Network layer
- network layer에서 하는 일은
Routing이다.
switch는 network device 중 routing 기능이 없다.edge router:
host들에게 직접 연결되어 있는 router.core router:
중간에 연결되어 있는 router.
Two key network-layer functions
-
forwarding:
move packets from router's input to appropriate router output. -
routing:
determine route taken by packets from source to destination.
Router에는 각각의 routing table이 있는데, overhead가 크다.
그래서 SDN(Software Defined Networking)을 사용하여 Server에서 다 결정 해서 정해진 경로로만 forwarding함
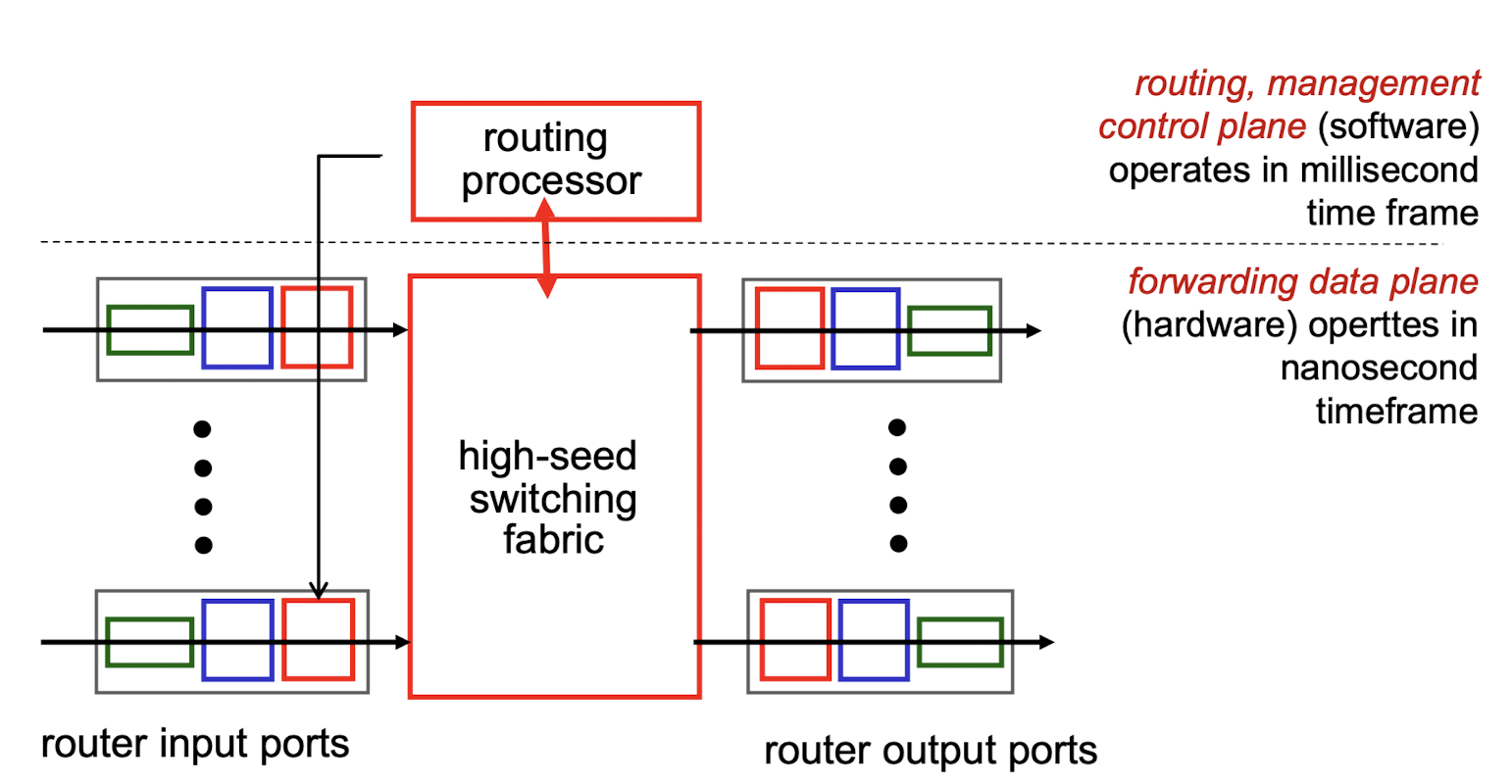
Router architecture : Data plane, Control plane
-
Data plane:- 각 router 마다의 forwarding function이다.
- router의 input port로 들어온 datagram을 어느 output port로 forwarding 해야 할지 결정한다.
-
Control plane:- network-wise logic으로,
datagram이 router들 사이에서 어떻게 routing되어야 할지를 결정한다. - Two control-plane approaches
1. traditional routing algorithm :
router들끼리 interactive하게 routing table을 만드는 방식이다.
overhead가 커서 최근에는 사용하지 않는다.
2. SDN(Software-defined networking) :
remote server에서 미리 만들어놓은 routing table을 갖고 routing한다.
- network-wise logic으로,
Desination-based forwarding
Longest prefix matching
- forwarding table을 찾아볼 때,
destination address와 longest address prefix인 Link interface로 forwarding한다.

- 예를 들어, 위와 같은 forwarding table이 있고,
다음의 Destination Address가 있다.

DA와 Destination Address Range와 AND 연산을 하여 가장 길게 일치하는 link interface로 간다.
첫번째 DA는 Link interface 0으로 간다.
두번째 DA는 Link interface 1로 간다.
➡️ 어떤 link interface로 보낼 것인지 빨리 찾기 위해 사용된다.
- 예를 들어, 위와 같은 forwarding table이 있고,
- 내부적으로 TCAM(Tenary Content Addressable Memories)으로 구현되어 있다.
➡️ bit 연산이 HW적으로 구현되어 있어서 1M routing table entry까지도 처리할 수 있다.
Three types of switching fabrics
- Longest prefix matching을 통해 어느 link interface로 보낼지 정해졌다.
이제 output으로 보내줘야 하는데, 어떤 식으로 보내줄 것인가?
시대순으로 다음과 같다.memorybuscrossbar
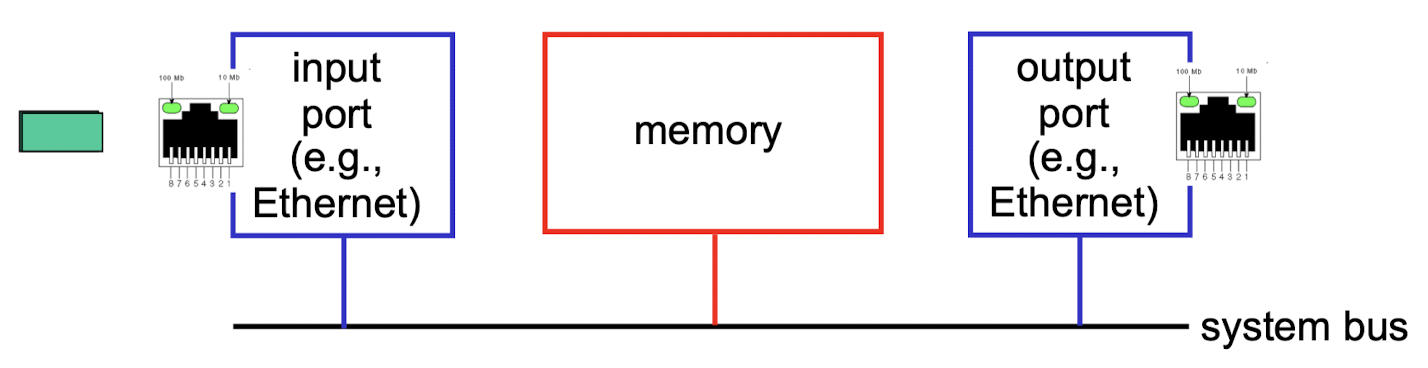
1. memory
memory:
들어온 address와 routing table의 longest prefix만큼 matching되는 link interface로 보낸ㄷ.
memory copy라 이루어진다.
2. bus
bus:
bus를 모두 공유하고 있는데,
그 안에 switch가 있다.
만약 a가 bus를 사용하려면 switch에 연결되어 bus를 사용한다.
단점으로는 a가 bus를 점유하고 있는 동안 b, c는 bus를 쓸 수 없다(bus contention)
그럼에도 불구하고, memory 방식보다 훨씬 빨라서 초창기에 나온 저가형 router에서 많이 사용되었다. (32 Gbps)
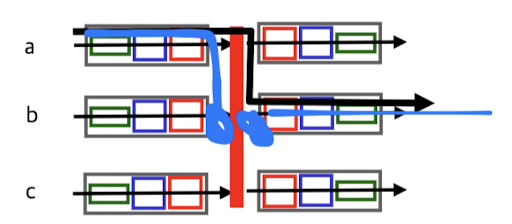
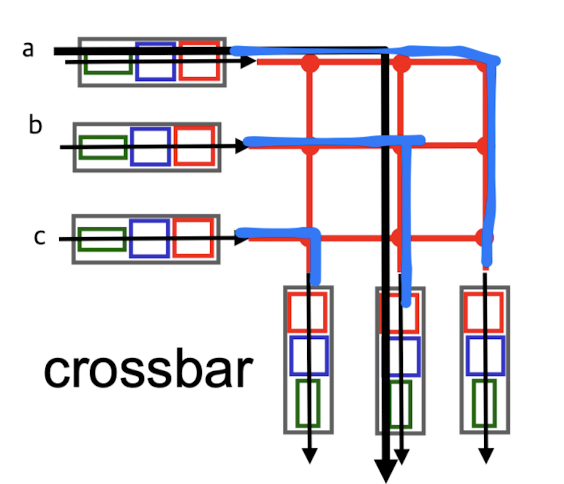
3. crossbar
crossbar:
bus 방식을 해결하기 위해 개선되었다.
bus 방식은 input과 output이 switch를 점유하고 있는 동안 다른 packet들은 대기했어야 됐다.
100개의 packet이 도착하면, switching이 100번 되어야 output 될 수 있었다.
