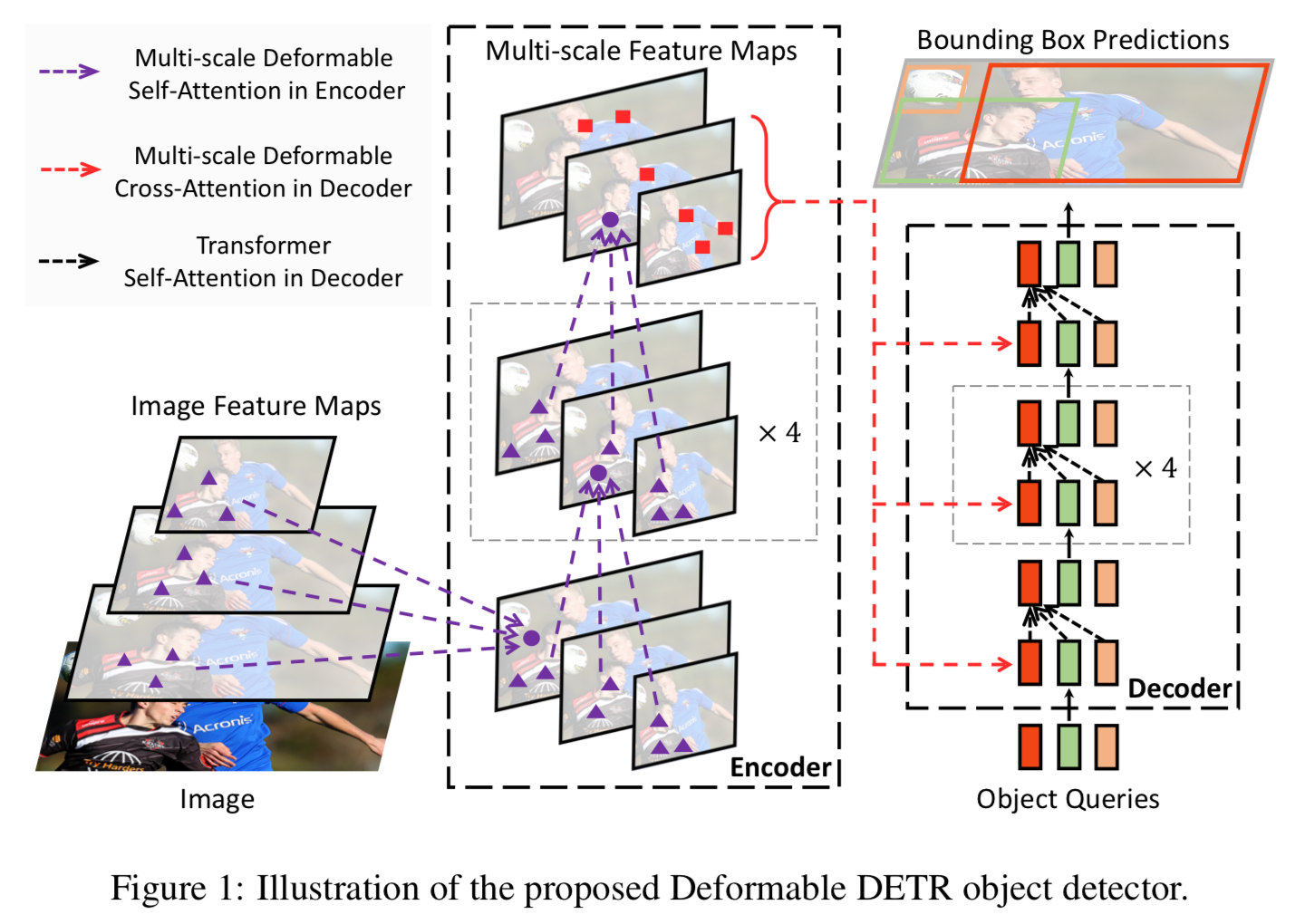
[2021 ICLR] [Deformable DETR] Deformable DETR: Deformable Transformers for End-to-End Object Detection
[Paper Review] 2D Object Detection
RT-DETR에서 Deformable DETR의 computational bottleneck을 지적
RT-DETR을 읽고 있었는데,
RT-DETR의 efficient hybrid encoder의 등장배경과 이해를 위해
Deformable DETR에서 소개한 multi-scale Transformer encoder를 알아야 할 것 같아서
Deformable DETR을 간략하게 읽어봤다
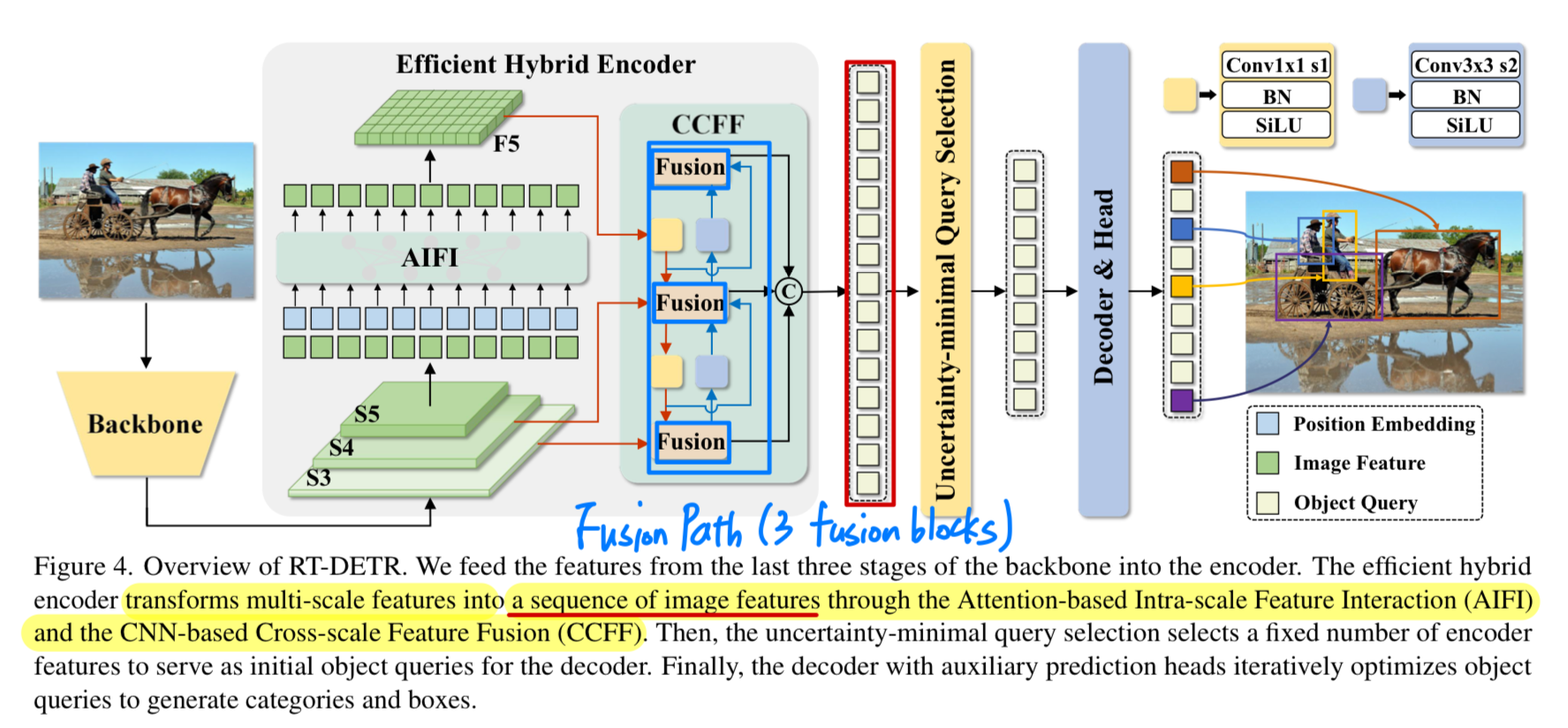
- RT-DETR의 efficient hybrid encoder의 등장 배경 :
Deformable DETR에서 사용한Multi-scale Deformable Attention Module은 computational cost를 줄이긴 했지만,
encoder에 약간 증가한 sequence length로 인해 computational bottleneck을 야기했다.
