3.1 Transport Layer
-
Application layer는 우리가 실제로 짤 수 있는 network program이다.
-
Internet protocol 5계층(application, tansport, network, link, physical layer)
- Network core에는 physical layer, link layer, network layer까지만 있다.
- Network edge에 transport layer, application layer가 있다.
transport layer는 application layer를 조력하는 역할을 하고, 드러나진 않는다.
-
Transport layer는 network edge에 있다.
end-to-end로 application message들을 어떻게 잘 보낼 수 있을까?를 처리한다.
transport layer data를 destination에서 decapsulation하기 때문에 end-to-end이다. -
각각의 layer마다 packet을 부르는 이름이 다르다.
- application layer : message
- transport layer : segment
- network layer : datagram
- link layer : frame
-
application에서 message를 transport를 보내주면, 작은 message와 큰 message가 있을 것이다.
transport layer에서는 자기가 관리할 수 있을만큼 자른다.
그래서 tranport layer에서는 자기가 관리할 수 있는 data의 단위를segment라고 한다.
자른 segment들을 network layer에 보낸다.
나중에 network layer에서는 잘라진 packet들은 이제 더이상 '순서'라는 것이 없어진다.
그래서 decapsulation할 때, application layer에서는 순서를 모르기 때문에
packet을 잘랐던 transport layer에서 다시 reassembling하여 application layer로 보내줘야 한다. -
Transport layer VS Network layer:
Network layer는 host들 간의 logical한 communication을 만들기 위해서 network core를 사용한다.
= IP 단위로 host-to-host로 전달한다.
transport layer는 process 간의 logical한 communication을 만든다.
= host 안의 여러 application process들 중에서 특정한 application process에 전달한다.
3.2 Multiplexing, Demultiplexing
-
transport, network, link, pyhsical layer는 모두 OS에 들어있다.
여러 개가 아니라 하나의 service가 도는 것이다.
여러 application에서는 이 하나의 service를 사용해야 하기 때문에 system call을 통해 사용한다. -
transport, network, link, pyhsical layer 가 하나의 service인데,
요청하는 application이 많으면 어떻게 해야 하는가? ➡️ multiplexing, demultiplexing (이 data는 어떤 application꺼인지?) -
Multiplexing (Mux):- data가 application에서 transport로 내려갈 때
= 여러 application process들이 하나의 service를 요청할 때
- data가 application에서 transport로 내려갈 때
-
Demultiplexing (Demux):- data가 왔을 때, tranposrt에서 application layer로 올라갈 때
= 하나의 service를 여러 application process들 중에 어디로 보낼 것인지 - data가 왔을 때, 어떤 process로 보낼 것인지 판별하기 위한 port number가 필요하다
- source port number
- destination port number
- data가 왔을 때, tranposrt에서 application layer로 올라갈 때
-
identifier 정리:
1. 어떤 host에서 보낸것인가? source IP address
2. 그 host의 어떤 application process에서 보낸 것인가? source port number
3. host는 어떤 destination으로 보낸 것인가? destination IP addres
4. destination의 어떤 application process으로 보낸 것인가? destination port number이렇게 host들은 적절한 application에서 받아들이기 위해 source IP address, source port number, destination IP address, destination port number를 갖고 Multiplexing을 사용한다.
-
만약 destination의 port number가 같으면, 어떻게 구분하는지?
source IP address와 source port number를 보면 된다.
UDP socket에다가 destination IP address, port number를 넣어야 한다.
3.3 TCP, UDP(간략)
- 어떤 application에서 어떤 service를 요구하느냐?
reliable? time sensitive?에 따라 TCP, UDP로 정한다. - 그것을 Transport layer에서 한다.
- 사실 transport layer의 service는 TCP, UDP가 전부이다.
TCP
-
connection-oriented reliable transport layer protocol,reliable,in-order delivery:
application에서 주는 message를 transport에서 자기가 관리할 수 있는 만큼 segment로 자른다고 했다.
TCP는 자른 segment들이 모두 오기를 기다렸다가 reassembling하여 보내준다. -
추가적으로
flow control,congestion control,connection setup이 필요하다.
source에서 destination까지 data를 보내기 전에,
circuit switching을 했던 것처럼
source의 TCP에서 destination의 TCP까지 end-to-end connection을 만들어놓는다.
그래서 TCP는 connection-oriented service라고 한다.
따라서 통신이 끝나면, connection을 끝내주는 작업도 필요하다.
이러한 작업들을 수행하기 위해 header에 정보들을 붙여야 한다.
따라서 TCP는 자체의 overhead가 커서 시간이 오래 걸린다. -
connection-oriented = TCP demux:
transport layer에서 어떤 application으로 줄 것인지? = 어떤 socket에 줄 것인지?
TCP는 연결을 한 번 해놓으면, 그 이후에는 data를 계속 주고 받을 수 있다.
TCP 연결을 하면, destination의 application과 통신할 수 있는 전용의 process가 생긴다.
TCP 연결수만큼 process가 생긴다.
destination(server)에서 data를 받았는데, 이것을 어느 application process에 보낼 것인가?
server의 port number는 같기 때문에, 어느 process에 보내야 할지는 모른다.
그렇기 때문에 해당 source process의 port number 뿐만 아니라 IP address까지 필요하다.TCP demux는 source IP address, source port number, dest IP address, dest port number 4개가 필요하다.
UDP (User Datagram Protocol)
-
connection-less transport layer protocol,less reliable:
no-frills extension of "best-effor" IP
군더더기 없이 최선을 다한다. 하지만 책임은 지지 않는다.
군더더기가 없다 = data를 받는 대로 application으로 올린다. 빠르다. ➡️ time sensitive service에 사용된다. -
Connectionless == UDP demux
process에서 9157이라는 자신의 port를 만듦.
destination은 6428- 보내는 쪽 :
source port number : 9157
destination port number : 6428 - 받는 쪽 :
source port number : 6428
destination port number : 9157
사실 source와 destination port number가 같아도 상관없다.
port number에 내부적으로 IP address도 같이 가는데, source와 destination의 IP address는 서로 다르기 때문에 구분이 된다.
UDP에서는 매번 data를 보낼 때마다 독립적이기 때문에 destination IP address는 host의 network layer에서 이미 확인한다.UDP demux는 source port number와 destination port number, 2개만 있으면 된다.
- 보내는 쪽 :
-
datagram을 network layer에서 packet을 부르는 용어인데, UDP는 tranport layer에 있다.
왜 그러면 datagram이라고 부르는가?
UDP는 transport layer에서 하는 일이 거의 없다는 의미이다.
server와 client 사이의 handshaking이 없이 host의 application에서 요청하면,
바로바로 해당하는 destination의 port number로 연결된다.
따라서 streaming multimedia application에 유리하다.
DNS에서 UDP를 사용한다. -
UDP를 사용하여 어떻게 reliable한 transfer를 하는가?
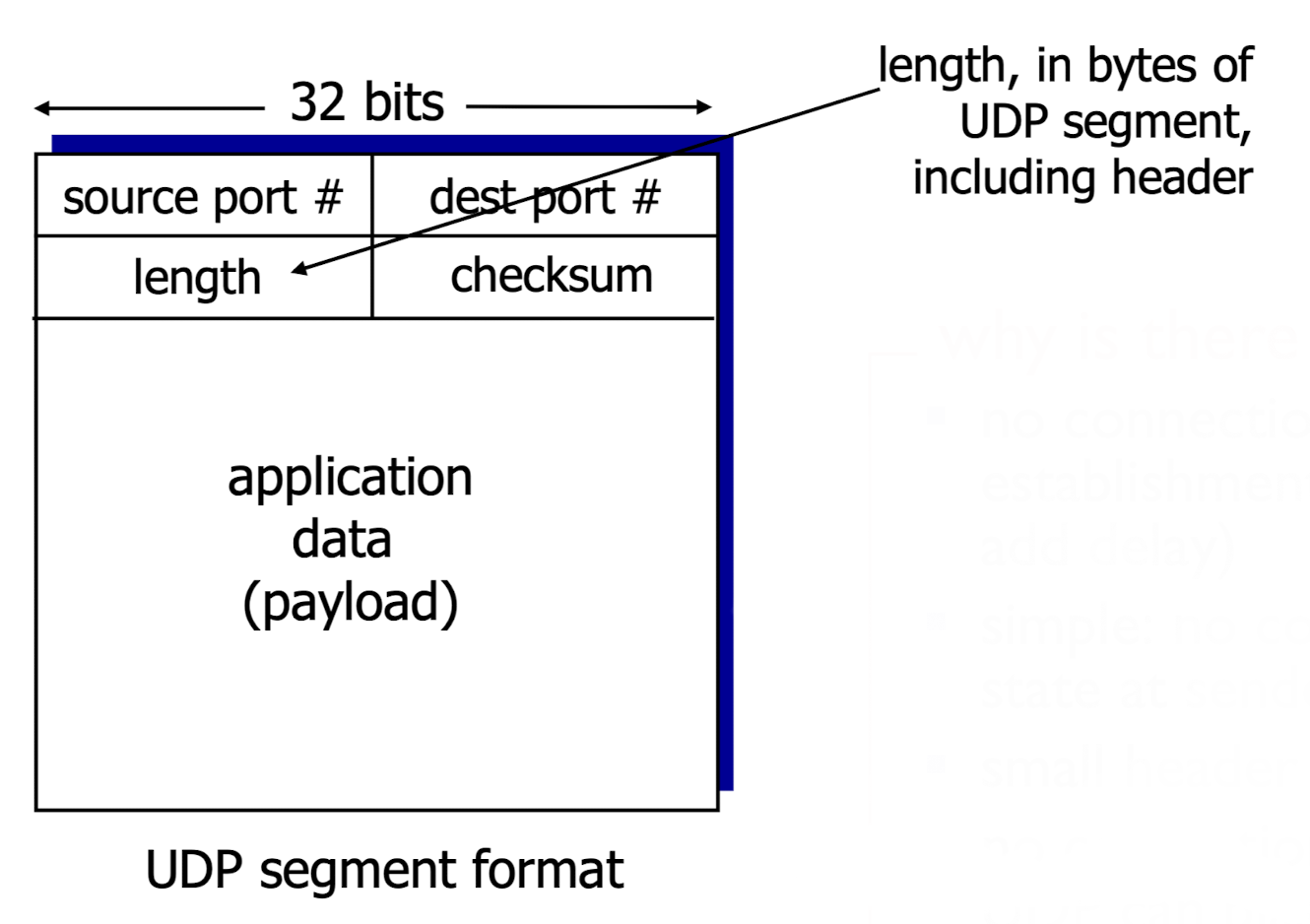
UDP segment header:- 맨 위 : source port number, destination port number
- Length : header까지 포함된 application에서 보내준 전체 data 길이
- checksum : error를 detection 기능.
보내는 애가 계산결과를 checksum에 넣음.
32bit를 16bit로 쪼개서 이진 덧셈(1의 보수 덧셈 = carry 발생한 것을 그대로 더해줌)
ex >
1 1 0
1 0 1
= 0 1 1 + 1(carry) = 1 0 0
1의 보수 덧셈의 결과인 1 0 0을 반전시킴
(최종결과) checksum = 0 1 1
받는 애는 전체 packet에 대해서 똑같이 1의 보수 덧셈 계산함.
1의 보수 덧셈 = 1 0 0
checksum field = 0 1 1
1 1 1 을 반전시켰을때,
0이면? error 없음. 어떤 값이라도 있으면? error 있음.
3.4 Principles of reliable data transfer
-
UDP에서 checksum을 계산하여 error detection을 한다.
하지만 UDP는 less reliable data transfer기 때문에 data integrity를 보장하지 않는다.
따라서 우리는 reliable data transfer가 필요하다. -
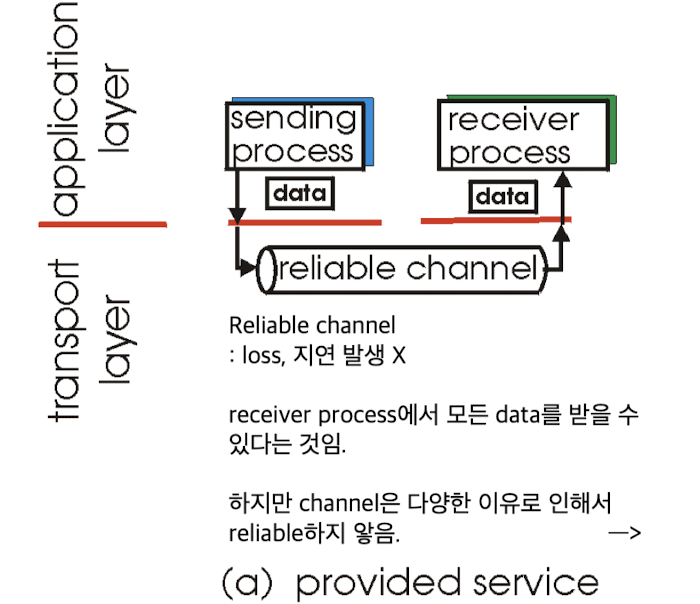
실제로 channel은 다양한 이유로 인해서 unreliable한 특성을 갖고 있다.
즉, data는 channel(router, switch, 등)을 통과할 때, 문제가 발생할 수 있다.
-
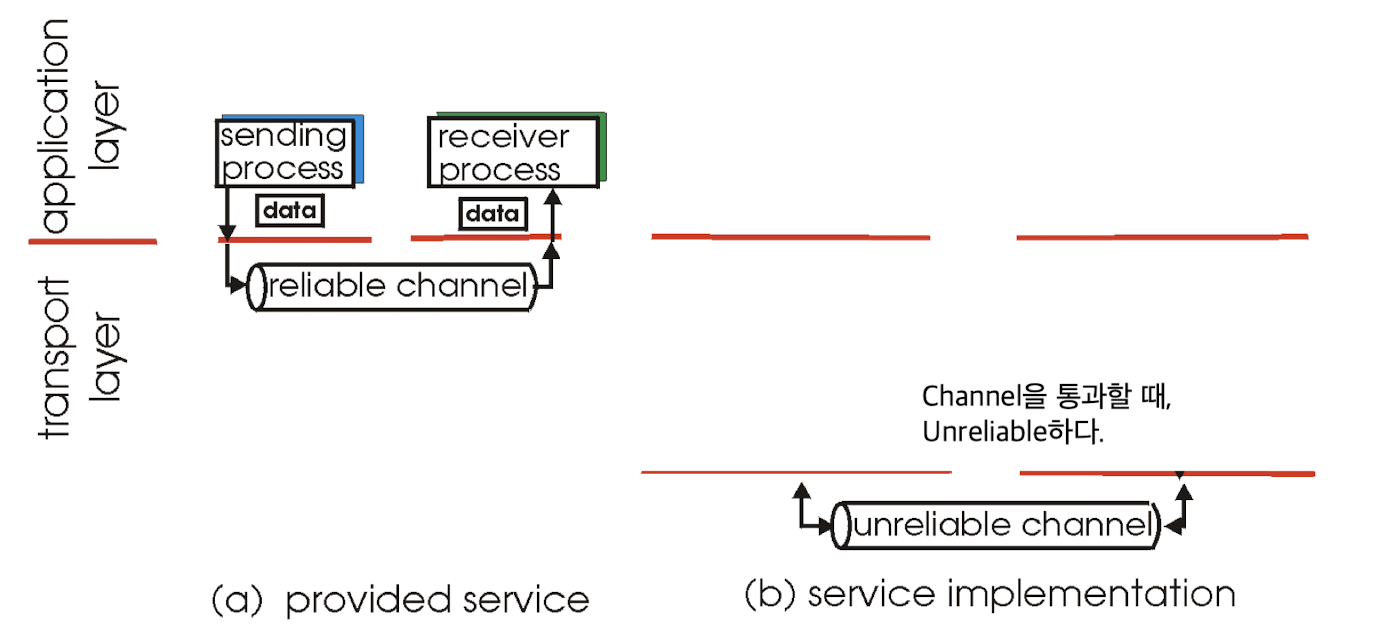
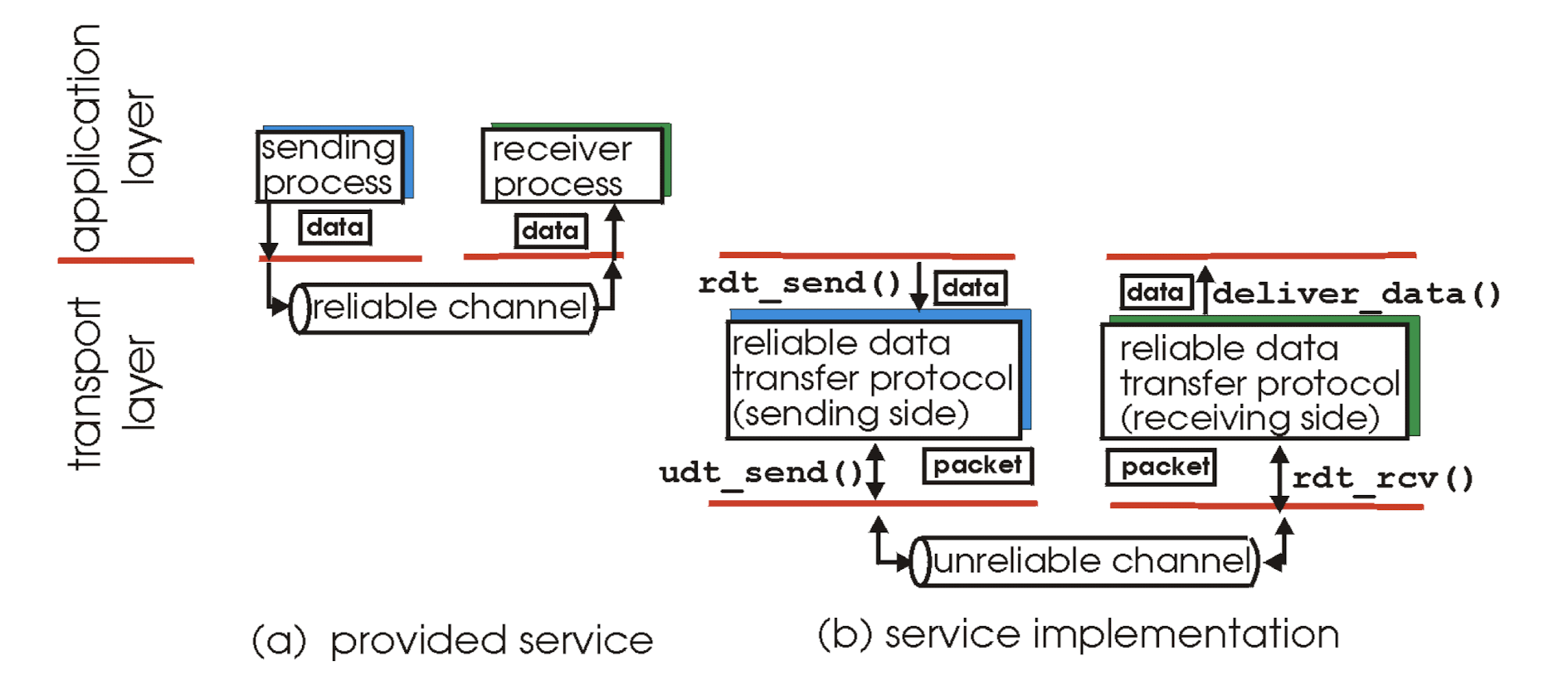
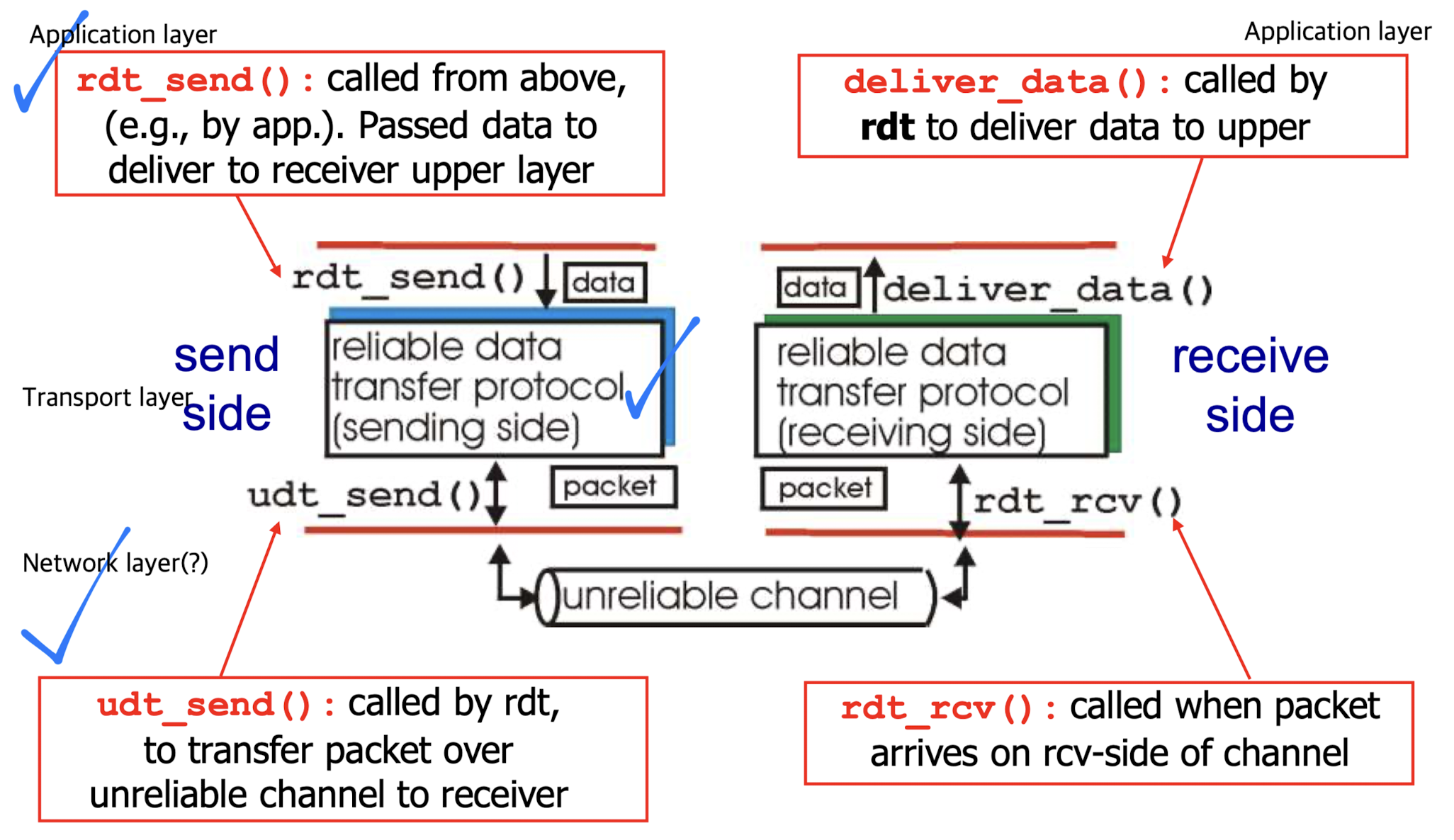
application에서 하위 계층으로 data를 보내는 것은
하위 계층에서 제공하고 있는 함수를 call하여 data를 넣어주는 것이다.
