[2019 CVPR] NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Abstract
-
현재 object detection을 위한 SOTA conv architectures는 manually designed되었다.
-
우리는 OD를 위한 a better architecture of FPN을 학습하는 것을 목표로 한다.
우리는 Neural Architecture Search(NAS)를 채택하여 cross-scale connections을 cover하는 a novel scalabe search space에 대한 a new FPN architecture를 소개한다.
이 architecture는NAS-FPN이라 부르고, scale들 사이에 features를 fusion하는 top-down and bottom-up connections의 combination으로 구성되어 있다. -
NAS-FPN을 RetinaNet framework에서 다양한 backbone models과 결합하여 SOTA object detection models보다
better accuracy and latency tradeoff를 달성했다.
1. Introductoin
- (Object detection에서 FPN이 나오게 된 계기)
class probability만 출력하면 되는 image classification과는 달리,
object detection은 다양한 scales and locations 내에서 multiple objects를 detect and localize해야 한다.
이 어려움을 극복하고자, multiscale feature layers로 image에 대한 pyramidal feature representations을 represent했고,
이는 현대의 ODs에서 흔히 사용된다.
(FPN에 대한 간략한 설명)
- FPN은 OD에서 pyramidal feature representations을 만들어내기 위한 하나의 representative model architectures이다.
FPN은 backbone model에 top-down and lateral connections이라는 두 개의 adjacent layers를 sequentially combining하여 만들었다.
high-level features는 lower resolution이지만 semantically strong하기 때문에
high resolution and semantically strong을 둘 다 갖는 feature representations을 생성하기 위해
higher resolution features들과 upsampled and combined된다.
비록 FPN이 simple and effecitve하지만, not be the optimal architecture design이다.
(FPN에서 파생된 여러 버전들 설명)
- PANet은 FPN에서 an extra bottom-up pathway를 추가하여 lower resolution features에 대한 feature representations을 향상시킬 수 있음을 보였다.
Many recent works에서 pyramidal feature representations을 생성하기 위해 various cross-scale connections or operations을 제안하고 있다.
(문제 제기)
- feature pyramid architecture를 deisgning하는 것의 challenge는 its huge design space이다.
서로 다른 scales로부터 features를 combine하기 위한 가능한 connections의 수는 the number of layers와 함께 기하급수적으로 늘어난다.
(제안 방법, NAS)
-
최근, NAS algorithm이 a huge search space에서
image classification을 위한 top-performing architecture를 efficiently discovering할 수 있는 유망한 방법임을 증명했다. -
[45]에서 영감을 받아, pyramidal representations을 생성하는 scalable architecture의 search space를 제안한다.
우리 연구의 key contribution은 multiscale feature representations을 생성하는 모든 가능한 cross-scale connections을 cover하는 search space를 designing하는 것이다.
search 동안에, 우리는 동일한 input and output feature levels을 가지며 can be applied repeatedly될 수 있는
an atomic architecture를 찾는 것을 목표로 했다.
(내 생각: 위와 같은 atomic architecture는 다른 말로 module화 되어 있는 거라, 바로 다음에서 modular search space라고 부르는듯함..)- 이 modular search space는 pyramidal architectures를 searching하는 것을 manageable하게 했다.
