SQL (Structured Query Language)
- 꼭 query를 위한 language는 아니다.
Table 생성 등 여러 가지에 사용된다.- DDL(Data Definition Language)와 DML(Data Manipulation Language)을 모두 포함
- 표준 발음은 "sequel(씨퀄)"이다.
Declarative(선언적) Language이다.
"어떻게"가 아니라 "무엇을"에 대해 기술. 원하는게 뭔지 선언함.
Procedural(절차적) Language(C언어)와는 반대이다.Relation DB를 생성하고 사용하는 순서
-
Design schema; create table using DDL
-
"Bulk load" initial data
-
Repeat; execute queries and modifications using DML
SQL 개요
DDL(Data Definition Language)
-
create table, drop table, alter table, ... 등
schema를 제어하는 조작어DML (Data Manipulation Language)
-
select, insert, delete, update, ... 등
Other commands
-
indexes, constraints(~오류가 나면, ~ 이렇게 처리해라), views, triggers,
transactions, authorization(특정 user에 특정 기능 부여), ... 등
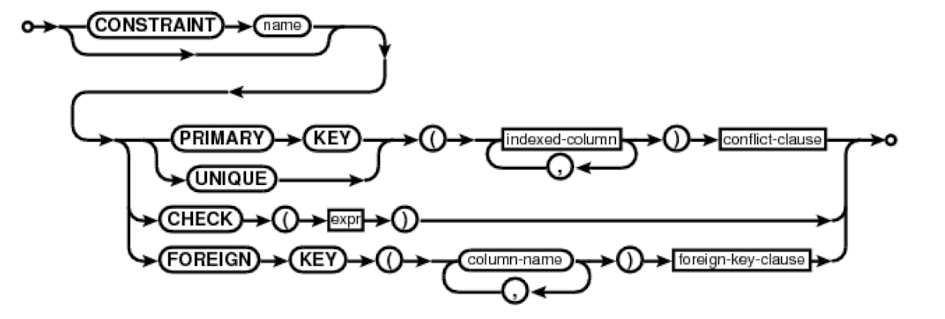
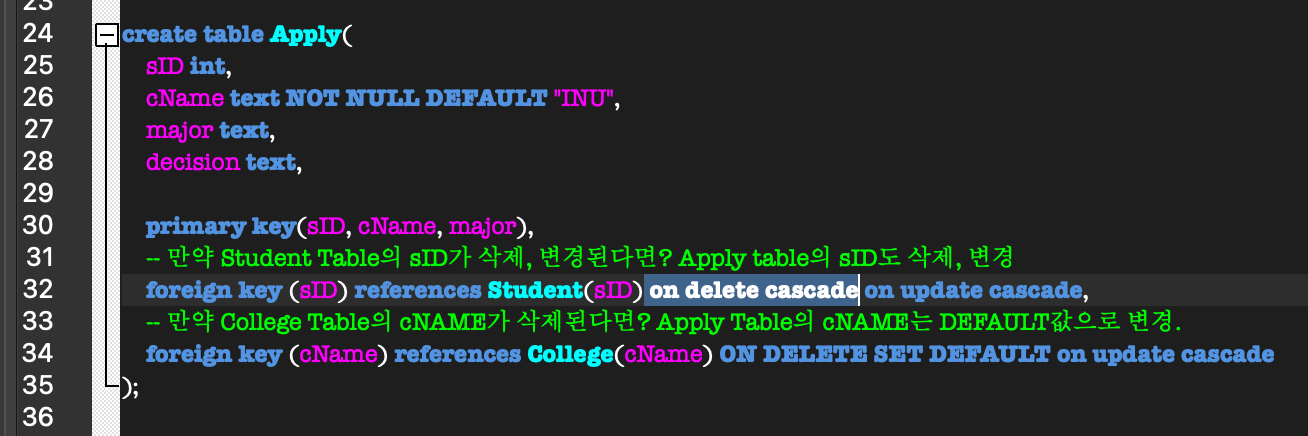
1. CREATE TABLE
아래와 같은 schema를 갖는 table을 create하라.

PRIMARY KEY, FOREIGN KEY, CASCADE, DEFAULT
ON UPDATE CASCADE 실험
- ON UPDATE CASCADE 실험 :
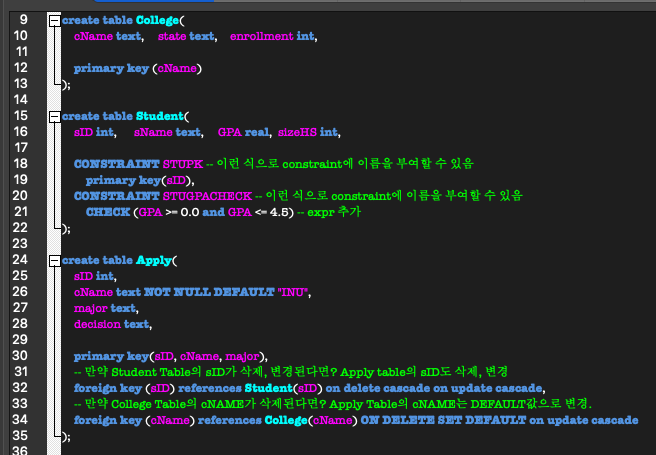
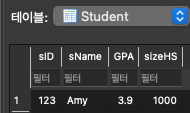

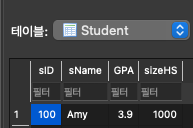
Amy의 sID를 123에서 100으로 바꾼다면?
Apply Table의 Amy의 sID도 100으로 바뀜.(cascade update를 했기 때문)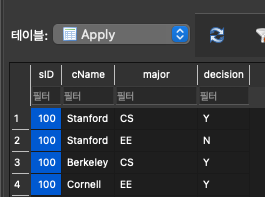
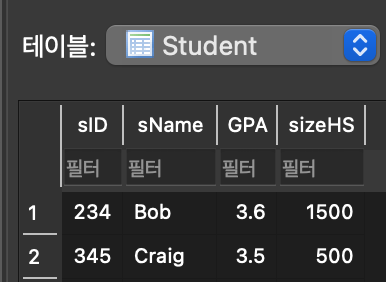
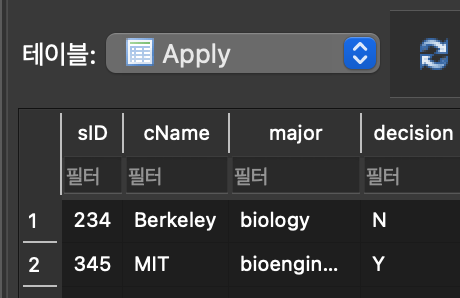
ON DELETE CASCADE 실험
