Pruning Filters for Efficient Convnets
실습 구상
- VGG-16 on CIFAR-10
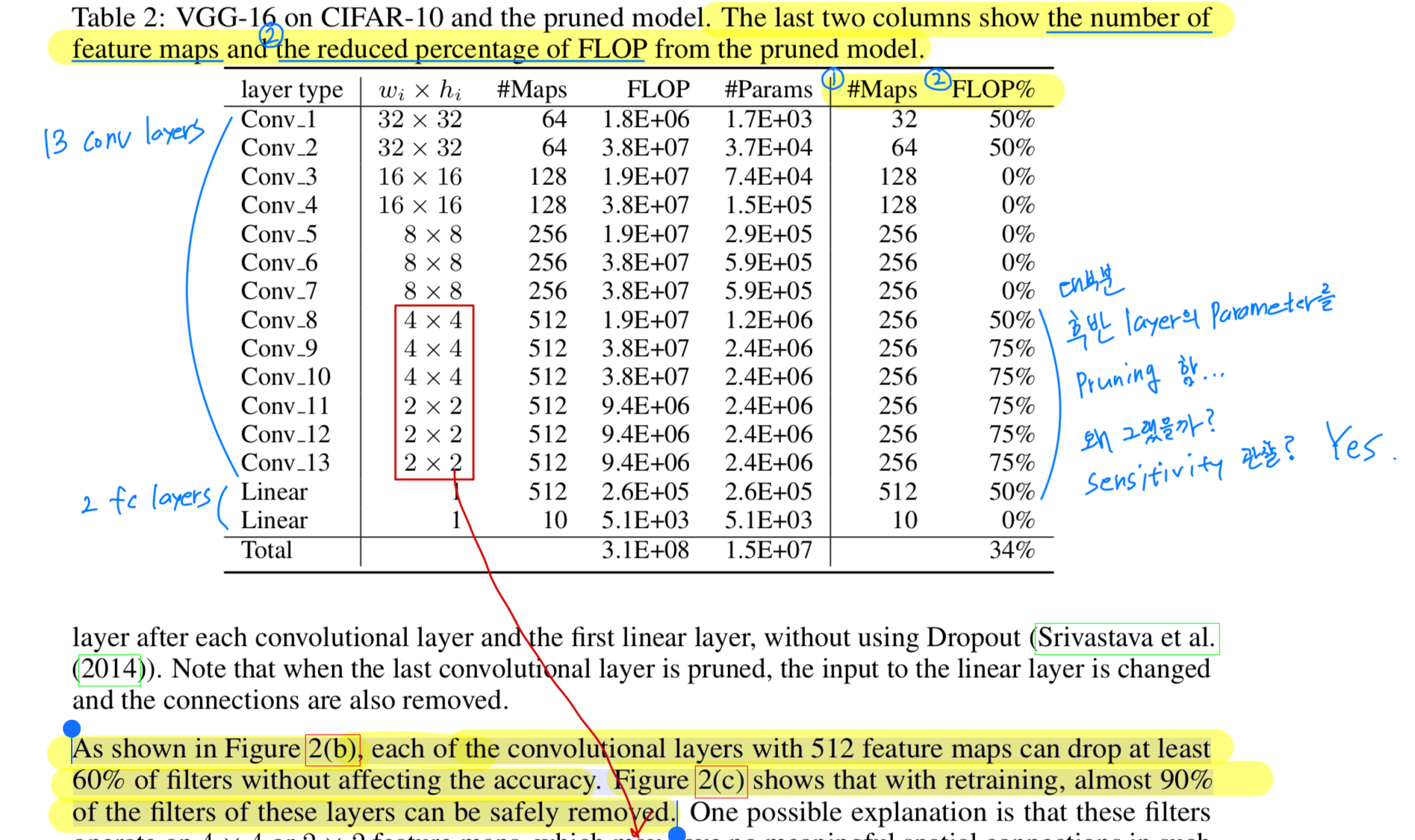
논문에서는 conv_8 512 ~ conv_13 512 feature map을 가진 conv layer들의 filter를 accuracy에 영향 없이 적어도 69%의 filter를 drop할 수 있다고 한다.
