[2022 arXiv] RTMDet: An Empirical Study of Designing Real-Time Object Detectors
[Paper Review] 2D Object Detection
Paper Info.
https://arxiv.org/abs/2212.07784
- Lyu, Chengqi, et al. "Rtmdet: An empirical study of designing real-time object detectors." arXiv preprint arXiv:2212.07784 (2022).
Abstract
-
이 논문에서,
우리는 YOLO series를 능가할 수 있고
instance segmentation and rotated object detection과 같이 다양한 object recognition tasks에 확장할 수 있는
an efficient real-time object detector를 설계 -
more efficient model architecture를 얻기 위해서,
backbone and neck에서 compatible(호환 가능한) capacitiy를 가진 architecture를 탐구했다.
이 architecture는 large-kernel depth-wise convolution으로 이루어진 a basic building block으로 구성된다.
-
우리는 accuracy를 향상시키기 위해
dynamic label assignment에서 matching cost를 계산할 때, soft labels을 도입했다. -
better training techniques와 함께,
결과적으로RTMDet라는 object detector는 NVIDIA 3090 GPU에서 300+FPS로 COCO에서 52.8% AP를 달성했다.
1. Introduction
-
Optimal efficiency는 real-world perception in autonomous driving, robotics 등에서 primary pursuit(연구)이다.
YOLO series는 one-stage detectors의 accuracy and efficiency를 향상시키기 위해 model architecture와 training technique을 탐구해왔다. -
이 연구에서,
우리는 YOLO series의 한계를 밀어내고
a new family of Real-Time Models for object Detection, namedRTMDet를 만드는 것에 집중했다. -
이 매력적인 improvements는 주로
better representation with large-kernel depth-wise convolutions and better optimization with soft labels in the dynamic label assignments에서 비롯되었다.- 특히,
우리는 model의 backbone and neck의 basic building block으로 large-kernel depth-wise convolutions을 사용했고,
이를 통해 model's capability of capturing the global context를 향상시킬 수 있었다.- 곧바로 building block을 depth-wise convolution으로 교체하는 것은 model depth를 증가시켜 inference speed를 느리게 하기 때문에,
model depth를 줄이기 위해 building blocks 개수를 줄이고 model width를 증가시킴으로써 model capacity에 대한 보상을 줬다. - 우리는 또한 neck에 더 많은 parameter를 넣고 backbone과 호환되도록 capacity를 맞춰준다면,
better speed-accuracy trade-off를 달성할 수 있다는 것을 관찰했다.
- 곧바로 building block을 depth-wise convolution으로 교체하는 것은 model depth를 증가시켜 inference speed를 느리게 하기 때문에,
- 우리는 model accuracy를 향상시키기 위해 training strategies를 재탐구했다.
- a better combinations of data augmentations, optimizationsm and training schedules 외에도,
기존의 dynamic label assignment strategies가 hard label 대신 soft targets을 도입함으로써
ground truthboxes and model predictions을 matching할 때 더욱 개선될 수 있음을 실험적으로 발견했다. - 이러한 design은
the discrimination(판별력) of the cost matrix for high-quality matching을 향상시킬 뿐만 아니라
the noise of label assignment를 줄여 model accuracy를 향상시킨다.
- a better combinations of data augmentations, optimizationsm and training schedules 외에도,
- 특히,
-
Fig. 1에서 볼 수 있듯이,
RTMDet은 previous methods 보다 better parameter-accuracy trade-off를 달성한다.
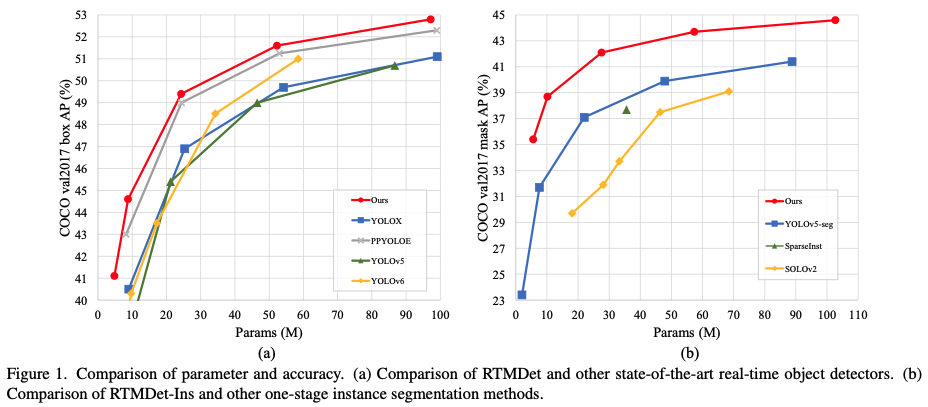
Specifically,- RTMDet-tiny achieves 41.1% AP at 1020 FPS with only 4.8M parameters.
- RTMDet-s yields 44.6% AP with 819 FPS, surpassing previous state-of-art small models.
- When extended to instance segmentation and rotated object detection,
RTMDet obtained new SOTA performance on the real-time scenario on both benchmarks,
with 44.6% mask AP at 180 FPS on COCO val set and 81.33% AP on DOTA v1.0, respectively.
2. Related Work
Efficient neural architecture for object detection.
-
real-time applications을 위해, 기존 연구는 주로 anchor-based or anchor-free one-stage detectors를 탐구했다.
model efficiency를 향상시키기 위해서,
efficient backbone networks and model scaling strategies and enhancement of multi-scale features을 handcrafted design or neural architecture search를 통해 탐구했다.