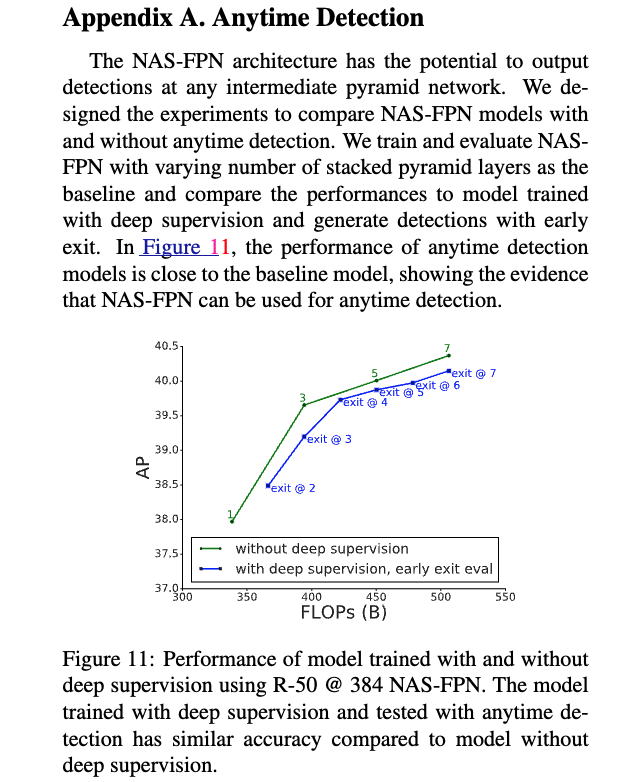
- modular pyramidal architecture의 또 다른 장점은 anytime object detection(or "early exit")이다.
2. Related Works
2.1. Architecture for Pyramidal Representations
-
multiscale feature presentations을 향상시키기 위해 많은 FPN variants들이 있었다.
-
pyramidal representations을 위해 manually designing architecture하는 것 대신에,
우리는 scalable search space와 NAS algorithm을 combination하여 pyramidal architectures의 the large search space를 극복했다.
2.2 Neural Architecture Search
-
[45]는 reinforcement learning with a controller RNN을 사용하여 cell(or a layer)를 설계한 NASNet은 ImageNet에서 SOTA acc를 달성했다.
search process의 efficiency를 향상시킨 network를 PNASNet라고 부르고, 이는 NASNet과 similar acc를 가짐.
유사하게, an evolution method [29]은 NASNet과 PNASNet을 향상시켜 AmoebaNets을 design하는 데에 사용되었다. -
RL controller와 evolution controllers는 유사한 성능을 보이므로, 이 논문의 experiment에서 RL controller만 사용했다.
-
우리의 method는 [44]와 비교했을 때, two major differences가 있다:
- [44]의 output은 classification을 위해 single scale features이지만 우리의 method는 multiscale features이다.
- [44]는 same feature resolution 내의 connections을 discovering하는 데에 집중했지만,
우리는 특히 cross-scale connections을 discovering하는 데에 집중했다.
3. Method
- our method는 RetinaNet framework에 based되어 있다.
The RetinaNet framework는 two main components를 갖는다:- a backbone network (often SOTA image classfication network)
- a feature pyramid networks (FPN)
- The goal of proposed algorithm은 RetinaNet을 위한 a better FPN architecture를 discover하는 것이다.
Figure 2는 RetinaNet architecture를 보여준다.
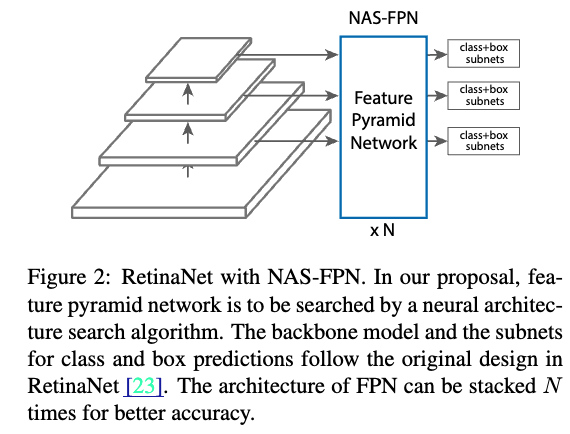
-
a better FPN을 discover하기 위해, 우리는 [44]에서 제안된 NAS framework를 사용한다.