- ON DELETE CASCADE 실험 :

ON DELETE SET DEFAULT 실험 (미해결)
ON DELETE SET DEFAULT실험해보려 했는데,
생각과는 달리 에러가 나옴..
 아래와 같이 College Table에서 cName = "Standford"인 tuple을 삭제하여
아래와 같이 College Table에서 cName = "Standford"인 tuple을 삭제하여
Apply Table의 cName도 "Standford"인 tuple을 DEFAULT값인 "INU"로 바꿔보려는 시도였지만...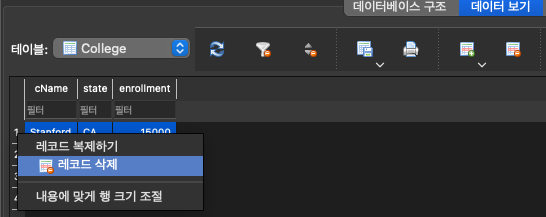 다음의 error msg가 출력됨
다음의 error msg가 출력됨
CHECK
CHECK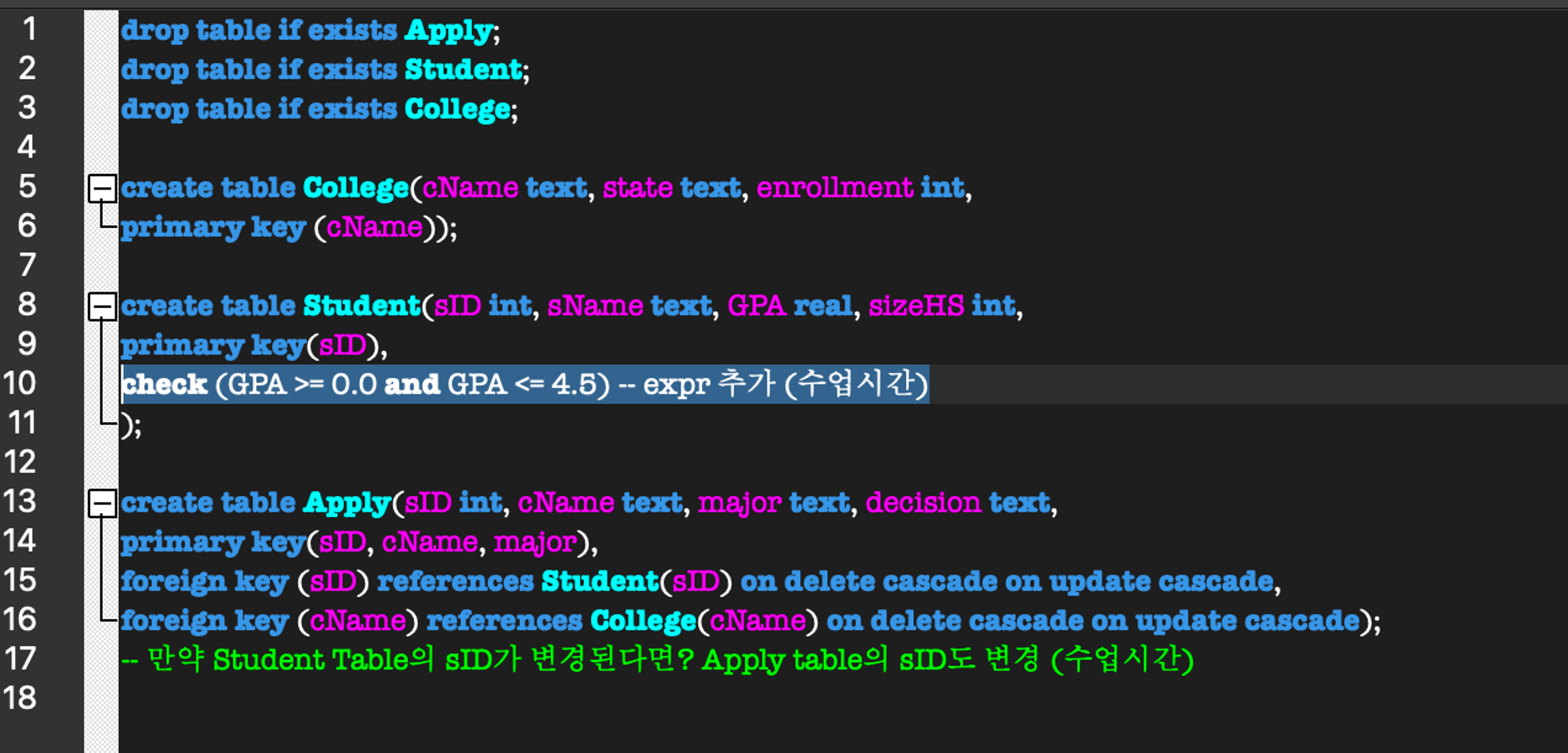
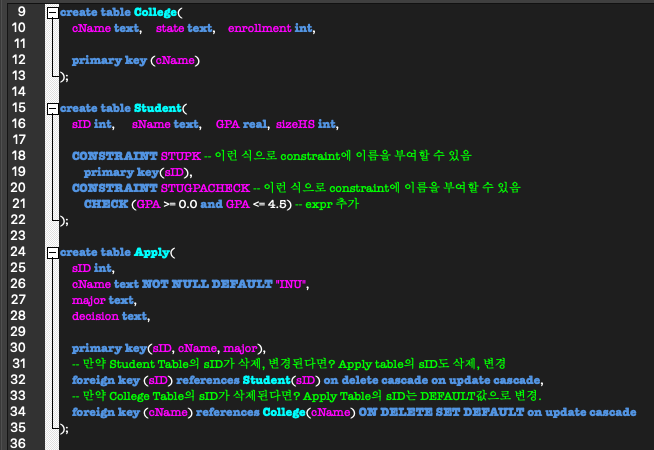
CREATE TABLE (College, Student, Apply) 최종 결과
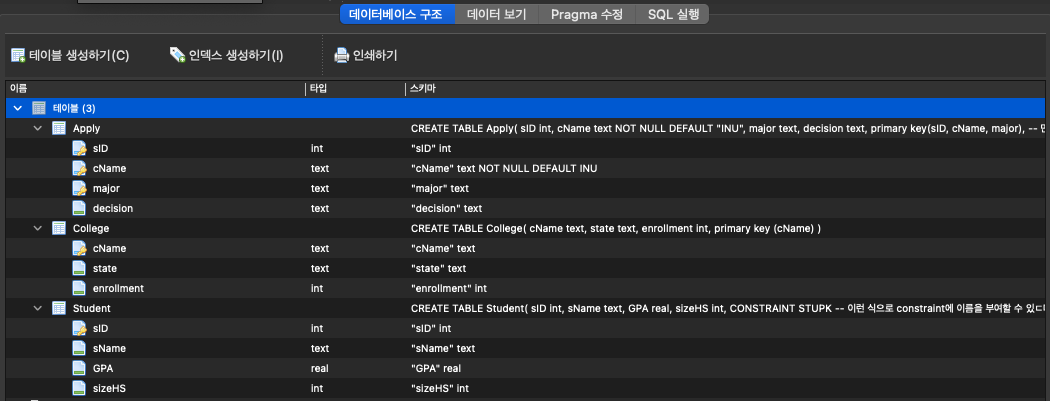
2. Bulk data load
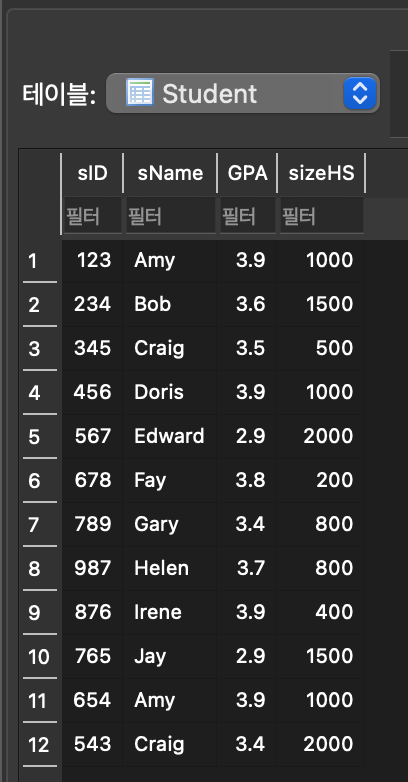
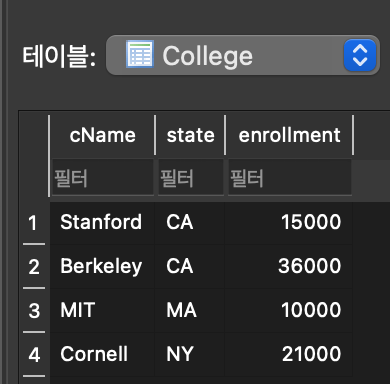
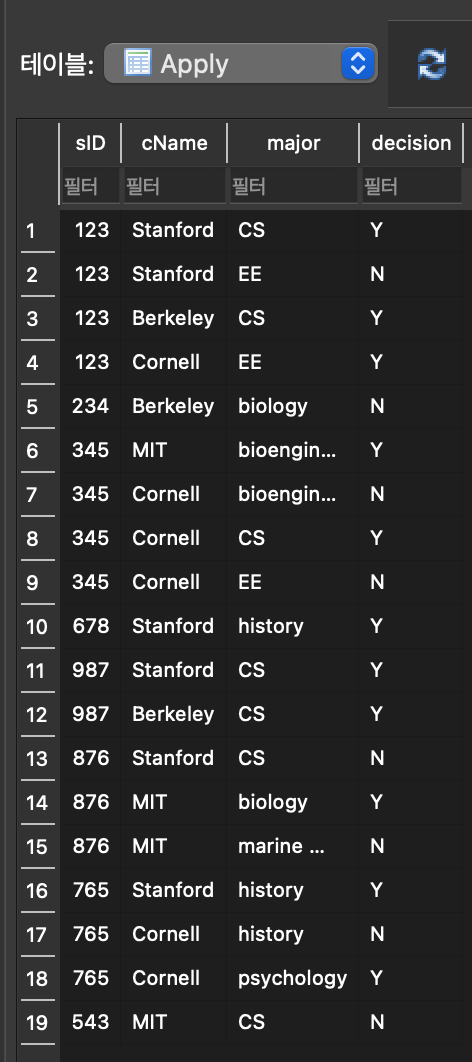
3. SELECT FROM WHERE
SELECT FROM WHERE ex
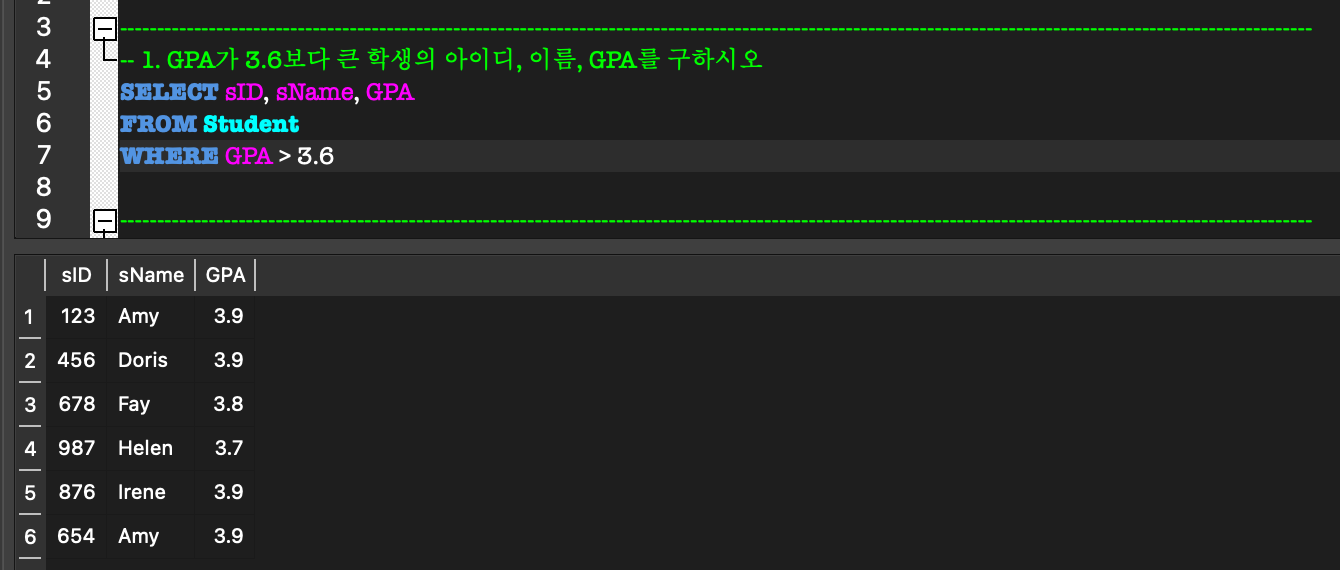
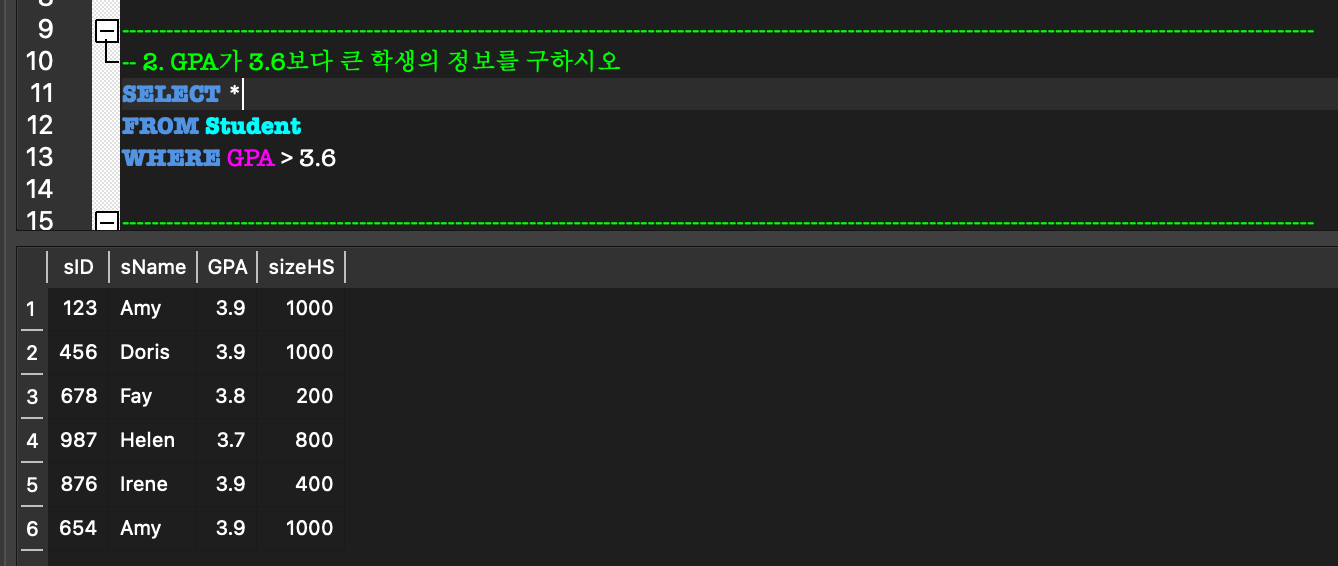
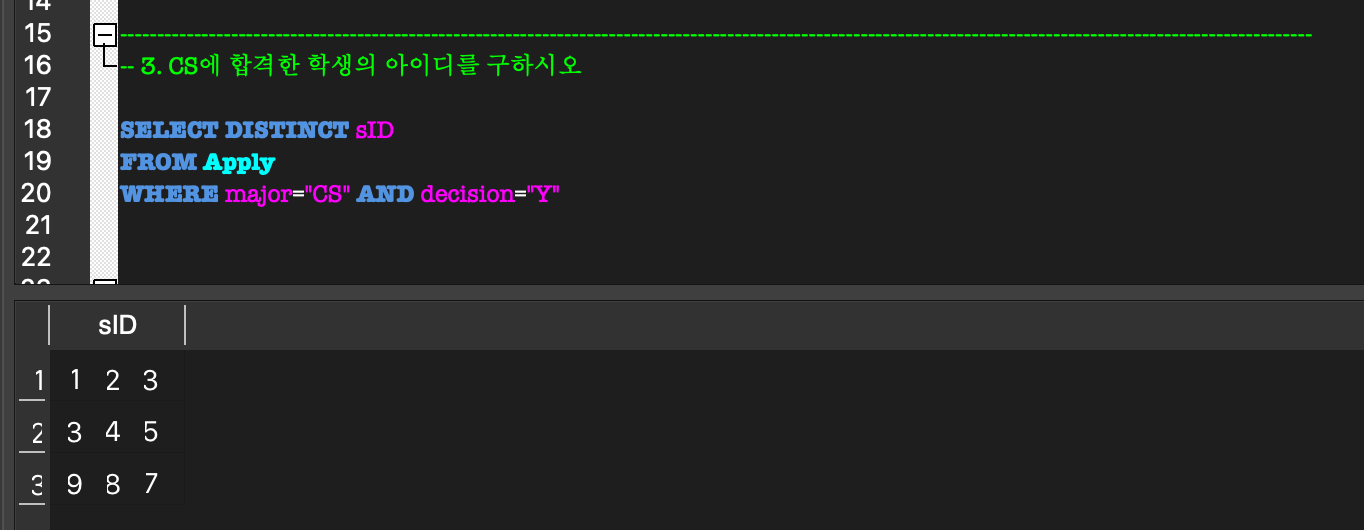
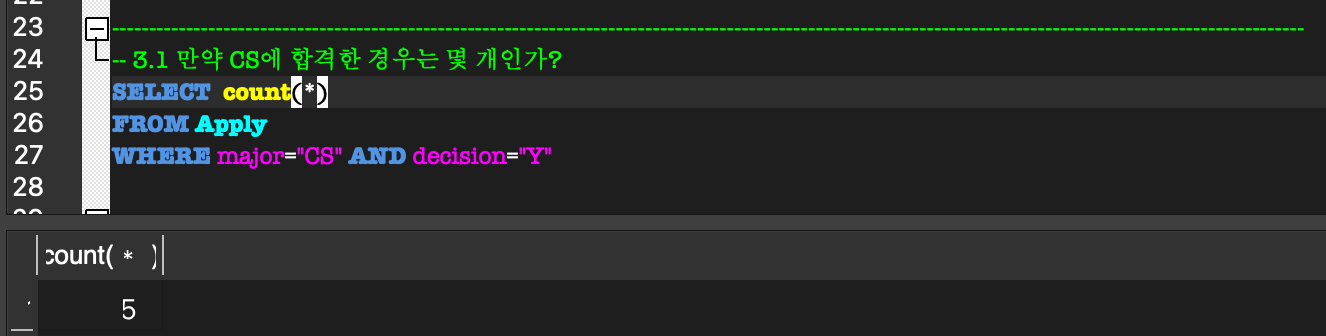
DISTINCT
DISTINCT:
SQL에서는 일반적으로 Relation을 집합으로 취급하지 않아서 중복된 tuple들이 나타난다.
따라서 중복된 tuple을 삭제하고 유일한 tuple들만 남기라는 의믜로DISTINCT가 사용된다.
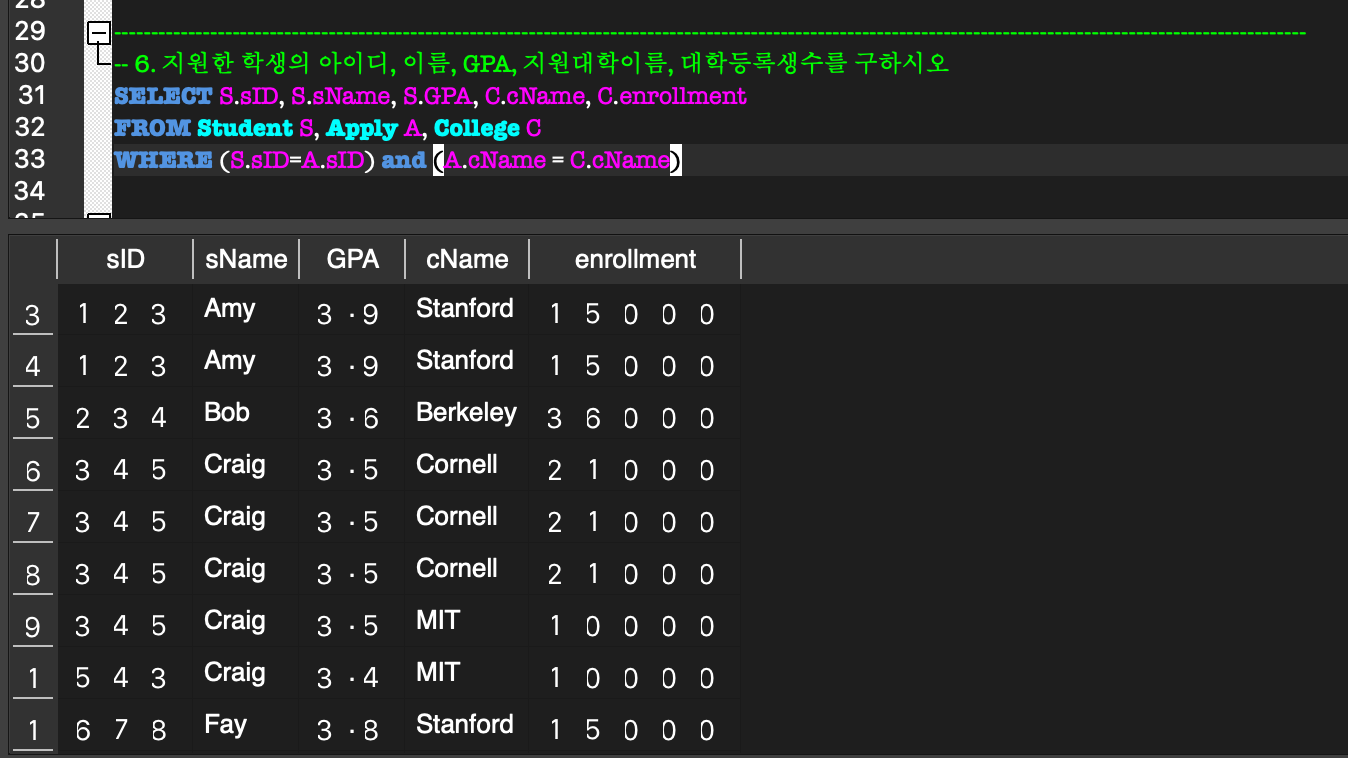
AS, Cartesian(Join)
AS:
동일한 Relation을 두 번 참조하는 경우, 모호성이 발생한다.
이 경우 모호함을 방지하기 위해서 Relation 이름에 alias를 붙여서 사용한다.
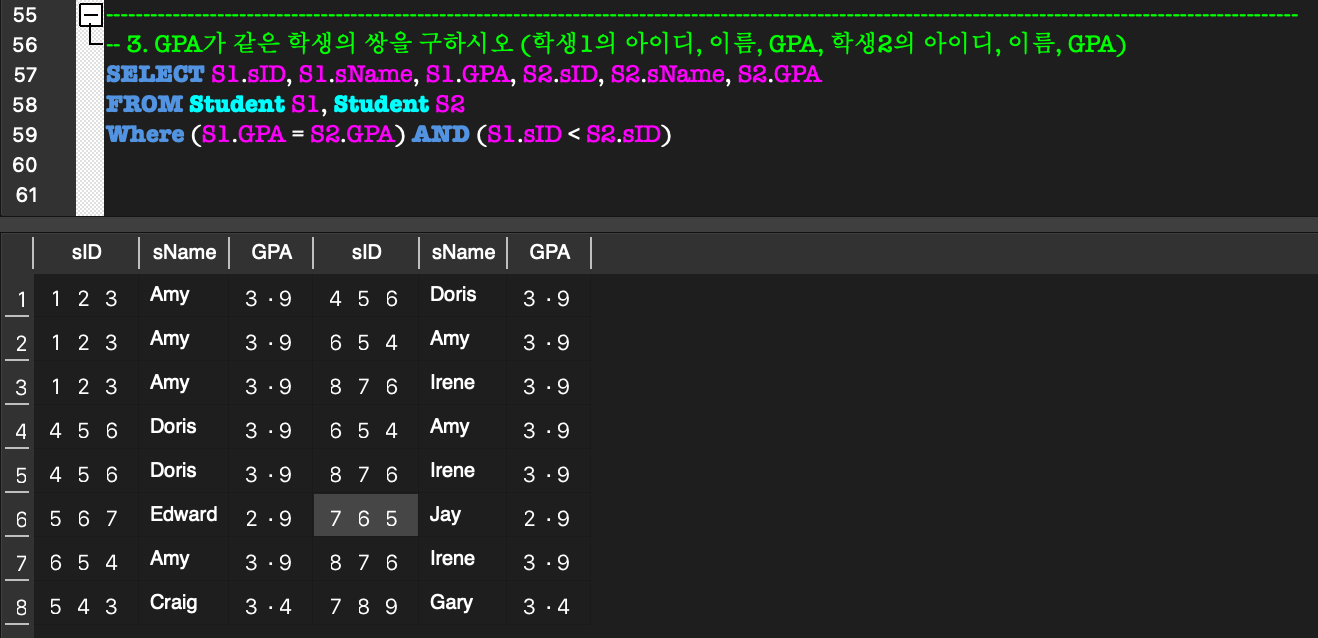
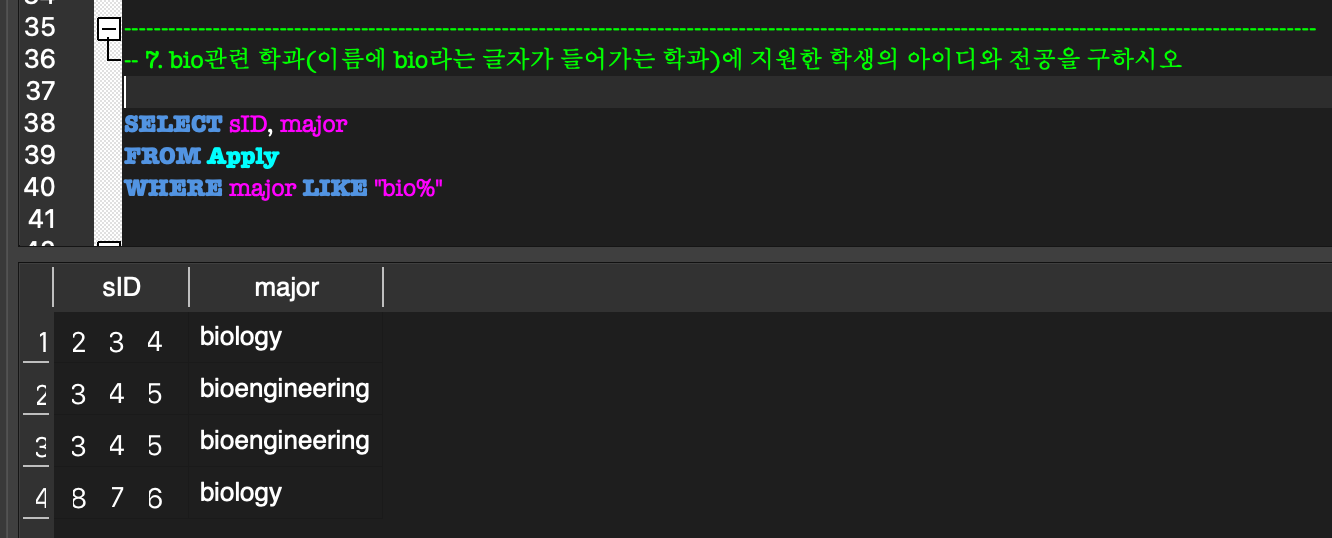
문자열 비교 연산자 (LIKE '% or _')
LIKE:
LIKE 비교 연산자를 사용하여 문자열에 대해 비교조건을 적용할 수 있다.
