[Chap 9] Memory Management
Background
OS가 하는 여러가지 목표 중에 HW Resource를 보호하는 것이었다.
Memory도 Resource이다.
니 데이터가 300번지에 있다라고 알려주고, 실제로는 다른 번지에 있다. (보호하기 위해서)
➡️ 내가 알고 있는 주소가 실제 주소가 아닐 수도 있다.
Binding of Instructions and Data to Memory
- program은 원래 이진 실행 파일 형태로 disk에 저장되어 있다.
- memory 주소 공간에서 instruction과 data binding은
그 binding이 이루어지는 시점에 따라 다음과 같이 구분된다.
-
Compile Time Binding
: compile(compile + linking이 큰 의미의 compile)할 때, 실행 시의 실제 주소가 미리 정해짐
compiler는 Absolute code(절대 주소)를 생성.
만약 위치가 변경되어야 한다면, 그 코드는 다시 컴파일 되어야 함
➡️ 작은 시스템이나 embedded system 등에서 사용 (OS가 없는 또는 매우 작은)
➡️ Firmware는 code, data를 절대 번지로 지정해놓음 -
Load Time Binding
: program이 memory에 올라오는 순간, 주소가 확정 된다.
Loader의 책임 하에 주소 부여.
compiler는 일단 Relocatable Code(재배치 가능 코드)로 만듦
➡️ 시작점 m, 상대번지는 m+1, m+10, …
이런 식으로 가정한 m번지는 실제 loading할 떄, 확정되어서 나머지의 주소가 모두 확정남 -
Execution Time Binding
: Loading될 때는 대충 올려놓고 실행될 때, 주소가 확정된다 == Binding된다.
CPU가 주소를 생성할 때마다 Binding을 점검 (Address Mapping Table)
실행될 때마다, 주소가 바뀔 수 있다.
이것이 가능하려면, 특별한 HW를 이용해야 함 (ex. Base & limit)
OS는 Execution Time Binding을 대부분 사용한다.
Multistep Processing of a User Program
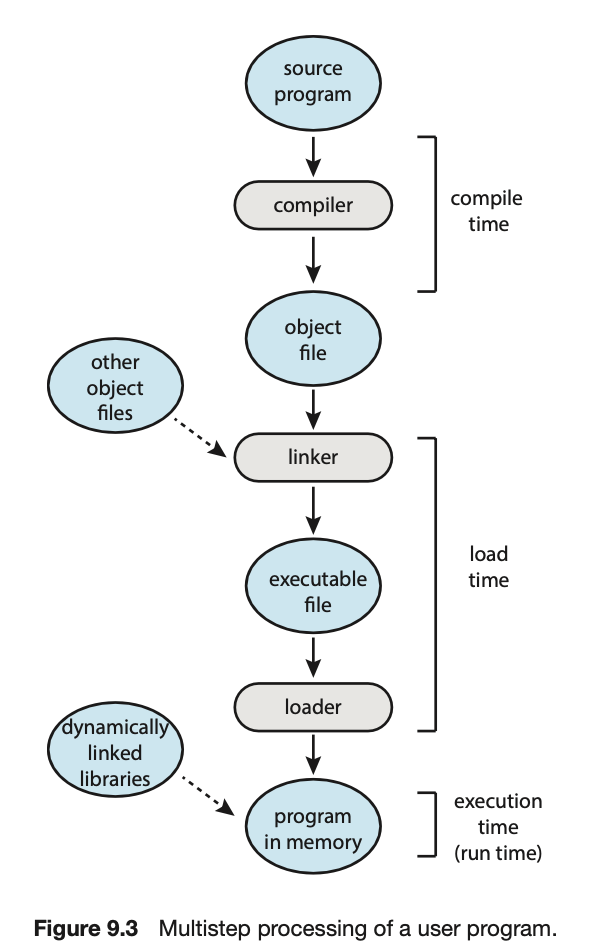
-
compile: source를 실행 가능한 명령어로 바꿔주는 과정
보통의 경우 compile되면, object file이 만들어짐
(Interpreter 언어는 소스코드를 바로바로 해석하여 실행됨)
➡️ compile을 하면, source code 언어가 다 달라도 system이 이해할 수 있는 중간 언어로 바뀐다.
각각의 언어의 장점에 맞게 코딩하고 모아서 사용할 수 있게 된다.
object 묶음이 library이다. (이미 컴파일된 것이기 때문에 바로 사용할 수 있다.
windows : .obj, linux : .o -
object에 linker를 linking.
이때, 실행파일이 만들어짐. -
실행파일을 실행시키면, loader가 동작하여 OS에게 memory에 올려달라는 요청.
OS가 실행파일을 memory에 올려줌. == loading

- A, B, C : 기호
- A는 100이라는 값이 있는 위치, B는 330이라는 값이 있는 위치, C는 exit라는 명령어가 있는 위치
그때 A, B라고 하는 것의 주소를 언제 명확하게 할 것인가?
1. Compile Time Binding
: 위 program이 compile되는 순간.
100은 30번지, 330은 32번지, .. 에 저장됨
2. Load Time Binding
: A가 30번지?32번지?인지는 모르겠지만
A가 100번지라고 정해졌으면 B는 102, C는 106번지 ... 로 정해진다.
3. Execution Time Binding
: program이 실행될 때, 명령어가 읽힐 때, OS가 할당해줌
마지막 정해지기 전까지 모든 번지는 기호이거나 상대번지이다.
Compile Time Binding이 아니라고 하면,
memory를 관리해주는게 반드시 있어야 한다.
그것이MMU(Memory Management Unit)이다.
Logical vs Physical Address Space
physical address: 실제 물리적으로 알고 있는 RAM에 배치되어 있는 주소.logical address:
실제 물리적으로 알고 있는 RAM에 배치되어 있는 주소가 아니다.
(나는 300번지라고 알고 있고 쓰고 있는데, 실제로는 4000임)
OS의MMU가 모든 과정에서 address를 낚아채서
physical address를 logical address로 바꾸어 알려준다.
우리가 아는 배열은 1, 2, 3, 4 번지 식으로 연속되어 있다고 아는데
실제로는 그렇지 않을 수 있다. 1000에 있는 것을 1로, 123을 2로, 35244을 3으로 .. 이렇게
따로 떨어져 있는 것을 1, 2, 3, 4라고MMU가 알려주는 것일 뿐이다.
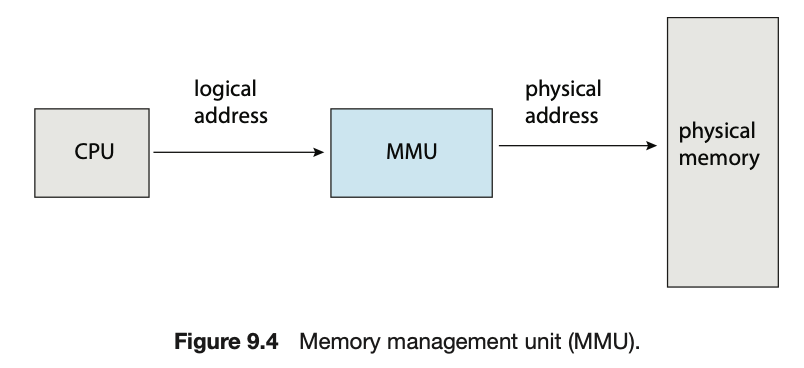
왜 바뀔까?
➡️ 대부분은 공간적인 효율을 위해
어떻게 바뀔까?
➡️ 여러가지 방법이 있다. (Address Mapping Table, MMU)
Address Mapping Table
- 주소 바꾸는 과정들을
Mapping이라고 하고,
아래와 같이 Table 형태로 바꾸는 것이 가장 기본이다.
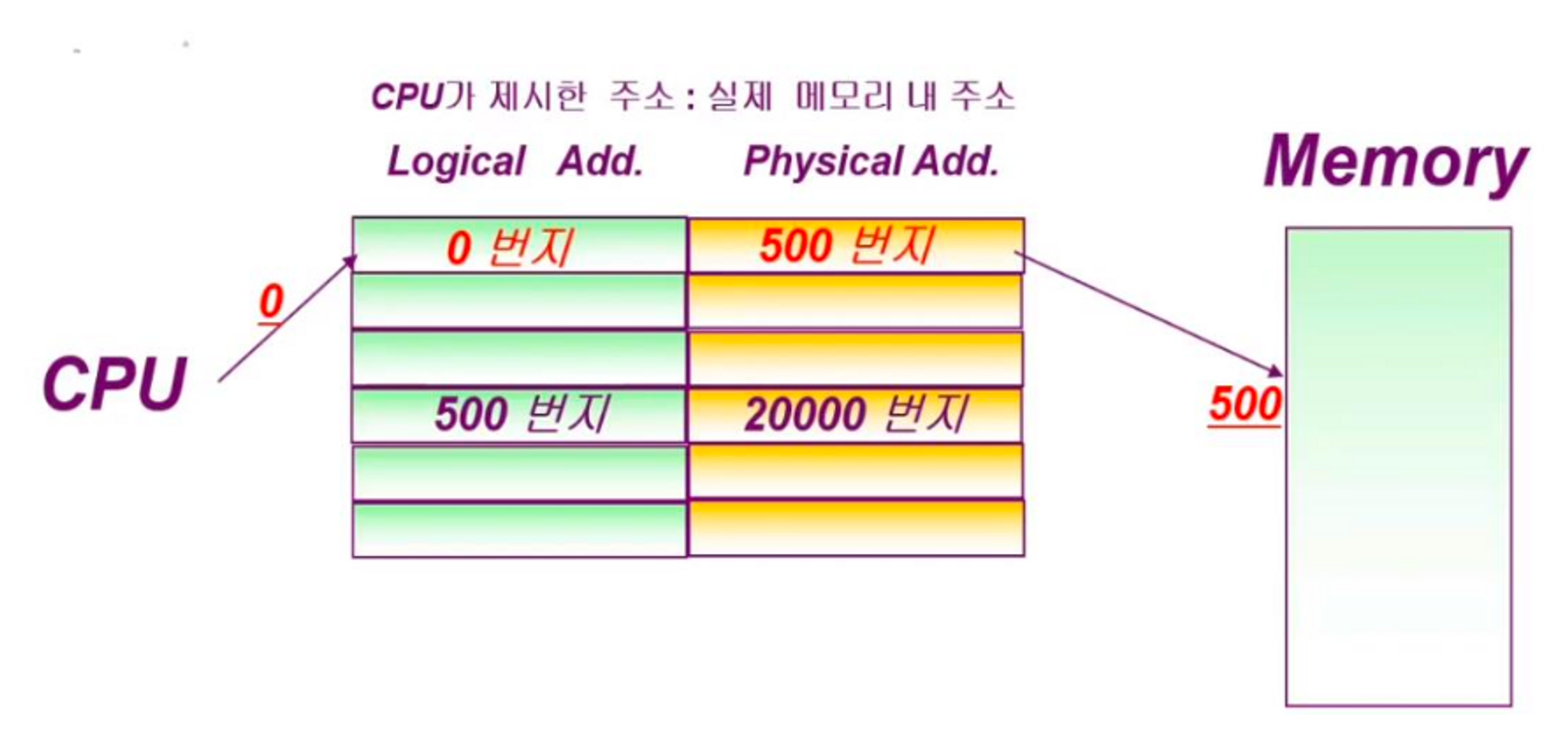
- 우리의 입장에서는 0번지라고 알고 있는게 끝이다.
