CvT: Introducing Convolutions to Vision Transformers
Paper Info.
- Wu, Haiping, et al. "Cvt: Introducing convolutions to vision transformers." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
Abstract
-
이 논문에서
Convolution vision Transformer(CvT)라는 새로운 architecture를 소개한다.
이는 ViT의 performanc와 efficiency를 개선하기 위해
convolution을 ViT에 도입하여 두 design의 장점을 모두 제공한다. -
이를 위해 두 가지 주요 수정 사항을 도입했다.
- 새로운 convolutional token embedding을 포함하는 hierarchy of Transformers
- convolution projection을 사용하는 convolution Transformer block
이러한 수정 사항은 ViT architecture에 CNN의 바람직한 properties(i.e. shift, scale, and distortion invariance)을 도입하면서도
Transformer의 장점(i.e. dynamic attention, global context, and better generalization)을 유지한다.
-
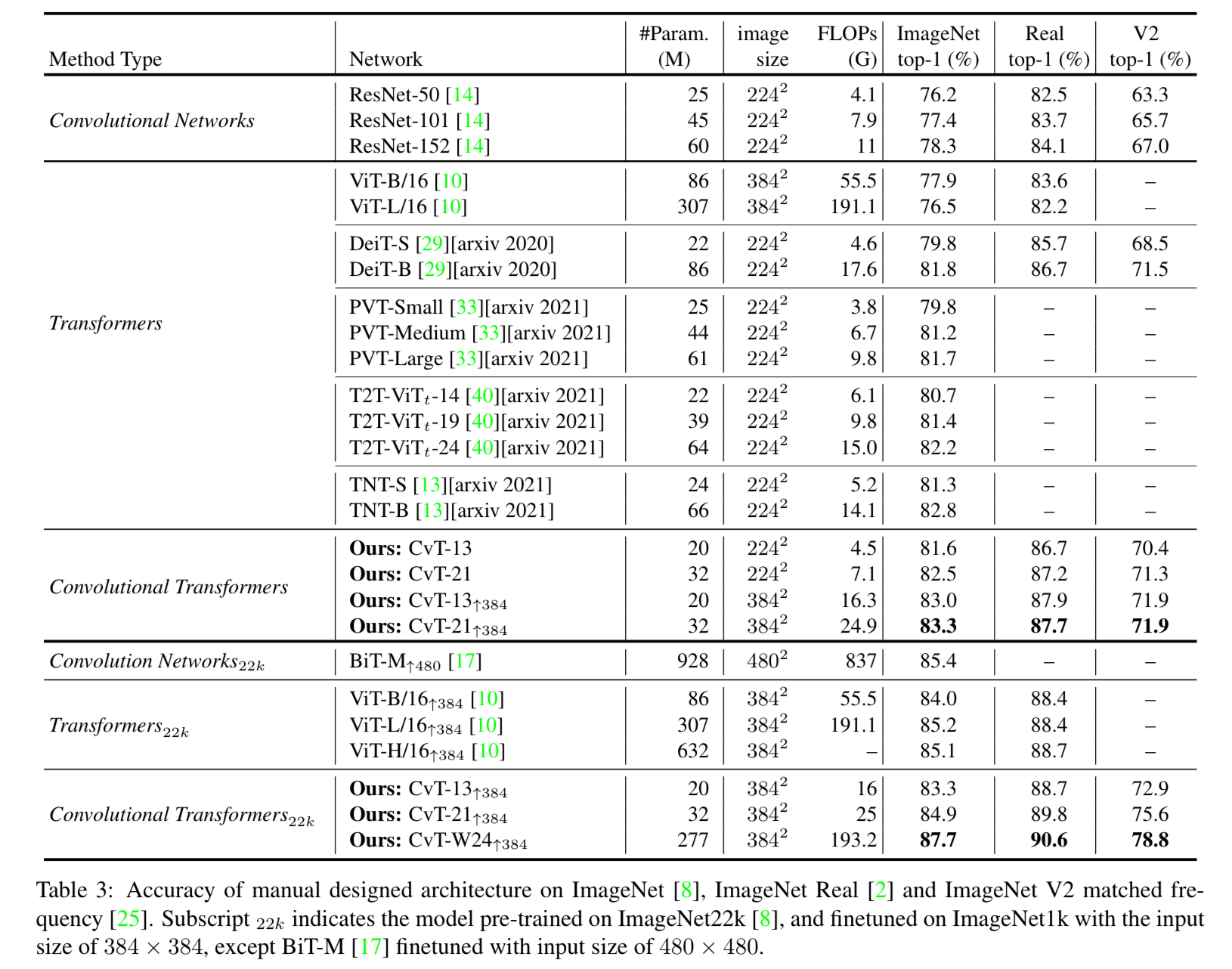
우리는 CvT가 ImageNet-1K에서
fewer parameters and lower FLOPs로도 SOTA를 달성하면서,
다른 Vision Transformers와 ResNets을 능가하는 성능을 보여주는 광범위한 실험을 통해 검증했다. -
또한 더 큰 Dataset(e.g. ImageNet-22K)에서 Pretrained되고 downstream 작업에 맞추어 finetuning될 때도 성능 이점을 유지한다.
ImageNet-22K에서 Pretrained된 CvT-W24는
ImageNet-1K val set에 대해서 87.7% top-1 accuracy를 달성했다.
(Code will be released at https: //github.com/microsoft/CvT)
1. Introduction
-
Transformer는 NLP task에서 다양하게 사용되고 있다.