최근의 발전은 model deployment 이후 inference speed를 향상시키기 위해 model re-parameterization도 탐구한다. -
본 논문에서는 more efficient object detector를 위해 large-kernel depth-wise convolutions로 구성된 a new basic building block을 제안한다.
Label assignment for object detection
- object detector를 향상시키기 위한 또 다른 dimension은 the design of label assignment and training losses이다.
Pioneer(선구적인) methods들은 label assignment에서 model predictions 또는 anchors와 ground truth boxes를 비교하기 위한 matching criterion으로써 IoU를 사용한다.
Later practices는 object centers와 같은 다양한 matching criteria를 탐구한다.
Auxiliary detection heads는 또한 training의 속도 향상과 안정성을 위해 사용된다.
DETR에서 Hungarian Assignment에 영감을 받아, dynamic label assignment는 convergence speed and model accuracy를 크게 개선하기 위해 탐구되었다.
이러한 strategies들이 loss와 동일한 matching cost function을 사용하는 것과 달리,
우리는 matching costs를 계산할 때 stabilizing training and accelerating convergence를 위하여
high-quality matches와 low-quality mathces의 구분을 확대하였다.
3. Methodology
- 이번 연구에서,
우리는RTMDet라고 불리는 a new family of Real-Time Models for object Detection을 만들었다.
- RTMDet의 macro architecture는 전형적인 one-stage object detector이다. (Sec. 3.1)
- 우리는 backbone and neck의 basic building block에 large-kernel convolutions을 적용함으로써 model efficiency를 향상시키고,
model depth, width, and resolution을 적절하게 balance하였다. (Sec. 3.2)- 우리는 추가로 dynamic label assignment strategies에 soft labels을 적용하고,
model accuracy를 높이기 위해서 a better combination of data augmentations and optimization strategies를 적용했다. (Sec. 3.3)- RTMDet은 instance segmentation and rotated object detection tasks로 확장시킬 수 있는
