Linear Model
-
Classification : 입력에 대해서
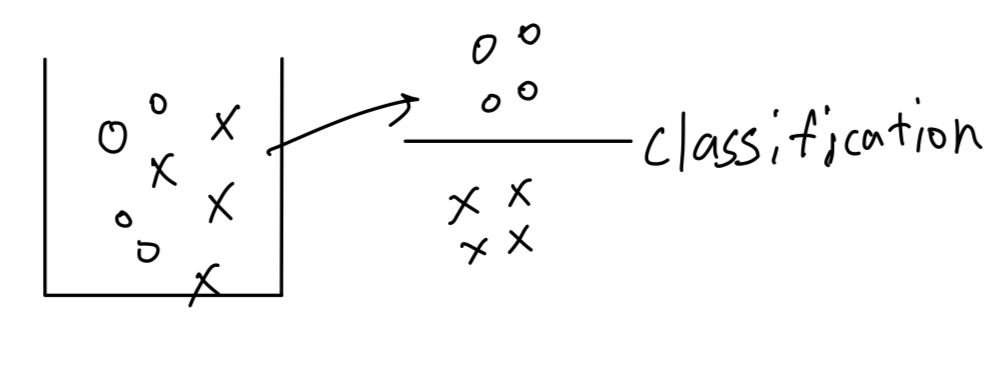
-
Regression : 입력에 대해 실수의 예측값을 예측하는 model
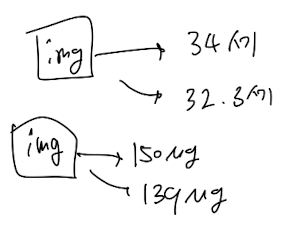
-
Logistic Regression : Regression 문제인데, 확률적인 요소가 들어간 model
이번 chapter는 Classification에 대해서 공부할 것임...
Linear Classification
- Set of Lines
- Often a good first choice
- Small VC dimension
VC dimension(model 복잡도 == parameter 수)가 적기 때문에
Generalization 성능이 좋다.
Generalize well from to
Two tpyes of linearly inseparable data
- linearly inseparable data에 대해서 타협하여 최적의 weight(= hypothesis = model)를 찾아야 한다.
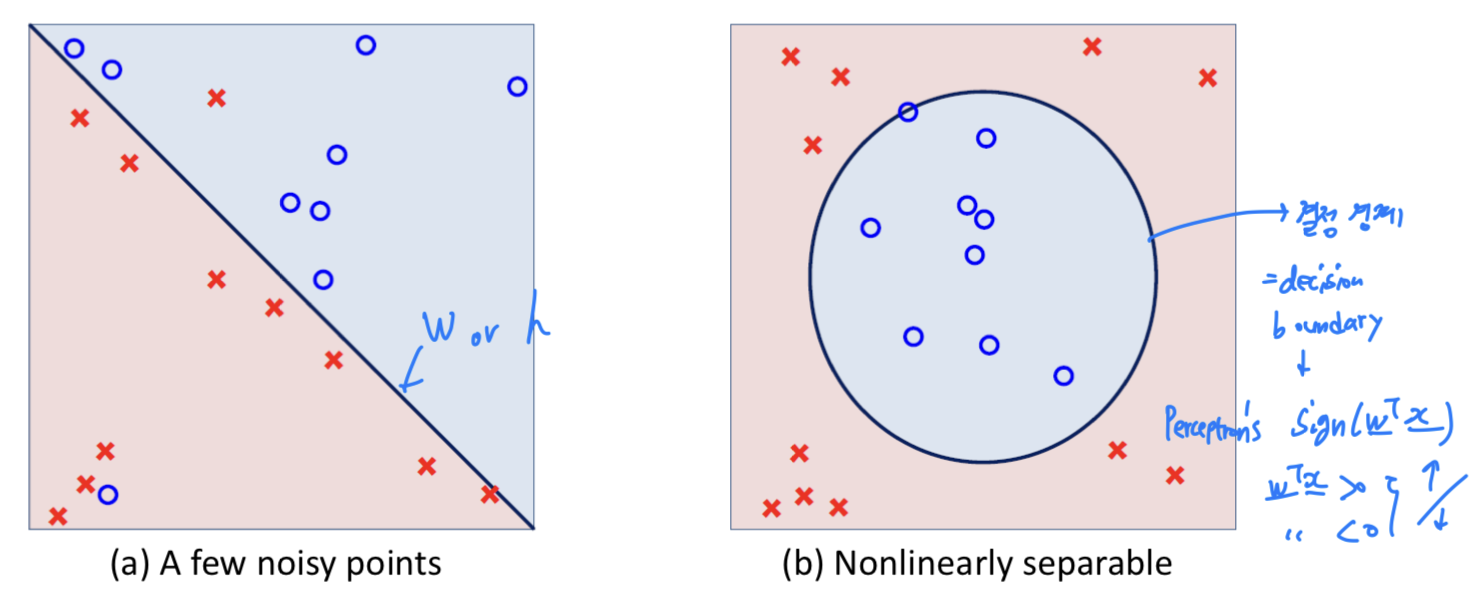
- (a) : 몇 개의 noise, outlier가 있지만 주어진 decision boundary가 최적인 것처럼 보임.
