[Chap 10] Virtual Memory
Memory Management의 대략적인 흐름
-
CPU가 바로 physical memory를 읽는 것이 가장 기본이었다.
하지만 Hole 관리가 어렵고 시간이 오래걸리는 문제가 있었다.
(External Fragmentation을 극복하기 위한 Compaction 또한 memory를 읽고 쓰는 데 비용이 발생.)
그래서 나온 방법이 Paging과 Segmentation이었다.
Paging : Logical memory(page) ➡️ Page Table ➡️ Physical memory(frame) -
Page는 CPU 입장에서 Logical Memory이고,
Page와 똑같은 것이 Frame이라는 것으로 Phyiscal Memory에 존재해야 한다.
➡️ Logical Memory와 Physical Memory는 1 : 1 관계라고 표현할 수 있다.
➡️ Logical Memory가 1MB라고 하면, Physical Memory도 1MB 있다는 것이다
➡️ 그런데 memory를 더 늘리고 싶다면? -
RAM이 1GB com, 128GB com 이 있다고 가정.
128GB의 memory가 필요한 game을 실행시킬 때,
1GB, 128GB는 둘 다 game을 진행시킬 수 있다.
(1GB는 힘들게 버벅이며 힘들게 실행시킬 것이고, 128GB는 부드럽게 실행시킬 것이다.)
그렇다면 1GB RAM Computer는 어떻게 이 게임을 진행시킬 수 있는가?- 1GB와 128GB 사이의 memory(127GB)만큼을 storage(HDD, SSD)를 이용하여 실행시키기 때문에
main memory보다 느리지만 실행이 된다.
그래서 버벅이지만 실행은 되는 것이다.
➡️이러한 기법을 Virtual Memory라고 한다.
- 1GB와 128GB 사이의 memory(127GB)만큼을 storage(HDD, SSD)를 이용하여 실행시키기 때문에
(정리)
logical memory와 physical memory를 page로만 두면, 1:1 관계이다.
하지만 실제로는 그렇지 않다.
예를 들어,
64-bit Computer일 때,
Physical Memory는 그대로이지만 Logical Memory는 16ZB의 data를 access할 수 있다.
하지만 실제로 Physical Memory를 16ZB 크기만큼 갖출 수 없기 때문에
실제로 Logical Memory의 크기와 Physical Memory의 크기가 다르다.
Logical Memory의 크기와 Physical Memory 사이의 크기 차이를 어떻게 극복할 것인가?
➡️Virtual Memory: 실제로 physical memory는 없지만 가상으로 있도록 해주자.
Demand Paging
-
Logical Memory를 Physical Memory로 가져오는데,
Physical Memory를 하염없이 늘릴 수 없다.
(64-bit Computer에서 를 Phsical Memory로 쓰는 것은 불가능하다.) -
Logical Memory의 크기는 커져도, Physical Memory의 크기에는 한계가 있다.
그러니까 어느 순간, Logical Memory가 읽으려는 memory가 Physical Memory에 존재하지 않을 수 있다. -
Demand Paging
: Logical Memory를 backing store에서 관리하고 있다가 필요할 때마다
Copy하여 Physical memory에 Write하는 기법.- Virtual memory = Logical memory
- memory map = page table
- backing store = storage(HDD, SSD)
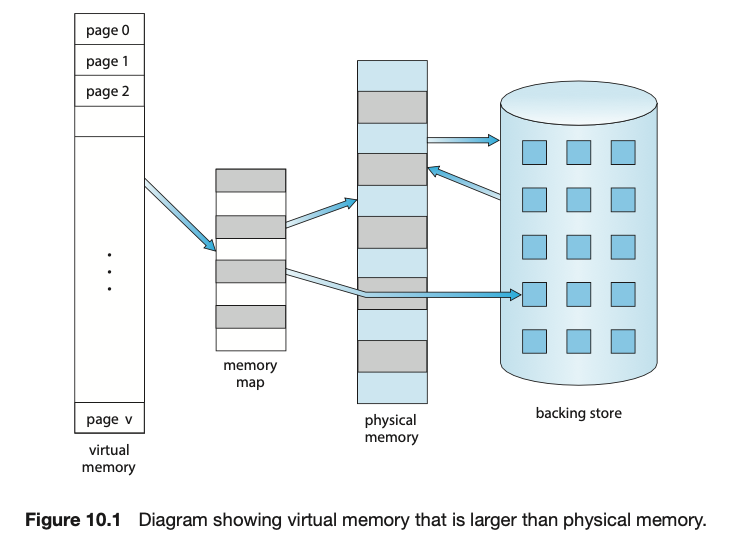
- Logical Memory에서 page 2의 내용이 필요한 상황이다.