또한 부분 문자열을 표현할 때%는 임의 개수의 문자를 의미하고,_는 임의 한 문자를 의미한다.
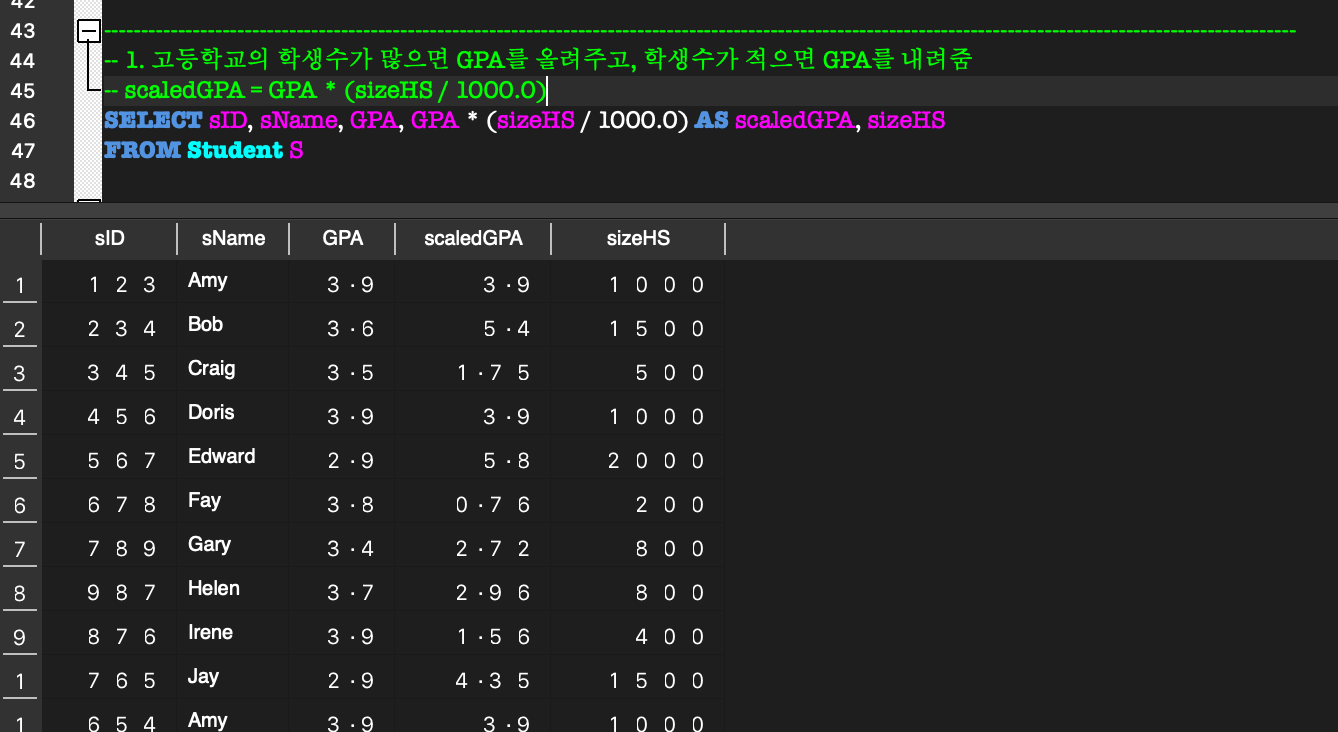
산술 연산자
ORDER BY [] DESC(default : ASC)
ORDER BY:
query 결과를 하나 이상의 attribute 순서로 정렬할 수 있다.ASC(default):
ASC == ASCending == 오름차순DESC:
DESC == DESCending == 내림차순
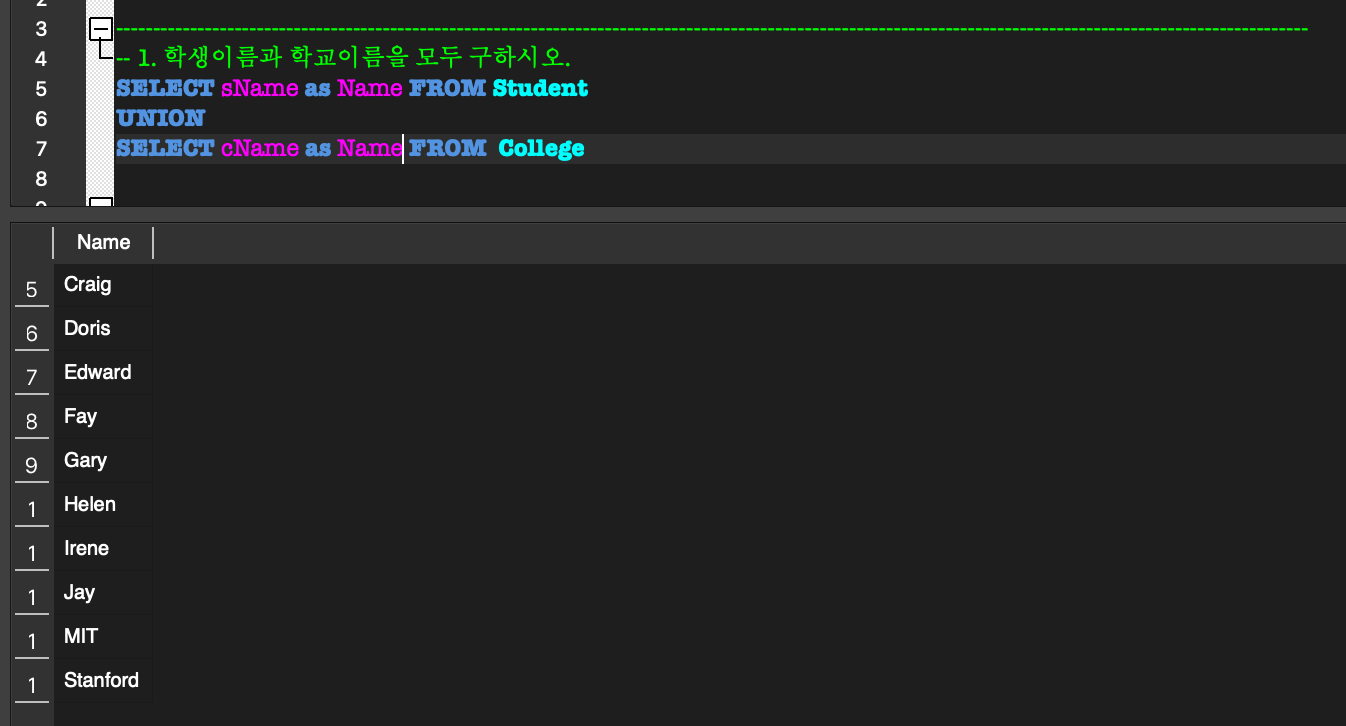
UNION, EXCEPT, INTERSECT
집합연산 조건- column의 개수가 같은 table끼리 집합연산해야 함
- domain이 같아야 함.
SQL에서의 집합연산:
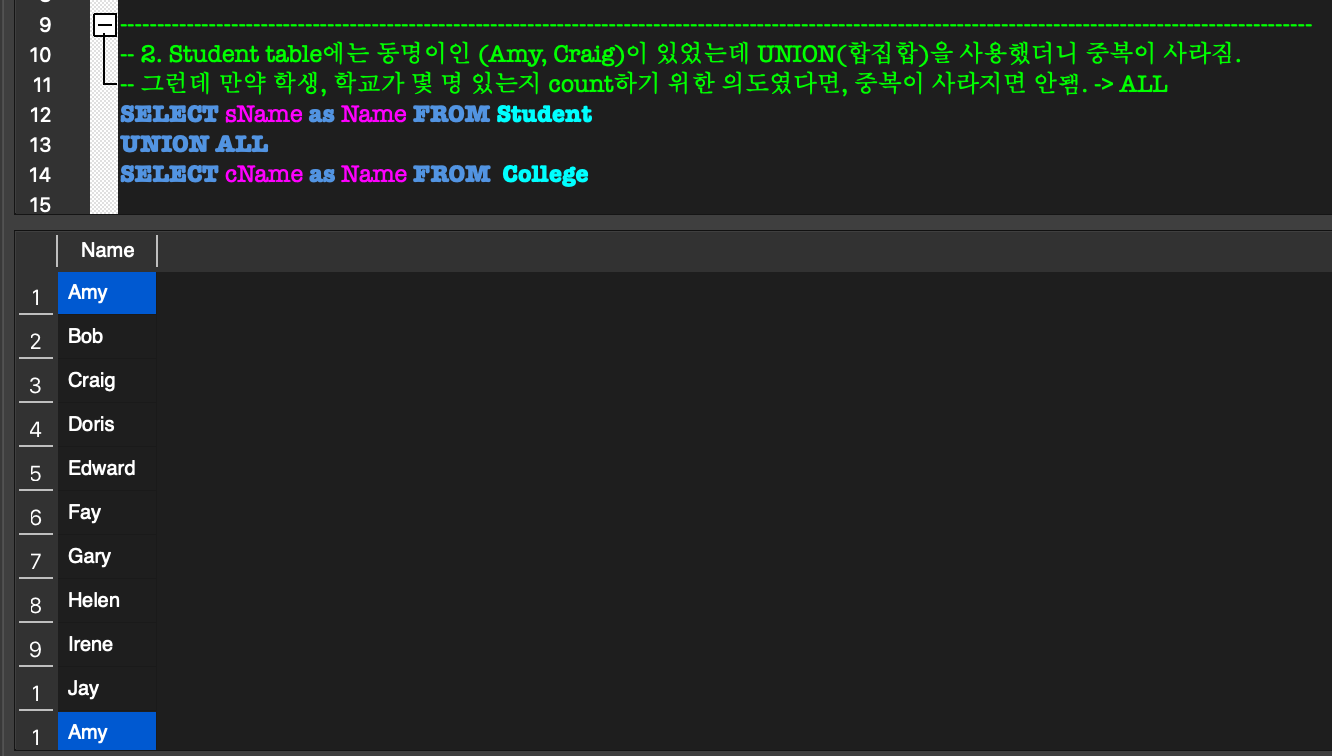
SQL에서는 중복을 자동으로 제거해주지 않는다고 했었는데,
집합연산에서는 중복을 자동으로 제거해준다.
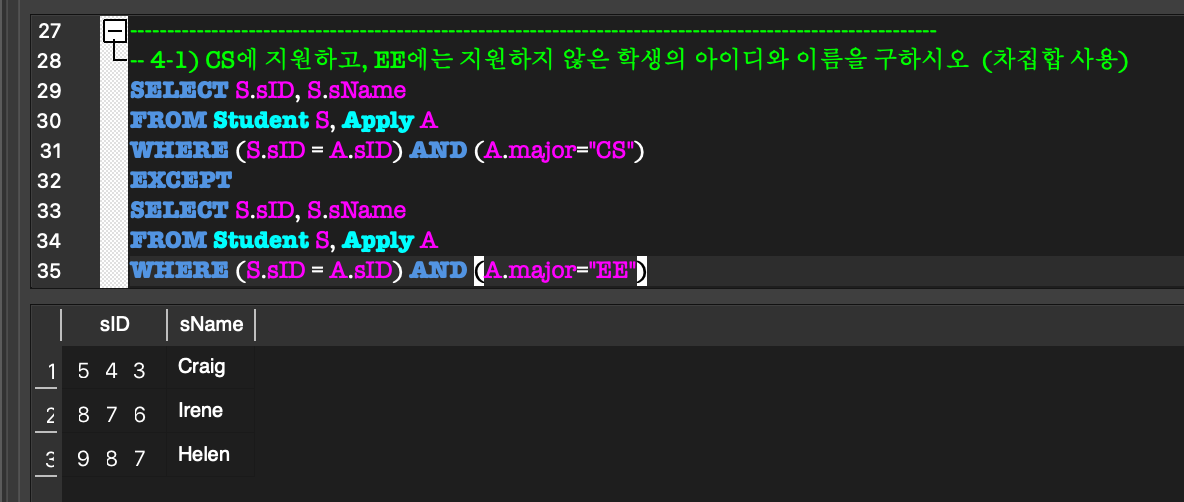
만약 예를 들어 count의 의도여서, 중복을 제거하지 않으려면 ALL을 붙여줘야 한다.- UNION :합집합
- EXCEPT : 차집합
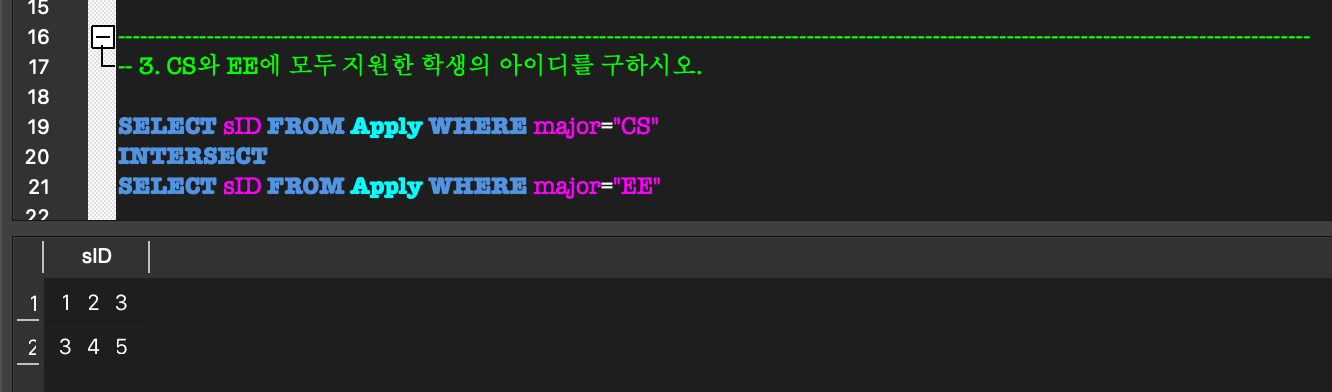
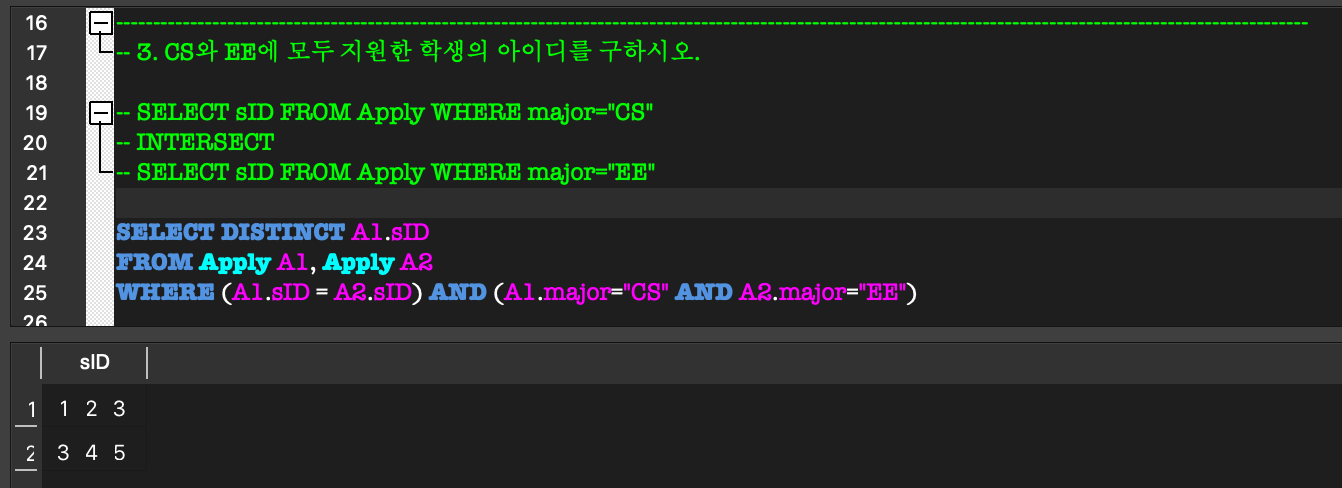
- INTERSECT : 교집합
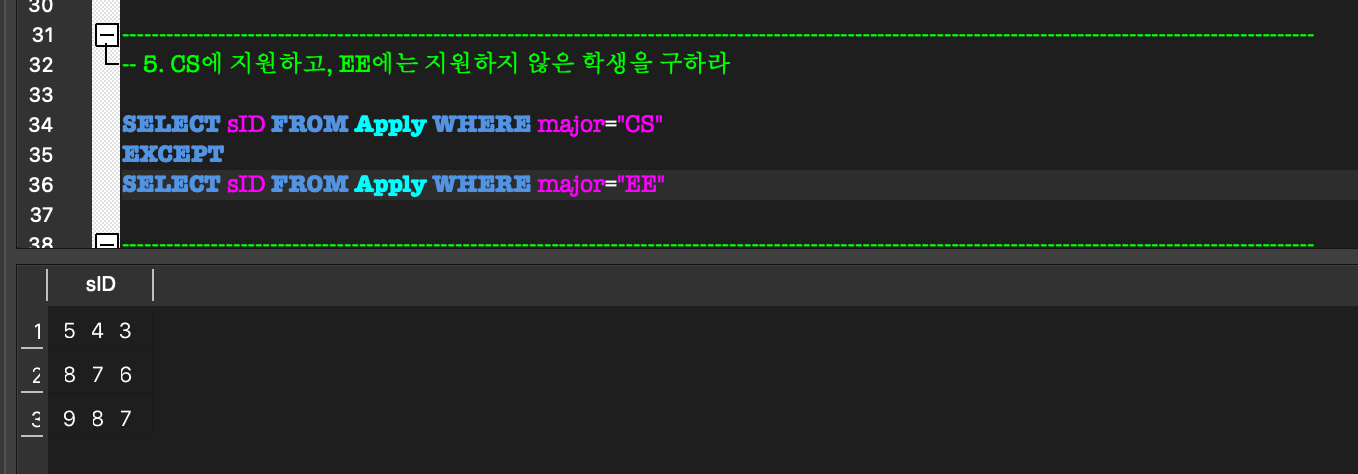
4. 더 복잡한 SQL Query
nested query((NOT) IN) correlated nested query((NOT)EXISTS, ALL/ANY))
nested query:
중첩 질의.