versatile(다용도의) object recognition framework이다.
3.1. Macro Architecture
-
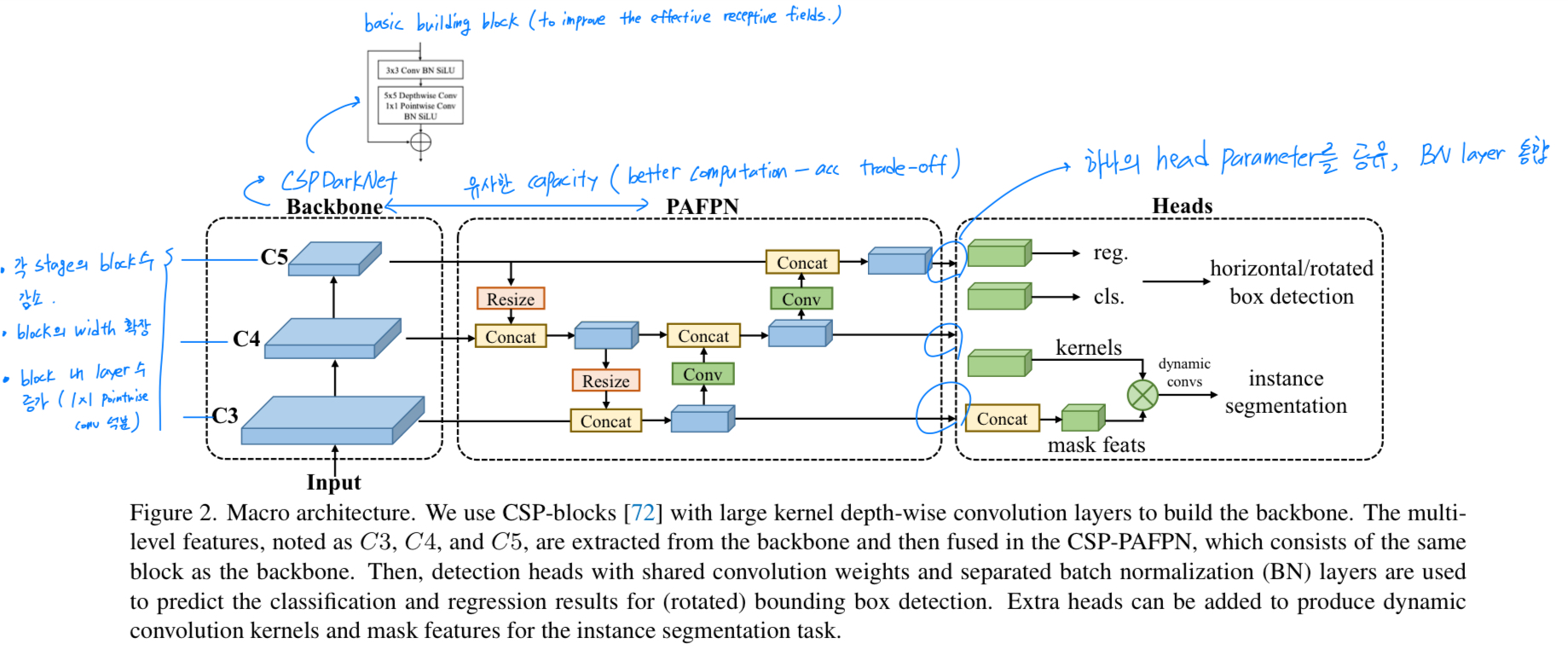
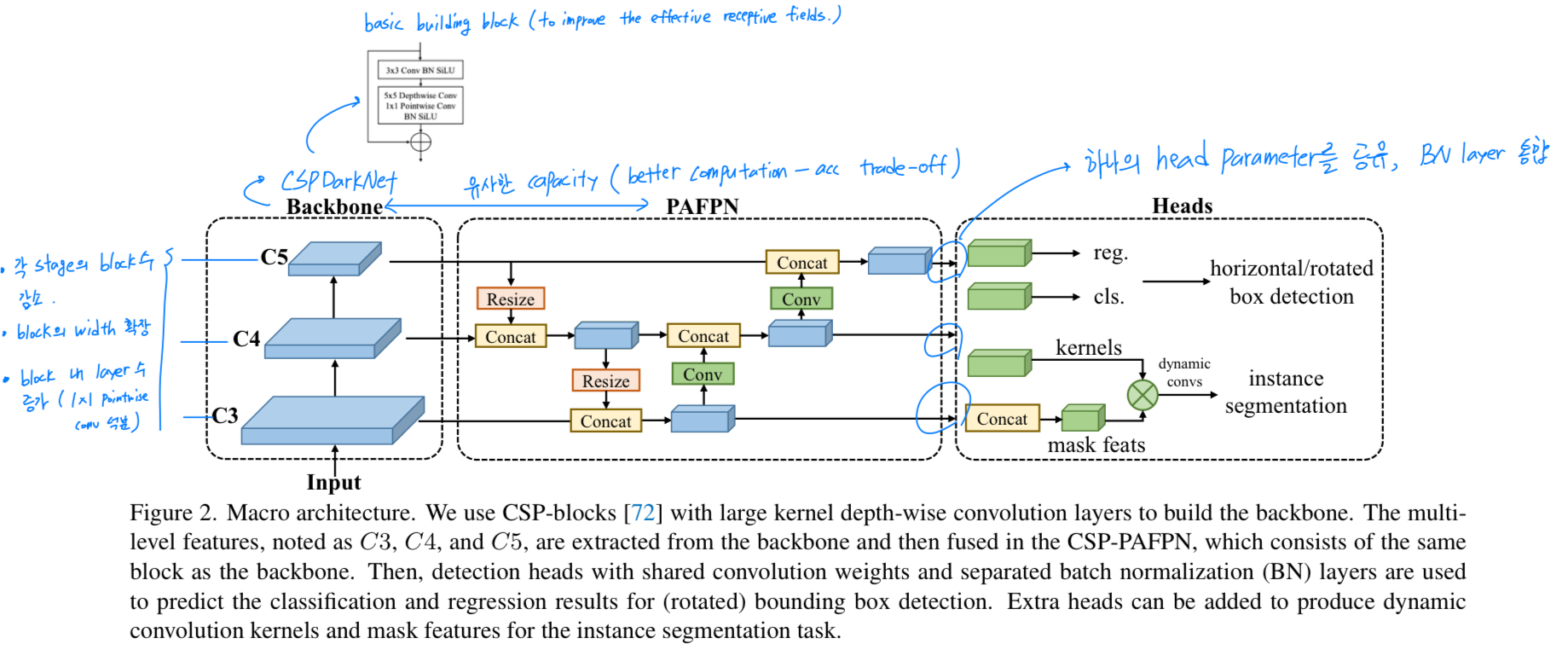
Fig. 2.에 있듯이,
the macro architecture of one-stage object detector를
backbone, neck, and head로 decompose했다.
-
backbone:
최근 YOLO series는 일반적으로 CSPDarkNet을 backbone architecture로 사용한다.
CSPDarkNet은 4개의 stage로 되어있고,
각 stage는 몇가지 basic building block이 stack되어져있다. (Fig.3.a)
-
neck:
neck은 backbone으로부터 multi-scale feature pyramid를 적용하고,
backbone과 동일한 basic building blocks을 사용하며,
bottom-up 및 top-down feature propagation을 통해 feature pyramid feature map을 향상시킨다 -
head:
마지막으로,
detection head는 각 scale에 대한 feautre map에 기반하여
object bounding boxes and their categories를 predict한다.
-
-
the potential of the macro architecture를 제대로 활용하기 위해서,
우리는 more powerful basic building blocks을 연구했다.
그리고나서 architecture의 computation bottleneck을 조사하고 backbone과 neck의 depth, width, and resolution을 balance하였다.
3.2. Model Architecture
Basic building block.
-
backbone에서 large effective receptive field는
object detection and segmentation과 같은 dense prediction tasks에 유리하다.
이는 image context를 더 포괄적으로 capture하고 modeling하는 데에 도움이 된다.
하지만 previous attempts(e.g., dilated convolution and non-local blocks)에서는
computationally expensive하고, real-time object detection에서 pratical use하기에 제한이 있다. -
최근 연구들은
the use of large-kernel convolutions을 재조명하면서,
depth-wise convolution을 통해 합리적인 computational cost로
receptive field를 확장시킬 수 있음을 보여줬다.