ViT는 large scale에서 경쟁력 있는 image classification 성능을 얻기 위해 Transformer architecture에만 의존하는 최초의 computer vision model이다. -
ViT design은 language understanding을 위한 Transformer architecture를 최소한의 수정으로 만들어졌다.
먼저, image를 개별적인 non-overlapping한 patches로 분할한다.
그 다음, patch들은 NLP에서의 token으로 취급되며, positional encoding과 함께 합산되어,
global relations을 modeling하기 위해 반복되는 standard Transformer layer에 입력된다. -
Vision Transformer가 큰 성공을 이뤘음에도 불구하고,
적은 양의 Data로 traing할 때는 유사한 크기의 CNN model(e.g. ResNets)보다 성능이 여전히 낮다.
그 이유 중 하나는 ViT가 vision task를 해결하는 데 CNN architecture에 내재된 특정 바람직한 특성이 부족하기 때문일 수 있다.
예를 들어, image에는 강력한 2D local structure가 있다.
(spatially neighboring pixels are usually highly correlated)
CNN architecture는 local receptive fields, shared weights, and spatial subsampling을 사용하여
이러한 local structure를 강제로 capture하게 한다.
따라서 어느 정도의 shift, scale, and distiortion invariance를 달성할 수 있다.
또한 convolutional kernels의 hierarchical structure는
단순한 low-level의 edge와 texture에서부터 higher order semantic pattern에 이르기까지
다양한 수준의 complexity를 갖는 local spatial context를 고려한 visual pattern을 학습한다. -
이 논문에서는 Convolution을 ViT 구조에 도입하여 performance와 robustness를 개선하면서
동시에 높은 수준의 computational and memory efficiency를 유지할 수 있다고 가설을 세웠다.
이러한 가설을 검증하기 위해, Convolution을 Transformer에 도입하여 고유의 효율성을 가진 새로운 architecture인 Convolutional Vision Transformer(CvT)를 제안한다.
CvT design은 ViT architecture의 두 핵심 부분에 convolution을 도입한다.- Transformer를 hierarchical structure를 형성하는 multiple stages로 나눈다.
- 각 stage의 시작 부분은 overlapping(겹치는) convolution operation을 수행하는 token embedding으로 구성되며,
이는 flatten된 token sequence를 다시 spatial grid로 reshape한다. - 이어서 Layer normalization을 수행한다.
➡️ 이를 통해 model은 local information을 capture할 뿐만 아니라,
단계별로 sequence length를 점진적으로 줄이면서 token feature의 dimension을 증가시킬 수 있다.
이는 spatial downsampling을 수행하면서 Feature map의 수를 증가시키는 CNN의 형태와 비슷하다.
- Transformer module의 각 self-attention block 전에 있는 linear projection을
제안된 convolution projection으로 대체한다.
이 projection은 depth-wise separable convolution 연산을 2D로 reshape된 token map에 적용한다.
➡️ 이를 통해 model은 attention mechanism에서 local spatial context를 더 잘 capture하고 semantic ambiguity(의미적 모호성)을 줄일 수 있다.
또한 convolution의 stride를 사용하여 key and value matrices를 subsampling하여 computational complexity를 관리할 수 있으며,
성능 저하를 최소화하면서 efficiency를 이상 향상시킬 수 있다.
- Transformer module의 각 self-attention block 전에 있는 linear projection을
-
요약하자면,
우리가 제안하는 Convolutional Vision Transformer(CvT)는
CNN의 모든 장점(local receptive fiels, shared weights, and spatial subsampling)과
Transformer의 모든 장점(dynamic attention, global context fusion, and better generalization)을 활용한다.
CvT는 CNN-based model과 Transformer-based model에 비해
fewer FLOPS and parameters를 사용하면서도 성능을 향상시킨다.
2. Related Work
- self-attention을 사용하여 global dependencies를 전적으로 의존하는 transformer model은
natual language modeling에서 지배적이었다.
최근에는 Transformer based architecture가 visual recognition tasks에서도
CNN의 유효한 대안으로 간주되고 있다.
(classification, object detection, segmentation, image enhancement, image generation, video processing, and 3D point cloud processing)
Vision Transformers
-
ViT는 순수 transformer architecture가 image classification에서 SOTA를 달성할 수 있음을 최초로 증명했다.
이는 Data가 충분히 큰 경우에 해당함.
DeiT는 ViT의 data-efficient training 및 distillation을 추가로 탐구했다. -
이 연구에서는 image classification에서
local 및 global dependencies를 효율적으로 modeling하기 위해
CNN과 Transformer를 결합하는 방법을 연구함 -
vision transformer에서 local context를 더 잘 modeling하기 위해,
일부 현재의 연구들은 design changes를 도입했다.
예를 들어,- Conditional Position encodings Visual Transformer(CPVT)는
ViT에서 사용되는 사전 정의된 positional embdding을 conditional positoin encodings(CPE)로 대체하여
transformer가 임의 크기의 input image를 interpolation 없이 처리할 수 있게 한다. - Transformer-iN-Transformer (TNT)는 patch embdding을 처리하는 outer Transformer block과 pixel embdding 간의 relation을 modeling하는 inner transformer block을 모두 사용하여
patch-level 및 pixel-level representation을 modeling한다. - Tokens-to-Token(T2T)는 sliding window 내에서 여러 token을 하나의 token으로 연결하여 ViT에서 tokenization을 주로 개선한다.