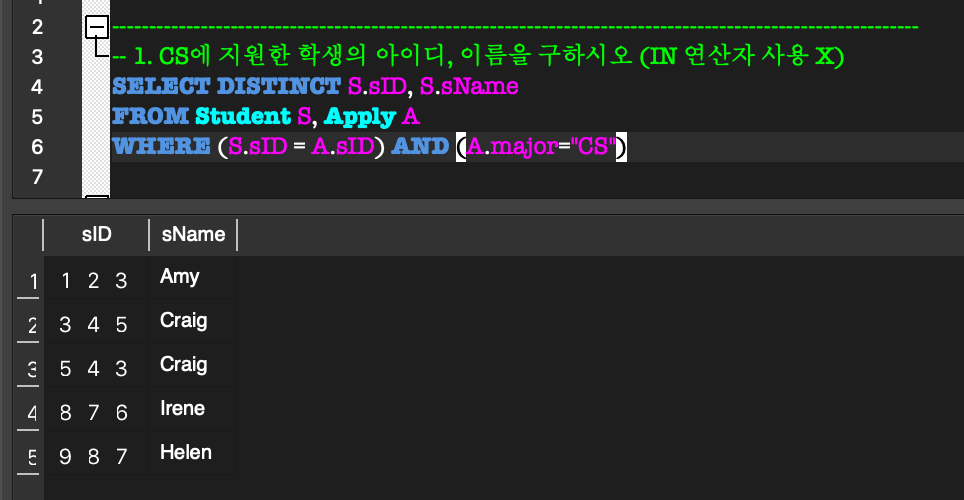
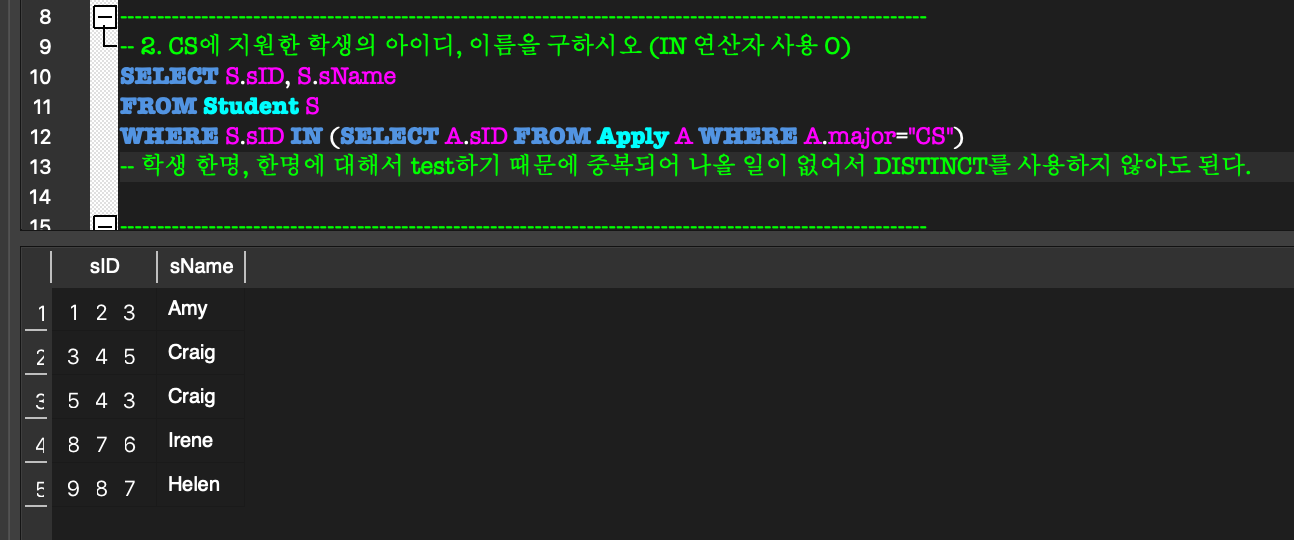
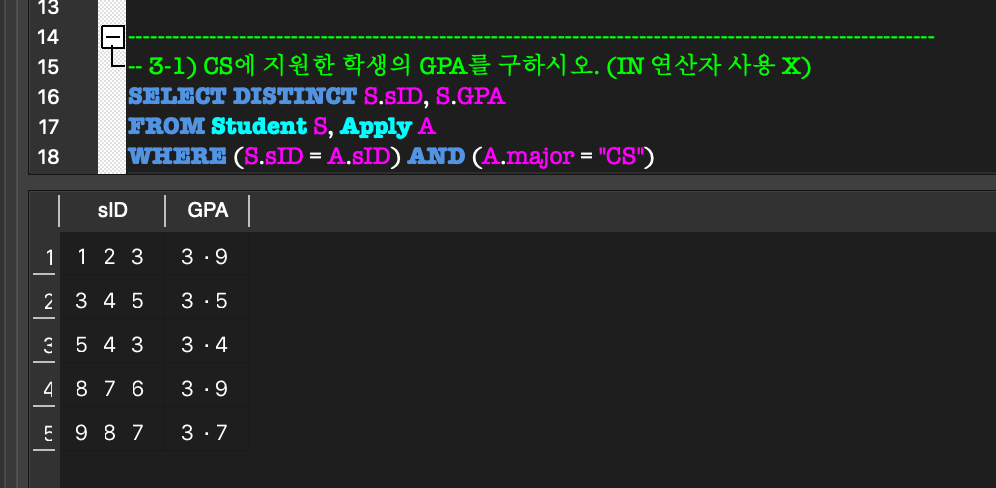
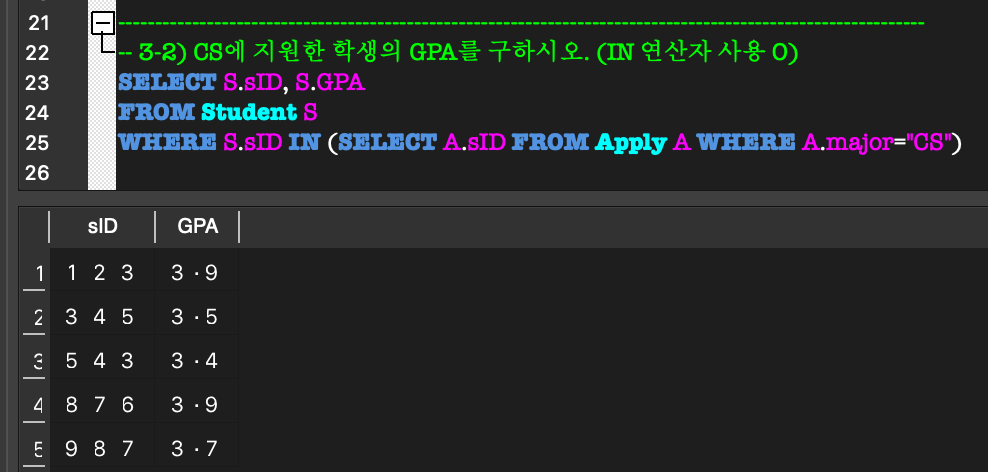
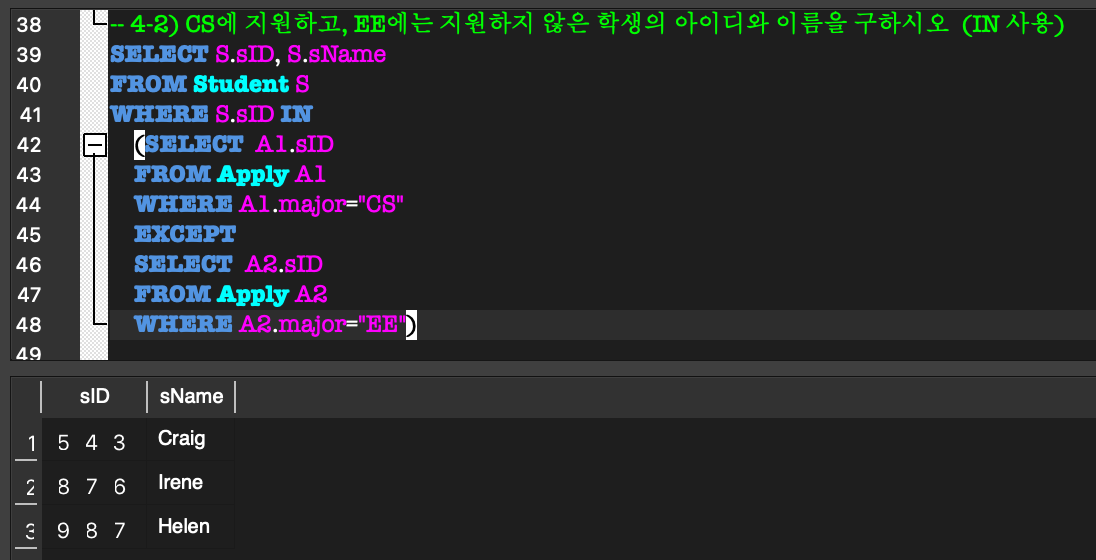
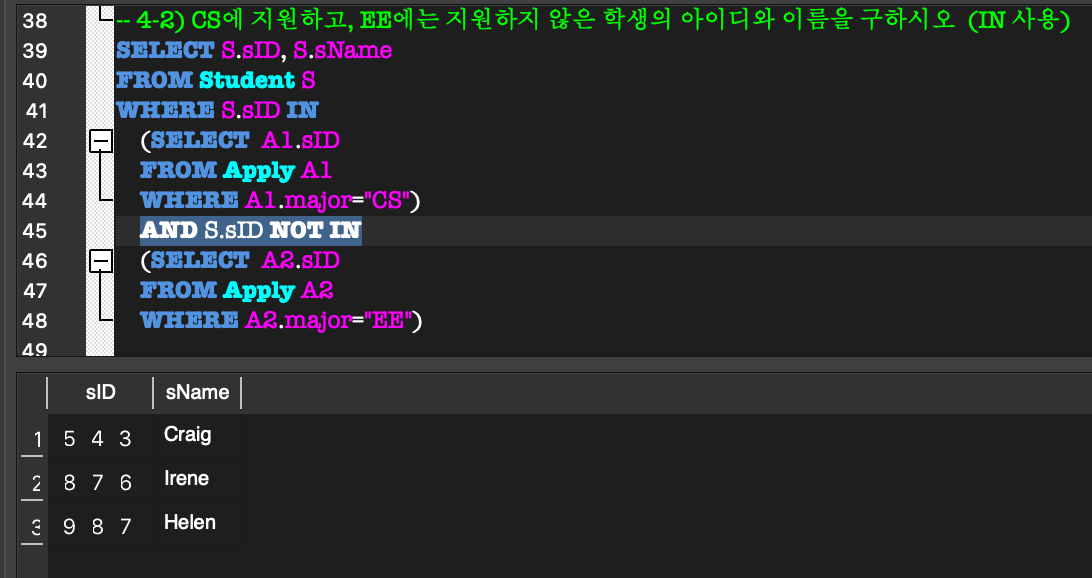
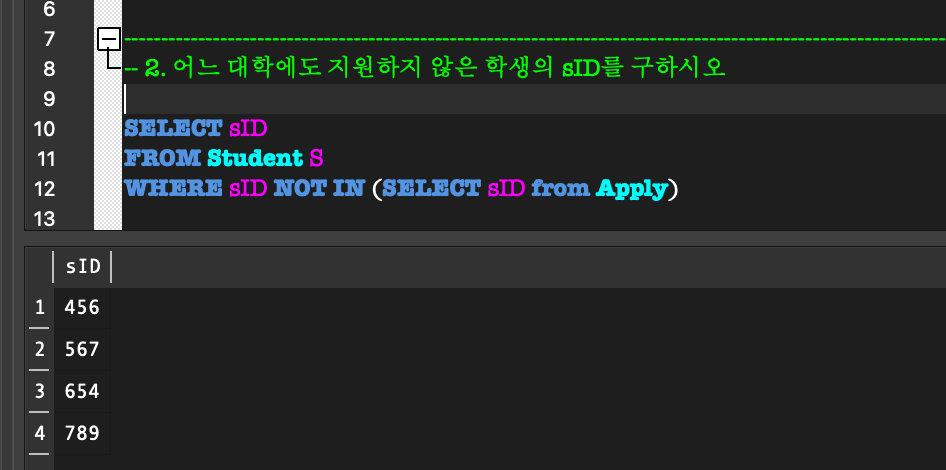
외부 질의의 WHERE절 내부에 완전한 SELECT 질의(내부 질의)가 나타나는 형태.(NOT) IN:
외부 질의의 한 tuple에 대하여,
그 tuple이 임의의 tuple 집합의 원소가 되는지 비교하는 연산.