이러한 findings에 영감을 받아,
the effective receptive fields를 향상시키기 위해
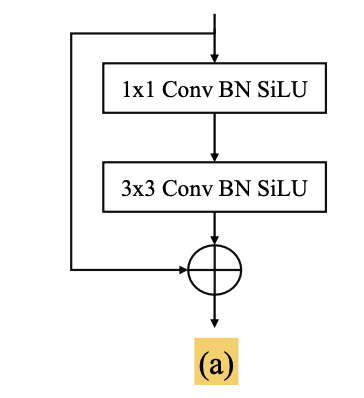
CSPDarkNet의 basic building block에 depth-wise convolutions을 도입했다. (Fig. 3.b)
This approach는 more comprehensive contextual modeling을 가능하게 하고 accuracy를 크게 향상시킨다.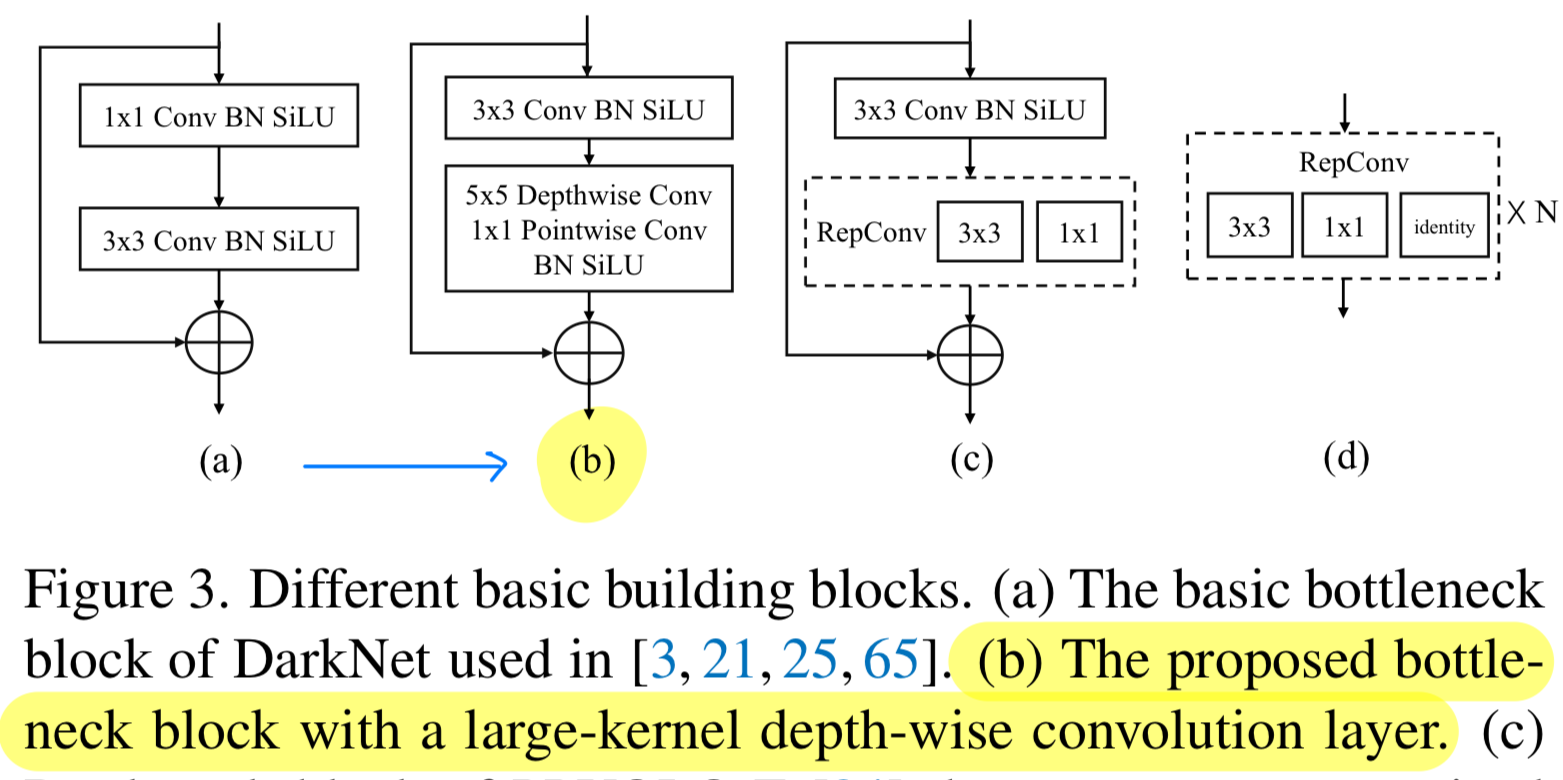
-
주목할 만한 점은,
최근의 real-time object detector들은
basic building block에서 re-parameterized(재구성된 ) convolutions을 탐구하고 있다. (Fig. 3.c&d)
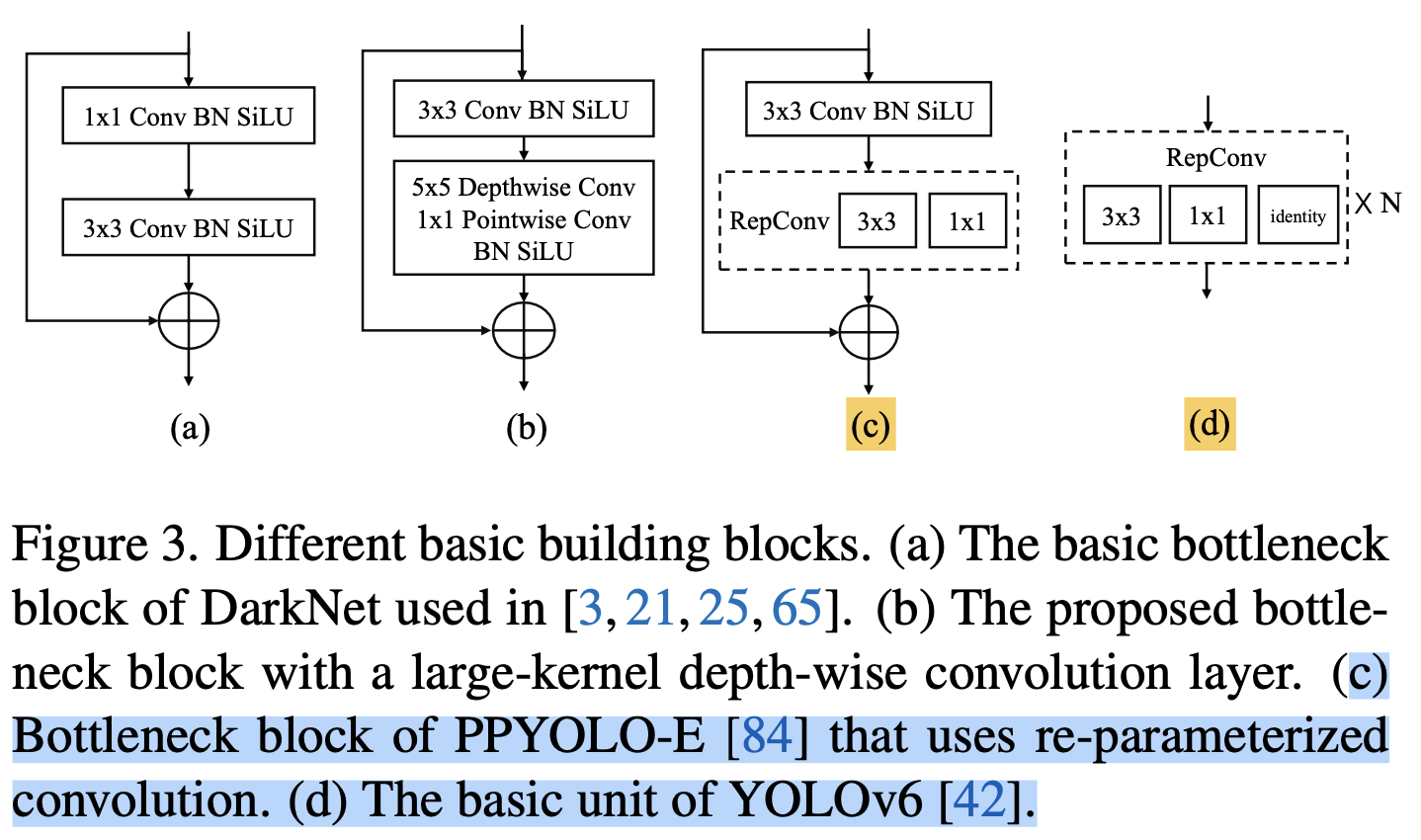 re-parameterized convolutions은 inference 시 accuracy를 향상시키기 위한 free lunch로 사용되지만,
re-parameterized convolutions은 inference 시 accuracy를 향상시키기 위한 free lunch로 사용되지만,
slower training speed and increased training memory와 같은 side effects를 유발한다.
또한,
model이 lower bits로 quantized된 후에 error gap이 증가하며,
이는 re-parameterizing optimizer와 quantization-aware training을 통한 compensation(보상)이 필요하다.
Large-kernel depth-wise convolution은
basic building block에 대한 re-parameterized convolution보다
training cost가 적고 model quantization 후 error gap이 적기 때문에
simple and more effective option이다.
Balance of model width and depth