NAS는 RL을 사용하여 a given search space에서 best model architectures를 select하는 a controller를 학습한다. -
The controller는 search space에서 a child model의 acc를 reward signal로 취급하여 controller의 parameters를 update한다.
trial and error를 통해 controller는 시간이 지남에 따라 better architectures를 생성하는 것을 학습한다.
previous works [36, 44, 45]에서 확인되었듯이, search space는 architecture search의 성공에 중요한 역할이 된다. -
다음 section에서는,
feature pyramid representations을 생성하는 FPN을 위한 a search space를 design한다.
우리는 또한 search 동안에, FPN의 scalability를 위해서, FPN을 times repeat하고 나서, a large architecture로 concatenate한다.
우리는 우리의 feature pyramid architecture를 NAS-FPN이라고 부른다.
3.1. Architecture Search Space
- 우리의 search space에서, FPN은 여러 input layers를 combine하여 RetinaNet을 위한 representations을 생성하는 여러 개의 "merging cells"로 구성된다.
다음에서 FPN의 inputs과 each merging cell이 어떻게 구성되는지 설명하겠다.
Feature Pyramid Network
- 우리는 RetinaNet design을 따르는데,
RetinaNet은 the last layer in each group of feature layers를 the inputs to the first pyramid network로 사용한다.
The output of the first pyramid network는 the input to the next pyramid network가 된다.- 우리는 feature stride of pixels 에 대응하는 5 scales 을 input features로 사용했다.