 따라서 RT-DETR에서는 Deformable DETR의 multi-scale Transformer encoder의 computational redundacny를 지적하며 새로운 방식은 hybrid encoder를 제시했음.
따라서 RT-DETR에서는 Deformable DETR의 multi-scale Transformer encoder의 computational redundacny를 지적하며 새로운 방식은 hybrid encoder를 제시했음.
Paper Info
- Zhu, Xizhou, et al. "Deformable detr: Deformable transformers for end-to-end object detection." arXiv preprint arXiv:2010.04159 (2020).
1. Introduction
- DETR은 2가지 issue가 존재.
- 기존에 존재하는 Object detector들보다 converge하기 위해 훨씬 많은 training epoch이 필요함.
- DETR은 상대적으로 small object에 대해서 Low performance를 보임.
- 이 논문에서,
우리는 Deformable DETR을 소개할 것이다.
Deformable DETR은 deformable convolution의 sparse spatial sampling과 transformer의 relation modeling capability를 결합한 것이다.
우리는 deformable attention module을 제안한다.
이 module은 모든 feature map pixel 중에서 중요한 핵심 요소를 pre-fitering하는 작은 sampling sampling location을 참조한다.
이 module은 FPN의 도움 없이도 multi-scale feature를 aggregating하는 데 자연스럽게 확장될 수 있다.
Deformable DETR에서는 feature map을 처리하는 Transformer attention module을
(multi-scale) deformable attention module로 대체했다. (Fig. 1.)
2. Related Work
(skip)
cross-attention은 Transformer의 encoder-decoder attention을 의미하는 것임.
(이미지 참조)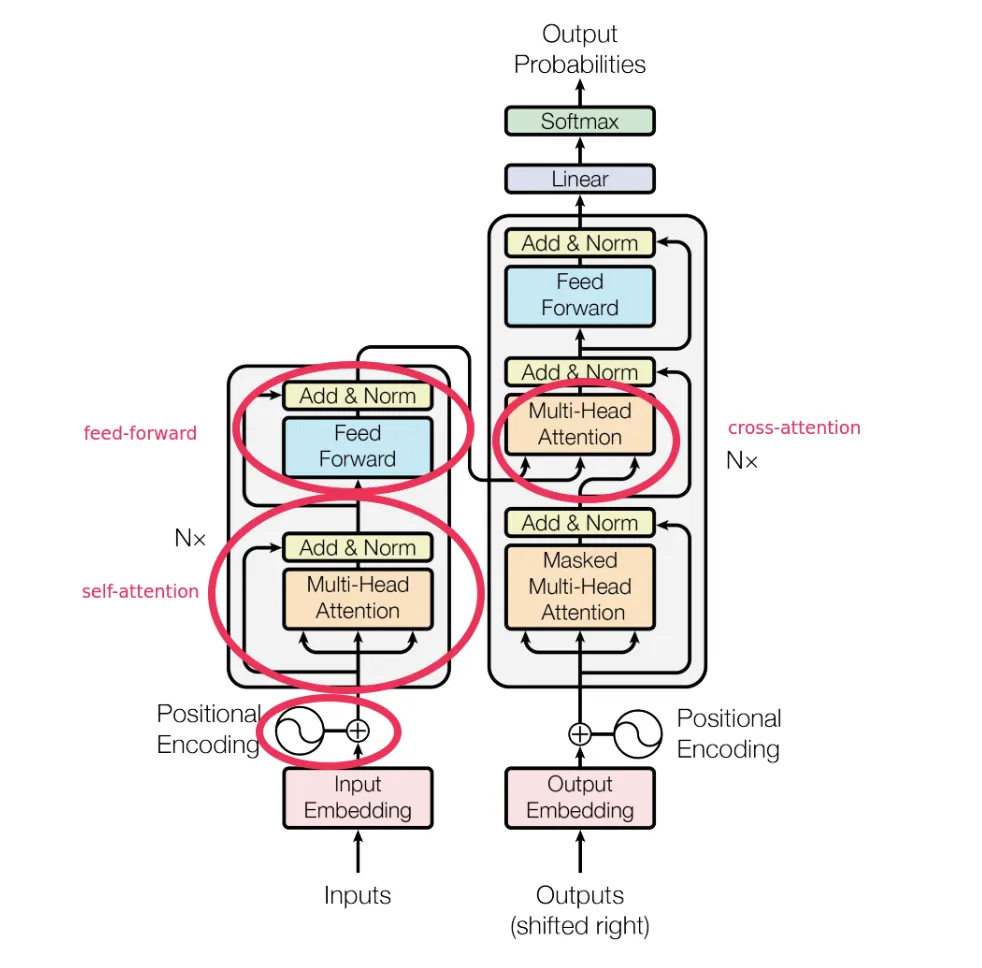
3. Revisiting Transformers and DETR
Multi-Head Attention in Transformers
- Transformers는 machine translation을 위한 attention mechanism에 기반한 network architecture이다.
주어진 query element(e.g. output sentence의 target word)와 key element(e.g. source words in the input sentence)을 바탕으로,
multi-head attention module은 query-key 쌍의 compatibility(호환성)을 측정하는 attention weights에 따라 key 내용을 적응적으로 aggregate한다.
model이 서로 다른 representation subspaces와 다른 위치의 contents에 집중할 수 있도록,
서로 다른 attention head의 outputs은 learnable weights로 linearly aggregated된다.
query element를 indexing하는 는 representation feature 를 가지며,
key element를 indexing하는 는 representation feature 를 가지고,
는 feature dimension이고, 는 the set of query elements, 는 the set of key elements라고 가정하면
Multi-head attention feature는 다음과 같이 계산된다 :
- Transformer에는 두가지 issue가 있음.