그러나 이 작업은 근본적으로 convolution과는 특히 normalization details에서 다르며,
여러 token을 concatenation하는 것은 computation and memory complexity를 크게 증가시킨다. - PVT는 CNN에서의 multi-scales과 유사하게
Transformer를 위한 multi-stage design(without convolutions)을 통합했다.
이러한 현재의 연구들과는 대조적으로,
본 연구는 image domain specific inductive biases를 가진 convolution을 Transformer에 도입하여
두 architecture의 장점을 모두 달성하는 것을 목표로 한다.
Table 1.에서는 위에서 언급한 현재 진행중인 연구들과 우리의 연구 간의 주요 차이점을
positional encodings, type of token embdding, type of projectoin, and Transformer structure in the backbone 측면에서 보여준다.
- Conditional Position encodings Visual Transformer(CPVT)는
Introducing Self-attentions to CNNs.
- self-attention mechanism은 vision task에서 CNN에 널리 적용되어 왔다.
이러한 연구들 중에서,
non-local networks([34])는 global attention을 통해 long range dependencies를 capture하도록 설계되었다.
local relation networks([16])는 local window 내에서 pixel/feature 간의 compositional relations에 기반하여 weight aggregation을 조정한다.
이는 공간적으로 인접한 input feature에 대해 고정된 weight aggregation을 사용하는 convolution layer와는 대조적이다.
이러한 adaptive weight aggregation은 recognition에 중요한 geometric priors(기하학적 사전)을 network에 도입한다.
