[2018 CVPR] Path Aggregation Network for Instance Segmentation
Paper Info.

Abstract
-
이 paper에서는, Path Aggregation Network (PANet)을 제안한다.
구체적으로, bottom-up path augmentation을 통해 lower layeers의 accurate localization signals로 the entire feature hierarchy를 강화하고,
이는 lower layers and topmost feature 사이의 information path를 줄일 수 있다. -
우리는 adaptive feature pooling을 제안한다.
이는 feature grid와 all feature levels을 link하여, 각 level의 useful information이 following proposal network로 직접 전달되도록 한다.
각 proposal에 대해 서로 다른 views(관점)을 capturing하는 complementary branch를 추가하여, mask prediction을 향상시킨다.
1. Introduction
- Instance segmentation은 각 image에 대해서 많은 instances를 localize하기 위해 class labels and pixel-wise instance masks를 predict하는 것을 목표로 하기 때문에 one of the most important and challenging tasks이다.
-
To achieve high performance, feature pyramid network(FPN)은 in-network feature hierachy를 extract하기 위해 사용되었고,
여기서, a top-down path with lateral connections으로 semantically strong features를 propagate하도록 보강되었다. -
최근 new released datasets은 새로운 algorithm 설계를 촉진한다.
COCO는 각 이미지에 complex spatial layout을 가진 여러 instances가 담겨 있다.
반면, Cityscapes and MVD는 각 image에 많은 traffic participants가 포함된 거리 장면을 제공한다.
이 dataset들에는 blur, heavy occlusion and extremly small instances가 나타난다. -
image classification에서 network를 설계하기 위해 제안된 몇 가지 principles들이 object recognition에도 효과적이다.
예를 들어, clear residual connection과 dense connection을 통해 information path를 shortening하고 information propagation을 쉽게 만드는 것이 유용하다.
또한, split-transform-merge strategy를 따라 parallel paths를 생성함으로써 information paths의 flexibility and diversity를 높이는 것 역시 도움이 된다.
Our Findings
- 우리의 연구는 SOTA Mask R-CNN의 information propagation을 더 향상시킬 수 있다.
구체적으로, feature in low levels은 large instance identification에 helpful하다.
하지만 low-level structure로부터 topmost features까지의 long path가 존재하고, 이는 accurate localization information을 access하기에 어려움을 증가시킨다.
이 process는 other levels에서 information들이 final prediction에서 유용할지라도 discarded되기 때문에 개선시킬 수 있다.
Our Contributions
- these principals and observations에 영감을 받아, instance segmentation을 위한 PANet을 제안한다.
