[Paper Review] Hybrid(Conv & Transformer) Architecture
1.CvT: Introducing Convolutions to Vision Transformers
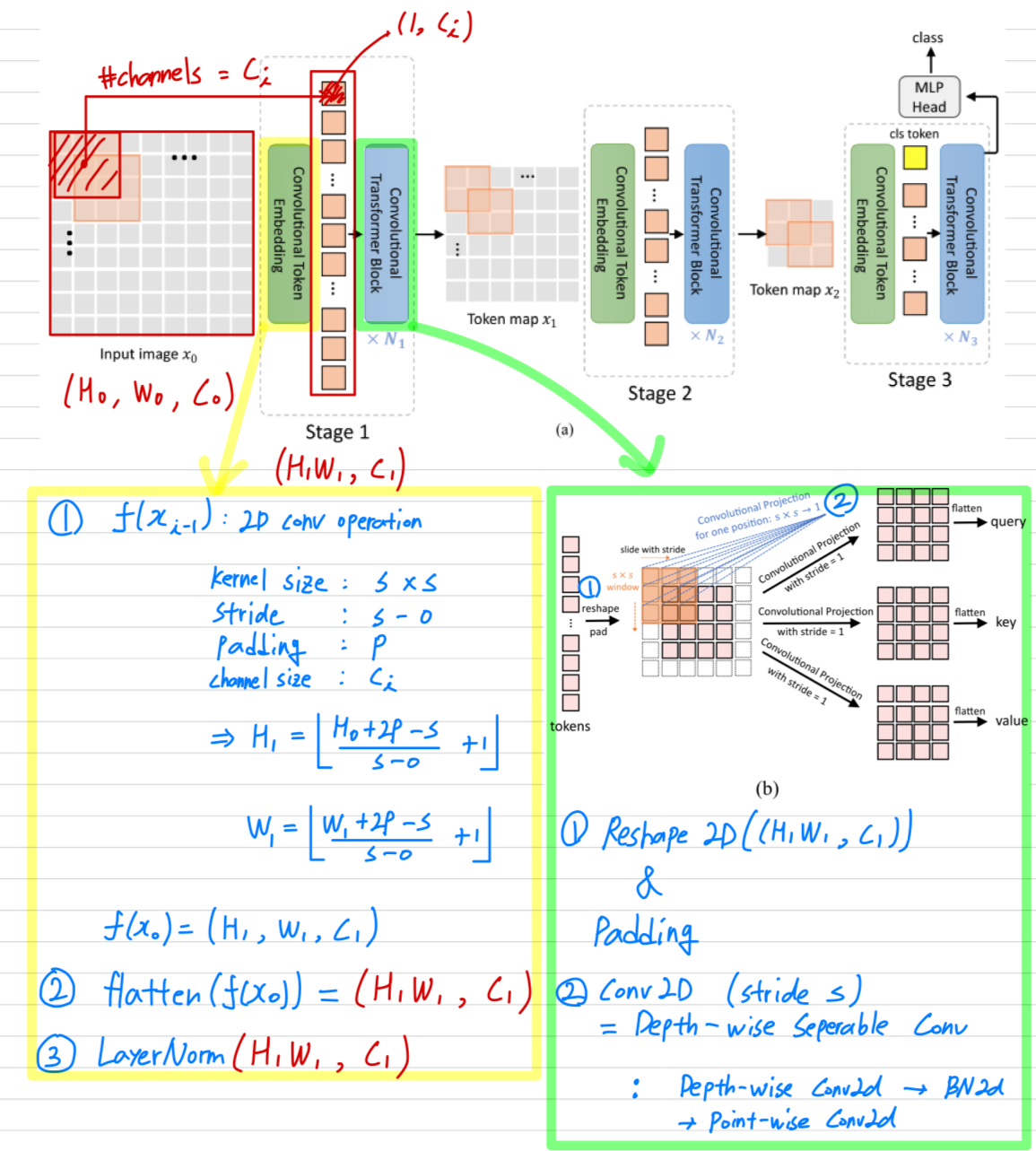
https://openaccess.thecvf.com/content/ICCV2021/papers/Wu_CvT_Introducing_Convolutions_to_Vision_Transformers_ICCV_2021_paper.pdfWu, Haiping, et a
2024년 6월 17일
2.[Simple Review] [DeiT] Training data-efficient image transformers & distillation through attention