최근 BoTNet은 ResNet의 마지막 3개의 bottleneck block에서
spatial convolution을 global self-attention으로 대체하는
backbone architecture를 제안하여 image recognition에서 좋은 성능을 달성.
반면, 우리의 연구는 반대 방향으로 진행된다: Transformer에 convolution을 도입하는 것
Introducing Convolutions to Transformers.
- NLP 및 speech recogntion에서는,
convolution이 Tranformer block을 수정하기 위해 사용되었다.
Multi-head attention을 conv layer로 대체하거나,
추가적인 conv layer를 병렬로 또는 순차적으로 추가하여 local relationships을 capture한다.
다른 선행 연구는 attention map을 residual connection을 통해 후속 layer로 전파하는 방법을 제안했는데,
이 때 attention map은 먼저 convolution으로 변환된다.
이러한 연구와 달리,
우리는 vision transformer의 두 주요 부분에 convolution을 도입하는 것을 제안:
- attention operation을 위한 기존의 position-wise linear projection을 우리의 convolutional projection으로 대체
- CNN과 유사하게 다양한 Resolution의 2D reshaped toekn map을 가능하게 하는 Multi-stage structure를 사용.
우리의 unique design은 이전 연구들에 비해 상당한 performance and efficiency benefits 이점을 제공한다.
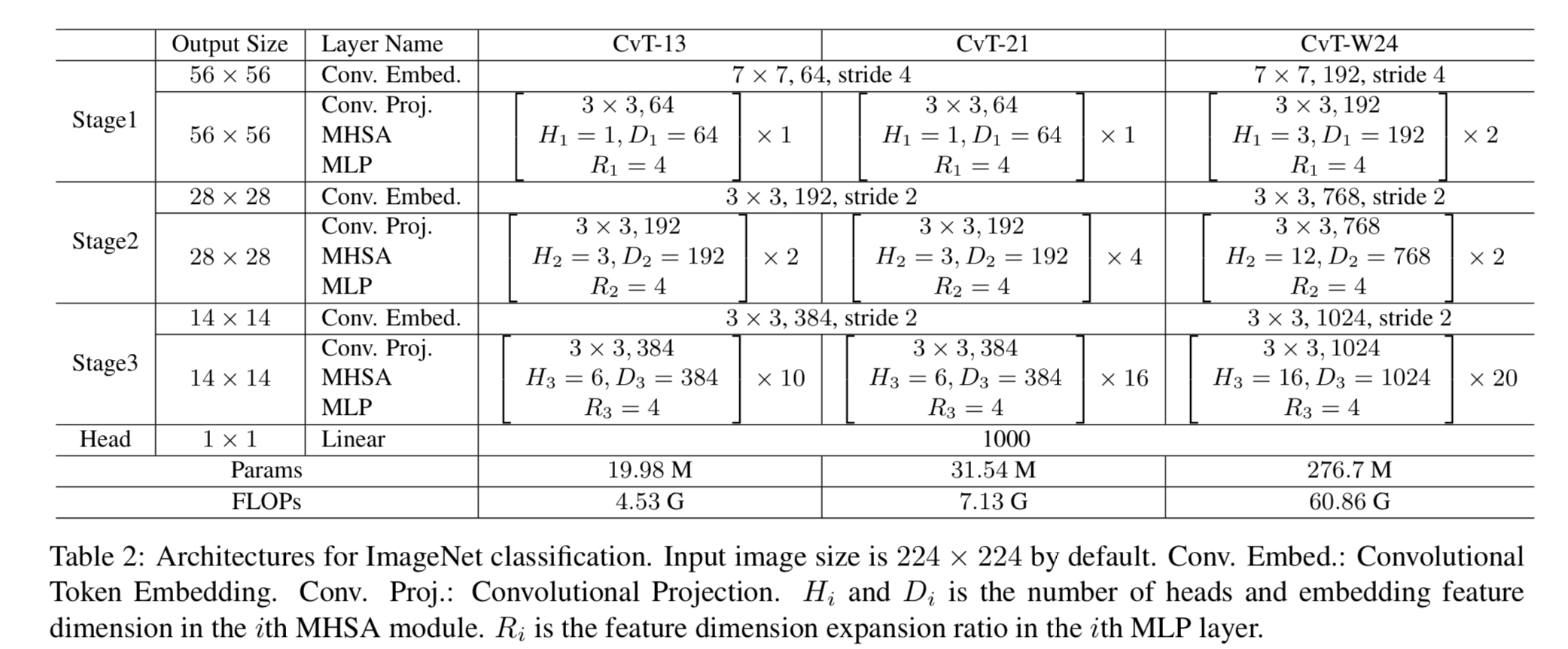
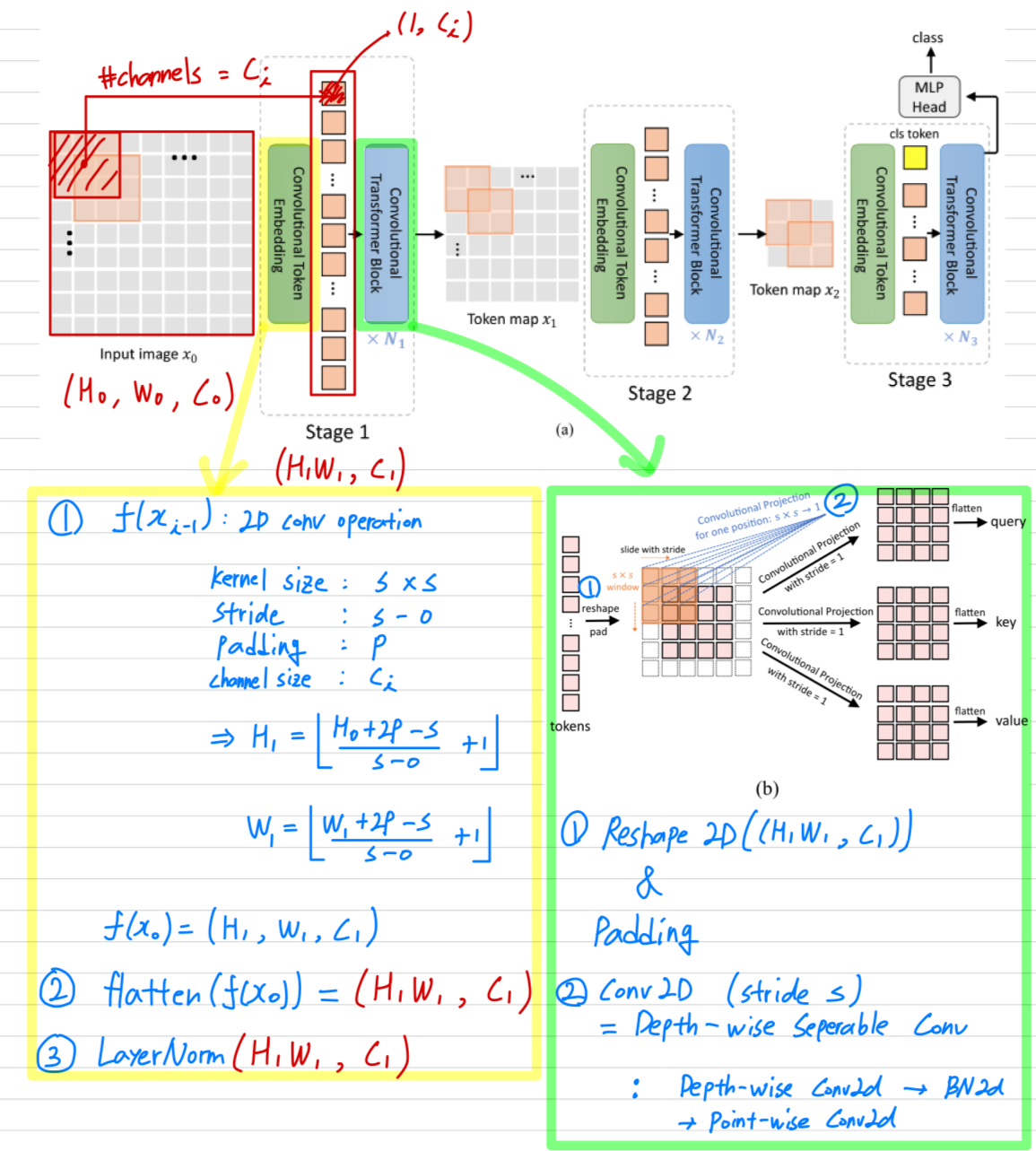
3. Convolutional vision Transformer
- CvT의 전체 pipeline은 다음과 같다.