- Transformer는 convergence하기 전에 long training schedule이 필요함.
query와 key elements의 수가 각각 와 라고 할 때,
일반적으로 와 는 mean 0과 variance 1의 distirbution을 따르도록 parameter initialization하고,
이는 가 충분힐 클 때, attention weights 로 만든다.
이는 input feature에 대해서 ambiguous(애매한) gradients를 주게 되므로,
attention weights가 특정 key에 집중할 수 있도록 long training schedule이 필요하다.
일반적으로 image pixel인 image domain에서는 (key elements 개수)가 매우 클 수 있으며, convergence로 이어진다. - the computational and memory complexity for multi-head attention can be high with numerous query and key elements.
Eq. 1(바로 위에 있는 그림)의 computational complexity는 인데,
pixels이 query와 key element가 되는 image domain에서 이기 때문에,
term에 의해 complexity가 dominated된다.
그러므로, multi-head attention moudle은 feature map size가 커질수록 quadratic complexity gowth로 인해 문제를 겪는다.
(어떻게 complexity를 구했는지 모르겠음.)
- Transformer는 convergence하기 전에 long training schedule이 필요함.
DETR
- DETR의 Transformer encoder에 대해서,
query와 key elements는 feature map의 pixel이 된다.
feature map의 height and width를 각각 , 라고 한다면
self-attention의 computational complexity는 가 되고,
spatial size에 따라 급격하게 증가하게 된다.
- DETR의 Transformer decoder에 대해서, input에는
encoder의 feature map과 learnable positional embeddings에 의해 표현되는 개의 Object queries가 있다.
decoder에는 두가지 attention type이 있는데, cross-attention과 self-attention module이다.- cross-attention module의 경우,
query elements는 object queries, key elements는 encoder의 output feature map으로 구성되어 있다.
따라서 , 이고,
complexity는 이다. - self-attention module의 경우,
query와 key elements는 모두 object queries이다.
따라서 이고,
complexity는 이다.
따라서 complexity는 object queries가 적당히 있을 때만 acceptable하다.
- cross-attention module의 경우,
- DETR은 많은 hand-designed components의 필요성을 제거하여 object detection에 대한 좋은 설계를 보여줬다.
그러나 이러한 model도 자체적인 문제를 갖고 있다.
이러한 문제들은 주로 transformer attention image feature map을 key element로 다루는 능력 부족으로 설명될 수 있다.- DETR은 small object를 detect하는 데 상대적으로 성능이 낮다.
현대의 object detector들은 small object를 더 잘 detection하기 위해 high-resolution feature maps을 사용하는데,
high-resolution feature map은 DETR의 Transformer encoder 내의 self-attention module에 대한
unacceptable complexity를 초래할 수 있다. - 현대의 object detector와 비교하여 DETR은 converge하기 위해 훨씬 더 많은 train epoch이 필요하다.
이는 주로 image feature를 처리하는 attention module이 학습하기 어렵기 때문이다.
예를 들어, initialization할 때, cross-attention module은 전체 feature map에 대한 average attentino을 갖고 있다.
그러나 학습의 끝부분에서는 attention map이 매우 sparse하게 학습되어 object에만 집중한다.
- DETR은 small object를 detect하는 데 상대적으로 성능이 낮다.
4. Method
4.1 Deformable Transformers For End-To-End Object Detection
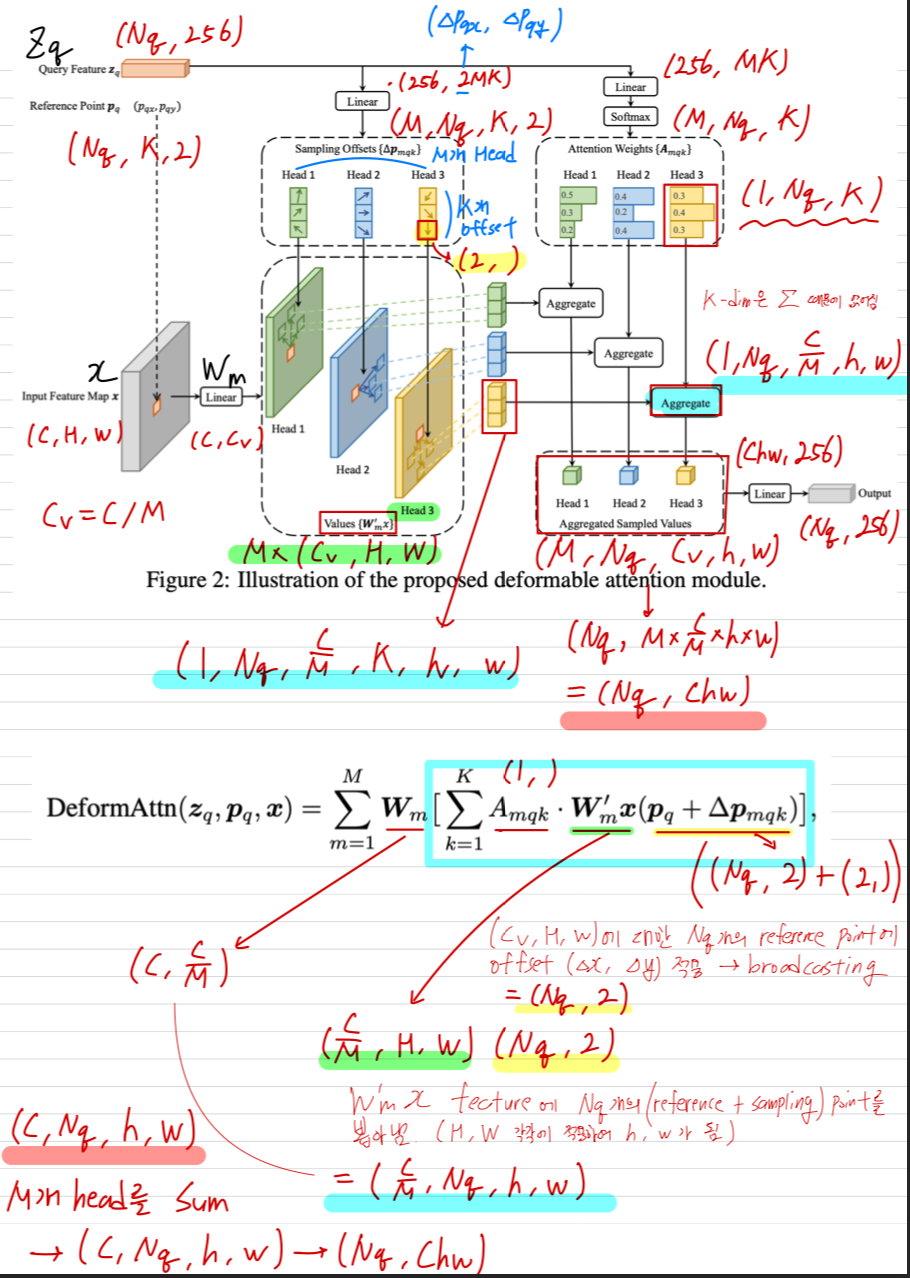
Deformable Attention Module
-
image feature map에 Transformer attention을 적용하는 핵심 문제는
모든 가능한 spatial locations을 살펴봐야 한다는 것이다.