이러한 문제점을 해결하기 위해 crossbar는 병렬적으로 처리하는 방식이다.
interface수를 N이라고 했을때, N x N의 crossbar가 있다.
ideal하게는 속도가 1/N만큼 줄어들겠지만,
두 packet이 동일한 destination으로 향하는 경우에는 blocking이 되어
이러한 경우 때문에 ideal하게 N만큼 성능이 좋아지지는 않는다.
그럼에도 불구하고 memory, bus 방식에 비해서는 매우 빠르다. (60 Gbps)
Input port queuing, HOL blocking
- queue가 실제 router에는 2개씩 있다. (router의 input port queue, output port queue)
지금까지는 router의 output port에 있는 queue만 이야기 했었다.
지금까지 말했던 congestion에 의한 queuing delay가 발생하는 queue는 output port에 달려있는 queue이다.
➡️ 실제로 핵심적인 queue이다.
여기서의 Input port queuing은 output쪽과는 상관이 없다.
Input port에서 들어오는 rate는 빠르지만 switching이 느려서 발생하는게input port queuing이다.
input queuing은 critical하게 network의 지연이 생길 정도로 문제가 되지는 않는다.
결국 router에서는 switching fabric을 빠르게 하여 스스로 해결할 수 있다.
그런데 bus방식 사용하든, crossbar방식을 사용하든HOL(Head-of-the-Line) blocking이라는 문제가 발생한다.
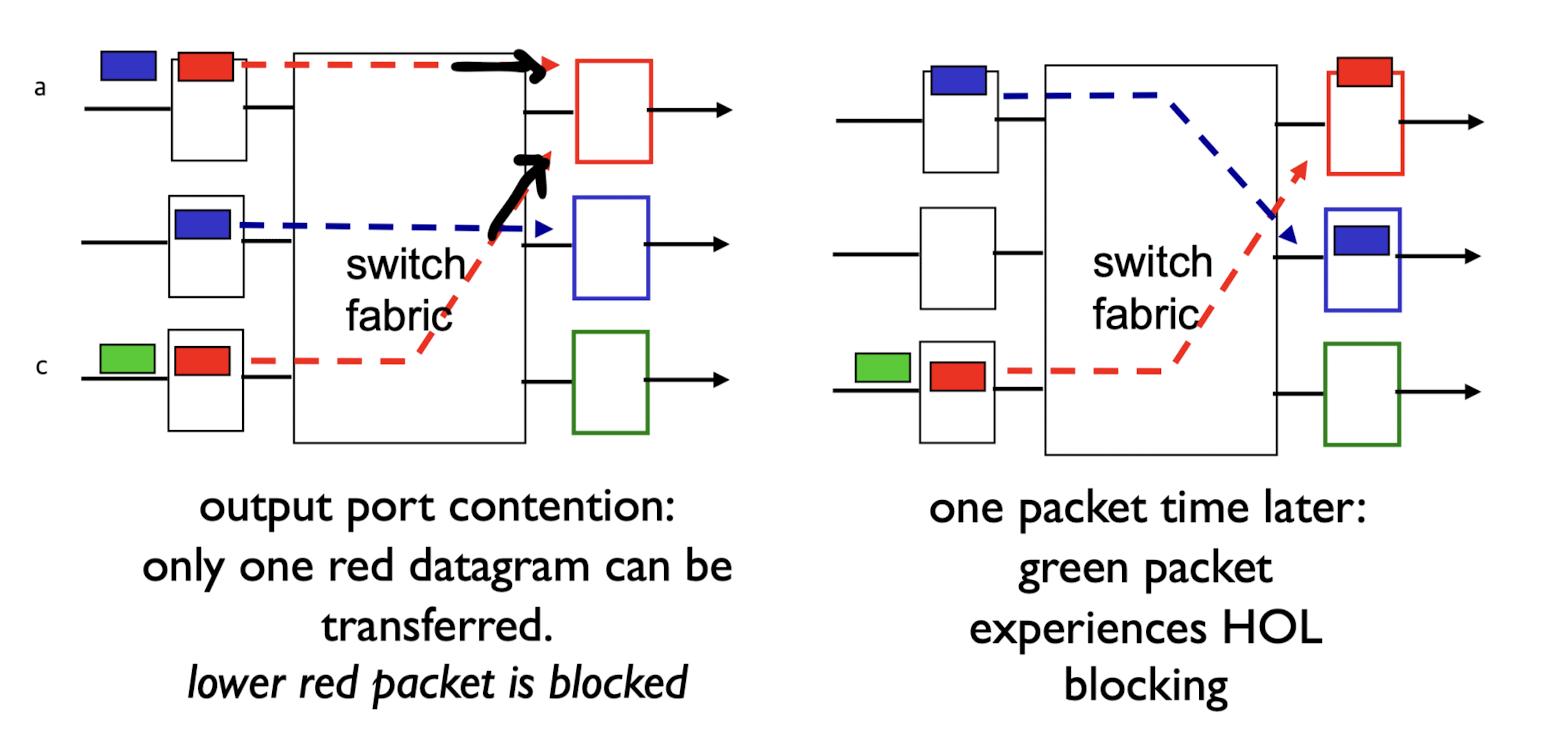 a의 가장 앞에 있는 빨간 packet은 빨간색 link interface로 output되기를 원하고,
a의 가장 앞에 있는 빨간 packet은 빨간색 link interface로 output되기를 원하고,
c의 가장 앞에 있는 빨간색 packet도 빨간색 link interface로 output되기를 원한다.
이처럼 input port queue의 가장 앞에 있는 packet이 한 곳의 output port로 몰려서 지연되는 현상을HOL blocking라고 한다.
Output port queuing
- Output port에 있는 queue가 실제로 핵심적인 queue이다.
사실 Input port의 switching fabric은 굉장히 빨라져서 packet delay가 거의 없다.
들어오는 속도와 유사하게 들어오는데, network로 내보낼 때가 문제이다.
➡️ 지금까지 알고 있던 queuing delay의 queue가 output port의 queue.
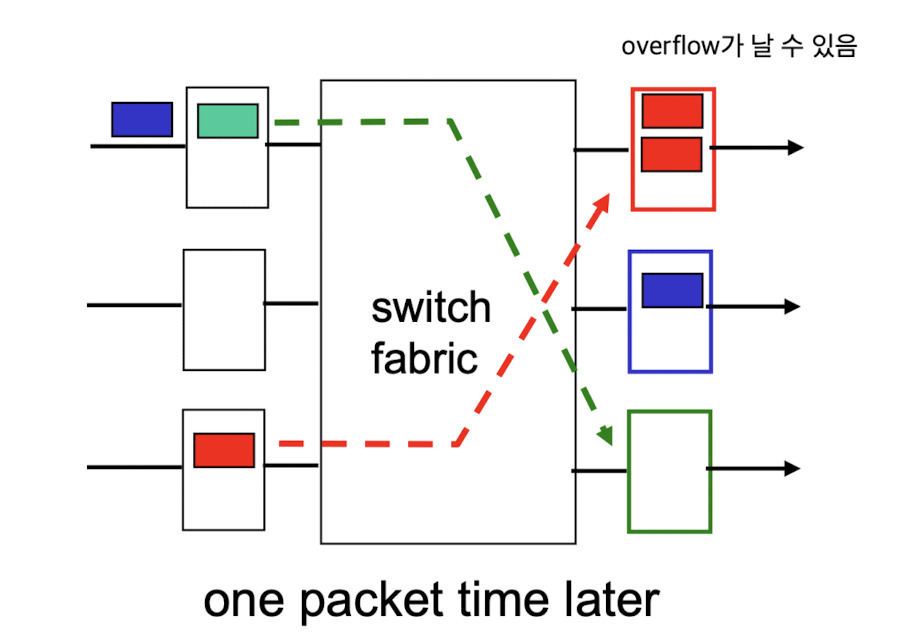
위의 빨간색 output port queue는 congestion이 발생해서 overflow가 날 수도 있다.
그런데 초록색 queue는 queue가 비어있다.
그래서 어느정도 output port queue의 상황을 고려해서 switching할 수 있지 않을까? 하여 나온게
Scheduling mechanism이다.
Scheduling mechanisms
FIFO scheduling
FIFO scheduling:
가장 기본적인 scheduling 방식으로, packet을 First In First Out한다.
그런데 일반적인 queue가 아니라
queue에 꽉 찼을 때, 어떤 packet을 버릴 것인가?(discard policy)를 고려한다.
discard policy에는 3가지가 있다.tail drop:
가장 늦게 들어온 pakcet을 버림.priority:
packet들이 들어올 때부터 priority를 부여해서 버림.
priority를 부여하기 위해서는 priority queue가 따로 있어야 한다.
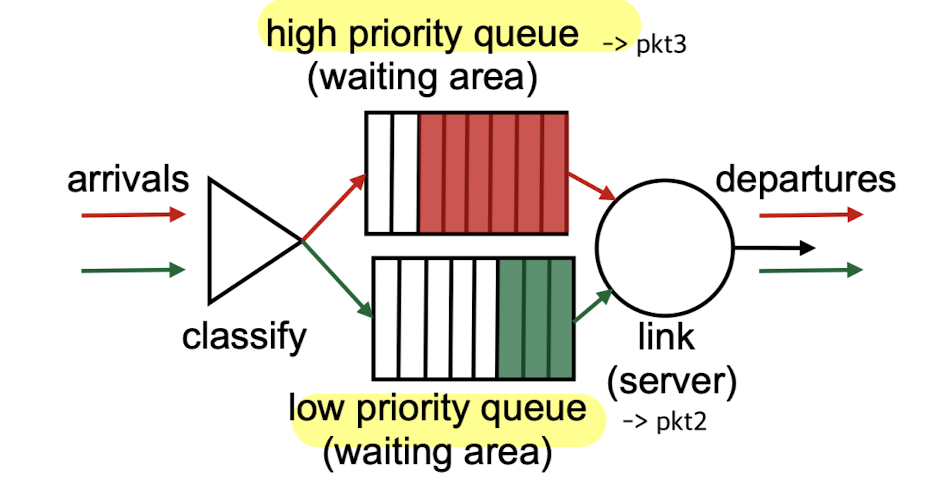 packet이 arrival이 되면,
packet이 arrival이 되면,
classifier에서 해당 packet의 priority를 부여하여 해당 queue로 각각 보내준다.