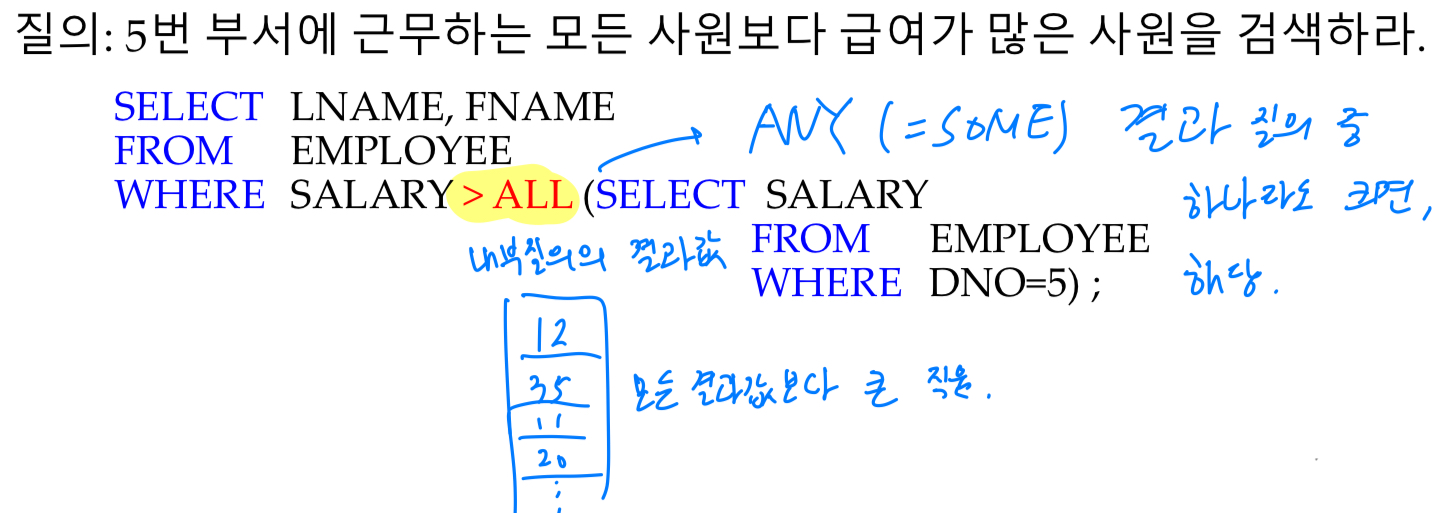
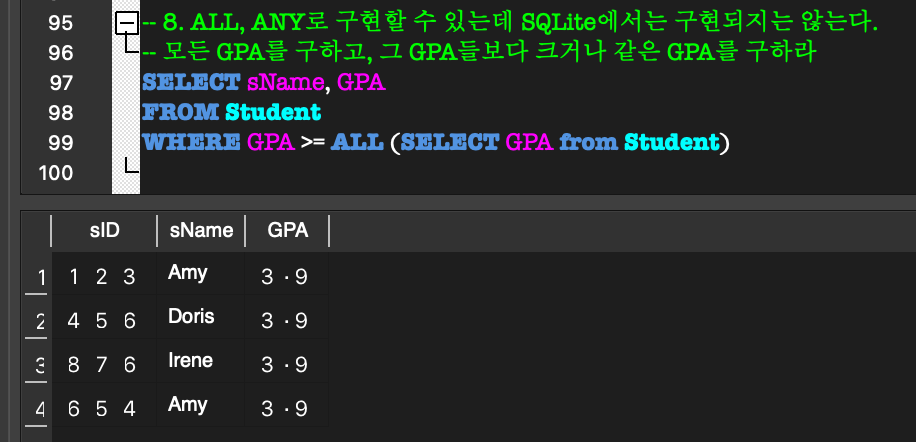
= 그 tuple이 내부 질의에 속하는지?ALL / ANY:
SQLite에서는 ALL / ANY 연산자가 구현되지는 않는다.
correlated nested query:
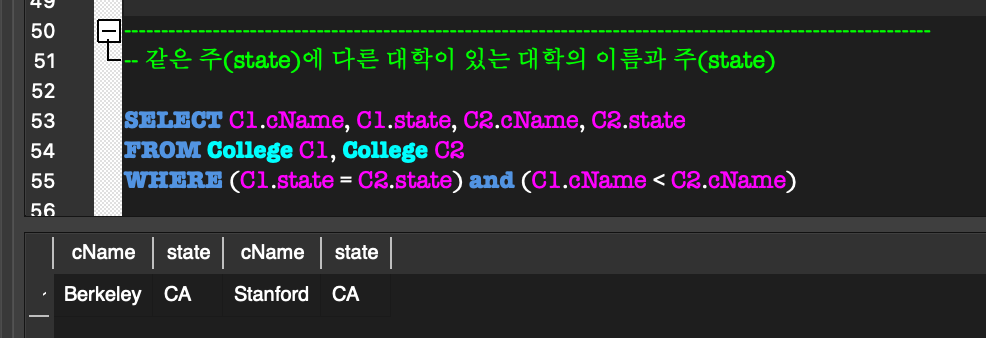
상관 중첩 질의.
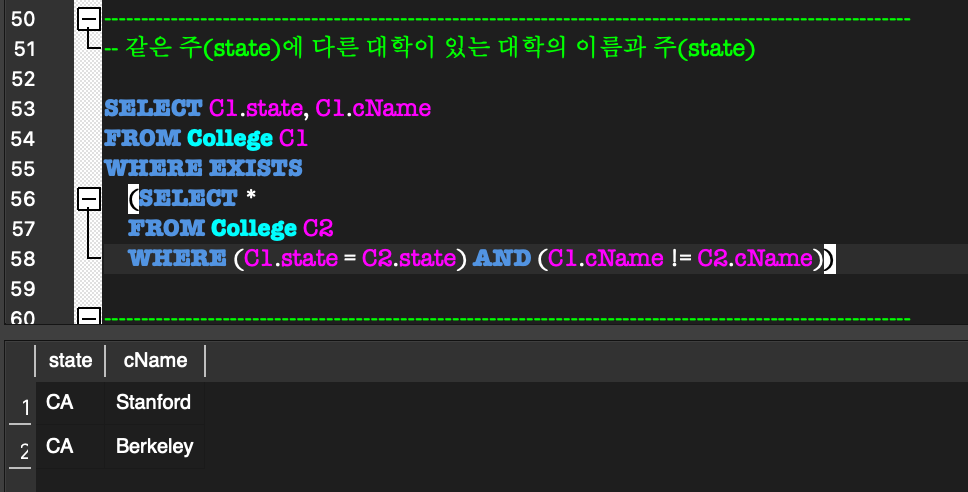
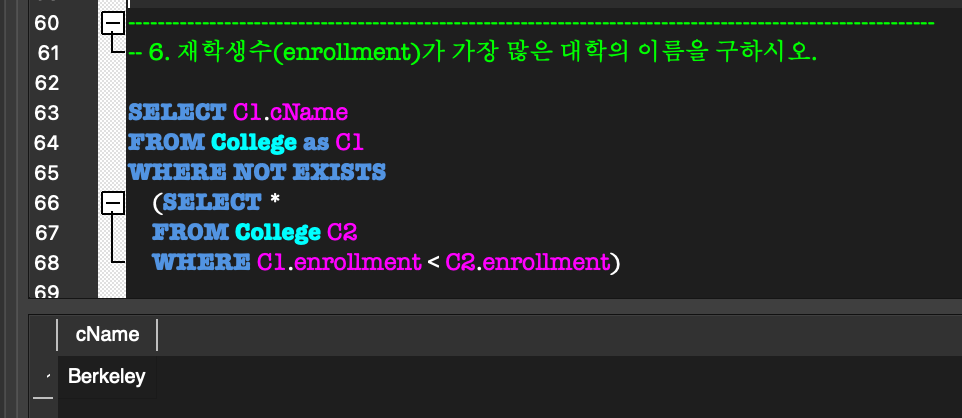
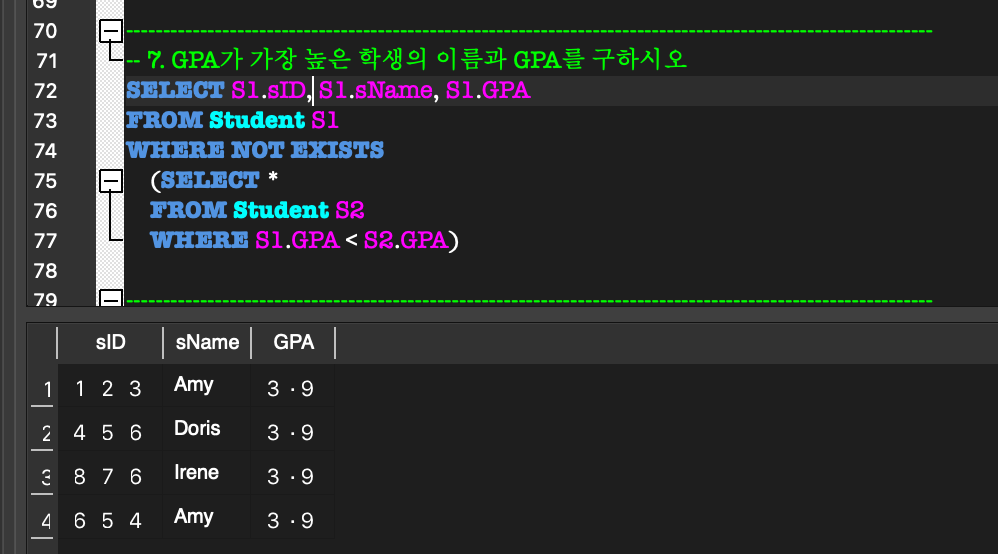
내부 질의의 WHERE절에 있는 조건에서 외부 질의에 선언된 relation의 일부 attribute를 참조하는 형태.(NOT) EXISTS:
상관 중첩 질의에서 내부 질의 결과가 공집합인가를 검사함.
최소한 한 개의 tuple이 있다면 TRUE를 반환.

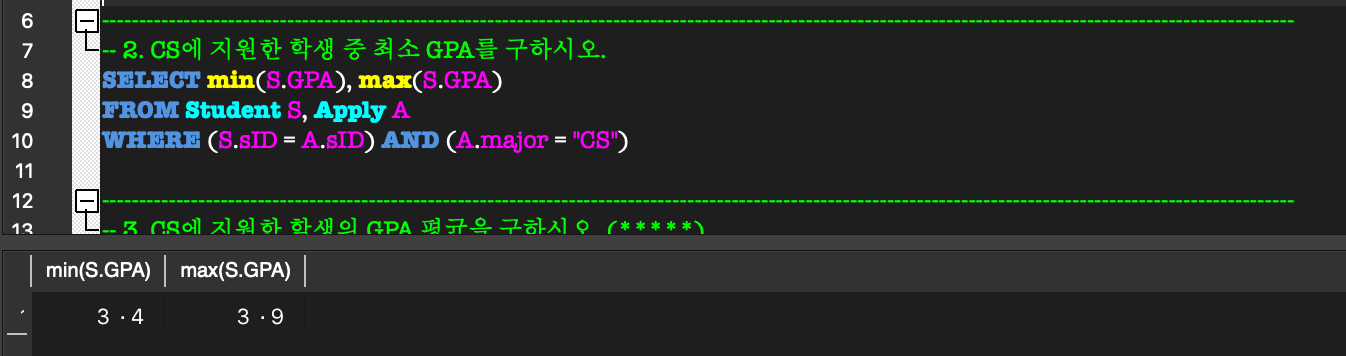