이를 해결하기 위해 우리는 deformable attention module을 제시한다.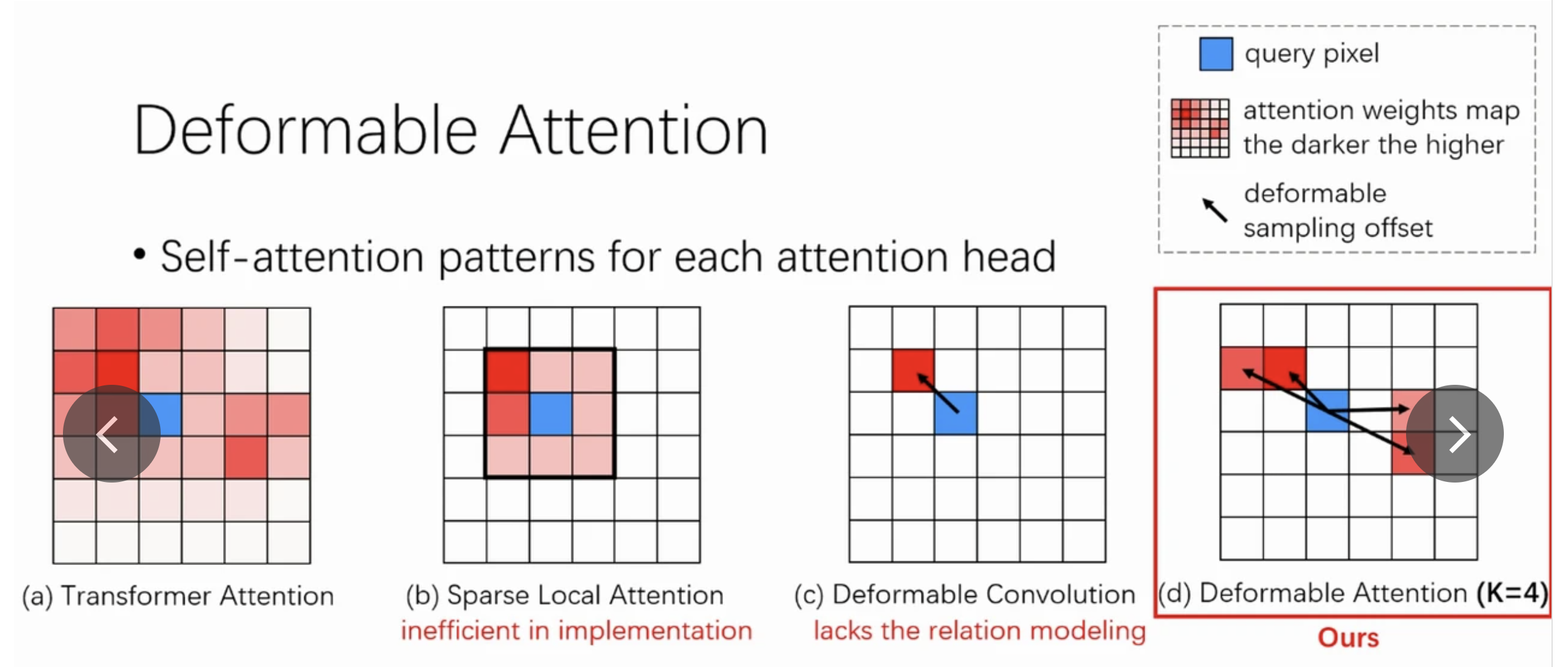 (출처 : https://iclr.cc/virtual/2021/poster/3105)
(출처 : https://iclr.cc/virtual/2021/poster/3105)
deformable convolution에 영감 받은, 이 deformable attention module은
feature map의 spatial size에 상관없이 reference point(기준점) 주변의 a small set of key sampling points에만 주목한다.
각 query에 대해 고정된 소수의 key만 할당함으로써, convergence 문제와 feature spatial resolution 문제를 완화할 수 있다. -
: input feature map
: index a query element with content feature
: 2- reference point
: attention head index
: the sampling point index
: total sampled key number ()
: the sampling offset
: attentino weight of the sampling point in the attention head.
(The scalar attention weight lies in the range [0, 1], normalized by )- 가 분수일 경우,
계산에 bilinear interpolation이 적용된다. - 와 는 둘 다 query feature 에 linear projection이 적용되어 만들어진다.