- 실제로는 500번지에 있다는 것을 전혀 모른다. == 알면 안된다
Memory Management Unit(MMU)
- Address Mapping Table처럼 logical address를 바꿀 수 있는데,
아래와 같이 단순한 숫자를 더해서 바꿔줄 수도 있다.
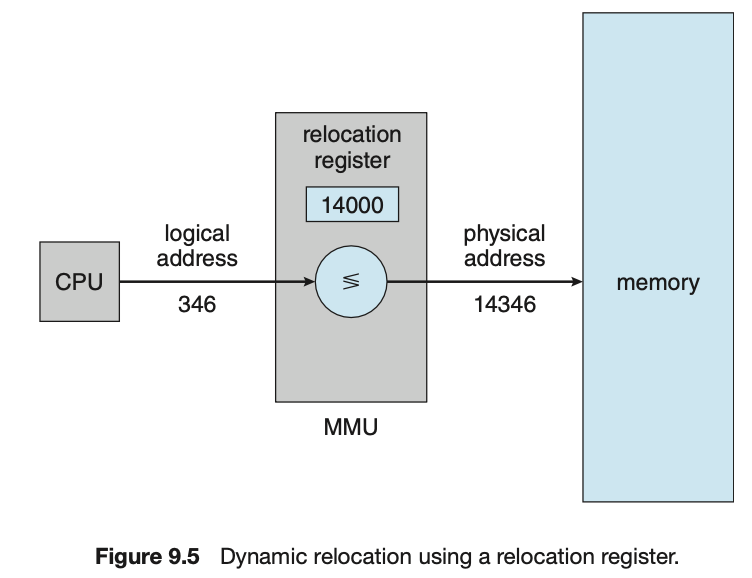
- 346 + 1400 = 14346
- 단순한 숫자를 더하는 것이 빠지고
hash code와 같은 program(algorithm)이 들어갈 수도 있다.
이처럼 실제 HW memory에 저장되는 address가 physical address이고,
CPU와 사용자가 알고 있는 address를 logical address라고 한다.
logical address를 physical address로 바꿔주는 모든 작업을 mapping이라고 하고,
그 mapping하는 과정을 책임지는 OS의 program을 MMU라고 한다.
SW만 갖고 동작할 수도 있고, HW를 사용해서 동작시킬 수도 있고,
1. mapping table, 2. 단순한 숫자 덧셈, 3. hash 등의 방법을 사용할 수도 있다.
Dynamic Loading
-
Rountine : 우리가 만든 program의 일부분.
-
Routine(program의 일부분)이 호출되기 전까지는 loading되지 않는다.
== program을 실행시킬 때, 전부를 main memory로 올리지 않겠다.
이유는?- memory 공간은 항상 원하는만큼 크지 않기 때문에
사용하지 않는 routine을 disk에 두고 있다가 필요한 순간에만 main memory로 옮김으로써
효율적으로 사용할 수 있도록 한다.
➡️ OS가 하는 것이 아니라 User program이 한다(다만 loading할 때는 OS의 도움을 받아야 한다)
나의 응용 program이 여러 rountine을 떼놓고 필요한 것을 부른다
- memory 공간은 항상 원하는만큼 크지 않기 때문에
필요할 때만 loading. OS가 아니라 User가 program을 직접 설계해야 함.
잘 안쓰는 것은 필요할 때만 쓰기 때문에 공간이 효율적이다.
Dynamic Linking & Shared Libraries
-
Static Linking과 다르고, Dynamic Loading과도 다르다
-
Static Linking:
Static Library(object file을 모아 library로 만들어놓은 것)
std lib라고 해서 printf, scanf 등등 수많은 함수들을 모아둔다.
그 중 하나의 함수만을 사용하기 위하여 std lib를 모두 사용하면, memory를 많이 차지하게 된다.
printf만 사용할 것이라면, printf만 떼서 사용하면 된다.
그런데 printf를 사용하는 program이 100개가 있다면 printf를 수행하는 subroutine이 100개가 있어서
전체 memory로 봤을 때, memory에 printf가 많이 있을 수 있다. -
Dynamic Linking:
이러한 비효율을 완화하고자 printf 1개를 정해진 곳에 올려주고,
100개의 program이 그 곳을 공유하여 갖다 쓸 수 있도록 하자.
program마다 출력은 다 달라야 하기 때문에 linking을 다르게 해야 한다.
나중에 printf가 필요할 때, printf가 있을 만한 위치에 stub이라고 하는
가짜 함수를 만들어서 연결하여 사용할 수 있다.
main program 입장에서는 printf가 자신의 program에 붙어있지 않고,
stub이라는 매개체를 통해서 printf를 연결하여 사용할 수 있다.
만약에 실행하려고 했는데,
memory에 해당 library가 없으면(어떤 Program이 처음으로 그 library를 사용하려고 하면)
OS가 그 library를 그때 한 번 loading해준다.
그리고나서 stub에 연결시켜준다.
또 다른 program이 똑같은 library를 사용하려고 할 때,
이미 loading이 되었기 때문에 연결만 시켜준다.➡️ 여러 program에서 반복적으로 사용하는 library의 특정 module을 memory에 올리고, 여러 program이 그곳을 공유하여 갖다 쓸 수 있도록 stub이라는 매개체를 통해서 연결하여 사용한다.
만약 memory에 해당 library가 없으면, OS가 그 library를 그때 한 번 loading해주고나서 stub에 연결시켜준다.
➡️ 따라서 dynamic loading과 달리 OS의 도움이 필요하다.
자주 쓰던 안쓰던 반복될 수 있는 것들은 모아 stub을 이용하여 공유시키자.
(.dll : dynamic link library)
→ 공간 절약(disk, main memory에서 모두 공간을 절약할 수 있어서 현대 OS는 모두 이러한 방식을 사용)
(Dynamic Loading과 달리 OS의 도움이 필요하다.)
Overlays
-
어떤 주어진 시간에 필요한 명령어와 데이터를 특정 memory에 유지하게 하는 것.
User에 의해 Implementation되고, OS는 관여하지 않음. -
example)
- 동시에 실행되지 않는 두 개의 Program이 있다.
- Program1의 영역 : pass 1 / Program2의 영역 : pass 2
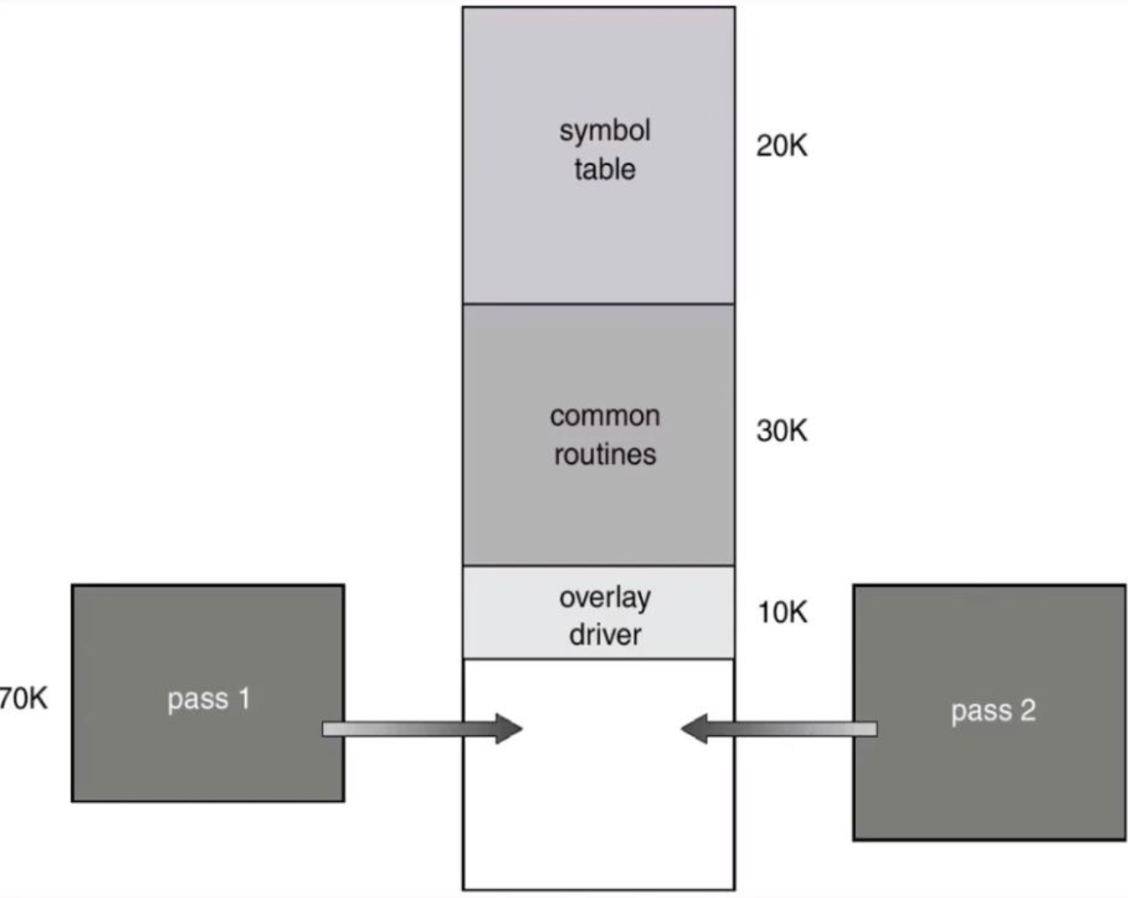
- 두 개 동시에 필요없기 때문에 과감하게 지운다.
- pass 1이 필요하면 pass1을 집어넣고, pass 2가 필요하면 pass 2를 집어넣는다.
- 예를 들어
닌텐도 OS가 기본적으로 실행되는데
게임을 고를 때, 그 곳에 Jump하여 독립적으로 실행시킨다
Contiguous Allocation
-
main memory는 두 부분으로 나뉨
1. OS가 쓰는 것
2. OS에서 할당해준 user process를 위한 것
➡️ user process는 OS의 memory를 침범해서는 안 된다. -
사용자 memory는 사용자 memory끼리 모여있게(Contiguous) 해야 한다.
Base and Limit Registers:
HW를 이용해서 OS가 User process의 영역을 정해주고, 벗어나지 못하게 한다.
memory에게 Base와 Limit을 정해둔다.
해당 process는 그 memory 안에서만 사용해야 함.