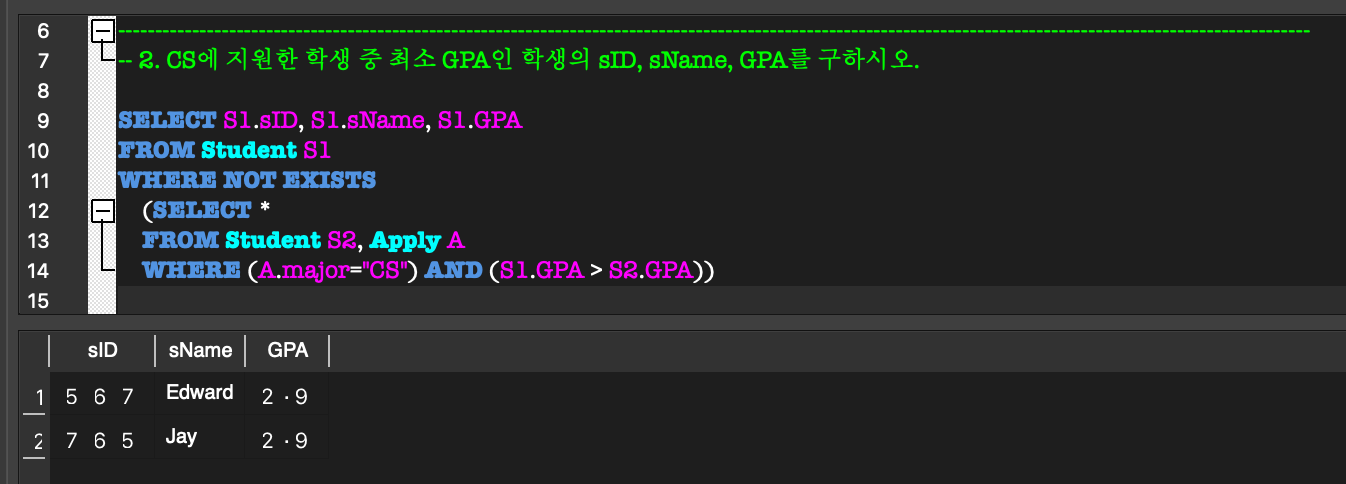
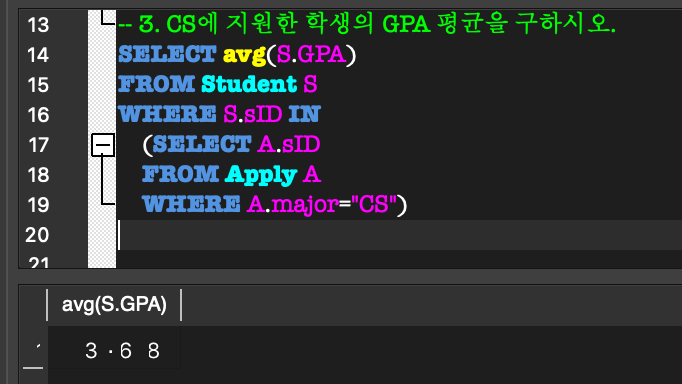
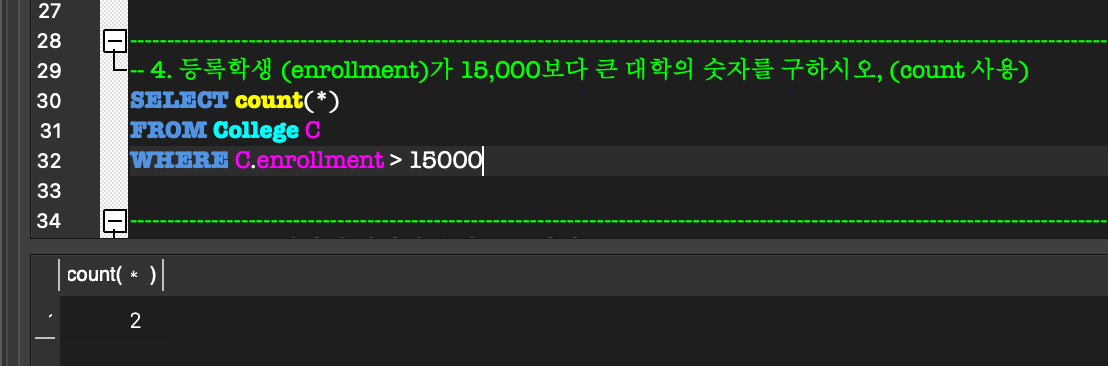
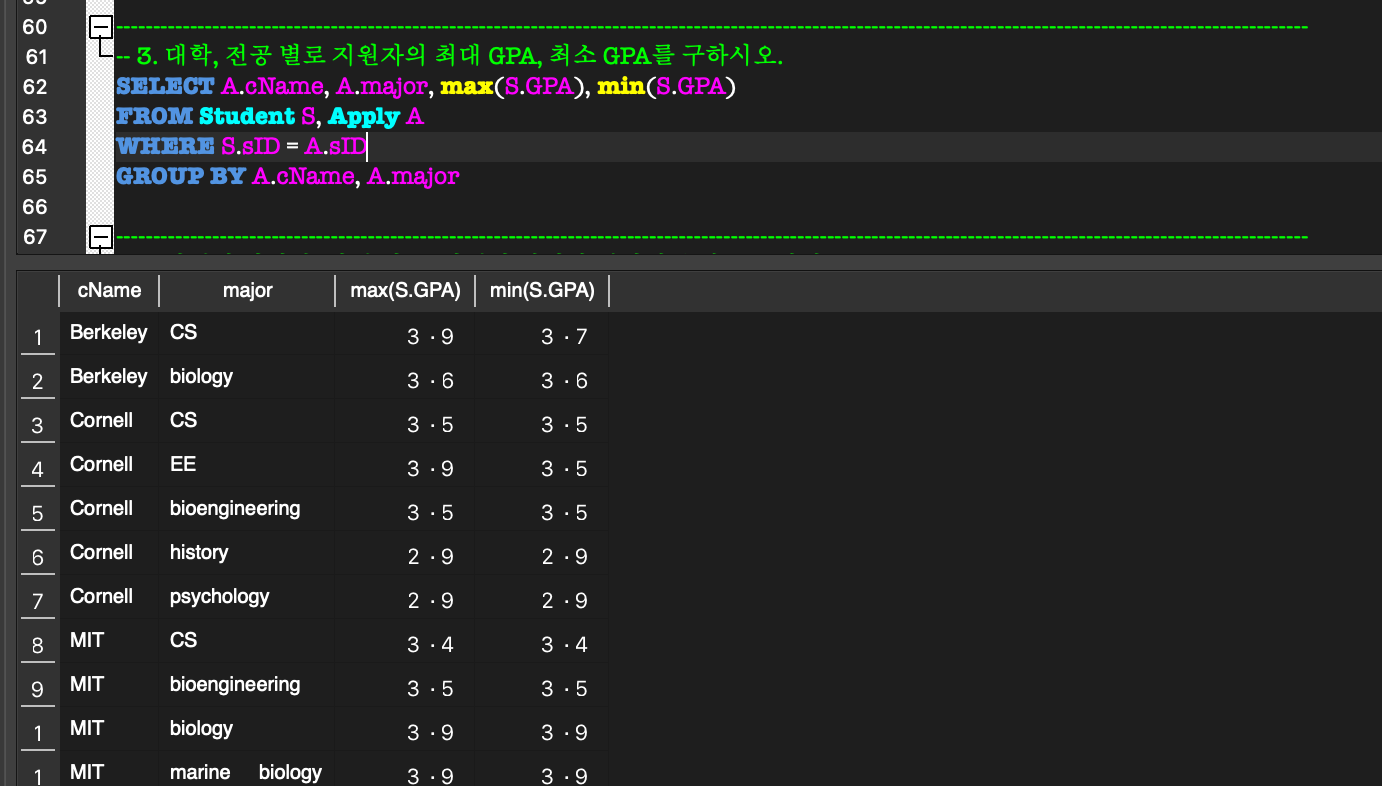
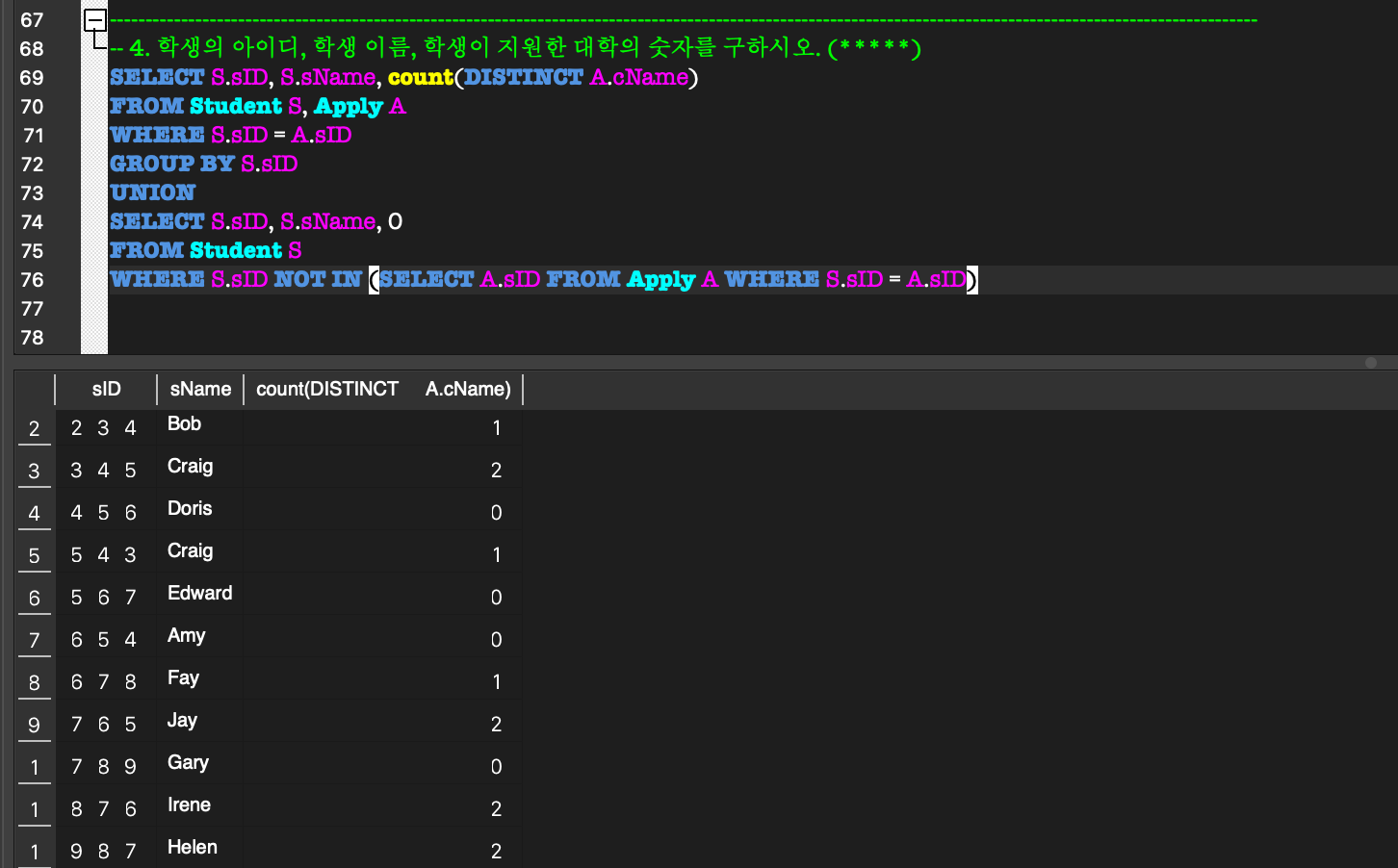
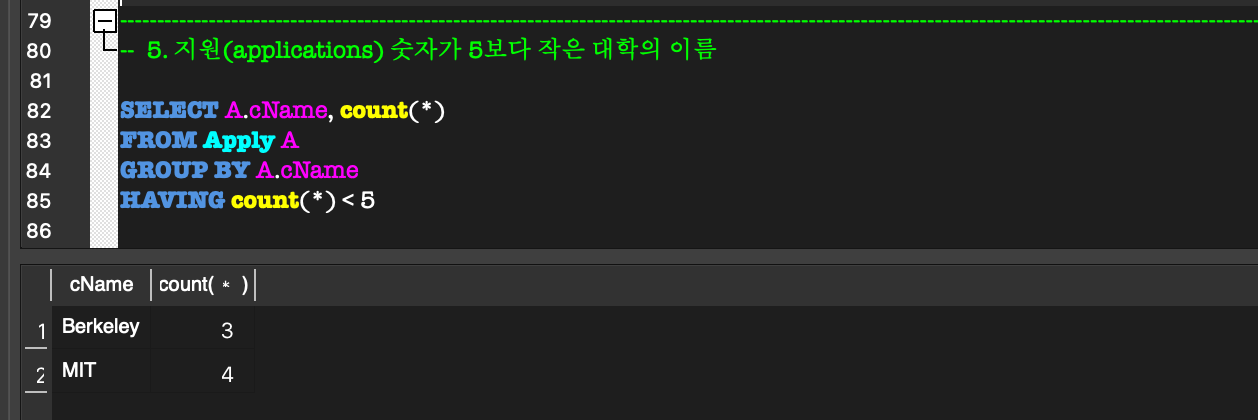
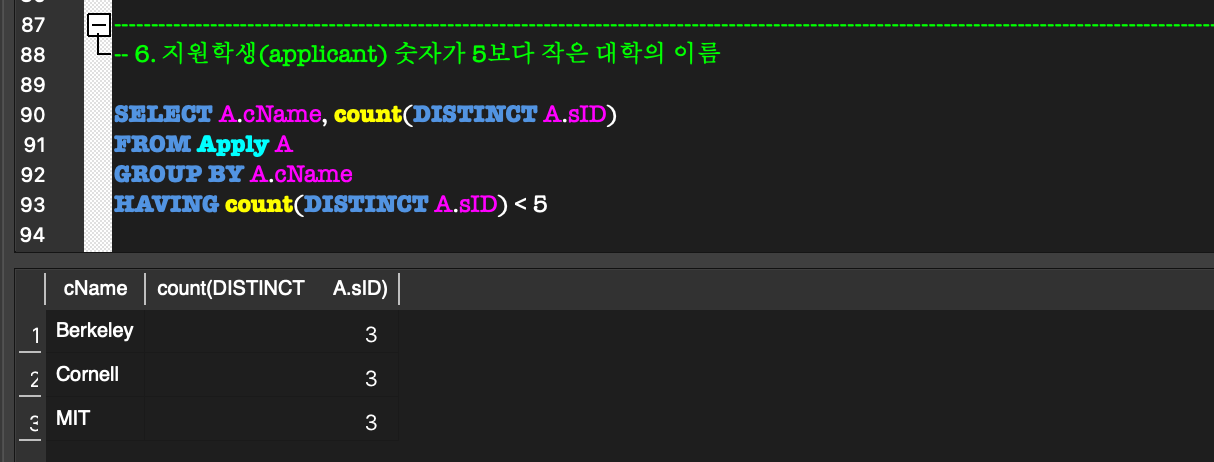
5. Aggregate Function, GROUP BY & HAVING
-
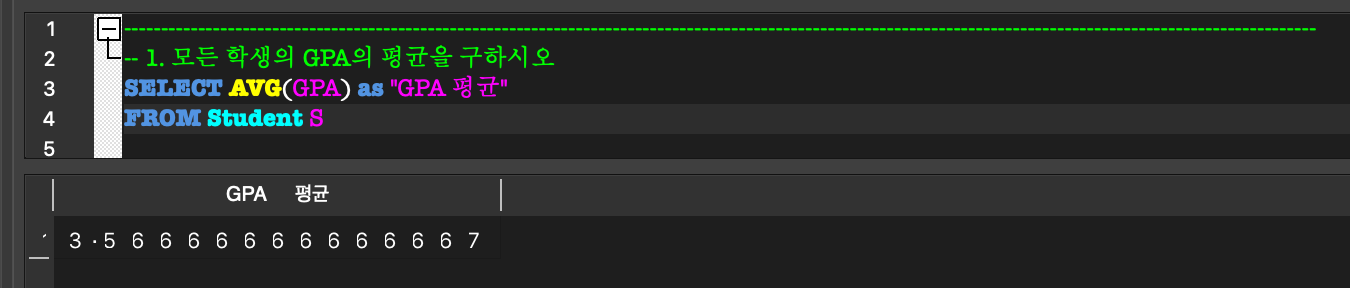
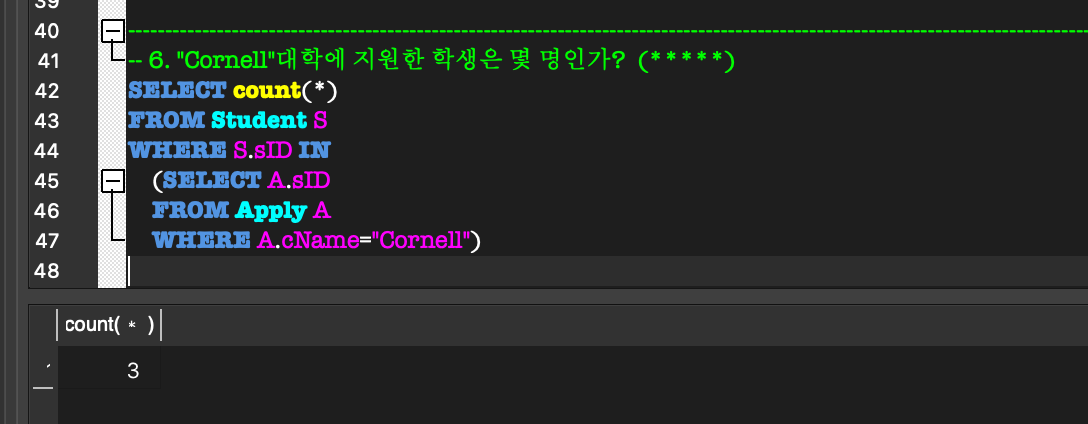
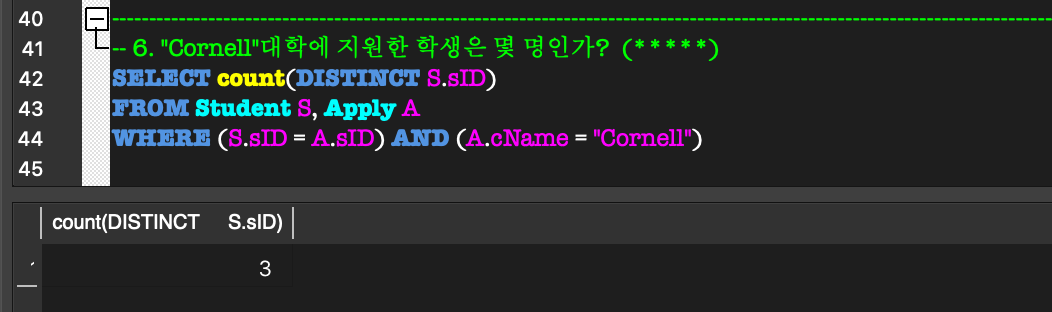
Aggregate Function:
COUNT, SUM, MAX, MIN, AVG 등의 함수를 제공.