- the large-kernel depth-wise convolution 뒤에 point-wise convolution 덕분에
basic block의 layer 수를 늘릴 수 있다.
이는 각 layer의 parallel computation을 방해하므로 inference speed가 감소한다. (?)
이 문제를 해결하기 위해서,
우리는 각 backbone stage의 block 수를 줄이고
parallelization을 증가시키기 위해 block의 width를 적절히 확장하고, model capacity를 유지시켰다. (실제로 accuracy 감소 없이 inference speed를 향상시킴)
parallel computation을 위해,
backbone stage의 block 수를 줄이고 block width를 확장하여 model capacity를 유지했다는데
이렇게 하면 왜 parallelization을 증가시키 수 있는 것인지 이해하지 못함...
Balance of backbone and neck.
- object detection에서 Multi-scale feature pyramid는
various scales의 object를 detect하기 위해 필수적이다.
multi-scale features를 강화하기 위해서 previous approaches는
a larger backbone with more parameters or a heavier neck with more connections을 사용한다.
하지만, 이러한 시도는 computation과 memory footprints를 증가시킨다.
그러므로,
우리는 basic blocks의 expansion ratio를 증가시킴으로써
backbone에서 neck으로 더 많은 parameters and computations을 옮기는 전략을 채택했다.
이를 통해 backbone과 neck의 capacity를 유사하게 만들어, better computation-accuracy trade-off를 얻을 수 있다.
backbone과 neck의 capacity를 유사하게 만든다해서 better computation-accuracy trade-off를 얻을 수 있는 것인가?
만약 그렇다면 왜 얻을 수 있는거지? 구체적인 설명과 가설을 얘기해줬다면 좋았을 것 같다.