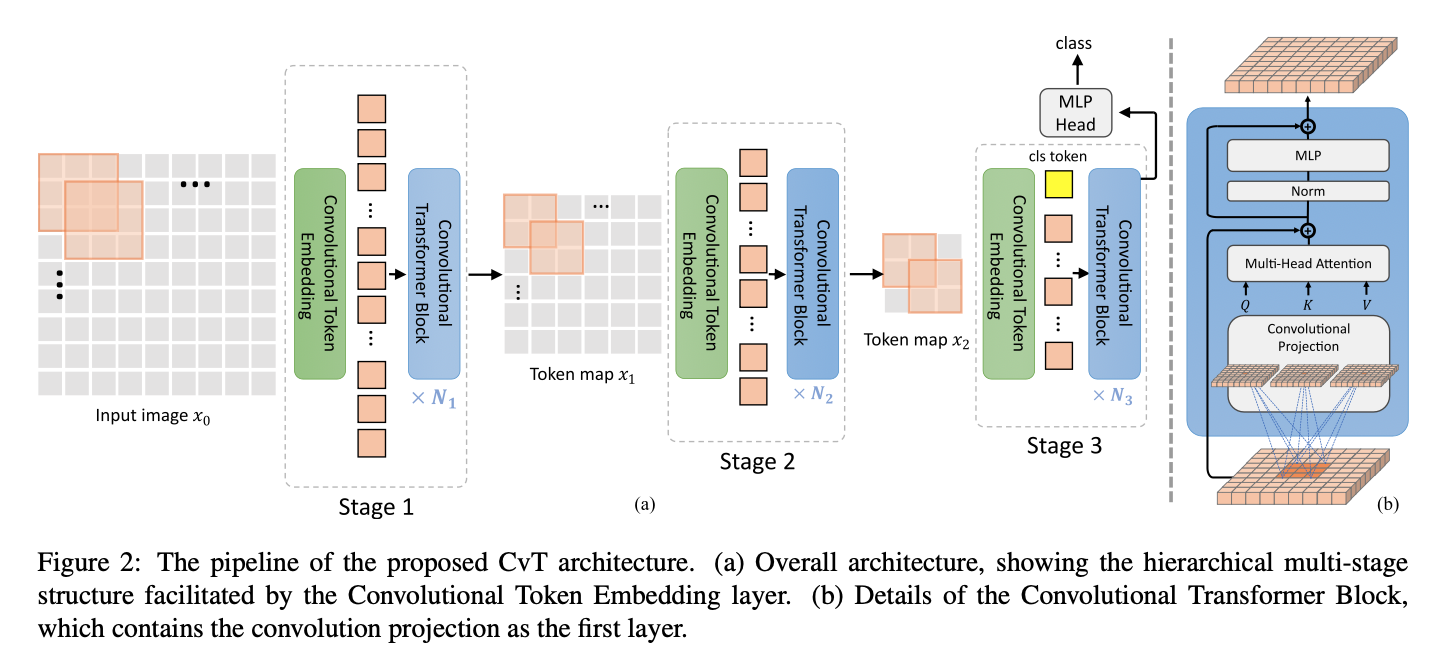 우리는 Vision Transformer architecture에 두 가지 convolution -based operation인
우리는 Vision Transformer architecture에 두 가지 convolution -based operation인
Convolutional Token Embedding과Convolutional Projection을 도입했다.
Figure 2 (a)에서 보이는 것처럼,
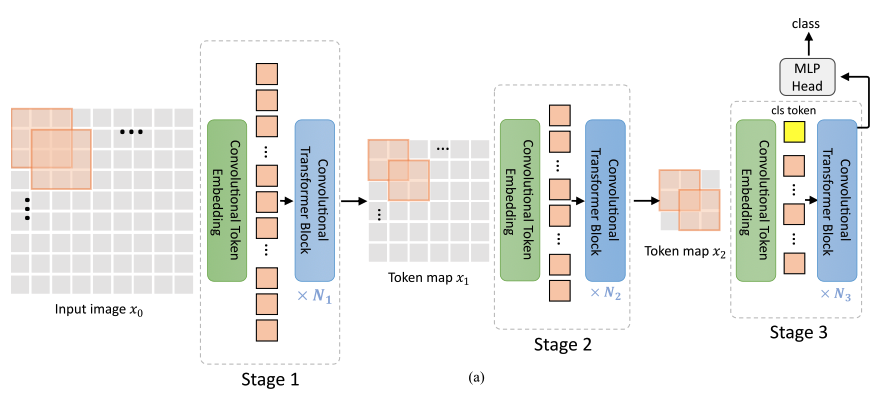
CNNs에서 사용한 multi-stage hierarchy design이 사용되며,
이 연구에서는 3 stages가 사용된다.
- 각 stage는 두 부분으로 구성된다.
- input image(or 2D로 reshaped된 token map)는 Convolutional Token Embedding layer를 거치게 되며,
이는 overlapping patch를 사용한 convolution으로 구현된다.
token은 input으로 2D spatial grid로 재구성된다(overlap 정도는 stride length를 통해 조절할 수 있음)
추가로 layer normalization이 token에 적용됨.
이를 통해 각 stage는 token의 수(i.e. feature resolution)를 점진적으로 줄이는 동시에
token의 width(i.e. feature dimension)을 증가시키게 되어,
CNNs의 design과 유사하게 spatial downsampling 및 representation의 richness(풍부함)를 달성할 수 있다.
다른 이전의 Transformer-based architecture와 달리,
우리는 token에 ad-hod position embdding을 더하지 않는다. - 제안된 Convolutional Transformer Blocks의 stack이 각 stage의 나머지를 구성함.
