ResNet34/50 on ImageNet, ResNet32 on CIFAR-10
torch에서 제공하는 models.resnet34(pretrained=False)로 먼저 성능을 평가한 후에,
내가 만든 resnet34인 MyResNet34()로 성능을 평가하여
둘이 비슷한 성능을 보이는지 관찰할 계획..
그러기 위해 PaperResNet34부터 training 시작
exp 0
exp 0-1 : Paper_ResNet34_exp0-1.ipynb
-
pytorch 첫 실습이기 때문에
논문에서 dataset을 detail하게 전처리한 것을 신경쓰지 않고,
우선 models.resnet34()가 제대로 training되는지 확인하고자 함. -
논문에서 learning rate를 plateau일 때 10씩 divide했다고 하여,
lr_scheduler를 다음과 같이 설정함.
하지만 epoch 40이 될 무렵, val loss와 val accuracy가 saturation되었는데도 lr decay가 되지 않았음.- 나중에 깨달은 이유이지만,
이 이유는 lr_scheduler의thresholdargument의 default값이 0.0001이어서
만약 loss가 0.0001 이상의 개선이 있었다면, patience가 0으로 초기화되기 때문
즉, validation의 flunctuation이 심한데다가 threshold가 매우 엄격해서 lr decay가 제대로 작동하지 않았단 것임.

- 나중에 깨달은 이유이지만,
lr_scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5, verbose=True)- 그래서 학습을 중단하고 epoch40 checkpoint의 model을 불러와서
learning rate를 손수 0.1 ➡️ 0.001로 바꾸어 학습을 진행
이때는 learning rate 0.1, 0.01이 매우 커서 학습이 제대로 진행되지 않을 것이라 생각하여 0.01이 아니라,
0.001로 바꾸어 학습을 진행시킴..
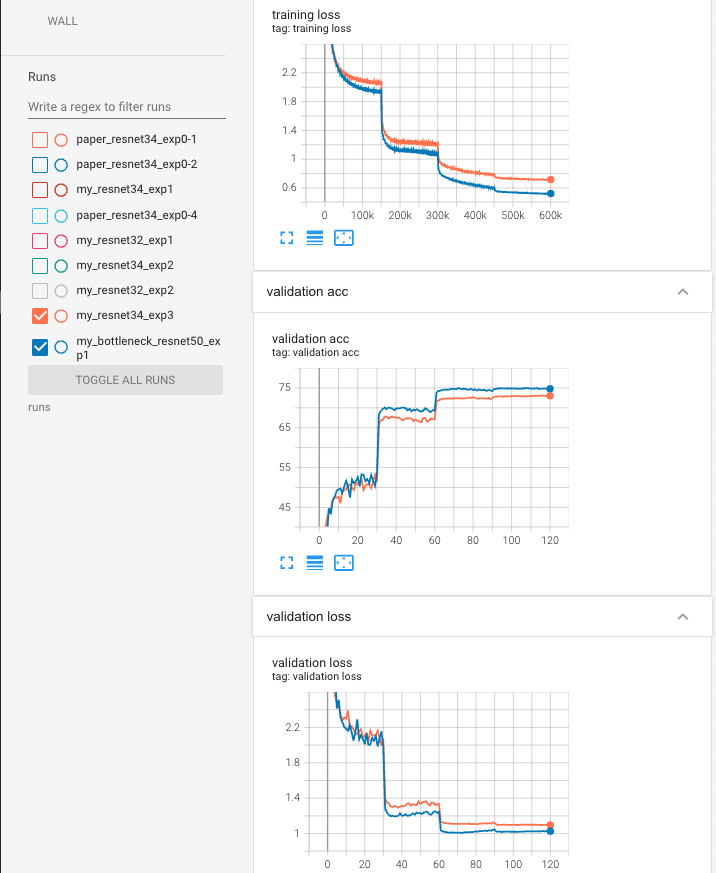
training graph
- 70 epoch부터 다시 val loss, accuracy가 정체되기 시작.
따라서 실험 0-2에서는 80 epoch에서 learning rate를 0.001 ➡️ 0.0001로 바꾸기로 ..
exp 0-2 : Paper_ResNet34_exp0-2.ipynb
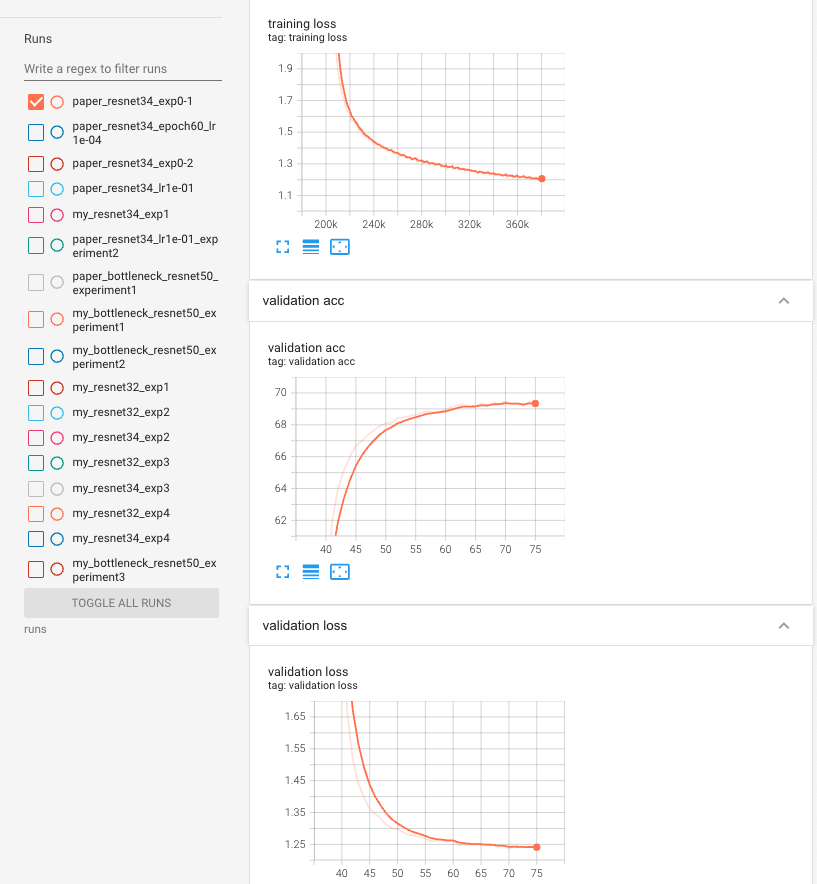
- 40 epoch부터 다시 training 시작(lr = 0.001)
80 epoch에서는 lr = 0.0001로 decay
training graph
- 80 epoch에서 lr decay를 하자마자 val loss, acc가 좋아지는 것을 확인할 수 있음.

실험 0-1, 0-2를 거쳐 torch에서 제공하는 models.resnet34(pretrained=False)은 제대로 학습되는 것을 알 수 있었음.