구현에서, query feature 는 channel의 linear projection operator에 입력되며,
처음 channel은 sampling offset 을 encoding하고,
나머지 channel은 attention weight 를 얻는다.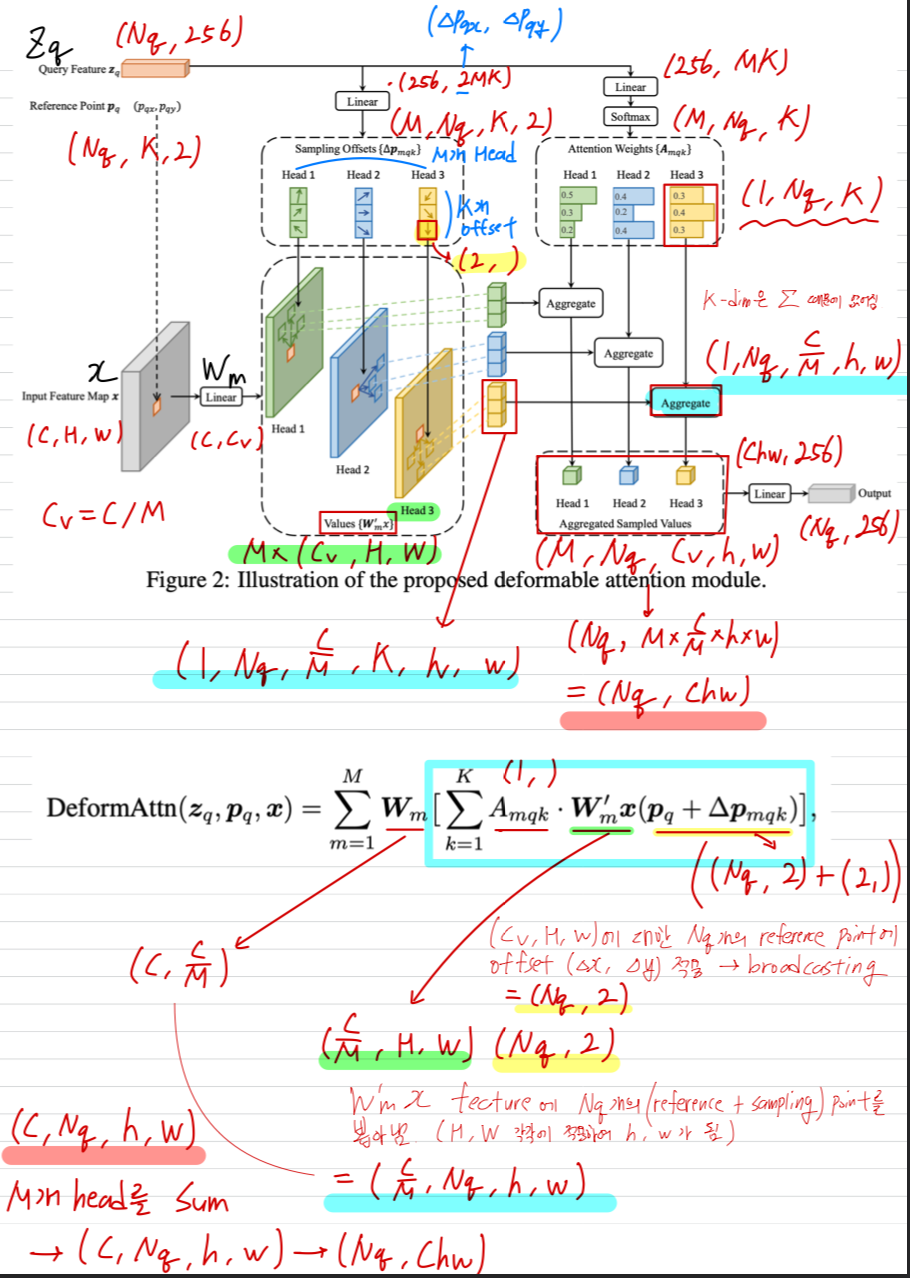
- 가 분수일 경우,
Multi-scale Deformable Attention Module (RT-DETR에서 지적한 computational bottleneck)
- input feature level를 index하는 추가


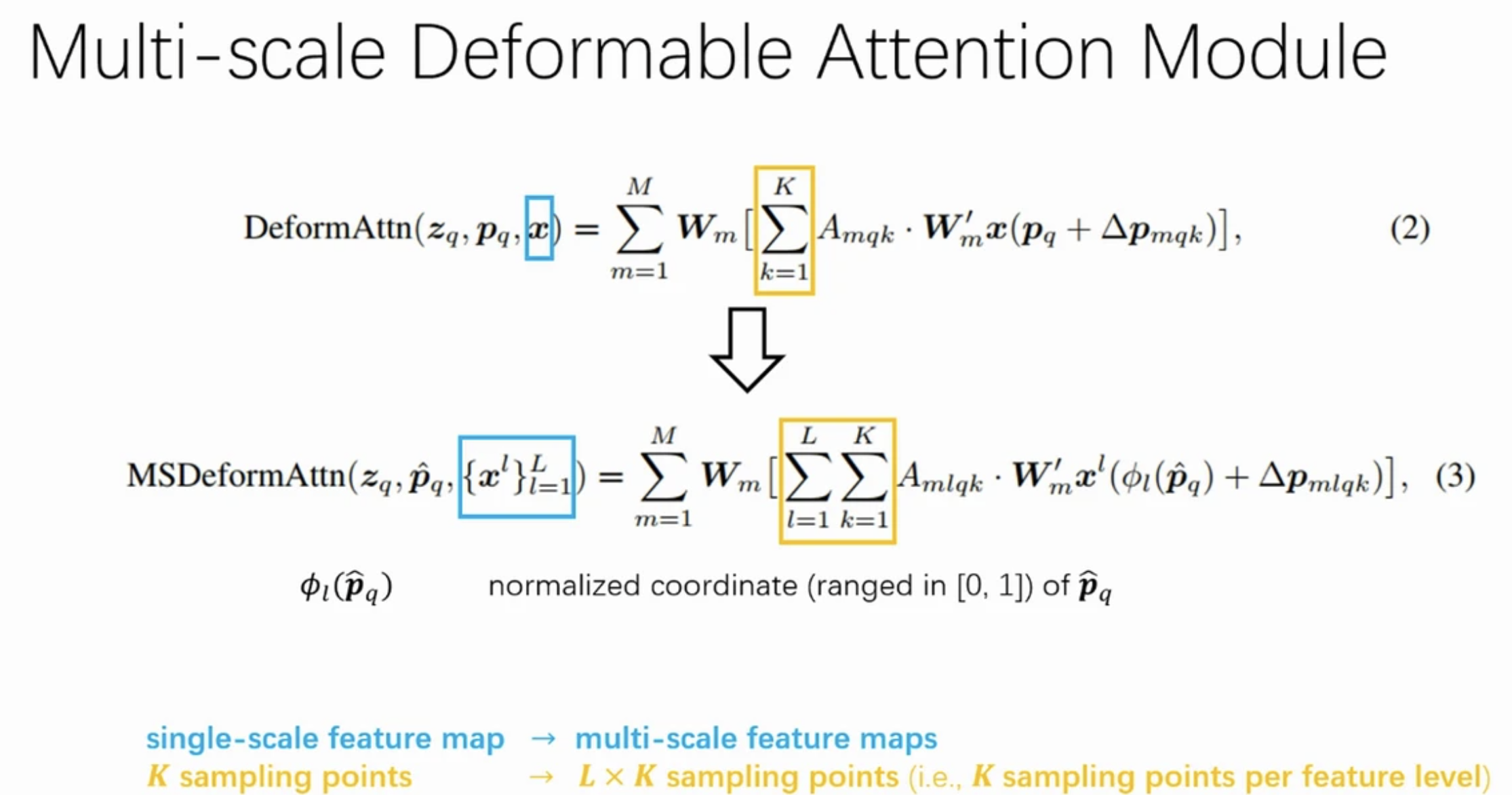 (출처 : https://iclr.cc/virtual/2021/poster/3105)
(출처 : https://iclr.cc/virtual/2021/poster/3105)
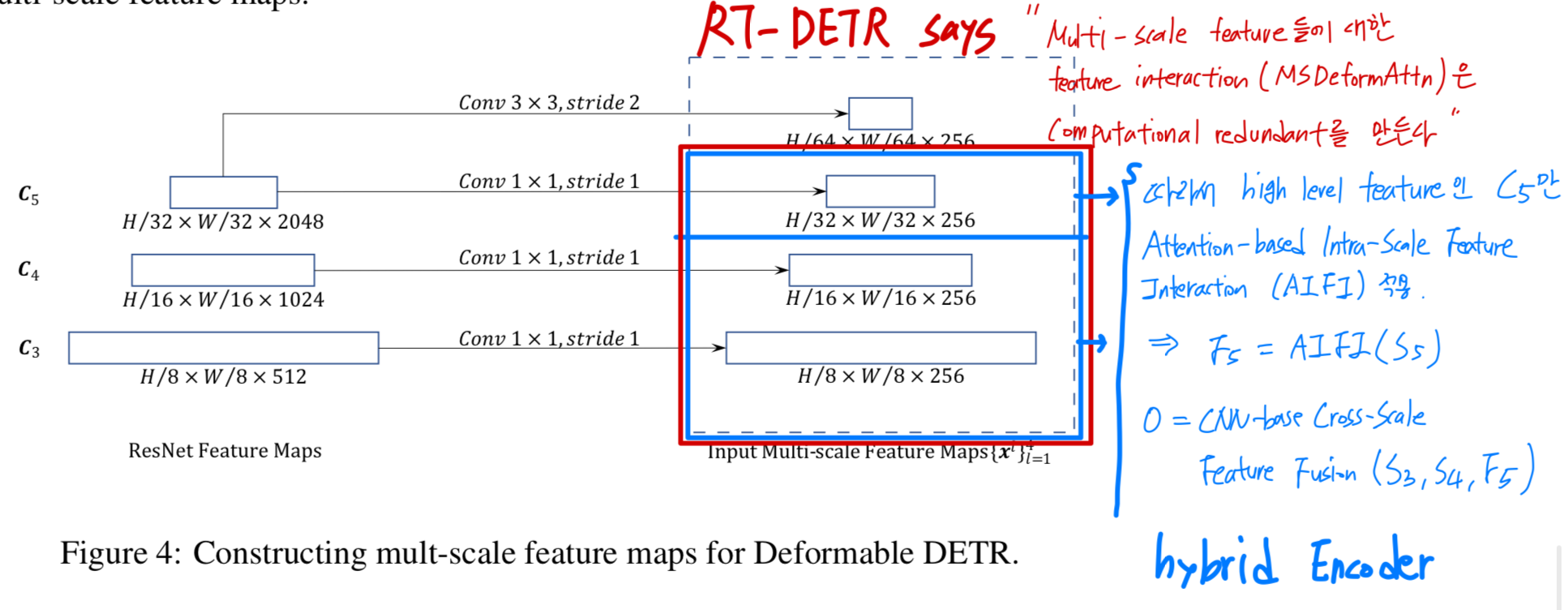
➡️ 이 부분을 RT-DETR에서는 encoder의 computational bottleneck이라고 지적하고, hybrid encoder를 제시한게 아래와 같은 구조
Multi-Scale Deformable Attention의 computational redundancy를 computatational bottleneck이라고 지적,
그리고나서 RT-DETR에서는 variants인 Efficient Hybrid Encoder를 제시

Deformable Transformer Encoder
- 우리는 DETR에서 feature map을 처리하는 Transformer의 attentino module을
multi-scale deformable attentino module로 대체했다.
encoder의 input과 output은 모두 동일한 resolution의 multi-scale feature map이다.