따라서 noise를 감수하고 위의 decision boundary를 유지하는 것이 좋아보임.
완벽하게 를 0으로 만들 수는 없지만, 최대한 가깝게 만들어야 하는 것이 목적임. - (b) : Linear Model로는 해결할 수 없어서
Nonlinear Tranformation이라는 technique이 필요하다
- (a) : 몇 개의 noise, outlier가 있지만 주어진 decision boundary가 최적인 것처럼 보임.
Hardness
- (a)를 봤을 때, outliers/noise로 인해 data가 항상 완벽하기 분리되지는 않는다.
- To find a hypothesis with the minimum
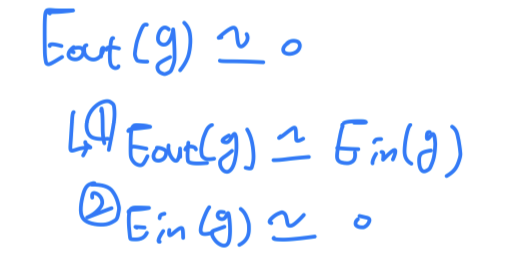
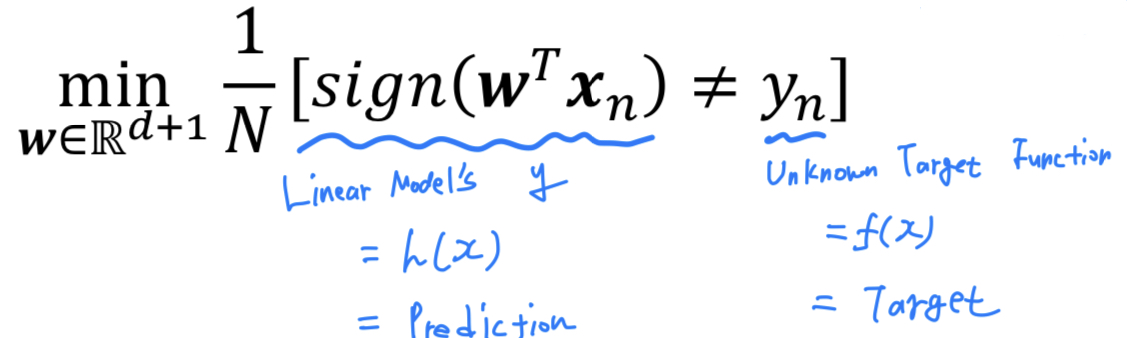
- 우리의 prediction인 과 target인 이 다른 경우를 최대한 줄여나가야 한다.
- 하지만 실제로는 이것은
NP-hard Problem이다. - 그 이유는 and binary error인 의 수식이 있기 때문에
위에 있는 식을 최적화하는 것이 매우 어렵기 때문이다.
따라서 Approximately minimize
Approximately minimizing
Pocket Algorithm
- 동작하는 Algorithm이 한 방향으로 진행한다.
안좋은 weight를 다시 update하지는 않고, 최적이라고 판단되는 weight를 pocket에 가지고 있는다. - The pocket Algorithm keeps 'in its pocket' the best encountered up to iteration in PLA
Pseudo Code

- : wieght vector pocket = optimal weight를 담을 pocket 생성
- iteration(번 = data를 보는 개수)을 정해준다.
- PLA : ⬅️
- 우리가 갖고 있는 모든 data에 대해서 를 계산
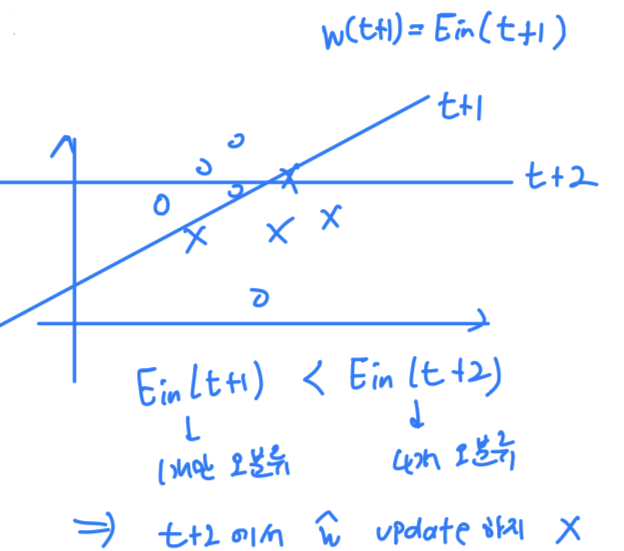
- 만약 현재의 가 Optimal Weight 보다 작다면,
- 에 를 저장.