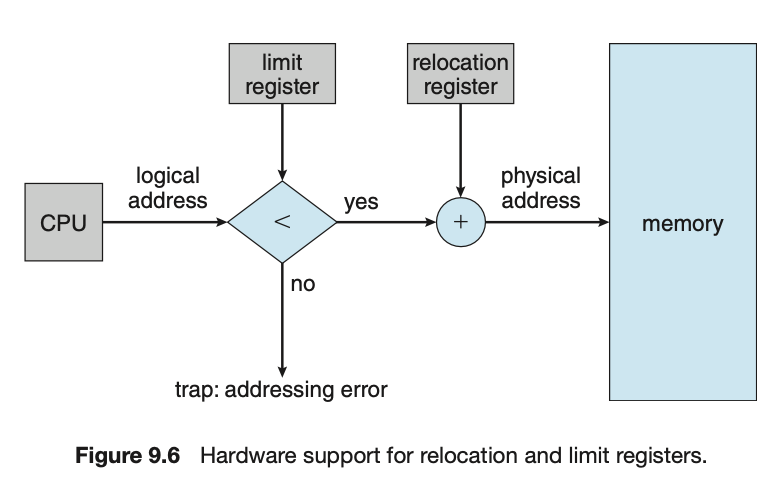
Limit Register:
(base) < logical address < (base+limit)
true? physical address값을 얻는다.
(100번지래. 100번지를 바로 읽는게 아니라 100번지를 읽는 것이 타당한가?를 먼저 수행해야 함.)Relocation Register
Memory Allocation
- 하나의 processs는 앞과 같이 연속이지만, 여러 process가 연속되면 좋지 않다.
➡️ 왜 그럴까?- process가 terminated되면, 굳이 그 memory에 있을 이유가 없다.
- 그 memory를 다른 process가 써야 하는데 쓰지 못하고 다음 memory를 쓰면 끝에 도달하여 system이 돌아갈 수 없다.
즉
process 안에서는 base, limit을 써서 연속적으로 하여 관리가 편하게 하는 것이 맞는데
굳이 limit이 끝난 그 지점에서부터 그 다음 process가 시작되게 할 필요가 없다.
그러면 어떻게 해야 하는가?
➡️ 그 다음 process는 연속적이지 않고 다른 memory에 있을 수 있다.
(하지만 다른 memory에 있기 때문에 또 문제가 생길 수 있다.)
Multiple-partition allocation
- Multiple-partition allocation
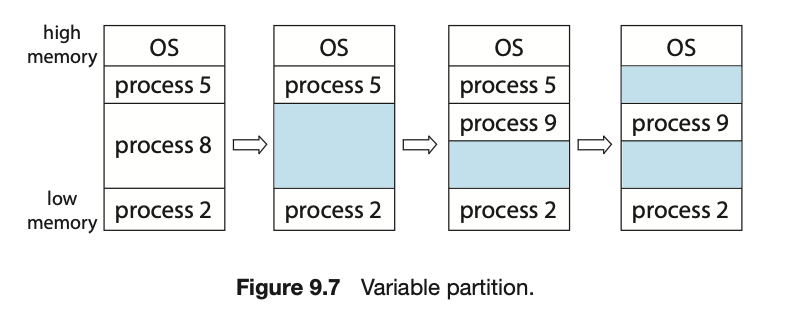
- , , 가 있다.
- 이 끝났다.
- 이 사용했던 memory를
Hole이라고 한다. - memory의 어디서부터 어디까지가 비어있는지? == Hole을 알고 관리해야 한다.
또한 어떤 process를 할당할 때, 그 Hole에 들어갈 수 있는지 검증도 해야 한다.
OS가 이러한 관점에서 Hole을 관리한다.
- 예전에는 아예 process의 크기를 일정하게 고정해놓고, 모든 process는 그 크기를 안넘기도록 했다.
- 고정(옛날 방식) :
작은 program들이 같은 공간을 차지하게 되니까 전체 memory 중에 안쓰는 공간이 많아진다
== 관리는 편하지만 낭비가 심해진다. - 가변(최근 방식) : 복잡해짐.
- 고정(옛날 방식) :
dynamic storage allocation problem
dynamic storage allocation problem(동적 메모리 할당 문제)
: 가용 공간 list로부터 크기 n-bytes block을 요구하는 것을 어떻게 만족시켜 줄 것이냐를
결정하는 문제이다.
이러한 문제에 대한 기본적인 해결책이 제시되어 있다.- First-fit
- Best-fit
- Worst-fit
fit: Hole에 맞춘다
1. First-fit
First-fit:
첫 번째 사용 가능한 공간을 할당한다.
2. Best-fit
Best-fit:
사용가능한 공간 중에서 가장 근접한 것을 택한다.
3. Worst-fit
Worst-fit:
가장 큰 가용공간을 택한다.
이 방식에서 할당해주고 남게 되는 가용공간은 충분히 커서 다른 프로세스들을 위하여 유용하게 사용될 수 있다.Best-fit이 가장 좋아보이지만, Best-fit은 계속해서 비교해야 하기 때문에 복잡하다.
일반적인 경우에는 First-fit > Best-fit > Worst-fit 순으로 좋지만
항상 그런 것은 아니다.
또한 남아 있는 Hole은 가능한 크게 유지하는게 좋다.
그런 면에서 Worst-fit은 좋지 않다.
- 전체 Hole : 2160K가 있었다.
그 상태에서 P1 ~ P5 process가 생겼다.
(time : duration time)
(P1부터 순서대로 들어왔다고 가정)
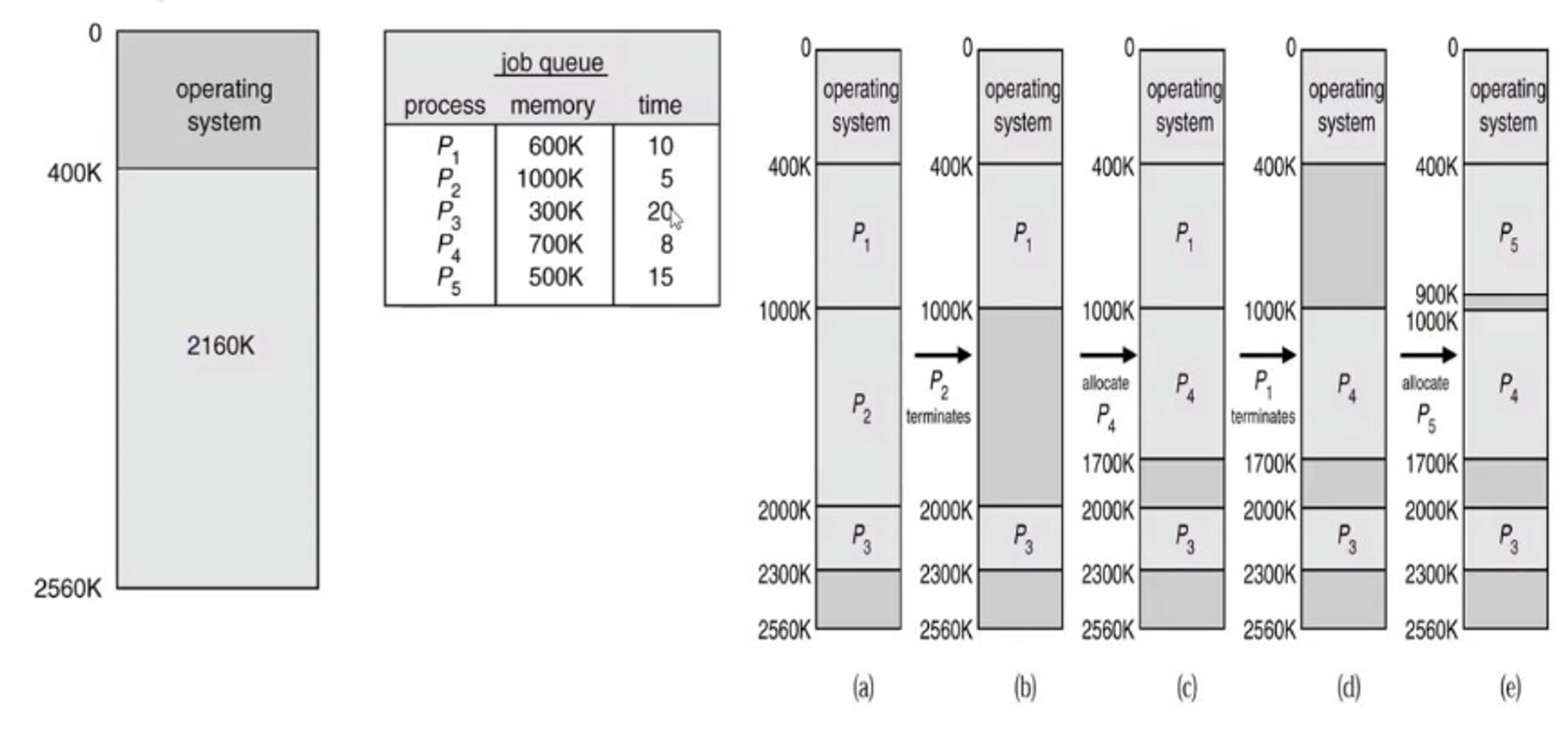
- (a) : 는 700K memory가 필요한데, 남아있는 memory space가 260K여서 대기.
- (b) : 5초 뒤에 가 끝남.
가 쓰던 1000K는 Hole로 바뀜. ( : 5 time 남음, : 15 time 남음) - (c) : 가 실행됨.
- (d) : 5초가 지나 이 끝남.
가 쓰던 600K는 Hole로 바뀜. ( : 10 time 남음, : 3 time 남음) - (e) : 이 실행됨.
만약 (c)에서 100K, 100K, 200K, 160K 4개의 Process가 왔다고 가정한다면?

Best-Fit이 Best, Worst-Fit이 Worst가 아닐 수가 있다.
어떻게 응용하느냐, data에 따라 결과가 달라질 수 있다.
Fragmentation
-
External Fragmentation:
process들이 memory에 load되고 제거되는 일이 반복되다 보면,
어떤 가용 공간은 너무 작은 조각이 되어 버린다.
예를 들어, 100K process가 있고, 20K, 30K, 50K Hole이 떨어져 있다.
전체 가용 공간은 100K가 있지만, 100K Process는 Continuous해야 하기 때문에
세 block으로 나누어 할당할 수 없다. -
Internal Fragmentation:
어떤 block을 만드는 그 자체 때문에 필연적으로 생길 수 밖에 없는 공간.
예를 들어, 10K짜리 block에 8K process를 할당하면
10K짜리 block 내부의 2K짜리의 공간은 사용하지 못하는 공간이 된다.
이처럼 모든 process가 그 block에 대해서 정확히 딱 맞는 것이 아니기 때문에
어쩔 수 없이 내부에 필연적으로 사용하지 못하는 공간이 생기게 된다.
-
HDD를 쓰다보면 처음에는 잘 돌아간다.
2, 3년 뒤에는 느려진다.
file이 여기저기 흩어지게 되어 처음에 1초 걸렸다면 2, 3초가 걸릴 수도 있다.
➡️ 그래서 defragmentation을 한다. 흩어져 있던 단편들을 모아준다. -
External Fragmentation을 살펴보자.
앞서External Fragmentation의 문제점은 다음과 같았다.
100K process가 있고, 20K, 30K, 50K Hole이 떨어져 있다.
전체 가용 공간은 100K가 있지만, 100K Process는 Continuous해야 하기 때문에
세 block으로 나누어 할당할 수 없다.
➡️ 떨어져 있는 Free memory들을 하나의 Hole로Compaction(압축=한곳에 몰기)해보자.
Compaction
- 다시 한 번 정리하자면,
External Fragmentation의 문제점을 해결하고자Compaction을 고려할 수 있다.