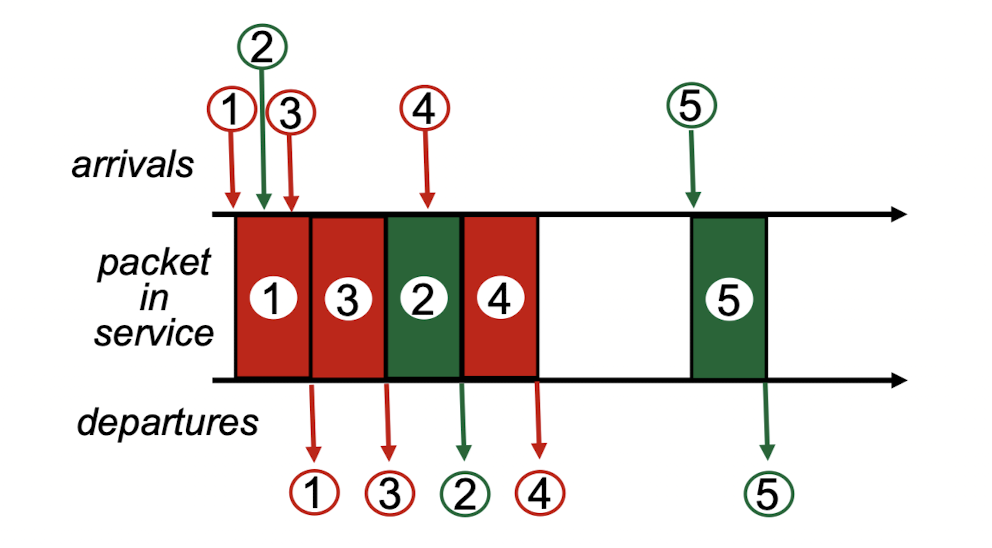 예를 들어,
예를 들어,
pkt1, pkt2, pkt3 순서로 들어왔다.
하지만 pkt3의 priority가 higher priority기 때문에 pkt3를 먼저 내보낸다.random:
확률적으로 버림.
RR scheduling
- class가 여러 개인 경우, cyclically scan한다.
어느 구간 안에서는 어느 정도 fair하게 보낸다.
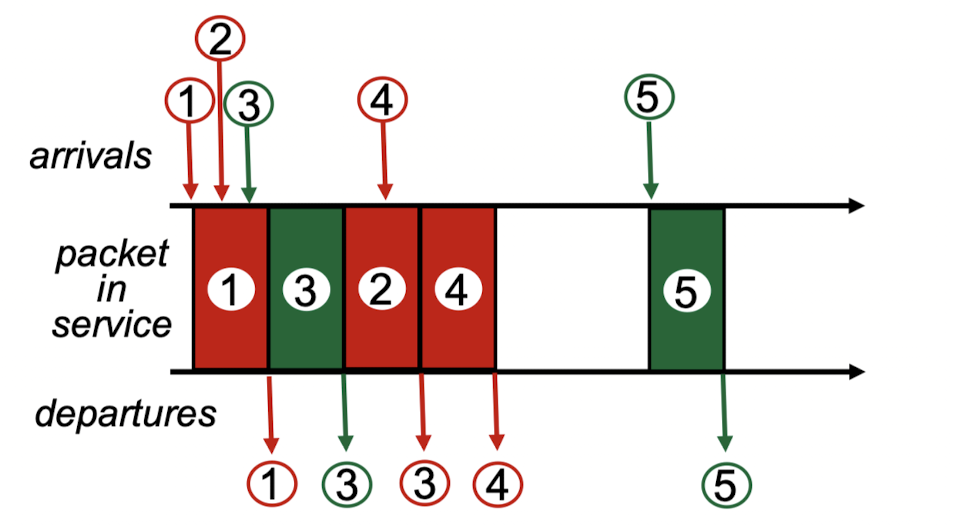
Weighted Fair Queuing (WFQ)
- weight를 다르게 줌으로써,
어떤 기준에 의해서 weight를 초과하는 packet 먼저 보낸다. (RR + priority)
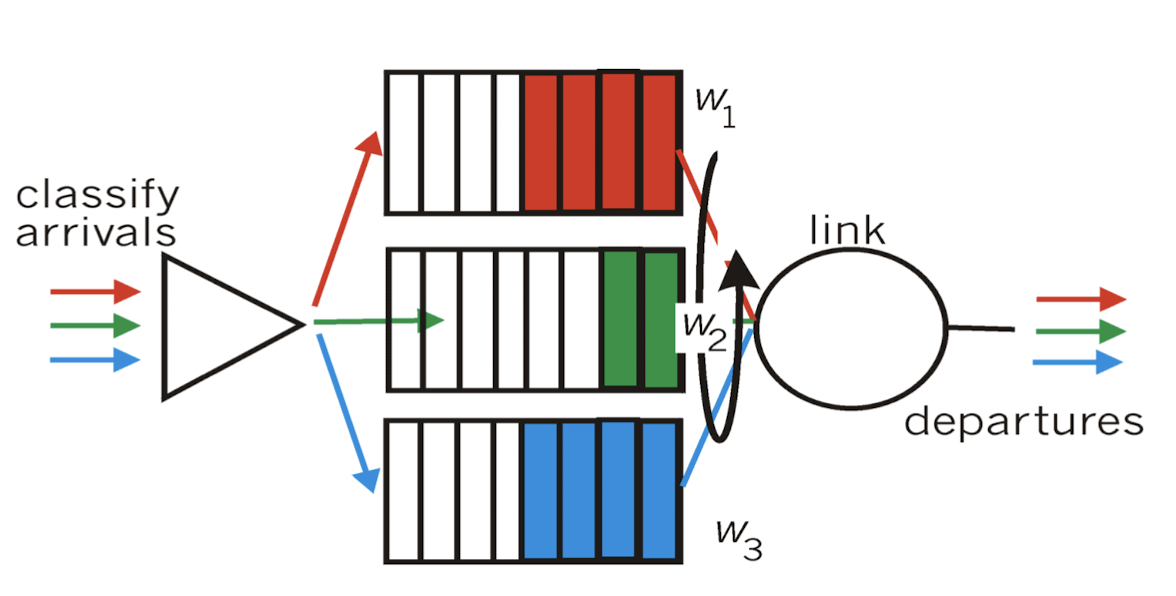
(결론)
priority 방식은 이론적으로 ideal하지만, 실제 환경에서는 쓸 수 없다.
internet은 기본적으로 fair하기 때문에 priority를 부여할 수가 없음.
그래서 실제로는 FIFO scheduling의 tail drop 방식을 사용한다.
➡️ 먼저 들어온 packet부터 내보내고, 마지막에 들어온 packet을 drop
IP : Internet Protocol
- network layer에는
routing protocol,ICMP protocol,IP protocol(핵심)들이 있음
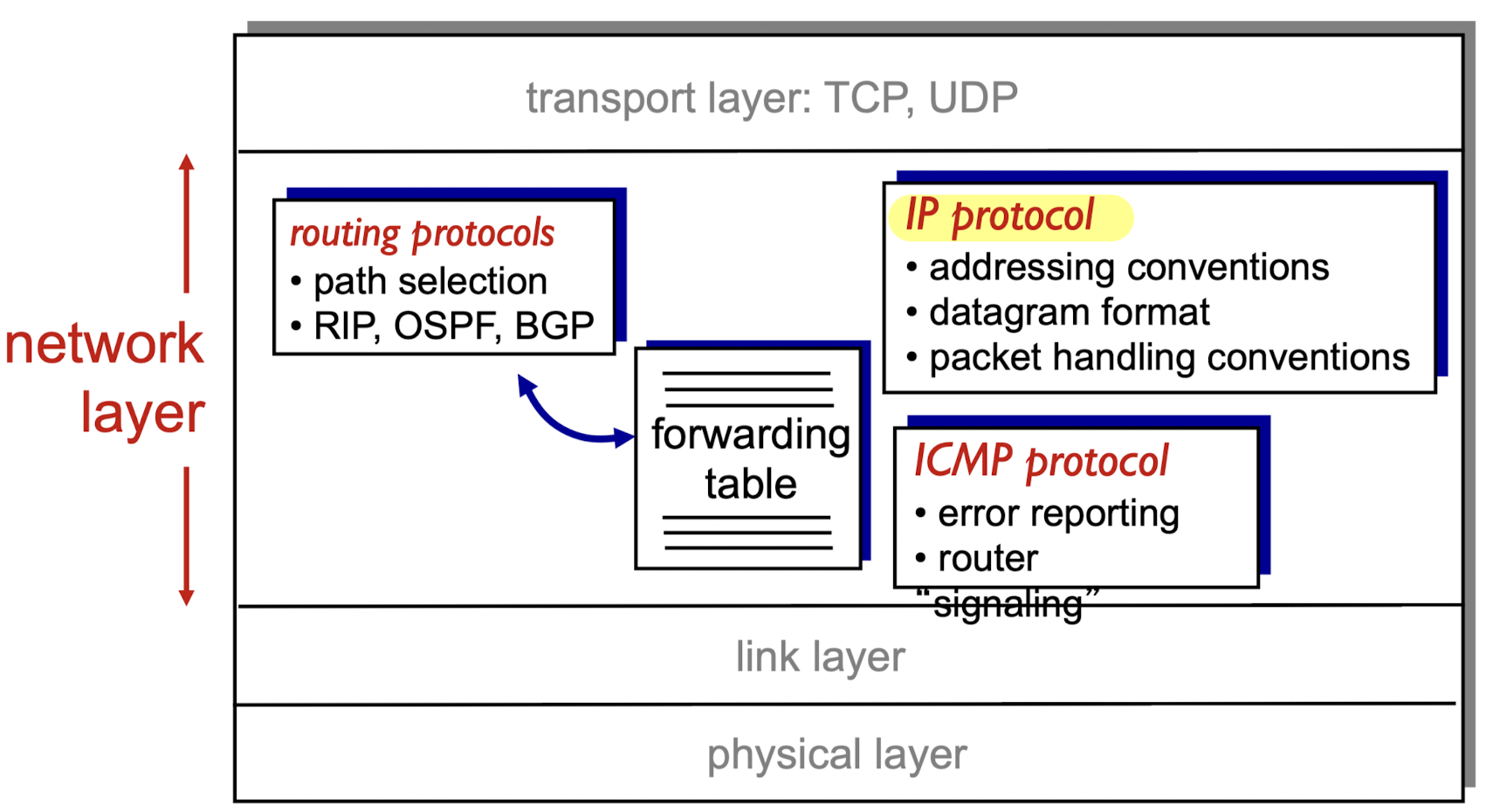
routing protocol:
왜 routing algorithm이 아니라 protocol인가?
routing을 하기 위해서 스스로 결정하는게 아니라 다른 router들과 table을 교환하면서
routing table을 보완해나가기 때문.