- Page Table을 통해 page 2의 physical memory 위치를 얻는다.
- 하지만 Page 2의 내용은 Physical memory에 없고, backing store(HDD)에 있다.
- 그래서 Page 2의 내용을 HDD에서 read하여 Physical memory에 write한다.
➡️ 해결은 된다.
하지만 main memory에 해당하는 내용이 없다면,
HDD에서 read하여 memory에 write해야 하기 때문에 그 속도만큼 delay된다.
-
Demand Paging은Midterm-Scheduling과 유사하다.
Midterm-Scheduling에서 process를 main memory에서 HDD로 swap out,
HDD에서 main memory로 swap in하는 swapping 연산이 있었다.
Demand Paging는 process 단위가 아니라 page 단위이기 때문에
process의 일부는 main memory에 있는 것도 있고, 일부는 storage에 있는 것도 있다는 것이 차이점이다.
Steps in Handling Page Fault
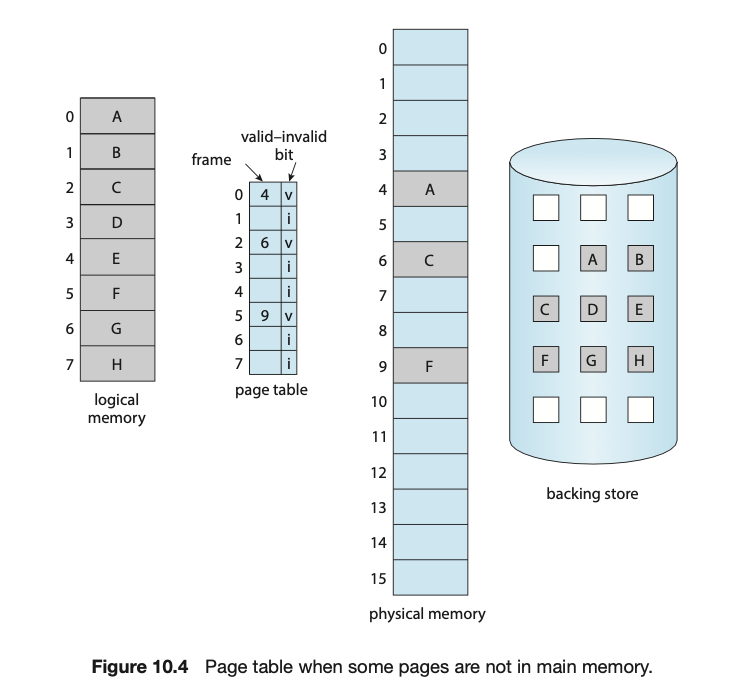
- 만약 읽으려고 하는 page가 main memory에 없다면,
backing store에서 main memory로 내용을 가져오기 위해
CPU에게 delay되는 시간을 벌어주기 위해Trap(Page Fault)을 발생시킨다.
