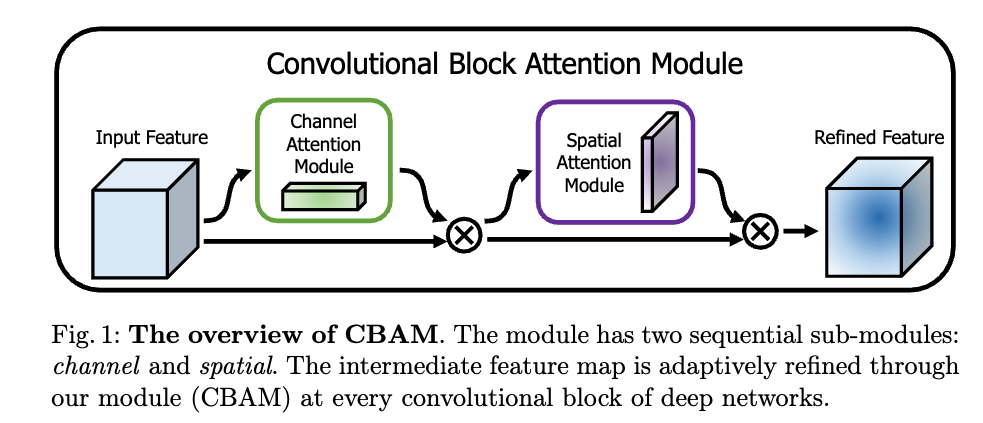
[2018 ECCV] [Simple Review] CBAM: Convolutional Block Attention Module
-
당시에 network engineering methods는 주로 depth, width, and cardinality를 focus했는데,
우리는 attention을 focus함.
attention은 실제로 one of the curious facets of a human visual system이기 때문. -
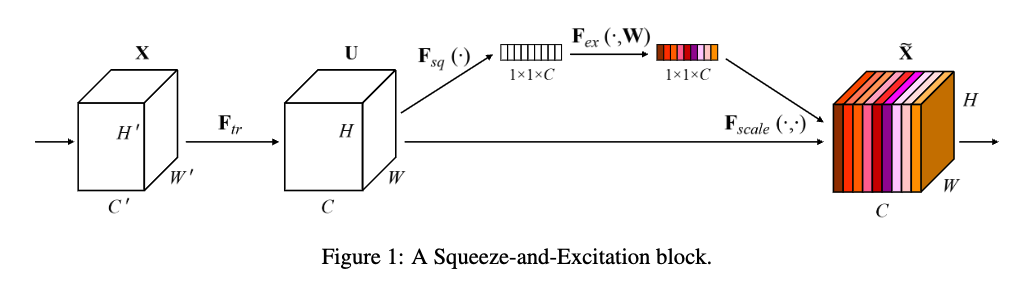
관련 연구로 Squeeze-and-Excitation module이 있는데,
그 연구는 channel-wise attention을 구하기 위해 global average-pooled features를 사용
-
우리는 both spatial and channel-wise attention을 할 것임.
근데, based on an efficient architecture and 경험적으로 SE보다 superior한.
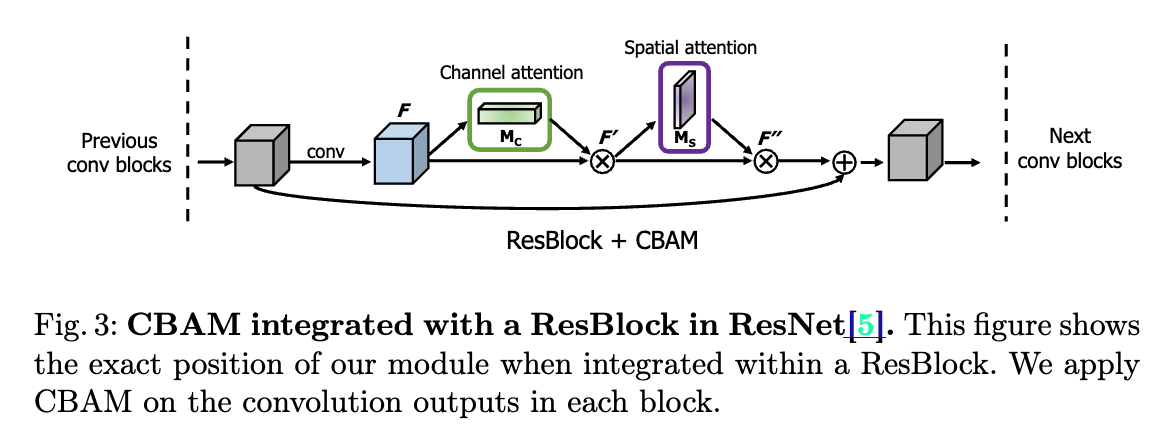
Given an input image, two attention modules, channel and spatial, compute complementary attention,
focusing 'what' and 'where' respectively.