그런데 최근에는 routing protocol들이 사용되지 않음.
SDN으로 centralized하게 forwarding table에 대한 rule을 준다. (뒤에서 배움)ICMP protocol:
Inter Control Message Protocol.
router 들끼리 router를 관리하는 server한테 보내는 message.
IP protocol: network layer의 핵심 protocol이다.
IP datagram format
IP datagram format:
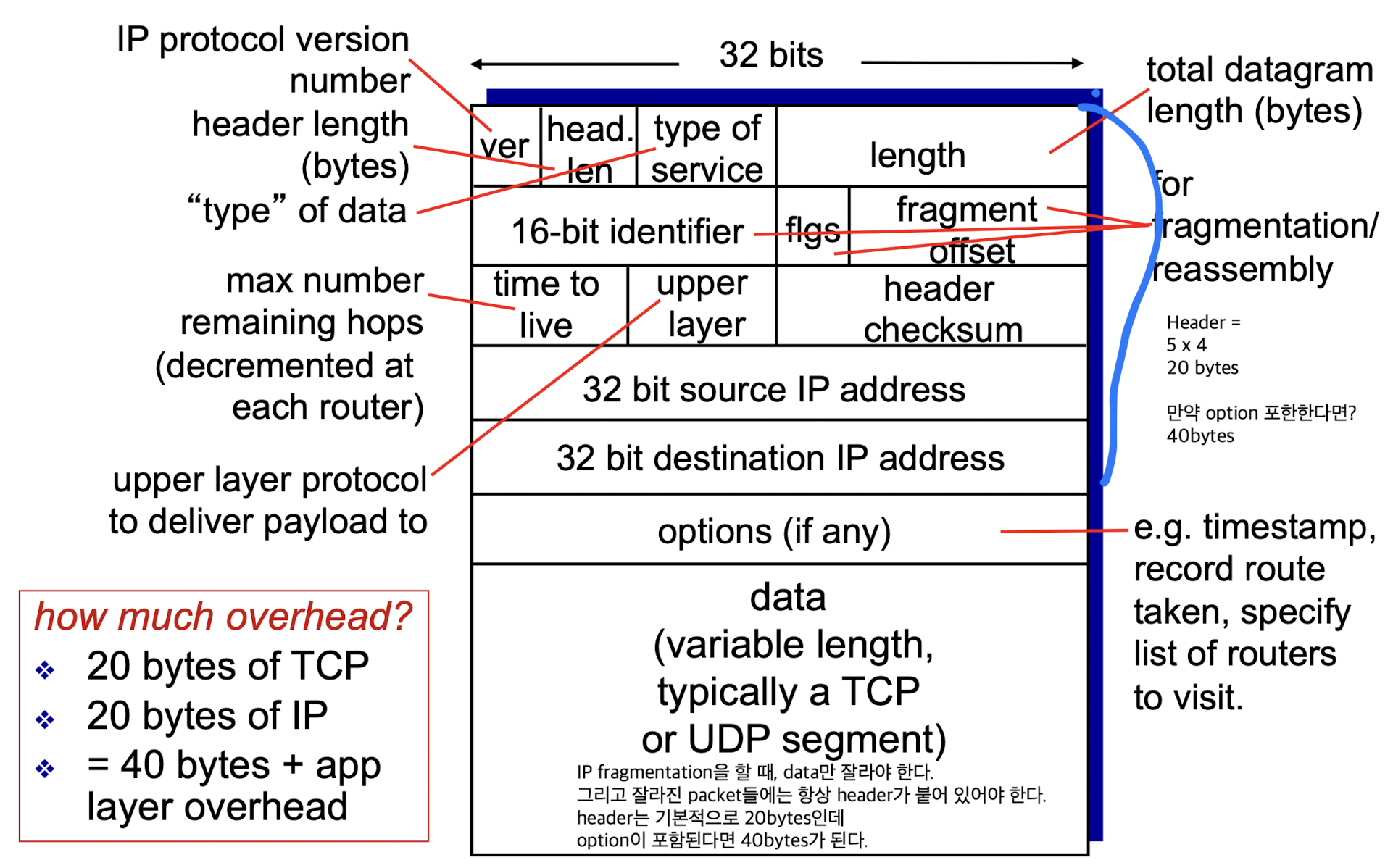
-
ver:
version.
우리가 사용하는 IP protocol version은 IPv4이다. -
head.len:
header length -
type of service:
priority를 부여하기 위해 만들어졌지만, 다양한 문제들로 사용하지 않음 -
length:
total datagram length. -
16-bit identifier:
밑에 32 bit source IP address와 32 bit destination IP address가 있는데,
16-bit identifier는 왜 필요할까?
사실은 (16-bit identifier, flags, fragment offset)이 하나의 set이다.
이 set는 IP fragmentation을 위해 사용된다.
IP datagram은 network에서 가다보면,
해당 link에서 보낼 수 있는 최대 크기인 MTU(Maximum Transfer Unit)를 초과하는 경우가 생긴다.
이러한 경우에 IP datagram을 잘라야 한다.
그런데 fragmentation을 할 때, 유의해야 한다.
예를 들어, 1000bytes IP datagram이 있다.
MTU가 300bytes라면? 300, 300, 300, 100bytes로 보내면 되는가?
안 된다.
잘라진 packet들이 어떤 packet인지 알 수가 없다.
위와 같이 잘랐다면, 어떤 packet은 header의 일부분만 있고, 또 다른 packet은 header의 나머지 부분과 payload의 일부만 있고 ...
이러한 문제점이 있기 때문에, fragmentation을 할 때는 항상 data만 fragmentation을 한다.
그리고 각각의 자른 data가 뭔지 알기 위해 header는 항상 붙어있어야 한다.
원래 하나의 data를 잘라서 각각에 header를 붙였으면, 모두 똑같은 32 bit source IP address와 32 bit destination IP address를 갖고 있다.
그리고 잘라진 fragment들은 모두 하나의 packet이라는 것을 알려주기 위해서,
자를 때 각각의 fragment에 같은 16-bit identifier를 부여해주는 것이다. -
flag:
이 packet이 잘려졌는지? 아닌지? -
fragment offset:
이 packet이 원래 data의 어디서부터 시작되는 부분인지?
➡️ datagram은 in-order(순차적으로)로 오지 않는다.
보낼 때는 frag1, frag2, frag3으로 보냈는데 받는 애는 어떤 순서로 들어올지 모른다.
그렇기 때문에 받은 애 입장에서는 오는 대로 해당 위치에 data를 잘 넣어서 fragmentation하기 전의 Packet으로 복원해야 한다.
assembling은 반드시 destination port에서 해야 한다.
network core에서 assembling하게 된다면, 서로 path가 다르기 때문에 중간에 fragmentation을 모을 수 없다. -
time to live:
maximum number of hops 이다.
죽어있는 server 또는 존재하지 않는 server의 address로 packet을 보냈다고 가정하자.
router들은 계속해서 해당 address를 찾는다.
그런데 해당 주소는 현재 없으니까 찾을 수 없이 무한히 떠돌게 된다.
그래서 router를 통과할 때마다 hop(time to live값)이 하나씩 줄어든다.
만약 time to live값이 0이 되면, 해당 packet을 파기한다. -
upper layer:
transport로 무엇을 쓰는가. TCP? UDP? -
Header checksum:
data는 checksum을 하지 않고 header만 checksum을 한다.
왜 data는 checksum을 하지 않는가?
➡️ transport layer(TCP/UDP)에서 data를 이미 checksum했기 때문에 network layer에서는 자신의 header만 checksum을 하면 된다. -
options:
routing에 관련된 것임 (skip...)정리)
fragmentation을 어디서 하는가?
➡️ 하나의 datagram의 size보다 MTU가 작은 곳에서 fragmentation을 한다.
assembling을 어디서 하는가?
➡️ 반드시 destination port에서 해야 한다.
network core에서 assembling하게 된다면, 서로 path가 다르기 때문에 중간에 fragmentation을 모을 수 없다.
-
IP fragmentation, reassembling
example:- 4000 bytes datagram
- MTU = 1500 bytes
라고 가정.
 위 하나의 datagram이 아래의 3개의 fragment로 fragmentation된다.
위 하나의 datagram이 아래의 3개의 fragment로 fragmentation된다.