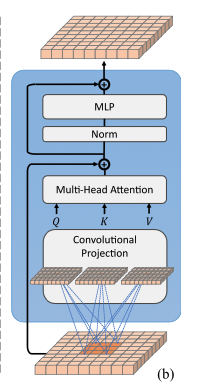
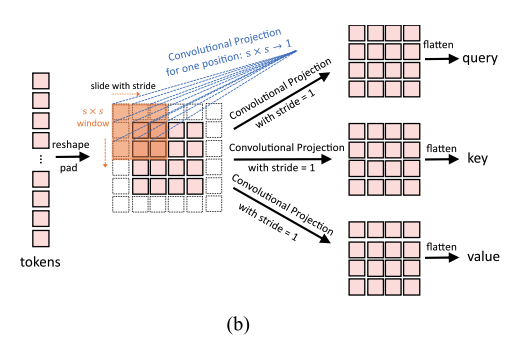
Figure 2 (b)는 Convolutional Tranformer Block의 architecture를 보여주며,
여기서 depth-wise separable convolution operation이 query, key, value embedding에 각각 적용되며,
이는 ViT의 standard positoin-wise linear projection 대신 사용된다.
추가로, classification token은 마지막 stage만 추가된다.
마지막으로, final stage output의 classification token에 대해
MLP(i.e. fully connected) Head를 사용하여 class를 예측한다.
- input image(or 2D로 reshaped된 token map)는 Convolutional Token Embedding layer를 거치게 되며,
3.1. Convolutional Token Embedding

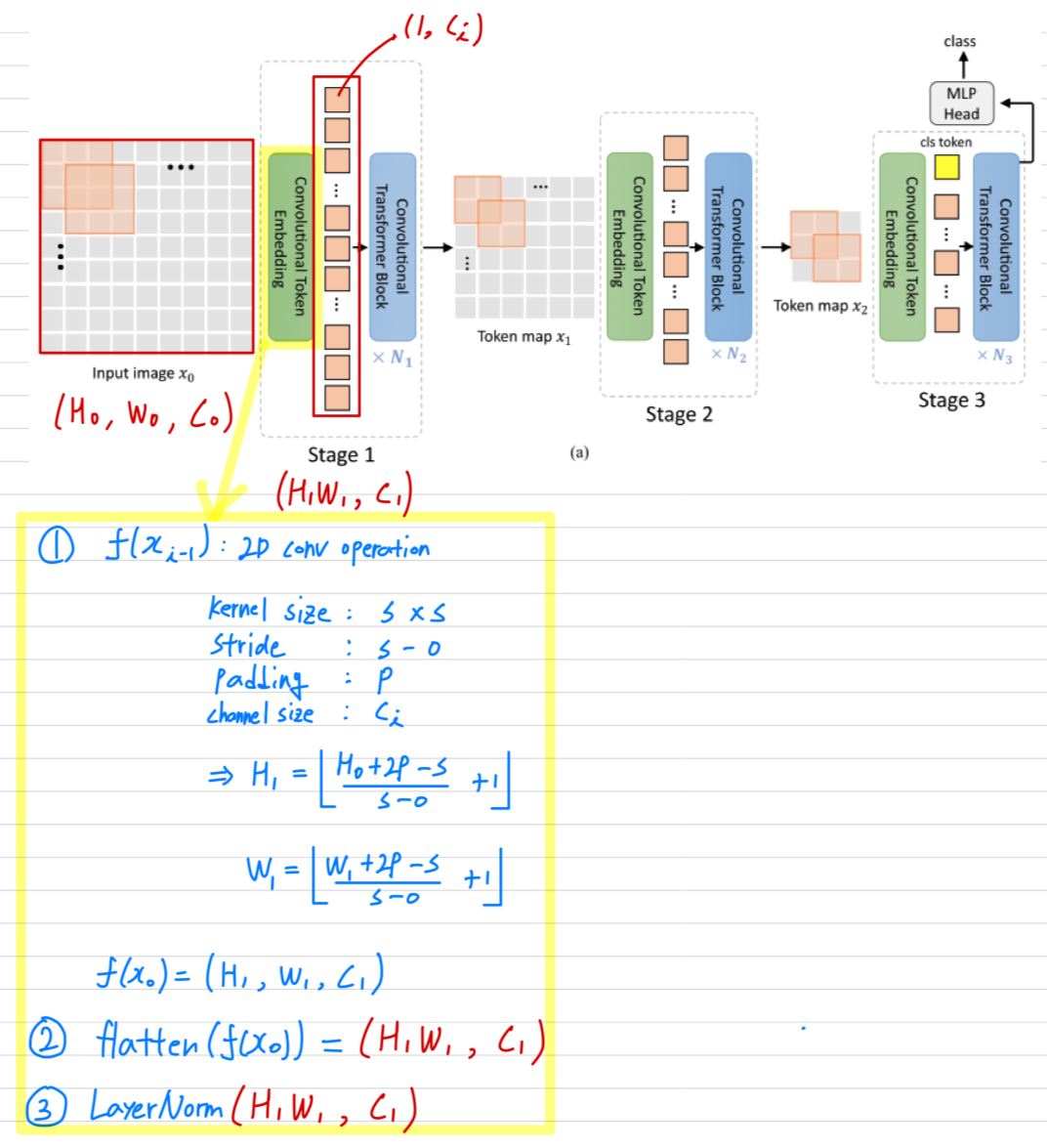 Convolution channel 개수 를 통해 한 token(feature) dimension을 조절 가능. ( == kernel 개수 == token dimension)
Convolution channel 개수 를 통해 한 token(feature) dimension을 조절 가능. ( == kernel 개수 == token dimension)
kerel size 및 stride를 통해 token 개수() 조절 가능.