이제 논문의 val loss, accuracy와 똑같게 training시키기 위해
data preprocessing, hyper parameter를 수정할 것임.
exp 0-3 : Paper_ResNet34_exp0-3.ipynb
-
이제 논문의 val loss, acc와 똑같게 training시키기 위해
dataset preprocessing, hyper parameter를 수정할 것임 -
논문에서 언급한 training data preprocessing 방법
-
THe image is resized with its shorter side randomly sampled in [256, 480] for scale augmentation[41]
- [41] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. :
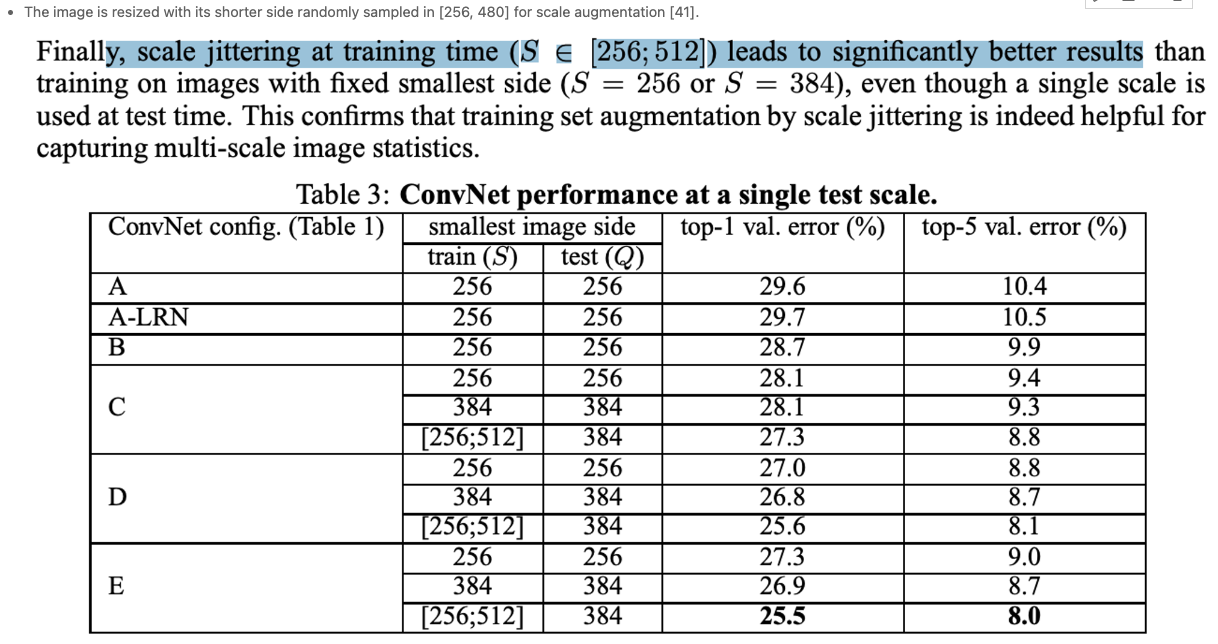
- [41] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. :
-
224 x 224 crop is randomly sampled from an image or it's horizontal flip, with the per-pixel mean substracted.
- [21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. :

- [21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. :
-
The color augmentation in [21] is used.
-
-
논문에서 한 preprocessing 방법을 기반으로 작성한 코드 :
class Lighting(object):
"""Lighting noise(AlexNet - style PCA - based noise)"""
def __init__(self, alphastd, eigval, eigvec):
self.alphastd = alphastd
self.eigval = eigval
self.eigvec = eigvec
def __call__(self, img):
if self.alphastd == 0:
return img
alpha = img.new().resize_(3).normal_(0, self.alphastd)
rgb = self.eigvec.type_as(img).clone()\
.mul(alpha.view(1, 3).expand(3, 3))\
.mul(self.eigval.view(1, 3).expand(3, 3))\
.sum(1).squeeze()
return img.add(rgb.view(3, 1, 1).expand_as(img))
__imagenet_pca = {
'eigval': torch.Tensor([0.2175, 0.0188, 0.0045]),
'eigvec': torch.Tensor([
[-0.5675, 0.7192, 0.4009],
[-0.5808, -0.0045, -0.8140],
[-0.5836, -0.6948, 0.4203],
])
}
trainset = torchvision.datasets.ImageFolder(
root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/train',
transform = transforms.Compose([
transforms.RandomResizedCrop(size=(256, 480)),
transforms.RandomCrop(size=224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
Lighting(0.1, __imagenet_pca['eigval'], __imagenet_pca['eigvec']),
])
)
valset = torchvision.datasets.ImageFolder(
root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/val',
transform=transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
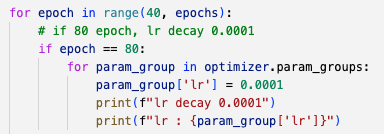
)- 또한 lr_scheduler를 제대로 작동시킬 수 있는 threshold argument를 알아냄.
따라서 val loss가 threshold=0.01보다 개선되지 않는 epoch이 3번 연속 지속된다면,
lr decay가 수행됨
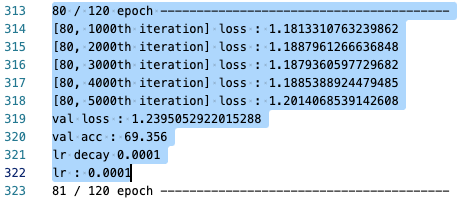
lr_scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=3, verbose=True, threshold=0.01)training graph
- 초록색 graph가 exp0-3 graph임.