실제로 VGG-16 on CIFAR-19 model을 pruning해봐서 #Maps, FLOP%, Accuracy를 측정해봐야 겠다.
(baselie) VGG-16 on CIFAR-10
-
먼저, pruning을 구현하기 위해 baseline model을 구현하는 것이 첫번째이다.
baseline model에서 parameter를 filter 단위로 pruning하며 실험을 진행할 것이다. -
baseline으로는 논문에서 제시한 VGG-16 on CIFAR-10 by Zagoruyko(2015) 의 code를 사
용할 것이다. -
하지만 여기서 문제가 발생했다.
VGG-16 on CIFAR-10 by Zagoruyko(2015) 의 code는 오래된 code이므로 lua language로 작성되어 있었다.
Lua code를 실행시켜보려 했지만, 나의 cuda version이 lua code를 지원하지 않아서
논문에서 사용한 baseline model을 손쉽게 얻을 수 없었다. -
그래서 VGG-16 on CIFAR-10 by Zagoruyko(2015) 의 code에서 preprocessing, hyperparameter을 어떻게 했는지 참고하여
직접 VGG16 on CIFAR-10을 구현하였다.
또한 논문에서는 Zagoruyko의 code에 한가지 조건을 적용하여 만들었다고 했다.- "We use the model described in Zagoruyko(2015) but add Batch Normalization layer each conv layer and the first linear layer, without using Dropout"
- "We use the model described in Zagoruyko(2015) but add Batch Normalization layer each conv layer and the first linear layer, without using Dropout"
00_vgg16_baseline_exp1/
-
Zagoruyko는 특별한 preprocessing없이 horizontal flip만 해서 92.45%의 accuracy를 달성했다고 했다.
그래서 직접 구현한 VGG16 model의 accuracy가 92.45%에 근접하게 나오는 것을 목표로 두었다.

-
첫번째 experiment라는 의미로 00_vgg16_baseline_exp1/ directory 밑에
train.py file을 생성하여 training code 개발을 완료하였다.
accuracy
- accuracy가 92.45%에는 못미치지만 거의 유사한 성능(91.86%)을 보여서
추가 실험을 하지 않고, 첫번째 실험에서 개발한 model을 바로 baseline model로 삼을 것이다.

00_vgg16_prune_and_retrain/
- 논문에서 pruning할 filter를 결정하기 위해,
(b) 각 layer 마다 filter들의 pruning sensitivity를 확인하여
(c) 최종적으로 pruning하고, retrain시킨
결과를 Figure 2.에 visualization하였다.
Figure 2. (b)
-
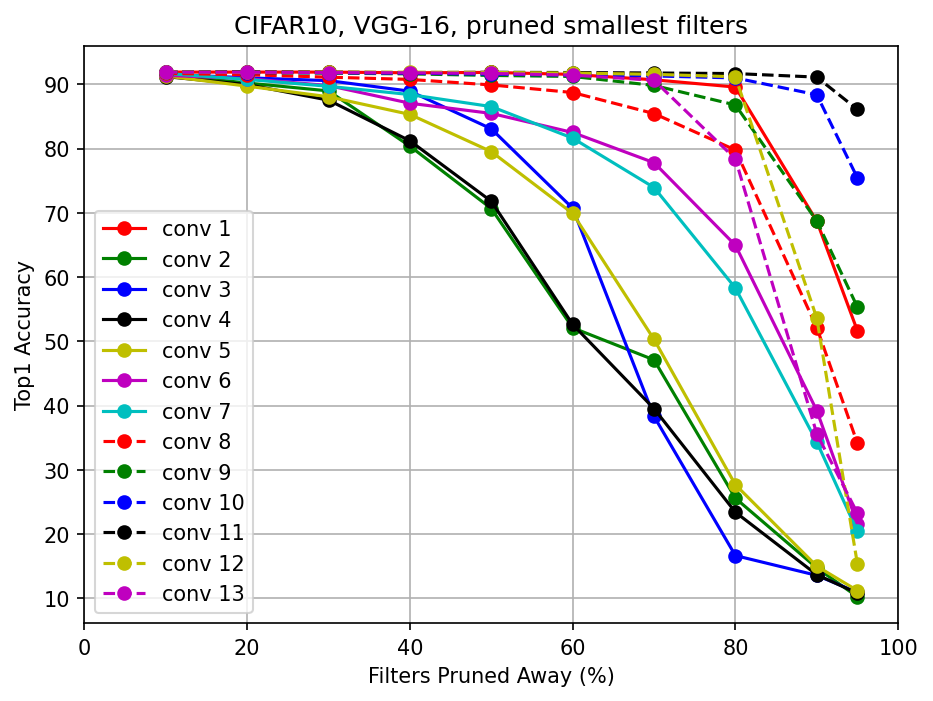
논문에서의 Figure2. (b) :
Figure2. (b)는 13개의 conv layer들마다 해당 layer의 filter들을
각각 [10, 20, 30, 40, 50, 60, 70, 80, 90, 95]% pruning하고 난 후에,
model의 accuracy를 다시 측정한 것을 visualization한 것이다.
그래프를 보면 알 수 있듯이,
논문에서는 뒷쪽의 conv layer들이 pruning에 robust하고,
앞쪽의 conv layer들이 pruning에 sensitive하다고 주장했다.
-
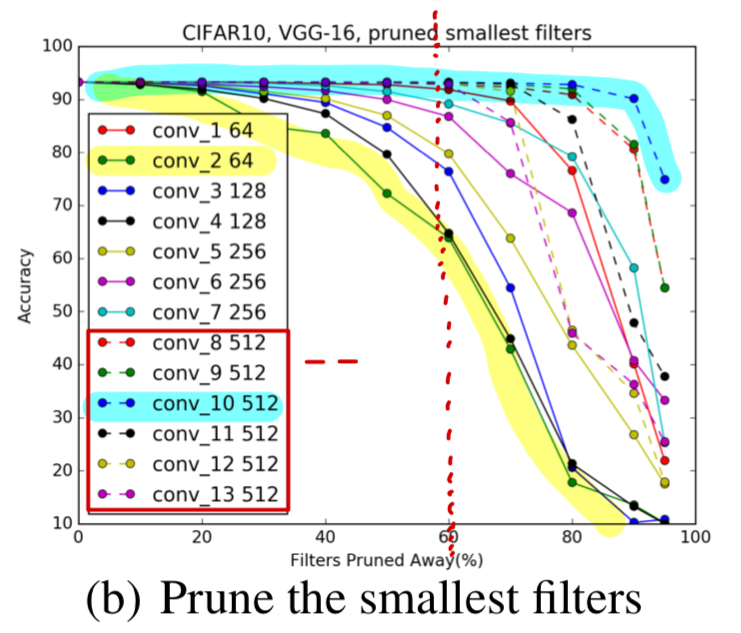
논문에서 주장한 대로,
뒷쪽의 conv layer들이 pruning에 보다 robust한지 알아 보기 위해
이미 학습해두었던 baseline model parameter를 이용하여
Figure 2. (b)와 똑같이 visualization해보았다. -
나의 Figure2. (b) :
결과는 논문에서와 같이 뒷쪽의 conv layer들이 pruning에 더욱 sensitive한 것을 알 수 있었다.- main code : 00_vgg16_prune_and_retrain/fig2_b_vgg16_prune_smallest.py
- log file : 00_vgg16_prune_and_retrain/log/vgg16_pruning_log.txt
- visualization code : 03_Pruning_Filters_for_Efficient_Convnets/Figure_2.ipynb
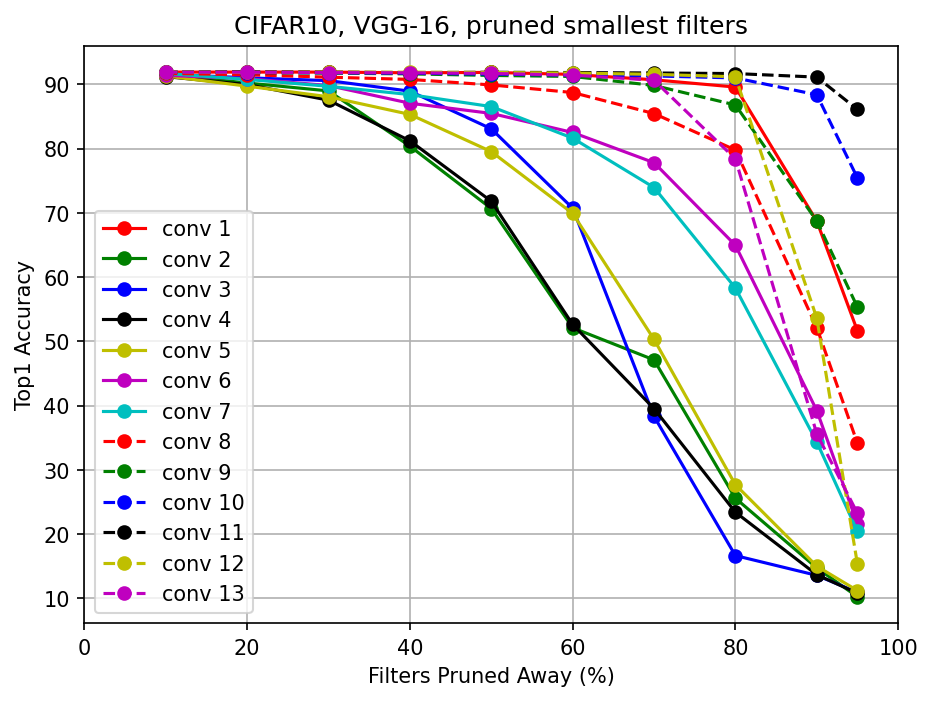
Figure 2. (c)
-
Figure 2. (b)에서처럼 pruning하는 것은 똑같지만,
20 epoch만큼 retrain시킨 후에 accuracy를 측정하여 visuliazation한 것이 (c)이다. -
논문에서의 Figure 2. (c) :
retrain을 시켜보니, 더욱 두드러지게 확인할 수 있는 것이
역시나 뒷쪽 conv layer들이 pruning에 매우 robust하다는 것이다.
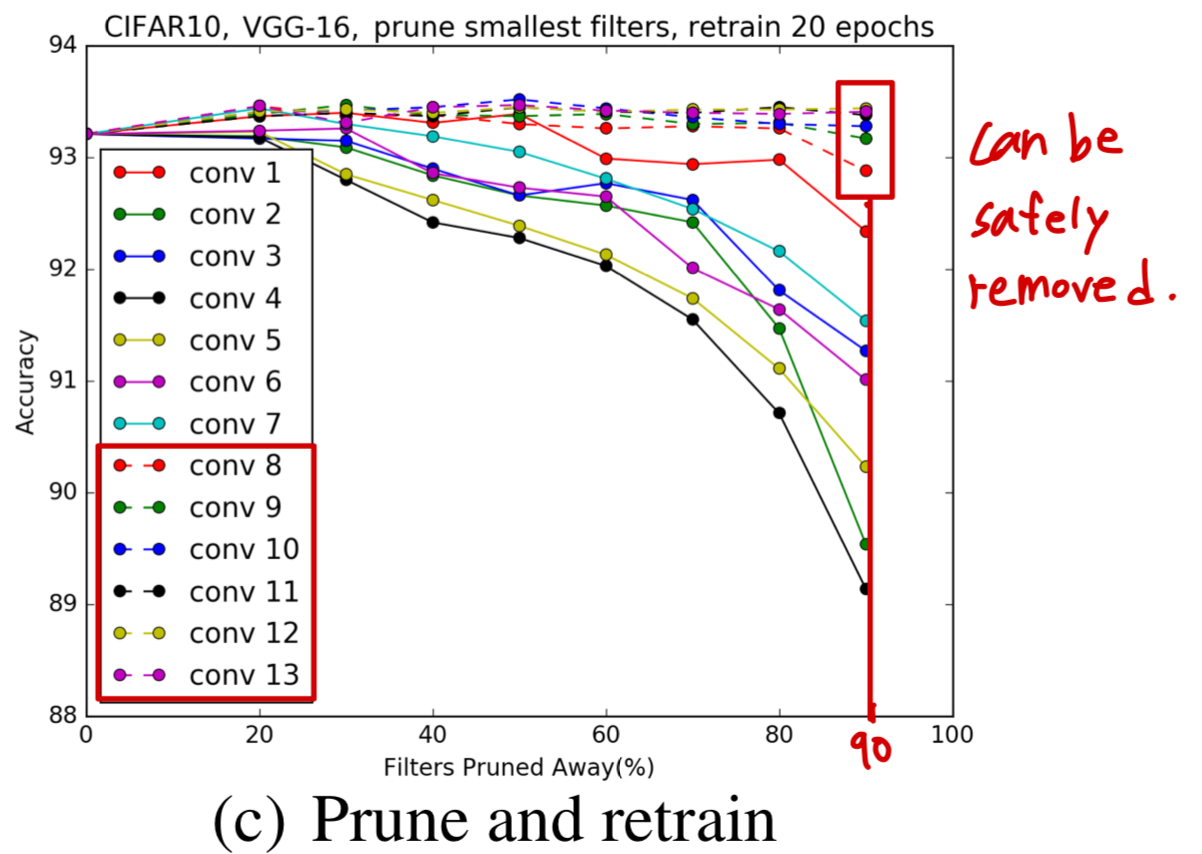
-
직접 구현한 Figure 2. (c) :
논문과 유사한 graph 형태가 그려진 것을 확인할 수 있었다.- main code : 00_vgg16_prune_and_retrain/fig2_c_vgg16_prune_smallest.py
- log file : 00_vgg16_prune_and_retrain/vgg16_pruning_retrain_log_epoch20.txt
- visualization code : 03_Pruning_Filters_for_Efficient_Convnets/Figure_2.ipynb
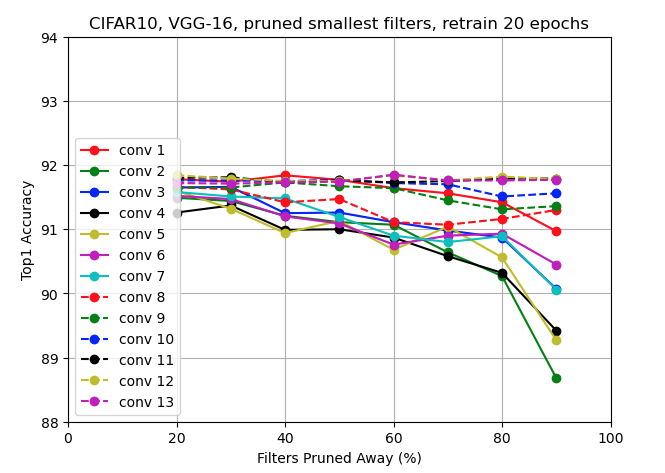
Table 1.
-
논문에서 Table 1.에 VGG-16에 대한 3가지 model에 대해서
Error%, #FLOPs, FLOPs Pruned%, #Parameters, Parameters Pruned%를 비교하였다.

-
- VGG-16 :
baseline model - VGG-16-pruned-A :
train된 baseline model에서 one-shot pruning 후 40 epoch retrain - VGG-16-pruned-A scratch-train :
train되지 않은 baseline model에서 one-shot pruning 후 scratch train
- VGG-16 :
1. (baseline) 00_vgg16_baseline_exp1/
- VGG-16
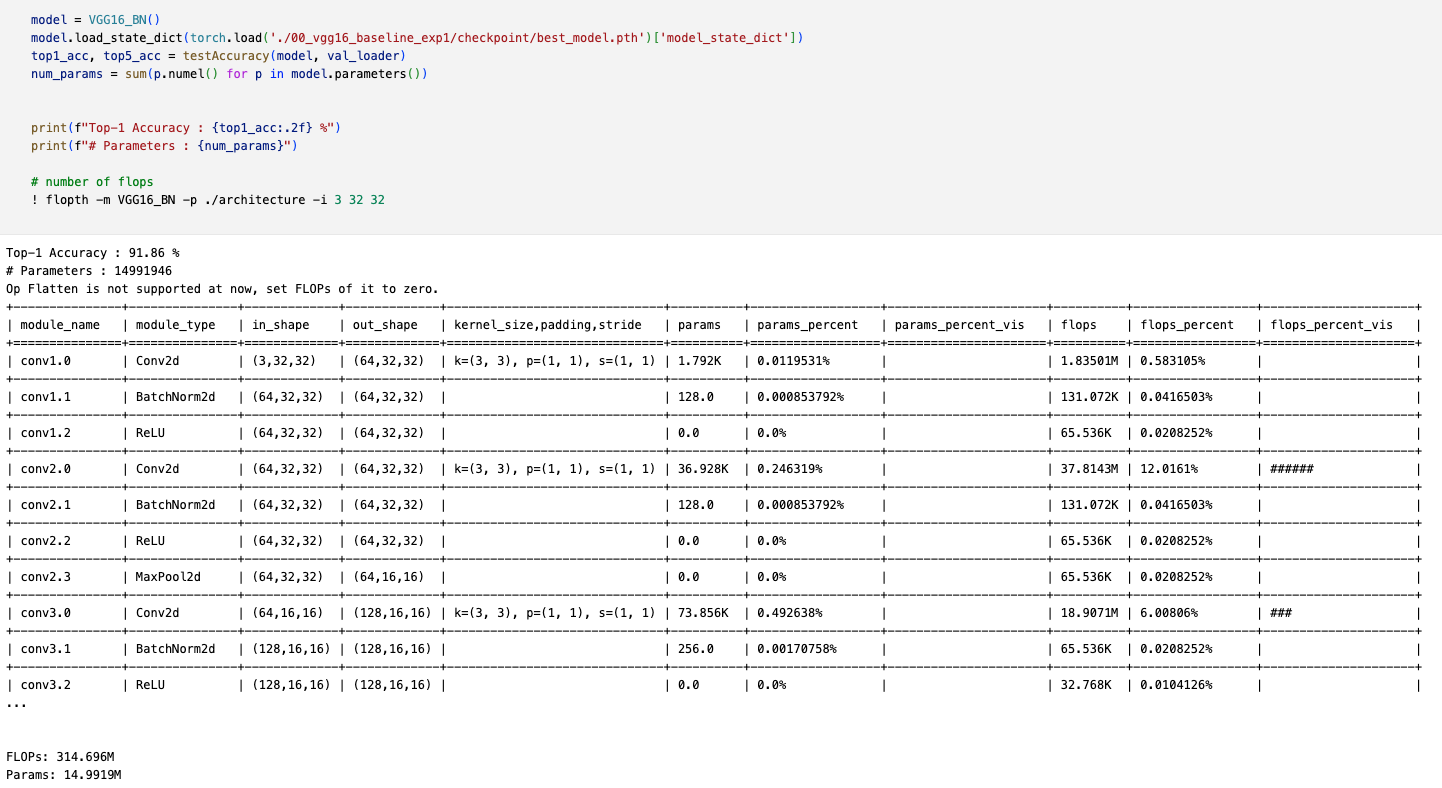
- Error% : 8.14%
- #FLOPs : 314.696M
- #Params : 14.991M
2. 01_vgg16_prune_A/
- VGG-16-pruned-A
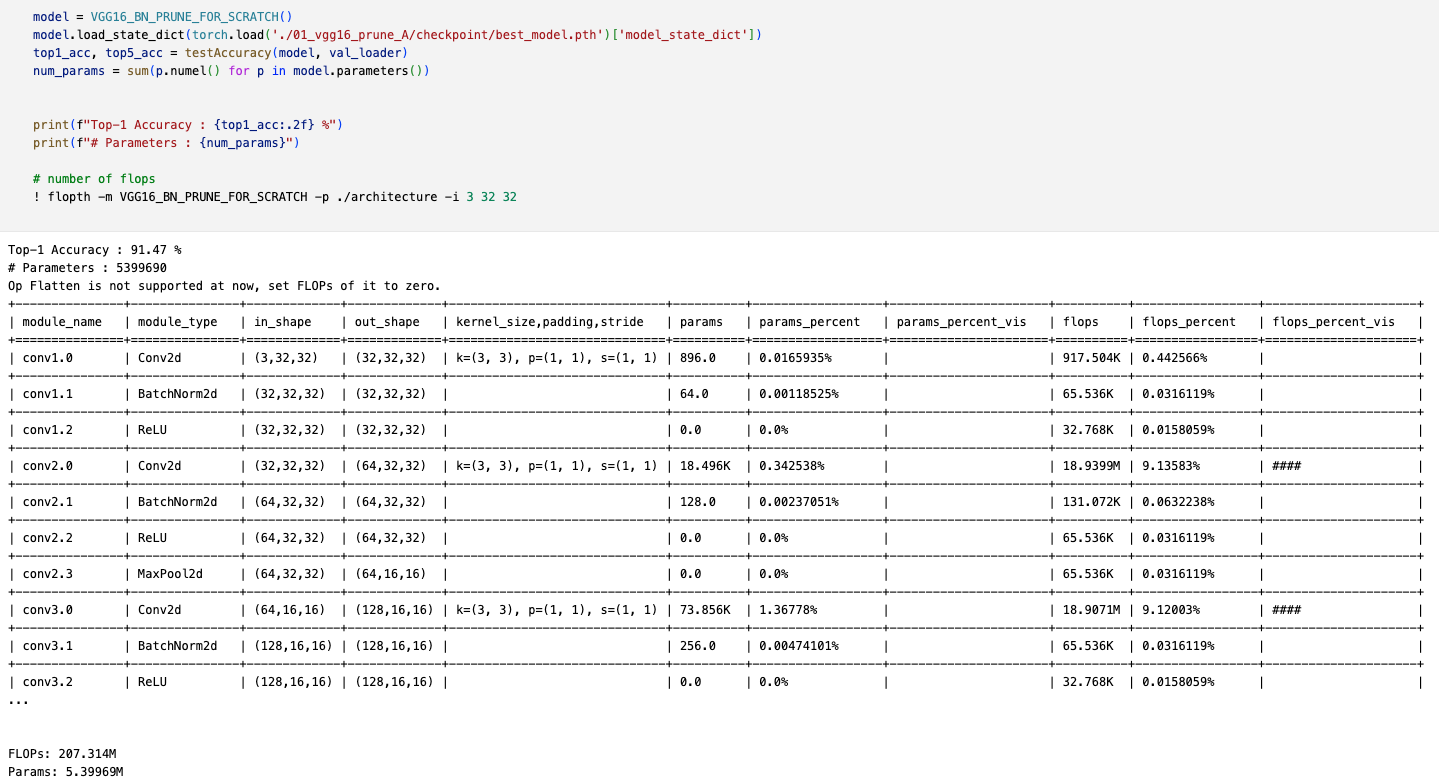
- Error% : 8.53% (+0.39%)
- #FLOPs : 207.314M (Pruned 34.12%)
- #Params : 5.39969M (Pruned 64.00%)
3. 01_vgg16_prune_A_scratch/
- VGG-16-pruned-A scratch-train
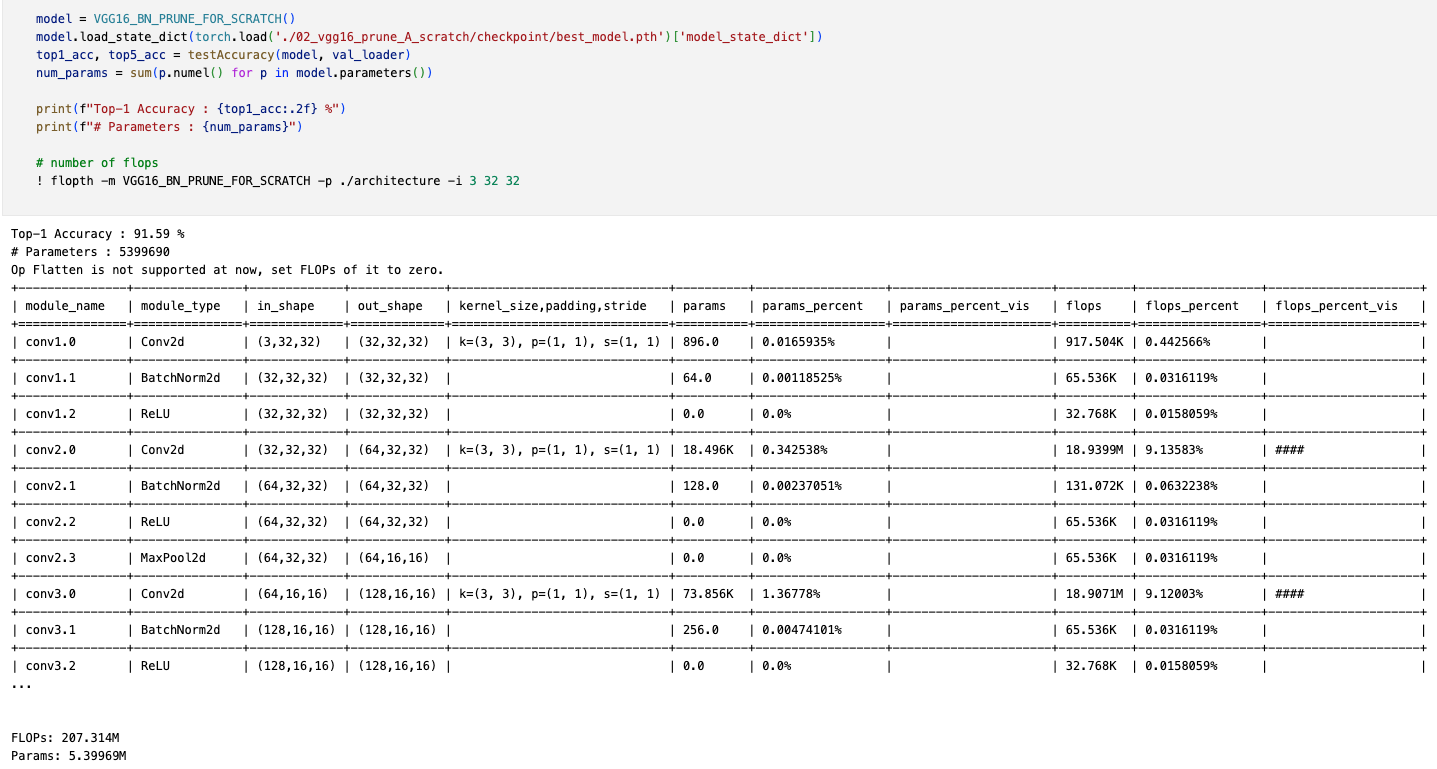
- Error% : 8.41% (+0.27%)
- #FLOPs : 207.314M (Pruned 34.12%)
- #Params : 5.39969M (Pruned 64.00%)
결론
baseline에 비해
34.12% 감소된 #FLOPs와 64% 감소된 #Params의 pruned model을 이용하여
baseline model의 error rate에서 단 +0.27%만 증가한 것으로 보아,
baseline model과 pruend model의 성능 차이는 거의 없다고 생각할 수 있다.
또한 논문과 유사한 결과가 나왔으니, pruning filter 구현을 성공적으로 한 것 같다.
