[2024] Slim-neck by GSConv: A lightweight-design for real-time detector architectures
Paper Info.

Abstract
- Real-time object detection은 산업과 연구 분야에서 중요.
edge device에서, 큰 model은 real-time detection 요구사항을 갖추기 어려움.
그리고 많은 depth-wise separable conv를 갖는 a lightweight model은 the sufficient accuracy를 얻기 어려움.
그래서 우리는 accuracy를 유지하면서 model을 가볍게 하는 a new lightweight convolutional techniques, GSConv를 제안.
GSConv는 an excellent trade-off between the accuracy and speed를 갖춤.
게다가 GSConv를 기반으로 한 Slim-Neck (SNs) design을 제시한다.
이는 real-time detectors의 higher computational cost-effectiveness를 달성할 수 있게 함.
1. Introduction
-
Deep Neural Networks (DNNs)의 high computational costs를 줄이기 위해, lightweight designs of DNNs이 떠오르고 있다.
-
이 연구에서는 주로 parameters와 FLOPs를 줄이기 위해 depth-wise separable convolutional(DSC)을 사용한다.
DSC의 lightweight 효과는 명백하다.
-
하지만 DSC의 disadvantages들도 명백하다 :
- input images의 channels information은 계산 과정에서 분리된다.
Figure 1 (a)는 vanilla convolutional(SC, the standard convolution),
Figure 1 (b)는 depth-wise separable convolutional(DSC)이다.
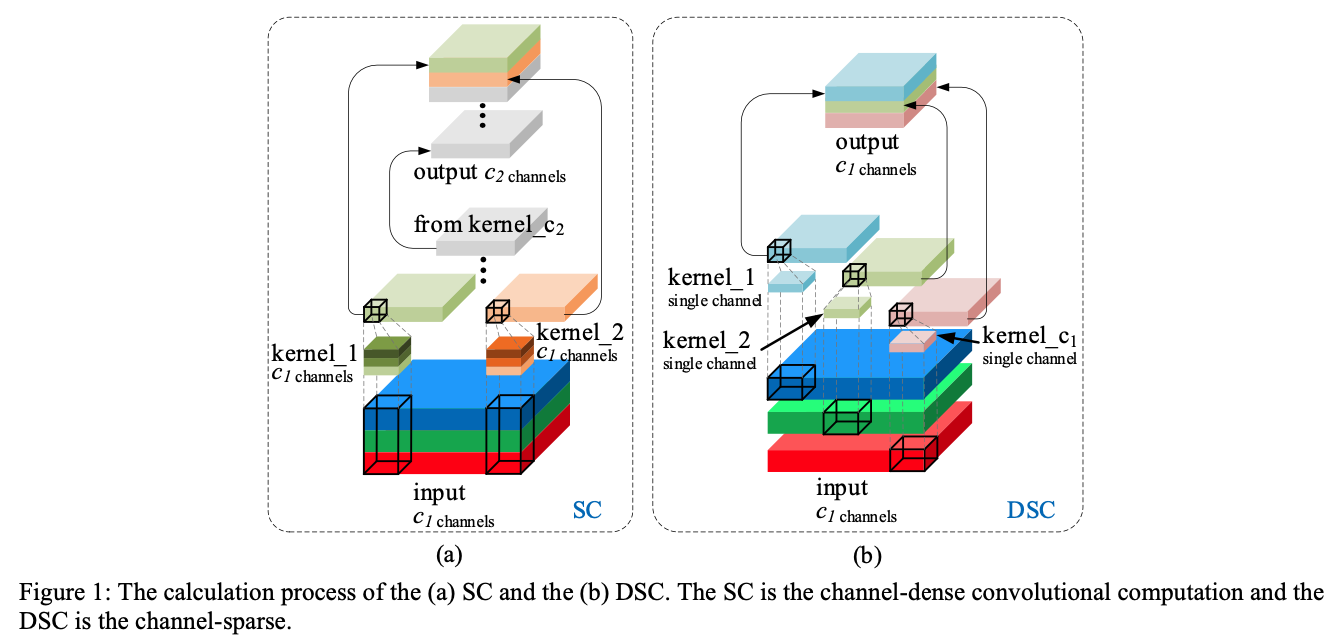
- 이 결함으로 인해 DSC는 SC의 representing capability of features(특징 표현 능력)가 훨씬 낮다.
이전의 lightweight 연구들은 DSC의 이러한 고유한 결함을 완화하기 위해 몇 가지 solution을 제안했다.- MobileNets은 1x1 dense convolutional을 사용하여 독립적으로 계산되는 channels information을 fusions했다.
- ShuffleNet은 "channel shuffle"을 사용하여 channels information 간의 interaction을 가능하게 하며,
- GhostNet은 "cheap operation"을 사용해 더 많은 feature를 생성했다.
(이전 연구들의 문제) 그러나 dense convolutional은 더 많은 computational resource를 소비하며, "channel shuffle" 또는 "cheap operation"을 사용하는 효과도 SC의 성능에 도달하지 못한다.