-
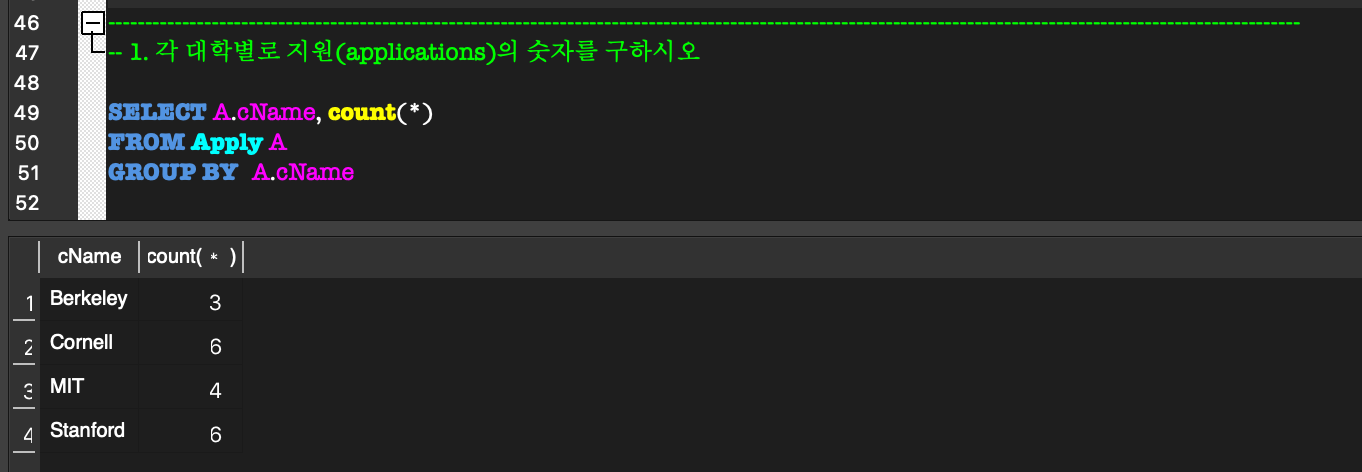
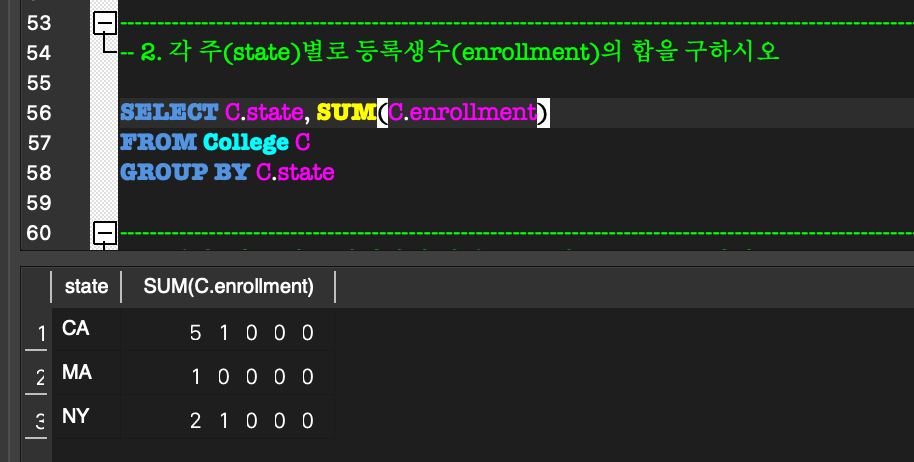
GROUP BY & HAVING:GROUP BY:
aggregate function을 사용할 때만 사용한다.
group을 특정 attribute 별로 group을 나눌 때 사용한다.HAVING:
각 group에 대한 조건을 제시하여 grouping할 수 있다.
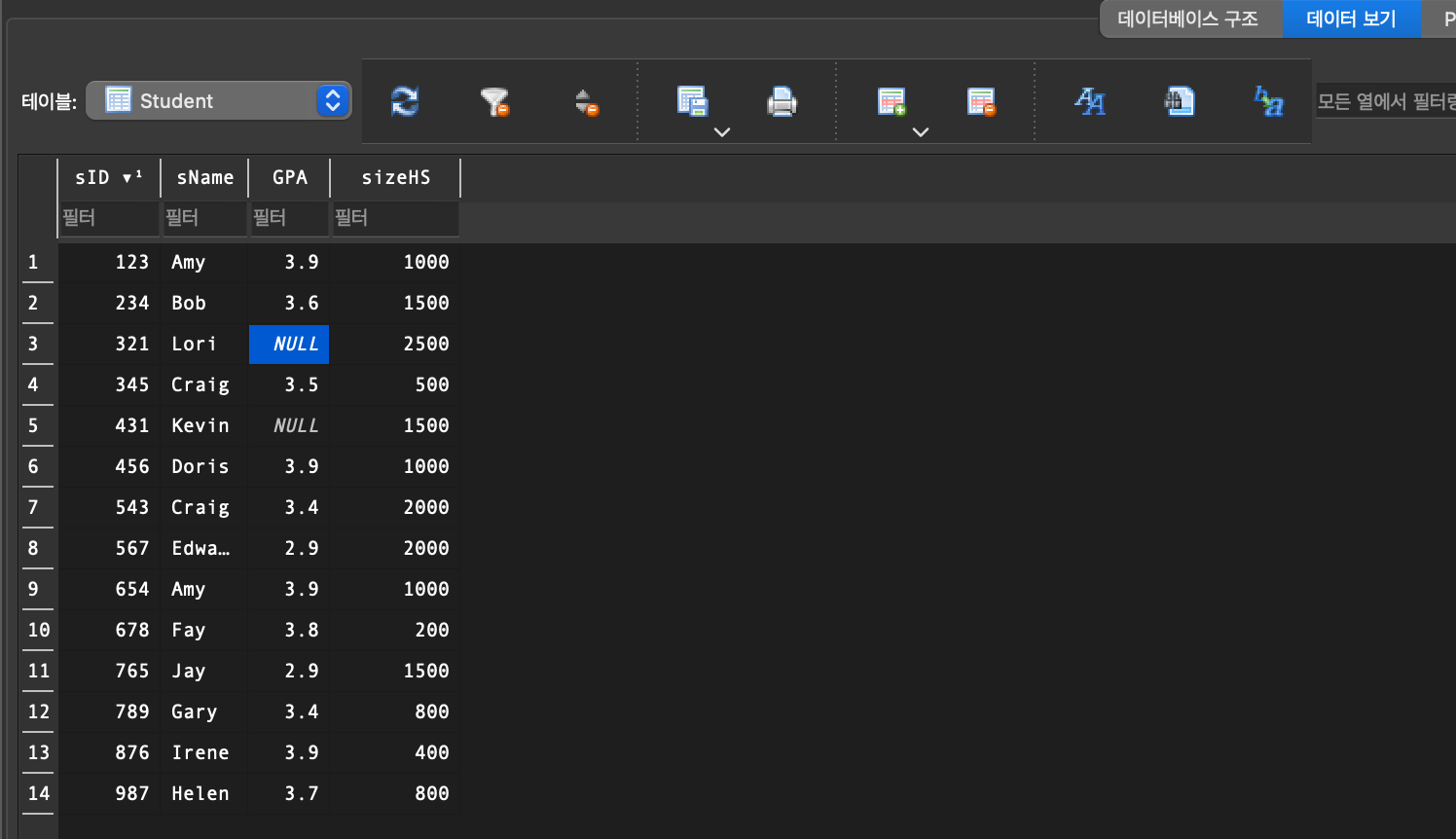
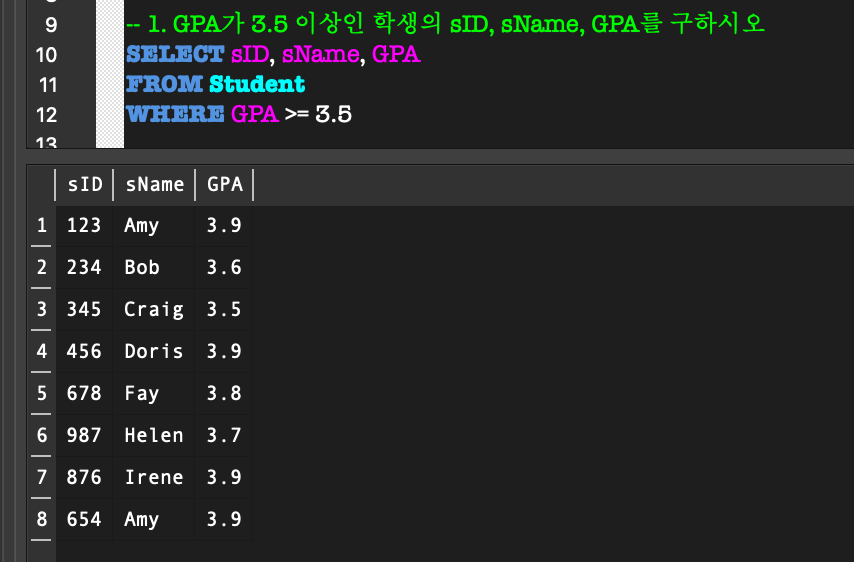
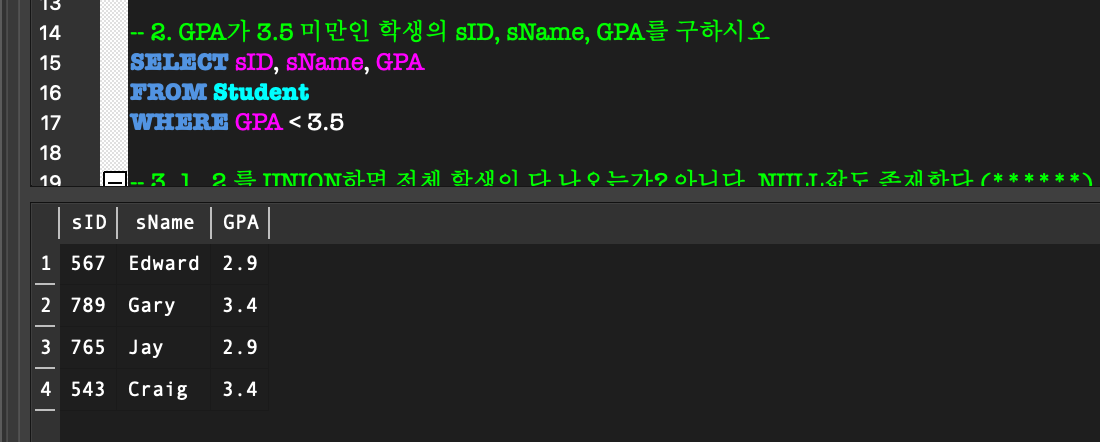
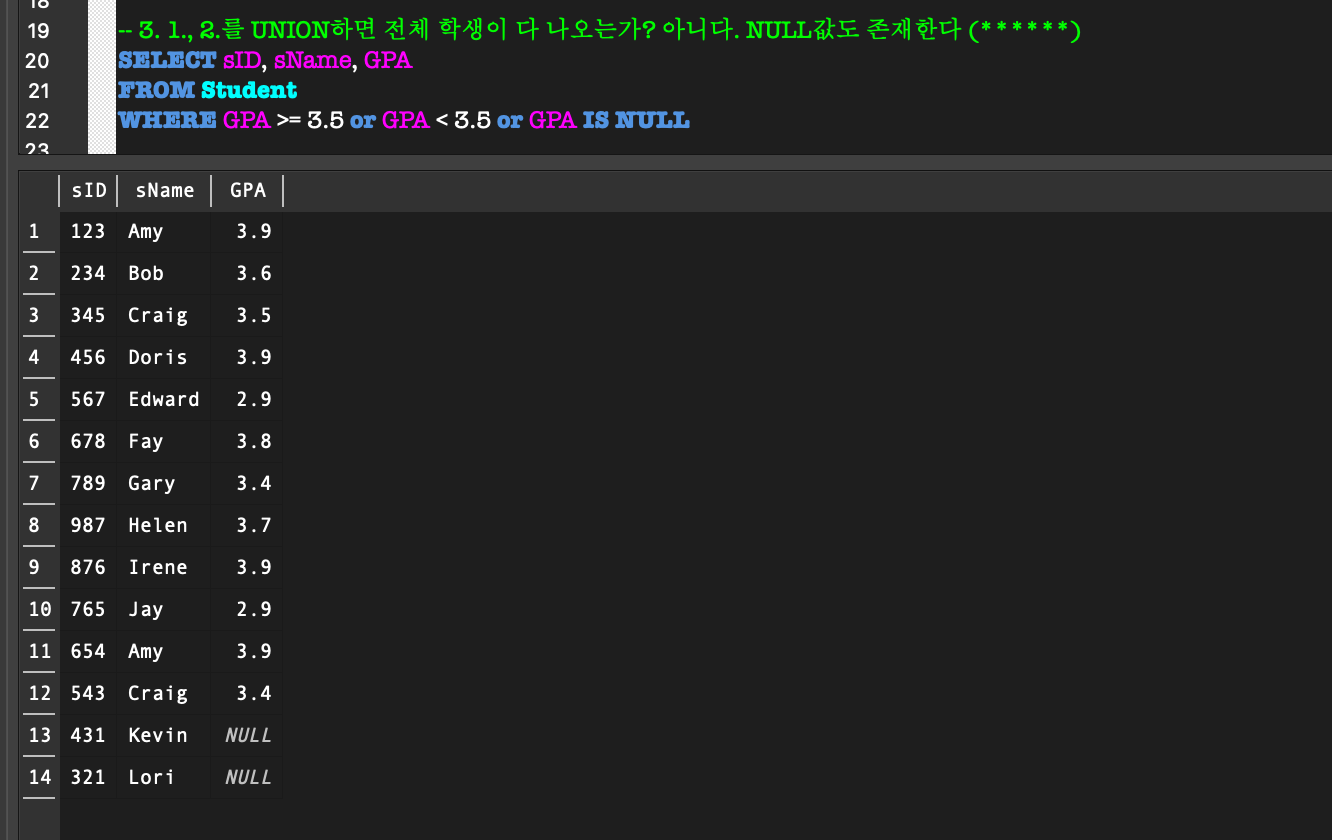
6. IS (NOT) NULL
NULL:
전체 data를 생각할 때, NULL값이 항상 있다는 것을 염두해야 된다!- 알려지지 않은 값
- 적용할 수 없는 attribute

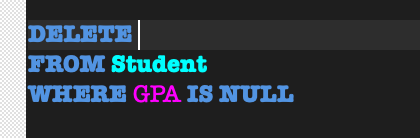
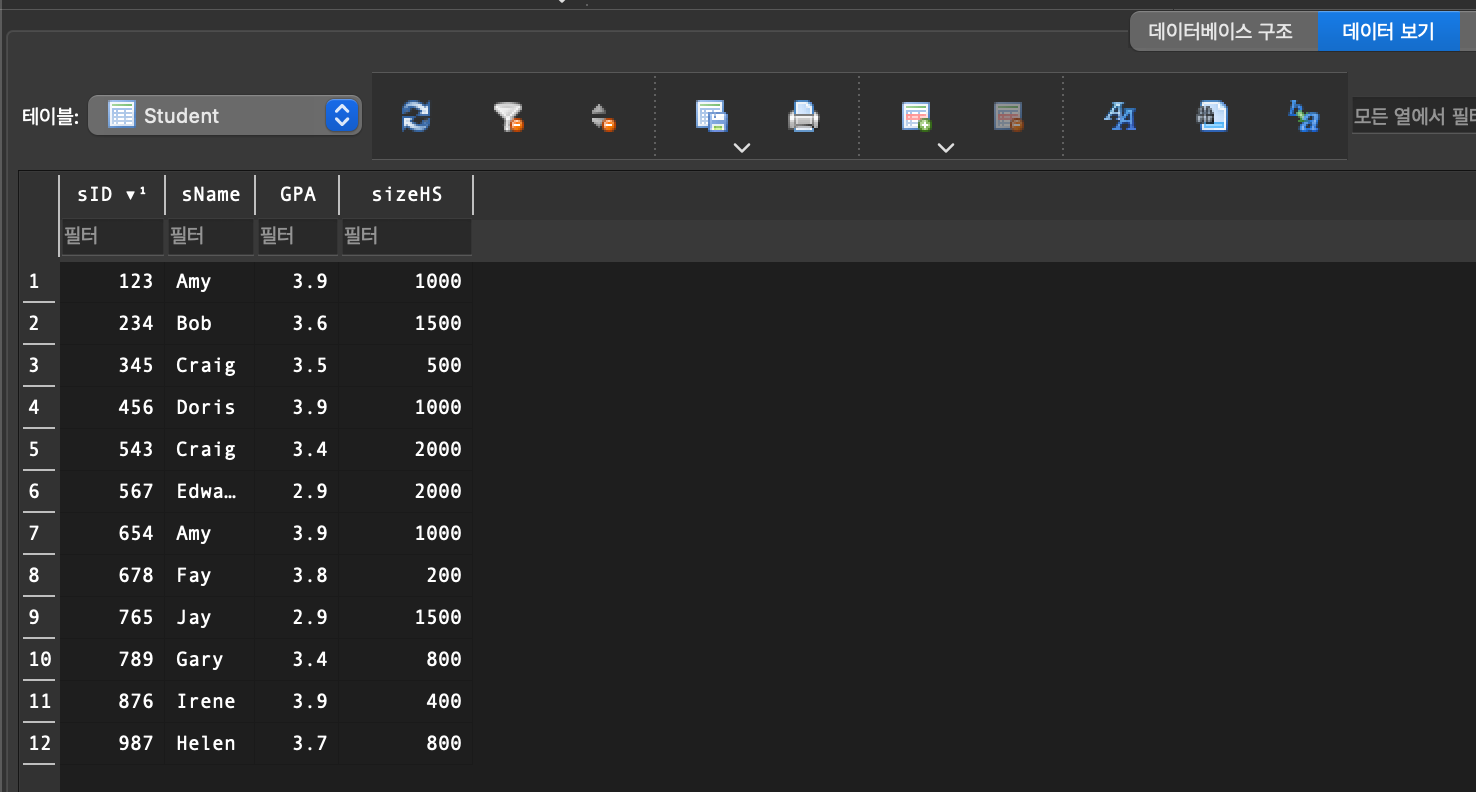
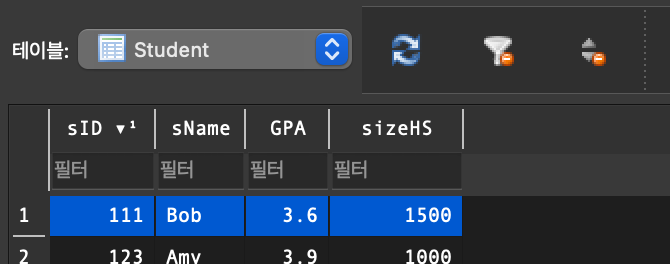
7. INSERT INTO VALUES, DELETE FROM, UPDATE SET
INSERT INTO VALUES:
삽입하는 tuple값은 CREATE TABLE에서 지정한 attribute 순서, domain이 동일해야 한다.DELETE FROM (WHERE):
WHERE절의 조건에 만족하는 tuple을 모두 삭제.