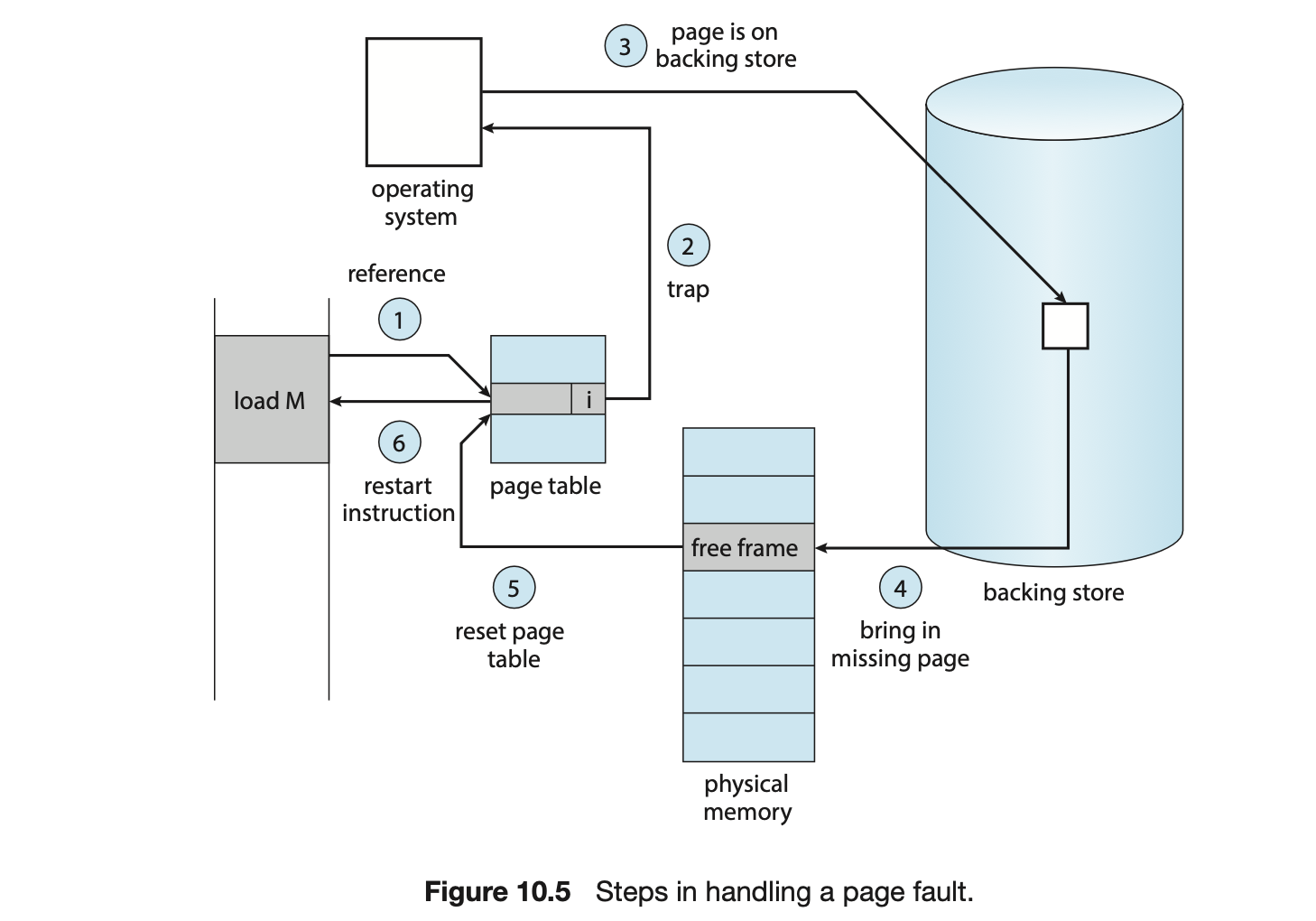
- OS에게 Page fault라고 하는 Trap을 발생시킴.
- invalid reference → abort : 잘못된 메모리를 요구하면? abort
just not in memory : 정상적인 메모리를 요구했지만 main memory에 없는 경우. - Find free frame(Hole)
- Swap page into frame via scheduled disk operation
- Reset tables to indicate page now in memory (set validation bit = v)
- Restart the instruction that caused the page fault
CPU 입장에서 생각해보자.
CPU에서 명령 하나를 실행한다고 가정해보자. ("100번지에 있는 내용을 AX register에 저장하라")
명령이 실행되고 있다고 가정.
100번지를 읽으려고 했는데, 100번지를 못 읽으니까 Trap을 걸어야 한다.
하지만 명령 하나는 atomic하기 때문에 중간에 Trap이 사실상 걸릴 수가 없다.
따라서 Trap이 실제로 걸리지는 않았지만, 걸렸다고 표현하고, 명령 자체를 취소한다.
그리고나서 100번지의 내용을 memory로 가져오고
취소한 명령을 처음부터 다시 Restart(Resume이 아님)하는 것이다.