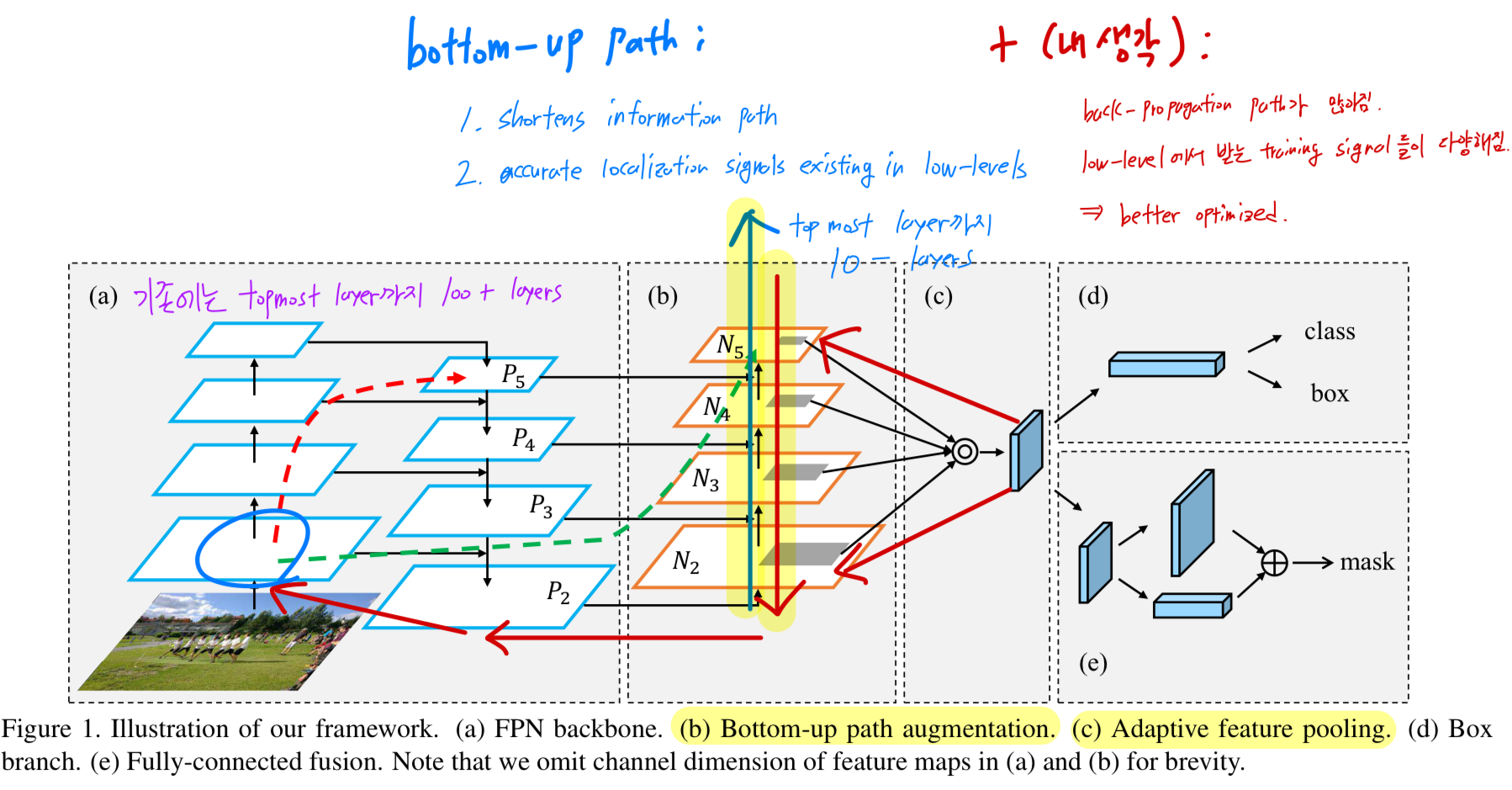
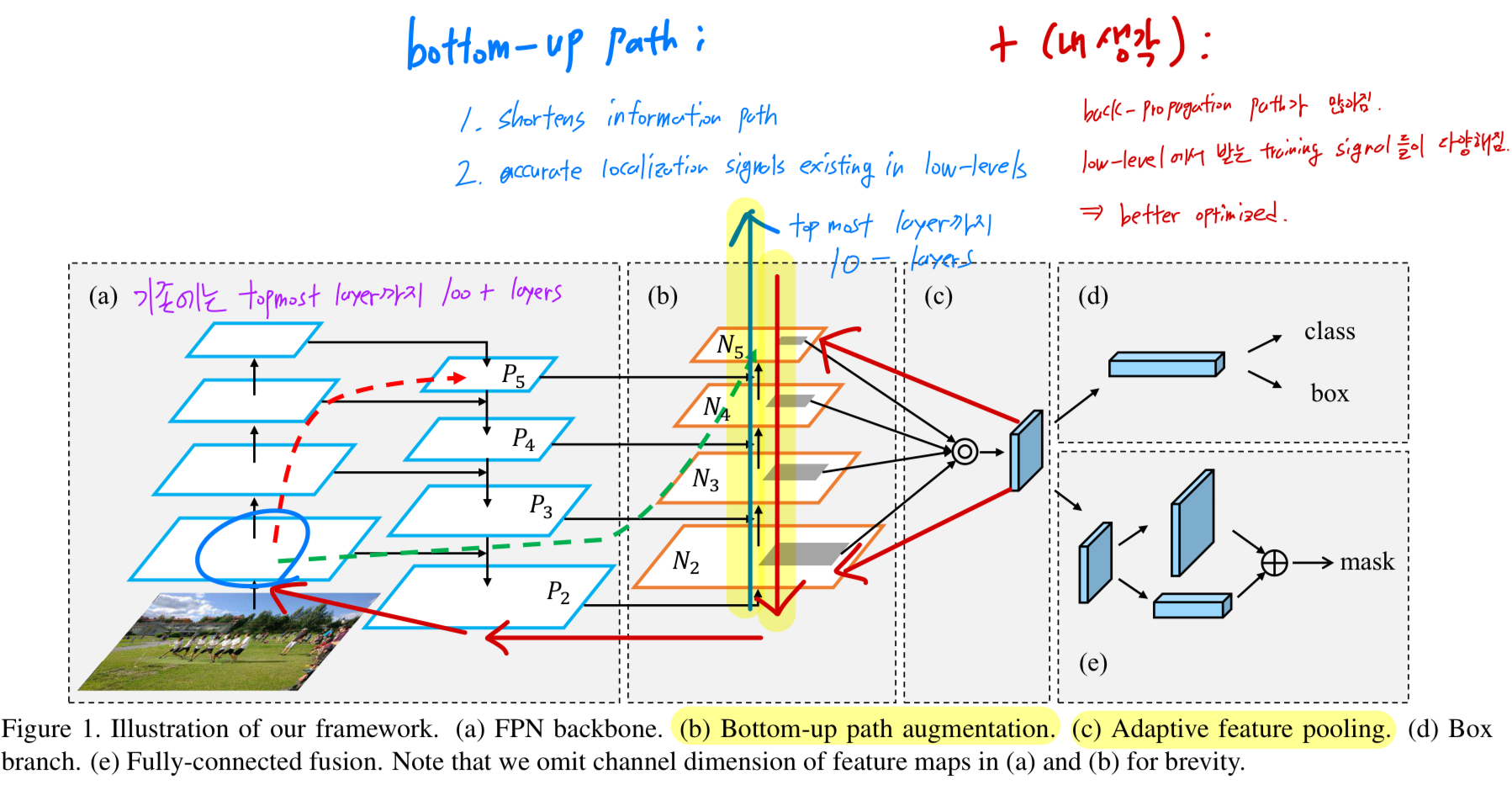
- (b): 우선, information path를 줄이고 fpn을 accurate localization signals existing in low-levels로 강화시키기 위해서,
bottom-up path augmentation을 생성한다. - (c): 두번째로, each proposal and all feature levels 간의 broken information path를 recover하기 위해서,
adaptive feature pooling을 개발했다.
이는 each proposal에 대해서 all feature levels로부터 features를 aggregate하는 a simple component이다. - (e): 마지막으로, 각 proposal의 서로 다른 views(관점)을 capture하기 위해, 우리는 tiny fully-connected(fc) layer를 사용해 mask prediction을 보강한다.
- (b): 우선, information path를 줄이고 fpn을 accurate localization signals existing in low-levels로 강화시키기 위해서,
2. Related Work
skip...
Larger Context Region
-
Larger context region methods에서는 서로 다른 resolution을 갖는 regions에서부터 context information을 활용하기 위해,
각 proposal에 대해 foveal 구조를 사용해 features를 pooled하였다.
larger region으로부터 pooled된 features는 surrounding context(주변 문맥 정보)를 제공한다. -
PSPNet과 ParseNet에서는 global pooling을 사용하여 semantic segmentation quality를 크게 향상시켰다.
[47] 또한 global convolutions을 이용해 유사한 경향을 보였다.