(내 생각)
neck에서는 backbone에서와 달리 multi scale feature들에 대한 feature extraction이 진행된다.
구체적으로 neck에서는 high-quality(low resolution) feature map과 low-quality(high resolution) feature map이 fusion되어 더 중요한 feature extraction이 이루어진다.
따라서 backbone의 computation이 neck에 옮겨지는 것은 neck에서 더 중요한 feature extraction이 증가하는 것이기 때문에 accuracy가 증가할 수 있을 것 같다.
하지만 low resolution과 high resolution까지 다양한 크기의 feature map을 다루기 때문에 computation도 증가할 수 있을 것이다.
그래서 논문에서는 이 trade-off를 적절하게 하기 위해, backbone과 neck의 capacity를 유사하게 만들었다는 것으로 이해했다...
Shared detection head.
-
Real-time object detectors는 일반적으로 higher performance를 위해
model capacity를 향상시키기 위해 서로 다른 feature scales에 대해 개별 detection heads를 사용하는데,
이는 multiple scale에 거쳐 detection head를 공유하는 것과는 다르다. -
우리는 이 논문에서 다양한 design choices를 비교하고,
head의 parameter 양을 줄이면서도 accuracy를 유지하기 위해
scale 간에 head의 parameter를 공유하되, 다른 BN layer를 통합했다.
BN은 또한 Group Normalization과 같은 다른 normalization layers보다 더 효율적인데,
이는 inference 시에 training 중에 계산된 statistics(통계)을 직접 사용하기 때문이다.
BN layer를 통합했다는게 무슨 말이지?
head parameter를 공유한 것처럼 BN layer도 공유했다는 말인가?
Figure 2. caption을 봤을 때, (BN) layers are used to predict the classification and regression results for (rotated) bounding box detection
라고 되어있으니 어떠한 task든 BN layer를 통합해서 사용했다는 의미인듯.
3.3. Training Strategy
Label assignment and losses.
-
one-stage object detector를 train시키기 위해서,
각 scale의 dense prediction은
different label assignment strategies를 통해 GT bboxes와 match될 것이다. -
최근 발전은 일반적으로
training loss와 일치하는 cost functions을 matching criterion으로 사용하는
dynamic label assignment strategies를 채택한다.
(DETR의 bipartite matching)
하지만, 우리는 their cost calculation은 몇가지 limitations을 갖는다는 것을 알아냈다.
(어떤 limitation이 있는지???)
그래서, 우리는 SimOTA에 기반한 dynamic soft label assignment strategy를 제안하고,
그것의 cost function은 다음과 같이 formulated된다.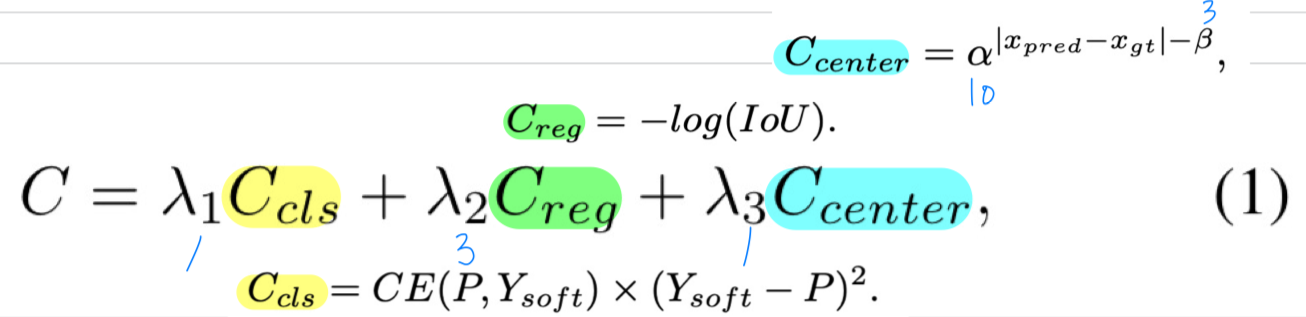
- :
이전 방법들은 보통 classification cost 를 계산하기 위해 binary labels(matching이 됐는지? 안됐는지?)을 이용한다.
(matching된 bbox끼리 classification cost 계산)
하지만 이는 classification과 regression이 서로를 방해한다.
(high classification score를 가진 prediction이 잘못된 bbox를 가질 때 low classification cost를 얻거나 그 반대의 경우도 가능하다.)
이러한 문제를 해결하기 위해, 우리는 에 soft labels을 도입한다.
이는 regression quality에 따라, classification loss를 reweight했다.
(IoU가 작으면, 고양이라고 추측할 확률을 좀 더 낮게 학습.
IoU가 크면, 추측할 확률을 좀 더 높게 학습.)
IoU가 1이면, 는 1이 됨)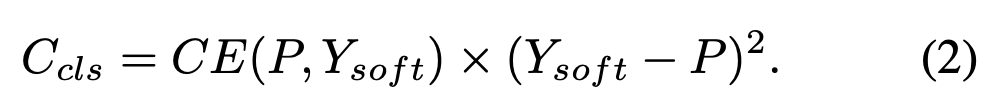 이 modification은 GFL에서 영감을 받았다.
이 modification은 GFL에서 영감을 받았다.
GFL은 prediction bbox와 GT bbox 간의 IoU를 soft label 을 사용하여 classification branch를 train시킨다. - :
Generalized IoU를 regression cost로 사용할 때,
best match와 worst match의 최대 차이는 1 미만이다.
