1. principles of network
Our goals
-
Chap1에서 우리는 Internet Protocol stack에 대해서 배웠었다.
- Application layer
- Transport layer
- network layer
- data link layer
- physical layer
-
우리는
1. Applicatoin Layer = Network application에 대해서 배울 것이다.
우리가 가장 많이 쓰는 application =Web
Network Application = Web을 어떻게 개발할 것인가? -
Our goals :
- transport layer srevice model : network application을 개발할 때, 가장 먼저 선정해야 함
- Client-Server model? P2P model?
- HTTP, FTP, DNS(Domain Name Service) 등 가장 대표적인 appplication protocol에 대해 공부할 것임
- creating network applications (socket API)
Some network applications
- e-mail
web
remote loging
P2P file sharing
multi-user network games
streaming stored video(Netflix, YouTube, Hulu, ...)
real-time video
social networking service
search
....
Creating a network app
-
No need to write software for network-core devices :

- Network application은 end system에서만 실행된다.
내꺼에서 동작되는 2개의 system이 아니라,
하나는 내 computer, 또 하나는 다른 end system에서 실행됨. - application을 작성할 때는 network core에는 router 밖에 없다.
router에는 physical, data, network layer.
이 3개의 layer만 있기 때문에 network core에 대해서는 전혀 고려하지 않고
end system에 대해서만 고려하면 된다.
systsem 하나에서만 실행되도록 만들면 되기 때문에 개발이 빠르다.
- Network application은 end system에서만 실행된다.
Application architectures
- 두 가지 application architecture가 있다.
- client-server
- peer-to-peer (P2P)
- 우리가 사용하는 대부분의 architecture가 client-server.
Client-server architecture
Server:always-on host:
우리가 naver server에 접속하려고 하면, server computer는 항상 켜져 있어야 한다.parament IP address:
또한 우리가 어디에서도 server에 접속하려고 하면, server의 IP address를 알아야 한다.
우리는 naver.com이라는 domain으로 요청하지만, 궁극적으로 DNS로 IP address로 바꿔 통신한다.
기본적으로 IP address는 device마다 고유해야 한다.
모든 Internet에 접속하는 device들이 고유한 address를 갖고 있어야 그 고유한 address로 data를 주고 받을 수 있다.
그래서 server는 parament IP address를 갖고 있어야 한다.dynamic auto scaling:
일반적으로 server는 사용자들이 얼만큼 접속할지 예측하는게 어렵기 때문에 Cloud를 사용한다.
그래서 접속자 수가 많아지면, 여러 개를 켜서 service가 제공될 수 있게 한다.
Client:dynamic IP address:
반대로 client들은 IP address가 고정되어 있지 않아도 된다.- client는 자기가 필요할 때만 Internet으로 연결한다.
통신을 할 때, server로 request를 보낸다.
그래서 일반적으로 Client-server architecture에서는 Client가 request로 먼저 통신을 시작한다. - Client들끼리 direct로 communication하지 않는다.
만약 direct로 communication한다면, 이게 바로 P2P이다.
- 우리(Client)는 고정 IP address를 받지 않는다.
우리는 DHCP라는 server를 통해서 IP를 할당 받는다.
학교에 있는 computer들이 고정 IP를 할당 받은 것처럼 보이지만,
실제로는 고정 IP가 아니다.
학교에서 만든 server를 외부에서 test하려고 하면, server가 없다고 들어가지지 않는다.
외부에서는 private IP로 되어있는 host가 전혀 보이지 않기 때문이다.
학교 안에서 server를 돌리려고 할 때, 학교 전산원에서 고정 IP를 따로 받아야 한다.
P2P architecture
P2P:
항상 켜져 있는 server는 고려하지 않고, 임의의 system들이 주축이 대등한 관계로 통신한다.- 이렇게 하기 위해서는 사전에 약속이 되어있어야 한다.
그래서 모든 application에서 P2P 통신을 쓸 수는 없다. - Peer들은 고정 IP가 아니라 dynamic IP를 갖는다.
그래서 P2P는 안정적으로 통신할 수가 없고, 보안 문제도 존재하기 때문에 많이 사용되지는 않는다.
- 이렇게 하기 위해서는 사전에 약속이 되어있어야 한다.
- 최근에는 Client-Server와 P2P를 hybrid하게 사용하는 메신저 프로그램이 있다. (telegram)
telegram은 server에 보내지지 않고 지워진다.
data 내용을 server로 보내는 것이 아니라 상대 IP를 갖고 direct로 통신을 진행한다.
또한 카카오톡은 msg가 server에 보내져서 server가 상대로 전달한다.
하지만 최근 보안 문제상 hybrid하게 통신하게 하는 service도 개발되었다.
Processes communicating
-
program: nonvolaitle memory인 HDD, SSD에 저장되어 있는 상태- 우리의 CPU는 HDD, SSD와 direct로 절대 일하지 않는다.
CPU는 항상 memory에 있는 program의 명령어, data만 처리를 한다.
그래서 program을 실행시키기 위해 RAM에 올려야 한다.
program을 RAM에 올리는 과정 = loading
- 우리의 CPU는 HDD, SSD와 direct로 절대 일하지 않는다.
-
process: program이 CPU에 의해 실행되기 위해 memory(RAM)에 loading된 program. -
word program, web browser라는 2개의 독립적인 process가 있다고 가정하자.
여기서 두 program 사이에서 data를 어떻게 주고 받을 수 있을까?- 두 process는 OS 입장에서 독립적인 process이기 때문에 기본적으로 두 process 간의 통신은 못하게 한다.
- 하지만 실제로 OS에는 process 간의 communication을 하는 것을 도와주는
IPC(Inter-Process Communication)이 있다.
IPC를 하기 위해 socket programming이 나왔다.
-
하나의 system에서 두 process가 통신하기 위한 IPC 얘기가 왜 나왔는가?
network application에서 communication 한다는 것
= 내 host에서 실행되고 있는 network application은 하나의 process이고,
다른 사람의 computer에서 실행되고 있는 network application도 하나의 process이다.
= 멀리 떨어져 있는 process 간의 통신을 한다.
= process간의 통신을 network로 확장한다.- Client에서 실행되는 application =
Client process - Server에서 실행되는 application =
Server process
- Client에서 실행되는 application =
-
socket programming:
내 computer 안의 process들끼리 통신하게 할 수도 있고,
외부에 있는 process들과 통신하게 할 수도 있다.
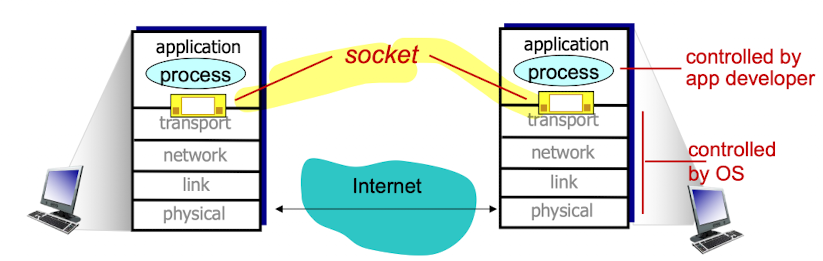
Sockets
Socket:
같은 host의 process뿐만 아니라, 외부 host의 process끼리 통신하게 해주는 일종의 interface이다.
(application을 제외한 모든 internet protocol layer는 모두 OS에 있음)
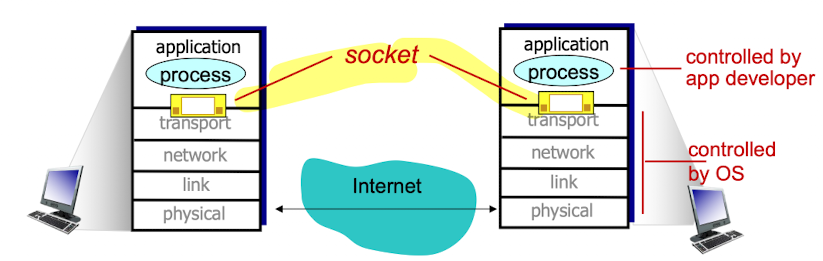
- transport, network, link, physical layer는 모두 OS가 관리한다.
우리가 program을 짜면, application layer에서 짠다.
application layer에서 짜는 program에서 OS의 service을 받기 위해 system call을 사용한다. - socket은 OS에서 관리하고 있는 network protocol stack을 사용할 수 있는 service를 제공한다.
이 service를 이용하여 멀리에 있는 또 다른 application process와 data를 주고 받을 수 있는 interface이다. - OS에 system call을 이용하여 HW에 대해 몰라도 program을 짤 수 있는 것처럼
socket을 이용하면 TCP/IP에 대해서 신경 쓸 필요 없다.
누구한테 어떤 data를 보내기 원하면, socket에서 해당하는 TCP/IP protocol stack을 사용하게 해줌.
- transport, network, link, physical layer는 모두 OS가 관리한다.
Addressing processes
-
Internet을 하기 위해 고유한 IP address가 필요하다
어떤 device인지 알아내기 위해서 고유 IP address는 Identifier로 사용된다.
IP address는 123.45.67.8 이런 식으로 4 bytes = 32 bit로 구성되어 있다. -
IP address만 있다면 Internet 통신이 가능할까?
내 computer에서 사용하는 여러 application(Youtube, Insta, Naver, ...)이 있을 텐데
각각의 process를 구분할 수 있어야 하기 때문에
data가 어떠한 process로 가야하는지 identification할 수 있는port number가 필요함.
그래서 같은 host 안에서는 동일한 port number를 가질 수 없다.
참고로 우리가 자주 사용하는 application들은 지정된 port number를 갖는다.
HTTP server : 80
mail server : 25 -
결론 :
IP address와 port number를 알아야
network application을 개발하고 application 간의 통신을 할 수 있다.
(정리)
IP address만 갖고서 application layer로 packet이 도달할 수 없다.
IP address는 내 computer까지만 오는 것이고,
어떤 process에서 그 packet을 가져갈 것인가? 하는 추가적인 port number가 필요하다.
엄밀히 말하면 process마다 할당되는 것은 아니다.
내 process 안에서 여러 개의 port number를 할당할 수 있다.
port는 socket을 만들 때, "이 process에서 이 port number를 쓰겠다"라고 binding해줄 수 있다.
Applicaion layer protocol defines
- Application layer에서 하는 일은 무엇인가?
- Message(application에서 packetd을 message라고 부름)들의 type을 정의 (request, response)
➡️ application의 service model은 일반적으로 Server-Client model을 따른다. - message syntax 정의 (해당 field에 어떤 값을 주면, 어떤 일을 수행하라)
- rules for when and how process send & respond to msg (언제 어떻게 msg를 주고 받아야 하는지)
- open protocols : defined in RFCs
Open protocol들은 RFCs라는 표준 문서로 정의되어 있다.
그렇지 않고 자체적으로 proprietary protocol로 사용되고 있다.