우리의 mask prediction branch 또한 global information을 access할 수 있도록 지원하지만, 우리의 방법은 기존 방법들과는 완전히 다르다.
3. Our Framework
- Our framework는 Figure 1에 그려져 있음.
- Path augmentation and aggregation은 imporving performance.
- A bottom-up pathway는 low-layer information을 easier to propagate하게 만듦.
- prediction을 위해 all levels로부터 information을 access할 수 있도록 each proposal에 대해 adaptive feature pooling을 설계.
- complementary path는 mask-prediction branch에 added됨.
3.1. Bottom-up Path Augmentation
Motivation
- [63]에서 제시된 insightful point는 high layers의 neuron은 entire objects에 strongly respond하는 반면,
다른 neurons들은 local texture and patterns에 activated된다는 것이다.
이는 FPN에서 semantically strong features를 propagate하고 all features가 reasonablee classification capability를 갖도록 top-down path를 추가해야 할 필요성을 보여준다.
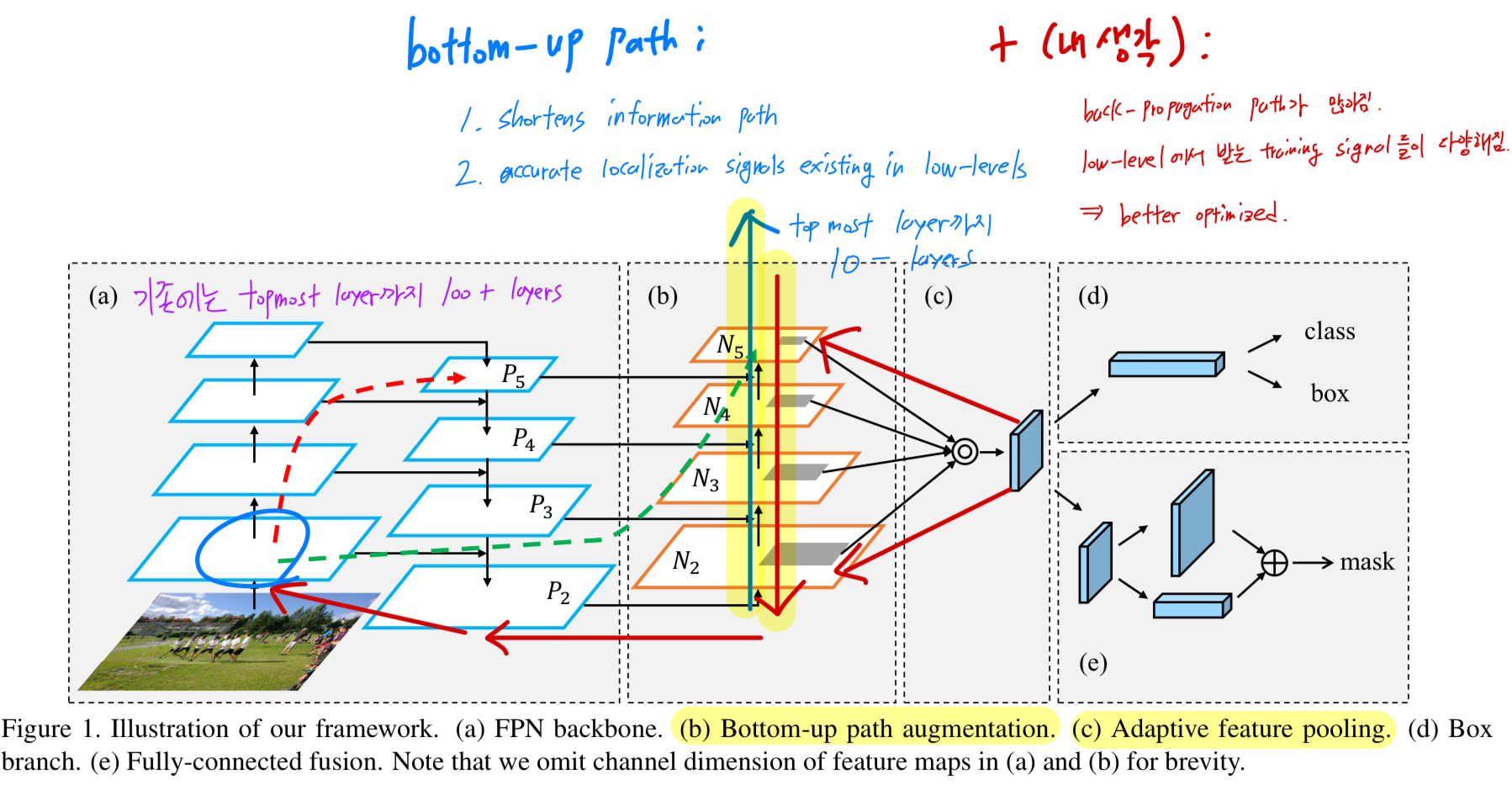
- Our framework 또한 low-level patterns의 strong reponses를 high-level에 전달함으로써 the entire feature hierarchy의 localization capability를 향상시킨다.