이는 low-quality matches들로부터 high-quality matches를 구별하기 어렵다는 것이다.
다양한 GT-prediction 쌍의 match quality를 더 구별되게 하기 위해, loss function에서 사용되는 GIoU 대신 IoU의 log를 regressiong cost로 사용한다.
이는 IoU값이 낮은 matching에 대한 cost를 증폭시킨다.
regression cost 는 다음과 같이 계산된다.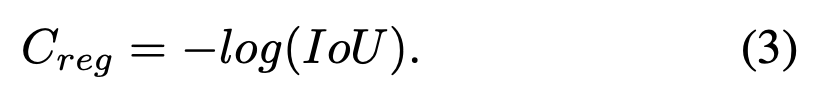
- :
region cost 에 대해서,
우리는 fixed center prior 대신 dynamic cost의 matching을 안정화하기 위해
soft center region cost를 사용한다.
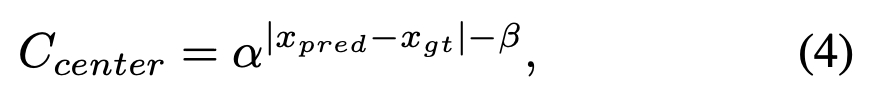
- :
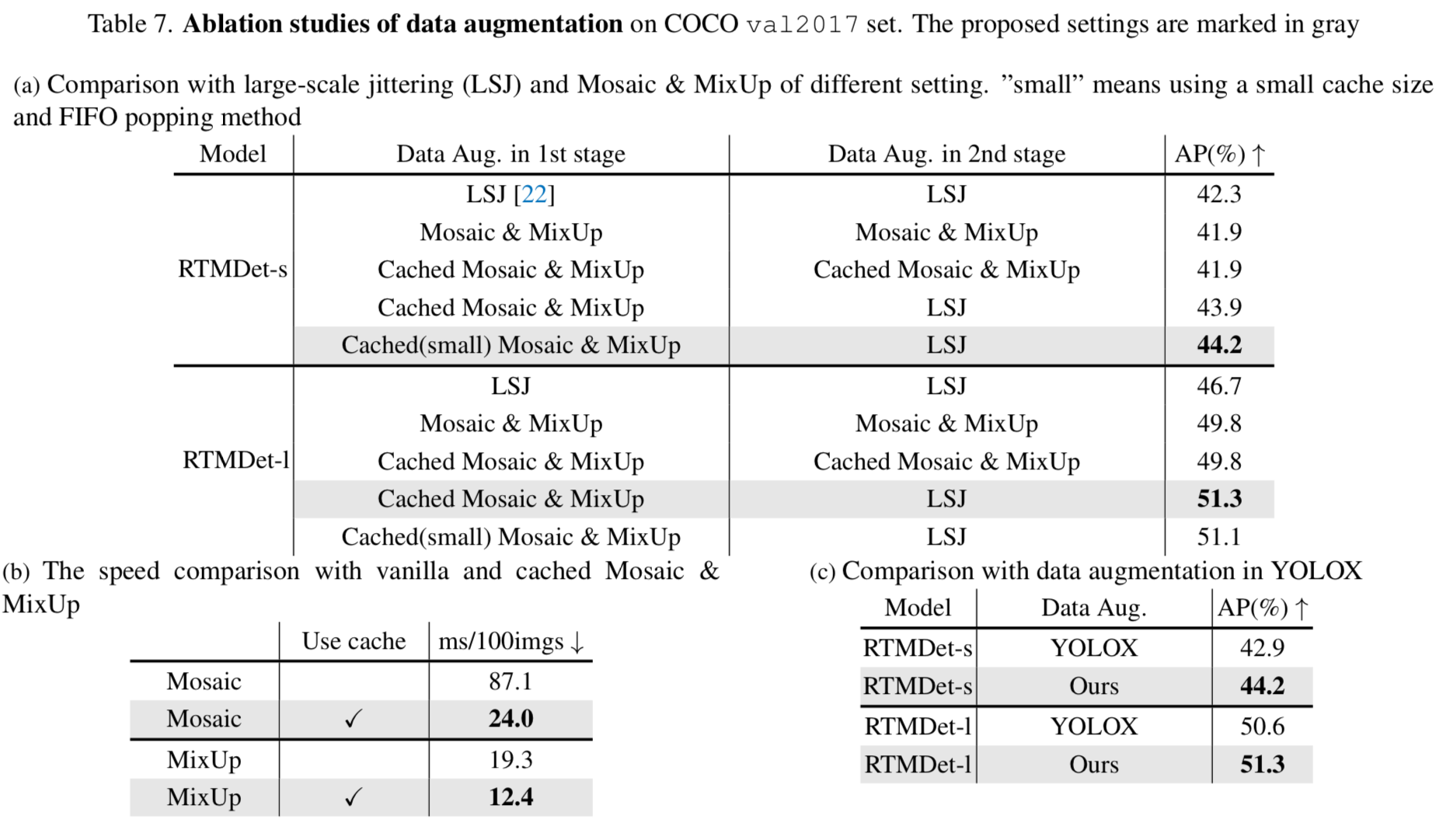
Cached Mosaic and MixUp
- 우리는 data loading 요구를 줄이기 위해 caching mechanism을 사용하여
MixUp과 Mosaic을 개선했다.
cache를 활용함으로써, training pipeline에서 image를 혼합하는 데 소요되는 시간을 single image를 처리하는 수준으로 크게 줄일 수 있다.
cache operation은 cache length와 popping method에 의해 제어된다.
large cache length and random popping method는 원래 cached되지 않은 MixUp and Mosaic operations과 동일한 것으로 간주될 수 있다.