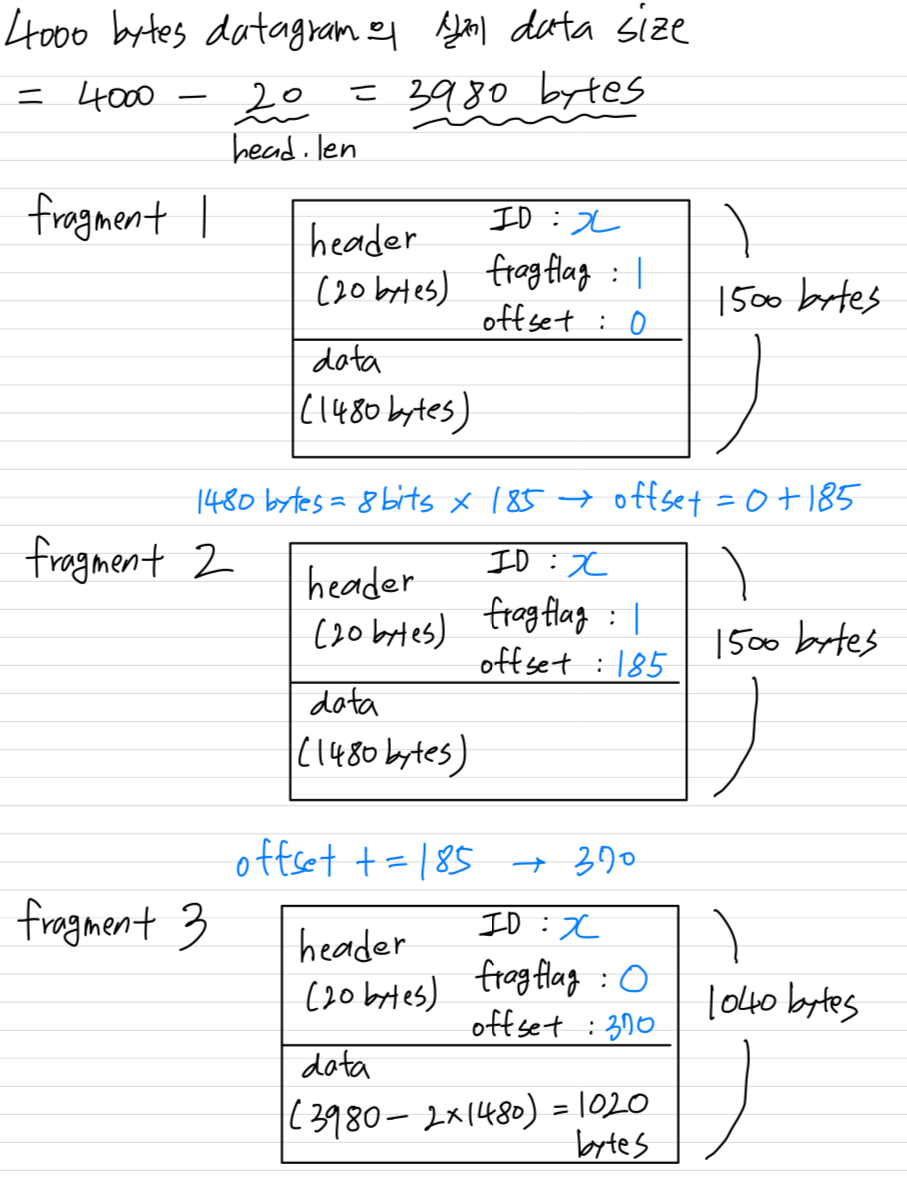
- 세 fragment의 ID는 모두 로 같다.
- fragment3의 fragflag가 0인 이유는 "자신이 마지막 fragment이다"라는 의미.
IP addressing
- switching hub의 경우, host로 직접 연결되어 있는데
router 자체에서 나오는 port 하나에는 단일 host에 연결되어 있지 않고,
subnetwork들에 연결되어 있다.
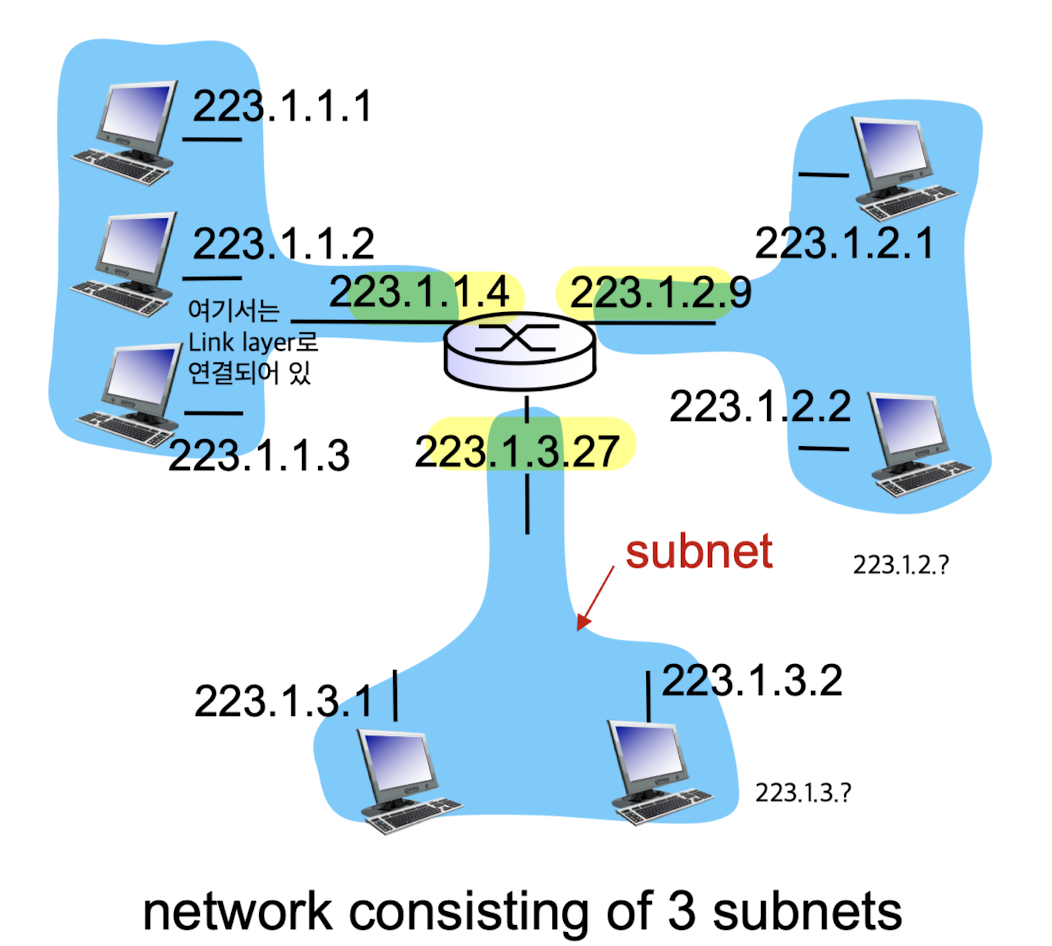 subnetwork 안에서는 switching hub와 같은 link layer로 되어 있다.
subnetwork 안에서는 switching hub와 같은 link layer로 되어 있다.
router를 거쳐 나가야 network layer까지 가는 것이다.
router를 거치기 전에 subnetwork 안에서는 host들끼리 직접 communication이 가능하다.
이를 one-hop 이라고 한다.
어떻게 가능한가?
➡️ 우선 IP address 체계는 크게subnet part와host part로 이루어져 있다.
같은 subnetwork에 있는 host들은 IP address의 subnet part가 동일하다.
어떤 subnetwork에서는 IP address가 223.1.1.? 로 시작해야 하고
또 다른 subnetwork에서는 IP address가 223.1.2.? 로 시작해야 한다.
여기서 223.1.1., 223.1.2. 는 subnet part가 되고,
그 subnet에 있는 host들은 서로 다른 host part를 갖게 되어 구분할 수 있다.
host part에는 해당 subnet를 관리하고 있는 edge router에서 보내기 때문에 결국 subnet part가 중요하다.
CIDR
CIDR(Classless InterDomain Routing):
예전에는 IP address가 Class로 되어 있었는데, Class를 없애고 IP address로 바꿨다.
그리고 subnet part와 host part로 나누었다.
 위의 예제에서
위의 예제에서 /23의 의미는 상위 23 bits가 subnet part라는 것이다.
그러면 나머지 하위 9 bits는 host part가 되고,
0~511. 총 512개의 host를 붙일 수 있을 것 같은데
0과 511은 broadcasting을 위해 제외하여 510개의 host를 붙일 수 있다.
여기서 우리는 subnet part를 AND연산으로 쉽게 알아내기 위해서
subnetmask를 사용한다.
예를 들어, subnetmask가 "255.255.255.0/23" 이라면?
IP address와 subnetmask를 AND연산 하여 상위 23 bits를 subnet으로 식별할 수 있다.
최근에 ISP 업체들은
subnet part의 bit를 늘린다. ? . ? . ? . ? (/26)
그러면 동시에 host part의 bit는 줄어든다.
DHCP
-
host의 개수가 줄어들고, host는 server처럼 계속 연결된게 아니라 간헐적으로 붙기 때문에
host를 더욱 효율적으로 관리하도록 하는 방법이DHCP이다. -
DHCP (Dynamic Host Configuration Protocol):
DHCP server가 연결을 요청하는 host에게 동적으로 일정 시간동안 IP address를 부여한다. -
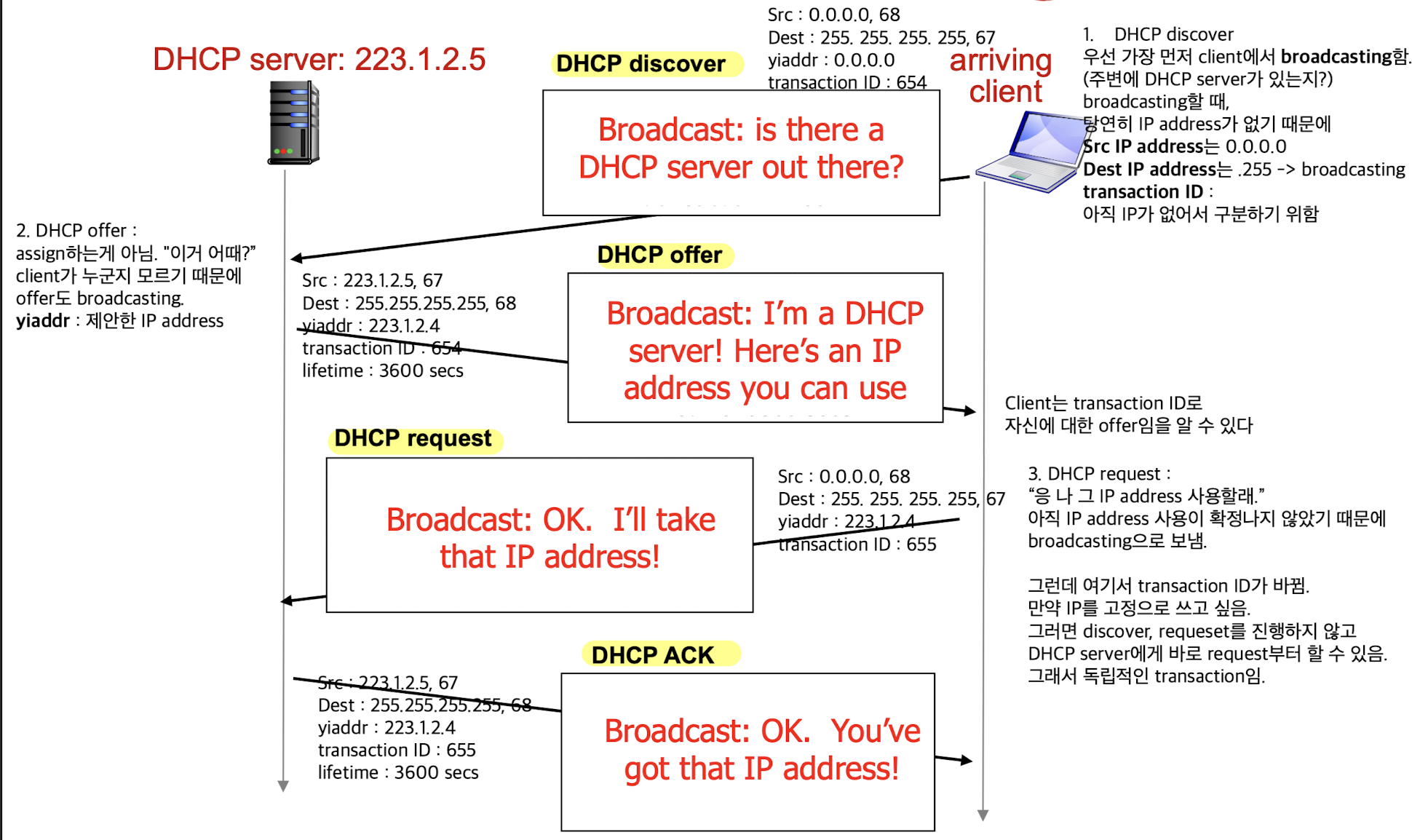
DHCP 4-step:
여기서 중요한 것은 인터넷을 하기 위해서는 IP address가 필요한데,
IP address가 없는 상태에서 DHCP server와 packet들을 주고 받아야 하는 것이다.