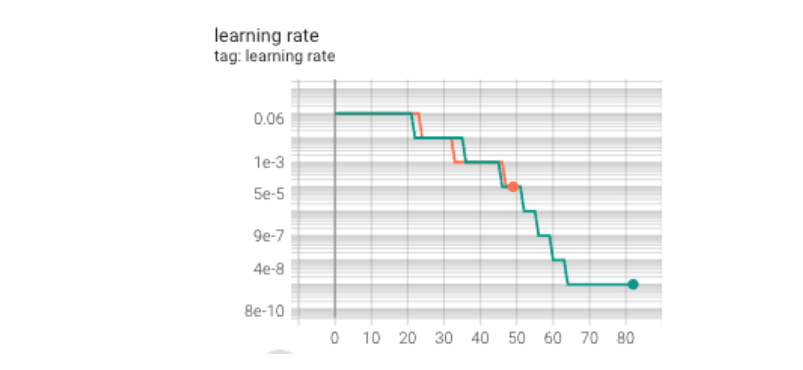
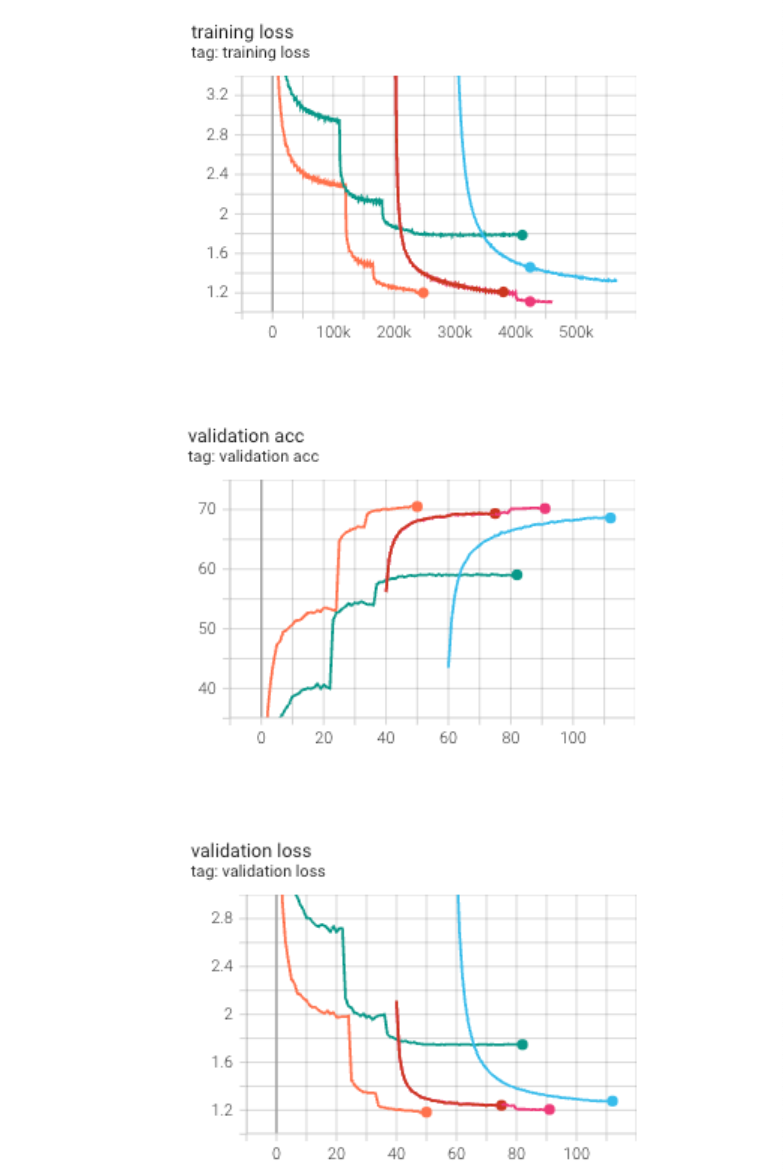
- val loss, acc의 성능이 더욱 안좋아지는 것을 확인..
나중에 이유를 알았지만, 그 이유는?
RandomResizedCrop() 함수에 대해서 잘못 알고 training을 진행했던 것이다...
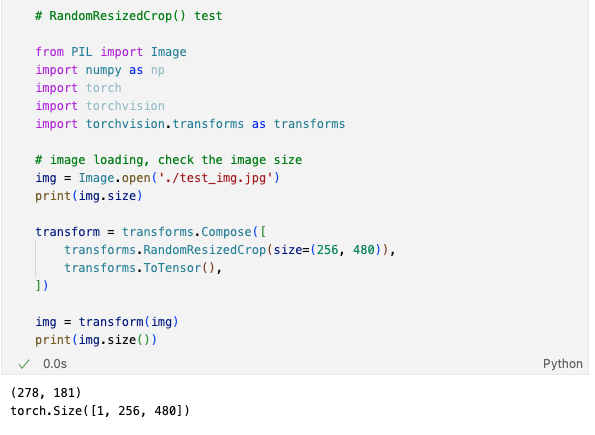
256 ~ 480 범위에서 random한 숫자로 shorter side를 만들어 (random x random) image를 만드는 것이 아니라
random한 crop 영역의 (256 x 480) image를 만드는 함수였다...
그래서 당연히 val loss, acc 의 성능이 떨어질 수 밖에 없었던 것이다...
- val loss, acc의 성능이 더욱 안좋아지는 것을 확인..
- 이때는 왜 성능이 더 나빠졌는지 이유를 몰랐어서(RandomResizedCrop() 때문임을 몰랐어서)
논문에서의 preprocessing 방법 말고,
pytorch community 또는 pytorch resnet sample code에서 사용했던 preprocessing을 그대로 사용하였다.
(exp 0-4)
exp 0-4 : Paper_ResNet34_exp0-4.ipynb
-
exp0-3에서는 왜 성능이 더 나빠졌는지 이유를 몰랐어서(RandomResizedCrop() 때문임을 몰랐어서)
논문에서의 preprocessing 방법 말고,
pytorch community 또는 pytorch resnet sample code에서 사용했던 preprocessing을 그대로 사용하였다.
(https://github.com/pytorch/examples/blob/42e5b996718797e45c46a25c55b031e6768f8440/imagenet/main.py#L89-L101)- torch github : examples/imagenet/main.py
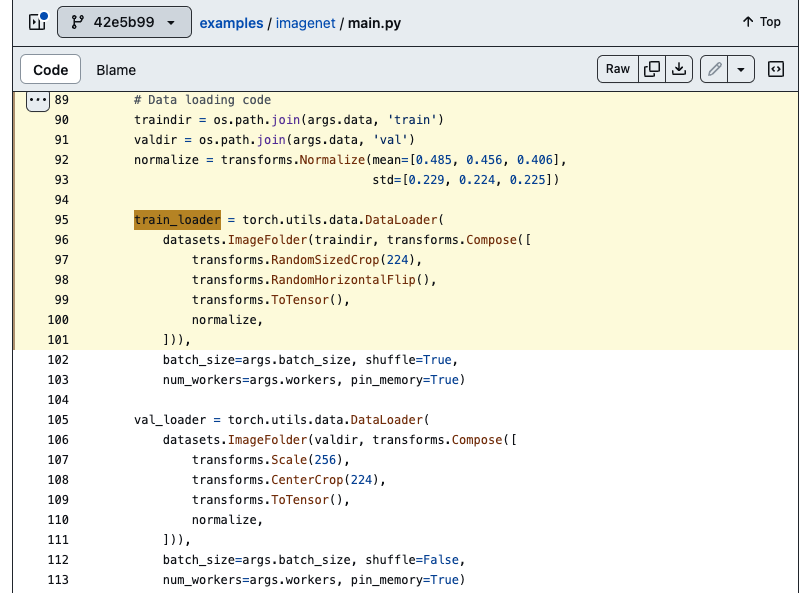
- 그대로 따라한 코드 :
trainset = torchvision.datasets.ImageFolder( root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/train', transform = transforms.Compose([ # transforms.RandomResizedCrop(size=(256, 480)), transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # Lighting(0.1, __imagenet_pca['eigval'], __imagenet_pca['eigvec']), ]) )valset = torchvision.datasets.ImageFolder( root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/val', transform=transforms.Compose([ transforms.Resize(size=256), transforms.CenterCrop(size=224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) )
- torch github : examples/imagenet/main.py
-
exp [0-1] ~ [0-3] + 추가 실험을 진행하면서 얻은
lr_schduler에 대한 heuristic한 직관으로 다음과 같이 설정.