- Message(application에서 packetd을 message라고 부름)들의 type을 정의 (request, response)
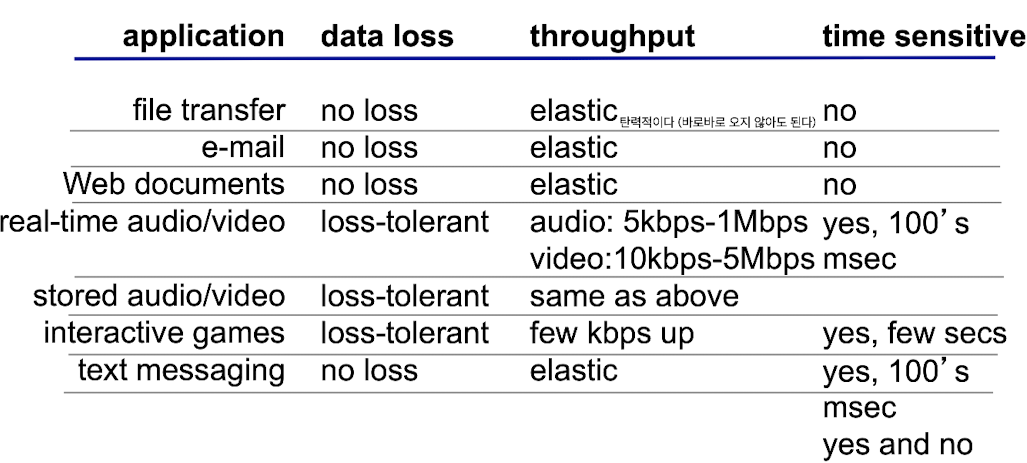
What transport service does an app need?
- Application 특징에 따라 요구되어지는 service가 다르다.
이러한 service는 transport layer에서 service되어진다.data integrity(reliability):
Web, file과 같은 application들은 100%의 reliable data transfer가 이뤄져야 한다.timing:
게임과 같은 application에서 조작을 내리는 것은 delay 없이 즉각적으로 대처돼야 한다.
email과 같은 app은 delay가 조금 있더라도 괜찮다. 가장 중요한 것은 reliability다.Throughput:
동영상 application 같은 경우, 적어도 15~30fps 정도 play를 해야 자연스러운 동영상을 볼 수 있다.
이를 위해 단위 시간 동안 data가 꾸준히 들어와야 하므로
throughput이 보장되어야 한다.security:
encrpytion, data integrity
Transport service requirements : common apps
- Application의 특성에 따른 data loss, throughput, time sensitive와 같은 guarantee를
누가 보장해주는가?
➡️Transport layer:
application의 data를 요구사항에 맞게 end-to-end(source와 destination 간의) 통신을 잘 할 수 있게 해줌.
Internet transport protocols services(TCP vs UDP)
-
Internet에서 사용하는 Transport layer의 protocol?
= Application의 message의 속성을 기준 삼아 TCP? UDP?를 설정한다.
해당 application의 message가 loss에 critical하다면? = data integrity가 중요하다? TCP.
해당 application의 message가 throughput과 time sensitivity가 중요하다? UDP.-
TCP service:- reliable transport :
message들을 desetination에서 완전히 받을 수 있을 때까지 보내주지 않는다.
중간에 일이 발생해도 모두 처리해준다.
data integrity는 보장되지만, time sensitivity는 떨어진다. - connection-oriented :
end-to-end의 논리적인 연결 수립 과정이 있다.
연결을 수립하고 나서 message를 보낸다.
(복잡함 congestion control, .. 등)
- reliable transport :
-
UDP service:- Less reliable data transfer :
best effort를 해주지만, 잃어버린 message에 대해서는 책임지지 않음.
(이를 위해서 congestion controll 등 )
data integrity는 떨어지지만, time sensitivity는 보장된다.
(편리함, 빠름)
- Less reliable data transfer :
-
Securing TCP
-
원래 TCP는 encrpytion이 없어서 보안이 약했음
최근에는 TCP와 security가 강화된 SSL 기능이 나옴. -
HTTPS가 SSL을 사용한 예시이다.
End-to-end에서 인증이 이루어짐.
SSL 자체는 application에 있지만, TCP로 binding되어 사용됨.
HTTPS service가 application에 있어서 test하기 위해 domain이 있어야 함.
2. Web and HTTP
-
가장 대표적인 internet application이
Web이다. -
Web은 기본적으로HTTPprotocol을 사용한다. -
web page는 다양한objects(동영상, 그림, 포맷 등)들로 이루어져 있다. -
app은 object들이 우리의 local(스마트폰)에 있다.
web은 object들이 server에 있어서 URL을 치는 순간, server로 request가 간다.
server에서는 object들을 "~에 ~을 배치하라"하는 기준인 HTML을 통해서 response를 준다. -
각각의 object들은 server안에 개별적으로 file로 있다.
(아이콘 1개, 버튼 1개, 이미지 1개, ...)
그 object들은 개별적인 URL이 붙는다.
 URL은
URL은 host name과path name으로 구성된다.
HTTP overveiw
-
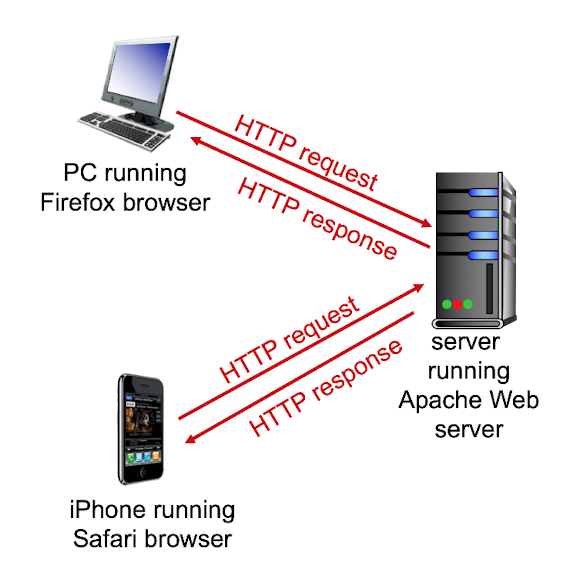
HTTP: HyperText Transfer Protocol -
server에는 web server(ex : Apache, AWS, 등)가 있어야 함.
client가 browser에서 HTTP protocol을 통해서 먼저 request를 보냄.
Server는 request에 대한 response를 보냄.
-
Web은 data integrity가 가장 중요하기 때문에 TCP를 사용.
TCP는 connect oriented이기 때문에 application에서 data를 바로 보낼 수 있는 것이 아니라,
circuit switching을 logical하게 구현한 것인 TCP이다.
따라서 data를 보내기 전에TCP connection을 먼저 initialization해야 한다.
application에서 network 연결을 시작할 때, server에서 실행하고 있는 port number를 사용한다.
server에서 실행하고 있는 port number. (web은 기본적으로 80)정리
port 80으로 TCP connection 요청.
server는 해당하는 client와의 TCP connection을 accept.
data를 다 주고 받으면, TCP connection을 끊어버림. (TCP를 연결한 상태로 두면 overhead가 커서)
(이 과정은 나중에 socket에서 자세히) -
home page: web server에 request했을 때, 가장 처음으로 받는 page
web page: web server에 있는 모든 page
request를 하면, server에서 HTML file 하나를 줌.
browser에서 HTML file을 parsing함.
parsing하면 reference된 object들이 나옴.
그 object들은 각각의 URL이 있기 때문에 그 URL을 통해 server로 또 request.
server는 그 request들을 하나씩 response해줌.
받는 대로 web browser에 보여주고 나서, TCP connection을 끊는다. -
HTTP protocol은 기본적으로
stateless(상태가 없는 protocol)이다.
예를 들어 naver.com을 치면, server에서 보내줌.
또 다시 naver.com을 치면, 또 다시 server에서 다시 보내줌.
stateful한 protocol을 만들기 위해서는 매우 복잡해짐.
모든 user들에 대한 과거 request들을 모두 처리하여 stateful하게 만들 수 없다.
그 중 하나의 방법으로는 login이 있다.
그런데, 어떤 사이트들은 login을 하지 않았는데도 이전에 봤던 검색 기록들이 남아 있다.
이게 login을 하지 않은 진정한 stateful protocol이다.
이를 가능케하는 것이쿠키이다. (나중에 배움.)
"쿠키"는 HTTP protocol에서 하는 일은 아니고, 추가적인 기능인 것이다.기본적으로 HTTP protocol은
stateless protocol이다.
HTTP connections
-
non-persistent HTTP:
TCP connection을 한 object마다 연결한다.
예를 들어 받아야 하는 object가 10개라면,
첫번째 connection -> 수립 -> object reqeust -> object response -> 받음
두번째 connection -> 수립 -> object reqeust -> object response -> 받음
...
열번째 connection -> 수립 -> object reqeust -> object response -> 받음
하나의 object 마다마다 connection하고 끊고를 반복.. -
persistent HTTP:
한 번에 TCP connection에 multiple objects를 받을 수 있음.
response time
RTT (Round Trip Time):
client(source)에서 server(destination)까지 request가 갔다가 response가 돌아오는 데까지 걸린 시간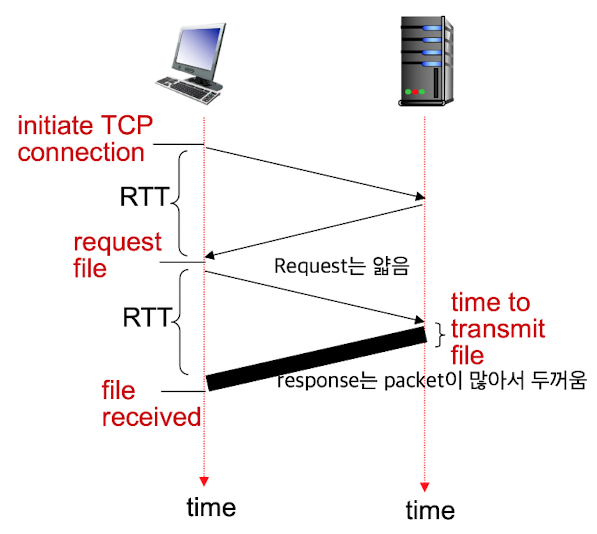 File size, RTT가 일정하다고 가정했을 때, m개의 object가 있을 때,
File size, RTT가 일정하다고 가정했을 때, m개의 object가 있을 때,Non-persistent HTTP response time:
( RTT(connection) + RTT + file transmission time ) x m
= (2RTT + file transmission) x mpersistent HTTP response time:
RTT(connection) + (RTT + file transmission time) x m
- 최근의 HTTP protocol방식은 persistent HTTP를 따른다.
HTTP request message
-
HTTP requeset message는
request line,header lines으로 구성되고, ASCII로 되어 있다.