그래서 broadcasting을 사용함. (? . ? . ? . 255)
ICANN
- IP address는 ICANN에서 할당해준다.
그런데 2011년 이후로 IP address 할당이 끝나서
더 이상 IPv4를 할당받을 수 없다.
그런데 우리는 인터넷을 문제 없이 사용할 수 있는가? ➡️NAT
그래서 IPv6가 생각보다 널리 사용되지는 않고 있다.
NAT
NAT(Network Addresss Translation):
IP address는 unique해야 하는데, 192.168.0.2, 3 ... 은 전세계 모든 방에서 사용중이다.
어떻게 가능한 것일까?
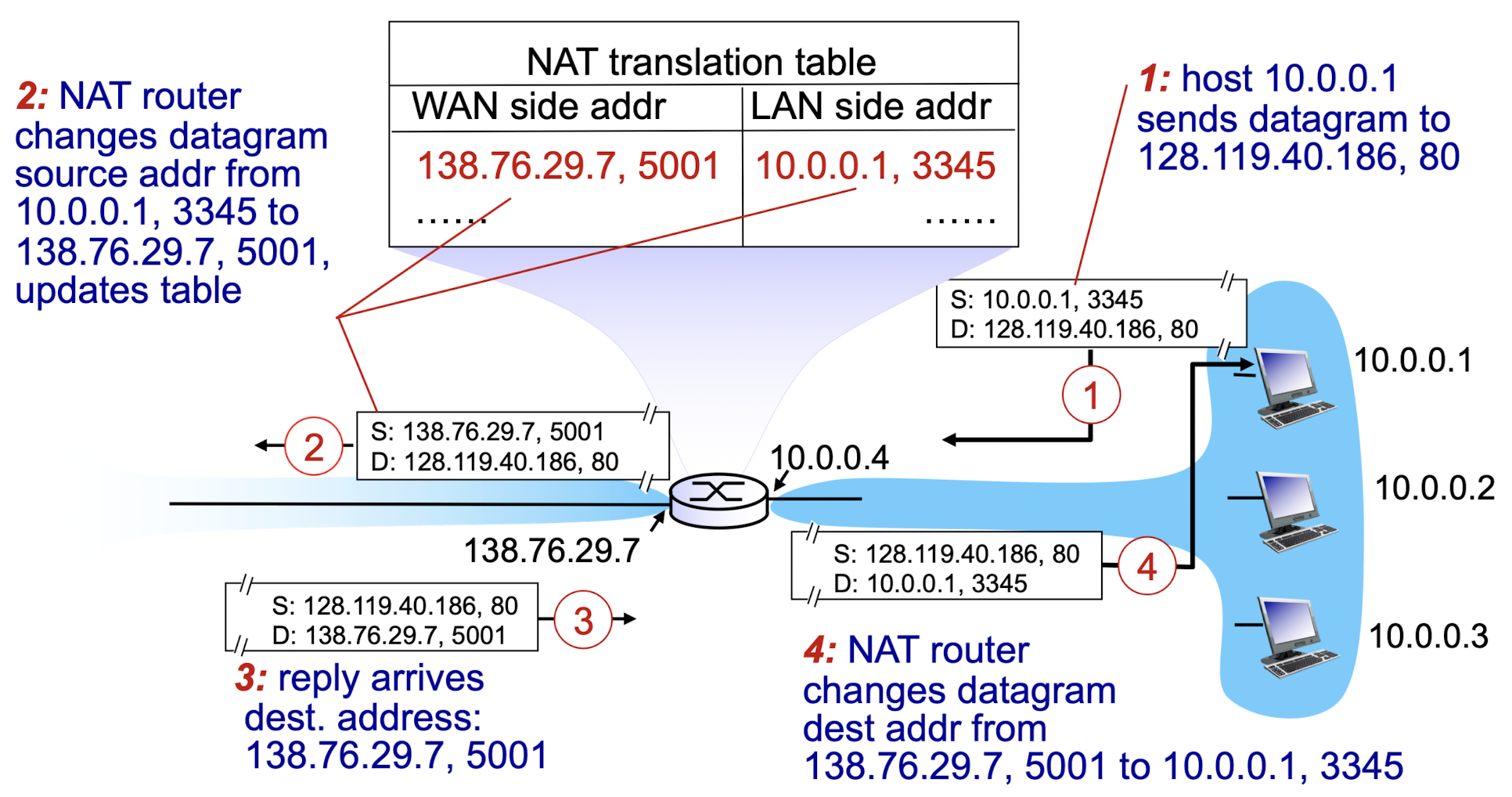
만약 학교 안의 system들끼리 사용하는 것은 전혀 문제가 없음.
문제는 학교 밖의 인터넷을 사용해야 한다.
만약 10.0.0.1로 외부 router에 요청한다면? 외부 router는 그 IP address가 존재하지 않기 때문에 응답을 무시함.
우리 학교 router도 마찬가지로,
한쪽은 subnet(10.?)으로 연결되어 있고(LAN side address),
core쪽은 실제 internet쪽의 address(WAN side address)로 연결되어 있다.
외부에서 볼 때는 WAN side address만 보인다.
이러한 기능을 하기 위해 router에서 NAT(Network Addresss Translation) table을 추가한다.
(1) router에서는 10.0.0.1, 3345를 받으면? NAT table에 138.76.29.7, 5001을 생성한다.
(2) 이제 Source IP는 138.76.29.7, 5001로 바뀜.
(3) web server(port:80)에서 reply받은 packet을 138.76.29.7, 5001로 전달.
(4) router에서는 138.76.29.7, 5001을 받으면? LAN side address인 10.0.0.1, 3345로 전달.
NAT와DHCP가 같이 사용된다면?
새로 붙는 host들에게 private IP address를 할당해줄 수 있다.
그리고 나서 edge router에 WAN side address, LAN side address를 추가해서 인터넷을 사용할 수 있게 한다.
이때, router에서는 생각보다 큰 overhead가 되지 않는다.
어차피 원래 router에서는 IP address header를 decapsulation해야 하기 때문에 table에 한 줄 추가한다고 overhead가 크지 않음.
IPv6
-
NAT라는 기술이 사용되기 전에, IPv4 address가 고갈될 것이라는 문제가 제기되어 IPv6가 나왔다.
-
IPv6:
"32bit address(IPv4)를 128bit로 확장하자"
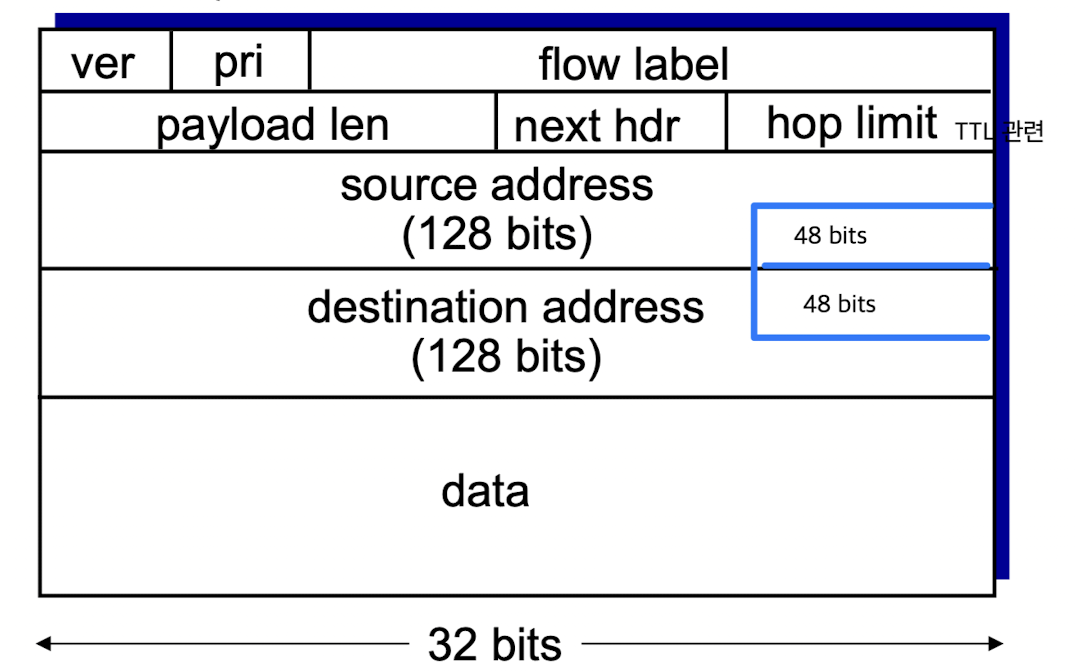
- source address가 128 bits로 확장되었는데,
그 중에 48 bits를 MAC address로 사용한다.