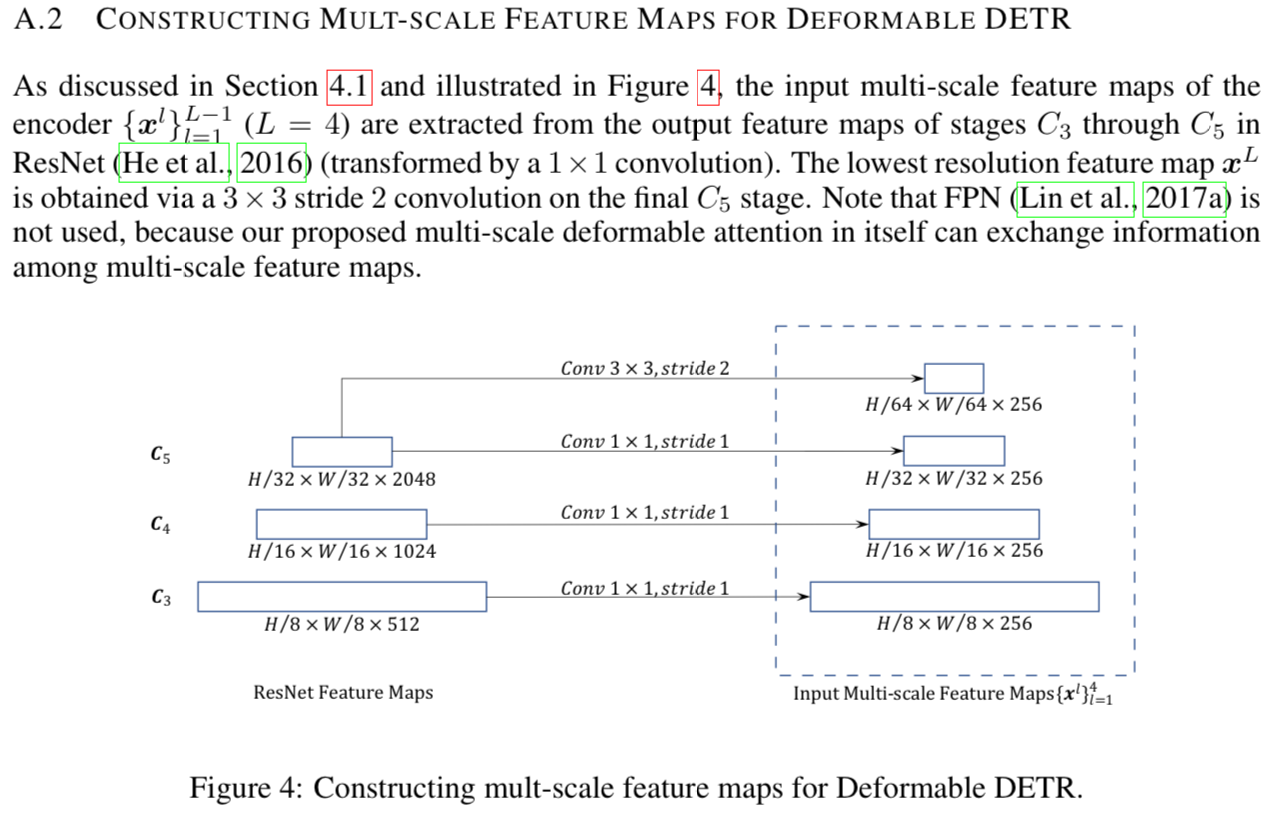
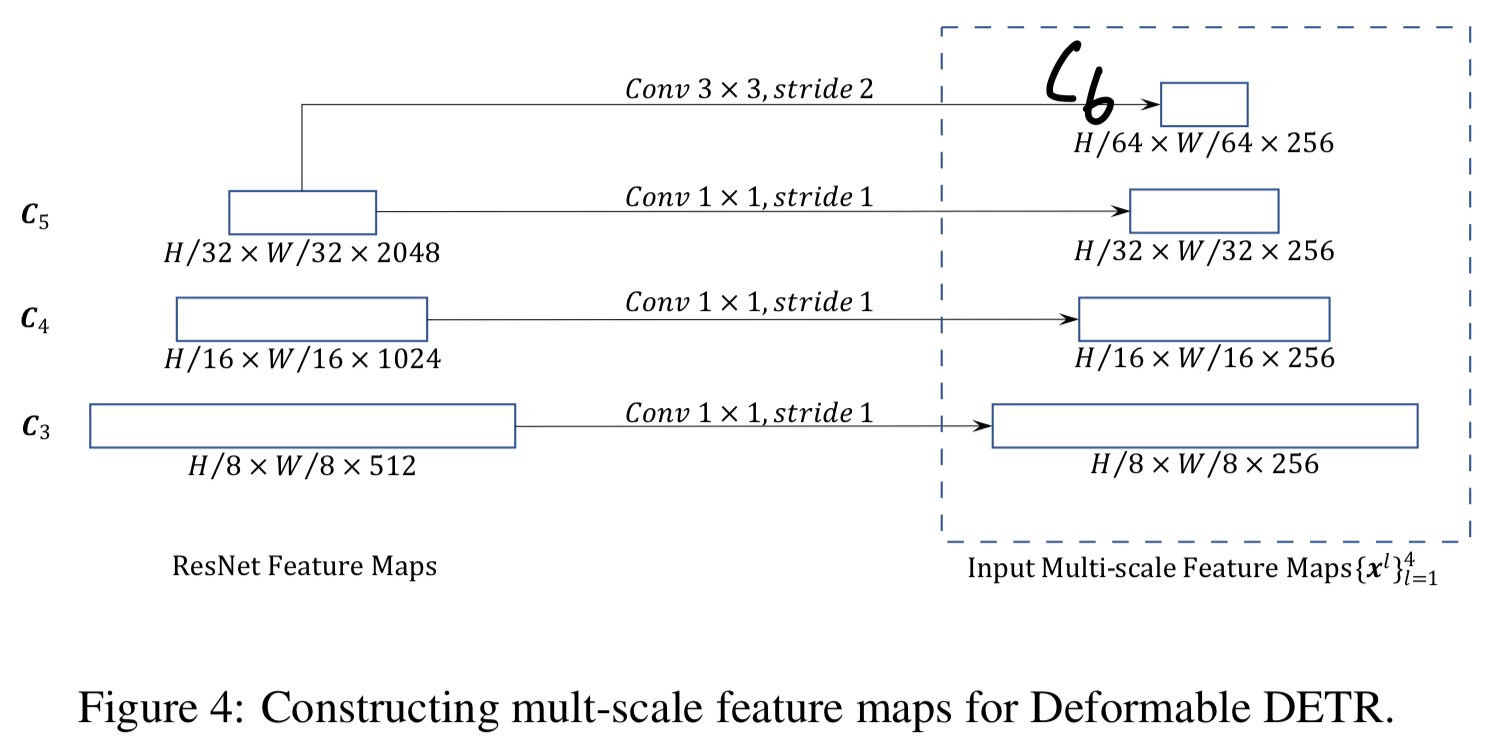
encoder에서는 ResNet의 부터 stage의 output feature maps으로부터 multi-scale feature map 을 추출했다.
(transformed by convolution ➡️ 모든 multi-scale feature map의 channel수가 이다)
여기서 의 resolution은 input image보다 배 낮다.
가장 낮은 resolution의 feature map 은 에 stride 2 convolution을 적용하여 얻은 이다.
-
우리는 multi-scale deformable attention module 자체가 multi-scale feature map 간 정보를 교환할 수 있기 때문에,
FPN의 top-down structure는 사용하지 않았다.
(Section 5.2의 실험 결과, FPN을 추가해도 성능이 향상되지 않음)
-
encoder에 multi-scale deformable attention module을 적용할 때,
output은 input과 동일한 resolution의 multi-scale feature map이다.
key와 query elements는 multi-scale feature map의 pixel이다.
각 query pixel의 reference point는 자기 자신이다.
각 query pixel이 속한 feature level을 식별하기 위해 positional embedding 외에
feature representation에 scale-level embedding 을 추가했다.