반면, small cache length and FIFO popping method는 repeated augmentation과 유사하게 볼 수 있어,
동일한 image를 같은 batch나 연속된 batch에서 다른 data augmentation과 혼합할 수 있게 한다.
(이해 어려움..)
3.4. Extending to other tasks
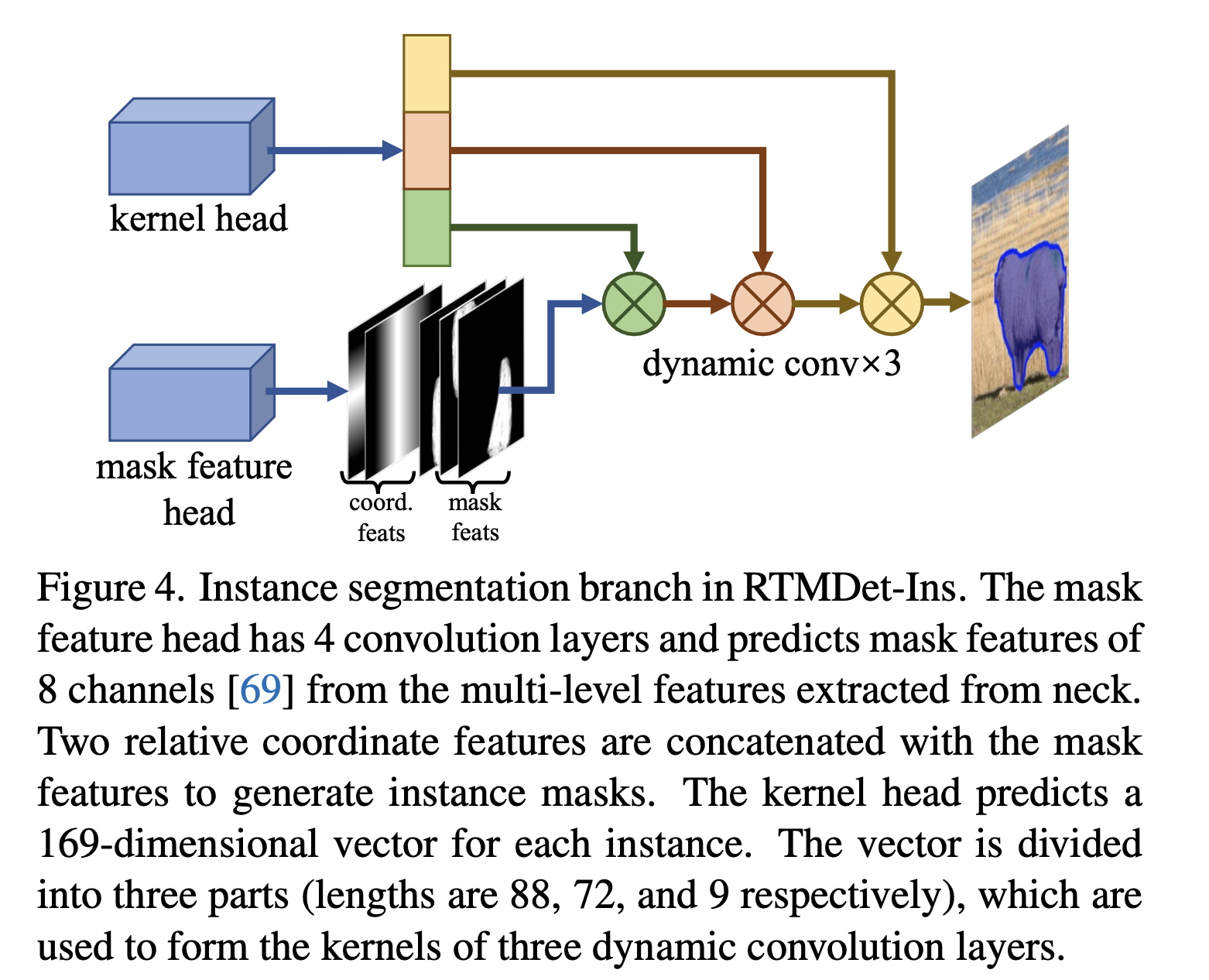
Instance segmentation
- 우리는 RTMDet을 간단한 수정으로 instance segmentation에 사용할 수 있도록 했으며,
이를 RTMDet-Ins라고 부른다.
Figure 4에서 설명된 것처럼, RTMDet에 additional branch가 추가되었고,
이는 CondInst와 유사한 kernel prediction head and a mask feature head로 구성된다.
mask feature head는 4 conv layer로 구성된다.
kernel prediction head는 각 instance에 대해 169-dimensional vector를 예측하며,
이는 mask feature and cooridinate feature와의 상호작용을 통해 instance segmentation mask를 생성하는 3개의 동적 conv kernel로 분해된다.
궁금한 점
- parallel computation을 위해,
backbone stage의 block 수를 줄이고 block width를 확장하여 model capacity를 유지했다는데
이렇게 하면 왜 parallelization을 증가시키 수 있는 것인지 이해하지 못함...