예를 들어, application layer에서 transport layer의 rdt_send() 함수에 data를 넣어서 data를 보낸다.
이때 sender는 packet을 unreliable channel을 통해 receiver에게 보낸다.
receiver는 packet을 받고, deliever_data()를 통해서 application layer로 data를 보낸다.
여기서, unreliable channel에서 어떤 일이 발생하는지? 어떤 일을 해야하는지?를 배울 것이다.
getting started, FSM
-
unreliable data transfer: 문제가 있으면 버리고, 문제가 없으면 바로 보내줌 -
reliable data transfer: 문제가 있으면, transport layer에서 해당 문제를 다 해결할 때까지 data를 application에 보내주지 않음.
-
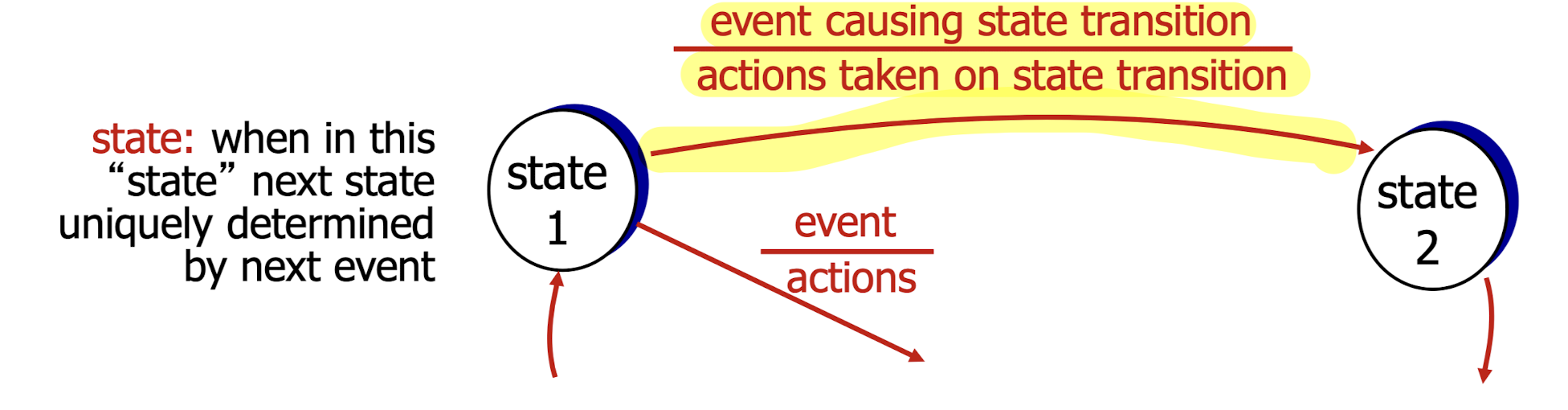
FSM(Finite State Machine = State Transition Diagram)
FSM은 state가 바뀜으로 인해서 어떠한 event/action이 있는지 정의하기 위해 사용한다.
sequential한 program에는 FSM을 사용하지 않아도 되는데,
다양한 event가 발생하는 program에서는 FSM이 필요하다.
 그런데 왜 FSM이 나오는가?
그런데 왜 FSM이 나오는가?
packet을 주고 받을 때,
packet을 받았을 때, 어떤 packet을 받았는가에 따라서 state를 다르게 정의하여 reliable data transfer를 보장할 것이다.
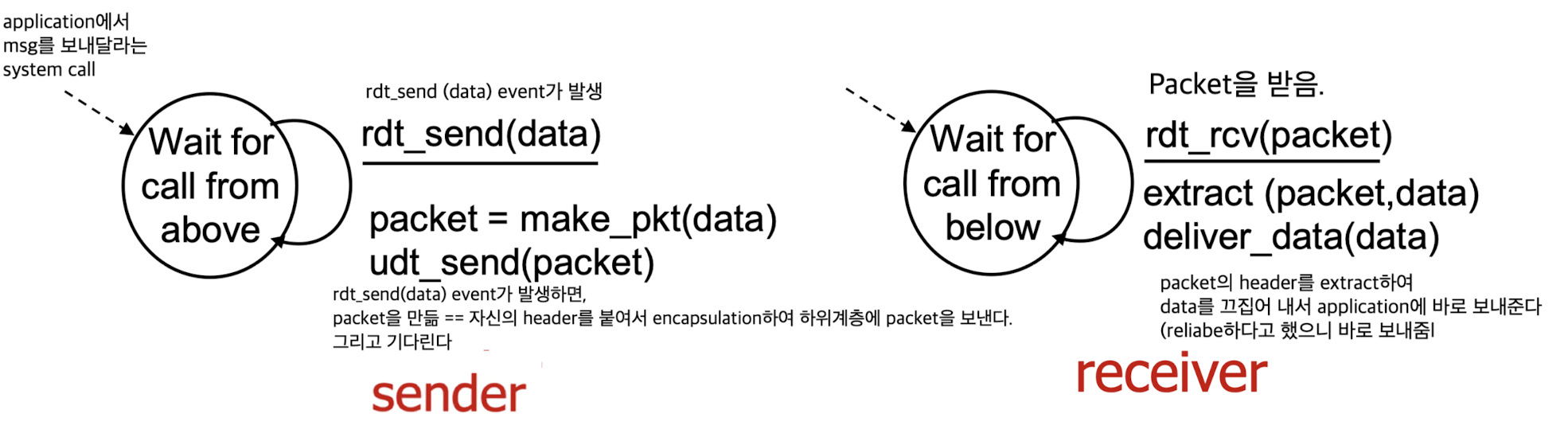
rdt1.0 : reliable transfer over a reliable channel
rdt1.0:
channel이 perfectly reliable하다고 가정.
no bit errors, no loss of packets이라고 가정.
➡️ 하지만 rdt1.0은 너무 ideal한 가정을 하고 있다.
rdt2.0 : channel with bit errors
-
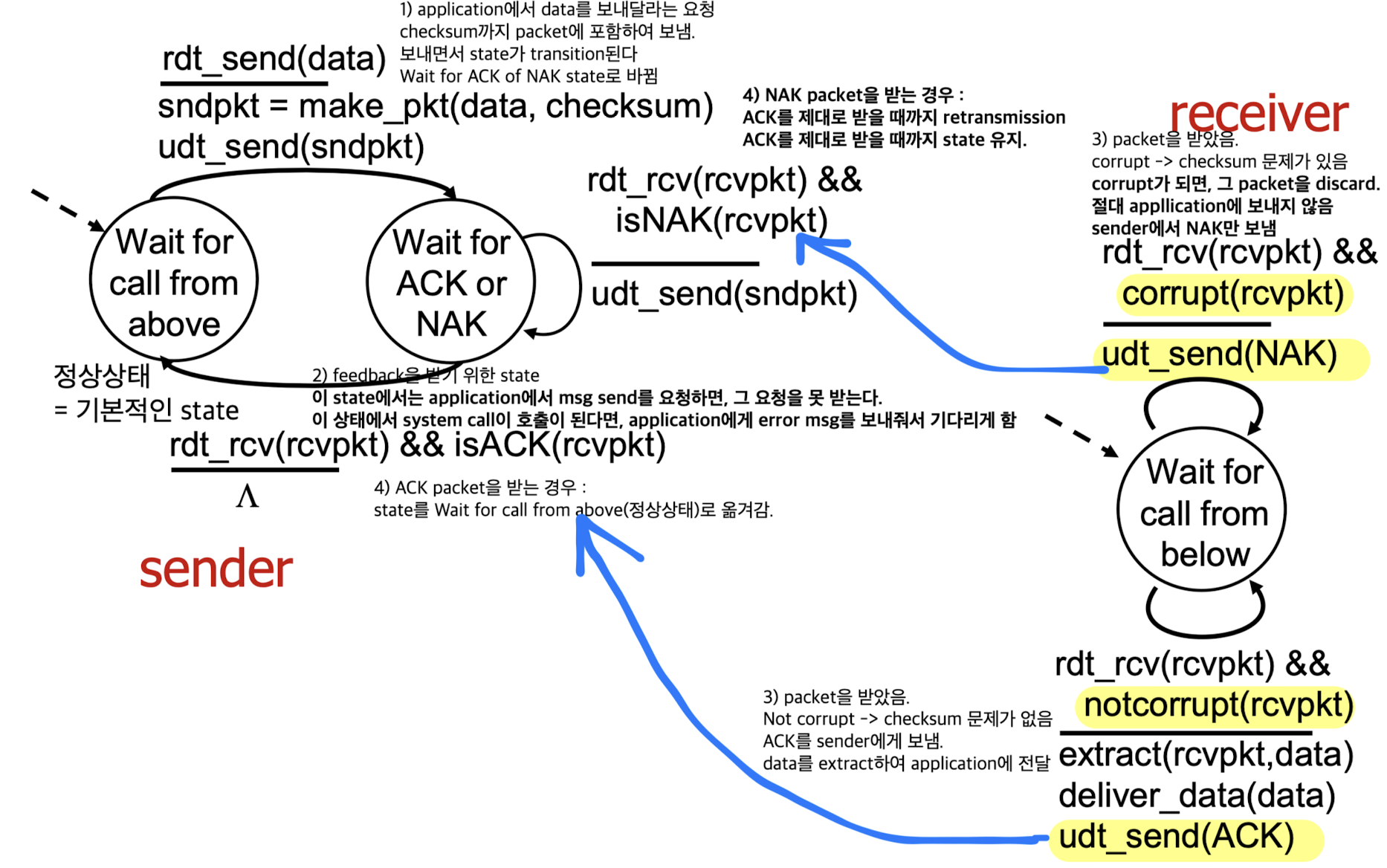
rdt2.0:
만약 channel에 bit error가 있다면? 즉, 중간에 오는 packet이 깨진다면?
checksum으로 확인할 수 있다.
하지만 checksum으로 확인까지만 하는 것은 UDP인데,
reliable data transfer이기 때문에 error가 발생한다면, 어떻게 recovery를 할 것인가? -
sender 입장에서는 자신의 packet이 잘 갔는지 안 갔는지 확인하기 위해
packet을 보내고, 각각의 packet에 대한 response 받아야 한다.
그 response는 receiver에서 보내는데,
response는 ACKs(Acknowledgement), NAKs(Negative Acknowledgements)이다.
만약에 receiver가 checksum하여 error가 발생한 것을 알았다면? NAK을 response한다.
만약 sender가 NAK을 받으면, retransmission한다. -
정리하자면,
rdt1.0에서 error detection(checksum), feedback(ACKs, NAKs)이 추가되어 state가 더 많아졌다.
application에서 transport에서 무엇을 하고 있는지 모르게(transparent하게) 하여 tranport layer를 설계함.
 하지만 rdt2.0은 치명적인 단점이 있다!
하지만 rdt2.0은 치명적인 단점이 있다!
만약 ACK/NAK가 corrupted된다면?
rdt2.1 :
-
rdt2.0에서도 channel 자체가 unreliable channel이기 때문에
receiver에서 보낸 response인 ACK, NAK 자체도 unreliable channel로 전송된다.
따라서 ACK, NAK조차도 unreliable하다.
➡️ duplicate msg를 어떻게 처리할 수 있을까? ACK, NAK가 깨졌는지 어떻게 확인할 수 있을까? -
지금까지는 매번 packet마다 independent했는데,
보내는 packet에 대해 고유한 sequence number를 붙여서 identification한다.
receiver쪽에서는 잘 수신한 sequence number를 처리했다는 정보를 buffer에 저장하고 있다.
만약 똑같은 sequence number packet이 들어오면, duplicate data이기 때문에 discard한다.
➡️ 이러한 protocol 형식을Stop and Wait라고 한다.
sender가 한 packet씩 보낸다.
receiver가 response하기 전까지 wait했다가 완벽히 처리되었을 때, 그 다음 packet을 처리한다.
Sender
Sender, Receiver의 형광펜, 파란색 부분 중요함.
Sender:
지금 보낸 packet의 sequence number = 0
다음 보낼 packet의 sequence number = 1
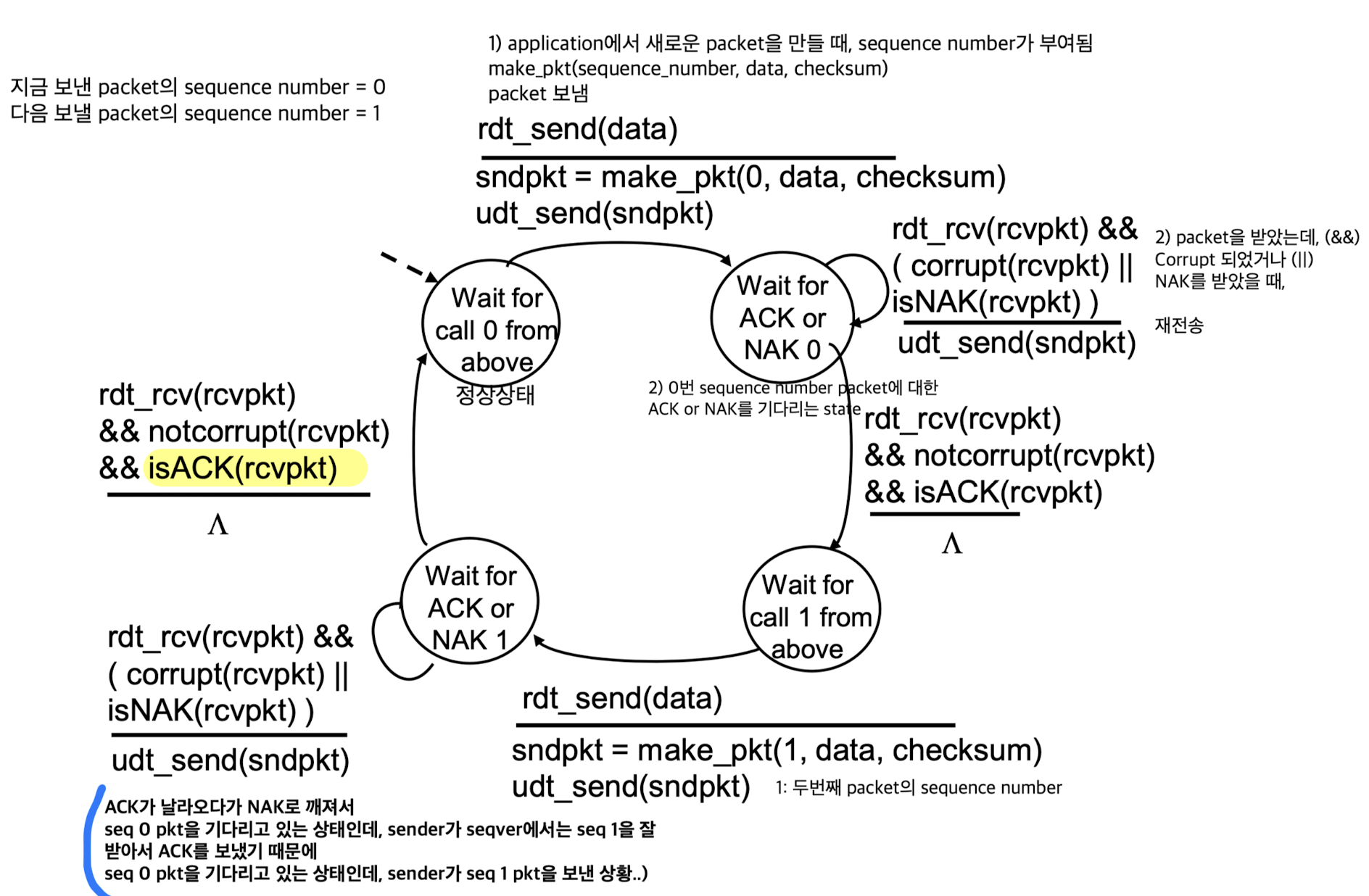
Receiver
Receiver:
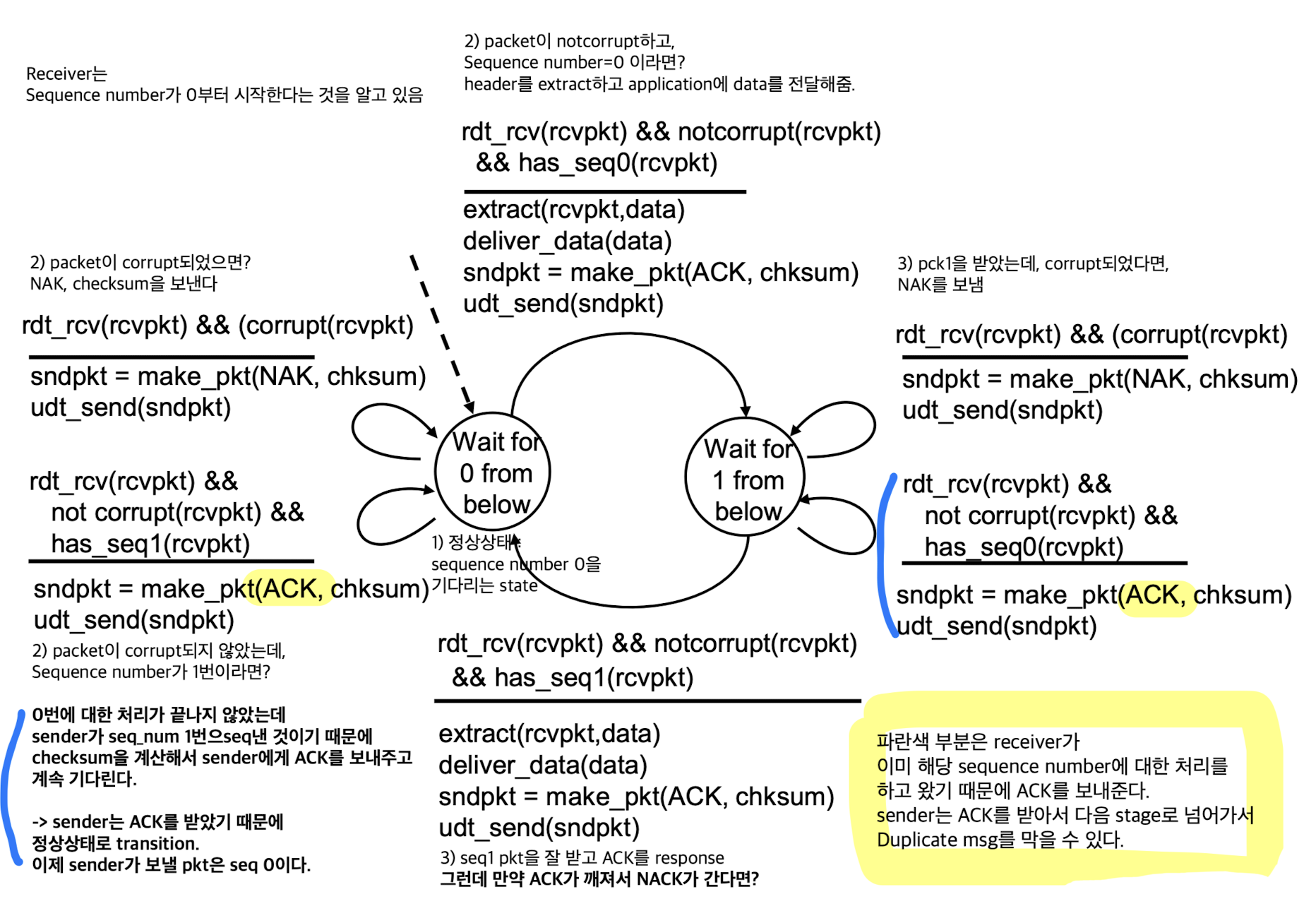
그런데 packet의 sequence number를 0, 1만 사용해도 충분한가?
충분하다.
stop and wait로 한 packet씩 기다리기 때문에
이번 packet이 0번이면, 그 이전의 packet을 받아도 discard하거나 ACK를 보내줘서 대처할 수 있다.
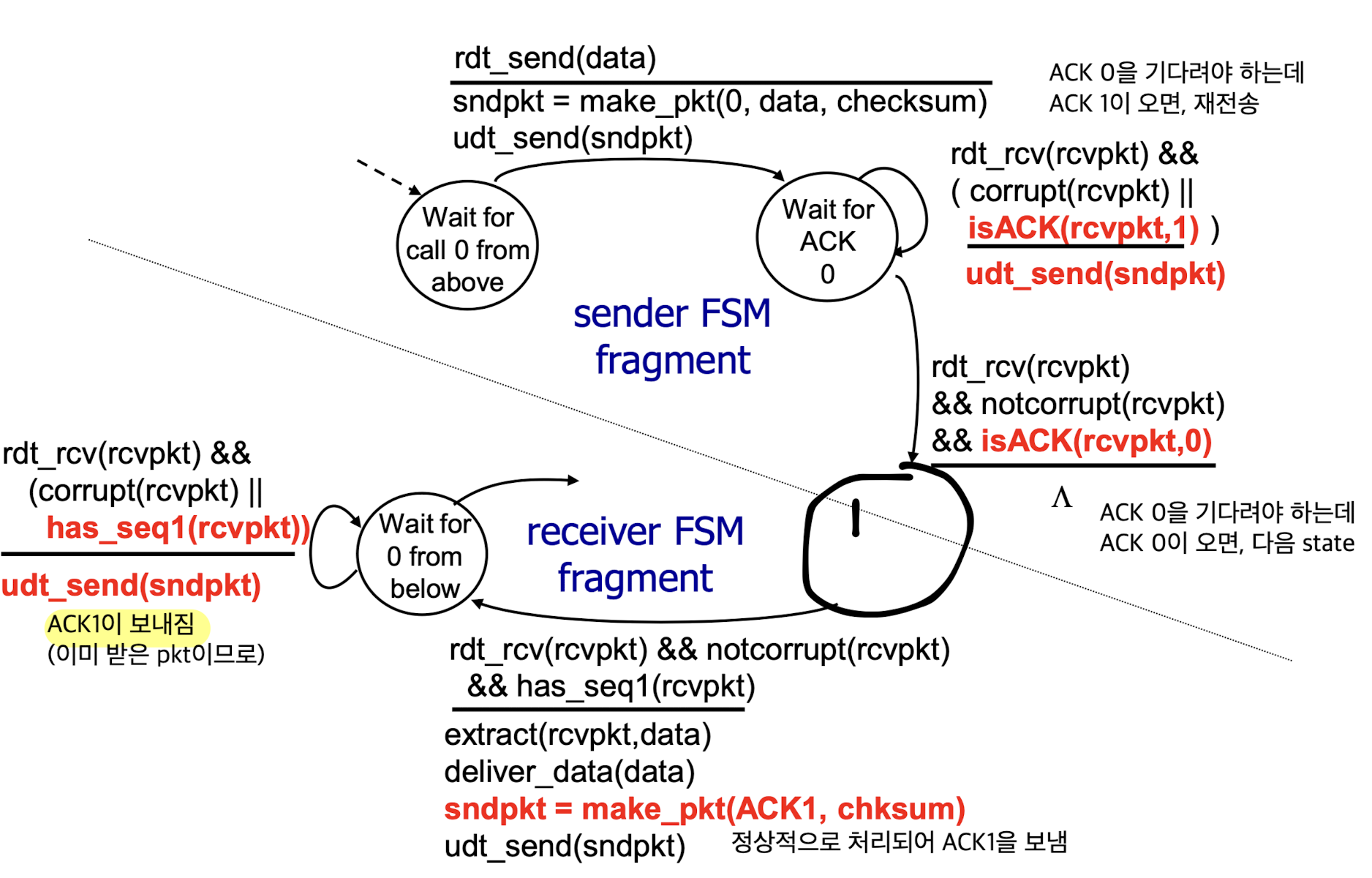
rdt2.2 : a NAK-free protocol
rdt2.2:
rdt2.1의 NAK를 없애서 ACK로만 해보자.
그럼 pkt이 잘못되었다는 것은 어떻게 알 수 있는가?
receiver에서도 ACK에 sequence number를 붙여서 response한다.
그래서 packet을 보냈는데, 똑같은 ACK가 중복되어 돌아올 경우, 재전송.
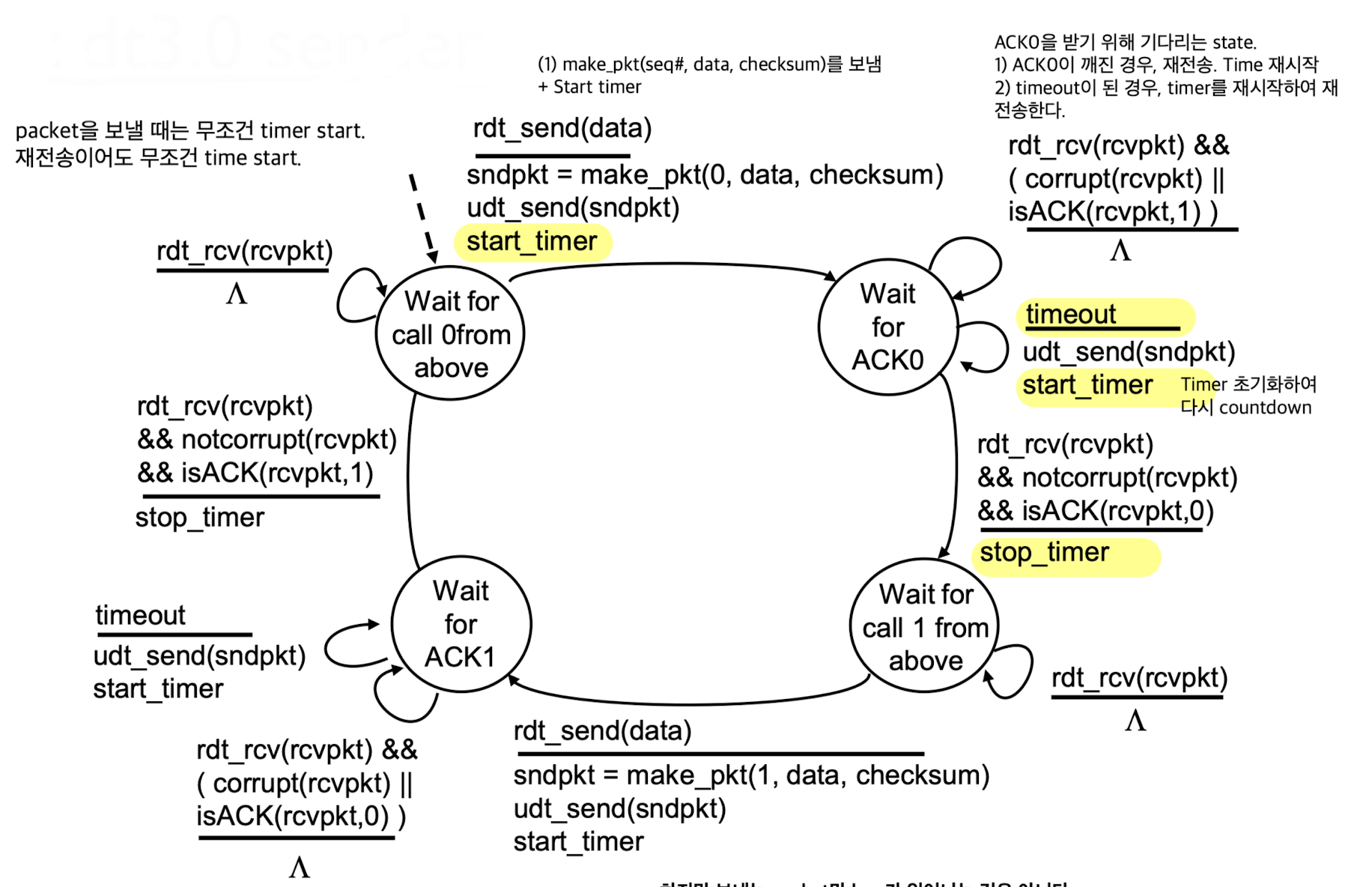
rdt3.0 : channels with errors and loss
-
rdt3.0:
가정이 하나 더 들어간다.
지금까지는 bit error만 고려했었는데, loss도 발생한다고 가정.
bit error만 있으면 아무리 심각하게 깨져도 도착은 해서 처리를 할 수 있다.
하지만 loss는 심각하다.
sender는 보냈는데 receiver는 아무것도 받지 않아 feedback 자체를 받을 수 없다. -
그래서
Timer를 써서 loss를 극복할 수 있다.
Timeout이 되기 전에 feedback이 오면, 이전처럼 처리.
만약 loss가 생긴다면 timeout이 되어 interrupt가 발생.
Timeout이 되면, receiver는 당연히 아무것도 받지 않았기 때문에 처리할게 없다.
sender는 재전송해야 한다.
sender
- sender :
 하지만 여전히 보내는 packet만 loss가 일어나는 것은 아니다.
하지만 여전히 보내는 packet만 loss가 일어나는 것은 아니다.
receiver의 ACK도 loss가 될 수 있다.
그렇다면 receiver에서도 timer를 사용해야 하는가?
아니다. receiver에서도 timer를 남용하면, 문제가 더 커지고 복잡해진다.
sender가 보낸 packet에만 timer를 사용해도 발생할 수 있는 문제들이 거의 사라진다.
in action
- (a) : no loss 경우
(b) : packet loss가 발생한 경우
(c) : ACK loss가 발생한 경우
(d) : permature timeout / delayed ACK가 발생한 경우
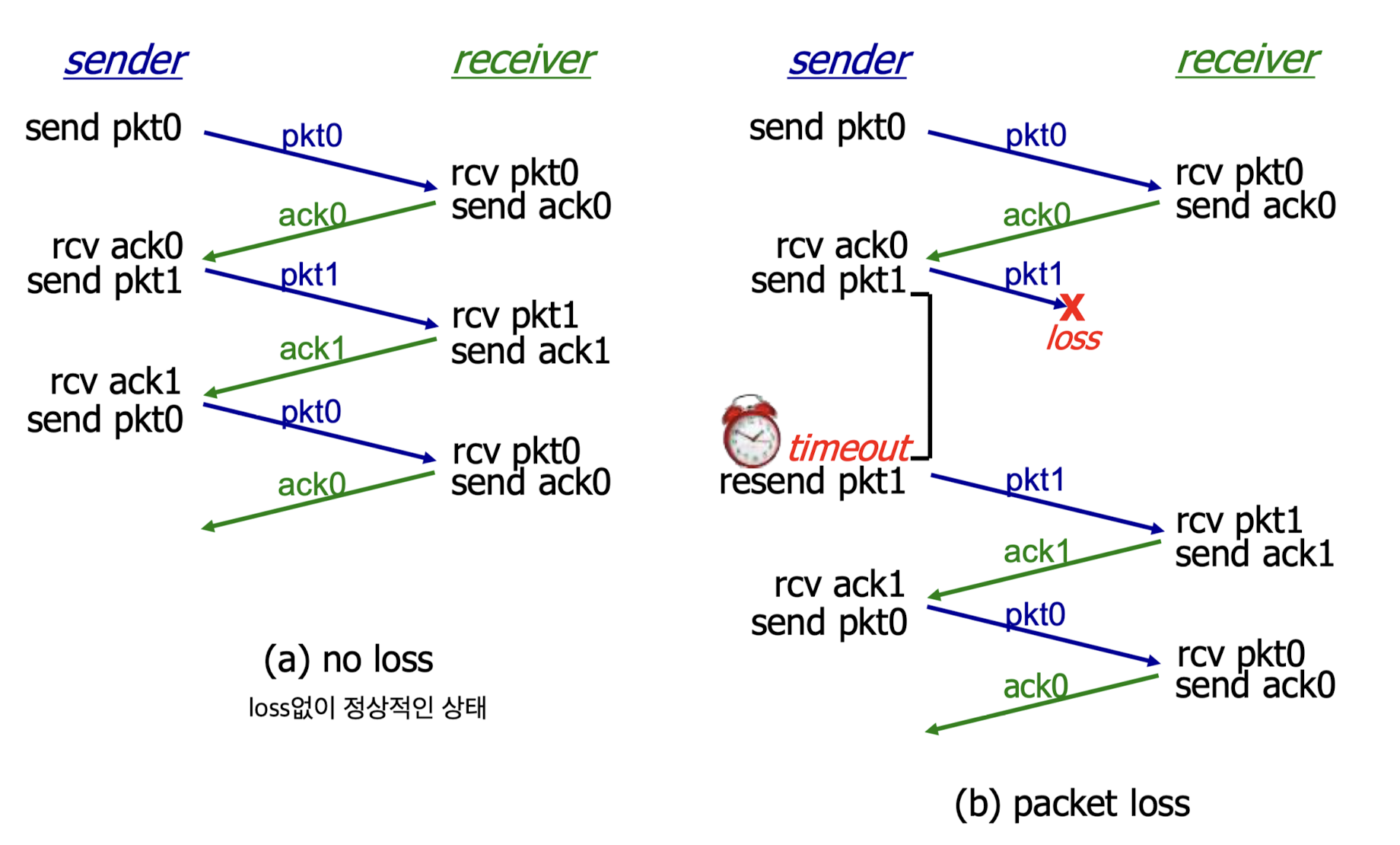
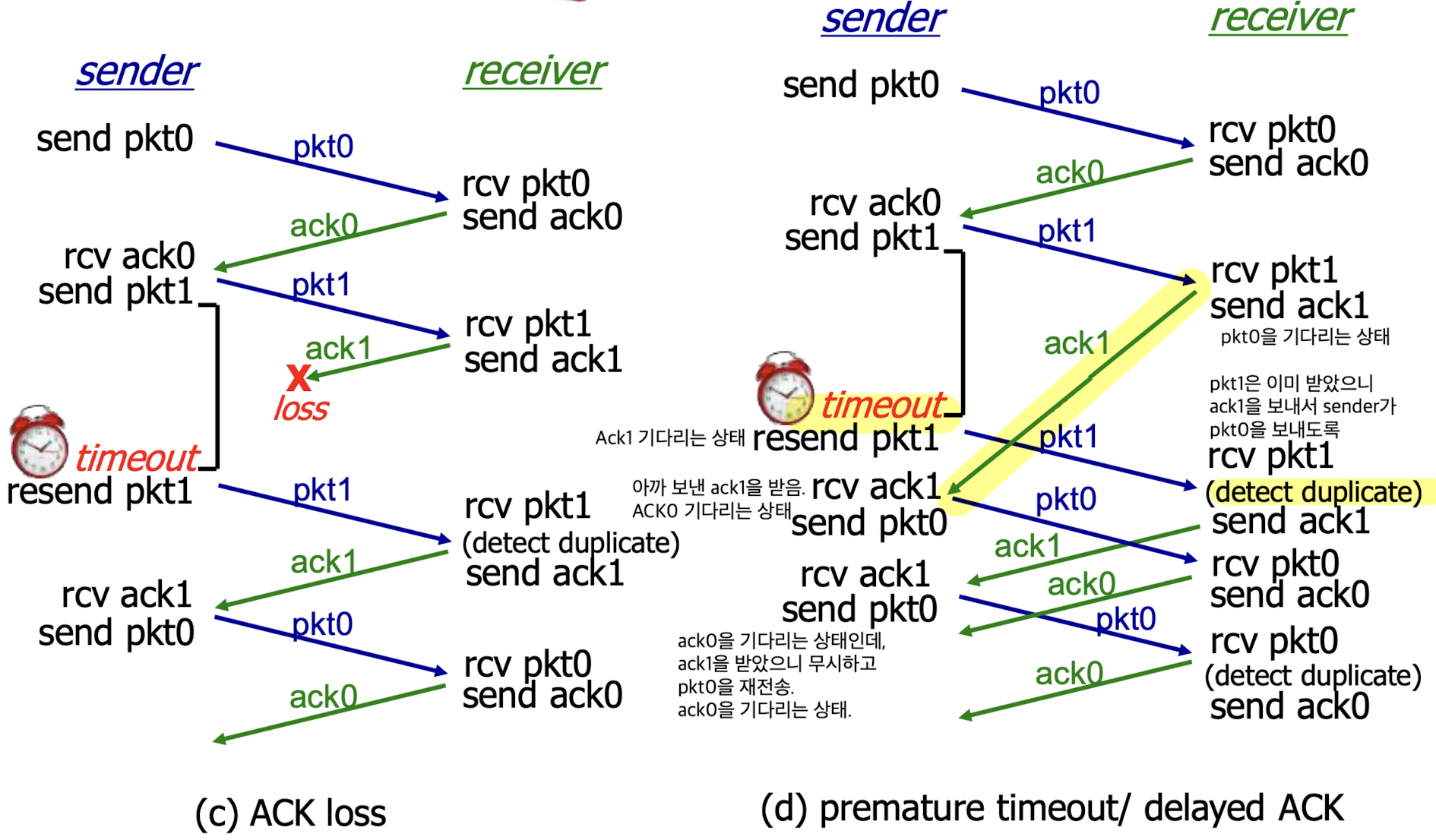
- (d) :
network 상황에 따라 delay가 많음.
receiver에서는 ACK1을 response했는데,
network 상황으로 인해 delay되어서 timeout 이후에 도착함.
sender는 ACK1에 대한 timeout이 되었기 때문에 pkt1을 재전송.
하지만 receiver는 pkt1이 duplicate pkt이기 때문에 ACK1을 재전송.
...
위 (d) 그림을 참고해보면, 복잡하게 처리가 되는 것 같지만 결국에는 처리가 된다.
- (d) :
Performance of rdt3.0 (stop and wait operation)
Utilization:
RTT 동안 얼만큼 보낼 수 있는지?
stop and wait 방식이므로 packet 1개를 보내고 나서 나머지 동안은 아무것도 하지 않는다.
따라서 packet 하나를 보내는 시간을 이라고 했을 때,
전체 중에 밖에 사용하지 못한다.
이는 utilization이 매우 좋지 않다.
그래서 utilization을 높이기 위해 나온 아이디어가 Pipeline이다.

Pipelined protocols
-
pipelining:
packet 1개를 보내고나서 stop and wait하는 것이 아니라,
우선 packet들을 계속해서 보내고 나서 그 후에 처리를 해보자.
그래서 utilization을 좋게(packet들을 더 많이, 빨리 보낼 수 있도록) 해보자. -
Pipielined protocol:
pipelining 기술에는 크게 두가지가 있다.- Go-back-N
- Selective Repeat
1. Go-back-N
-
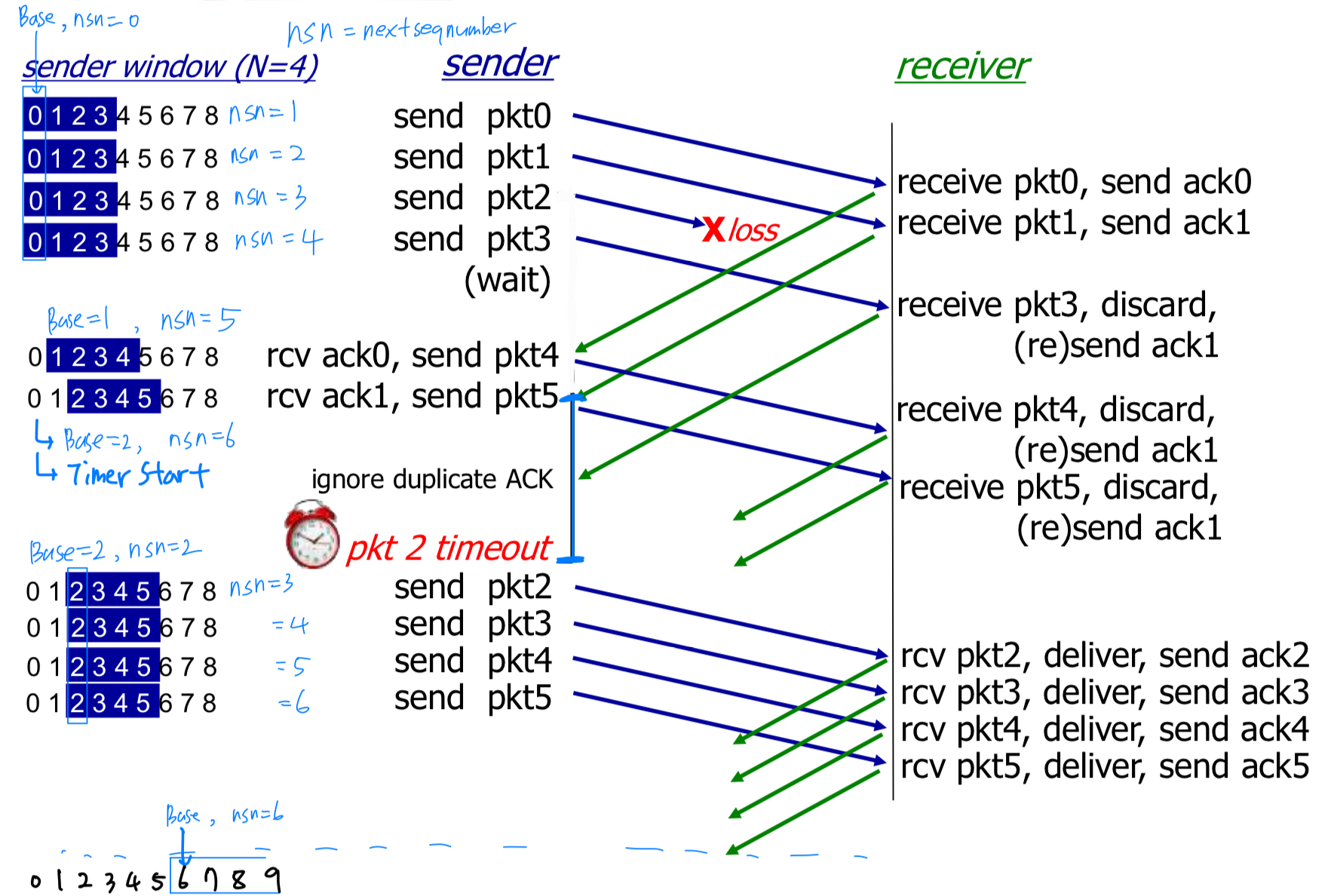
Go-back-N:- packet을 보낼 때, sliding window 안에 있는 packet들을 보낸다.
window는 ack를 받은 만큼씩 sliding한다. - base에 있는 pkt에 대한 timer 1개만 사용한다.
- 만약 packet에 문제가 생겨 timeout이 되었다면,
그 packet부터 전부 다 retransmission.
- packet을 보낼 때, sliding window 안에 있는 packet들을 보낸다.
-
Sender:
cumulative ack : 3번에 대한 ack를 받았다 = 이미 1, 2, 3번은 잘 받았으니 4번 packet으로 sliding하고, timer restart.
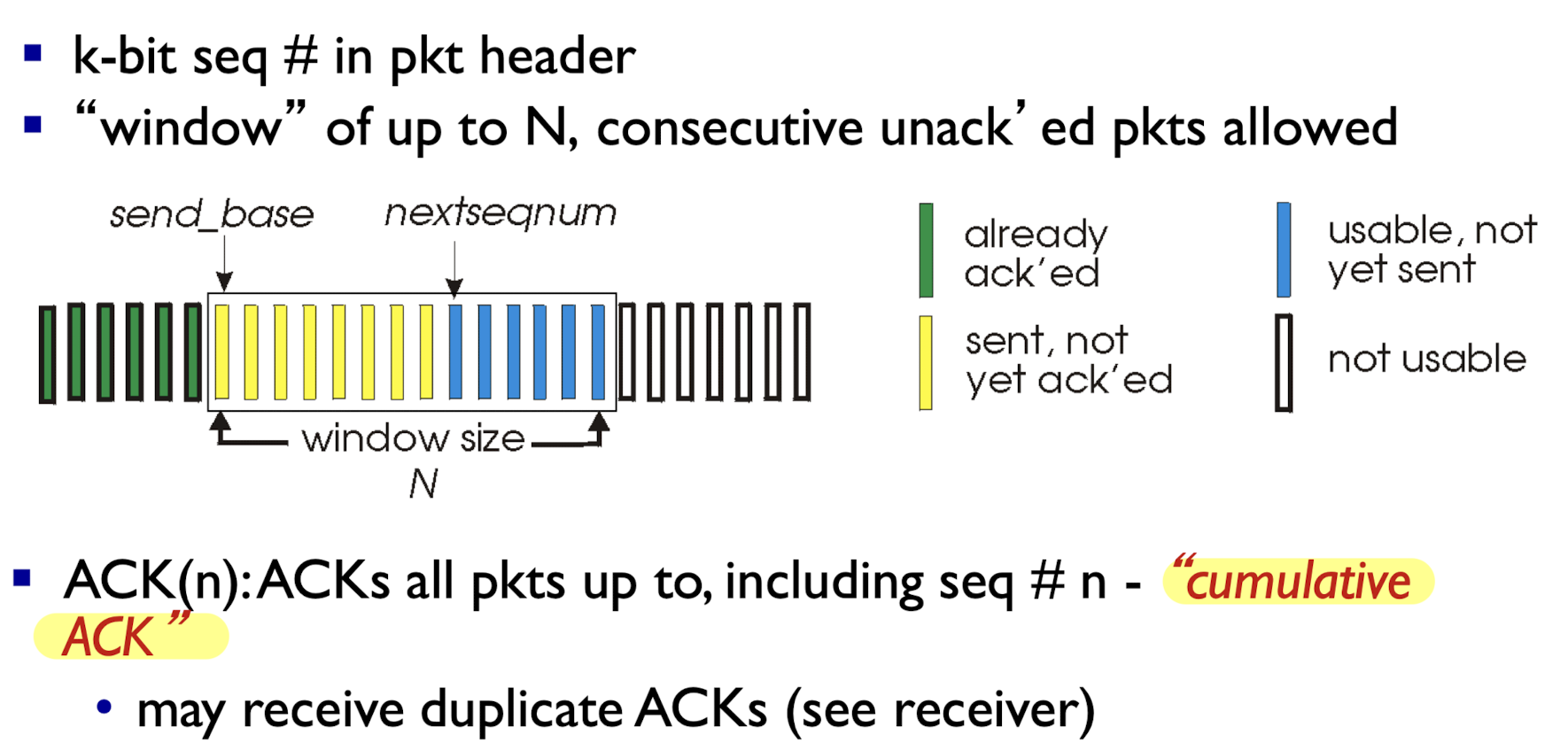
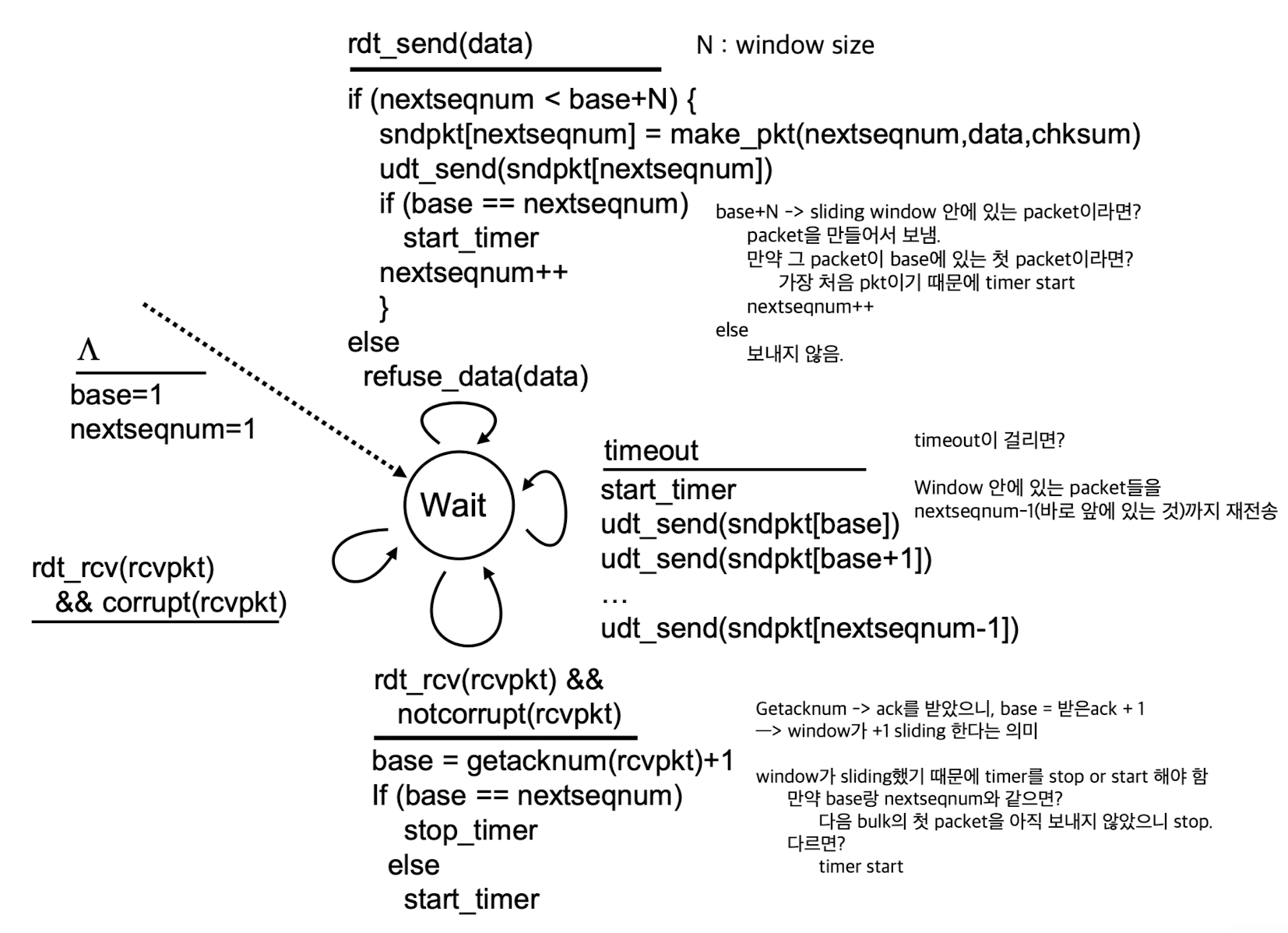
-
Receiver:
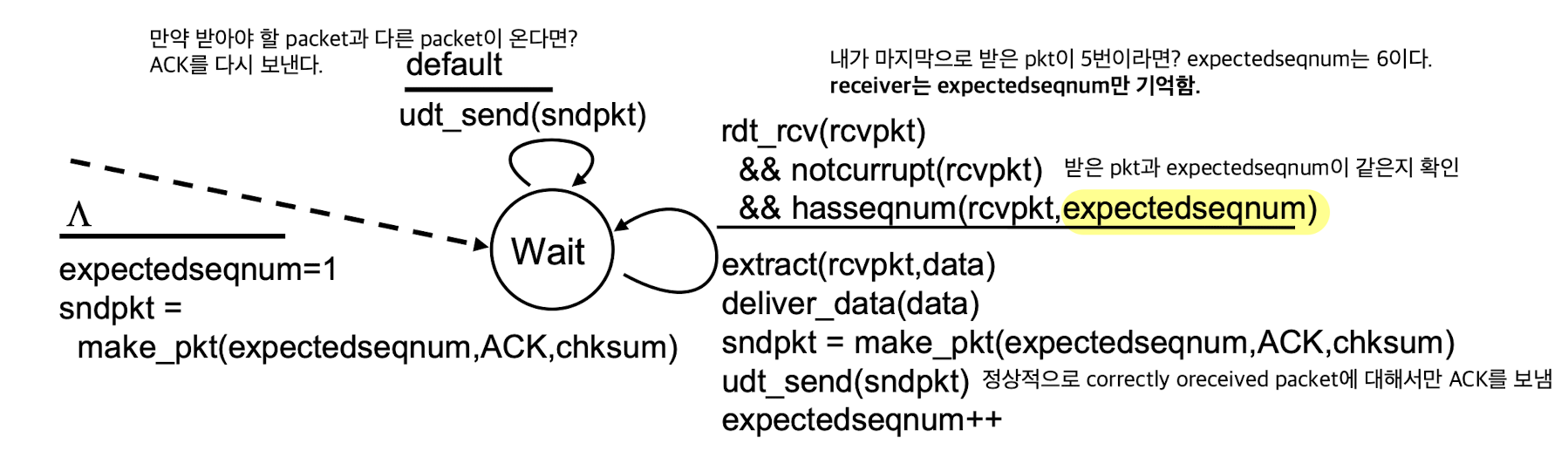
-
GBN in action:
2. Selective Repeat
-
Selective Repeat:- (GBN과 다른점 1) sliding window 안에 있는 packet들만큼의 timer가 필요하다.
- 만약 packet에 문제가 생겨 timeout이 되었다면,
timeout된 packet만 retransmission. ➡️ packet마다 개별적으로 관리를 하겠다 - (GBN과 다른점 2) receiver도 buffer가 있다.
-
Sender, Receiver windows:
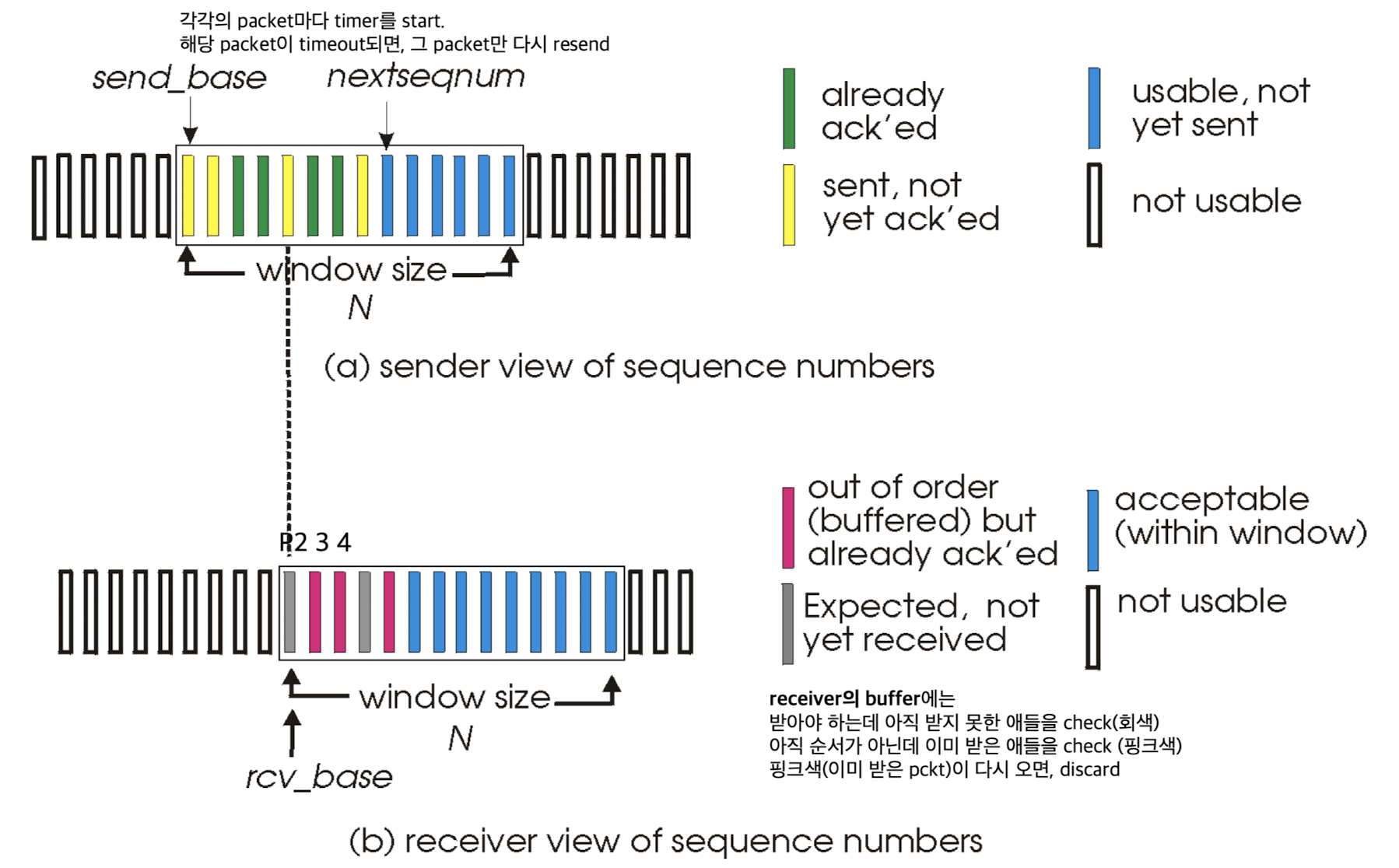

-
Selective repeat in action:
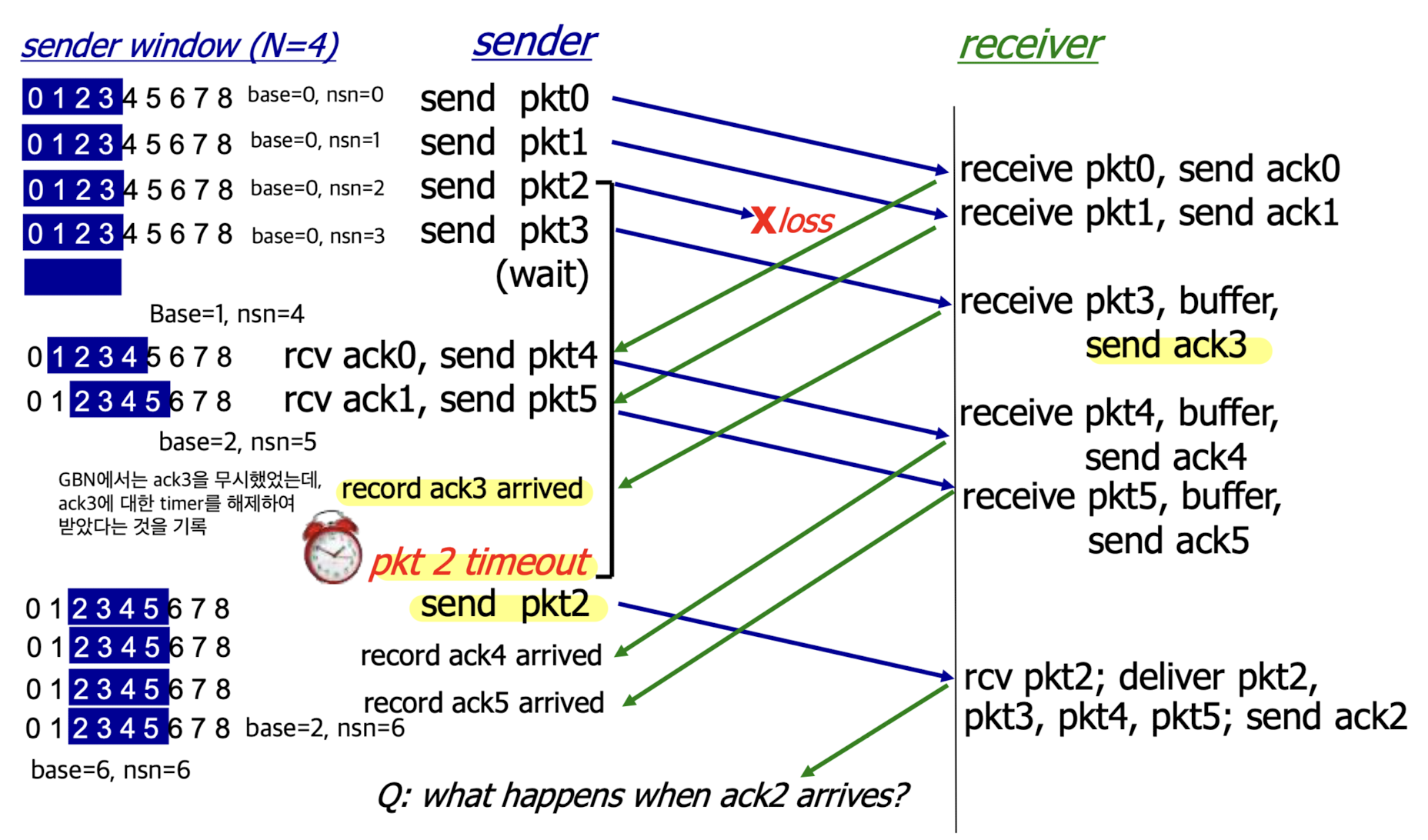
-
Selective repeat dilemma:
receiver 입장에서는 (a), (b) 모두 똑같은 sequence number를 받지만,
서로 다른 data이다.
(a)에서는 제대로된 data를 받지만
(b)에서는 receiver가 처음에 보내는 ack0, 1 2가 모두 loss되었는데 receiver는 이를 모른다.
sender는 ack가 오지 않았기 때문에 처음 보낸 pkt0, 1 2를 재전송한다.
이때, receiver는 그 pkt들이 처음 pkt 0, 1, 2라 생각하지 않고 pkt 4(0), 5(1), 6(2)라고 생각하게 된다.
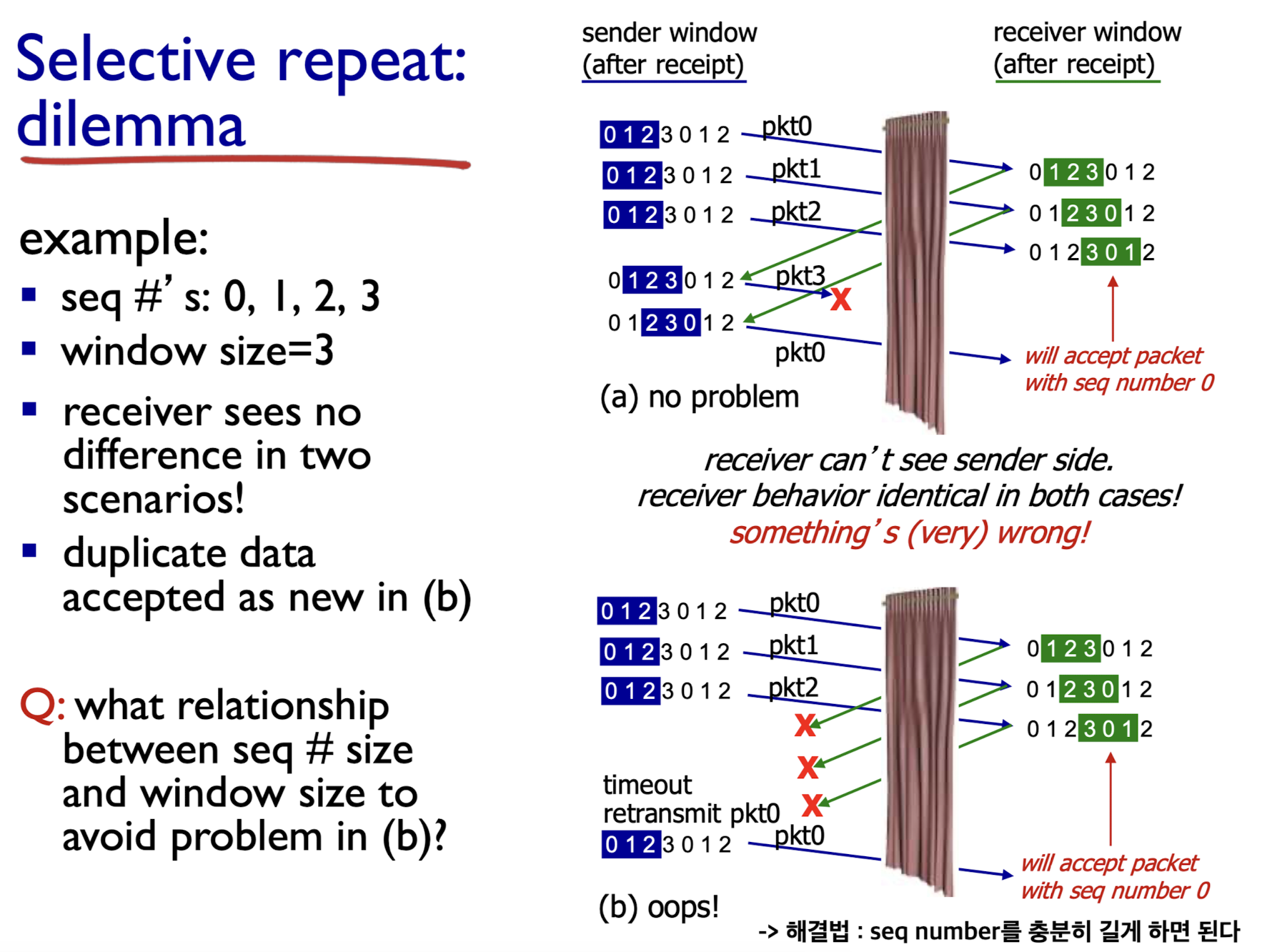 ➡️ 이에 대한 해결법으로는 seq number를 충분히 길게 하면 된다.
➡️ 이에 대한 해결법으로는 seq number를 충분히 길게 하면 된다.
3.5 Connection-oriented transport : TCP
TCP : Overview
-
TCP는 표준이 여러개이다.
-
TCP는
point-to-point(= one-to-one)이다. (1 : N이 아니다) -
reliable, in-order byte steam이다.
-
pipelined방식 사용.- pipeline 방식을 사용하다 보니까 또 다른 문제점이 발생하긴 한다.
나만 TCP를 사용하는게 아니다.
다른 사람들도 TCP를 사용해서 pipeline 방식을 사용하기 때문에
network core 보내는 packet들이 많아진다.(traffic이 많아진다)
결국에 congestion이 발생한다. - application에서는 read라는 system call로 data를 읽어가야 한다.
그런덴 application에서 빨리빨리 안읽어가면, transport layer에서 data를 계속 갖고 있어야 한다.
그러다보면, transport layer buffer의 overflow가 발생한다.
이러한 문제들을 해결하기 위해서 TCP에서는 나중에 배울congestion control, flow control을 한다.
➡️ network 상황에 따라 sender, receiver의 window size를 가변적으로...
- pipeline 방식을 사용하다 보니까 또 다른 문제점이 발생하긴 한다.
-
하나의 TCP connection으로 full duplex data가 가능하다.:- simplex : A만 send 할 수 있고, B는 receive만 할 수 있음
- half duplex : A, B 모두 send와 receive할 수 있는데, A가 sender일 때 B는 receiver여야 하고, B가 sender일 때 A는 receiver여야 한다.
- full duplex : A, B는 동시에 송수신이 가능하다
- MSS unit(Maximum Segment Size) : segment를 한 번에 보내도록 관리하는 unit. (나중에 배움)
-
connection-oriented:
UDP는 data가 생기면 destination으로 바로 보내고, receiver는 받았을 때 checksum error가 없으면 바로 application layer로 올려줌
하지만 TCP는 data를 보내기 전에 TCP connection을 수립하고 나서 data를 보내기 시작한다.
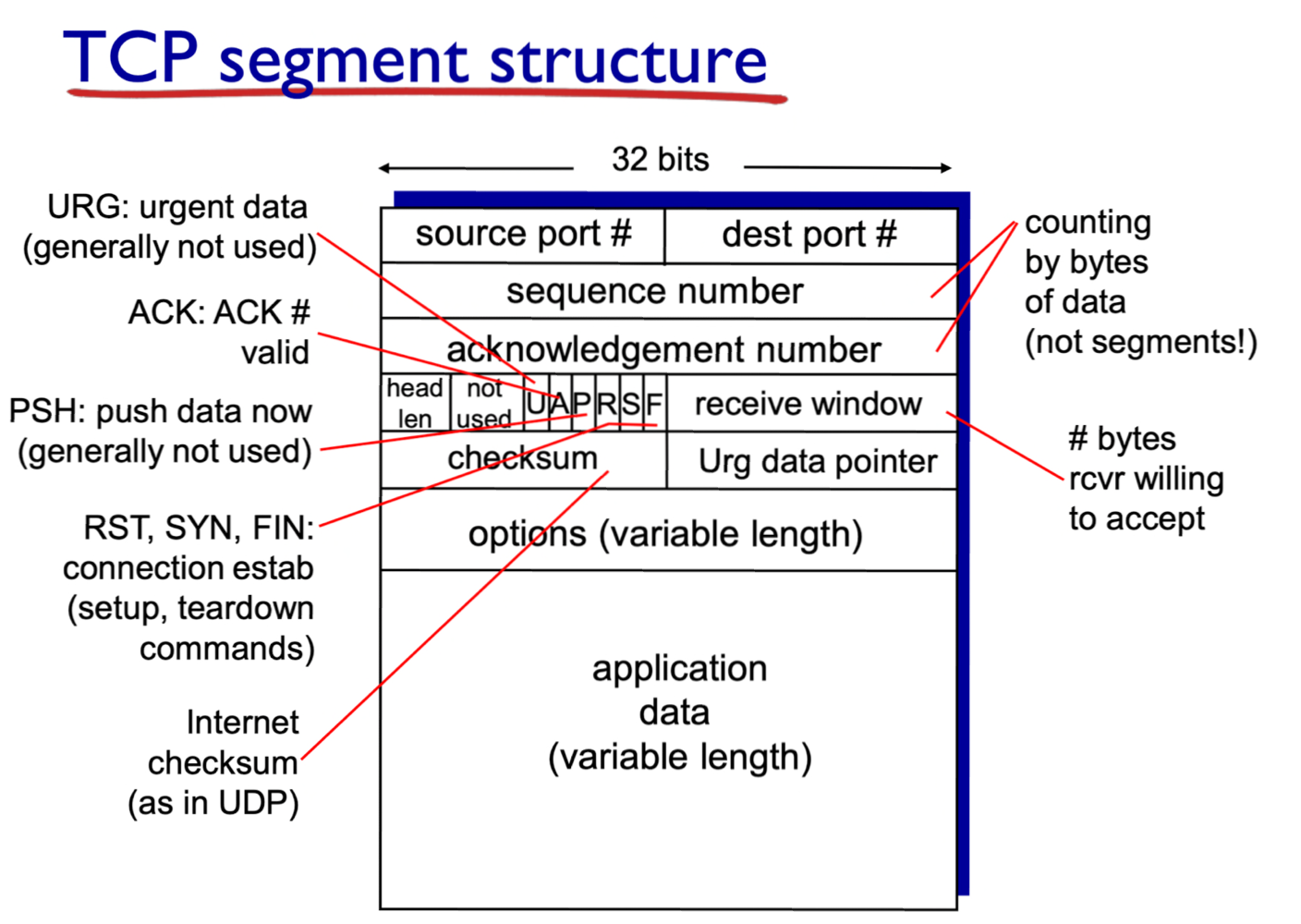
TCP segment structure
(비교를 위한) UDP segment structure:
TCP segment structure:
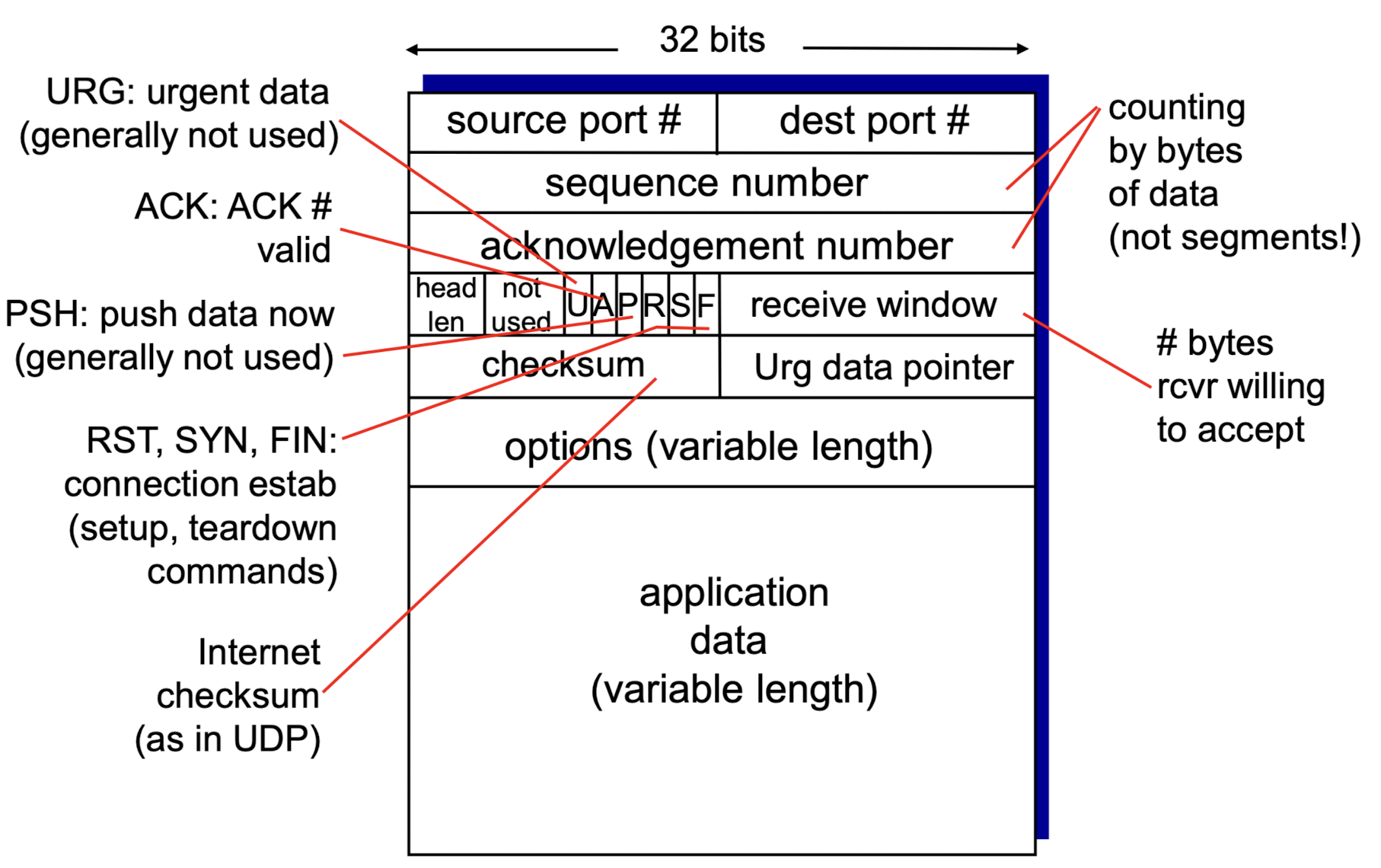
source port #, dest port #:sequence #, acknowledge #:- 내가 sender일 때는 보내야 할 sequence #와 받아야할 ack #을 보냄.
내가 receiver일 때는 받아야 할 sequence #와 보내야할 ack #을 보냄. - 나의 sequence #는 상대방의 ack #가 된다.
상대의 sequence #는 나한테 ack #가 된다. - sequence #가 너무 적으면, 많은 packet들을 처리하는 데에 문제가 생길 수 있어서
connection establish할 때,
sequence #를 보내야 할 data의 첫번째 ascii code로 시작함.
- 내가 sender일 때는 보내야 할 sequence #와 받아야할 ack #을 보냄.
head len:
UDP는 그냥 length(header와 data를 모두 포함한 length)였는데, TCP는 head len(header length만)이다.
왜 TCP는 head len를 보낼까? 전체 packent length를 어떻게 아는가?
➡️ TCP는 MSS(Maximum Segment Size)를 미리 설정하기 때문에
어차피 header를 포함한 data length를 알고 있기 때문에 header length만 보내도 상관 없다.acknowledge #:U: Urgent flag (1이면, 그 data에서 어디까지를 urgent하게 보낼것인가? -> 많이 쓰이지 않음)
A: 1이면, "data에 대한 Ack packet이다"라는 의미.
P: PUSH data now
(buffer에서 data를 관리하다가 다 될때까지 application에 올려주는 것이 아니라 지금까지 받은 것을 application으로 올리라는 flag)
R(Reset), S(Syn), F(Fin):
connection establish(setup), termination에 사용하는 flag
➡️ 똑같은 TCP packet인데 사실 그 안에 두 종류의 packet이 있다.
(1) data packet(실제 data를 포함한 packet) (2) control packet(data와 상관없이 둘 간의 connection을 관리, 제어)checksum:
(UDP와 마찬가지로)16bit로 쪼개서 header부터 data까지 전체 보내는 data에 대한 checksum을 계산

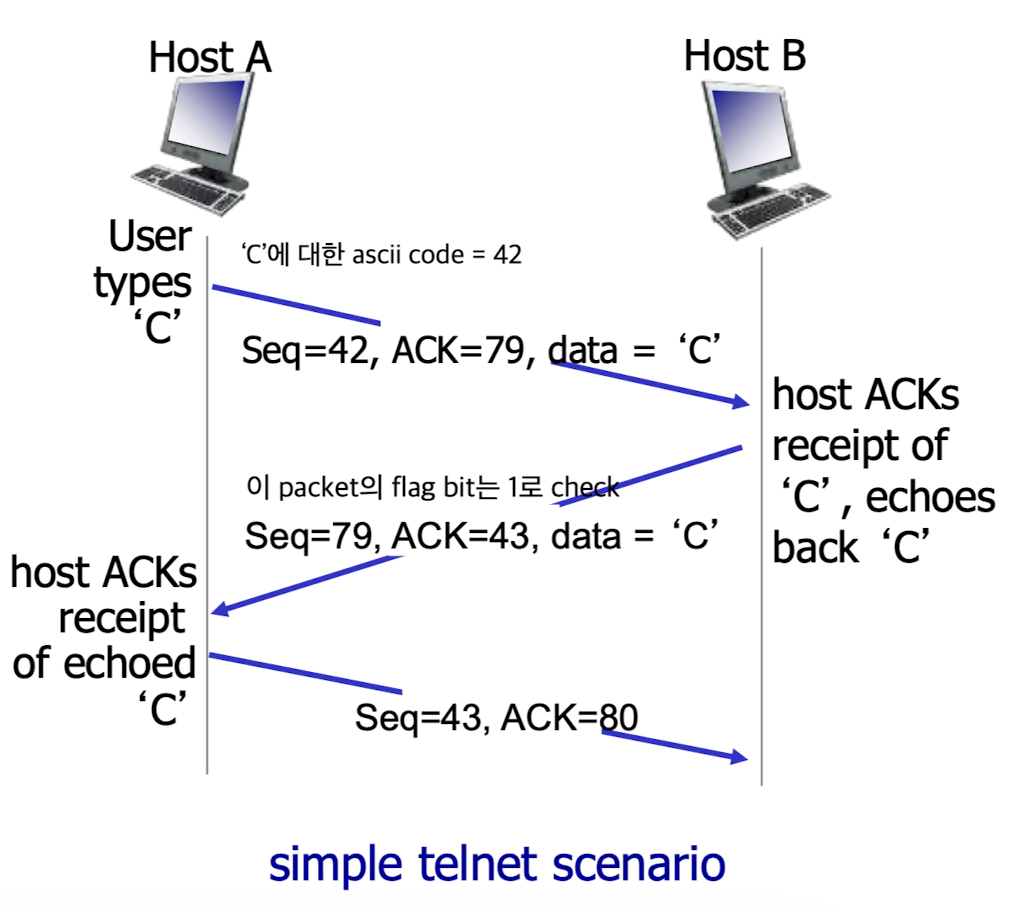
TCP seq #, ACKs
Loop back: 보낸 것을 그대로 돌려줌. (echo)
원래는
data ->
<- ack
data ->
<- ack
였는데...
이렇게 data와 ack를 동시에 보낼 수 있다.
seq=seq, ack=ack ->
<- seq=ack, ack=seq+1
TCP round trip time, timeout
-
TCP timeout value는 어떻게 설정하는가?:
TCP는 pipeline을 사용하는데, 기본적으로 GBN 방식을 사용한다. = Timer 1개만 사용한다.
network는 상황에 따라 RTT가 계속해서 다르기 때문에 timer를 고정된 값으로 설정하면 안된다.
따라서 RTT에 적합한 time을 setting하는 것이 중요하다.
따라서 지속적으로 RTT값을 monitoring하여 exponential weighted moving average를 통해
현재의 RTT 기대값인 EstimatedRTT에 조금 더 margin을 둬서time을 설정해야 한다. -
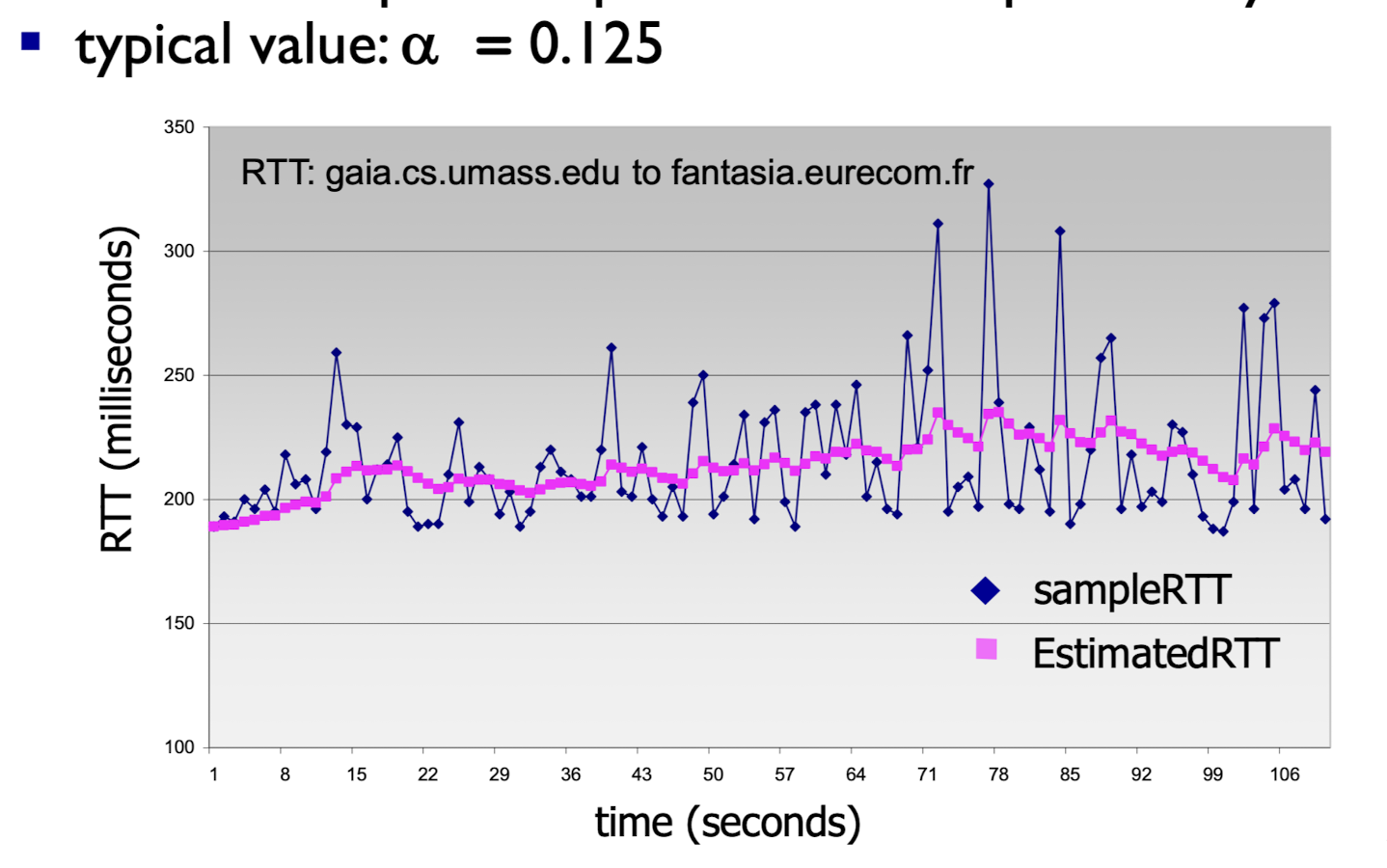
- 가 크면? 현재값에 weight를 더 주겠다.
- 가 작으면? 과거 값들의 추이에 weight를 더 주겠다.
➡️ smoothing
-
timeout interval: EstimatedRTT + "safety margin"
"safety margin" = (typically, ))

➡️ timer값이 너무 크거나 너무 작은 것을 방지하기 위해
과거부터 현재까지 RTT 변화추이를 잘 따라갈 수 있는 EstimatedRTT를 구할 수 있고,
그 값을 기반으로 safety margin을 둬서 최종적으로 TimeoutInterval을 구할 수 있다.
➡️ 하지만 위 방법이 최선은 아니고, 이 외에도 다양한 TimeoutInterval setting 방법(논문들)이 있다..
reliable data transfer
-
reliable data transfer는 TCP의 가장 핵심적인 기능 중 하나이다.
-
duplicate acks, flow control, congestion control을 무시하고 simplified TCP sender의 입장을 고려해보자.- 지금까지 배운거는 timeout될 때, 재전송했었는데
duplicate acks할 때도 재전송한다. (왜 그러는지는 나중에 배움)
- 지금까지 배운거는 timeout될 때, 재전송했었는데
-
TCP sender events:- application layer로부터 data를 받은 경우 :
- seq#로 segment들을 만듦.(data의 첫번째 byte값을 seq#로 설정)
- timer가 시작하고 있지 않으면 timer를 시작한다. (oldest unacked segment에 대한 timer)
- timeout된 경우 :
- segment 재전송
- restart timer
- unacked segment에 대한 ack를 받은 경우 :
- sliding window가 이동
- start timer(expiration interval : TimeOutInterval = EstimatedRTT + 4 * DevRTT)
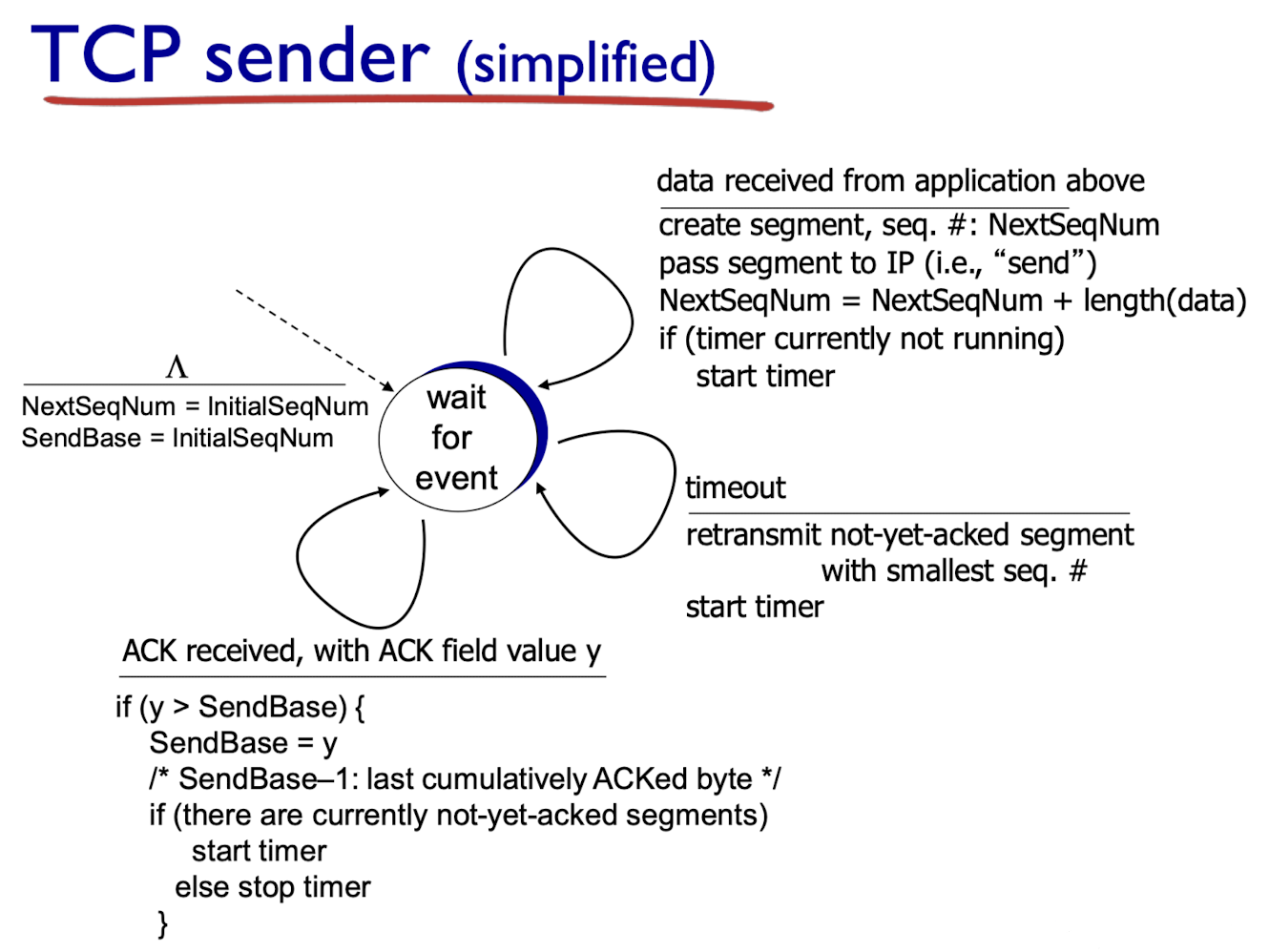
- application layer로부터 data를 받은 경우 :
retransmission scenarios
-
Lost ACK scenario:
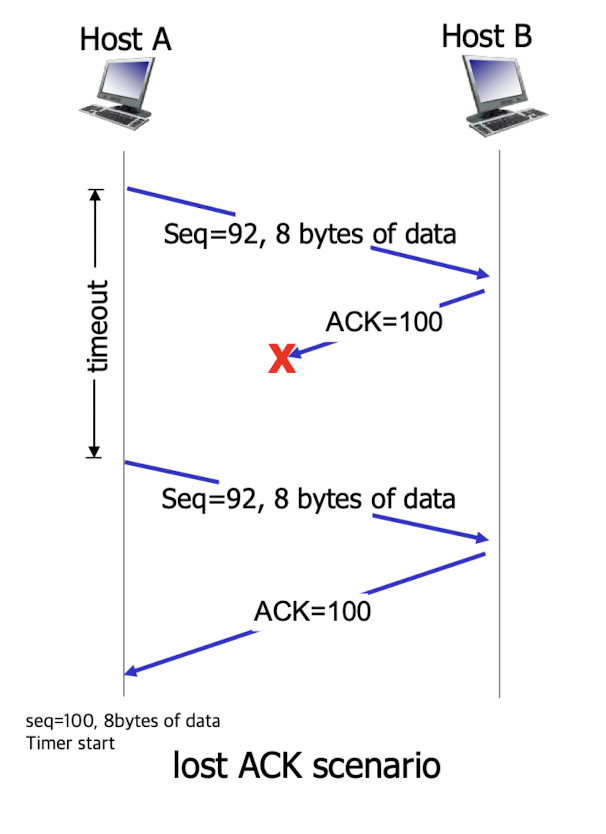
-
premature timeout:

-
cumulative ACK:
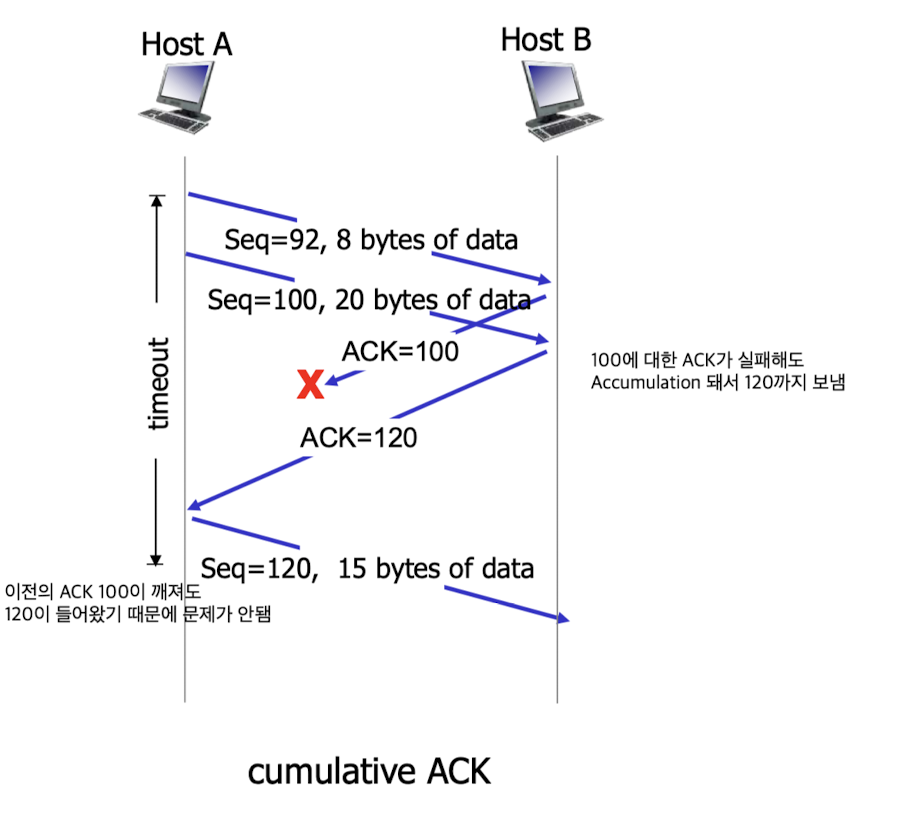
TCP fast retransmit
TCP fast retransmit:
timeout 징조가 보이기 전에 먼저 retransmit한다.
timeout 징조는 어떻게 아는가?
만약 sender가 duplicate ACK 3개를 받는다면, smallest seq #를 retransmit한다.
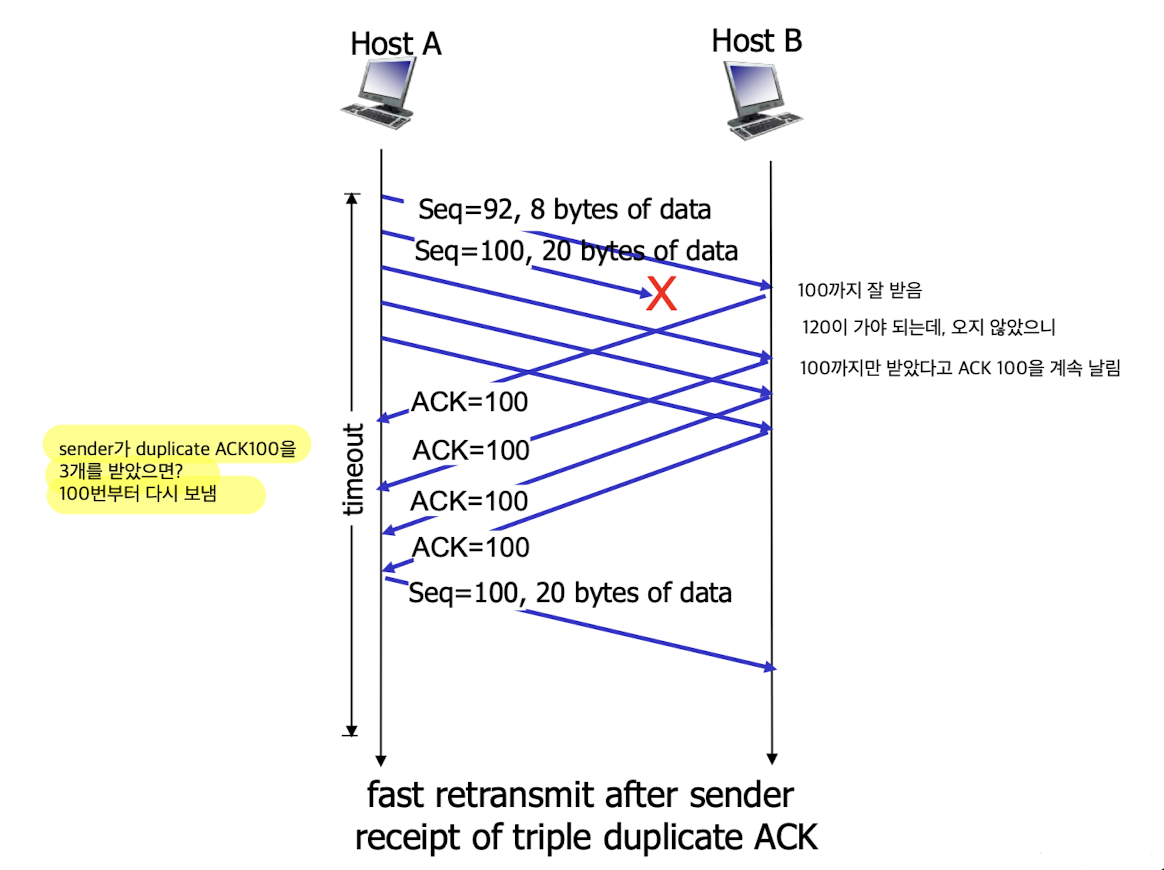
Flow Control
Flow Control: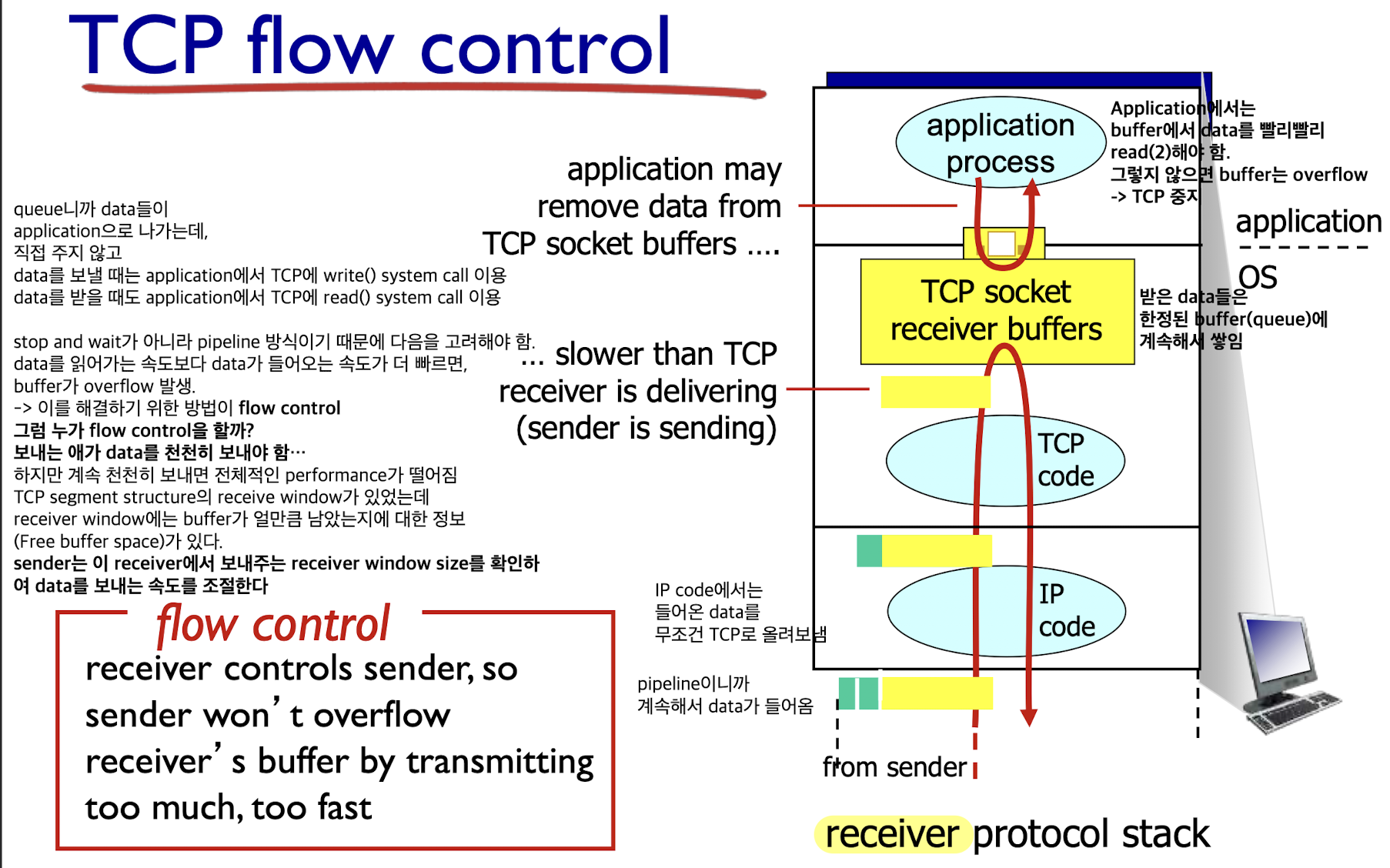
Flow Control은 receiver단에서 할 수 있는게 아무것도 없다.
receiver는 들어온 data를 buffer에 저장하고 application에서 읽기만 하기 때문에
sender가 data를 천천히 보내줘야 한다.
하지만 그렇다고 sender가 data를 계속해서 천천히 보낸다면,
전체적인 performance가 느려지기 때문에
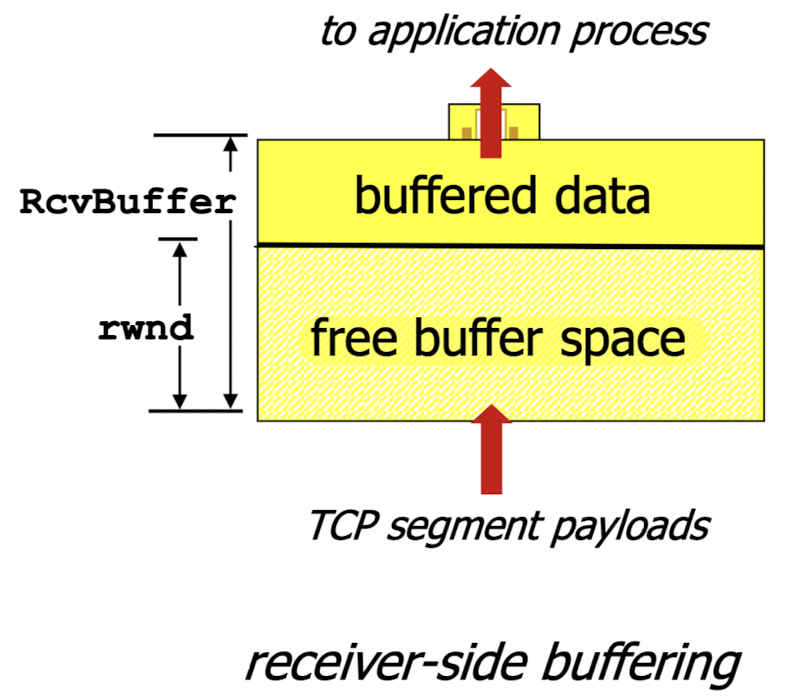
TCP segment structure의 receive window에
buffer가 얼만큼 남았는지(rwnd)를 sender에게 알려준다.
(free buffer space(rwnd) = 전체 buffer size - buffered data)
 그러면 sender는 receive window size를 보고
그러면 sender는 receive window size를 보고
overflow가 나지 않게 sender에서 flow control을 한다.
Connection Management
- TCP는 기본적으로 connection oriented이기 때문에
TCP connection을 먼저 수립해야 한다.
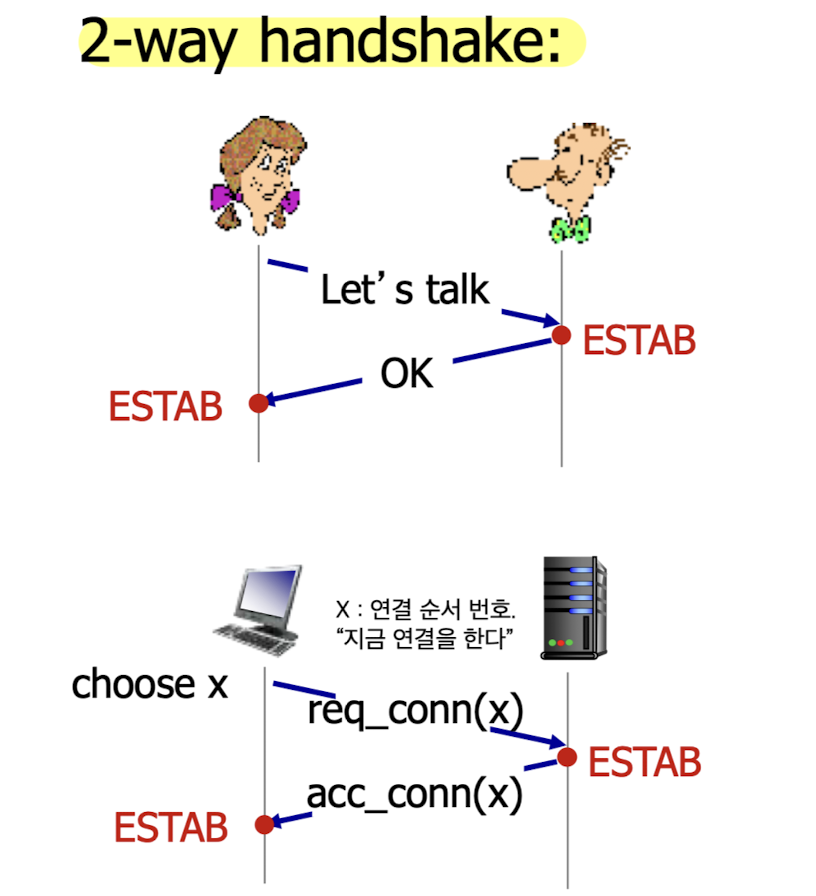
2-way handshake
-
2-way handshake:
가장 기본적인 connection 방법.
항상 client가 server에게 먼저 request한다.
-
하지만 2-way handshake가 문제가 되는 상황이 있다.
2-way handshake failure scenarios :
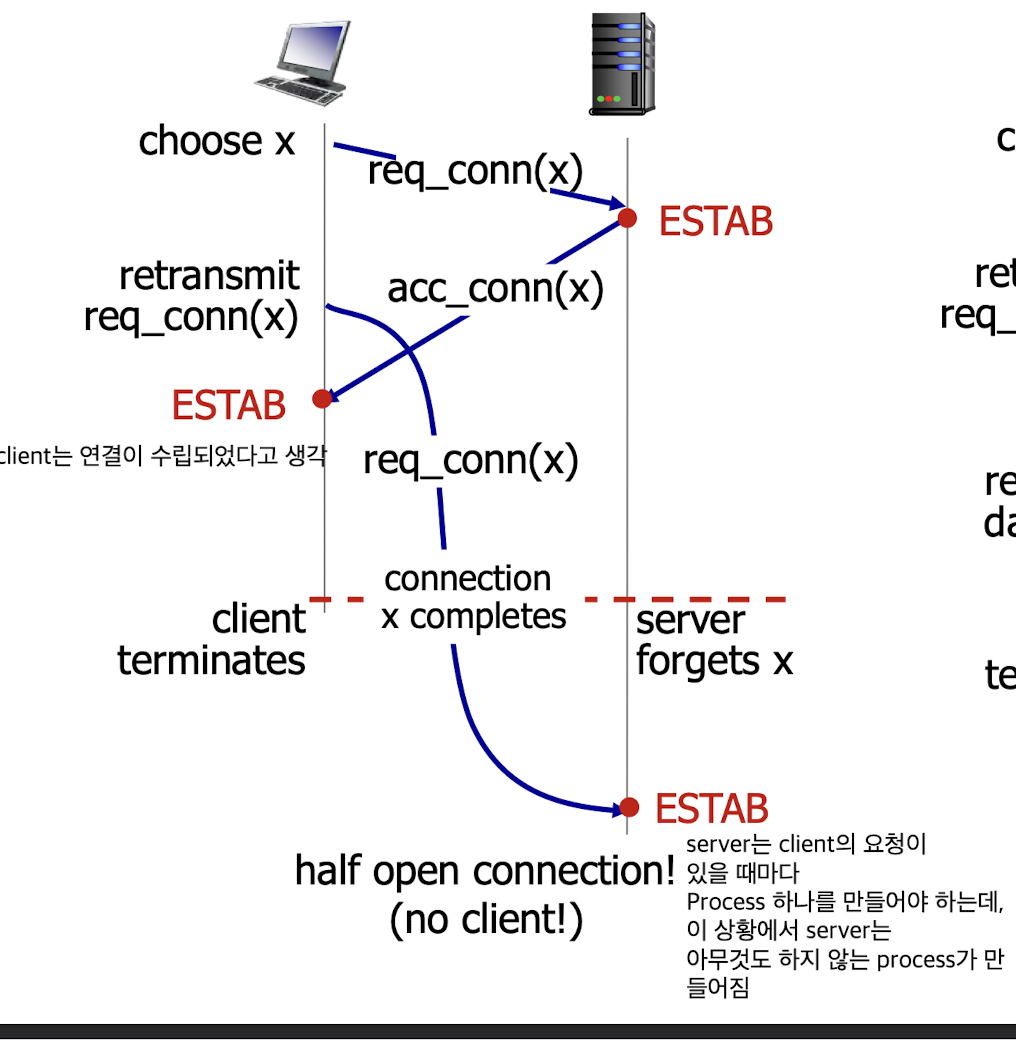
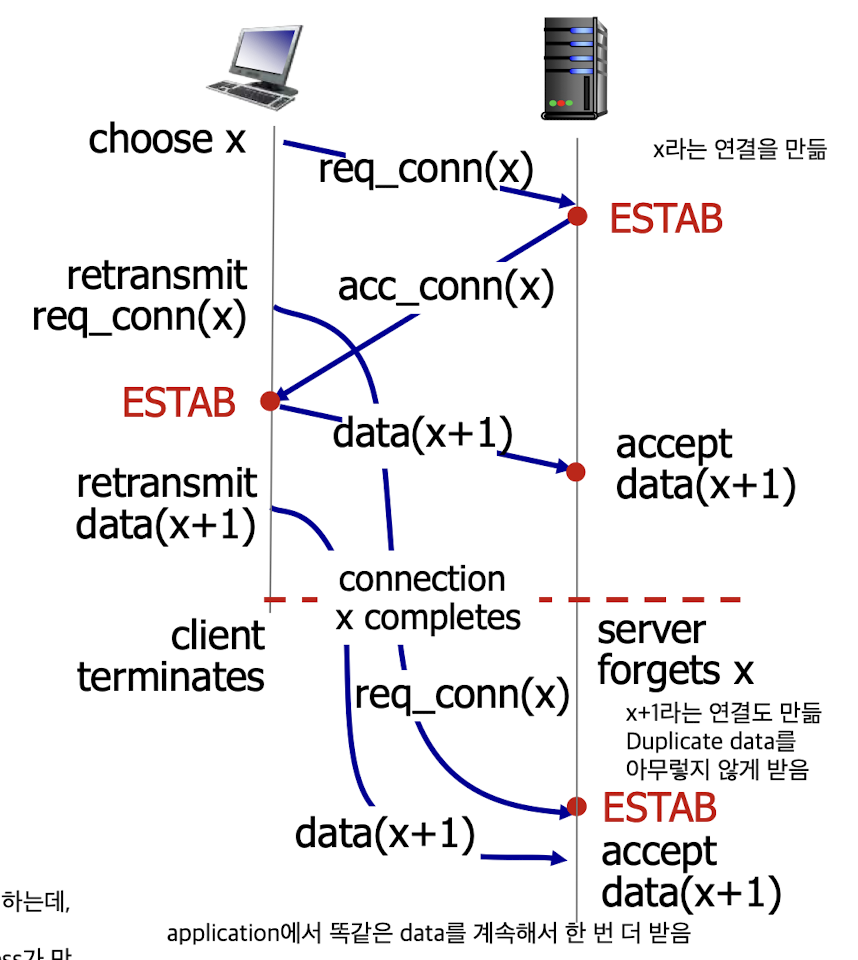
Client가 establish되기 전에
Server에서 establish가 먼저 되기 때문에 문제가 발생하는 것임.