fixed encoding에 positional embedding과는 달리, scale-level embedding 는 random하게 initialized되어 network와 함께 jointly trained된다.
Deformable Transformer Decoder
-
decoder에는 self-attention module과 cross-attention module이 있다.
두 attention module의 query elements는 object queries이다.
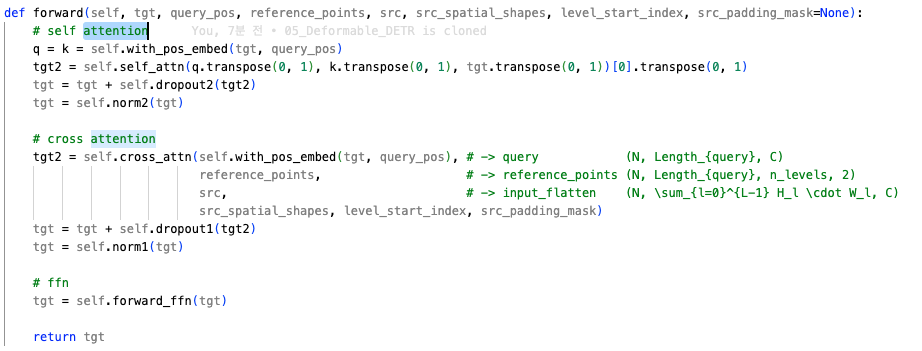
- Self-attention에서는,
object queries들이 서로 interact하며, key elements는 object queries이다.
➡️ (object queries와 object queries를 self-attention) - Cross-attention module에서는,
object queries가 encoder의 output feature map을 key elements로 하여 feature를 추출한다.
➡️ (object queries와 encoder의 output featuer map(=src)을 cross-attention)
- Self-attention에서는,
-
transformer는 encoder와 decoder로 이루어져 있는데,
- encoder는 DeformableTransformerEncoderLayer로 이루어진 DeformableTransformerEncoder로 이루어짐.

- decoder는 DeformableTransformerDecoderLayer로 이루어진 DeformableTransformerDecoder로 이루어짐.

- encoder는 DeformableTransformerEncoderLayer로 이루어진 DeformableTransformerEncoder로 이루어짐.