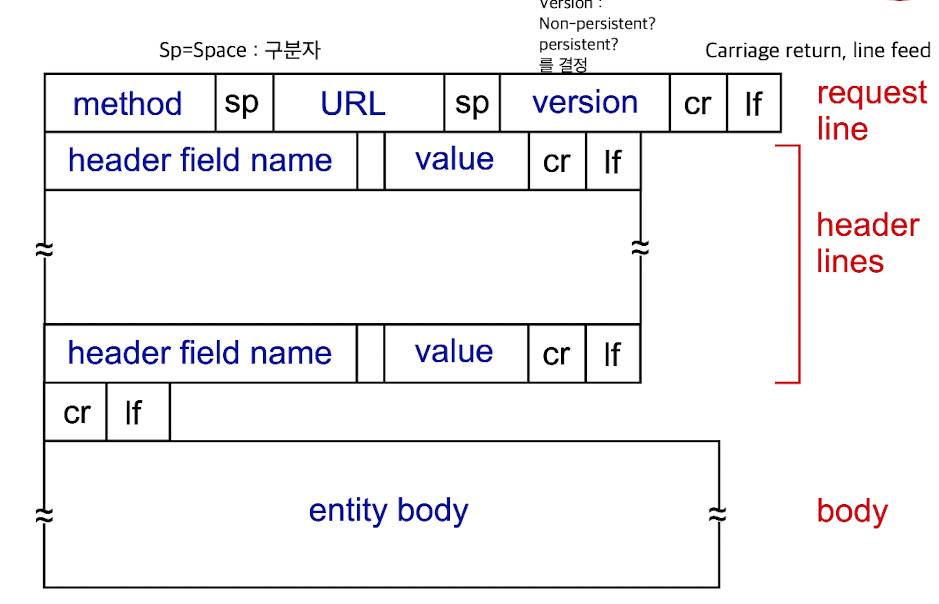
request line:
request line이 핵심이다.
header lines은 안보내도 상관없는 optional한 부분임.
'curl' 이라는 program을 사용해서 domain만 치면 해당 web page를 통째로 받아올 수 있다.
ASCII이기 때문에 한 line의 구분자는 \r(carriage return char)\n(line-feed char)이다.- method : GET? POST?
version : HTTP/version ➡️ Non-persistent? persistent? 결정
- method : GET? POST?
header lines:
Uploading form input (POST vs GET)
-
form: 입력창 -
기존의 원래 HTTP protocol은 request로 web page에 대한 file을 달라고 request하여
해당하는 reference된 object를 보여주는 것인데,
form에 있는 data는 내가 일방적으로 server에게 보내주는 data이다.
= 기존의 request와는 다른 방식
➡️ 이러한 input form을 upload하는 2가지 방법이 존재한다.POST method:
input form에 대한 data(key, value 형태의 json)를 entity body에 넣어서 server에 전달한다.GET method(= URL method):
input form에 대한 data를 entity body에 쓰지 않고, URL에 붙여서 넣는다.
따라서 URL에 붙일 수 있는 syntax를 알아야 함.
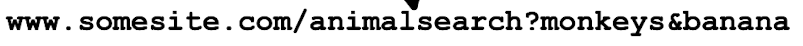
-
예전에는 별도의 parsing이 없기 때문에 더 빠른 GET method를 선호했지만,
URL에서 data가 보이기 때문에 security가 약함.
따라서 최근에는 POST method를 더 선호함.
Method types
-
HTTP/1.0:- GET
- POST
- HEAD
-
HTTP/1.1:- GET
- POST
- HEAD
- PUT :
POST와 GET을 mix.
URL을 통해서 어떠한 data를 수정할지 parameter를 받는다.
그리고 수정할 데이터 값을 Entity Body값을 통해서 받는다.
(uploads file in entity body to path specified in URL field)
client에서 file을 upload할 때 사용. - DELETE :
deletes file specified in the URL field.
HTTP response message
-
status line,header lines:
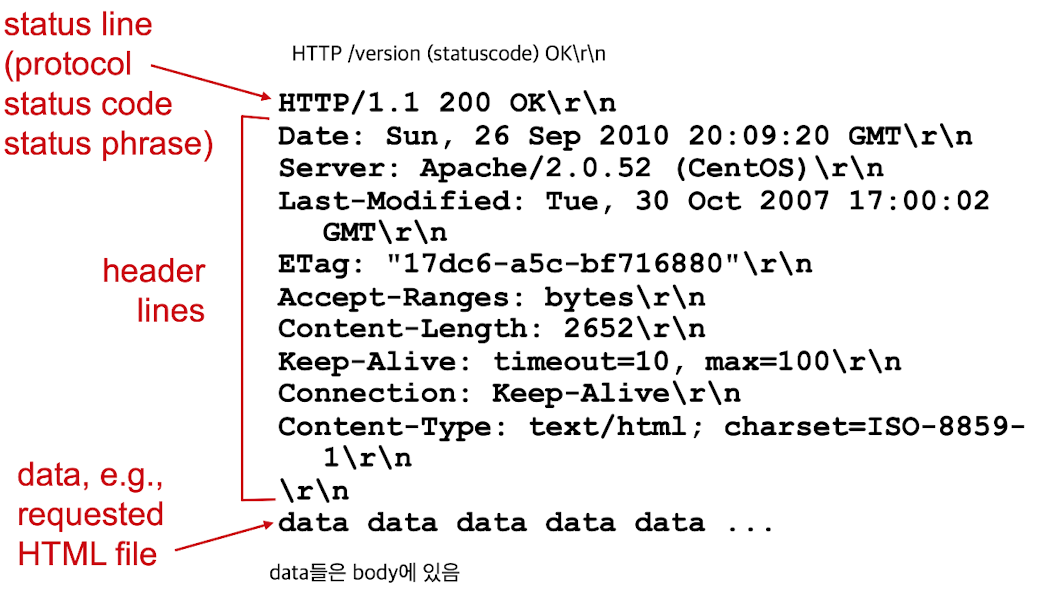
status code:- 200 : OK
- 301 : Moved Permanently
server는 살아있는데, web page의 directory 구조가 바꼈는데, 요청을 예전의 object를 요청했을 때, - 400 : Bad Request
- 404 : Not Found (File을 찾을 수 없습니다.)
- 505 : HTTP Version Not Supported
-
data, requested HTML file:
response로 object(file = 동영상, 이미지, ...)를 받아야 함.
이러한 data들은 body에 들어가 있다.
- curl [domain] :
object들을 parsing하기 전인 HTML을 받음.
User-server state : cookies
-
login을 하지 않은 상태를 가정하여, Server는 기본적으로 stateless하다.
내가 10번을 request하면, 내가 누군지 모른다.
10명의 서로 다른 사람들로 인식하여 home page를 똑같이 보여주는게 원래 web server의 역할이다.
기존의 web protocol을 사용하면서 stateful한 상태로 유지할 수 없을까? 하여 나온게 cookie이다. -
cookie는 우리가 login을 하지 않고도, 내가 누구인지, 뭘 했는지에 대한 정보를 남기는 것이다. -
cookie는 4개의 component가 있다.
cookie header line of HTTP response message:
왜 response message에 cookie header line이 포함되는지? (나중에..)cookie header line of HTTP request message:cookie file kept on user's host, mananged by user's browser:
내가 무엇을 했는지?는 server DB에 저장하면 되지만,
내가 누구인지?는 어떻게 접속했는지에 따라 IP address가 계속 달라지기 때문에 login을 하지 않고서는 알 수 없다.
따라서 누구인지?에 대한 정보를 저장해야 하는데, 그것이 cookie이다.
cookie는 file로 우리의 PC에 저장이 된다.
결국 이러한 file을 browser에서 관리한다.back-end DB at Web site:
cookie에 등록된 해당 user가 무엇을 했었는지를 back-end DB에 저장.
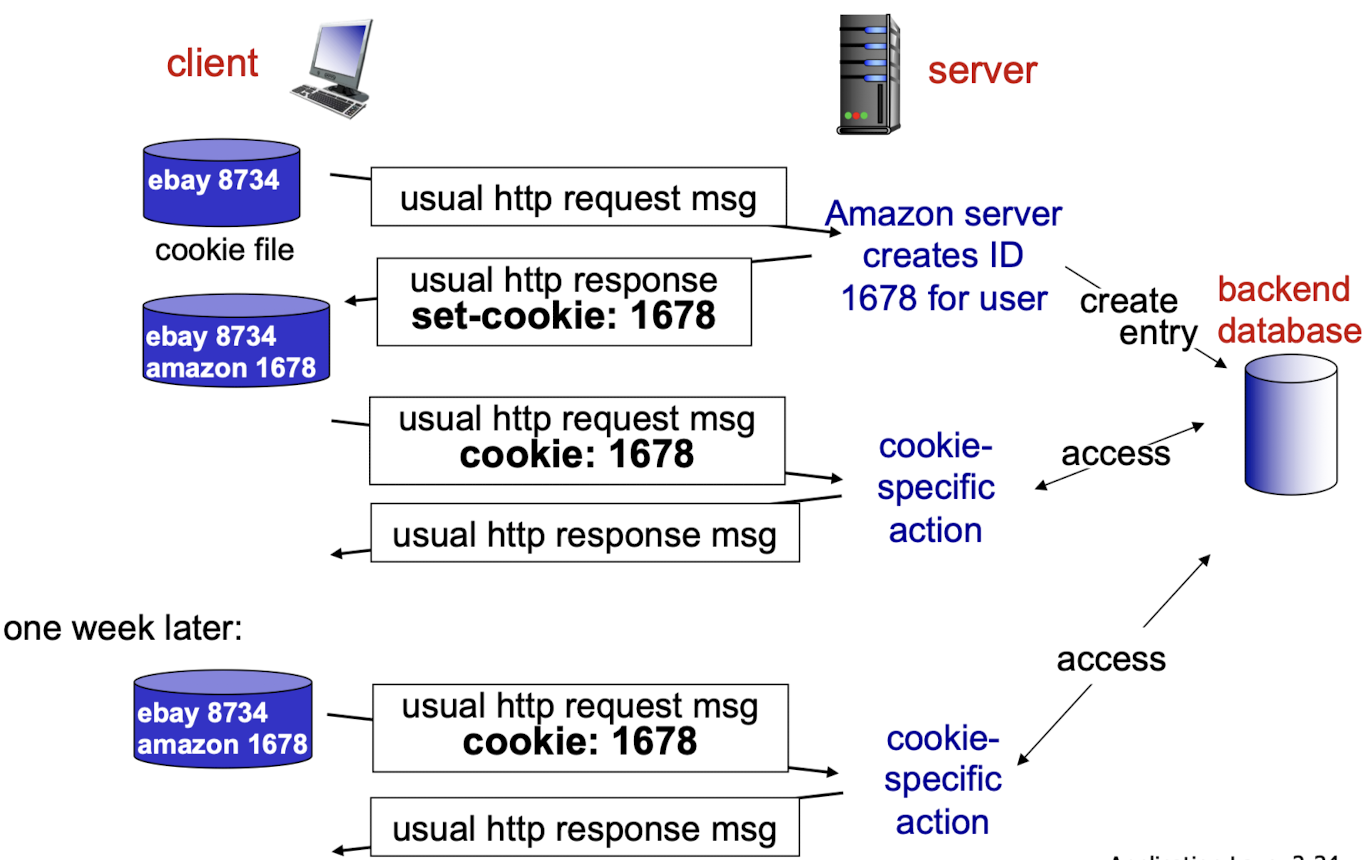
Cookie 작동 원리
-
client side에 있는 cookie file은 HDD에 해당하는 ID값이 저장되어 있음.