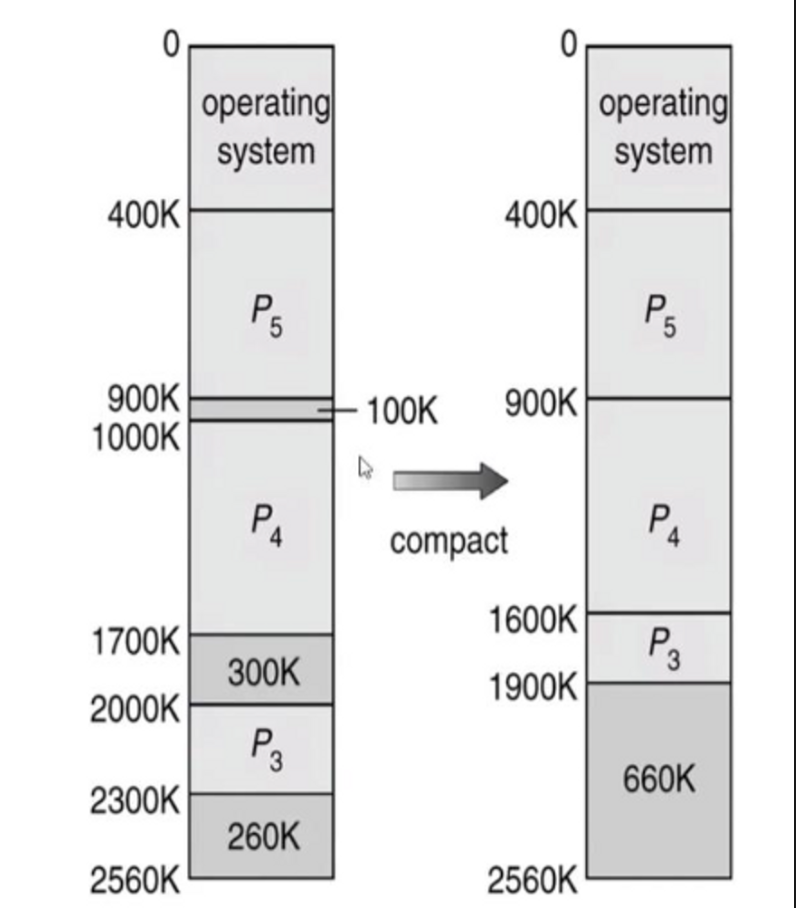
- 총 660K의 Hole이 3개로 나눠져 있다. 100K, 300K, 260K
- compaction하기 전에는 400K짜리 Process가 들어왔을 때, 할당할 수 없지만
compaction하고 난 후에 400K짜리 Process를 할당할 수 있게 된다.
Compaction을 위한 memory 이동 정책
- Compaction을 하기 위해 memory 이동 정책이 필요하다.
어떻게 옮기느냐에 따라 효율적인 방법이 있을 수 있다.
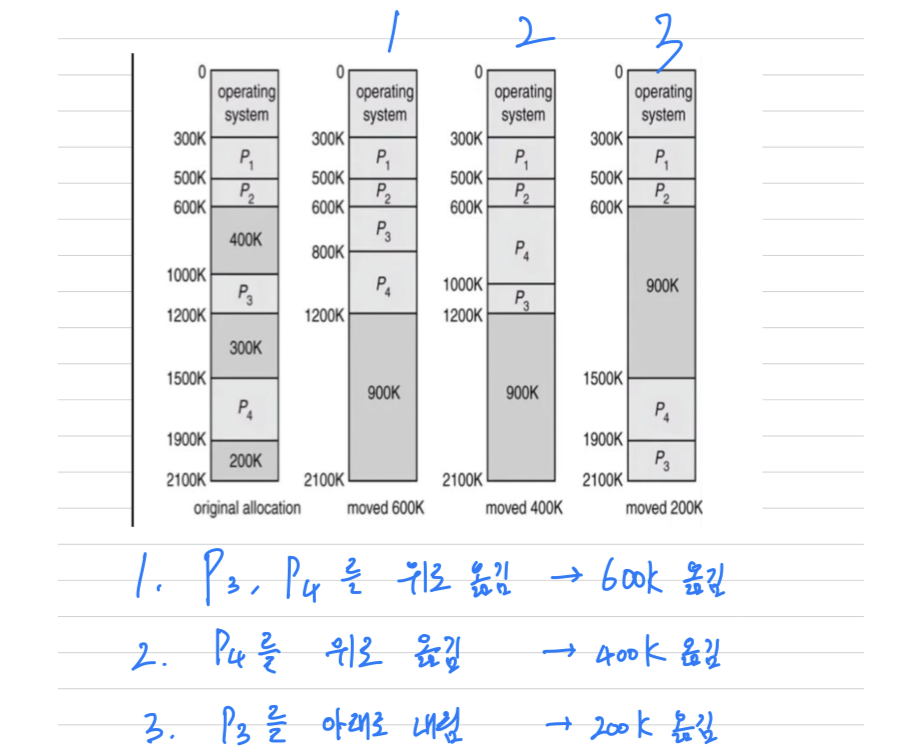
- 600K를 읽고, 쓰고 ,… → I/O가 한다. → 비효율적, 매우 느려짐
위 1, 2, 3 방법도 OS 입장에서 data를 옮기는 비효율이 생긴다.
그 원인은 Process를 Contiguous하게 한 것.
따라서 Process를 Contiguous하게 하지 말자
➡️Paging
Paging
-
지금까지 논의된 memory management는
process의 physical address space가 contiguous해야 했다.
그로 인해서 compaction 기법을 사용하였고,
그것도 I/O를 이용하여 Data를 읽고, 쓰는 비효율적인 방법이 될 수 있었다. -
즉
process들이 contiguous하게 있어야 하는 것이 문제였기 때문에 contiguous하지 않게 해보자.
➡️ CPU 입장, user 입장에서 실제로는 연속적으로 있는 것처럼 해보자. -
Paging:- Physical address can be noncontiguous : 물리적 주소는 연속적이지 않을 수도 있다.
- physical memory : 실제 RAM에 있는 byte
- Logical memory : CPU가 계산하는 memory
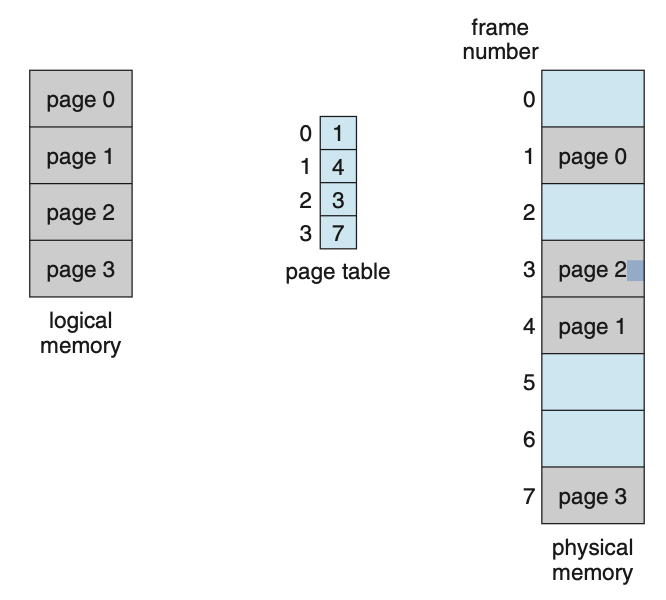
logical memory 입장(CPU 입장): 1, 2, 3, 4가 연속으로 있다.physical memory: page table로 page 0이 physical memory의 어디에 있는지 정보를 저장.이게 왜 좋을까? compaction을 할 필요가 없어짐.
paging을 쓰면, external fragmentation은 절대 생기지 않는다.
Address Translation Architecture
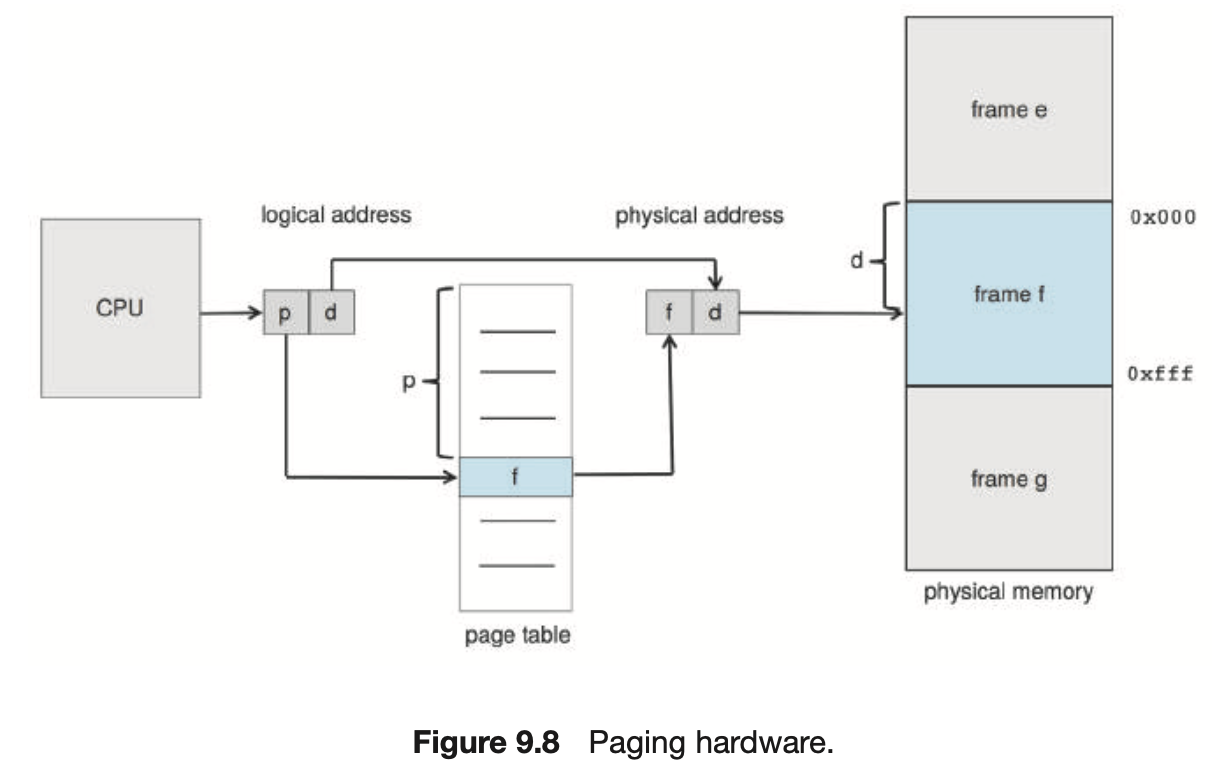
-
CPU : 내가 1000번지 읽겠다. → 1000번지 가서 data를 읽어오는 것이 아니다.
1000번지 : Logical Address
1000이 p, d로 이루어져 있다.
p: page 번호,d: offset (기준부터 얼만큼 떨어져 있는가) -
(p, d)로 이루어져 있는 Logical address를
(f, d)로 이루어져있는 Physical Address로 바꾸겠다.