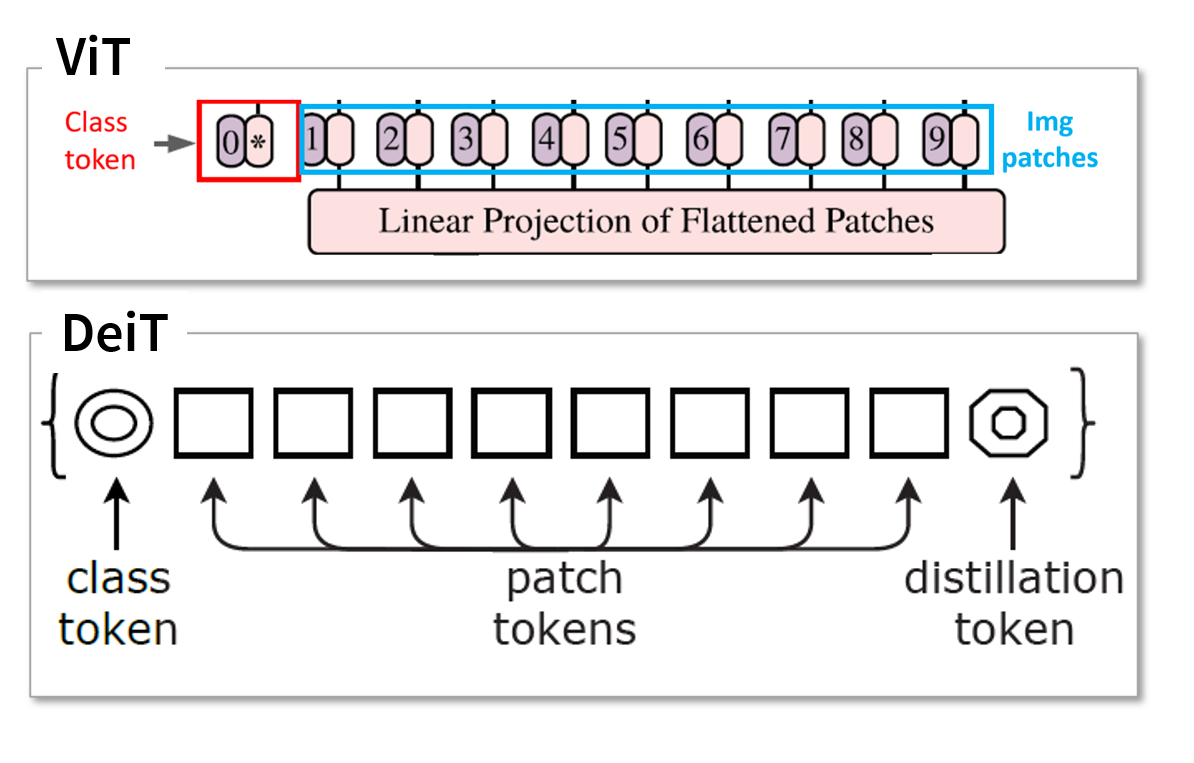
https://proceedings.mlr.press/v139/touvron21aTouvron, Hugo, et al. "Training data-efficient image transformers & distillation through attention."
2024년 6월 19일
3.LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
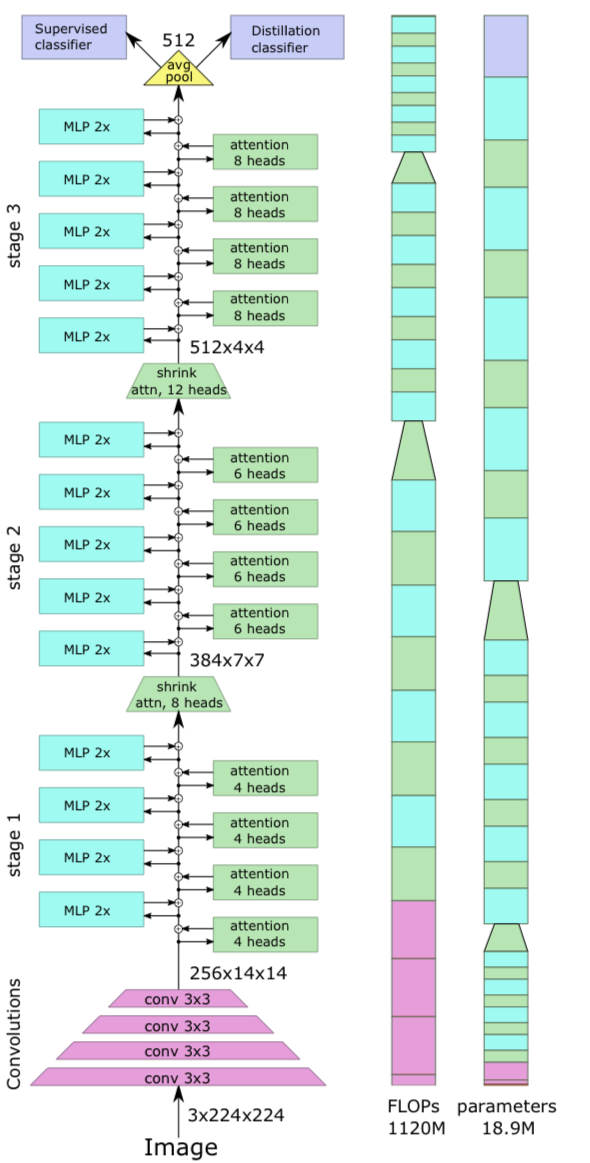
https://openaccess.thecvf.com/content/ICCV2021/papers/GrahamLeViTAVisionTransformerinConvNetsClothingforFasterInferenceICCV2021_paper.pdf Paper Info
2024년 6월 18일
4.[Simple Review] CoAtNet: Marrying Convolution and Attention for All Data Sizes
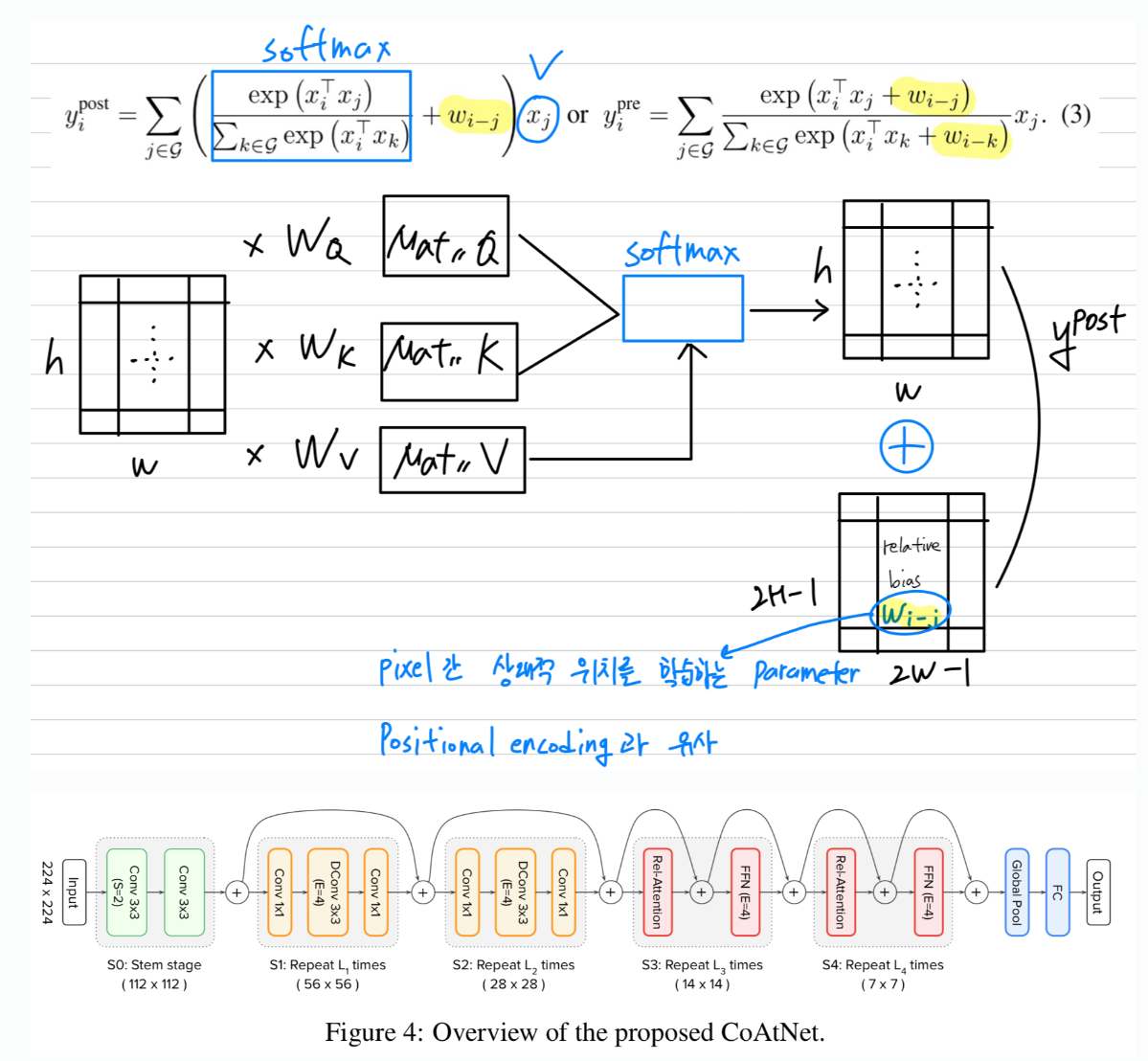
Dai, Zihang, et al. "Coatnet: Marrying convolution and attention for all data sizes." Advances in neural information processing systems 34 (2021): 396
2024년 6월 12일