and 은 에 대해 각각 stride 2 and stirde 4 max pooling을 더해 만들어졌다. - 그리고나서 input features들은 a series of merging cells로 구성된 FPN을 거친다.
- 그러면 FPN은 augmented multiscale feature representations 을 outputs한다.
FPN의 inputs and outpus은 둘 다 identical scales을 갖기 때문에,
the architecture of the FPN은 better acc를 위해 can be stacked repeatedly()할 수 있다.
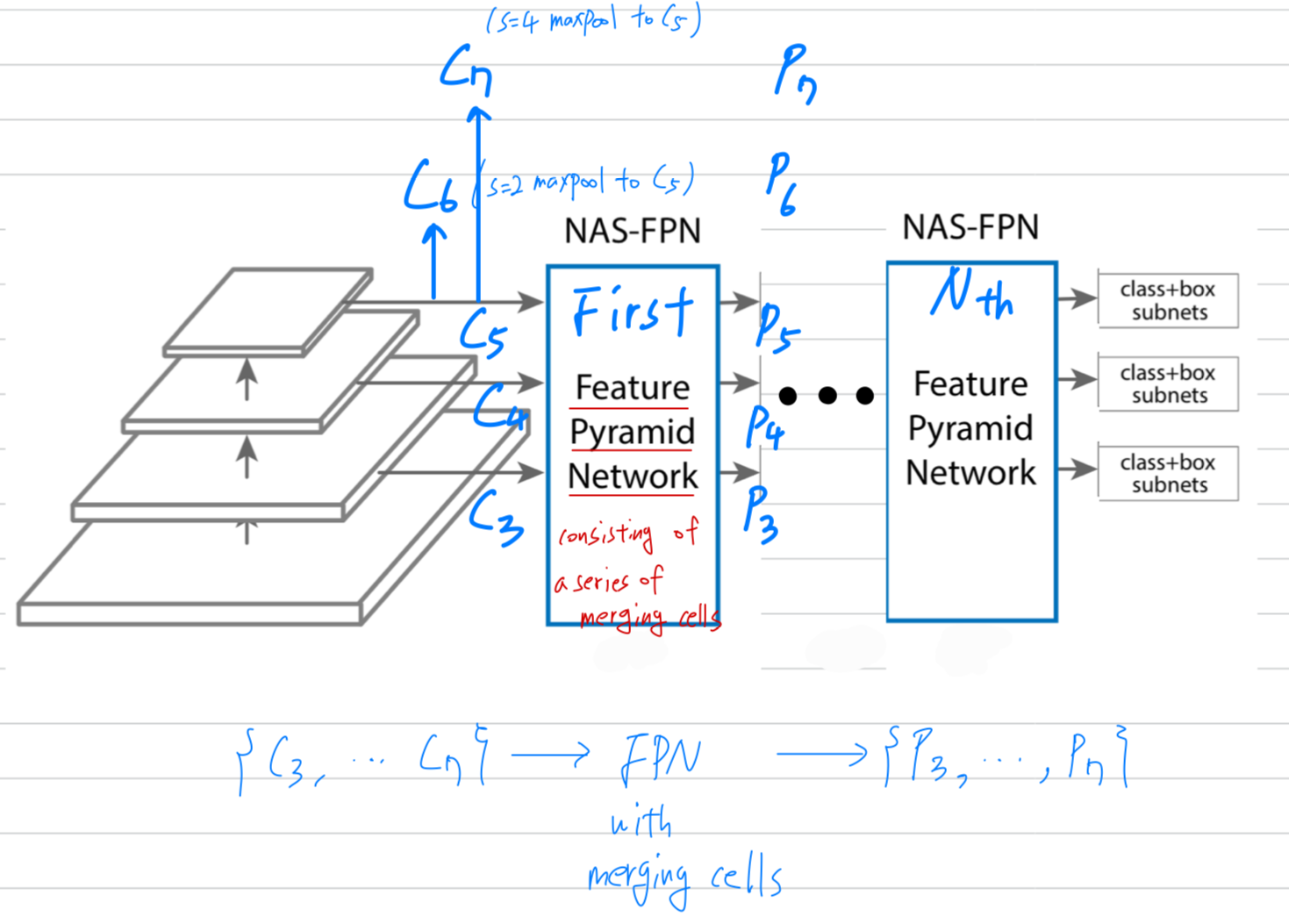
- 우리는 feature stride of pixels 에 대응하는 5 scales 을 input features로 사용했다.
Merging cell
-
OD의 이전 연구들에서 중요한 observation은 "merge" features at different scales의 필요성이다.
cross-scale connections은 high-level with strong semantics와 low-level features with high resolution을 combine하게 한다. -
우리는 merging cell을 제안한다.
merging cell은 any two input feature layers를 a output feature layer로 merge하기 위해 만들어진,
a fundamental building block of a FPN이다.- 우리의 implementation에서,
each merging cell은 two input feature layers(서로 다른 scales이 될 수 있다.)에 대해서,
processing operatiosn을 취하고,
one output feature layer of a desired scales을 만들기 위해 그들을 combines한다.
- 우리의 implementation에서,
-
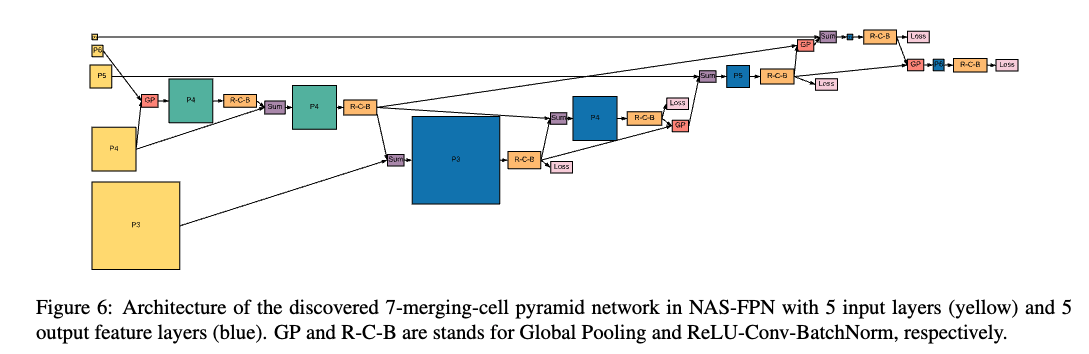
A FPN은 개의 서로 다른 merging cells로 구성되고, 은 search 동안에 주어진다.
a merge cell에서는, 모든 feature layers가 the same number of filters를 갖는다.