➡️ 똑같은 크기의 p(page)를 page table을 통해 똑같은 크기의 f(frame)으로 바꾼다.
Address Translation Scheme
- (p, d)의 bit수를 이라고 하자.
- 한 페이지 안에 몇 개가 있느냐?
- 페이지가 몇 개 있느냐?
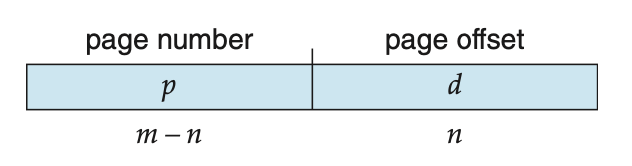
- 이라고 가정하자.
- 한 page 안에 data를 4개 넣겠다. ➡️ , 가 된다.
- 니까 이된다. ➡️ 4개 짜리 크기를 갖는 page가 개가 있다.
example 1
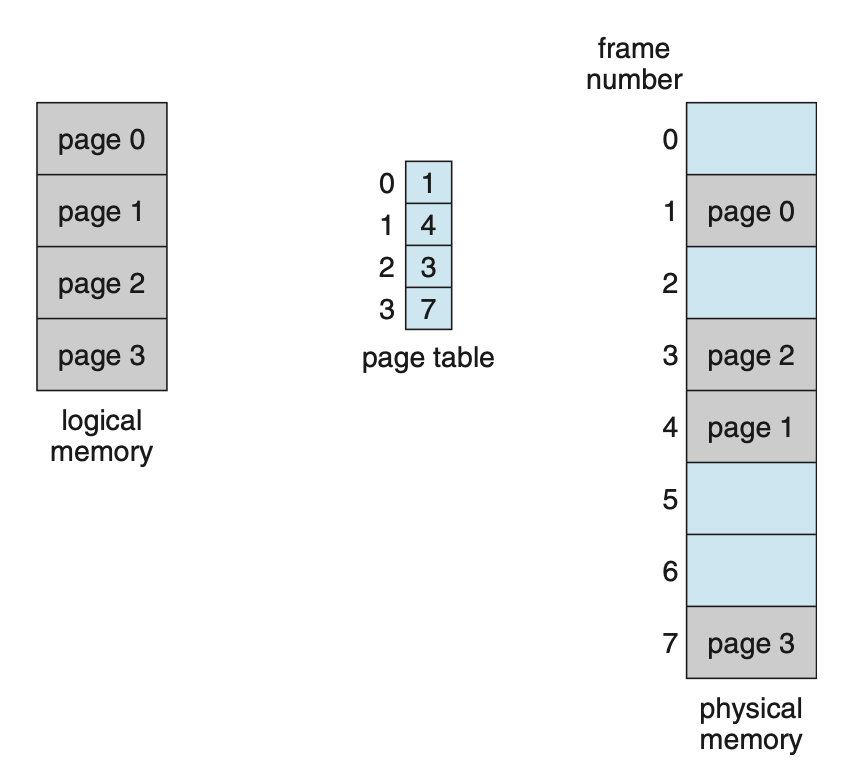
- 위 example 1에서 page는 4개이다.
- 이를 통해 알 수 있는 것은
example 2
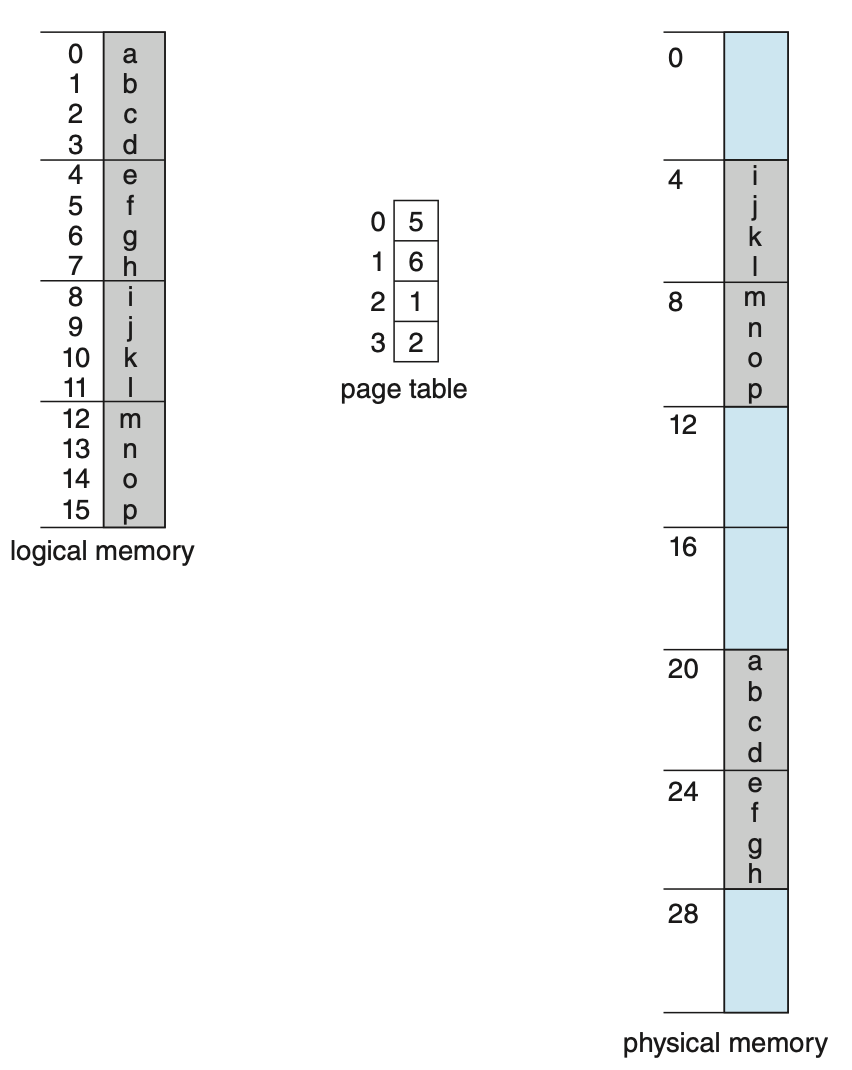
- page 개수 4개. ➡️ . ➡️ bit 2개만 있으면 된다.
한 page의 크기도 4개. ➡️ . ➡️ 이것도 bit 2개만 있으면 된다.
따라서 라는 것을 알 수 있다.
- page table이 지워지면?
logical memory를 physical memory에 mapping할 수 없기 때문에 data가 없어진다.
- page 개수 4개. ➡️ . ➡️ bit 2개만 있으면 된다.
일반적으로 logical memory가 physical memory보다 훨씬 크다.
: 그래서 physical memory를 마치 있는 것처럼 생각하는게 Virtual Memory이다. (추후에 공부..)
Calculation Internal Fragmentation
-
External Fragmentation을 해결할 필요가 없다.
page table을 이용해서 값만 써주면 된다. -
Internal Fragmentation을 계산해보자.
Page size = 2,048 bytes
Process size = 72,766 bytes
라고 가정해보자.- 72,7666 (bytes) = 35 pages + 1,086 bytes 이기 때문에
- 총 36 pages(73,728 bytes)를 써야 한다.
- 73,728 bytes - 72,666 bytes = 962 bytes
➡️ 어쩔 수 없이 962 bytes의 Internal Fragmentation이 생김
- Worst Case는 다음과 같다.
Process size = 라 했을 때,
% 인 경우
➡️ 2048 - 1 = 2047 bytes의 Internal Fragmentation이 생김.
- Best Case는 다음과 같다.
Process size = 라 했을 때,
% 인 경우
➡️ 2048 - 2048 = 0 bytes의 Internal Fragmentation이 생김.
➡️ Fragmentation이 생기지 않고 크기가 딱 맞음.
- Average Case는 다음과 같다.
Average Fragmentation = (1 / 2) * (frame size)
➡️ 1,024 bytes
Internal Fragmentation을 줄이기 위해서 Page의 크기가 줄어야 한다.
그럼 Page의 크기를 작게 하면 Internal Fragmentation을 해결할 수 있는 것 아닌가?
➡️ Internal Fragmentation을 해결할 수는 있지만, 무작정 Page를 작게할 수는 없다.
왜?
page 크기가 작아지면 Internal fragmentation이 줄어들지만, page table이 늘어난다.
page table도 결국 memory에 있기 때문에 무작정 page 크기를 작게 만들 수 없다.
따라서 page 크기를 무작정 크게 하는 것도 좋지 않고, 작게 하는 것도 좋지 않다.
Free Frames
-
Free Frames: 가용 frame. 할당되지 않은 frame.
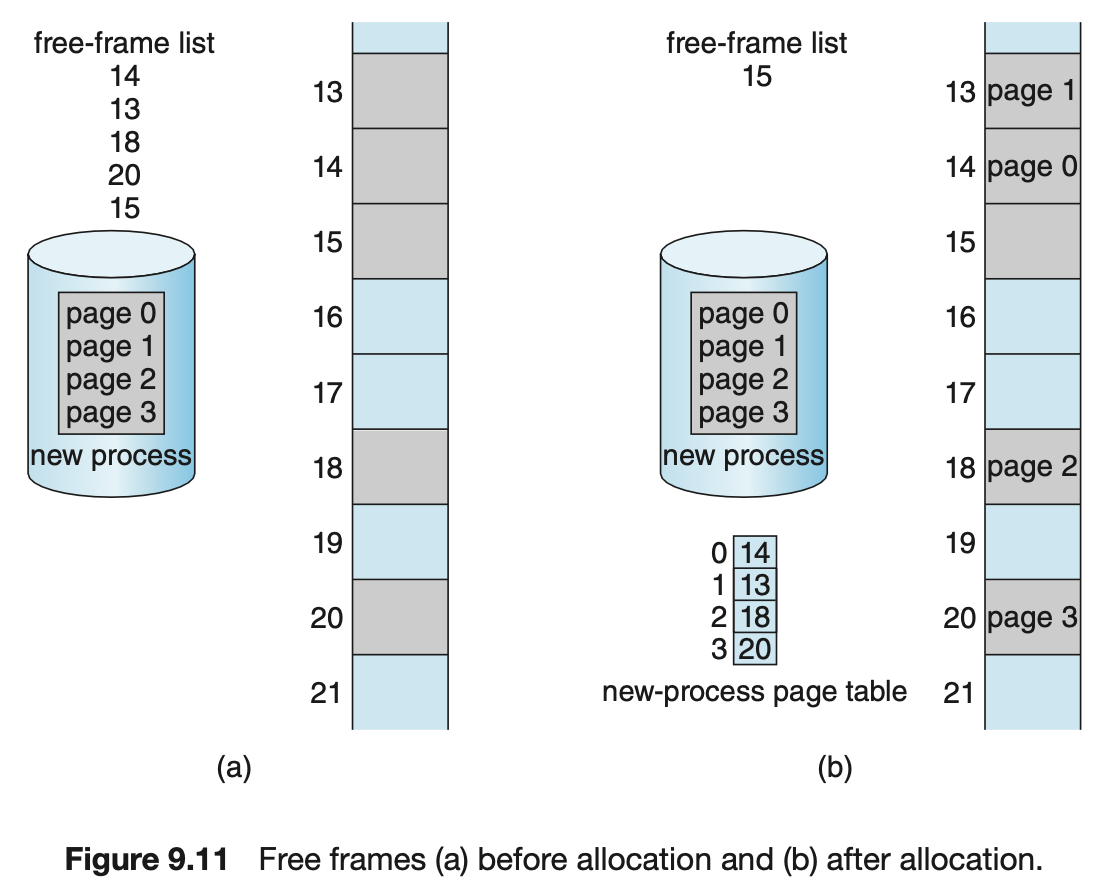
-
OS는 Physical Memory를 관리하기 때문에
Physical memory의 자세한 할당 상황에 대해 파악하고 있어야 한다.