MAC address = HW address는 LAN카드 제조회사들이 할당 받아서 network interface card에 고정시켜놓는다.
- source address가 128 bits로 확장되었는데,
-
IPv6를 굳이 써야 하는가?: No... NAT!
IPv4에서 IPv6로 바꾸려면 전세계 router를 모두 바꿔야 하고,
NAT를 쓰게되면서 사설 IP를 쓰다보니, IP가 더이상 부족하지 않다.
기존의 router들을 전부 건들이지 않아도 된다.
그래서 IPv6는 생각보다 많이 쓰이지 않고 있다.
tunneling
tunneling:
결국 최근에 IPv6는 cloud에서 많이 사용한다.
그러면 IPv4와 IPv6가 혼제되고 있는데 이를 어떻게 해결해야 하는가?
➡️ tunneling
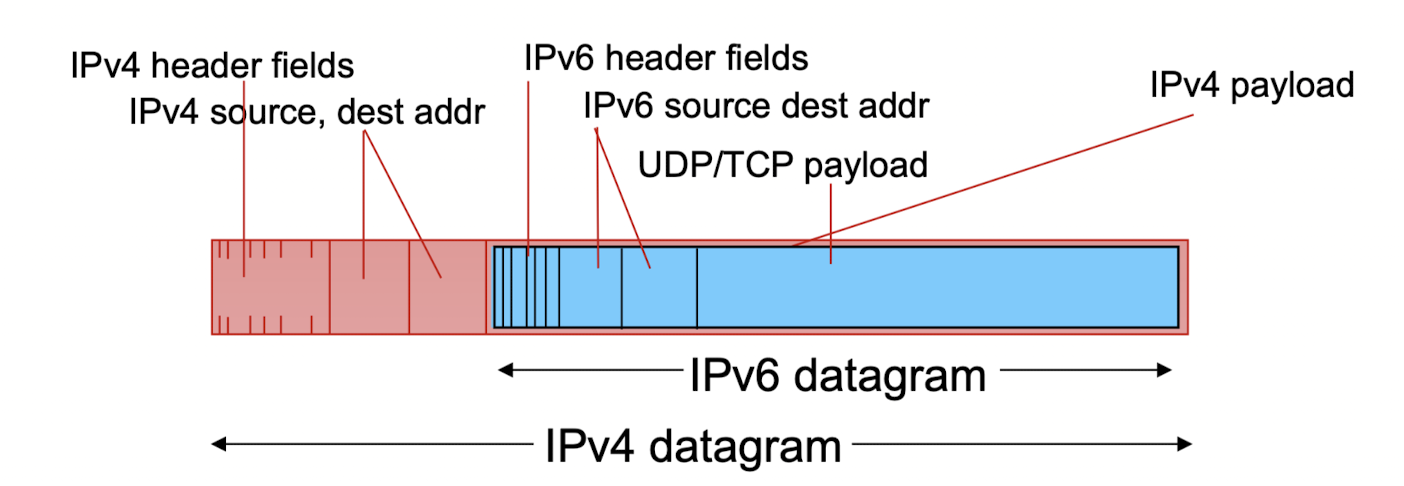
- IPv6 network로 들어갈 때, IPv6의 header와 data를 통째로 IPv4의 data에 넣는다
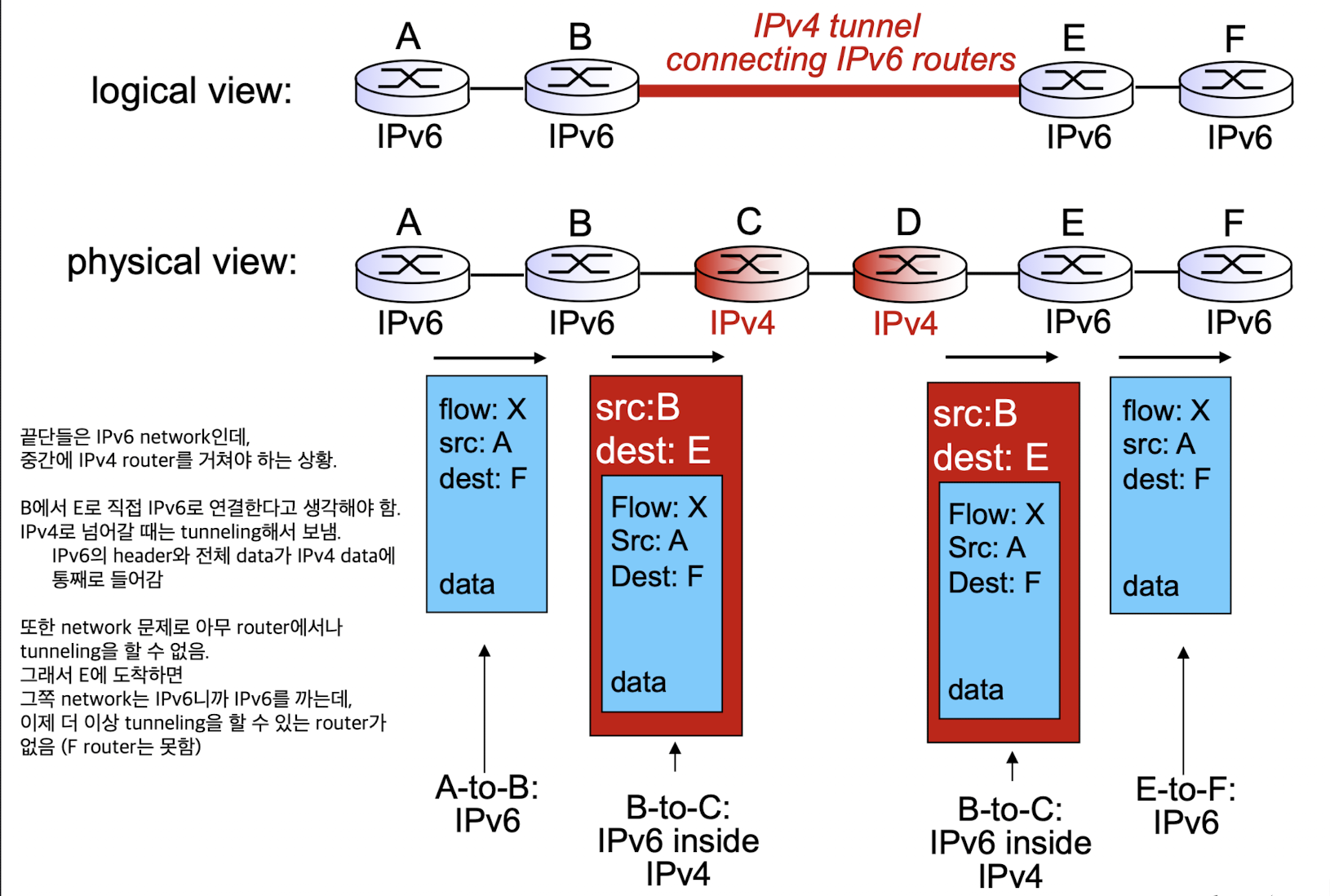
- IPv6 network로 들어갈 때, IPv6의 header와 data를 통째로 IPv4의 data에 넣는다
Generalized Forwarding vs. SDN
-
Generalized Forwarding:
traditional한 routing 기술.
router가 어떤 algorithm을 돌리느냐에 따라서 router의 overhead가 매우 크다. -
SDN:
router의 routing table 관리를 routing management server에서 centralized하게 관리, 수정한다.
forwarding을 결정하는 것은 forwarding table을 보고 하는데,
만약 SDN에서 forwarding table을 미리 관리, 수정해준다면
router에서 과거 방식처럼 복잡한 routing protocol을 통해서 dynamic하게 직접 바꿀 필요 없이 할 일이 간단해진다.