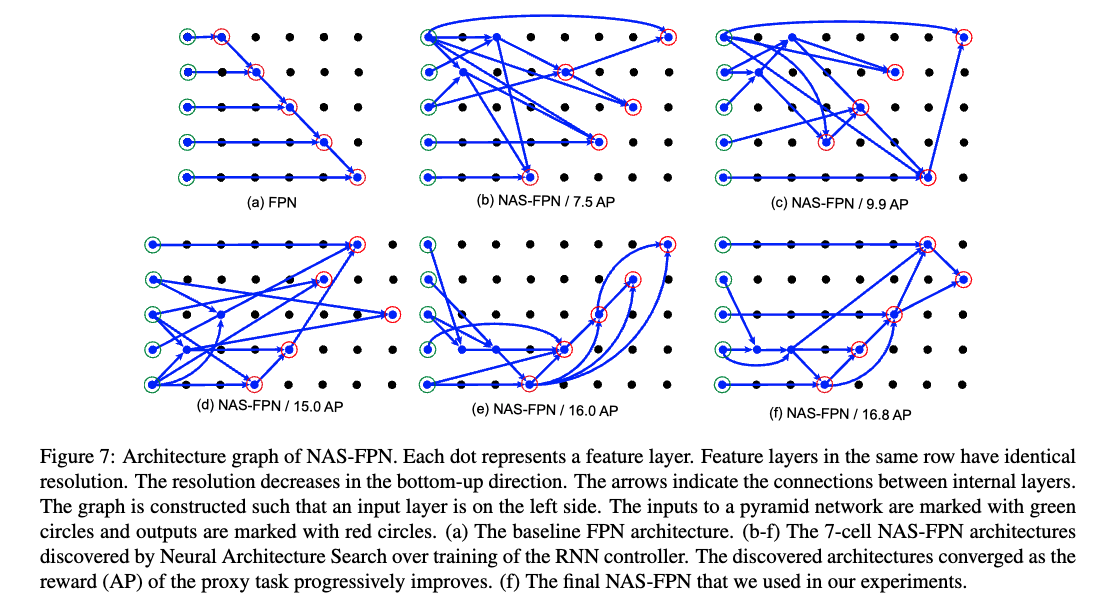
The process of constructing a merging cell은 Figure 3에 있다.
The decisions of how to construct the merging cell은 a controller RNN에 의해 만들어진다.
The RNN controller는any two candidate feature layers와a binary operation to combine theminto a new feature layer를selects한다.
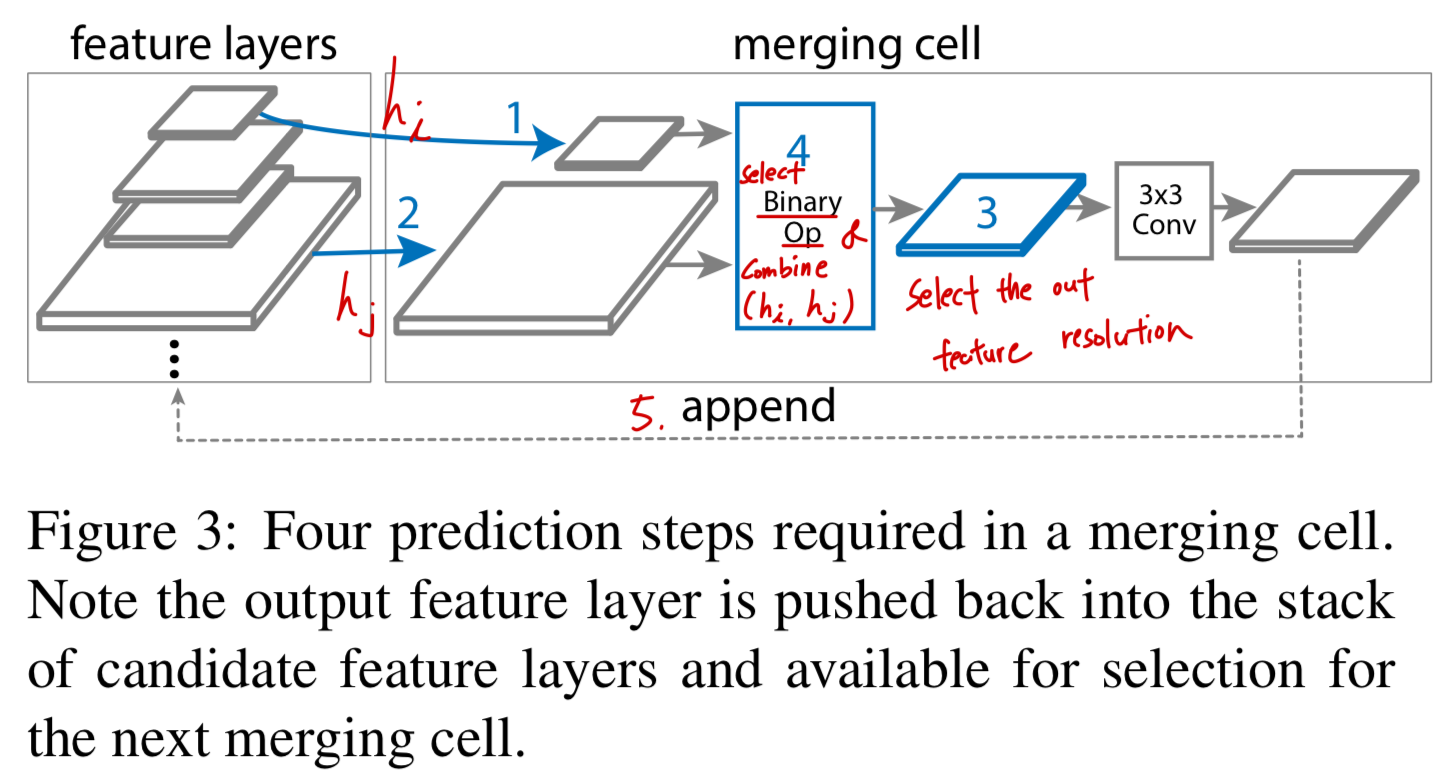 Each merging cell은 distinct softmax classifiers로 구성된 4 prediction steps을 갖는다:
Each merging cell은 distinct softmax classifiers로 구성된 4 prediction steps을 갖는다:Step 1.
Select a feature layer from candidatesStep 2.
Select another feature layer from candidates without replacement
(without replacement는 어떻게 한다는 뜻이지?)Step 3.
Select the output feature resolutionStep 4.
Select a binary op to combine (Step 1) and (Step2)
and generate a feature layer with the resolution selected in Step 3.
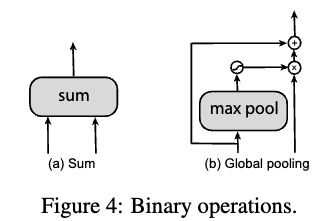 우리는 step 4에서 two binary operations를 design 했다.(sum and global pooling.)
우리는 step 4에서 two binary operations를 design 했다.(sum and global pooling.)
These two ops는 simplicty and efficiency를 위해 선택됐다.
sum and global pooling은 do not add any extra trainable parameters이다.
The input feature layers는 binary op를 적용하기 이전에 필요에 의해
nearest neighbor upsampling or max pooling으로 the output resolution이 조절된다.
The merged feature layer는 항상 ReLU, a 3x3 conv, and a BN layer로 구성되어있다.Step 5.
Step 5에서, the newly-generated featuer layer는 the list of existing input candidates로 append되고,
a new candidate for the next merging cell이 된다.
architecture search 동안에 the same resolution을 공유하는 multiple candidate features가 존재할 수 있다.
discovered architecture의 computation을 줄이기 위해서, 우리는 Step 3에서 selecting stride 8 feature를 avoid했다.Step 6.