즉, 어느 frame이 사용 가능한지, 총 frame은 몇 개나 되는지 등을 알아야 한다.
따라서 OS는 그러한 정보들을 위해Free-Frame List라는 목록으로 보관하고 있어야 한다. -
OS는 각 Process마다 Table을 따로 따로 갖고 있다.
-
Hardware Support
- logical memory와 physical memory를
mapping해주기 위해 page table을 사용하는데,
2개의 HW 도움을 받는다.PTBF(Page-Table Base Register)
: page table이 주기억장치에 저장된 위치PTLR(Page-Table Length Register)
: page table의 크기
- main memory에서 data를 읽기 위해서 중간에 table을 한 번 거쳐야 한다.
100번지면, 100번지 바로 읽지 않고
page table을 읽고나서 table에서 주소를 가져오면, 실제 주소를 읽어야 한다.
2번 읽어야 한다.
➡️ 2배 느려질 것이다- 그래서 속도를 빠르게 하기 위해서
cahce를 사용하자는 아이디어가 제시됨
- 그래서 속도를 빠르게 하기 위해서
TLB(Translation Look-aside Buffer)
-
TLB(Translation Look-aside Buffer)
: main memory에서 data를 읽기 위해
(1) page table에서 주소를 읽고
(2) 그 실제 주소에서 가서 data를 읽어야 하기 때문에
시간이 오래 걸리는 것을 방지하고자,
TLB라고 하는 cache를 이용해보자. -
page table을 읽기 전에 읽은만한 예상된 것들을 모아둔 것을 cache에 넣어보자.
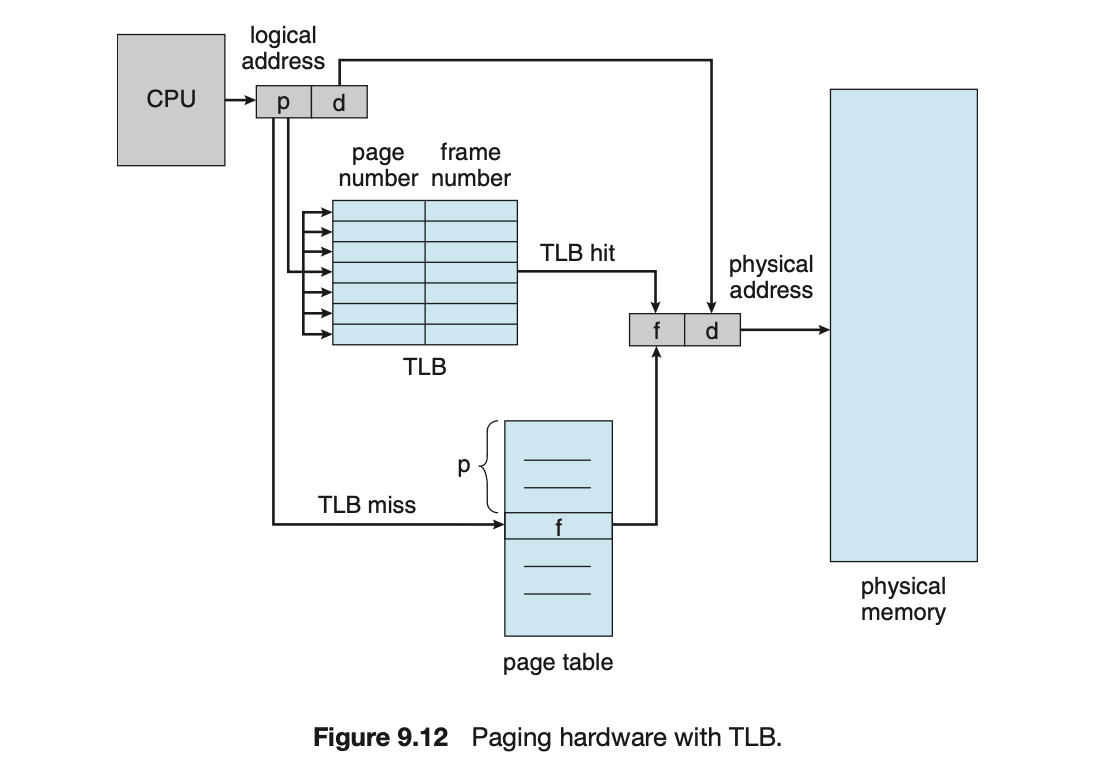
- table을 읽기 전에 TLB를 먼저 참조해보자.
➡️ TLB cache에 page number가 있는 경우, 바로 frame으로 mapping한다.
➡️ TLB cache에 page number가 없는 경우, page table로 가서 한 번 더 읽고 mapping한다.
- page table에는 page number가 모두 있지만,
TLB cache에는 곧 사용될 것으로 예측되는 일부분의 page number들만 존재한다.
- cache memory를 무한정 쓸 수는 없다.
- table을 읽기 전에 TLB를 먼저 참조해보자.
Effective Access Time
hit: cache에 있다.
miss: cache에 없다.
- : cahce에 있을 확률 == hit ratio
: cache에서 data를 읽어오는 시간
: memory에서 data를 읽어오는 시간
-
EAT(Effective Access Time)
: , , 정보가 있으면,
CPU에서 data를 읽을 때 걸리는 시간을 계산할 수 있다.- 다음은 EAT 수식은 수학적 수식이 아니라, 논리적인 수식이다.
- 다음은 EAT 수식은 수학적 수식이 아니라, 논리적인 수식이다.
-
Example : Cache에서 data를 찾은 경우 == 최상의 경우
-
Example : Cache에서 data를 못 찾은 경우
-
Example
The percentage of times that the page number of interest is found in the TLB is called the hit ratio. An 80-percent hit ratio, for example, means that we find the desired page number in the TLB 80 percent of the time. If it takes 10 nanoseconds to access memory, then a mapped-memory access takes 10 nanoseconds when the page number is in the TLB.
➡️ 해석해봤을 때,
hit ratio = 80%, main memory 접근 시간 10ns, cache 접근 시간 00ns가 소요된다고 가정했을 때, EAT?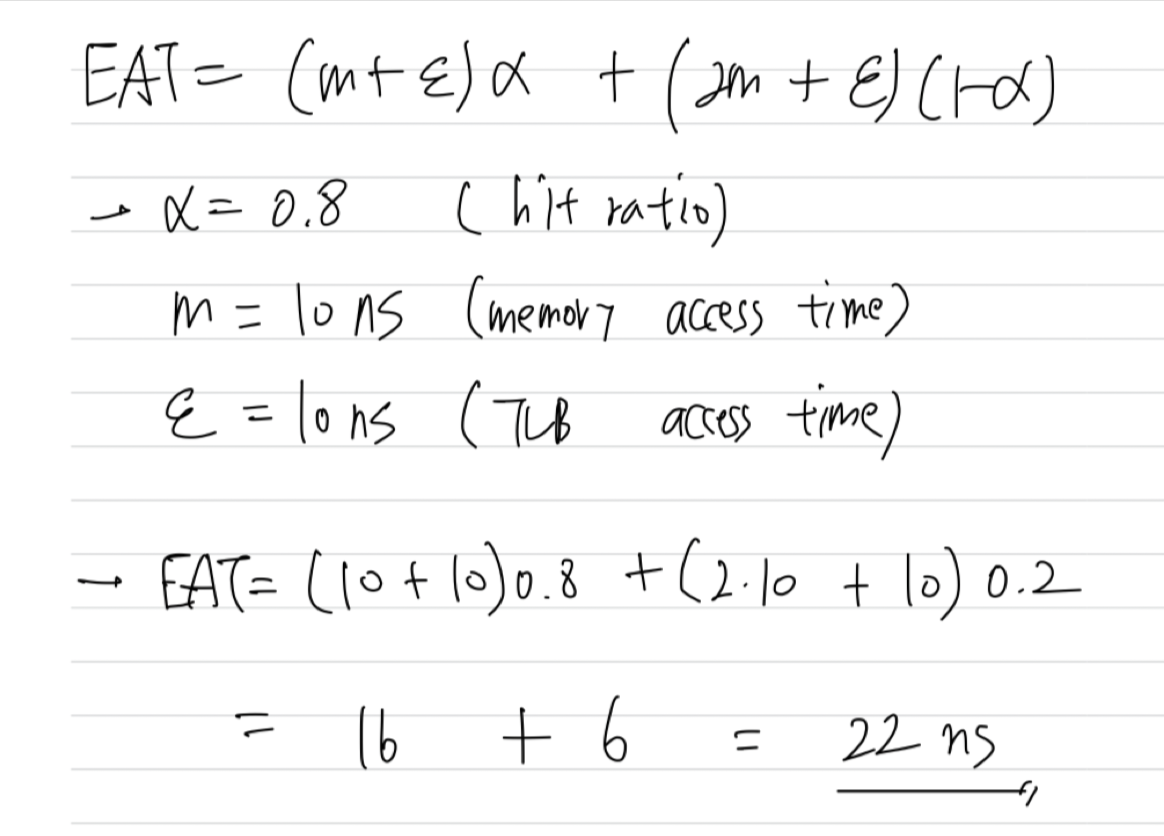
Protection
- page table이 잘못된다면, 실제 읽는 memory값도 잘못된다.
그래서 protection bit를 사용해서 최소한의 memory protection을 해보자.
➡️ 어떻게? Page Table에 bit를 추가해주자.