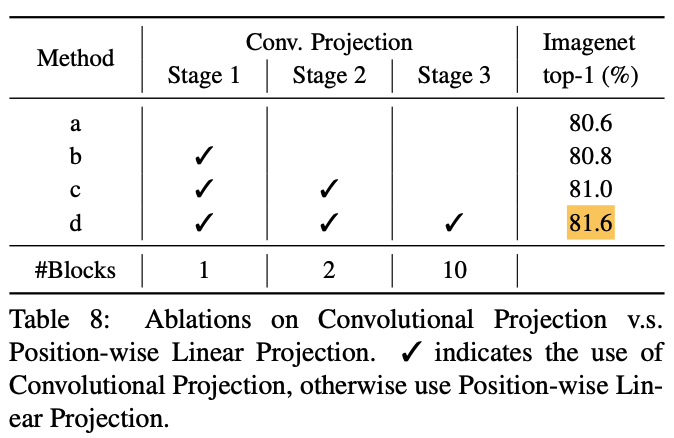
3.2. Convolutional Projection for Attention
-
Convolutional Projection layer의 목표는 local spatial context를 추가로 modeling하고,
와 matrices를 downsampling할 수 있도록 하여 Efficiency를 향상시키는 것이다. -
기본적으로,
Convolutional Projection을 포함한 Transformer block은 original Transformer block의 일반화된 형태이다.
우리는 Mult-Head Self-Attention(MHSA)을 위한 기존의 position-wise linear projection을
depth-wise separable convolution으로 대체하여 Convolutional Projection layer를 제안한다.
3.2.1 Implementation Details
-
Figure 3 (a)는 ViT에서 사용된 original position-wise linear projection
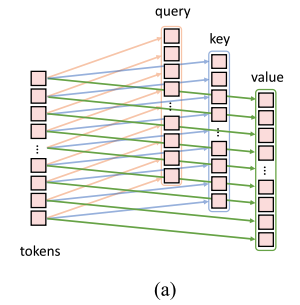
-
Figure 3 (b)는 우리의 Convolutional Projection이다.
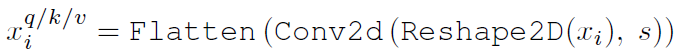
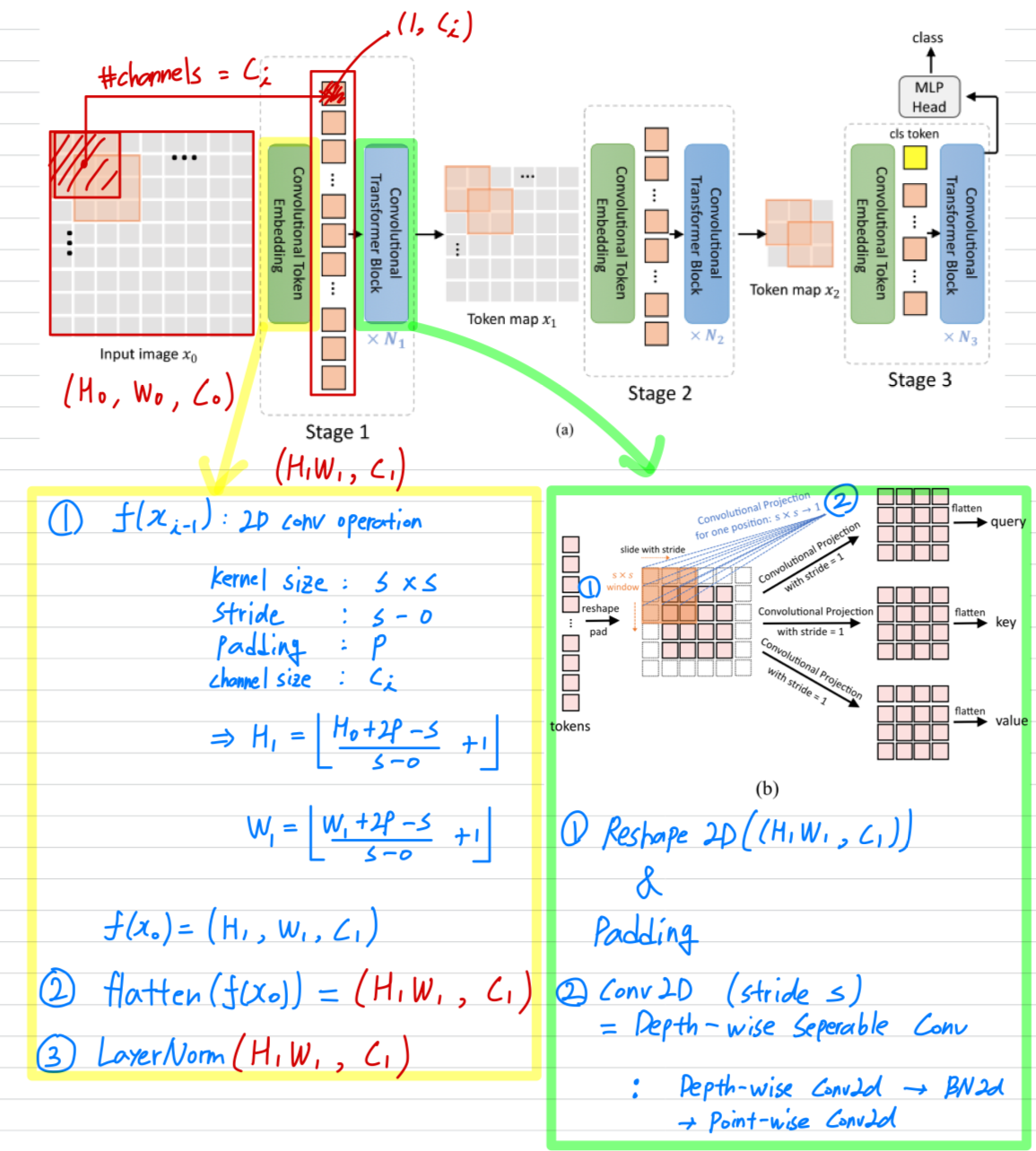
3.2.2 Efficiency Considerations
- 우리는 efficient convolution을 사용한다.