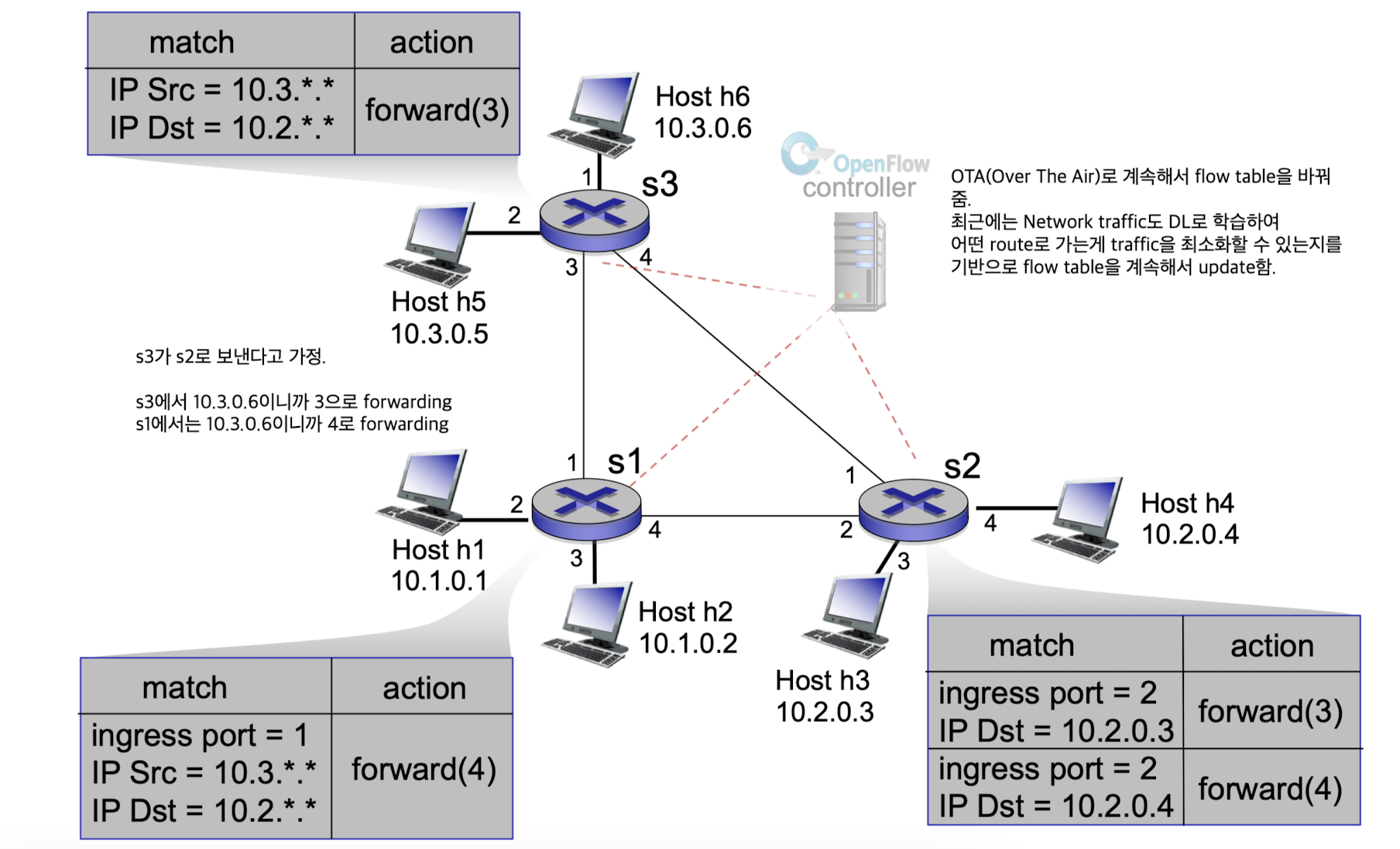
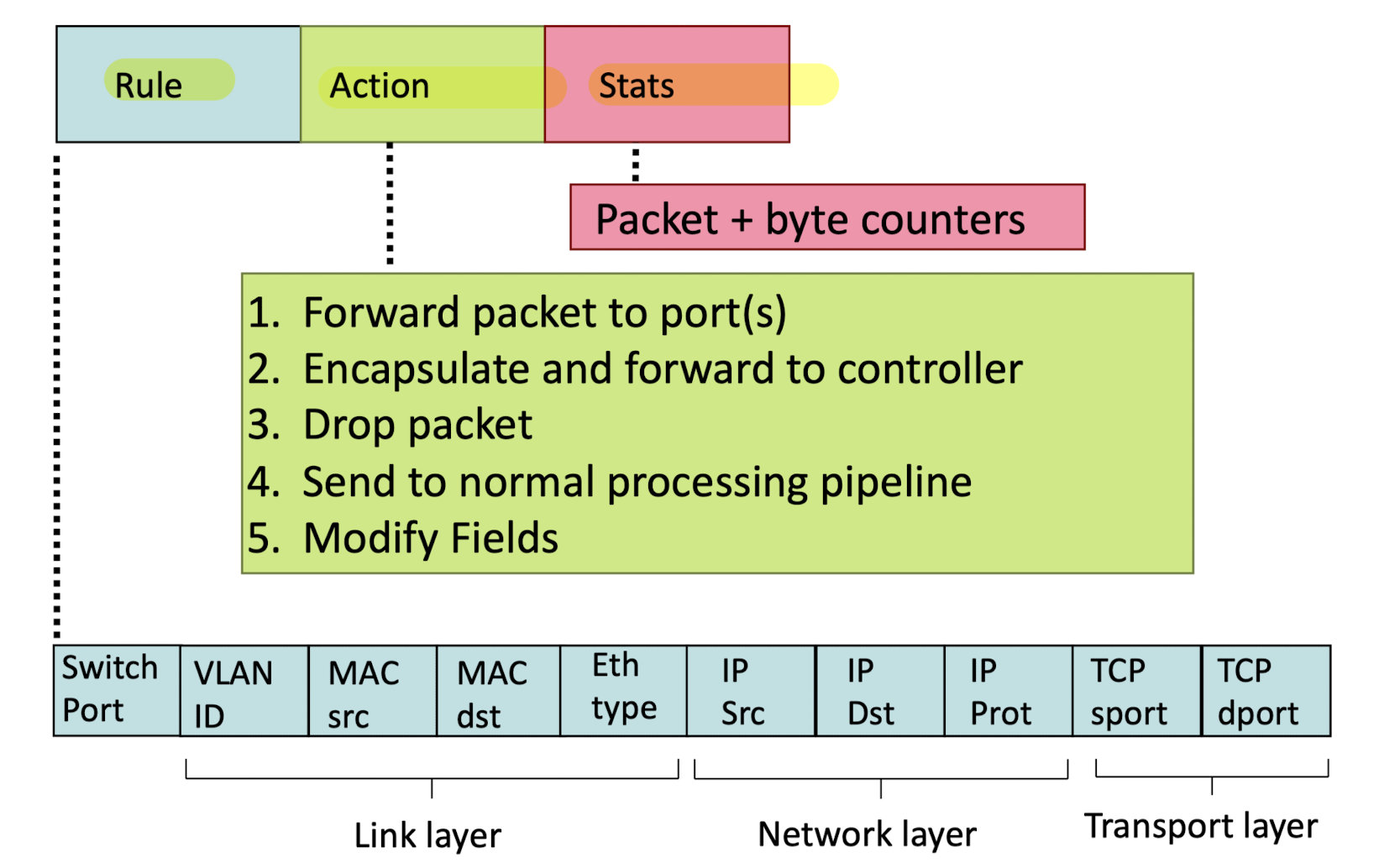
OpenFlow
OpenFlow:
SDN의 가장 대표적인 기술.
flow : header field에 정의되어 있는 flowPattern: header fields 안에 어떤 값이 match되면? event를 발생시킴Actions: pattern이 matching되었다는 event에 대해서, 어디로 가라.Priority:Counters: 받은 packet의 #bytes, 개수
 예를 들어,
예를 들어,
router에 위처럼 flow table이 정의되어 있어서 packet을 선별할 수 있다.
크게 보면Rule,Action,Stats으로 나눌 수도 있다.
아래와 같이 SDN에서는 layer를 넘나들면서 SW(match + action)적으로 flow를 control(Router, Switch, Firewall, NAT)할 수 있다.
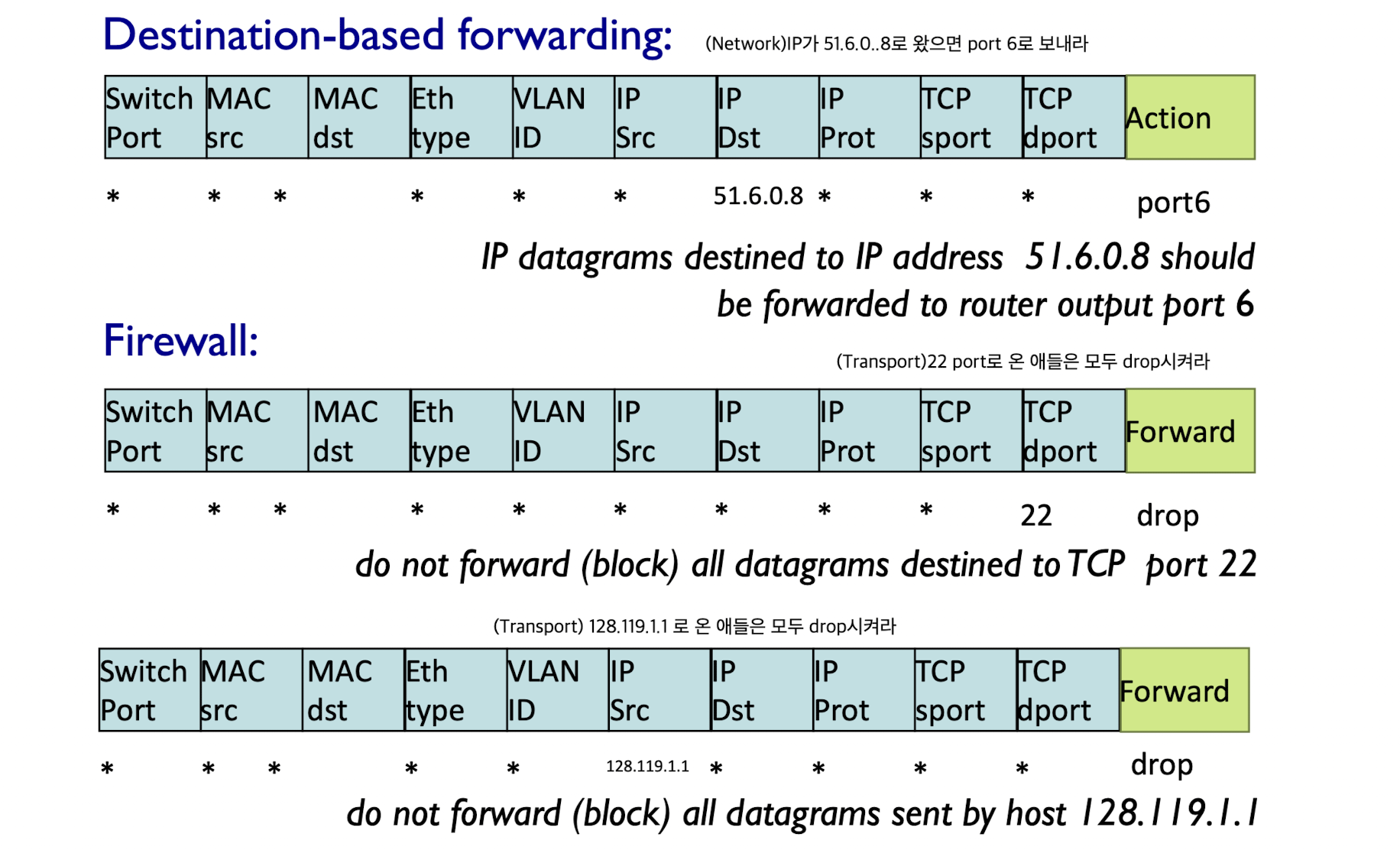

Example: