Machine learning framework
steps- training image image들로부터 feature를 뽑아내어 vector로 변환한다.
그 vector들을 training시키고, label 로부터 Loss를 측정하여 parameter 를 찾는다.
학습된 parameter 는 라는 linear classifier로 동작한다.
testing(=inference) 동안에는 학습된 로 test data에 대하여 prediction을 예측한다.
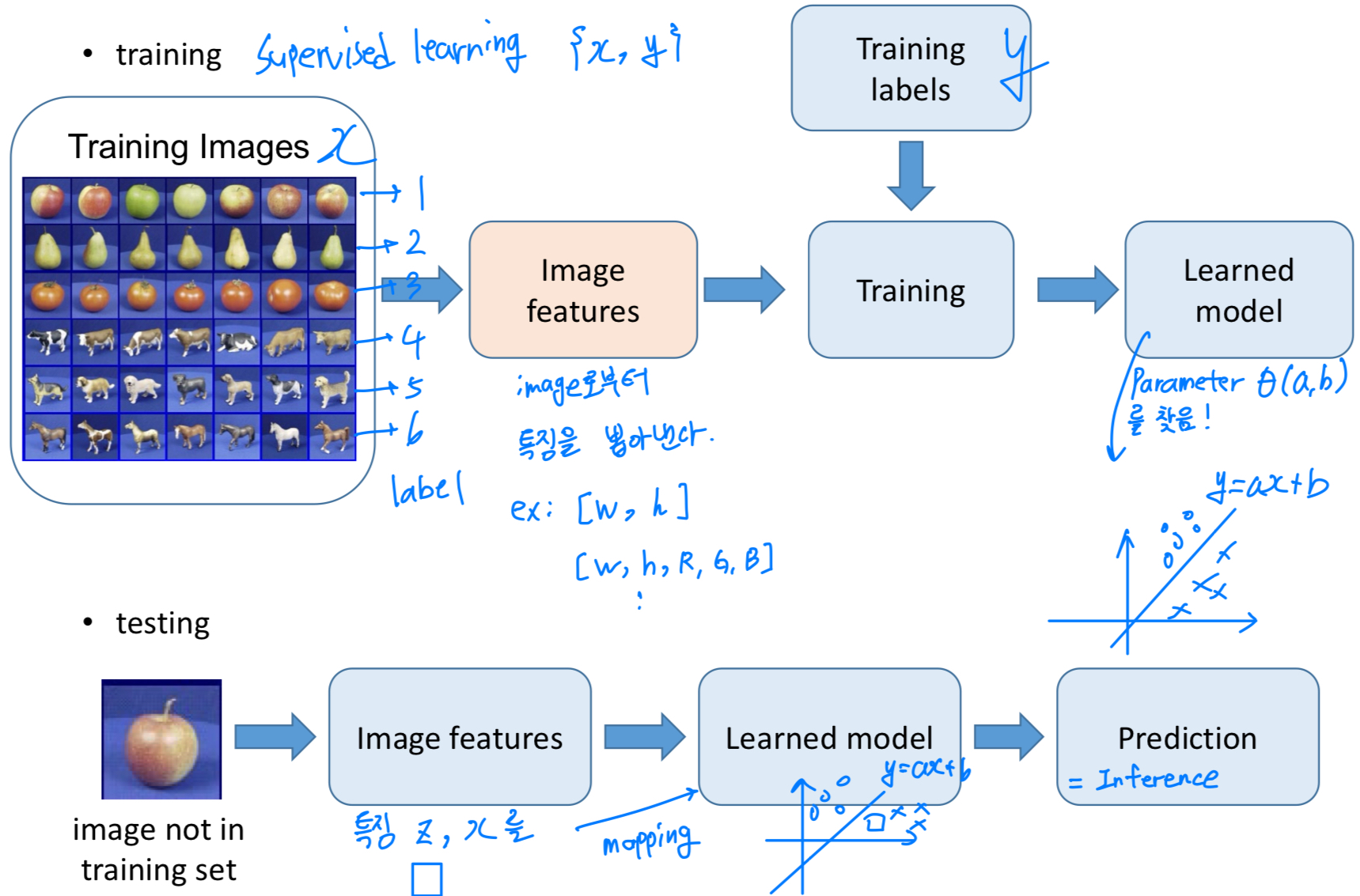
- apply a prediction function to a feature representation of the image to get desired output .

- training image image들로부터 feature를 뽑아내어 vector로 변환한다.
features: feature를 만들어내는 방법- raw pixels : Deep Learning
- histograms
- templates
- local descriptors
예전에는 handcraft(수작업)으로 A라는 기준, B라는 기준, ... 등에 넣어서 feature를 찾아냈었는데
최근에는 raw pixel 자체를 입력으로 넣어서 model에서 알아서 특징을 추출해주기를 바라는 추세...
Supervision:
어떠한 supervision('label')을 고려해야 할까?
image에 대응되는 납득할 만한 label을 지정해줘야 한다.
label의 종류는 다양할 수 있다.
object detection을 위한 bounding box,
segmentation을 수행하기 위해서는 object의 boundary,
detail object를 찾기 위해서는 handle, wheel, 등 여러 방법으로 annotation할 수 있다.

unsupervised: label이 전혀 없는 경우weakly supervised: image-level label이 있는 경우 (label이 하나)fully supervised: pixel-level label이 있는 경우 (label이 많음)
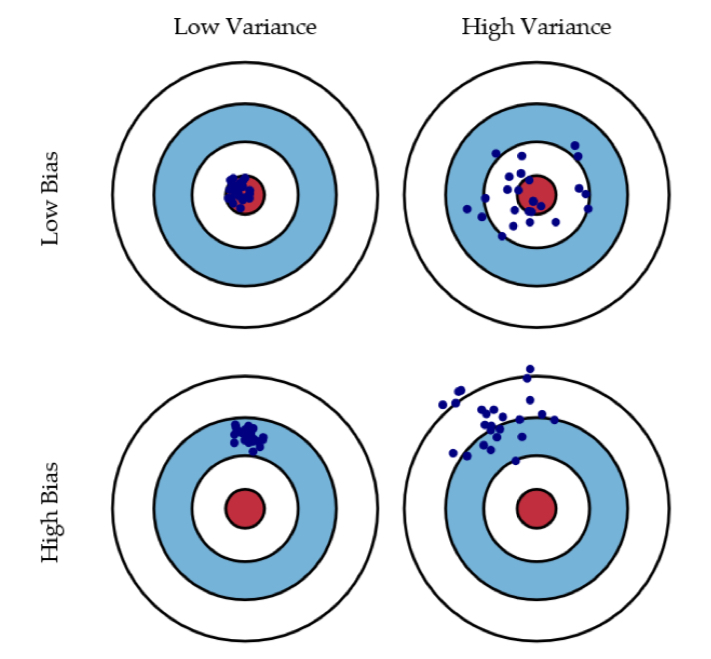
Bias-Variance trade-off
-
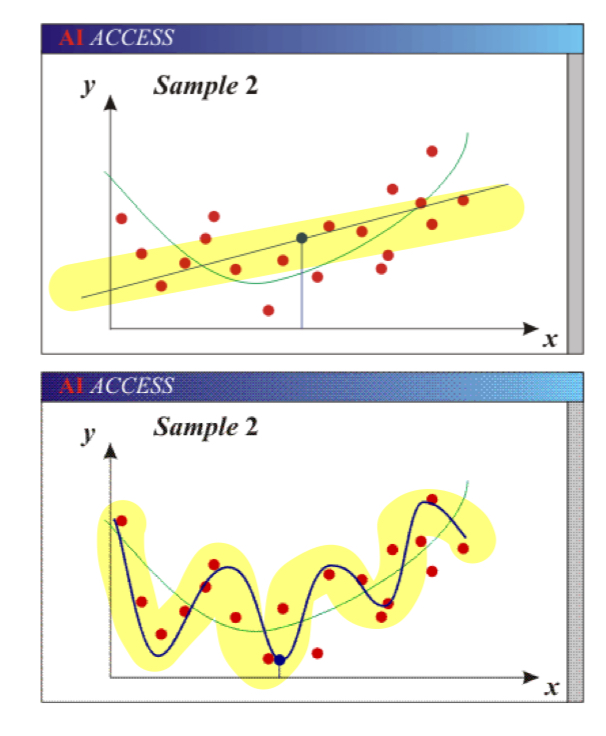
bias: high bias and low variance -> underfitting. model is too simple(too few parameters) -
variance: low bias and high variance -> overfitting. model is too complex(too many parameters)

-
Complexity & Training Error
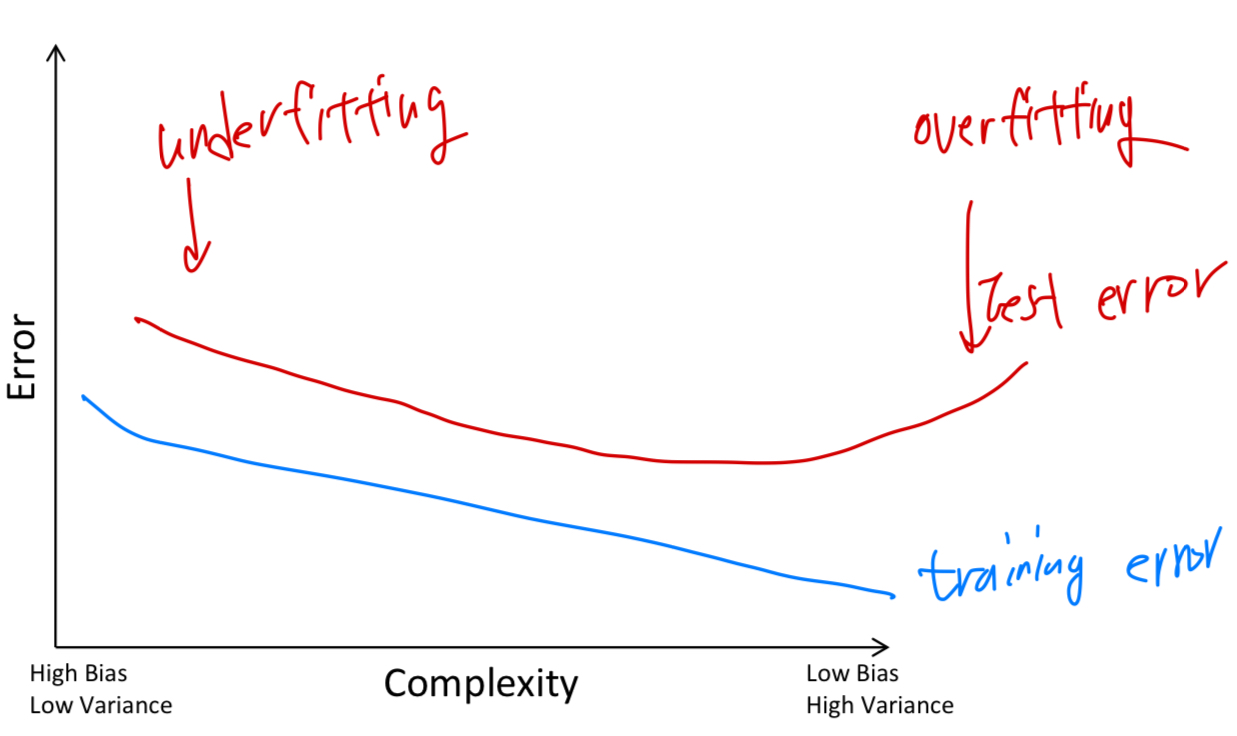
-
Complexity & Test Error
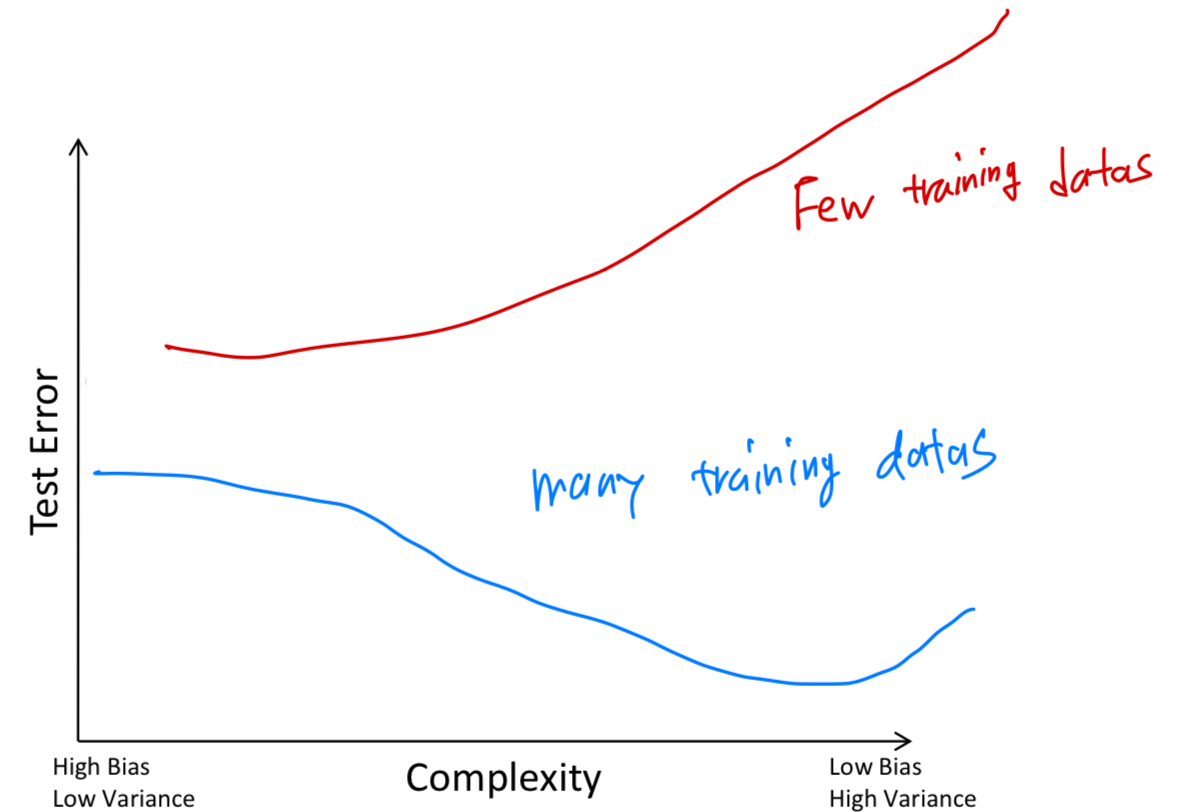
-
#Training Examples & Error

The perfect classification algorithm
- objective function = Loss function을 정의하여 Loss가 최소값을 가지도록해야 함
- parameterization : 복잡도를 적절히 설정해야 함
- regularization : training data에 대한 적당한 regularization 필요
- training algorithm : SGD, Adam 등 optimizer 필요
- inference algorithm
Three kinds of error
- inherent : 어쩔 수 없는 error = noise
- bias
- variance
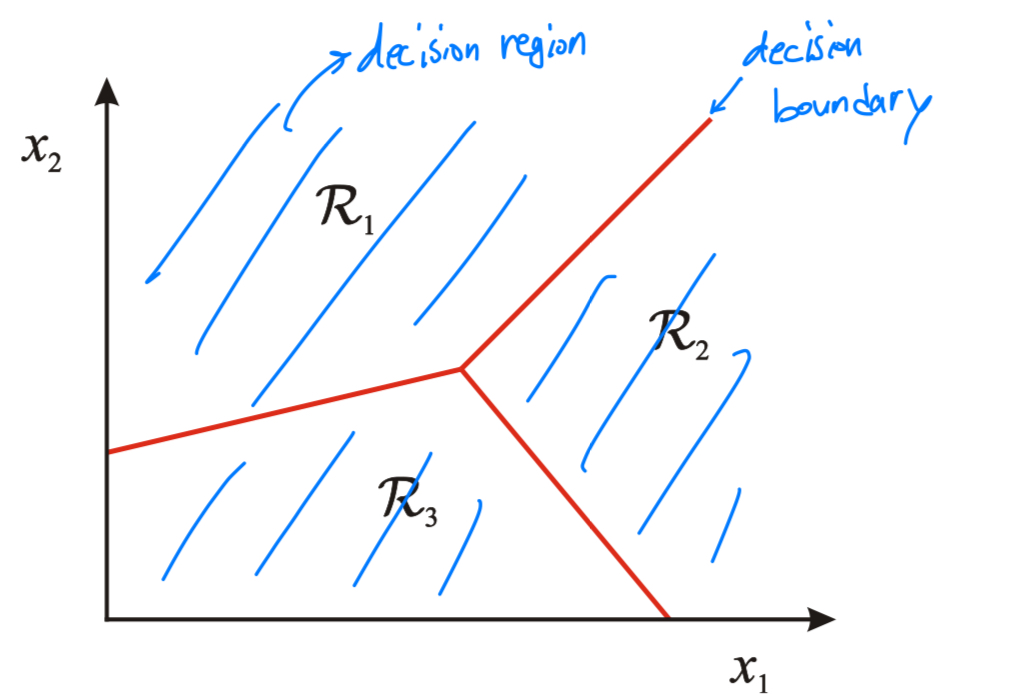
Classification
Classification: input vector를 2개 이상의 class 중 하나의 class에 할당하는 것.
Generative vs Discriminative
- classifier는 크게 두 가지로 분류된다.
Generative model:
learn joint distributionDiscriminative model:
learn conditional distribution
Many Classifiers
- SVM
- Neural Networks
- Naive Bayes
- Bayesian network
- Nearest Neighbor
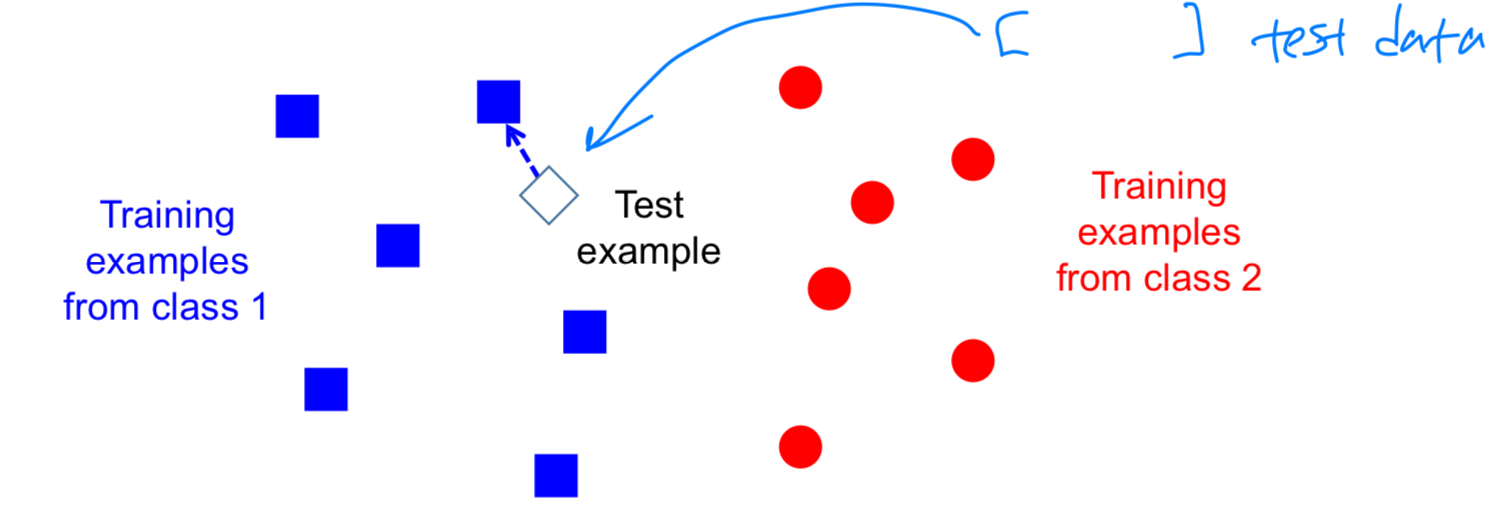
Nearest Neighbor (NN)
- 인접한 class로 test data의 class를 할당한다.
decision boundary를 만들 필요 없이 정해져 있는 class들 중에서 가까운 class로 할당.
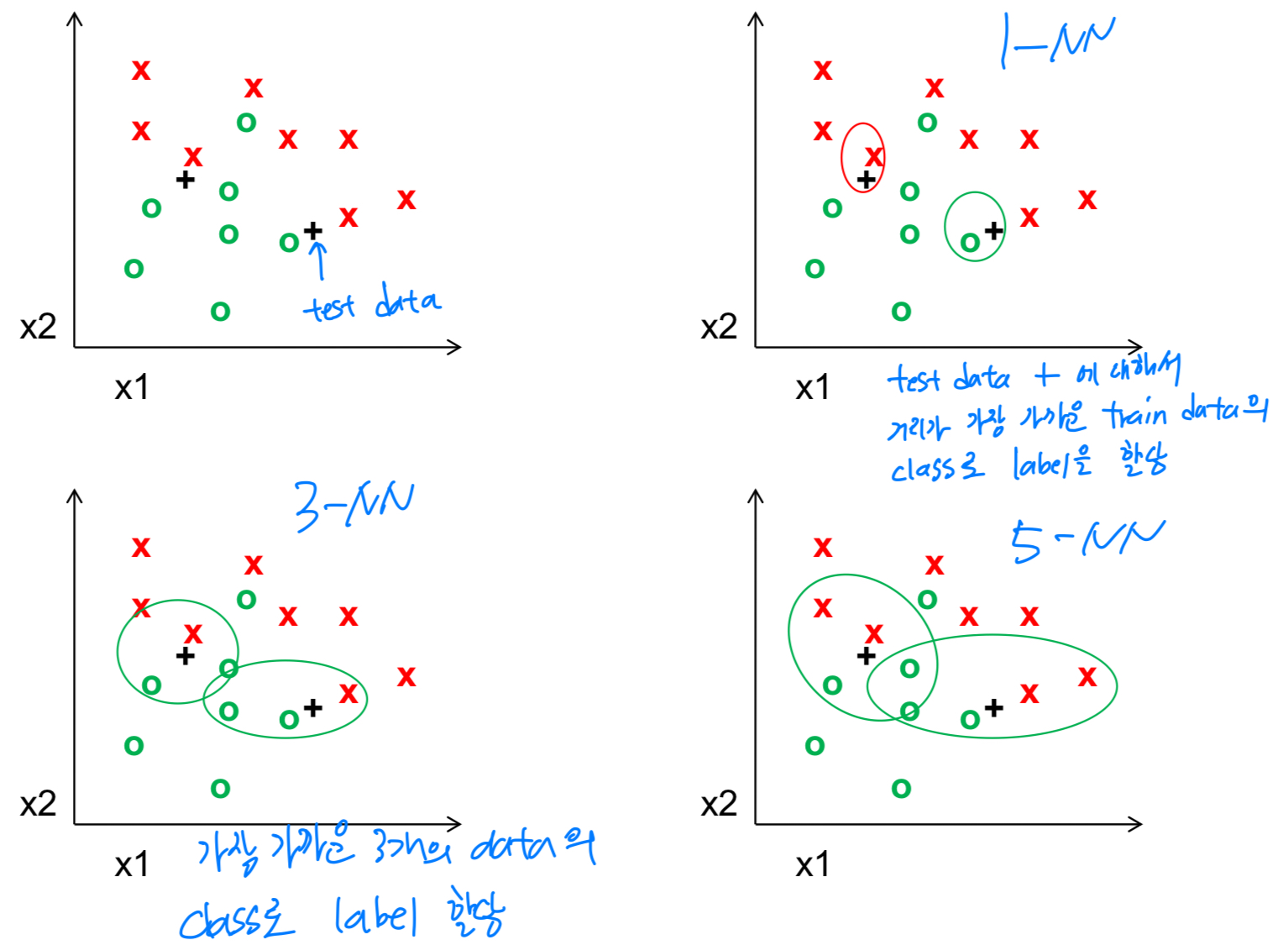
K-nearest neighbor
Linear SVM
- 를 1 or 0의 값을 갖도록 sign()을 적용한다.
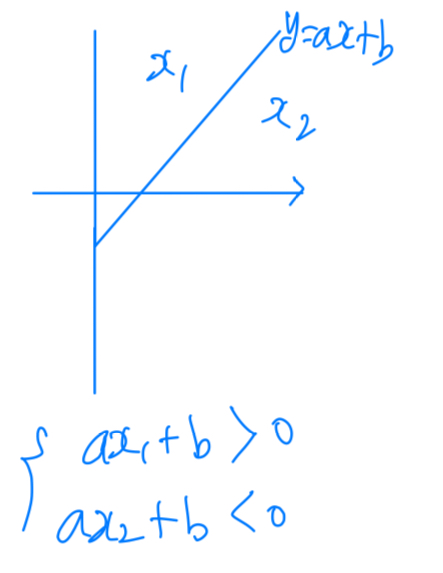
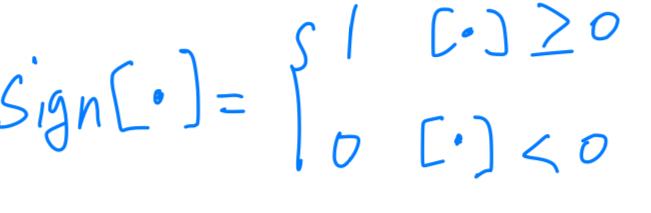
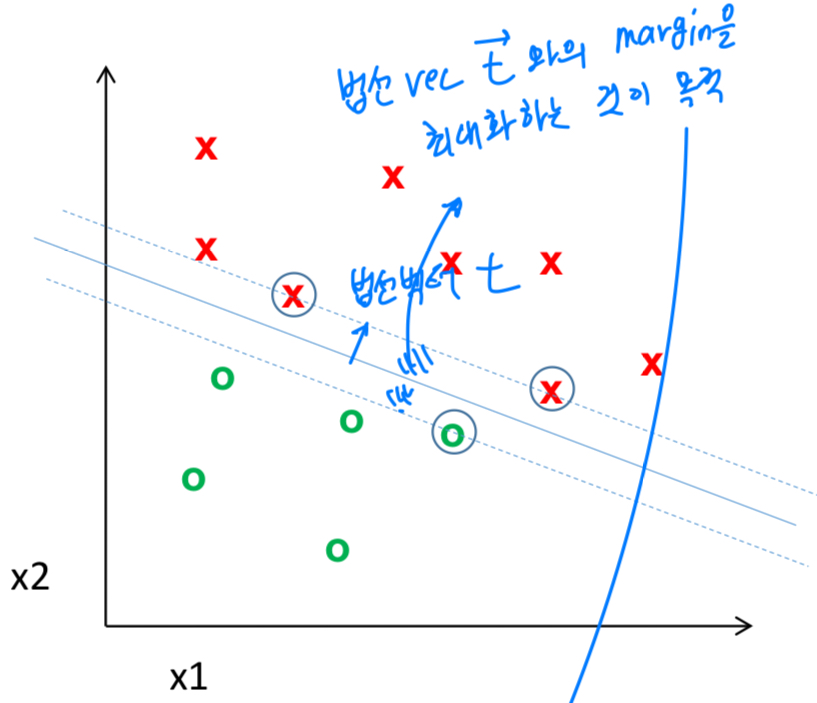 그어진 와 법선 vector 가 만드는 margin을 최대화하는 것이 목적이다.
그어진 와 법선 vector 가 만드는 margin을 최대화하는 것이 목적이다.
하지만 아래와 같이 선형 분리가 불가능한 경우도 존재한다.
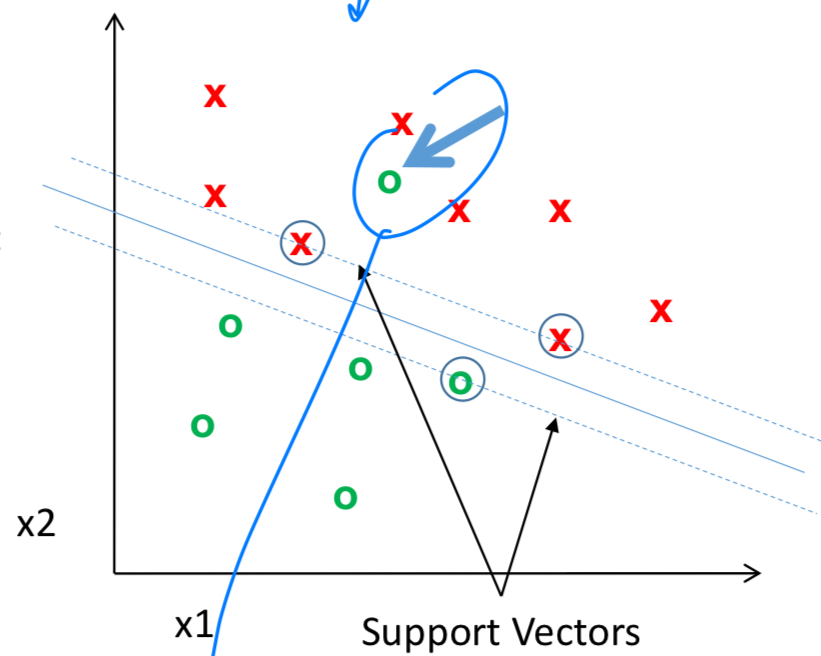 그래서 Nonlinear한 classifier를 도입해야 한다.