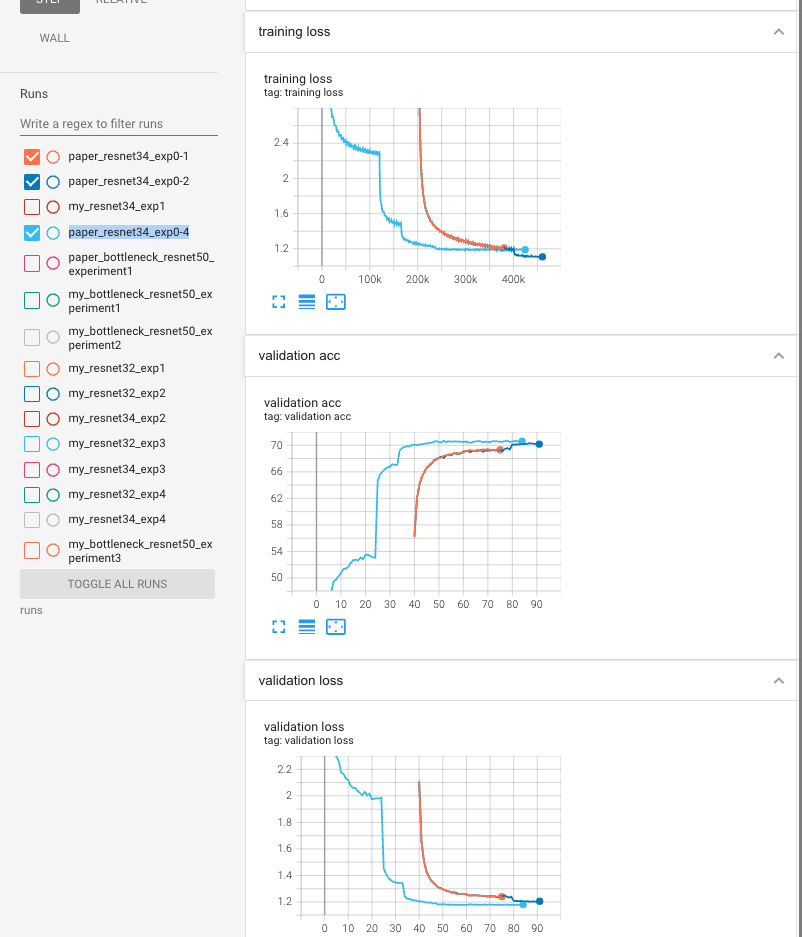
lr_scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=3, verbose=True, threshold=0.01)training graph
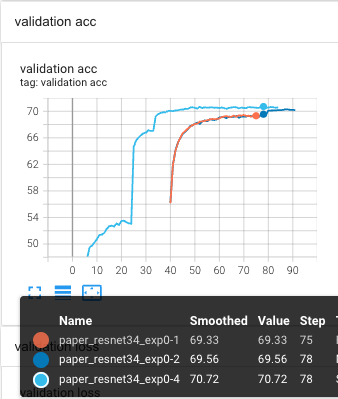
- exp [0-1] ~ exp [0-3] 중에서 가장 좋은 val loss, acc()를 보임.
top 1 val acc : 70.72% (78 epoch)
하지만 여전히 논문(78.16%)에 비하면 한참 모자람..
Top 1 val acc
Top-1 val acc: 70.72%
Top 1, Top 5 val acc (10-crop)
-
Paper:
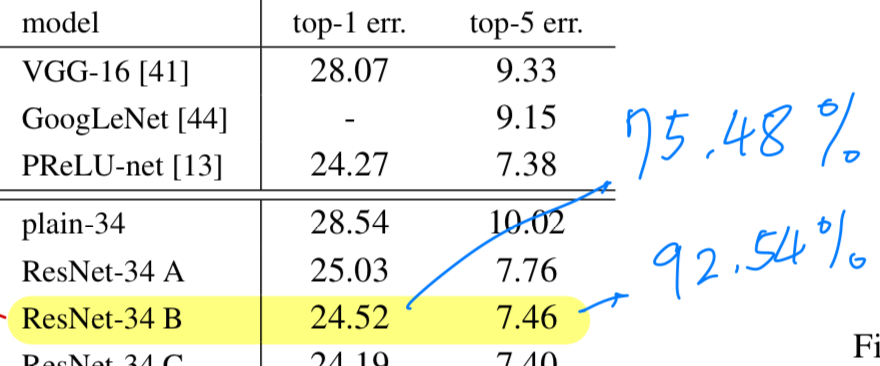
-
Top-1 val acc: 73.02%
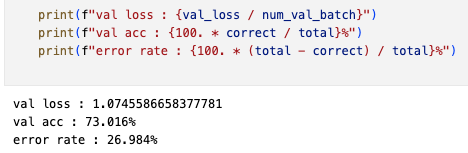
-
Top-5 val acc: 91.32%
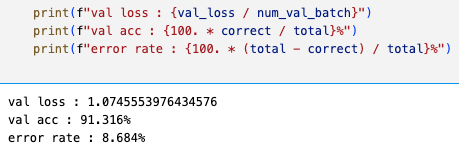
torch ResNet34는 training하는 데에 성공했지만,
논문과 image preprocessing, hyper parameter가 미세하게 달라서
완전히 똑같은 validation accuracy를 달성하지는 못했다..
[Paper]
top-1 val acc (10-crop) : 75.48%
top-5 val acc (10-crop) : 92.54%
[Torch]
top-1 val acc (10-crop) : 73.02%
top-5 val acc (10-crop) : 91.32%
My ResNet34 (first try)
exp 1 : My_Resnet34_exp1.ipynb
-
앞에서 했던 실험들 중 바로 위에서 했던
Paper_ResNet34_exp0-4.ipynb 가장 성공적인 성능을 보였으니
data preprocessing을 똑같이 하여 내가 만든 resnet34() 가 제대로 training이 진행되는지 확인해보고자 함 -
preprocessing, hyper parameter 모두 동일.
model만 models.resnet34()가 아닌 내가 직접 구현한 class인 resnet34()로 대체하여
training 진행.
training graph
- torch models.resnet34()와 차이점으로는
직접 구현한 resnet34() 인 것 빼고는 모두 같은 조건에서 training했으므로
동일한 graph 형태가 그려짐.
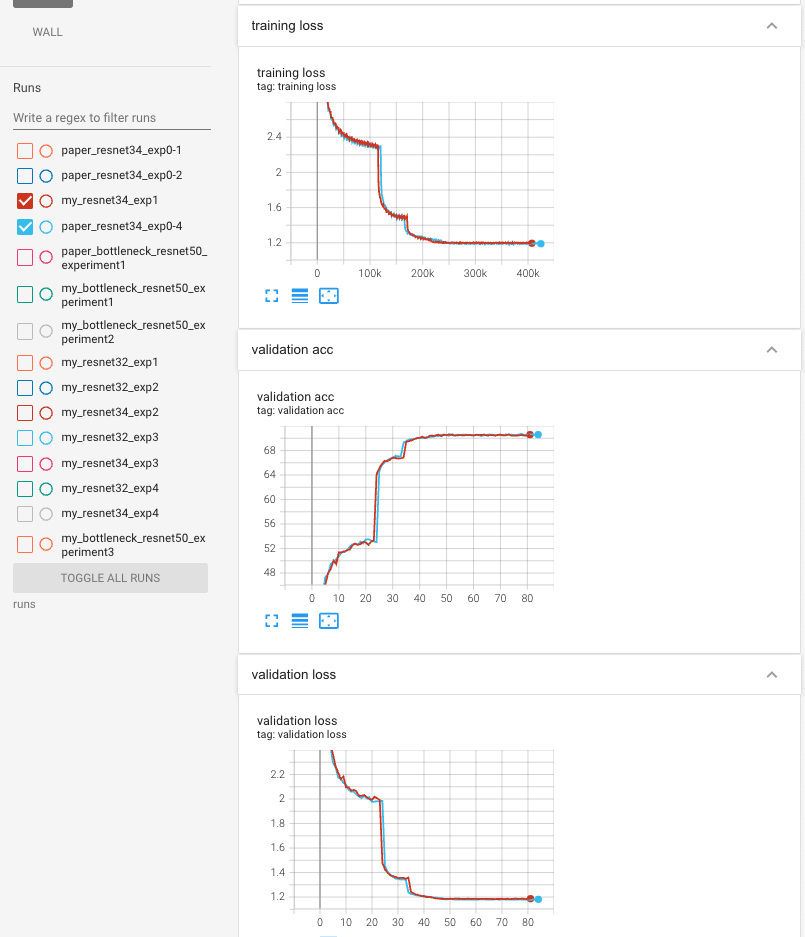
Top 1, Top 5 val acc (10-crop)
-
Paper:
-
Top-1 val acc: 72.914% (torch : 73.02%)
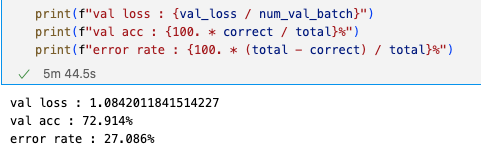
-
Top-5 val acc: 91.094% (torch : 91.32%)
10-crop testing을 하기 전에 centercrop()만 했을 때,
논문과 val acc 차이가 약 7~9% 차이가 났기 때문에
architecture 문제인지, image preprocessing 문제인지, hyper parameter문제인지 파악하기 어려웠다.
일단 torch에서 제공하는 models.resnet34()와 내가 구현한 myresnet34()의 val acc가 똑같이 나왔기 때문에
architecture 상의 문제는 없다고 판단했지만,
혹시 몰라서 ResNet32 on CIFAR-10을 구현하여 architecture의 문제가 없는지 또 한 번 판단하기로 했다.
My ResNet32 on CIFAR-10
-
MyResNet34의 architecture 문제가 있는지 없는지 판단하기 위해
똑같은 residual block을 이용하여 만든 resnet32를 이용하여
ResNet32 on CIFAR-10이 논문에서의 val acc와 똑같이 나오는지 판단하기로 했다. -
resnet paper에 소개한 대로 CIFAR-10을 위한 ResNet32를 구성하였고,
option (A), (B) 2개로 각각 training 시켜보았다.- option (B) :
projection shortcuts are used for increasing dimension - option (A)` : 논문에서 사용한 방법
zero-padding shortcuts are used for increasing dimensions. (parameter-free)
- option (B) :
-
참고로 논문에서 ResNet32 on CIFAR-10에는 option (A)를 사용함.
exp 1 : My_ResNet32_exp1.ipynb
- exp 1은
option (B)를 사용했다.- option (B) :
projection shortcuts are used for increasing dimension

- option (B) :
training graph
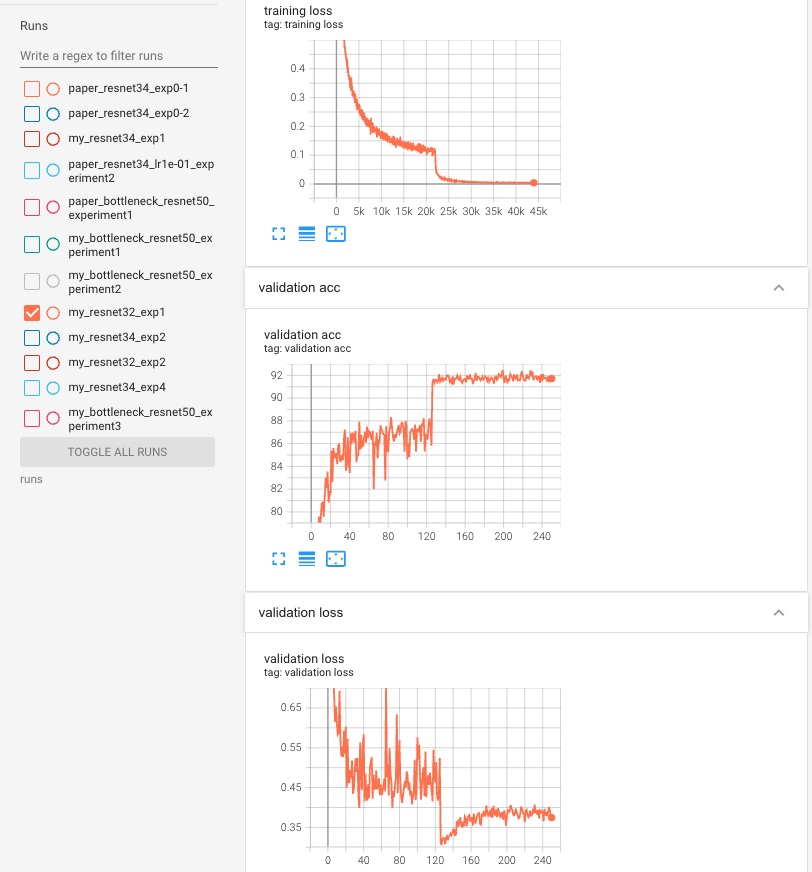
#params
- myresnet32 : 0.46M
- paper resnet32 : 0.46M
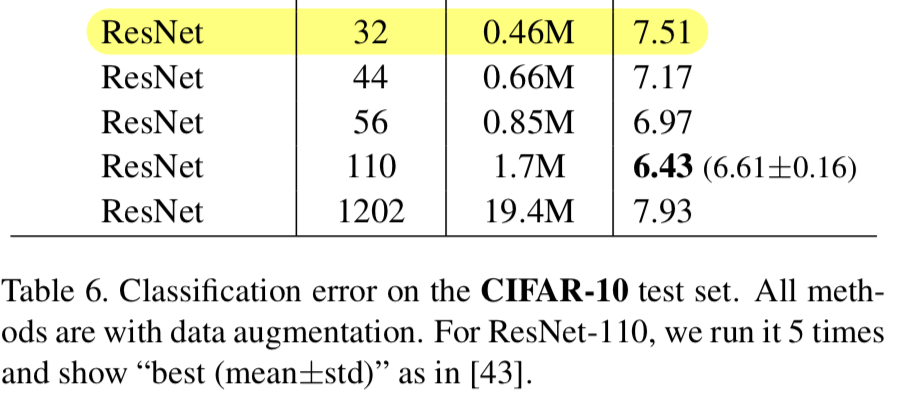
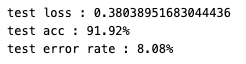
Top 1 test acc
Top-1 test acc: 91.84%(Paper : 92.49%)
exp 2 : My_ResNet32_exp2.ipynb
- exp 2은
option (A)를 사용했다.- option (A) :
zero-padding shortcuts are used for increasing dimensions. (parameter-free)

- option (A) :
training graph
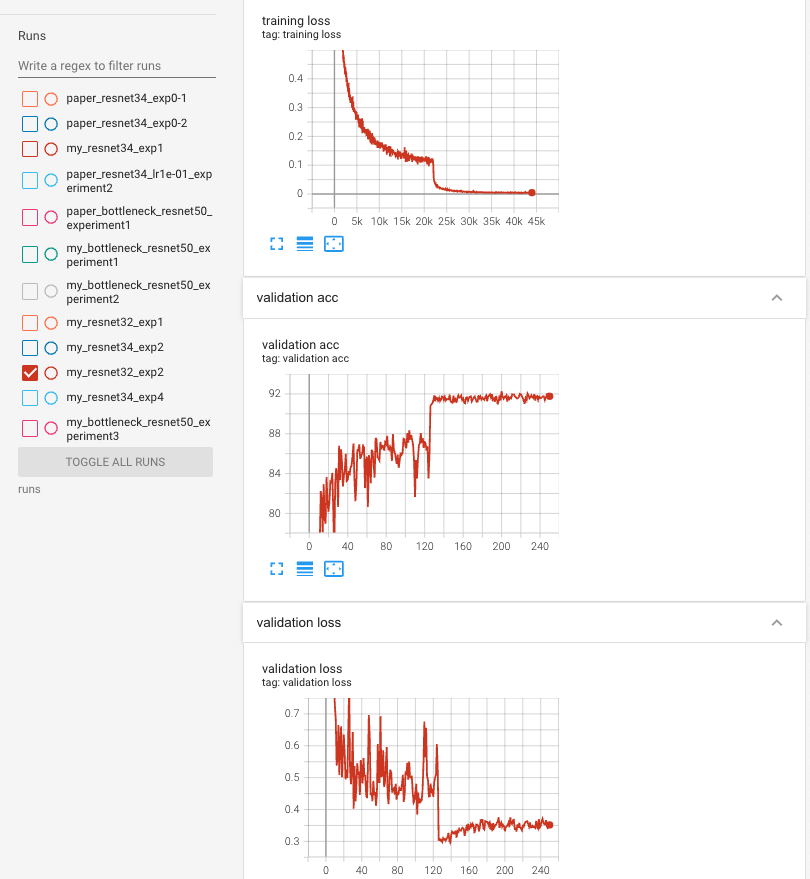
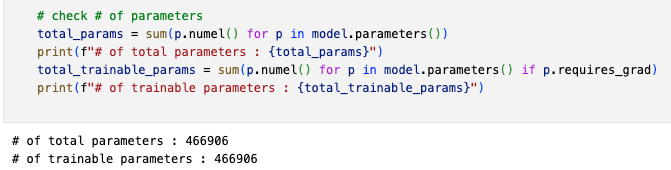
#params
-
myresnet32 : 0.46M
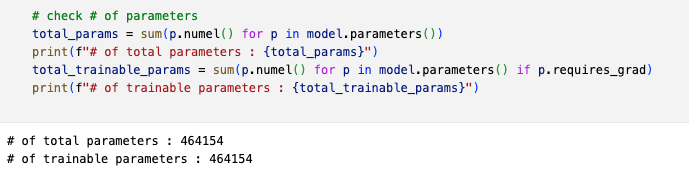
- dimension increasing할 때, zero padding(parameter free)이기 때문에
exp1에서의 # params (466906)보다 조금 더 적은 개수임을 알 수 있다.
- dimension increasing할 때, zero padding(parameter free)이기 때문에
-
paper resnet32 : 0.46M
Top 1 test acc
Top-1 test acc: 91.92%(Paper : 92.49%)
My ResNet34 (second try)
exp 2 : My_Resnet34_exp2.ipynb
-
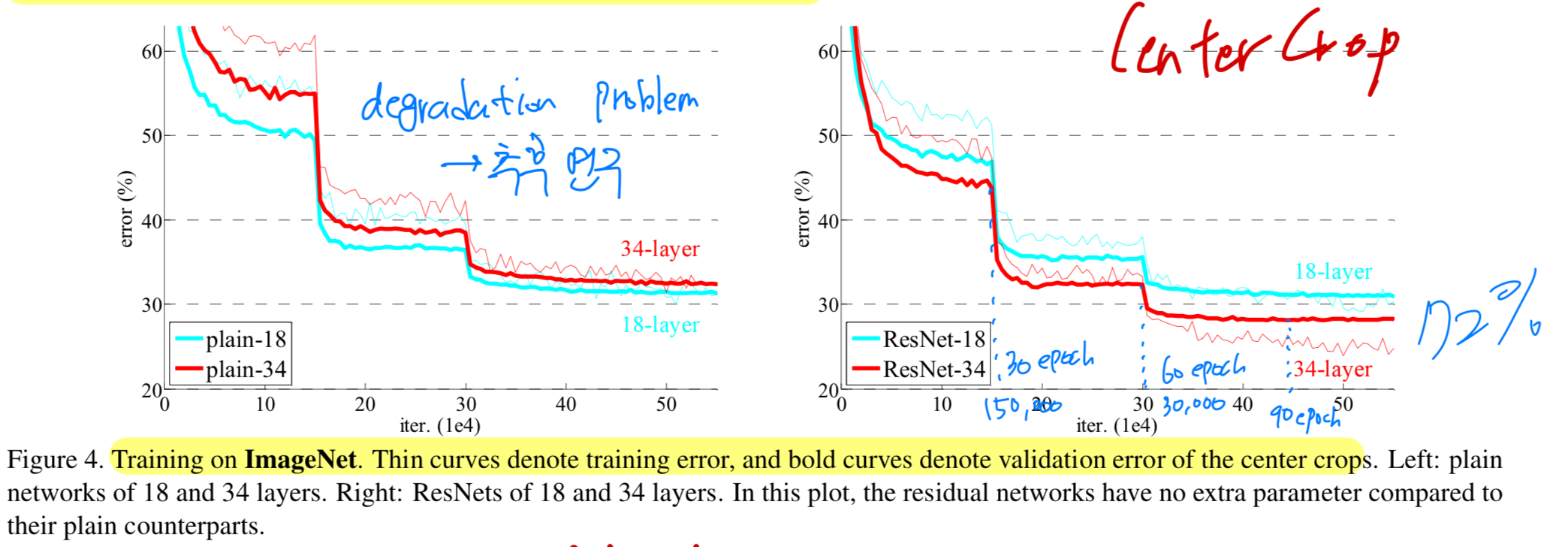
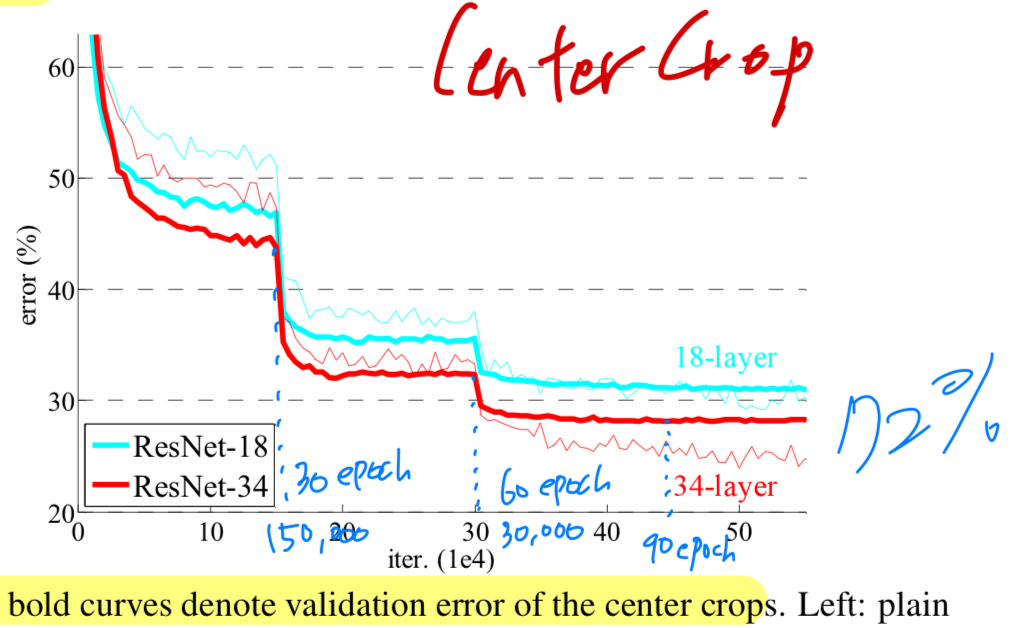
resnet32 on CIFAR-10을 진행하면서,
논문에 있는 figure 4.를 유심히 봤었는데
논문에서 글로는 plateau일 때마다 10씩 divide해줬다고 되어있었지만
figure 4에서는 30, 60, 90 epoch마다 10씩 divide해준 것을 추측할 수 있었다.
(figure 4의 오른쪽 graph)
-
그래서 exp2에서는
lr_scheduler로 ReduceLROnPlateau()를 사용하지 않고,
lr_scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30, 60, 90], gamma=0.1, verbose=True)로 수정하였다.
- 또한 논문에서 scale augmentation을 위해 써있던
"The image is resized with its shorter side randomly sampled in [256, 480] for scale augmentation [41]."을 위해
trainset의 transform에 다음의 함수를 추가함.
def shorter_side_resize(img):
w, h = img.size
if w < h:
new_w = torch.randint(256, 480, (1,)).item()
new_h = int(new_w)
else:
new_h = torch.randint(256, 480, (1,)).item()
new_w = int(new_h)
return transforms.Resize((new_h, new_w))(img)
trainset = torchvision.datasets.ImageFolder(
root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/train',
transform = transforms.Compose([
shorter_side_resize,
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
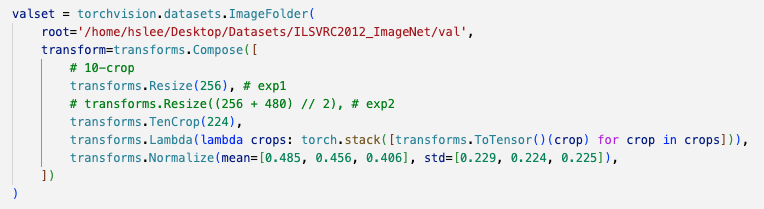
)- 그리고 이전에서는 논문에서 10-crop testing을 했다는 문장을 무시했었는데,
이번에는 마지막 test시에 10-crop dataset을 이용하여 평균을 내서 성능을 평가해봤다.
valset = torchvision.datasets.ImageFolder(
root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/val',
transform=transforms.Compose([
# 10-crop
transforms.Resize(256),
# transforms.Resize((256 + 480) // 2),
transforms.TenCrop(224),
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
)training graph
- 실수로 tensorboard에 그릴 graph를 삭제해버려서...
best model과 성능 평가 결과만 남음
Top 1, Top 5 val acc (10-crop)
-
Paper:
-
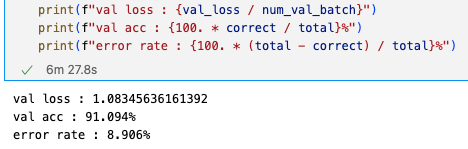
exp1:
top-1 val acc: 75.266%

top-5 val acc: 91.678%

-
exp2:

top-1 val acc: 73.006%

top-5 val acc: 91.678%

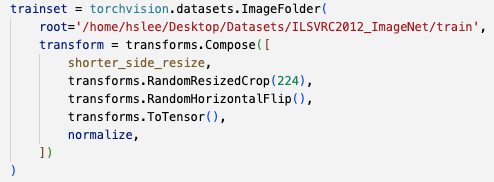
exp 3 : My_Resnet34_exp3.ipynb
- exp2에서 trainset transform에 transforms.RandomResizedCrop(224)을 사용했었다.
-
그런데 document를 자세히 참고하여 봤더니, (https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)
RandomResizedCrop(224)은 scale을 default (0.08, 1.0)으로 조정한 뒤,
random area를 224로 crop하는 함수였다.
하지만 scale augmentation을 위해서 앞서 shorter_side_resize 함수를 통해
scale을 [256, 480]으로 random하게 맞춰준 다음에 random하게 224만 crop하면 되는 것이기 때문에
RandomResizedCrop()이 아닌,RandomCrop()을 사용하는 것이 더 알맞은 것이라고 생각이 들었다. -
그래서 trainset transform에 transforms.RandomResizedCrop(224) 대신에
transforms.RandomCrop(224)으로 변경하여 다시 처음부터 학습을 돌려보았다.
trainset = torchvision.datasets.ImageFolder(
root='/home/hslee/Desktop/Datasets/ILSVRC2012_ImageNet/train',
transform = transforms.Compose([
shorter_side_resize,
# transforms.RandomResizedCrop(224),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
)training graph
- exp2의 training graph는 실수로 삭제하여 볼 수 없지만 비슷한 양상이었다.
그리고 확연하게 exp1보다 validation acc, loss가 좋은 것으로 보아 generalization 성능이 더 좋다고 생각할 수 있다.
또한 마침내
논문에서 Centercrop한 validation error graph와 동일한 양상, 동일한 error rate를 그려내는 데에 성공했다..!
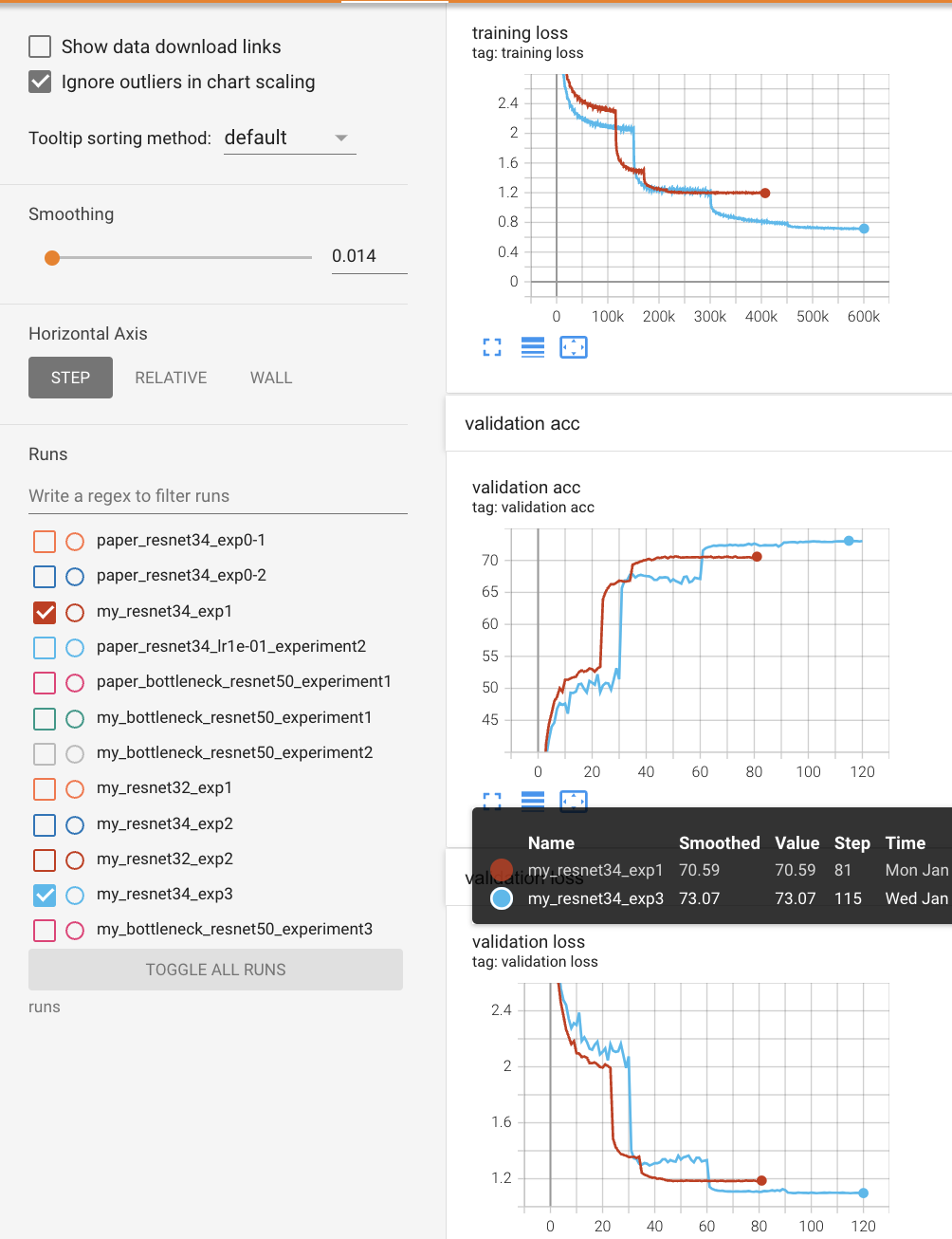
Top 1, Top 5 val acc (10-crop)
-
Paper:
-
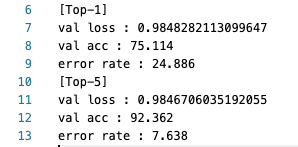
exp1:top-1 val acc: 75.114%top-5 val acc: 92.362%
-
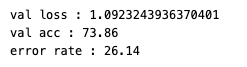
exp2:top-1 val acc: 73.86%top-5 val acc: 91.99%
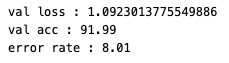
My ResNet50 (bottleneck)
exp1 : MY_bottleneckResnet50_exp1.py
- My_Resnet34_exp3와 모두 똑같은 preprocessing, hyper parameter.
- architecutre만 다름.
- 논문에서 ResNet50부터
bottleneck architecture를 사용.
따라서 1x1, 3x3, 1x1 형태의 residual block이 사용됨.

- 논문에서 ResNet50부터
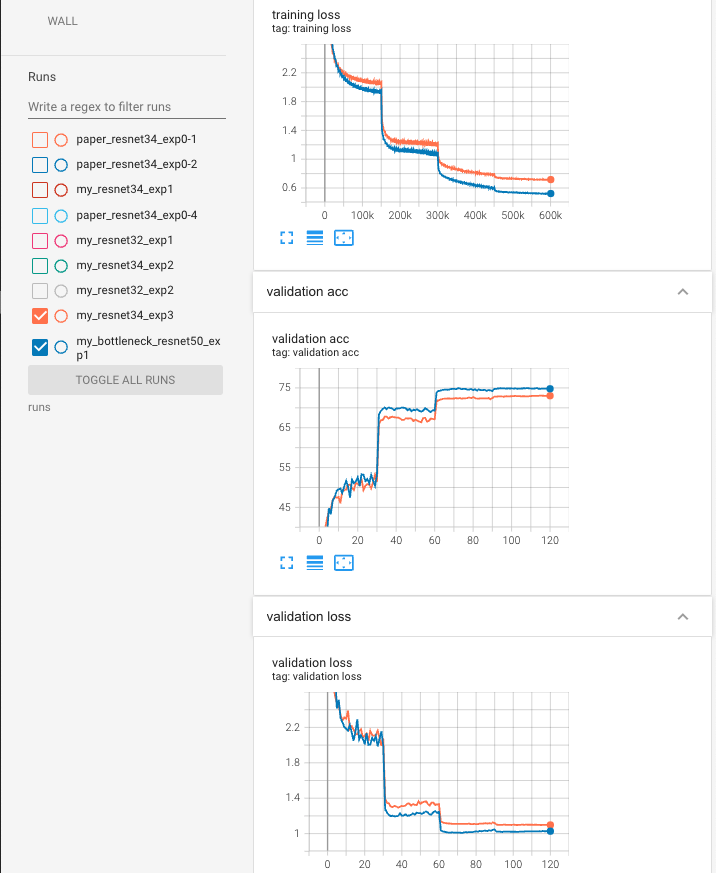
training graph
- ResNet34_exp3보다 ResNet50_exp1의 성능이 더욱 좋아짐
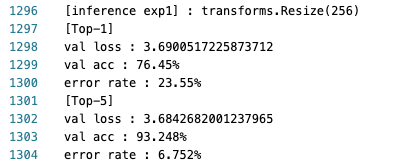
Top 1, Top 5 val acc (10-crop)
Paper:

exp1:top-1 val acc: 76.45%top-5 val acc: 93.248%
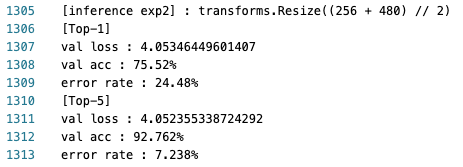
exp2:top-1 val acc: 75.52%top-5 val acc: 92.762%
마무리, 향후 계획
논문에서 제시한 architecutre를 직접 구현해본 결과,
accuracy가 약 0.05~0.1%가 떨어지는데, 거의 동일하다고 볼 수 있을 것 같다.
구현에는 성공했지만
아직실험은 시도해보지 못했다.
구현보다는실험이 중요하다고 생각하여 이제실험에 대해 고민해봐야겠다...