만약 WHERE가 없다면, 해당 table 내의 모든 tuple이 삭제되어 빈 table이 된다.UPDATE SET (WHERE):
WHERE절 조건에 만족하는 tuple을 SET절에 있는 내용으로 update.


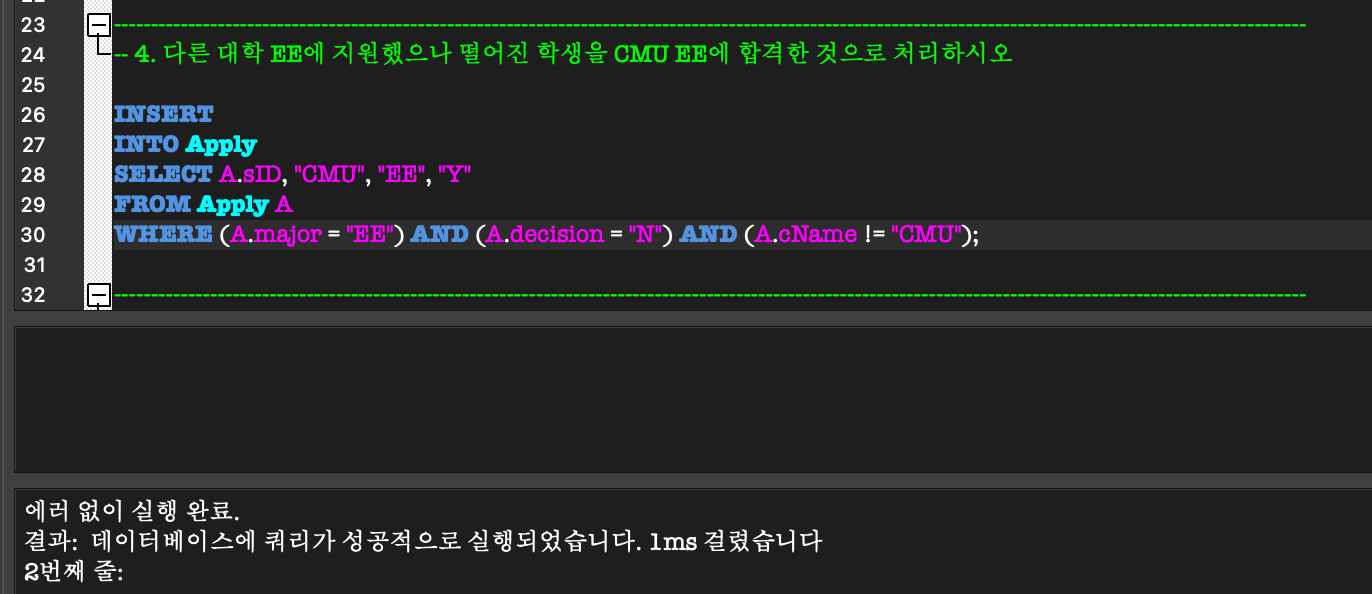
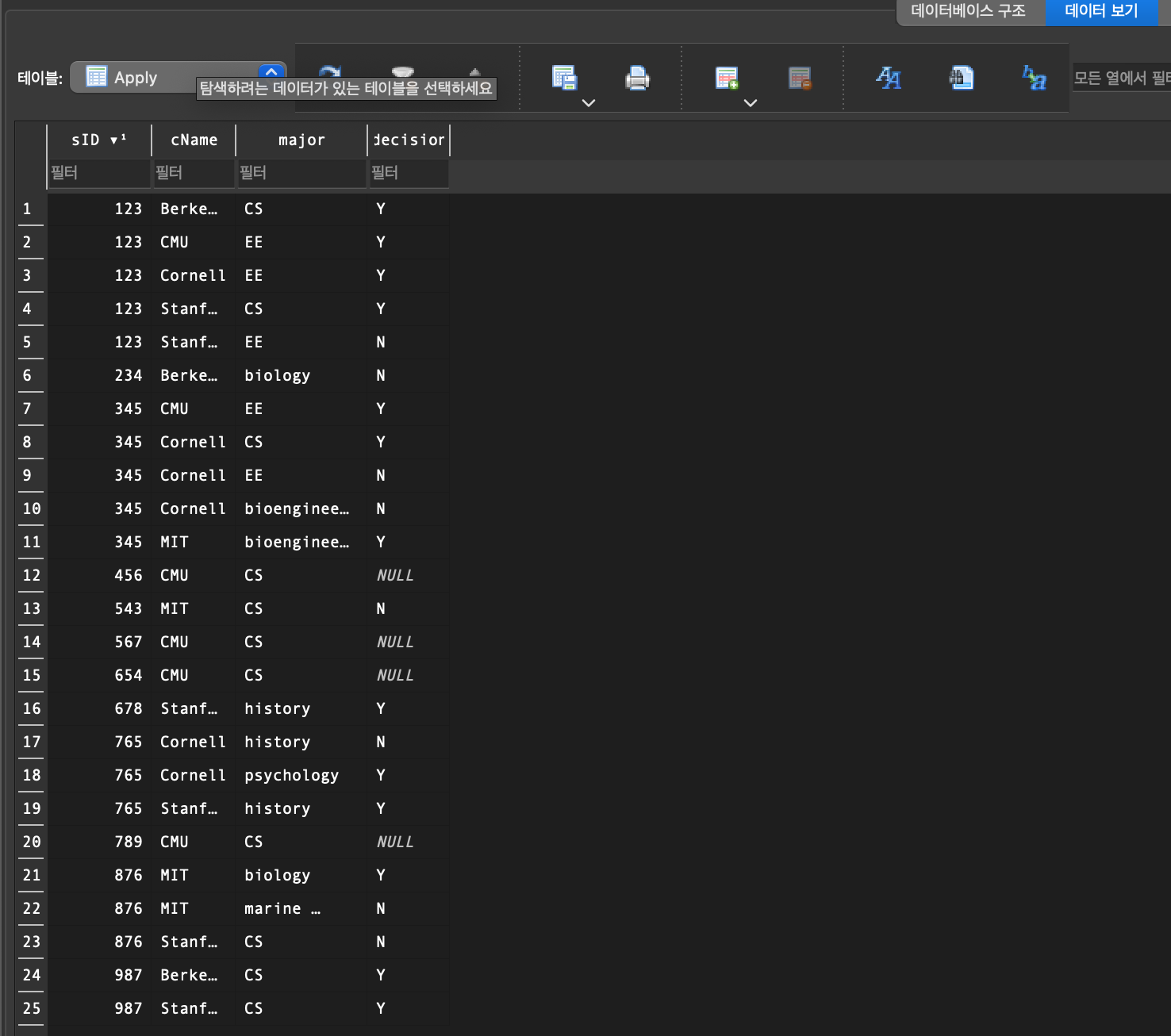
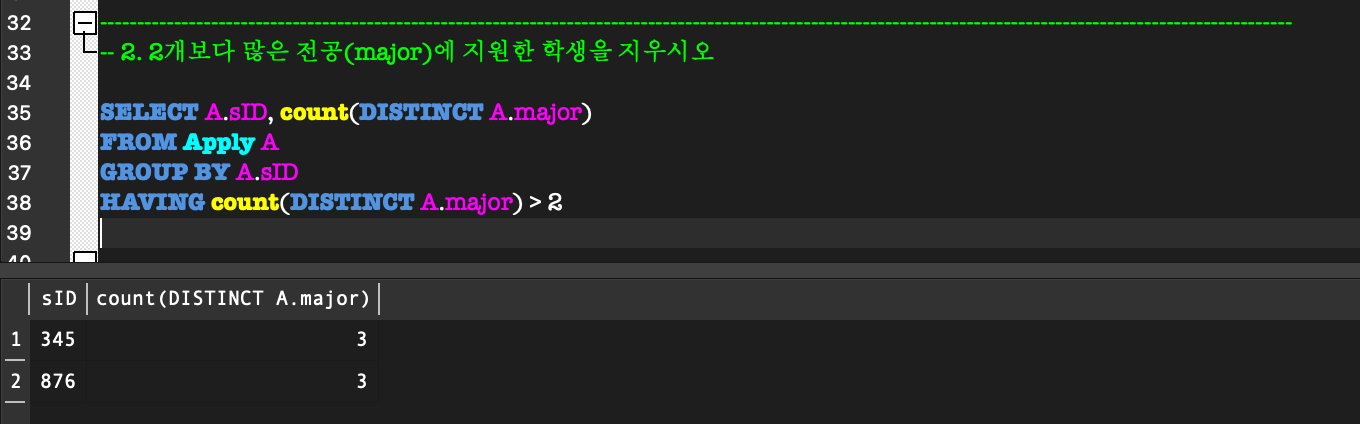
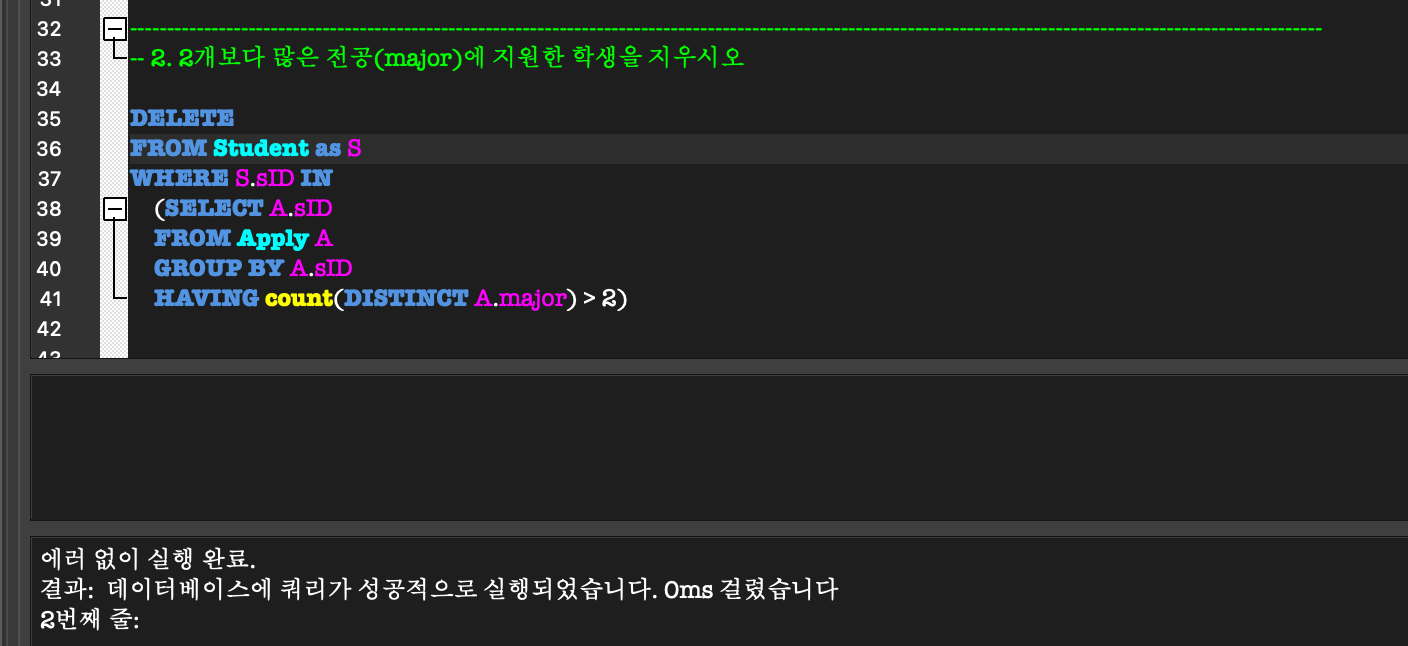
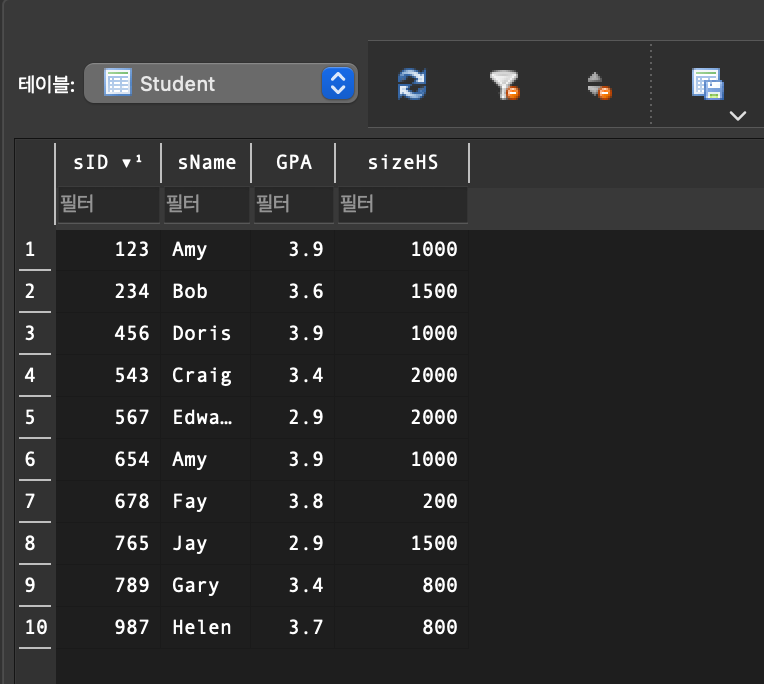 (sID = 345, 876이 delete된 것을 알 수 있다)
(sID = 345, 876이 delete된 것을 알 수 있다)
(여기서 궁금한 것이 생김.
FROM Student as S가 아니라,
FROM Student S 라고 하면 에러가 남..
지금까지는 FROM Student S라고 해도 alias 적용이 되었었는데 여기서는 왜 안될까???)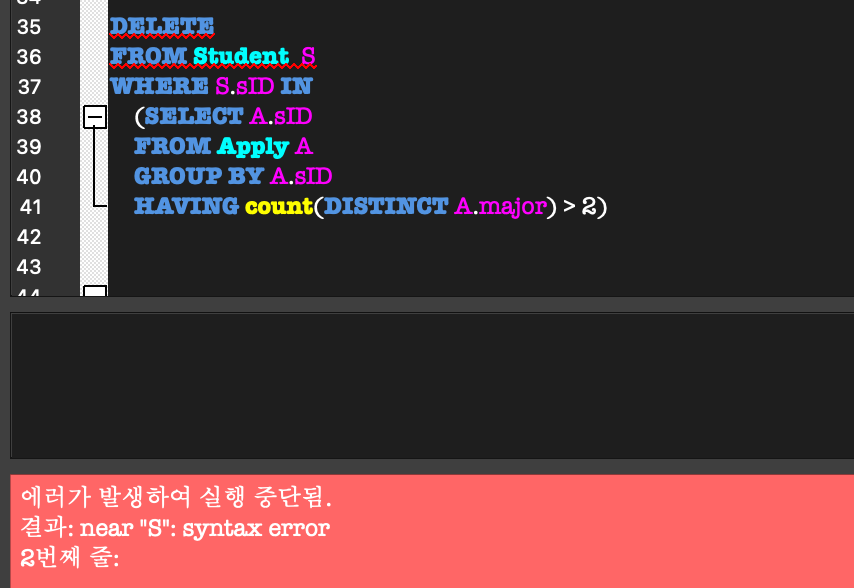



Efficient Deep Learning