우리는 login을 하지 않았기 때문에 ID값 우리를 구별하기 위한 Identifier임. -
amazon server에 처음 접속했다고 가정.
일반적인 HTTP request message를 보냄.
amazon server에서는 그 user를 위한 unique한 ID(1678)를 생성하여 Back-end DB에 entry를 만든다.
그리고나서 amazon server는 response message의 cookie header line에 set-cookie:1678이라는 정보 넣어 보낸다.
client는 login을 하지 않고도 다음 request message에 cookie : 1678을 넣어 보내기 때문에
server는 client에 대한 정보를 계속해서 Back-end DB에 저장한다.
그리고나서 1주일 뒤 다시 접속하면, 해당하는 site에 대한 cookie 정보가 있다면 그 cookie ID(1678)를 갖고 request한다.
➡️ 결국 cookie는 server가 client의 state를 유지할 수 있게 해주는 기능이다.
stateless인 web protocol을 stateful하게 만들어 준다.
-
언뜻 보면, Cookie는 privacy 문제가 있을 것 같다.
하지만 cookie에는 민감한 개인 정보는 저장이 되지 않는다.
그리고 file이 오가는 것이 아니라 server에 entry만 생성되는 것이기 때문에 지금까지 보안상 문제는 없었다.
Web caches
-
cache:
CPU 외부에 있는 memory에 data를 접근하려면 속도가 느리기 때문에
해당 Process에서 자주 사용하는 data를 cache에 저장하여 사용한다.
cache에서 찾으면 "hit", 없으면 "miss"라고 한다.
cache 실행 시간 = hit rate + miss rate
이러한 cache 기능을 web에서도 사용한다. -
Web cache:
우리 학교의 많은 학생들이 네이버에 동시에 접속한다.
내가 request를 해서 갔다 오는 response와 옆의 학생이 request해서 갔다 오는 response와 같다.
학교에 있는 main router 측면에서 보면, 이는 매우 비효율적이다.
따라서 망 내부에proxy server가 있다.
proxy server에는 가장 최근에 client가 접속한 site들의 data를 갖고 있다.
client A가 naver를 요청했다.
proxy server에 naver가 있는지 확인한다.
없으면? proxy server가 대신하여 origin server에 request하고, HTTP response를 갖고 있다.
그리고나서 client B가 naver에 요청했다.
proxy server에서 방금 naver에 대한 정보를 main server로부터 받았기 때문에 외부로 나갈 필요 없이
proxy server에서 naver를 client B에게 response한다.
update를 자주 하지 않는 site를 request하면 좋지 않다.
만약 update를 자주 하는 site라면, main server의 site와 비교하여 proxy server의 site는 outdate.
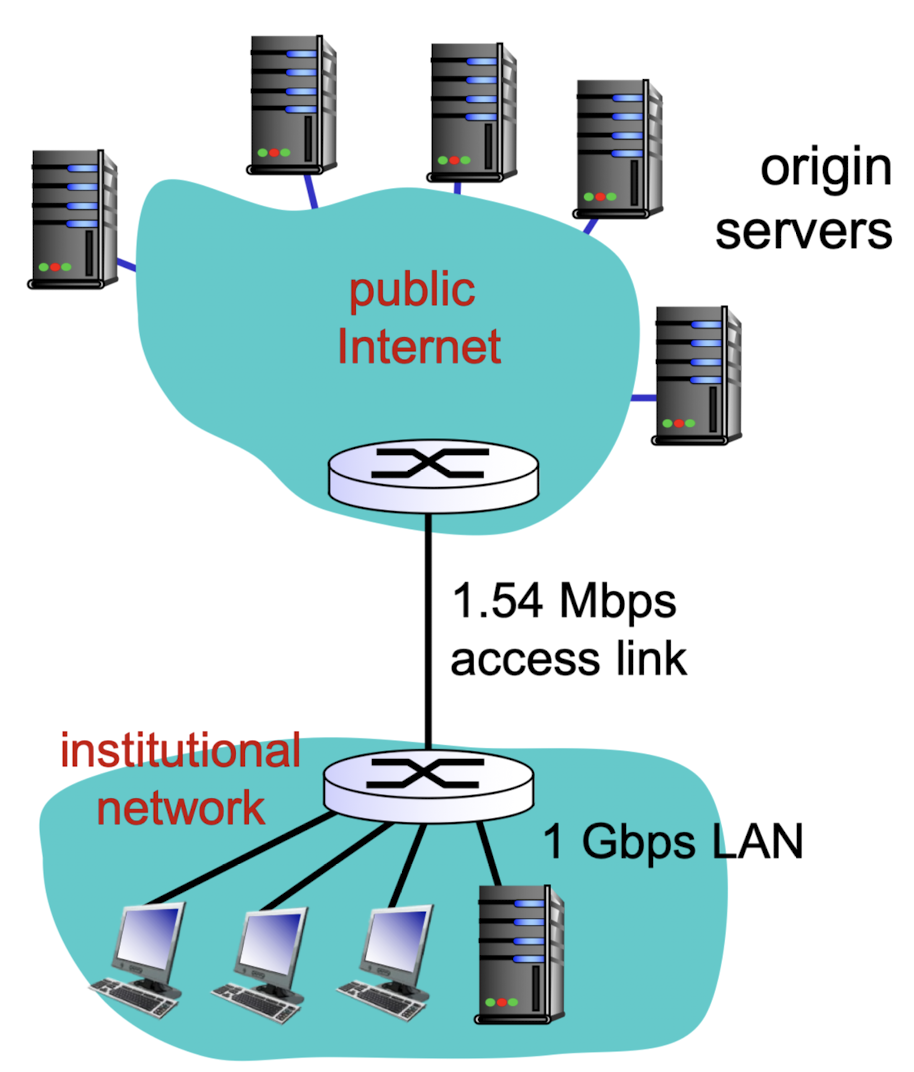
why web cache?:
나를 대신해서 data를 요청하고 data를 받아주는 proxy server를 이용하여,
access link의 traffic이 줄어들어,
client request들에 대한 response time을 줄여주기 위해 사용한다.
conditional GET
-
hit rate가 높다면,
돈을 늘리지 않고(access link를 늘리지 않고도) local에 web cache를 두는 것이 좋다. -
hit rate가 낮다면, web cache의 성능이 굉장히 낮다.
web cache의 가장 큰 문제:
cache hit가 얼마나 잘 되는지에 따라 성능이 매우 달라진다.
그래서 우리의 browser에서 Web cache의 freshness를 보장하기 위한 방법으로conditional GET을 사용한다. -
conditional GET을 쓰면, 주기적으로 해당 site가 update되었는지 아닌지 확인할 수 있다.
request message의 header line에 다음과 같이 넣는다.
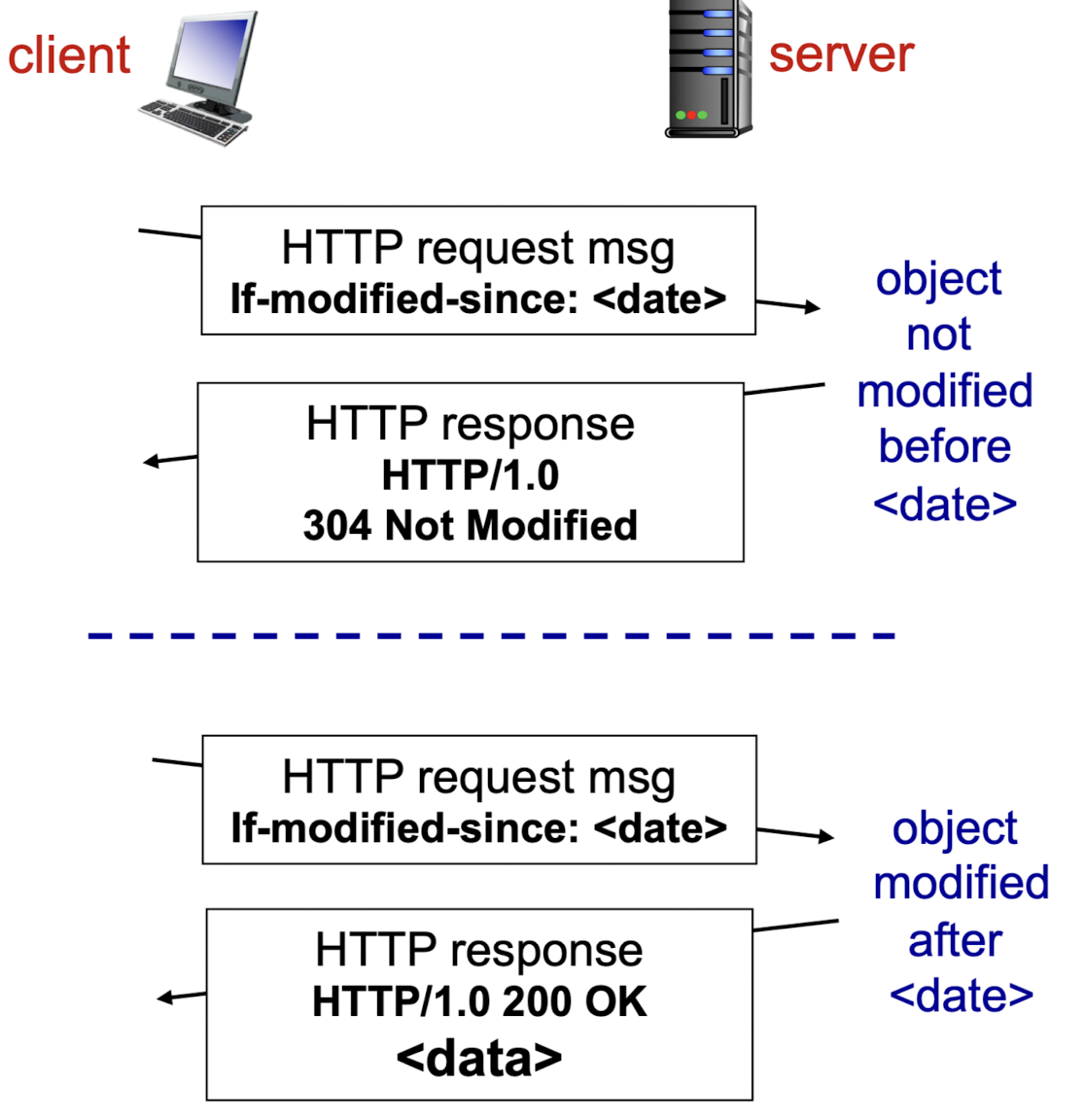
우리가 요청하면, 1차적으로 browser에서 검색을 하거나, proxy server에서 갖고 있는 날짜가 있을 것이다.
