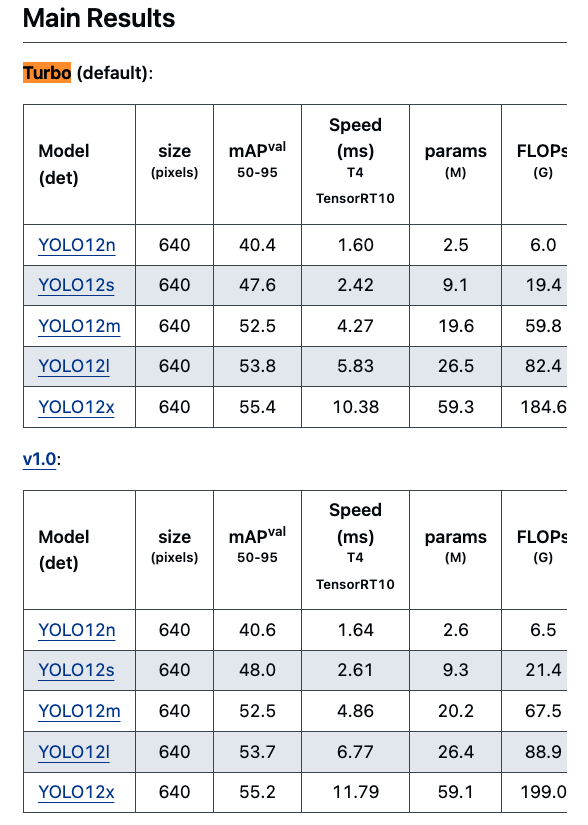
YOLOv12 .v1 vs .turbo는 무슨 차이?
- 현재 main branch는 YOLOv12 turbo branch(default)이고,
초기에는 v1 branch가 있었는데... yolov12 cfg file에서는 둘의 차이점이 드러나있지 않음.
training 방법 또는 class 내 내부 구현이 살짝 다를 수 있음..
이에 대한 명확한 차이점 명시가 필요.
appendix에 있을 것 같은데, NeurIPS poster에 accept은 되었는데 publish 직전이라 appendix는 못 구하겠음.