그래서 Nonlinear한 classifier를 도입해야 한다.
Nonlinear SVM
-
직선 1개로 분리가 불가능한 상황에서
kernel trick과 유사하게,
original dimension high-dimension으로 Transformation을 통해 새로운 feature space를 만든다.
즉,kernel trick은 선형 분리가 불가능한 경우에 선형 분리가 가능하도록 도와준다.
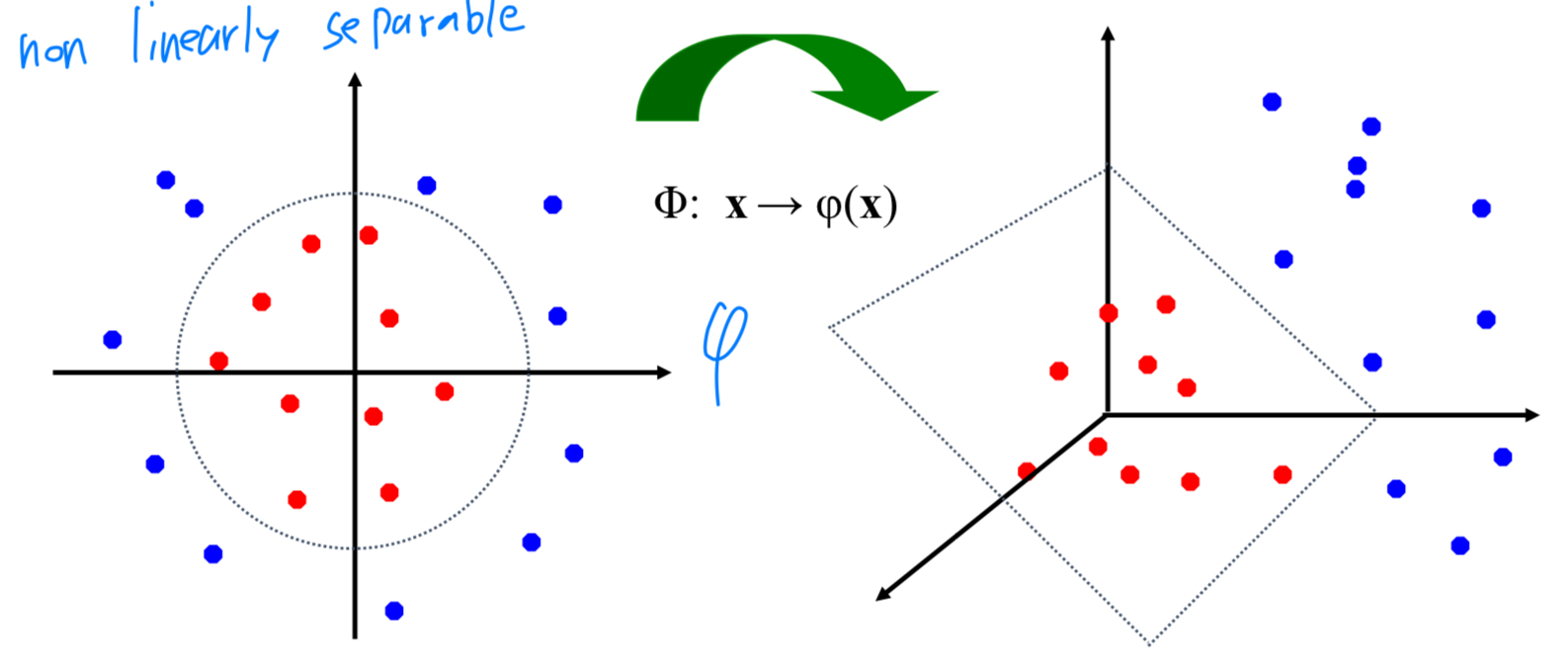
-
장점:- SVM은 Neural Network가 나오기 전에 가장 많이 사용되었다.
- kernel-based framework는 매우 강력하다
- SVM은 적은 training example에 대해서도 잘 동작함
-
단점:- 직접적으로 multi-class classification을 할 수 없어서,
one-versus-others 방식을 반복적으로 수행해야 한다.
따라서 computation, memory 비용이 높다.

- 직접적으로 multi-class classification을 할 수 없어서,

Efficient Deep Learning