이를 위해, 우리는 from low level to top ones의 a path with clean lateral connections을 설계.
이 과저에서 "shorcut"(dashed green line in Fig 1)이 생성되며, 이 path는 less than 10 layers로 구성됨.
반면, FPN의 CNN trunk에서는 low layers에서 the topmost one까지 100+ layers를 거치는 long path(dashed red line in Fig 1)가 존재함.
Augmented Bottom-up Structure
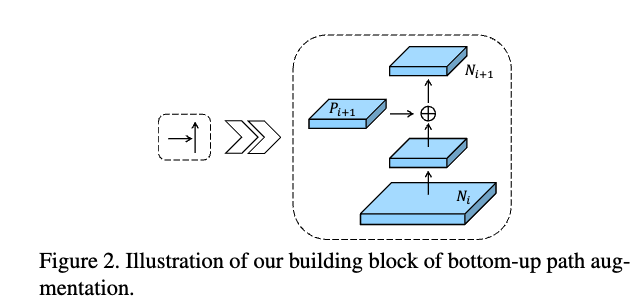
- Note that is simply , without any processing
- The feature grid for each proposal is then pooled from new feature maps, i.e.
3.2. Adaptive Feature Pooling
Motivation
-
FPN에서, proposals은 그 크기에 따라서 서로 다른 feature levels에 assigned된다.
그래서 small proposals은 low feature levels에 assigned되고 higher proposals은 high feature levels에 assigned된다.
이는 simple and effective긴 하지만, it could generate non-optimal results.
예를 들어, two proposals with 10-pixel difference는 서로 다른 levels에 assigned될 수 있다.
실제로, 이 two proposals은 similar하다. -
또한, feature의 importance는 반드시 그것이 속한 levels과 strongly correlated되지 않을 수 있다.
high-level features는 large receptive fields를 가지며 richer context information을 capture한다.
따라서 small proposals이 이러한 feature에 access할 수 있도록 하면, prediction에 유용한 fine details and high localization accuracy를 가질 수 있다.
따라서 large proposals이 low-level feature에 access할 수 있도록 하는 것은 obviously beneficial 하다.
이러한 생각을 바탕으로, each proposal마다 all levels로부터의 features를 pooling하고, 이를 prediction에 fusing하는 방법을 제안한다.
우리는 이 과정을 adaptive feature pooling이라고 부른다. -
이제 adaptive feature pooling을 통해 서로 다른 level에서 pooling된 feature들의 ratio를 분석한다.
우리는 서로 다른 level의 features들을 fuse하기 위해 max operation을 사용하였고,
이는 network가 element-wise useful information을 선택할 수 있도록 한다.
우리는 FPN에서 원래 assigned된 level을 기준으로, proposals들을 4개의 classes로 cluster했다.