그래서 TCP에서는 3-way handshake를 사용함
3-way handshake
3-way handshake:- establish a connection
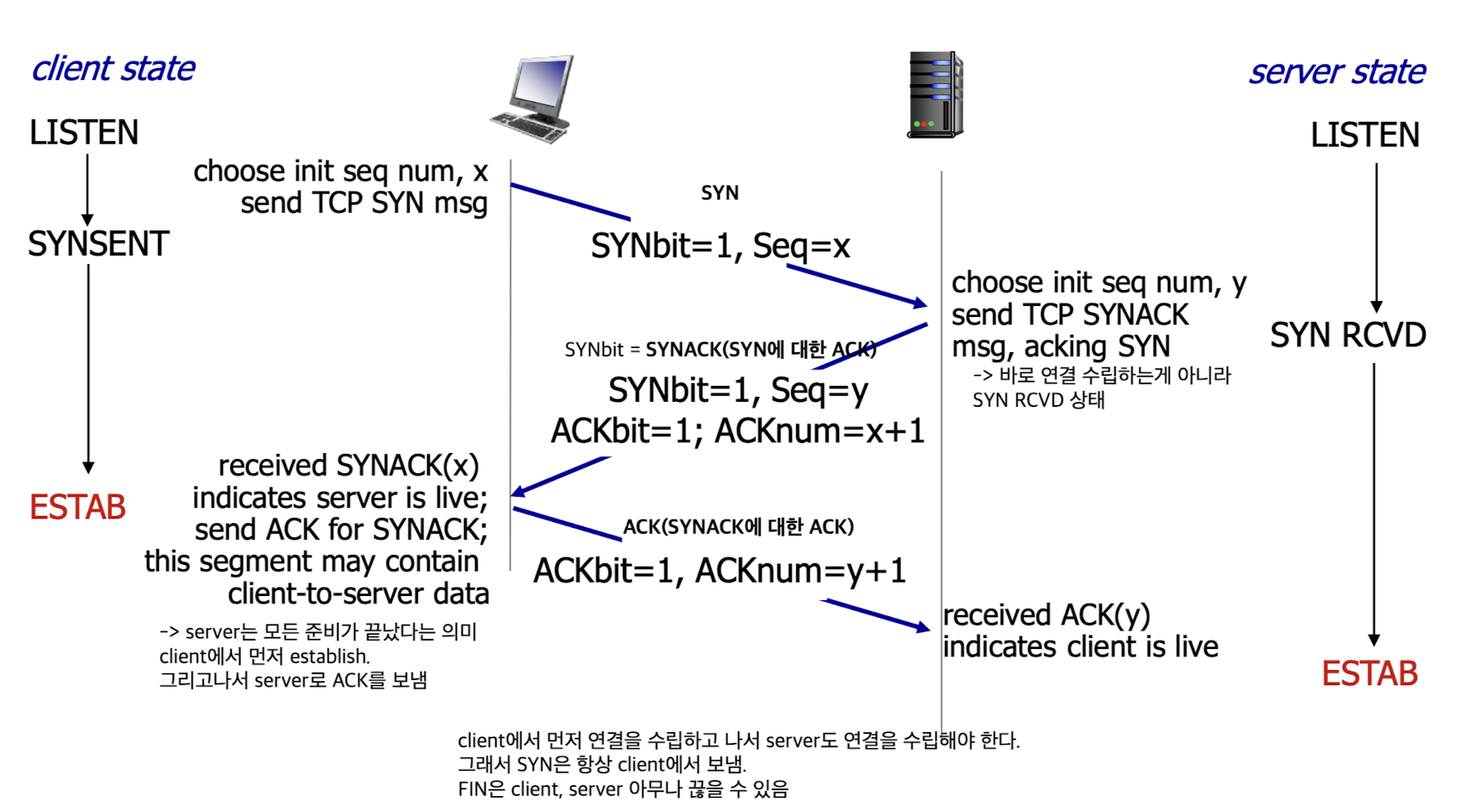
- closing a connection
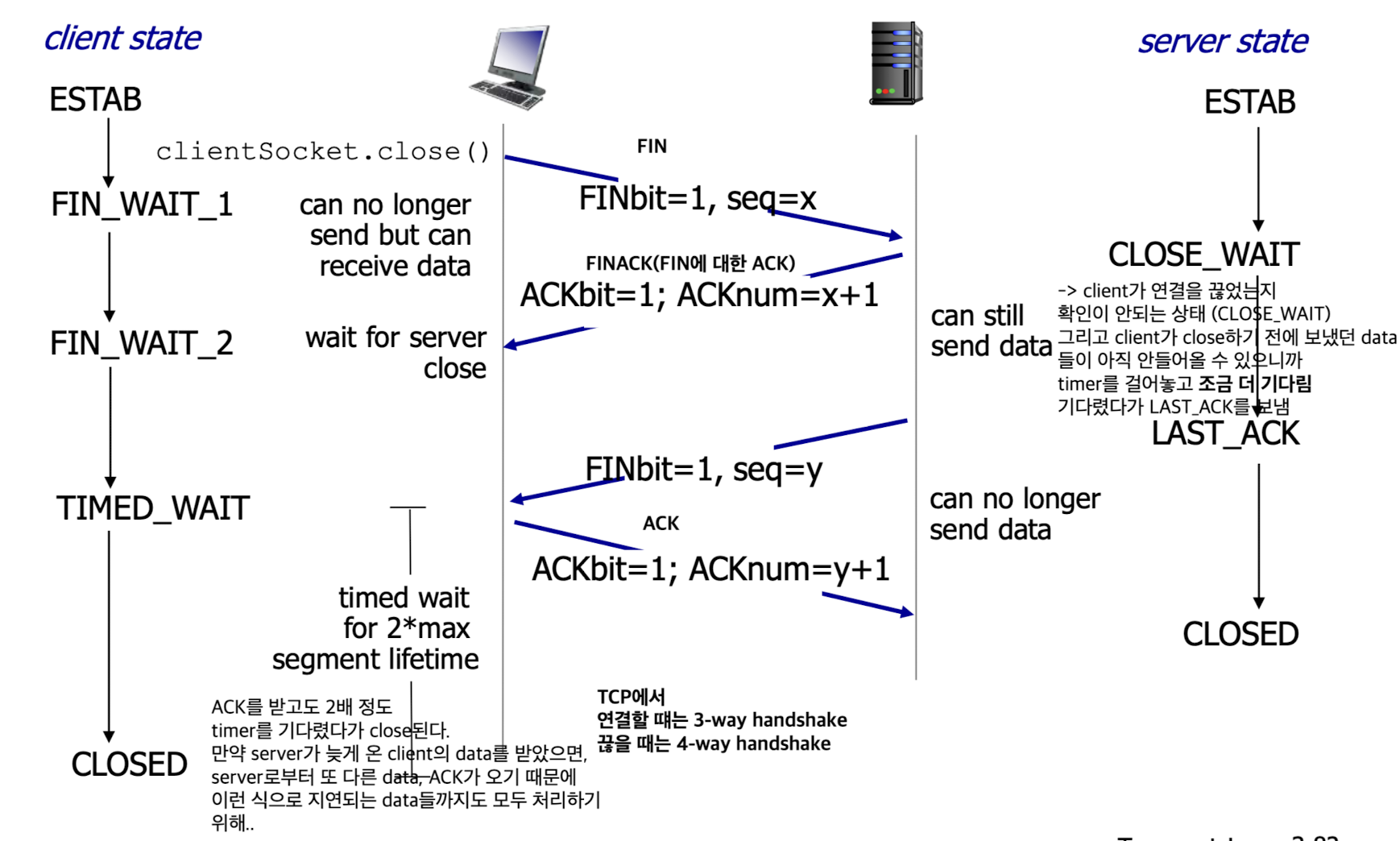
- establish a connection
3.6 principles of congestion control
-
Congestion control과 Flow control은 완전히 다르다.
Flow control은 network 상황과는 관계가 없다.
receiver application에서 얼마나 빠르게 읽어가서 buffer에 overflow가 발생하지 않는가에 대한 문제이다.Congestion control은 sender가 data를 빠르게 보내서 network core에 많은 data들이 loss되거나 delay되는 것을 해결하기 위한 문제이다.
하지만 책임은 core가 아니라 edge에 있는 host의 transport layer의 TCP에서 진다.
-
packet이 loss되거나 delay되는 것이 congestion 때문이다.
congestion되는 것은 sender에서 책임져야 한다.
congestion 문제는 NP problem이어서
논리적인 방법, 물리적인 방법(Link speedup)이 연구되어지고 있다. -
Congestion이 발생했는지 어떻게 아는가?
manifestations(조짐, 징후)가 있다.timeout이 빈번히 발생:
sender는 packet loss가 발생했음을 알 수 있다.delay가 길어짐:
sender, receiver 모두 알 수 있다.
data가 pipeline으로 보내지기 때문에 일정한 gap을 두고 data가 들어온다.
receiver는 gap이 점점 늘어난다면 delay가 발생했다고 판단할 수 있다.
sender는 RTT가 점점 늘어난다면 delay가 발생했다고 판단할 수 있다.
-
Congestion 발생 scenario :
Packet loss가 되면, timeout, 재전송
원래 data가 빨라서 생기는 문제도 있지만
재전송되는 data도 network로 같이 들어가는 것도 문제임.
data가 보내지고 있는 중에 timeout이 걸려서 재전송 된다면
original data와 retransmission data들은 network에 함께 존재
➡️ 계속해서 악화되는 congestion
throughput R/2를 넘어서는 순간 꽉 막혀버린다..
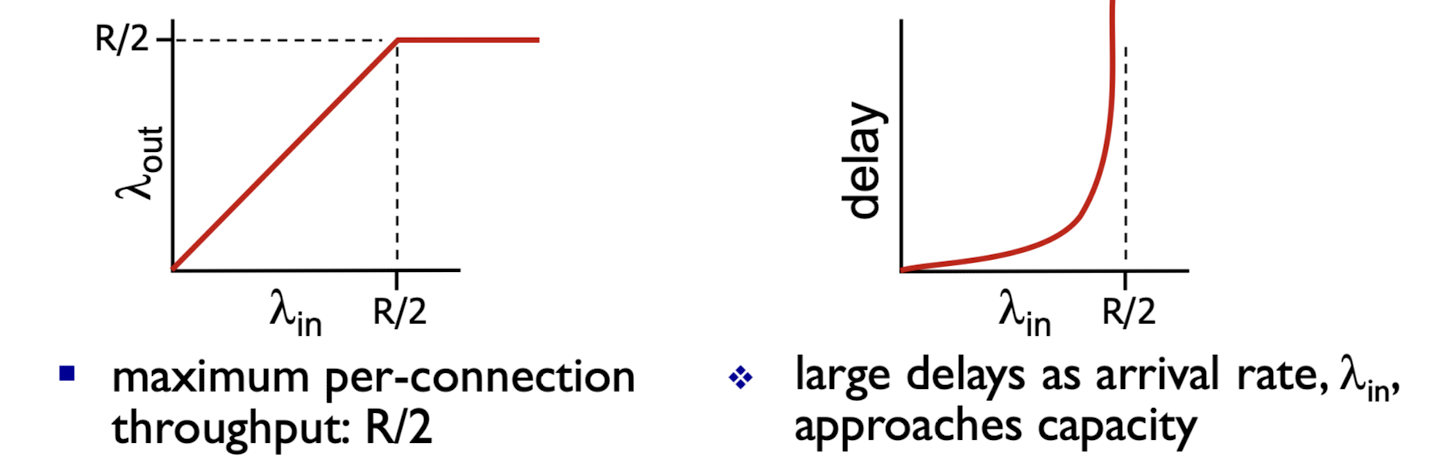
3.7 TCP congestion control
-
TCP의 기본 철학
- fair (congestion control을 application에서 하지 않고, TCP에서)
- adaptive (network 상황에 맞게)
-
그러면 TCP에서는 congestion을 어떻게 control할 것인가?
AIMD(Additive Increase Multiplicative Decrease)Slow Start
1. AIMD(Additive Increase Multiplicative Decrease)
AIMD(Additive Increase Multiplicative Decrease)
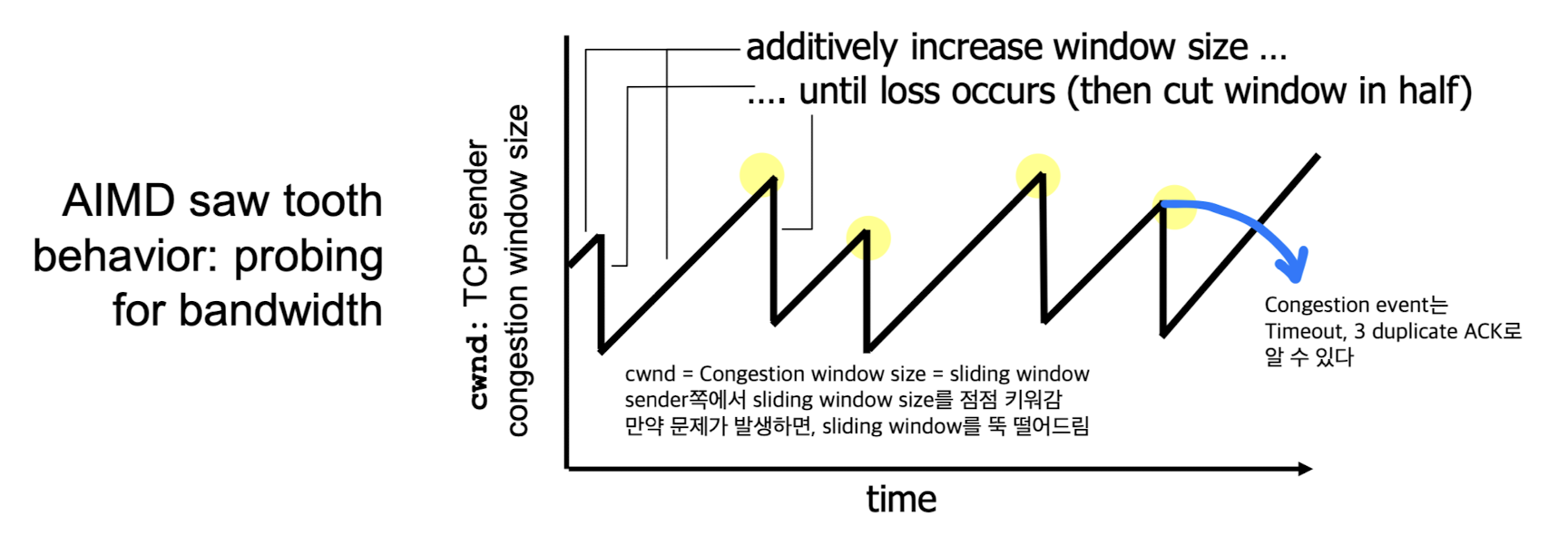
2. Slow Start
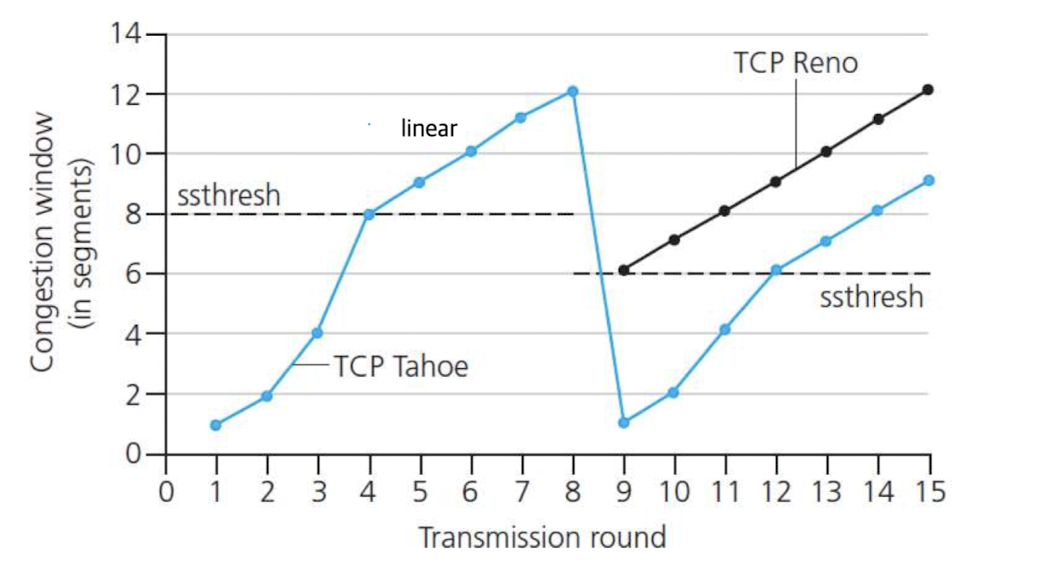
Slow Start:
exponential하게 가다가
ssthresh부터 linear하게 증가함.
그러다가 congestion(timeout, 3 duplicate ACK)이 발생한다면?
TCP Tahoe, TCP Reno 방식에 따라 각각 다르게 동작한다.timeout이 발생한 경우(가장 심각한 경우):
TCP Tahoe와 TCP Reno 모두 cwnd = 1로3 duplicate ACK가 발생한 경우:
TCP Tahoe는 cwnd = 1,
TCP Reno는 cwnd = ssthresh(ssthresh = 직전에 congestion이 발생한 지점의 cwnd / 2)
Why is TCP fair?
-
나의 cwnd가 작을 때,
다른 client의 cwnd는 커서
불공평한 상황이 있지 않나?
➡️ 아니다.
시간이 지나면서 equal bandwidth share로 수렴하기 때문에 fair하다.
congestion이 발생하면, 나만 천천히 보내는 것이 아니라 다른 client들도 상황을 인지하고 천천히 보내고 있을 것이다.
➡️ 또한 TCP는 OS 하나의 task이고
TCP에서는 이러한 일을 계속해서 하고 있기 때문에 overhead가 꽤 큼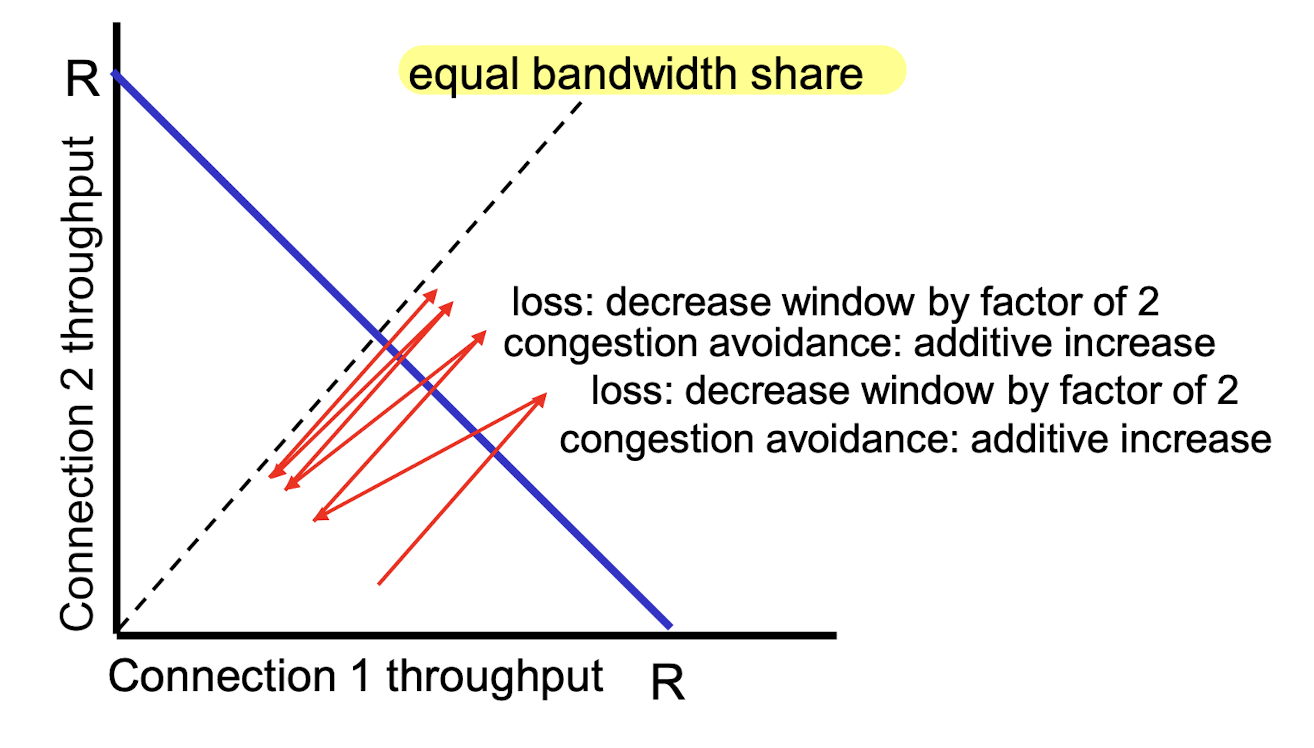
-
한 application에서 TCP를 여러개 만들 수 있음
만약 3개 만들었다면, 3개는 별도로 연결 수립이 이루어짐
그러면 여기서의 congestion control은 한 연결 당 하나씩 TCP congestion이 이루어짐.
앞서 한 TCP 연결마다 fair하다고 했는데,
이것을 역이용하는 방법이 있다
➡️ application에서 조작하는 것.
한 computer에서 TCP를 parallel로 여러개 만듦.
link가 R이고 이미 서로 다른 9개의 TCP connection이 있다고 가정.
나도 새로운 application의 TCP를 넣으면 총 10개.
처리할 수 있는 rate는 각각 R/10이므로 fair함.
그런데 만약 내가 11개의 TCP 연결을 parallel하게 만든다면,
총 20개 중에 나의 TCP가 11개가 된다.
그러면 그 link의 (11/20)*R만큼의 rate를 제공받아서 절반 이상의 TCP rate를 제공받을 수 있다.
web server에 이러한 꼼수를 이용함.
원래는 web server에 TCP 1개를 연결하여 object를 순차적으로 1개씩 가져오는데,
object수만큼 parallel하게 TCP를 연결해서 한 TCP 당 한 object를 가져와서 매우 빠르게 받을 수 있다.
Explicit Congestion Notification (ECN)
-
Congestion control은 sender가 data를 빠르게 보내서 network core에 많은 data들이 loss되거나 delay되는 것을 해결하기 위한 문제이다.
하지만 책임은 core가 아니라 edge에 있는 host의 transport layer의 TCP에서 졌었다. -
network-assisted congestion control:
또 다른 기술로 network layer에서 직접 congestion 문제를 해결하려는 기술이 있다.
IP header에 ToS (Type of Service)라는 field가 있다.
network router가 congestion이 일어났으면?
ToS field에 ECN bit에 congestion이 일어났다고 명시적으로(explicit) flag를 올려준다.
Destination에서는 TCP ACK segment 안에 ECN bit를 set하여 다시 보내준다.
➡️ 사실 거의 안쓰이는 알고리즘이다.
Network Layer
- 다음에 배울 Network Layer :
network core에는 router밖에 없음.
예전에는 Dijkstra algorithm 같이 최적화, 최단경로를 배웠는데
최근에는 SDN이라는 최신 기술이 있어서 배우지 않음...