그 날짜 이후로 update된게 있는지 conditional GET을 server로 보낸다.
만약 object가 update된게 없다면, 304 Not Modified라는 response message만 보낸다.
만약에 browser라면 가장 최근의 object를 보여준다.
proxy server라면 자신이 갖고 있는 object를 보여준다.
만약 해당 날짜 이후로 update가 되었다면, 변경된 data들을 response한다.
3. electronic mail
Email을 하기 위한 3가지 구성요소:User Agent:
email을 보고, 쓰는 program.Mail servers:
email은 보내고, 받는 쪽의 mail server가 다 있어야 한다.SMTP(Simple Mail Transfer Protocol):
mail server에는 message queue가 있다.
송신 server의 message queue에 보내려는 mail을 담는다.
수신 server에는 mail box가 있는데, 우리의 mail box에 바로 오는 것이 아니라 mail server에서 mail을 나의 mail box에 보내준다.
어떨 때는 mail이 빨리 가고, 어떨 때는 늦게 간다.
-> 원인 1 : network에서의 delay
-> 원인 2 : mail server가 그 시간대에 보내야 되는 mail이 많다면, message queue에서 기다리는 시간이 오래 걸리는 것임
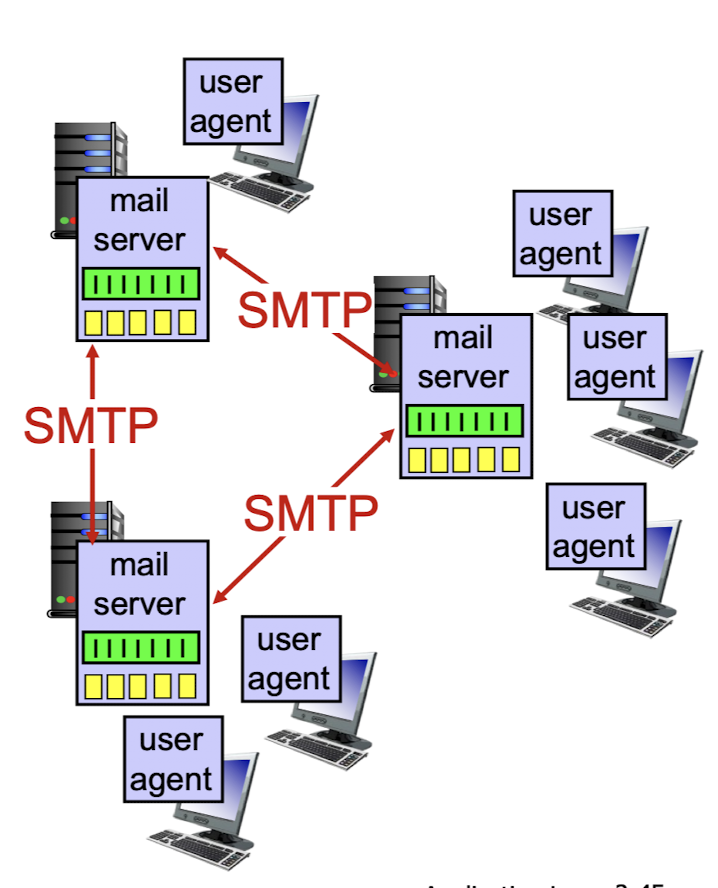
Web과 가장 큰 차이점 :
Web은 명확한 client와 server가 있었다.
client가 server에 data를 direct로 요청을 한다.
Mail의 SMTP도 client-server model이지만,
Web이랑 가장 큰 차이점은 server들끼리 주고받는 것이다.
따라서 보내는 server가 client 역할을 하고, 받는 server가 server 역할을 한다.
Scenario : Alice sends msg to Bob
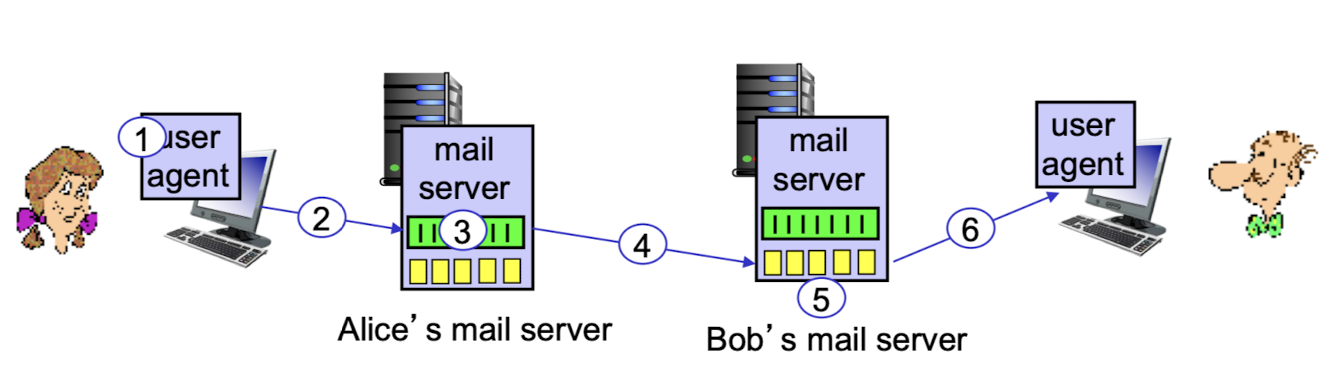
mail agent에서 mail을 쓰고, 보내기 버튼 누름.
바로 보내지지 않고, 해당 mail이 송신 mail server의 message queue에 대기.
message queue가 비어있다면, 기다리지 않고 바로 보내짐.
송신 mail server와 수신 mail server 간의 SMTP 통신이 동작되면서,
송신 mail server가 client가 되고, 수신 mail server가 server가 된다.
수신자는 User agent를 통해서 내 mail box에 있는 mail을 확인한다.
SMTP
-
SMTP는 기본적으로 persistent connection을 유지한다.
message에는 Header(제목, 수신자, 첨부) & Body(본문)가 있다.
SMTP는 CRLF.CRLF로 end of message가 결정된다. -
comparison with HTTP:- HTTP :
- client 입장에서는 server에서 가지고 와야 한다. -> pull
- 각각의 object들이 독립적으로 처리된다.
Response msg 1개마다 각각의 response를 받고, 각각의 object file들이 있다.
- SMTP :
- email은 송신 mail server에서 수신 mail server로 mail을 밀어버린다. -> push
- SMTP는 하나의 response 안에 multiple objects
- HTTP :
Mail access protocol
Mail access protocol:
user agent와 mail server 간의 Protocol이다. (SMTP와는 다른 것임.)
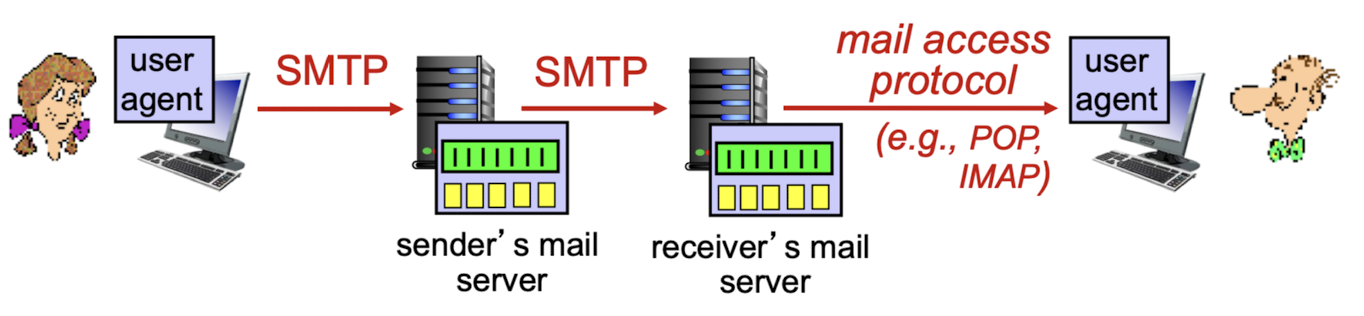
- POP3
- IMAP
- 최근에는 POP3, IMAP을 사용하지 않고 Web mail(HTTP)을 사용한다.
POP3, IMAP protocol의 필요성이 줄어듦
4. DNS (Domain Name System)
-
Domain Name은 하위 protocol과는 전혀 관계가 없다. (Application Layer에 있다.)
그냥 부가적인 service이다.
원래는 internet 안에서 각각의 host를 구분하는 기준은 IP address를 알아야 한다.
그런데 IP address를 기억하기 어렵기 때문에 사람들이 잘 알 수 있는 text 형태로 matching해주는 것이DNS(Domain Name System)이다. -
DNS는 일종의 Database이다.
Key, value가 있다.
Key : Domain name (Naver)
Value : IP address (Naver의 IP address) -
DNS는 단순히 query(domain name을 물음)를 해서 답(IP address)을 받는다.
DNS server에는 www.naver.com이 어떠한 IP address를 갖는지 알고 있다. -
DNS는 network 안쪽으로 들어가지 않고, edge에서 이루어지기 때문에 complexity가 복잡하지 않다.
-
Host aliasing:
Host마다 이름이 있다.
Domain이 1개이더라도 host는 여러개일 수 있다.
(host aliasing)@inu.ac.kr -
Load distribution:
부하를 분산시키기 위해서 똑같은 server를 복제하여 여러개 둠.
각 server들마다 개별적인 IP address가 있다.
main server들마다 개별적인 IP address가 있음.
main server에서는 해당하는 server의 IP address 여러 개를 갖고 있는데,
그 중 지역적으로 가장 가까운 server의 IP address를 준다.
지역적인 server 말고 traffic을 보며 상황에 따라 다른 IP address를 넘겨준다.
DNS : a distributed, hierarchical database
-
why not centrailze DNS?:
DNS server는 centralization되지 않고, 철저히 distribution되어 있다.
만약 DNS server가 하나만 있다면?
그 server가 잘못 된다면, 전세계 사람들은 internet을 사용할 수 없게 된다.
또한 전세계의 모든 traffic을 감당할 수도 없다.
그리고 지역적으로 가까이 있는 client들은 빨리 받고, 멀리 있으면 여러 hop을 거쳐서 service를 받기 때문에 늦게 받는다.