각 set of proposals에 대해, 서로 다른 level에서 selected된 featurs의 비율을 계산한다.
notation에서, levels 는 low-to-high levels을 나타낸다.
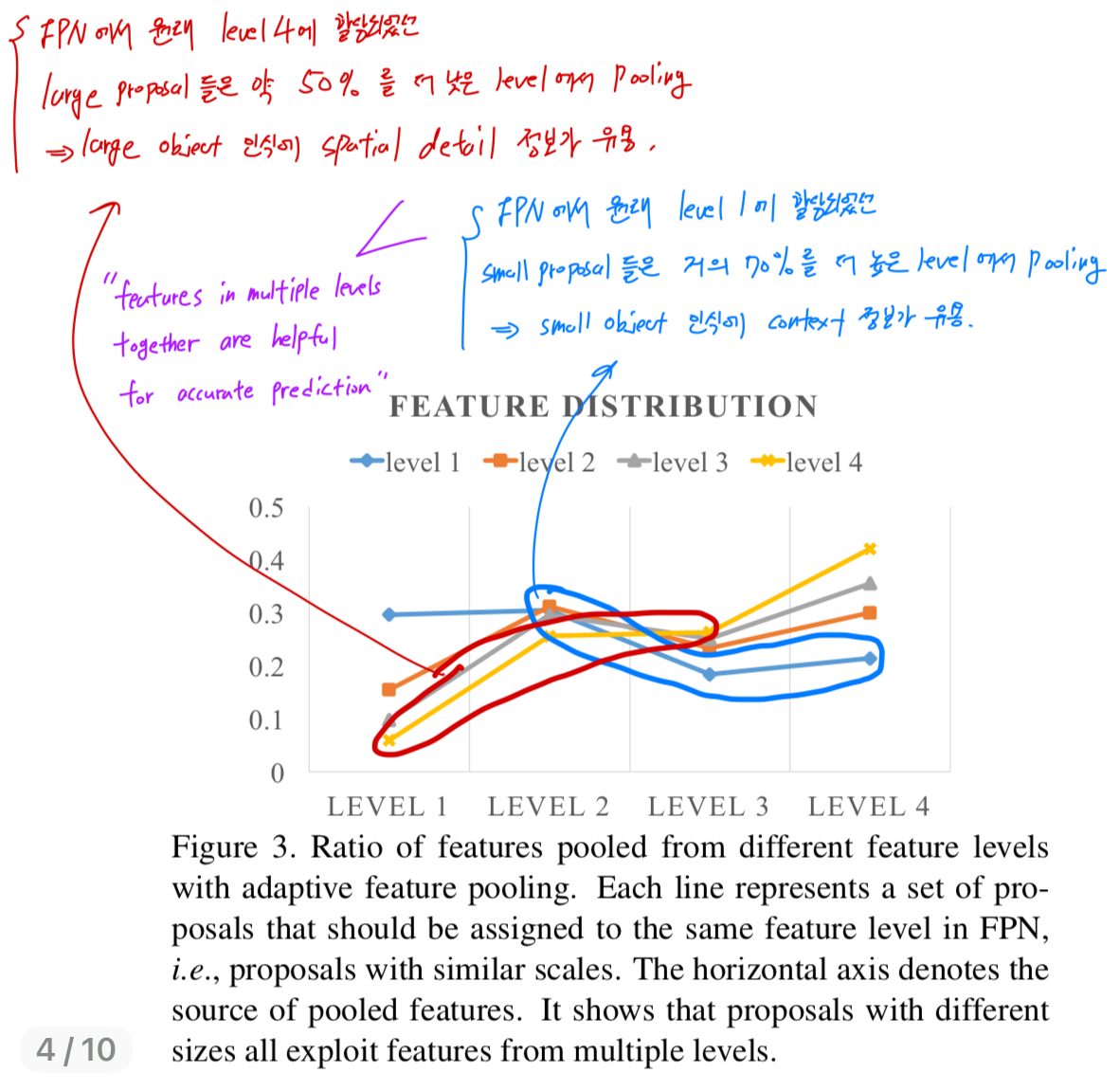 Figure 3에서 볼 수 있듯이,
Figure 3에서 볼 수 있듯이,
the blue line은 원래 FPN에서 level 1(low-level)에 할당된 small proposals을 나타낸다.