-
deformable attention module은 key elements로 convolutional feature map을 처리하도록 설계되었기 때문에,
각 cross-attention module만 multi-scale deformable attention module로 바꾸고,
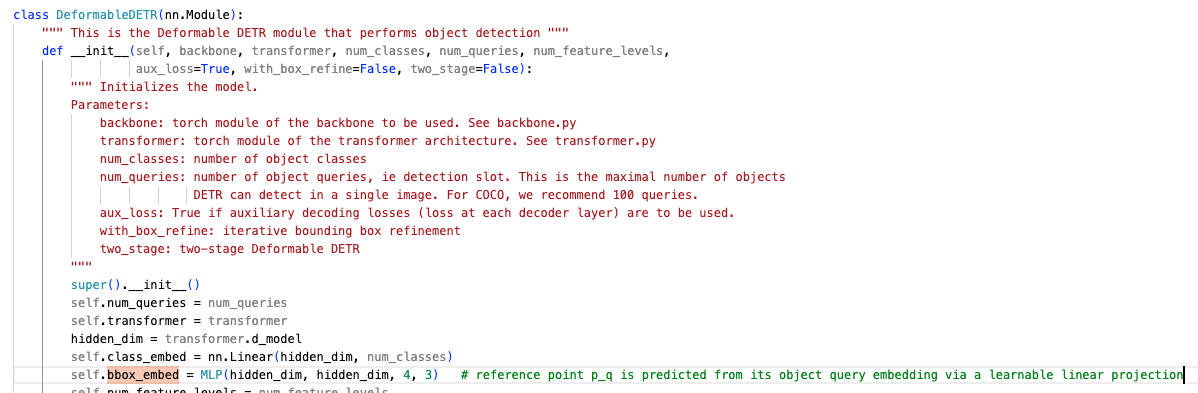
self-attention module은 그대로 두었다.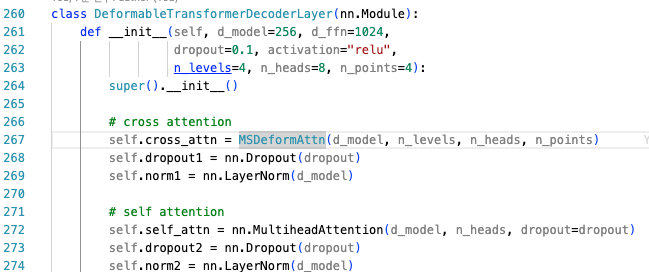 각 query에 대해 reference point 의 2-d normalized 좌표는 learnable linear projection을 거쳐 sigmoid function으로 predicted된다.
각 query에 대해 reference point 의 2-d normalized 좌표는 learnable linear projection을 거쳐 sigmoid function으로 predicted된다.
multi-scale deformable attention module은 reference point 주변의 iamge feature를 추출함로,
detection head는 reference point에 대한 상대적인 offset으로 bbox를 예측하여 optimization difficulty를 줄인다.
reference point는 bbox의 initial guess of the box center로 사용된다.
detection head는 reference point에 대한 relative offsests을 예측한다.

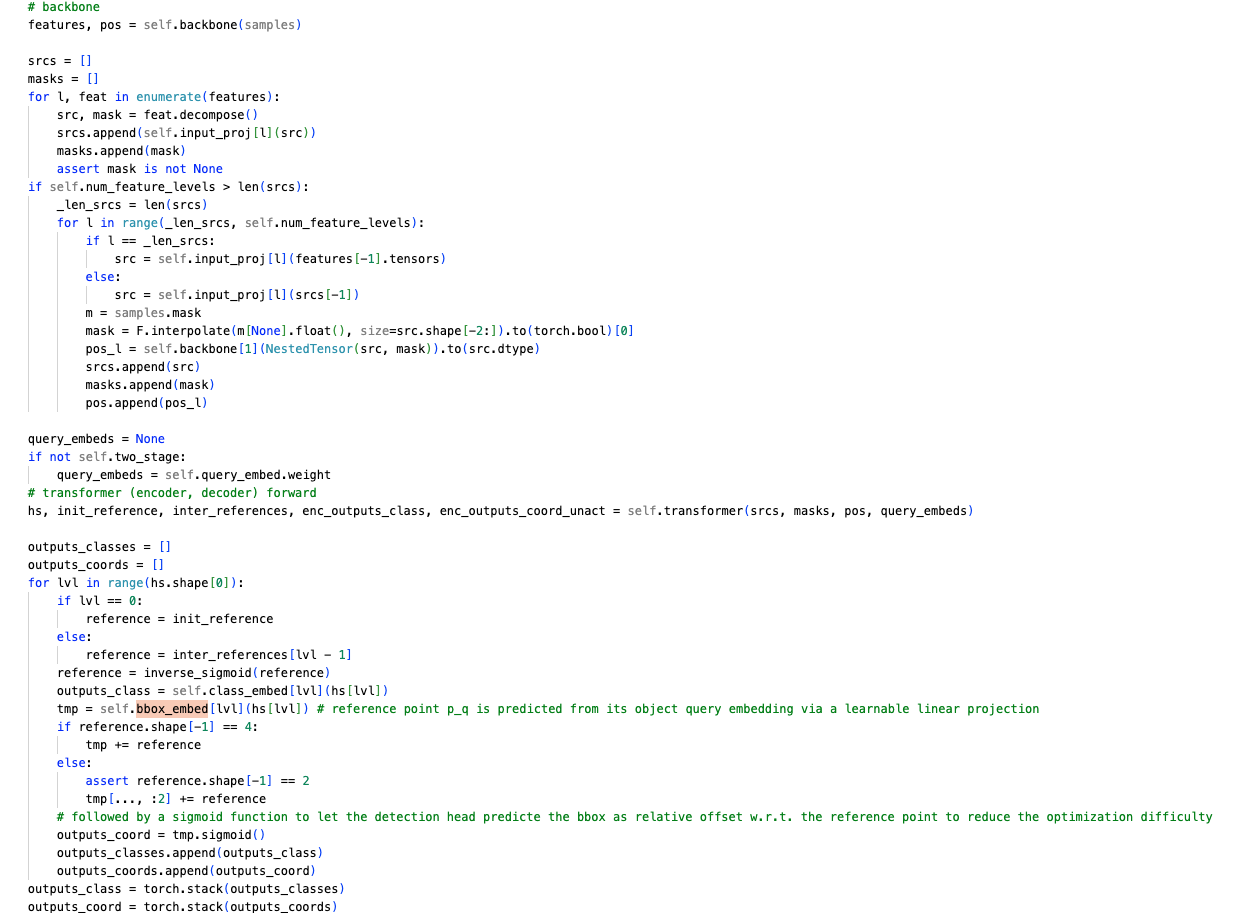 이 방식으로 학습된 decoder attention은 predicted bboxes와의 strong correlation을 갖게 되어 training convergence 속도가 빨라진다.
이 방식으로 학습된 decoder attention은 predicted bboxes와의 strong correlation을 갖게 되어 training convergence 속도가 빨라진다.
Trnasformer의 attentino modules을 deformable attention module로 교체하여,
efficient and fast converging detection system인 Deformable DETR을 구축했다.