만약 DNS server를 유지, 보수해야 해서 잠시 중단시킨다면 전세계 모두가 중단된다. -
hierarchical DB:
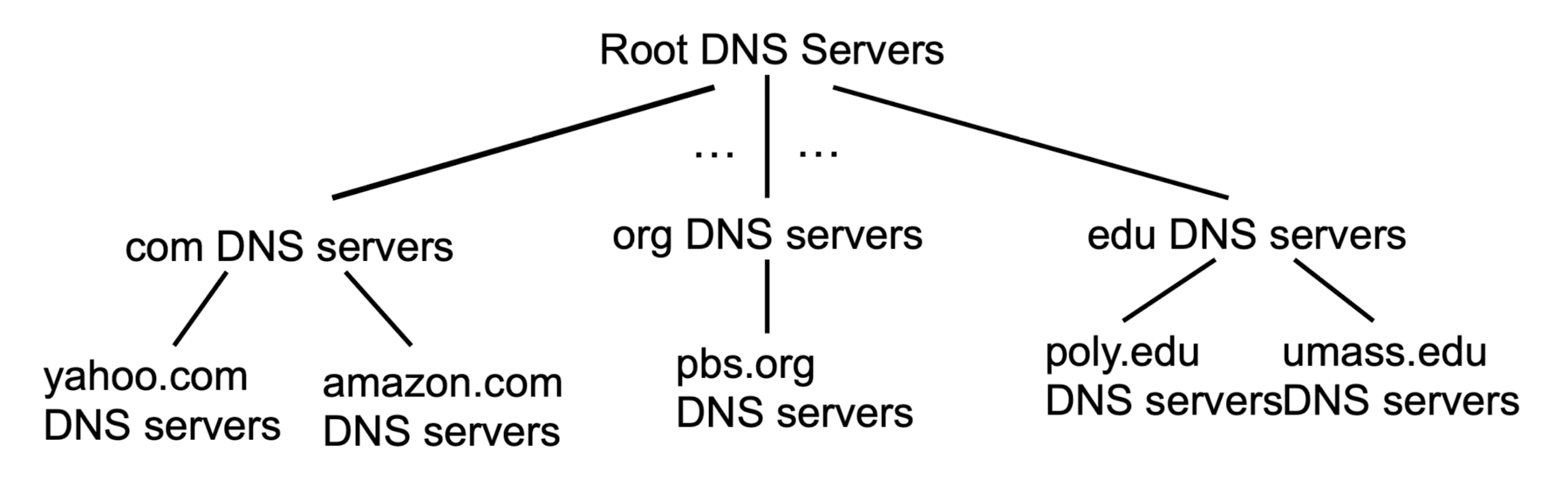
DNS가 모두 대등한 관계라면 관리하기 힘들다.
DNS server를 계층화하여 관리가 쉽고, 전파가 빠르게 만든다.
Root DNS servr는 모든 것을 아는 것이 아니라,
자기한테 붙어있는 하위 1계층의 DNS server들에 대해서만 알고 있다.
모든 DNS server는 이러하다.
TLD server
TLD(Top-Level Domain) servers:
TLD server는 .com, .org, .net, .edu 등과 Top-level country domain(uk, fr, kr, jp 등)을 관리한다.
TLD server는 name server들을 관리한다.
authouritative servers
authoritative DNS servers :각각의 기관들은 자신의 authoritative DNS server가 있다.
해당 DNS server는 Name server에 대한 기능을 갖고 있다.
Local DNS name server
Local DNS name server:
ISP 업체들이 관리하는 name server.
IP address setting할 때, 적는 default DNS server..
DNS name resolution example
resolution:
내가 어떻게 Domain에 대한 IP address를 획득할 수 있는가?
host는 gaia.cs.umass.edu에 접속하고 싶다.
gaia.cs.umass.edu를 치거나, 해당 domain이 연결된 link를 클릭한다.
하지만 바로 접속하지 못한다.
그래서 host는 gaia.cs.umass.edu의 IP address를 획득해야 한다.
방법 2가지.iterated query:
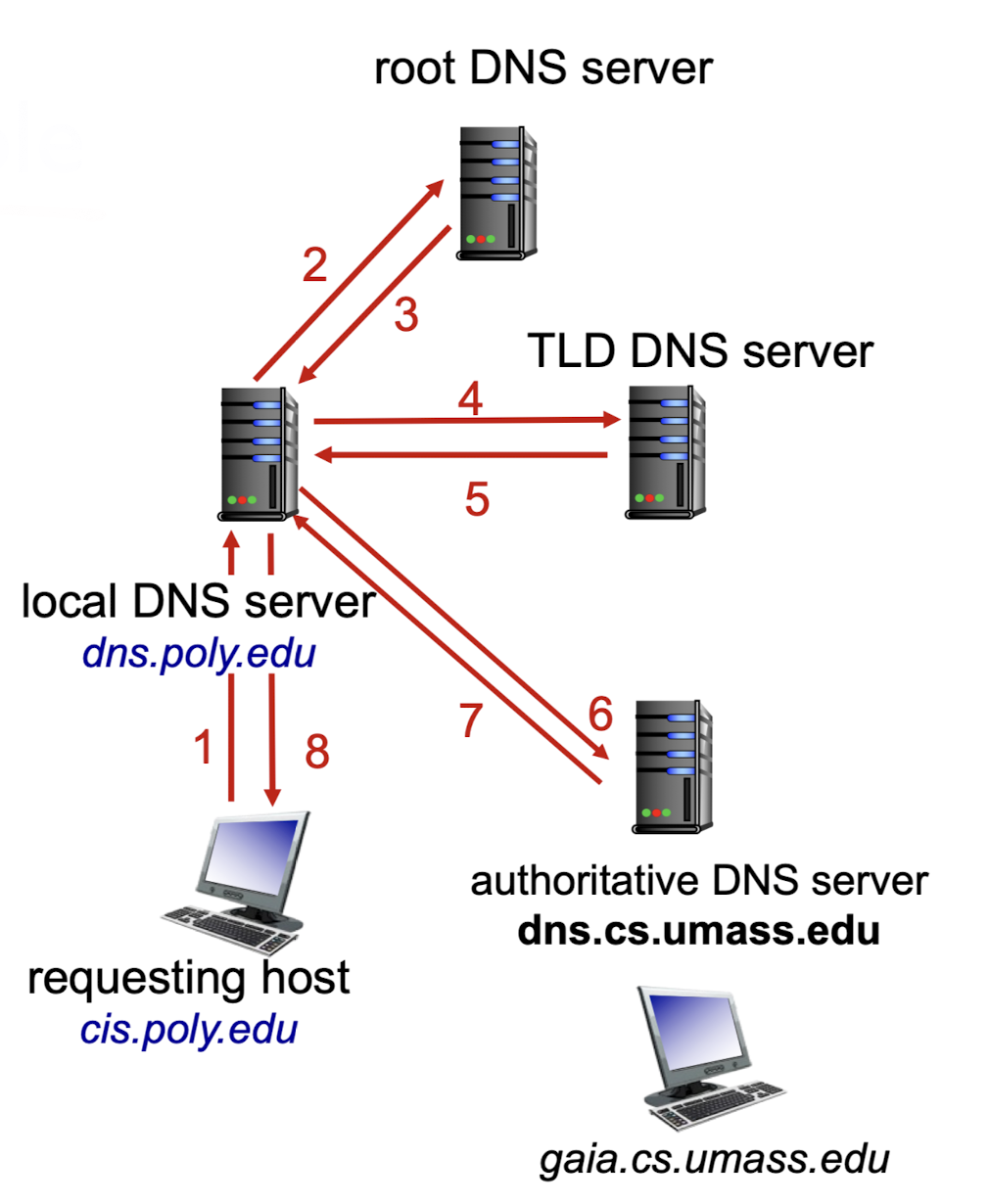 host의 local DNS server를 local DNS server라고 하고,
host의 local DNS server를 local DNS server라고 하고,
상대방의 local DNS server를 authoritative server라고 함.
local DNS server에 destination의 IP address를 물어봄.
알면? 바로 넘겨주고 종료.
모르면? local DNS server의 상위 계층인 root DNS server에 물어봄.
모르면? 그 밑에 있는 TLD(Top-level Domain) DNS server의 주소를 넘겨줌.
local DNS server는 받은 TLD DNS server의 주소에 물어봄.
TLD DNS server는 모르지만, authoritative DNS server의 IP address를 넘겨줌.
local DNS server는 authoritative DNS server에 물어봄.
authoritative DNS server는 destination IP address를 알기 때문에 local DNS server에 넘겨줌.
recursive query:
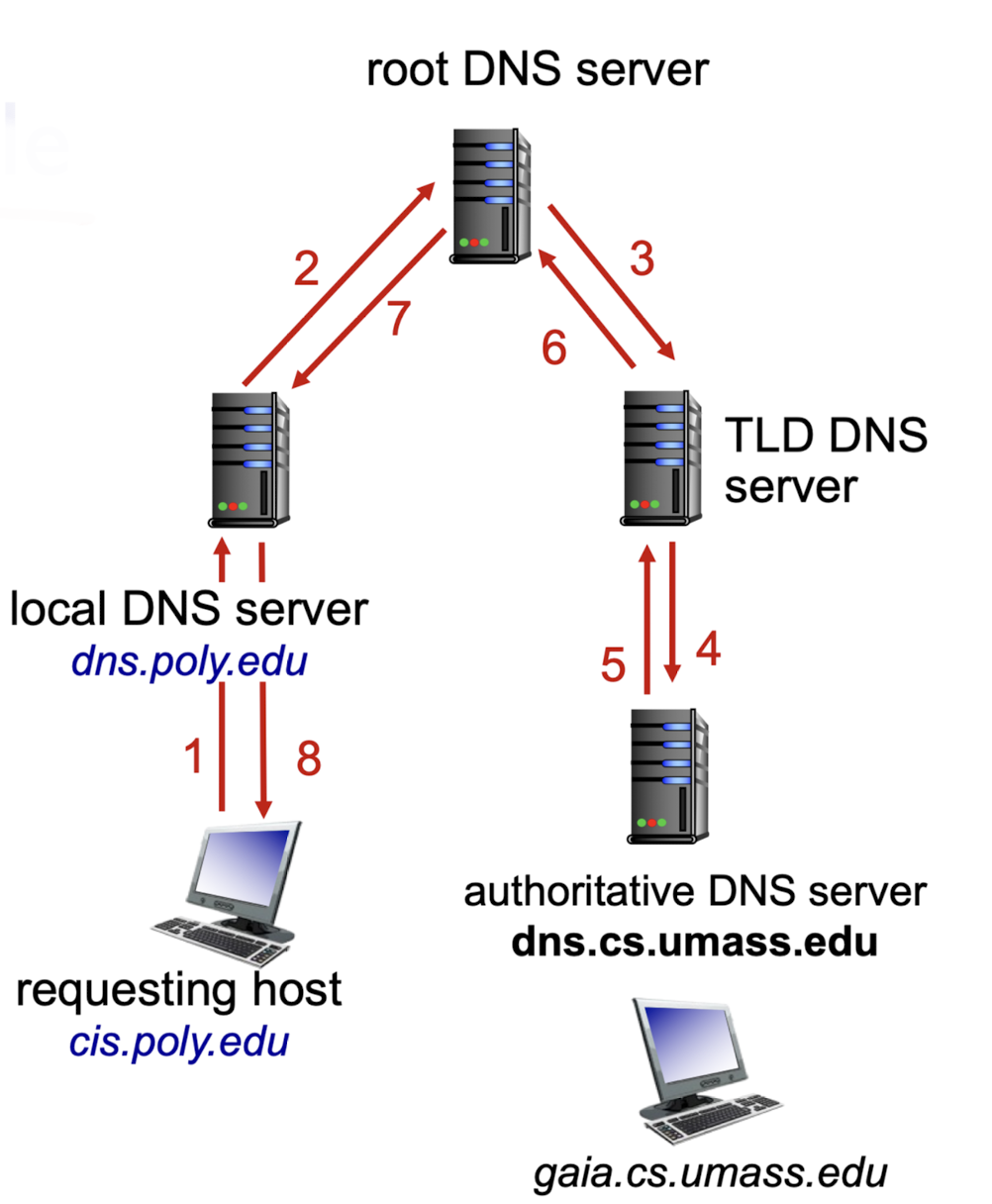
누군가 알겠지? 하며 상위, 하위 server에 계속해서 toss한다.
local DNS server에서 모르면? root.
root DNS server 에서 모르면? TLD DNS server.