놀랍게도, 약 70%의 feature를 higher levels에서 가져온 것이다.
the yellow line은 FPN에서 level 4(high-level)에 할당된 large proposal을 나타낸다.
여기서도 50% 이상의 feature가 lower levels에서 pooling된 것이다.
이 관찰을 "features in multiple levels together are helpful for accurate prediction"을 명확히 보여주며, bottom-up path augmentation의 strong support가 된다.
Adaptive Feature Pooling Structure
- Adaptive feature pooling은 Fig 1(c)에 그려진 것처럼 simple in implementation이다.
- 먼저, 각 proposal에 대해서, 그들을 서로 다른 feature levels에 mapping한다.
(Fig 1(b)의 dark grey regions에서 denoted된 것처럼)
(Faster/Mask R-CNN에서는 RPN(Region Proposal Network)에 의해 아직 class가 확정되지 않은 후보 bounding box를 예측하는데, 이 예측된 후보 bounding box들을 proposal이라고 함.) - Mask R-CNN과 같이 ROIAlign을 사용하여 각 level에서 feature grid를 pooling한다.
- 이후 fusion 연산(element-wise max or sum)을 통해 서로 다른 level의 feature grid를 합친다.
- 다음 sub-networks에서는 pooling된 feature grid가 각각 하나의 parameter layer를 거친 뒤 fusion 연산을 수행하여 network가 feature를 adapt하도록 한다.
???
예를 들어, FPN의 box branch에는 두 개의 fc layer가 있다.
first layer 뒤에 fusion 연산을 적용한다.
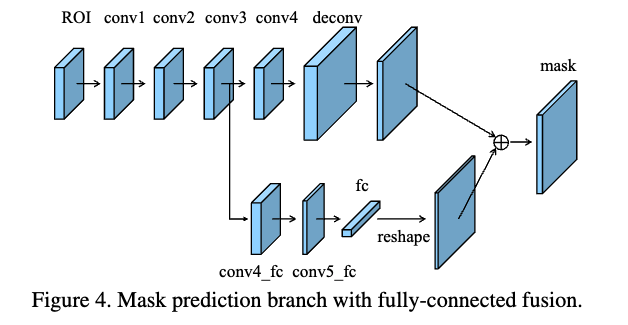
Mask R-CNN의 mask prediction branch에는 연속된 4개의 conv layer가 있으며, fusion 연산은 first and second conv layer 사이에 적용된다. (Ablation study는 Section 4.2.)
The fused feature grid는 각 proposal의 further prediction(classification, box regression and mask prediction)에 사용된다.
???
저자의 설명과 그림이 매치가 안돼서 ??? ~ ??? 부분을 이해 못하고 있었는데, 그림이 잘못된 것이 맞았다.
저자가 업데이트한 논문의 아래 Figure 6를 참고하니, 이해가 된다.
(Figure 1에서는 adaptive feature pooling과 sub-network 사이에 대한 디테일이 생략되었었다.)
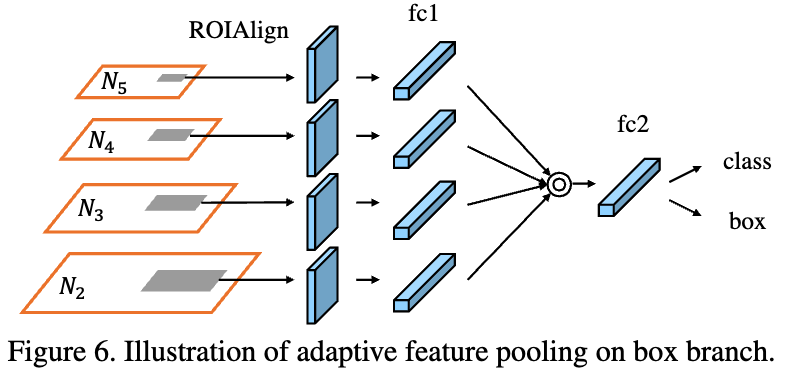
- 먼저, 각 proposal에 대해서, 그들을 서로 다른 feature levels에 mapping한다.