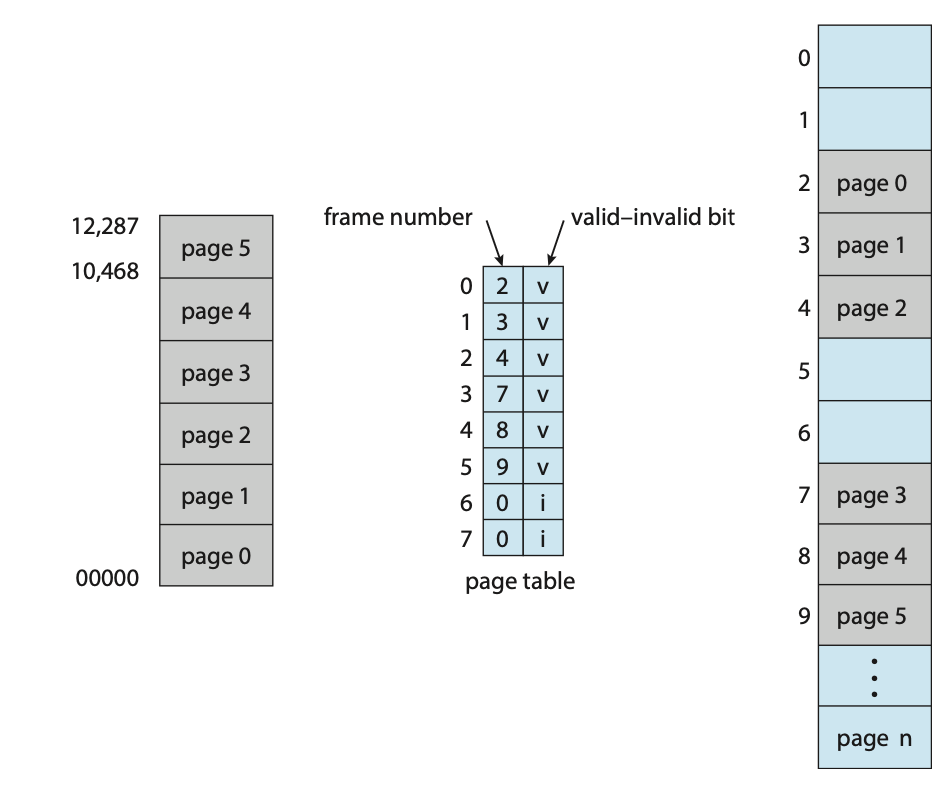
v: valid bit (제대로 쓴거 맞다)
i: invalid bit (쓰레기 값이다)
Page Table Structure
- memory가 커지면, 복잡해진다.
- 32-bit computer를 쓴다고 가정하면, memory는 4GB()까지 addressing이 가능하다.
64-bit computer는 RAM을 까지 사용가능. 거의 무한대로 사용 가능하다.
하지만 memory가 커진다는 의미는 page table도 커진다는 의미이다.
이 큰 memory를 handling하는 Table을 만드는 것은 쉽지 않고, 용량이 매우 커지고, 찾아가기도 쉽지 않다.
- 따라서 Page Table을 Handling하기 위해
Page Table Structure가 있다.- Hierarchical Paging
- Hashed Page Table
- Inverted Page Table
- Oracle SPARC Solaris
Hierarchical Paging
-
Hierarchical Paging: Page Table의 Level을 나누자. -
2 Level Example
32bit computer에서 2 Level로 한다고 가정
offset 크기가 라고 가정 == 한 page 크기가 12bit
➡️ 정확히 10, 10, 12 bit가 나온다.
왜 그럴까?
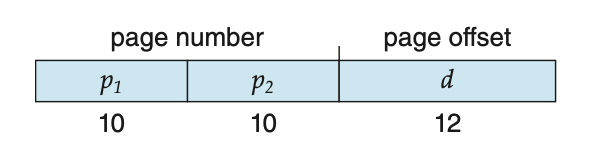
- 32-bit computer라는 말은
memory bus, 명령어 크기가, data를 읽어들일 때 최대 4B라는 뜻.
== data를 기본적으로 4B로 표현한다. - memory에 bit의 크기가 있는데,
한 번에 32-bit(4B)를 읽으니까 bit가 있는 것이라고 볼 수 있다. - 그래서 , 에 bit가 필요한 것이다.
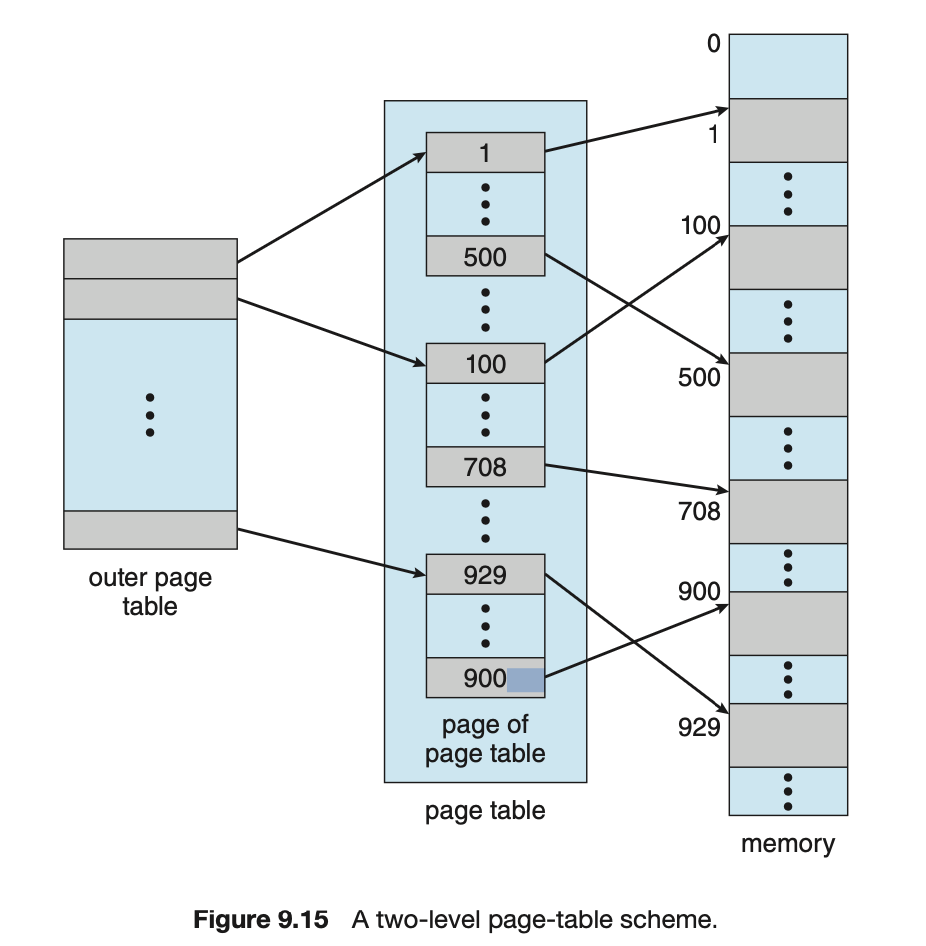
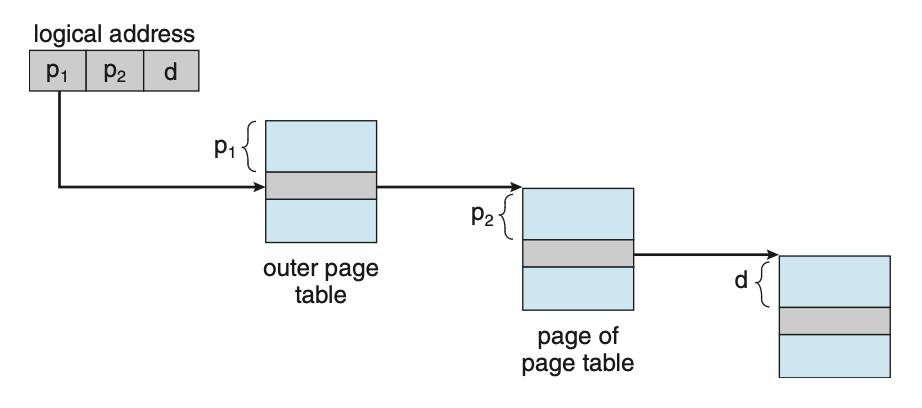
- 32-bit computer라는 말은
- 만약 위의 예시에서 Page Table을
3 또는 4 Level로 한다면?
1. Multilevel Paging and Performance
- 캐시 적중률이 98%라고 가정
4 Level Hierarchical이라고 가정,
cache access time 20ns, memory access time 100ns라고 가정- 만약 cache에 있을 때는, cache 1번 읽고 바로 memory 읽으면 된다
20 + 100 = 120ns - 만약 cache에 없을 때는, cache 1번 읽고, table 4번 읽고, memory 읽어야 된다.
20 + 5x100 = 520ns
- 만약 cache에 있을 때는, cache 1번 읽고 바로 memory 읽으면 된다
→ hit ratio가 올라가면, 빨라진다.
HW문제가 아니라, program을 만들 때 HW를 잘 이해하고 만드는 것이 중요하다.
2. Hashed Page Table
- Hash Function이 필요함.
- 일대다 관계 (hash 결과 하나가 나올 때, 그 한곳에 여러가지 나올 수 있다 == collision)
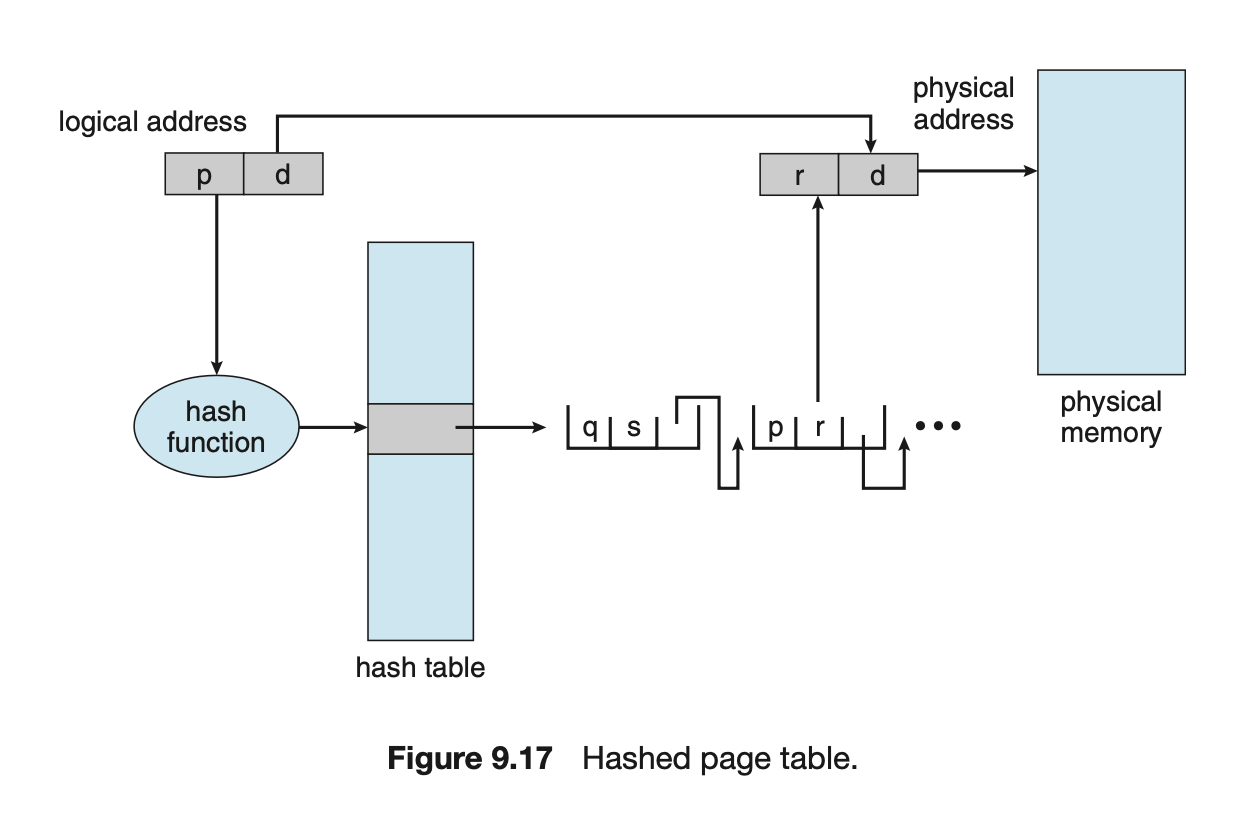
- 를 로 바꾸는 과정을
page table을 두는게 아니라 hash function을 통해 hash table을 사용하여 바꾸겠다. - 만약 collision이 발생한다면, list를 만들고 순차적으로 찾는다.