문제점 : 를 계산하는 과정이 매우 오래걸린다.
모든 data에 대한 를 계산하기 때문에 복잡도가 증가한다.
(따라서 Pocket Algorithm은 PLA보다 훨씬 느리게 수행된다.)
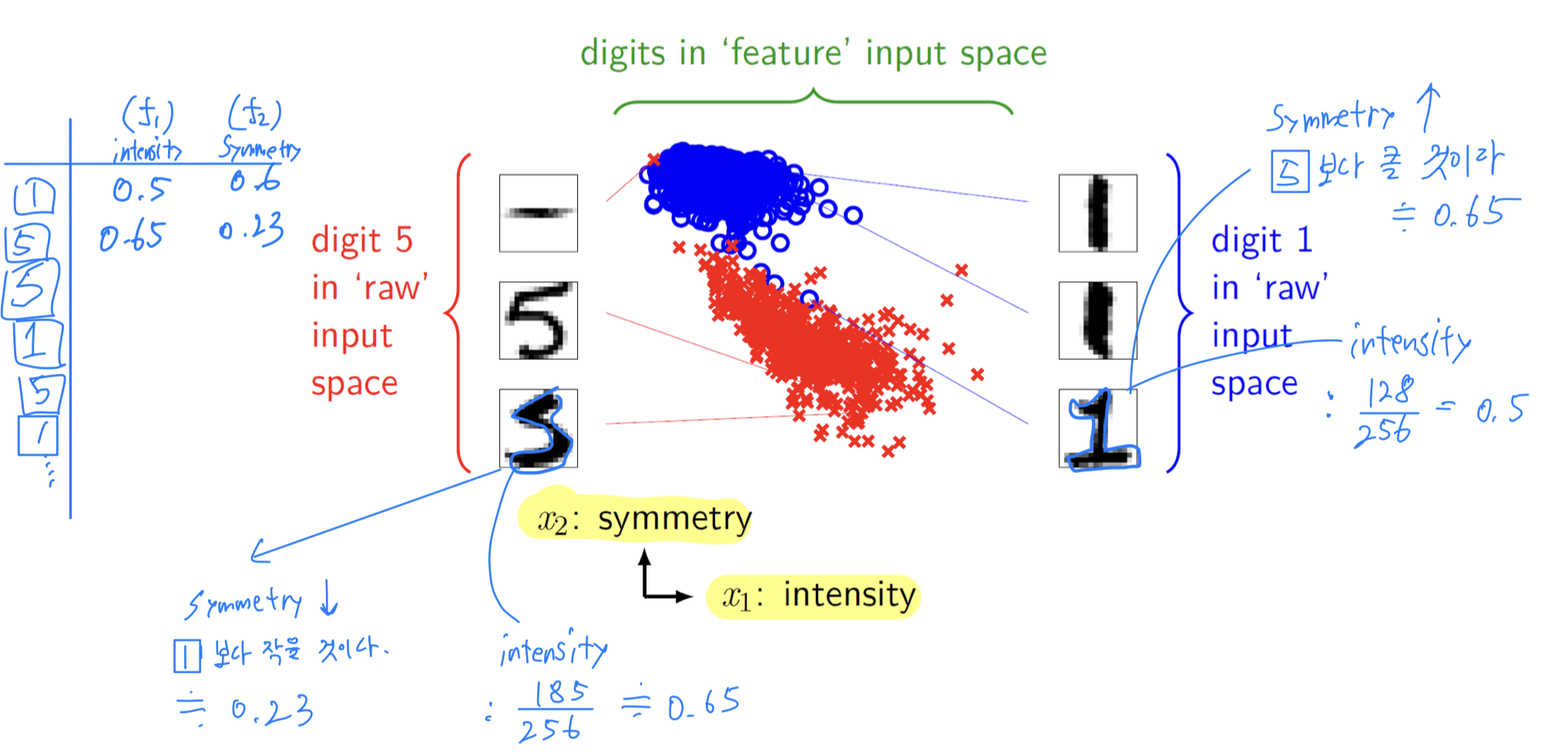
Example : Handwritten Digit Recognition
1. Decomposition from multiclass to binary classification
- 0~9의 손글씨 data에 대한 multi classification 문제를
Focusing on digit {1, 5}하여, binary classification 문제로
2. Feature Extraction
- 256pixel(=[16 x 16] pixels) 중에서