3.3. Fully-connected Fusion
Mask Prediction Structure
개념 정리
proposal
Faster R-CNN에서 Region Proposal Network(RPN)으로 후보 bounding box를 만들어 내는데, 이를 proposal이라고 함.
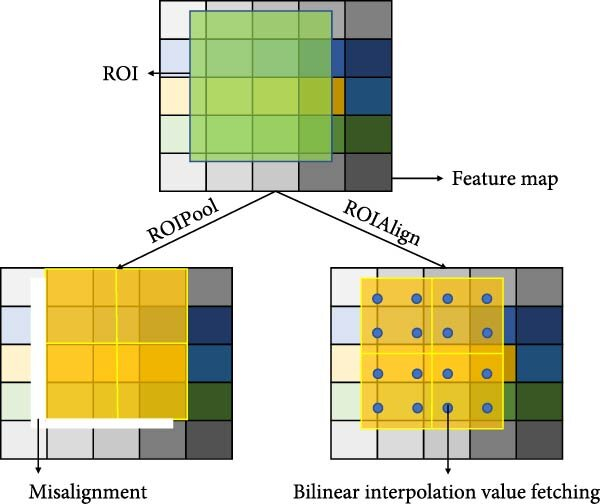
ROIPool vs. ROIAlign
(출처: https://www.researchgate.net/figure/Comparison-of-ROIAlign-and-ROIPool_fig3_380755265)
-
ROIPool- Faster R-CNN에서 처음 사용.
- 방법:
- Proposal (Region of Interest, ROI) box를 feature map 상에 mapping (위 그림 참고)
- mapping할 대, 해당 region을 고정 크기 (예: ) grid로 나눔
- grid마다 max pooling 수행.
- 문제점:
- ROI 좌표가 float인데, grid로 나눌 ㄸ때 정수로 quantization(rounding)함.
이 때문에 spatial misalignment 발생하여, small objeect나 mask segmentation에서 성능 저하.
그래서 Mask R-CNN에서는 ROIAlign을 제안
- ROI 좌표가 float인데, grid로 나눌 ㄸ때 정수로 quantization(rounding)함.
-
ROIAlign- Faster R-CNN에서 제안된 ROIPool의 단점을 개선하기 위해 Mask R-CNN에서 제안.

- 방법:
- ROI 좌표를 float 단위로 유지 (quantization 없음)
- grid sampling 시 bilinear interpolation 사용하여 sub-pixel 위치에서도 정확한 feature 값 추출
- 결과적으로 pixel 단위 정밀도 개선, small object 및 segmentation 성능 향상
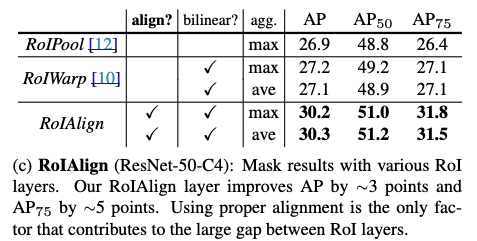
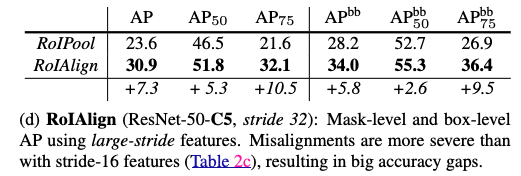
- Faster R-CNN에서 제안된 ROIPool의 단점을 개선하기 위해 Mask R-CNN에서 제안.