TLD DNS server에서 모르면? authoritative DNS server.
찾았으면? 역순으로 destination의 IP address를 넘겨줌.
recursive 방식이 더욱 효율적이므로 recursive 방식이 사용된다.
DNS : caching, update records
-
local DNS server는 한 번 찾은 address를 자신의 DNS table에 저장한다. (DNS server는 Database이기 때문)
하지만 어느정도 시간까지만 저장함.
local DNS(=name) server는 memory overflow의 문제,
또한 보안 문제로 server IP address가 계속 바뀌기도 한다.
따라서 계속 저장하는 DB가 아니라, 어느 정도 시간만 record를 저장하기 때문에DNS caching이라고 한다. -
각각의 record에는
TTL(Time To Live)이 있다.
TTL이 expire될 때까지만 저장해야 한다.
보통 이러한 cache형 DB는 각 record에 TTL이 있다.
이러한 temporary한 data들을 memory가 아니라 HDD에 저장했다가, 시간 지나면 자동으로 삭제되니까 효율적으로 이용이 가능하다.
이 mechanism은 IETF standard로 되어 있다.
DNS protocol, messages
query and reply message, both with same message format

identification:
www.naver.com enter을 할 때, DNS server로 날아간다.
이때, random number 16-bits identifier가 만들어져서 넘어간다.
recursive 방식에서 packet 자체에 어떤 query에 대한 응답인지 알아야 하기 때문에
query의 ID와 reply의 ID가 같아야 한다.
따라서 ID가 매우 중요하다.flags:
recursive 방식이면, recursion available flag가 set되어야 한다.questions:
query인지? reply인지?
query에는 domain name이 들어간다.RR(Resource Record):
question 몇 개인지? answer 몇 개인지? -> multiple하게 요청할 수도 있다.answer:
destination의 IP address가 들어가 있다.
Attacking DNS
-
DDoS attack -
Redirect attack:
name server를 공격하여, 공격자가 만들어 놓은 다른 IP address로 바꿔 놓는다.
다른 사이트로 유도.
5. video streaming and content distribution networks
Video Streaming and CDNs
-
전체 internet bandwidth 중에서 Netfilx, Youtube이 50% 넘게 차지함.
어떻게 이렇게 많은 user들에게 OTT service를 제공할 수 있을까?
(single server로는 못하고, traffic, 거리에 따라 속도가 다름, ..
또한 user마다 접속 환경이 다양함 = edge에서 접속하는 host들의 bandwidth가 다 다르다.
throughput은 bandwidth가 가장 작은 곳으로 수렴하는데, bandwidth가 작은 host들에게 어떻게 service를 제공할 것인지?)
➡️ solution : distributed(multi server), application-level infrastructure (service를 network level이 아니라, 상위로 띄움) -
한 frame마다마다를 보내면 사이즈가 크기 때문에 encode해야 한다.
encode 방법 2가지- spatial (within image) :
한 frame 내에서 유사한 pixel들의 값을 합쳐버림.
한 frame 내에 색의 변화가 없을 때, 성능이 좋다.
ex: 밤하늘을 찍으면, 압축이 더 많이 된다. 단풍나무를 찍으면, 압축이 거의 안된다. - temporal (from one image to next) :
앞, 뒤 frame의 변화에 따라서 압축.
frame 변화 속도가 33ms 정도 되는데,
정적인 상황에서는 frame 간의 변화가 거의 없다.
동적인 상황에서는 frame 간의 변화가 크다.
앞, 뒤 frame 변화가 있는 부분에 대해서만 frame 변화가 얼마나 있는지 기재.
변화가 없으면 앞의 frame을 그대로 써도 된다.
➡️ spatial, temporal encoding 기법을 사용해서 MPEG라는 동영상 압축 기능을 이용한다.
- spatial (within image) :
Streaming stored video
- server에 저장된 video를 어떻게 streaming할 수 있는가?
client가 server에 video를 요청.
예전에는 전용의 Player를 사용했지만, 요즘에는 Web을 이용한다.
Web에서 사용하는 protocol이DASH이다.
Streaming multimedia : DASH
DASH(Dynamic, Adaptive Streaming over HTTP):
Stored video를 자유롭게 보기 위해 사용하는 Web protocol.- server :
- video를 multiple chunk(듬성듬성 나눈다)
- chunk들을 다른 rate로 encoding(고객 만족도를 위해 network 상태가 좋으면 최고의 화질로 보여주기 위해).
encoding rate가 높을수록 화질은 떨어진다.
encoding rate가 작을수록 용량은 커지지만 화질은 좋다. - manifest file : 다른 chunk들에 대한 URL을 제공한다 (chunk는 각각 서로 다른 object -> 서로 다른 URL)
- client :
-
주기적으로 bandwidth를 측정한다.
작은 packet이 갔다 오는 Round Trip Time을 알 수 있다.(보낸 packet size와 시간을 아니까 bandwidth를 알 수 있다.)
-
bandwidth가 좋으면? encoding을 적게 된 것을 받을 수 있고,
그렇지 않으면? encoding rate가 높은 것을 받을 수 있다. -
network는 실시간으로 달라지기 때문에 한 번에 한 chunk씩 요청한다.
이는 받고 있는 상태에서 back channel로 다른 채널이 돌고 있기 때문에 overhead가 그렇게 높지 않다.
-
- server :
client가 일을 더 많이 한다.
Client가 bandwidth를 계속해서 check하여 available한 bandwidth에 맞는 URL server에 request를 하기 때문에 "intelligent" at client 라고 한다.
Buffer starvation : buffer가 완전히 비어있다.
Buffer overflow : buffer가 꽉 참.
이러한 것들이 발생하지 않도록 request를 한다.
- server와 client 간의 효율적인 protocol이었다.
network architecture 측면에서 보면, client들이 한 server로 집중되어서 요청하면 문제가 될 수 있다.
그래서 CDN(Contest Distribution Networks)가 나옴.
CDN(Content Distribution Networks)
-
DASH는 streaming multimedia protocol이었고,
network architecture 자체를 다르게 바꿀 필요가 있다. -
challenge : 수백 수천 명의 사용자에게 동시에 stream content를 제공한 것인가?
- option 1 : single, large "mega-server"
- 문제점 :
single point of failure.
해당 server가 잘못되면, 모든 service가 종료된다.
또한 server가 한 개이기 때문에, 그 server 주변으로 congestion이 발생한다.
server가 멀리 있으면, 큰 용량을 거쳐 가는 router마다 모두 감당해야 한다.
- 문제점 :
- option 2 : video들의 multiple copies를 물리적으로 distributed sites에 저장한다. (=CDN)
- option 1 : single, large "mega-server"
-
CDN(Content Distribution Networks):
distributed한 server들을 client side로 multiple copies를 만들어 보낸다.
2가지 type이 있다.
현재 1., 2. 중에 뭐가 좋은지는 따질 수 없다.Enter deep: push CDN servers deep into many access networks.- access network 안으로 CDN server들을 넣는 방법.
access network 안에 있으니까 client들에게 가까움.
cloud 기반의 CDN 전문 업체에서 함.
- access network 안으로 CDN server들을 넣는 방법.
Bring home: smaller number of larger clusters in POPs near access networks- POPs라고 하는 큰 cluster들의 작은 수를 access network 근처에 넣는다. core쪽에 있음.
-
Netflix도 CDNs을 쓴다.
Netflix의 모든 service는 AWS에서 이루어진다. (AWS에서 location을 설정하는게 나오는데, 그게 CDN이다.)
똑같은 copy를 이곳저곳 저장한다.
분산된 server들도 엄밀히 말하면 개별적인 server라서 각각 IP address가 다름.
하지만 domain으로 접속하여 service를 받기 위해 main server도 필요하다.
처음에 main server에 요청한다.
main server는 traffic을 고려하여 나에게 manifest file(어느쪽에 있는 server의 URL에 접속하라는 정보)을 준다.
해당 server에서 영상을 받는다.