intensity(f1)andsymmetry(f2)features를 Extraction.- intensity : 전체 pixel들 중에 값이 127(=threshold)보다 큰 pixel
- symmetry : 대칭 정도
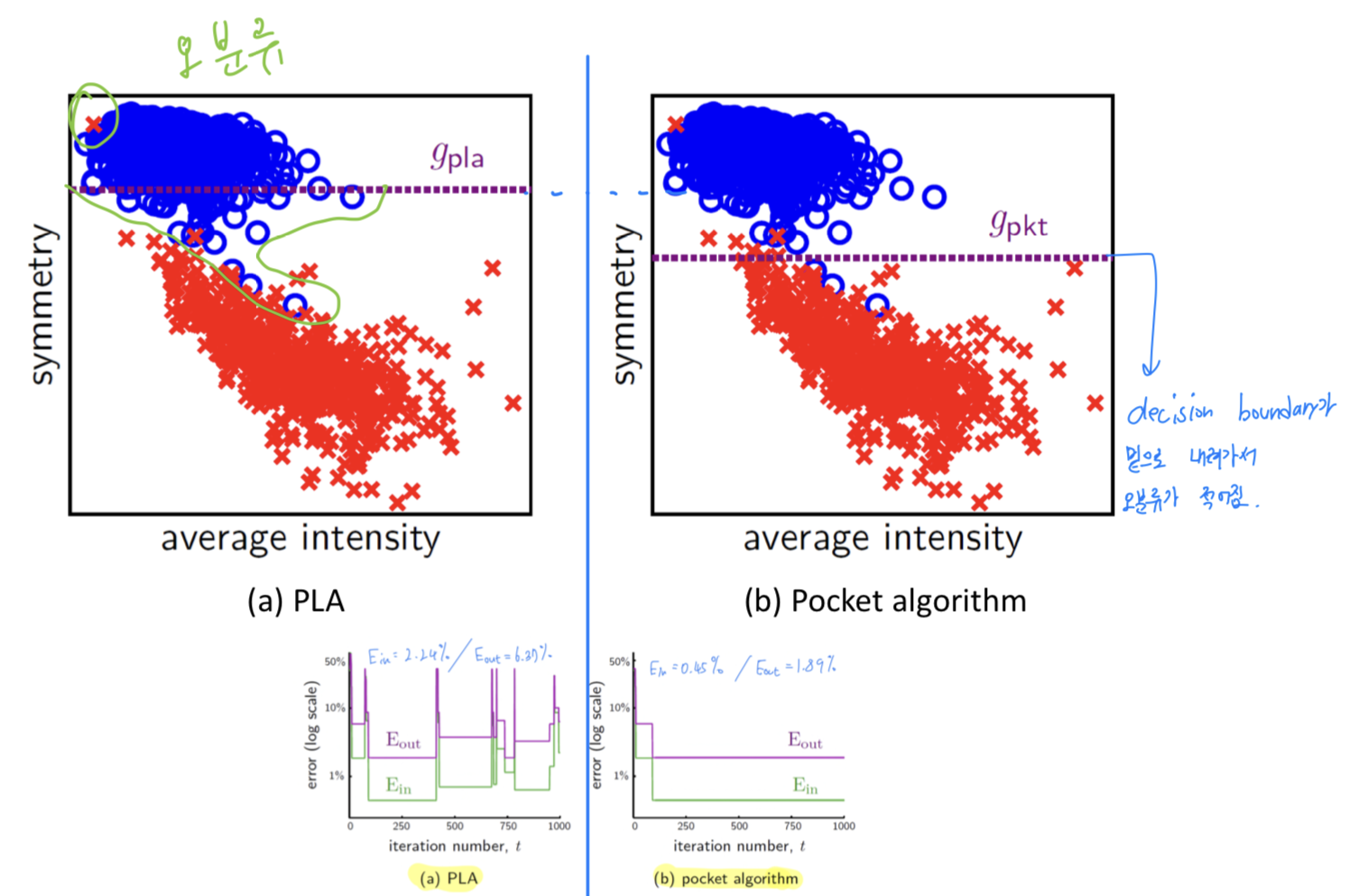
Error : PLA vs Pocket
Summary
- Linear Model은 3가지 있다.
- Classification
- Regression
- Probability Estimation(= Logistic Regerssion)
- Small and generalize well ➡️ So First Practical Choice
모델 복잡도가 낮아서 처음 시도해볼 만한 model이다.
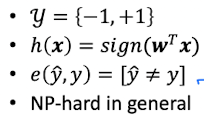

Efficient Deep Learning