- Convolution Projection에서 standard convolution을 직접 사용하는 경우,
parameters and FLOPs가 필요함.
(: token channel dimension, : #tokens for processing)
대신에, 우리는 standard convolution을 depth-wise separable convolution으로 나눈다.
이를 통해 제안된 Convolutional Projection은 원래의 position-wise linear projection과 비교하여 parameters and FLOPs만을 추가로 도입하게 되어,
전체 parameter수와 FLOPs 측면에서 무시할 수 있는 수준이다. - 우리는 제안된 Convolution Projection을 활용하여 MHSA computation cost를 줄인다.
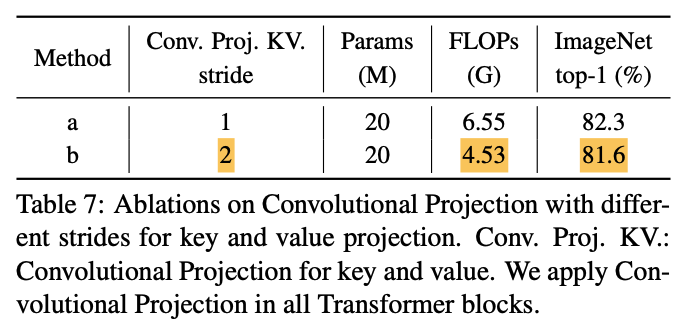
Convolutional Projection은 stride가 1보다 큰 convolution을 사용하여 toke수를 줄일 수 있다.
Figure 3 (c)는 Convolutional Projection을 보여주며, 여기서 key and value projection은 stride가 1보다 큰 convolution을 사용하여 subsampling된다.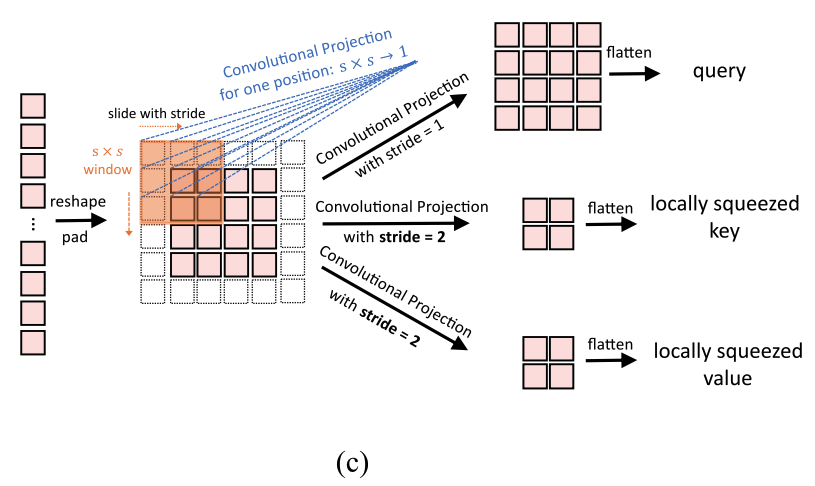 우리는 key and value projection에 대해 stride=2를 사용하고,
우리는 key and value projection에 대해 stride=2를 사용하고,
query에는 stride=1을 그대로 유지한다.
이렇게 하면 key and value toke수가 4배 줄어들고, MHSA computation cost도 4배 줄어든다.
image의 neighboring pixels/patches에서는 appearance/semantics에서 중복되는 경향이 있기 때문에
성능 저하가 최소화된다.
추가로, 제안된 Convolutional Projection의 local context modeling은 resolution reduction으로 인해 발생하는 정보 손실을 보완한다.
- Convolution Projection에서 standard convolution을 직접 사용하는 경우,
3.3. Methodological Discussions
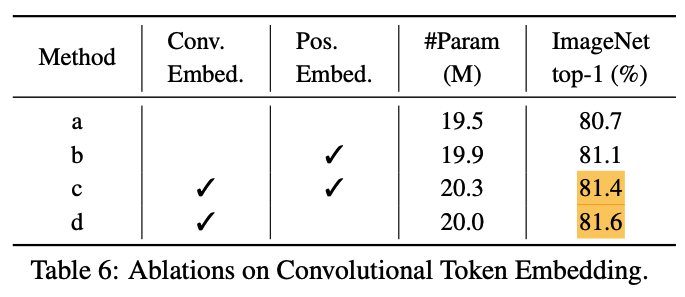
Removing Positional Embeddings:
- 모든 Transformer block에 Convolutional Projections을 도입하고
Convolutional Token Embedding을 결합함으로써,
network를 통해 local spatial relationships을 modeling할 수 있는 능력을 얻게 되었다.
이러한 built-in 속성 덕분에 network에서 position embedding을 제거해도
성능에 영향을 주지 않으며, 이는 experiments(Section 4.4)에서 입증되었다.

Relations to Concurrent Works:
4. Experiments
4.1. Setup
Model Variants