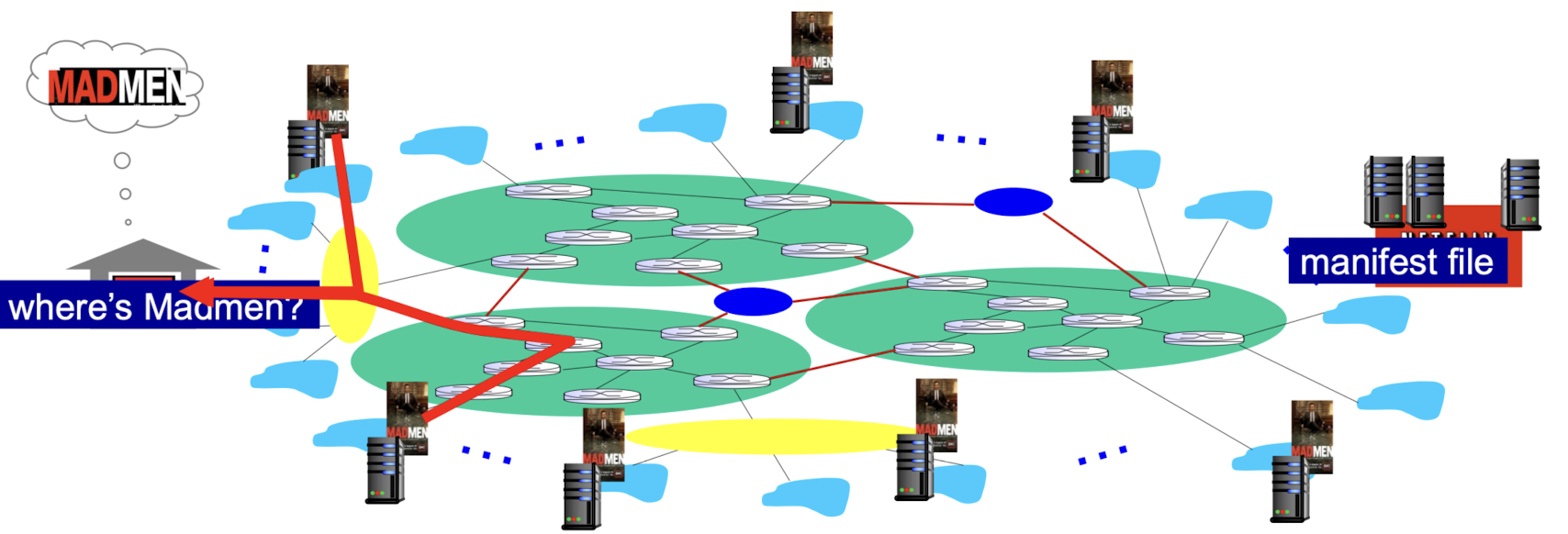
OTT(Over The Top):
CDNs은 edge쪽에서 application layer에서 이루어지는 network라서 "Over The Top"이라고 한다.
그래서 core에서의 문제는 전혀 없다.
Host-Host communication service를 제공한다.

- OTT challenges :
- congested internet을 잘 다룰 수 있겠는가?
- congestion이 존재했을 때, 시청자는 어떻게 해야 하는가?
- 어떤 CDN node(= 분산된 server)가 어떤 content를 갖고 있어야 하는가?
CDN node들은 나라별 특징을 고려해서 해당 지역에서 선호하는 content를 갖고 있음.
- OTT challenges :
자세한 CDN 동작원리:
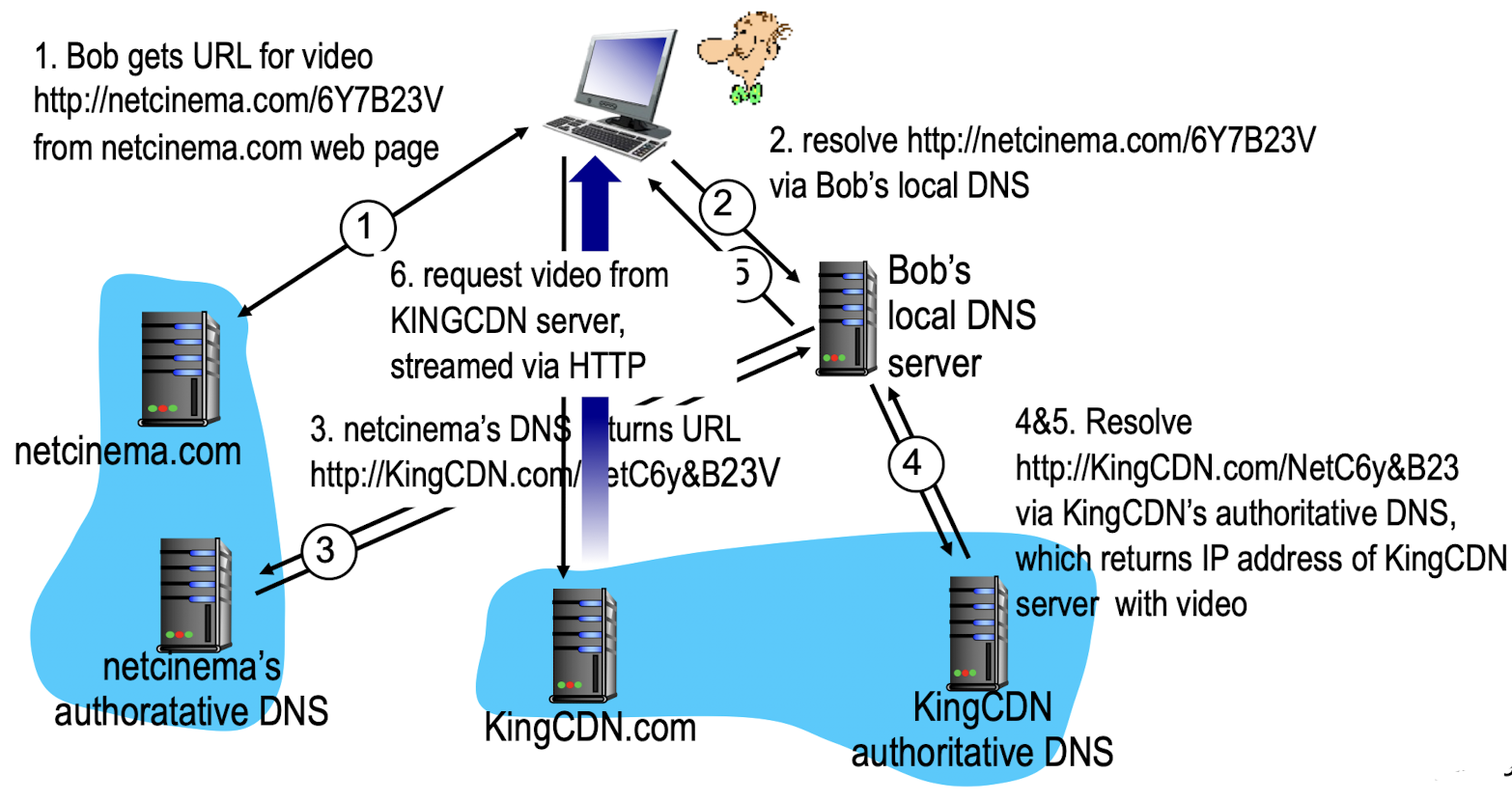
Bob이 video를 보고 싶음.
Bob은 main server로 video를 요청함.
main server는 해당 영화의 URL을 줌.
Bob은 DNS server에 해당 URL을 주고 나서,
그 URL(server)이 어디에 있는지에 대한 IP address를 받음.
Bob은 받은 server의 IP address를 이용하여 영화를 제공 받음.
➡️ main server가 모든 request에 대해서 CDN node의 IP를 모두 알려줄 수 없으니까
DNS service를 잘 활용해서 알려준다.Netflix:
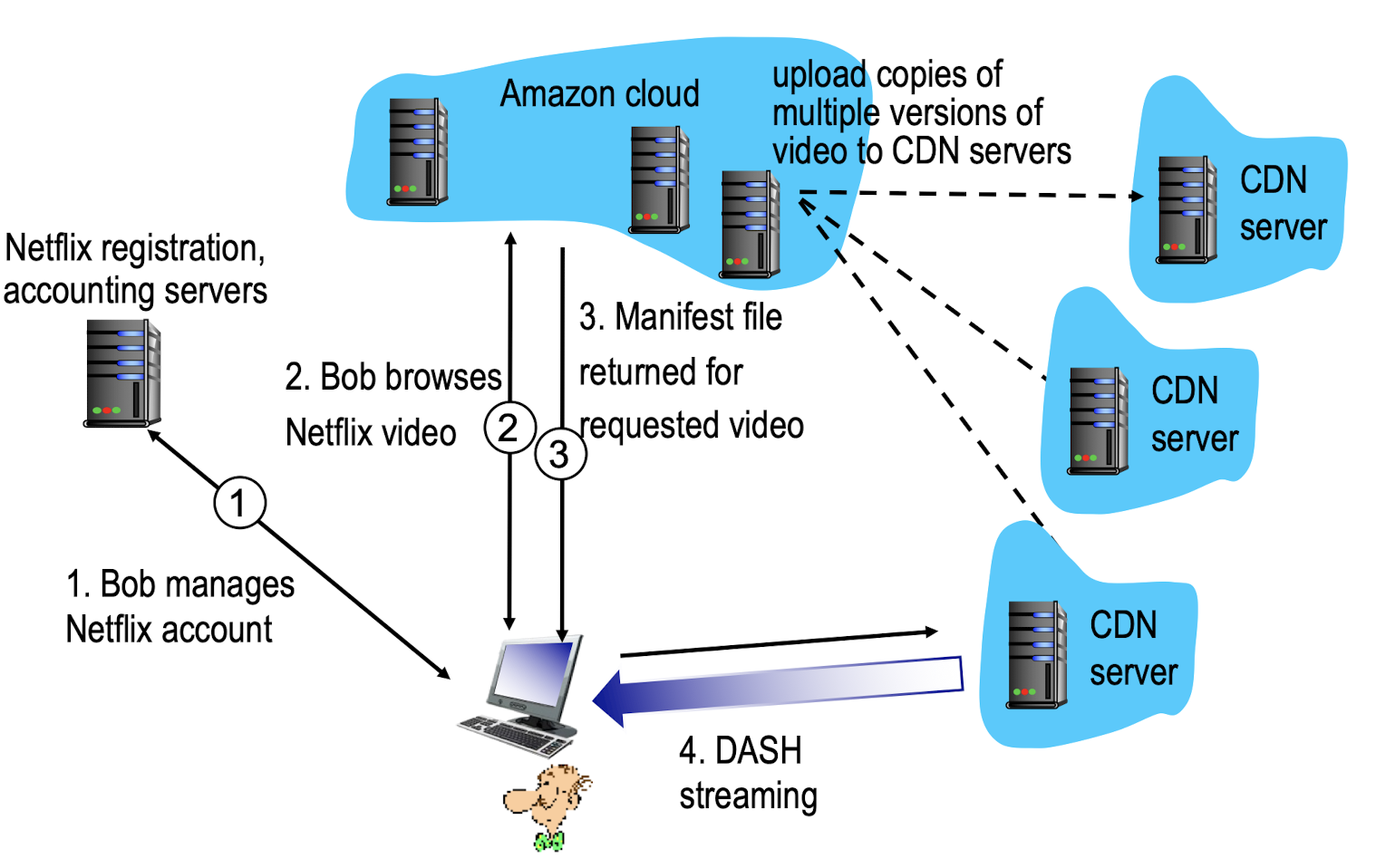
Netfilx는 AWS를 사용하기 때문에, DNS를 쓰지 않는다.
accounting server에 login을 하고 나면, netflix page가 나옴.
이제 영화를 Amazon cloud에 요청하면, 요청한 영화의 manifest file을 return한다.
응답 받은 manifest file을 이용해서 CDN server에 접속할 수 있게 된다.
amazon cloud를 사용하는 service는 내부에서 알아서 DNS server를 관리하고 있으니까 사용할 필요 없다.
따라서 분산적인 CDN server로 DASH streaming을 통해서 data를 가져온다.
6. socket programming with UDP and TCP
- Chapter 3. 끝나고 socket programming 공부