마지막으로, the last 5 merging cells은 outputs feature pyramid 를 위해 design된다.
The order of output feature levels은 controller에 의해 predicted된다.
그리고나서 Each output feature layer는 the output feature pyramid가 fully generated될 때까지 step 1, 2, 4를 repeating함으로써 생성된다.
[44]와 유사하게, 그 어떠한 output layer에 연결되지 않은 모든 feature layers를 해당 resolution을 갖는 output layer와 sum해준다.
3.2. Deeply supervised Anytime Object Detection
- scaling NAS-FPN with stacked pyramid networks의 한가지 이점은
feature pyramid representations이 any given pyramid network의 output에서 얻어질 수 있다는 것이다.
이 property는 detections results를 early exit할 수 있는 anytime detection을 가능하게 한다는 것이다.
- [19, 13]에 영감을 받아, 우리는 all intermediate pyramid networks 이후에 classifier and box regression heads를 attach하고,
deep supervision [19]으로 학습시킬 수 있다.
inference 동안에, model은 all pyramid networks를 forward pass하지 않아도 된다.
대신에, model은 any pyramid network의 output에서 stop할 수 있고, detection results를 만들어낼 수 있다.
이는 computation resource or latency가 우려대상인 상황에서 desirable할 수 있다.
Appendix A에서, 우리는 NAS-FPN이 anytime detection으로 사용될 수 있음을 보인다.
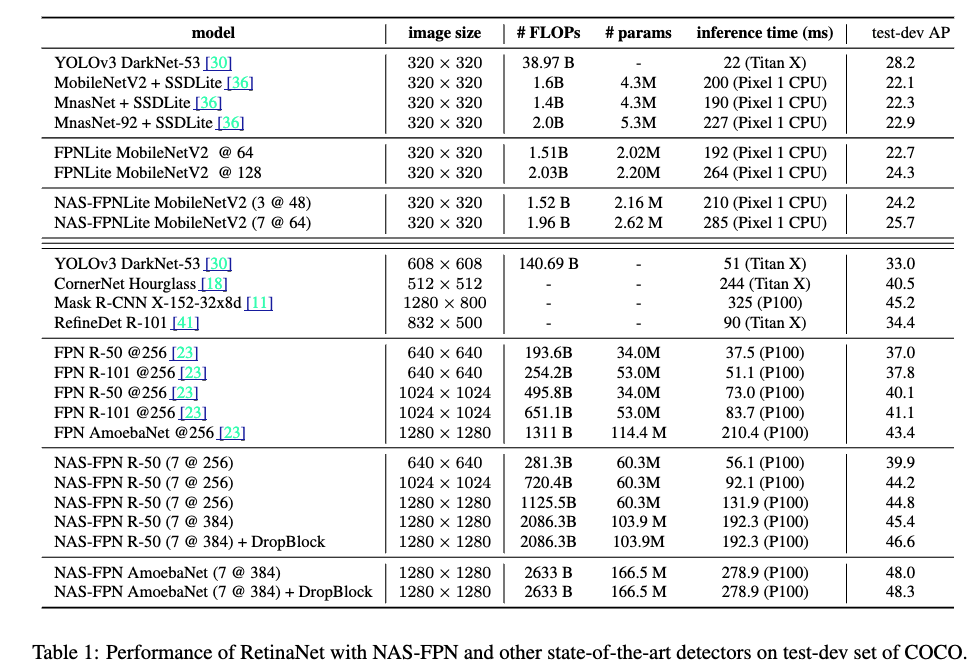
4. Experiments

Critique
Reinforcement Learning으로 controller를 학습해야 하는 과정이 필요해서 end-to-end training이 되지 않아보임.
controller 학습 자체에서 충분한 trial and error를 거쳐야 함.