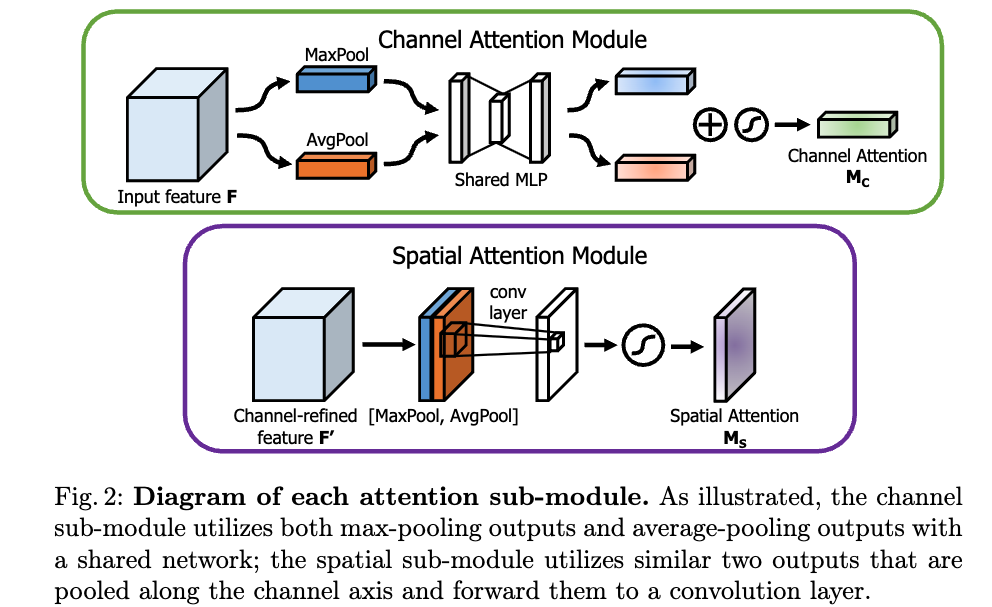
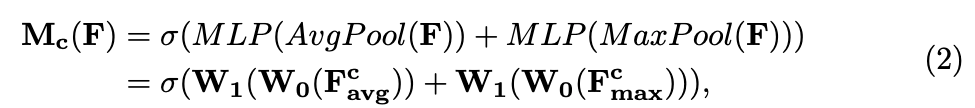
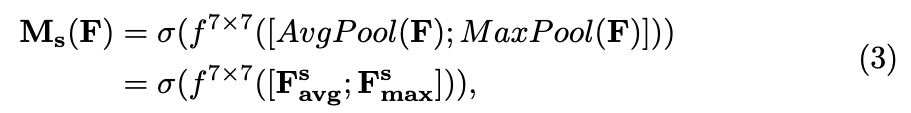
-
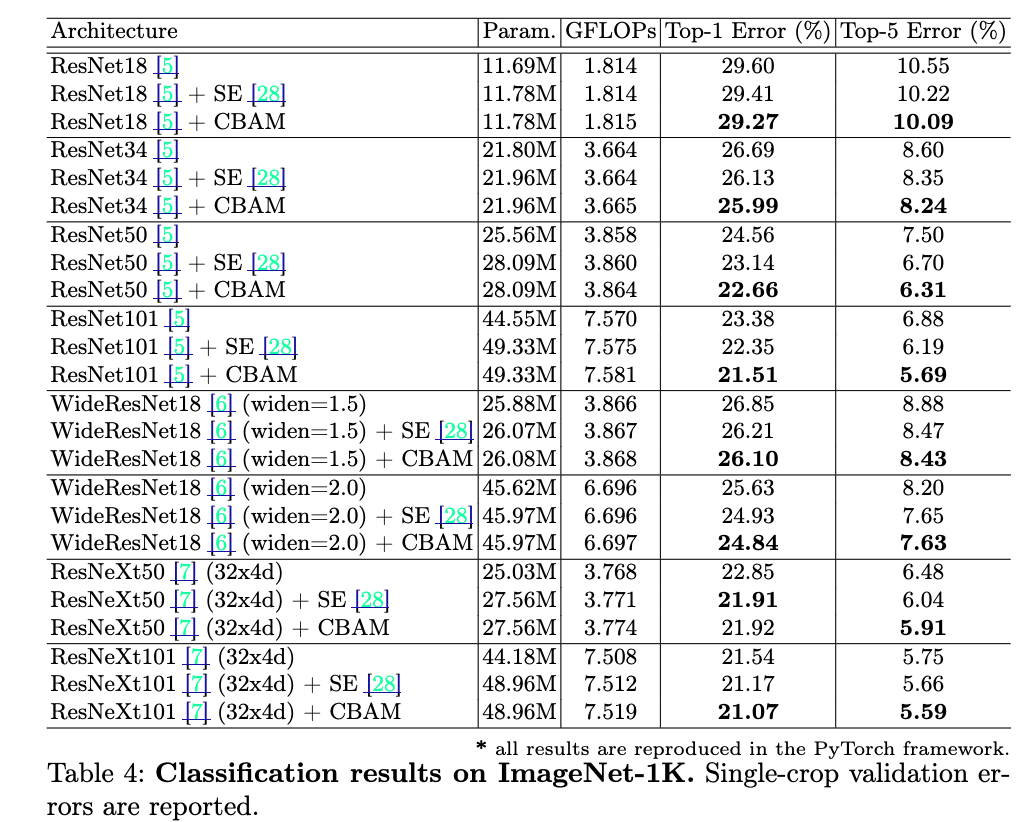
ImageNet-1K

Efficient Deep Learning