- 장점 : 관리가 단순해진다, sequence search 하지 않고 random search를 통해 system 효율이 보다 높아진다.
- 를 로 바꾸는 과정을
Segmentation
- assembly할 때,
- Segment : memory 덩어리.
- 그 segment와 offset을 이용해서 찾아갔다.
- segmentation이 따로따로 떨어져있을 거라고 생각되지만, 붙어져 있다
User’s View of a Program
- Logical Address Space : subroutine, stack, symbol table, main program, ...
이 segment부터 offset만큼은 subroutine이야.
이 segment는 여기부터 offset만큼이 stack 이야.
…
➡️ 이렇게 하면 구분하기 어렵지 않을 것이다.
➡️ Segmentation HW
Segmentation HW
-
offset(d)은 base ~ base+limit 안에 있어야 한다.
== d가 limit보다 작으면? physical memory로 mapping : trap; addressing error
➡️ physical memory = base + d
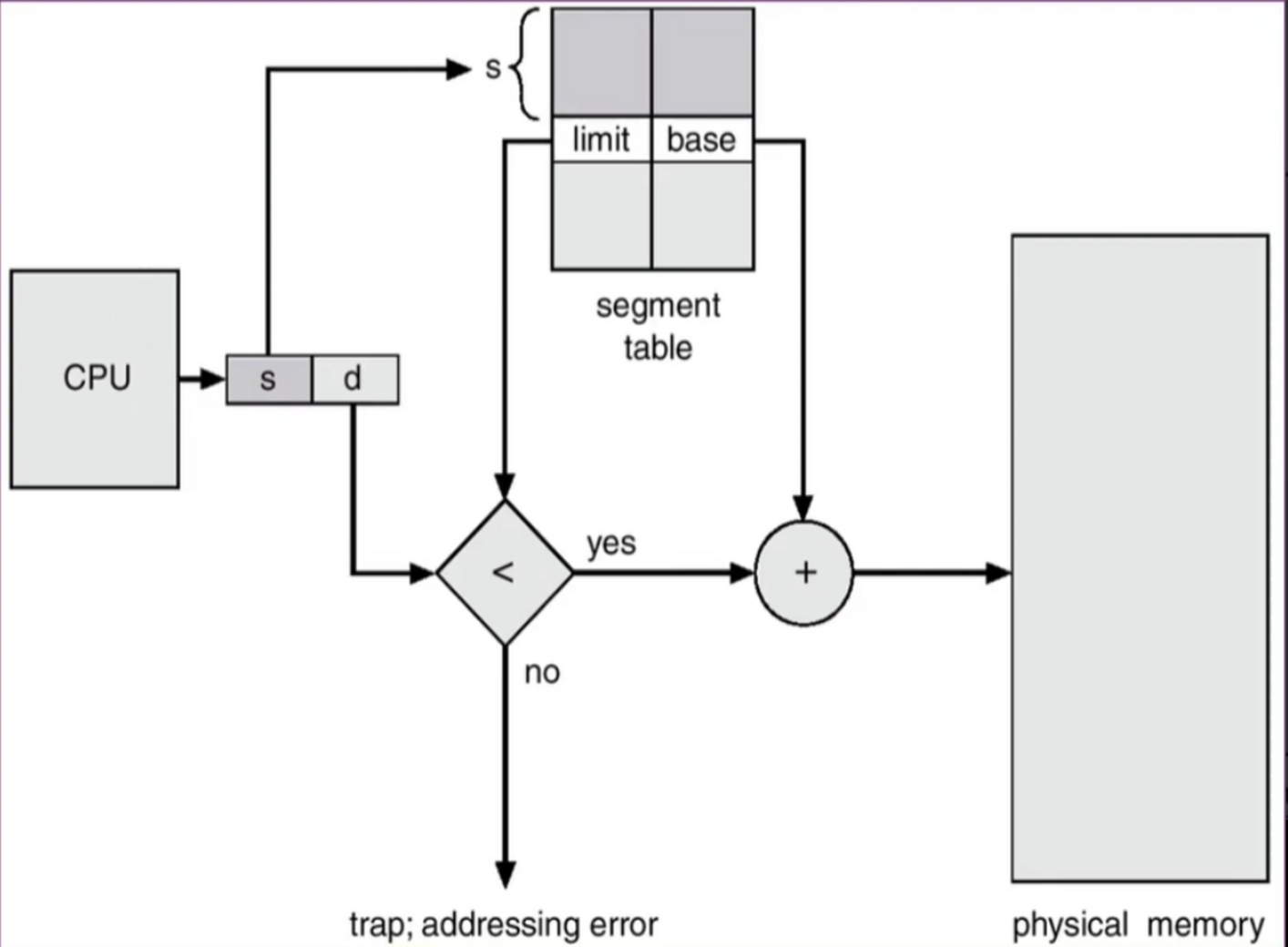
-
따라서 segment table만 잘 관리하면,
여러 개의 segmentation을 관리할 수 있다.
➡️ 현대의 큰 computer에서는 memory가 너무 커지니까 이렇게 하지 않고 page와 같은 기법 사용. embedded system에서 이러한 방법을 사용한다. -
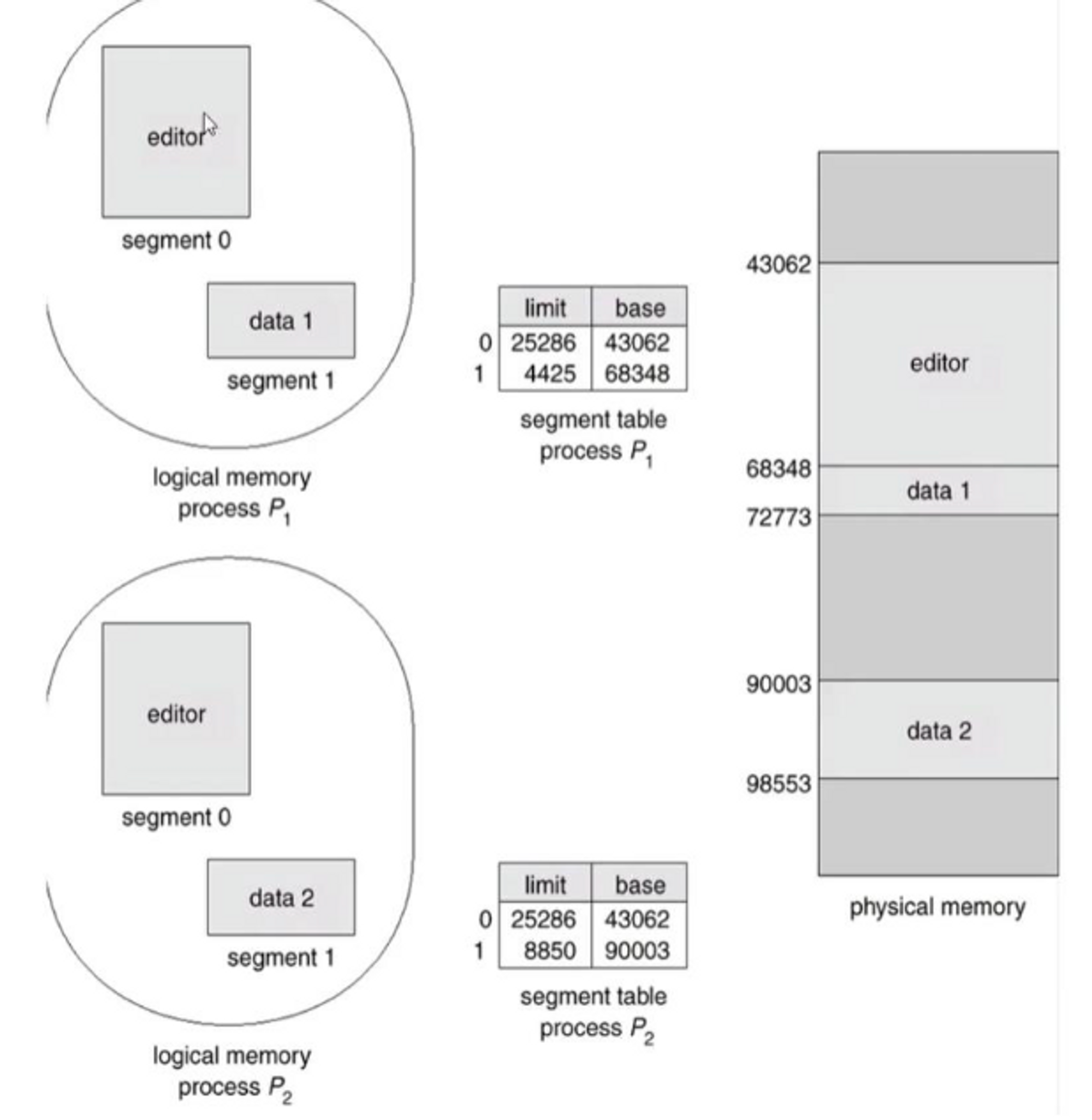
장점 1
: 작은 memory나 embedded system에서 서로 memory를 침범하지 않도록 하는 장점이 있다.
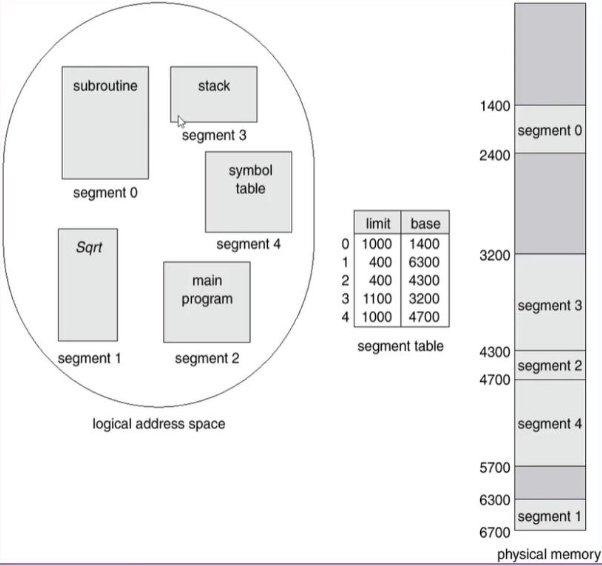
-
장점 2
: memory를 공유하여 physical memory 사용의 효율을 높일 수 있다.
예를 들어, editor(메모장)가 있고,
program 자체의 code와 그 process가 쓰는 data로 이루어져 있는데,
editor를 두 개를 띄웠을 때,
editor program code는 공유하고, 각각의 process가 갖고 있는 data만 다르게 하면 된다.
→ Code segment는 공유, data segment는 분리한 경우