- input images의 channels information은 계산 과정에서 분리된다.
-
많은 lightweight model들은 DNNs의 시작부터 끝까지 DSC만을 사용하지만, (? 동의할 수 없는 내용... references가 필요해 보임)
classification이나 detection에 사용되는 backbone의 경우에 DSC의 결함은 바로 증폭된다.
우리는 DSC output channel만 shuffling하는 경우 생성된 feature가 여전히 "depth-wise separated"로 남아있다는 점을 주목한다.
따라서 우리는 SC와 DSC에서 생성된 feature를 shuffling하여 DSC의 output을 SC와 가능한 한 유사하게 만드는 mixing strategy를 채택한다.
이것이 GSConv이다. -
GSConv는 SC와 DSC를 협력시키기 위한 탐구이다.
lightweight real-time detector에서는 SC를 GSConv로 대체하기만 해도 정확도가 크게 향상된다.
표준 detector에는 backbone에서 SC를 사용하고 neck 부분에서는 GSConv를 사용하는 Slim-neck, SNs solution을 적용해 accuracy를 유지하면서 빠르게 inference할 수 있다.
SNs는 DSC의 결함(channel 간 정보 교환이 없는 것)으로 인한 부정적 영향을 최소화하고 이점(lightweight 연산)을 효율적으로 활용한다. -
이 연구에서의 main contributions은 다음으로 요약될 수 있다 :
- a new lightweight convolutional technique, GSConv를 도입하여 lightweight convolutional의 representational ability를 vanilla convolutional과 가깝게 만들고 computataional cost를 줄였다.
- real-time detector architecture를 위한 efficient neck design solution인 slim-neck (SNs)을 제공한다.
- 우리는 널리 사용되는 다양한 trick을 popular real-time detectors에서 검증하였으며, 이는 object detection 연구에 참고가 될 수 있다.
2. Related Work
- 보통 CNNs 기반의 detector들은 세 가지 parts로 구성되어 있다 : a backbone, a neck, and a head
- backbone은 input의 features를 추출하는 데에 사용되고
AlexNet에서 CNNs의 강력한 features extracting을 입증했다.
그리고나서 VGG, ResNet, and DarkNet과 같은 SC를 이용한 detection의 backbone 또는 detectors들이 설계되기 시작했다. - neck은 feature를 fusion한다.
neck에서는 FPN이 서로 다른 scale의 features들을 fusing함으로써 detectors의 speed와 accuracy를 향상시켰다. - head는 object를 detecting한다.
head에서는 anchor-based 또는 anchor-free 방식을 사용한다.
- backbone은 input의 features를 추출하는 데에 사용되고
- 또한, attention mechanisms, 예를 들어 SPP(Spatial Pyramid Pooling), SE(Squeeze-and-Excitation), CBAM(Convolutional Block Attention Module), CA(Coordinate Attention) 등은
특히 lightweight detectors에서 efficiency와 performance를 개선할 수 있다.
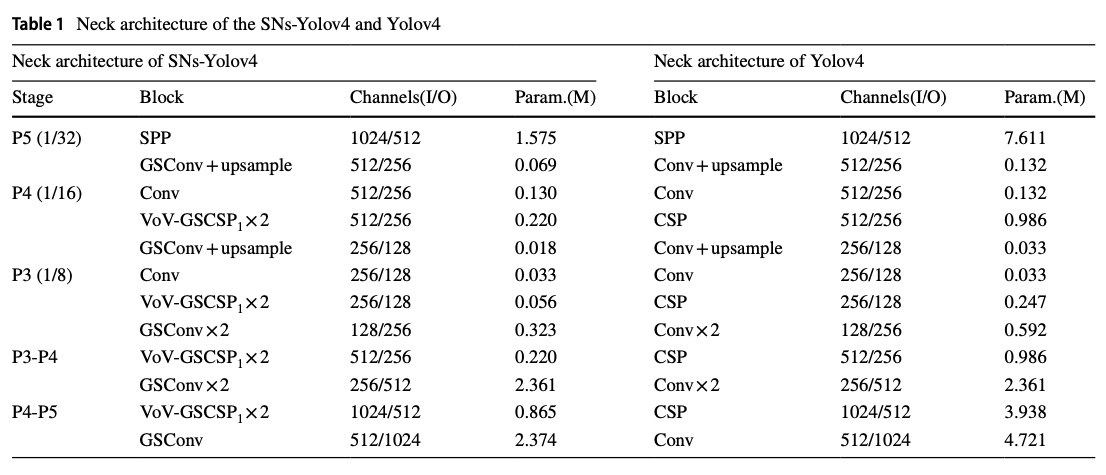
3. Slim-neck architecture design
-
이 연구의 핵심은 이 section에서 자세히 설명된다.
여기에는 GSConv 기법, efficient cross stage partial block(VoV-GSCSP),
lightweight detectors를 향상시키기 위한 free tricks,
적절한 activation funcions 및 bounding box regression loss functions 선택이 포함된다. -
우리의 목표는 detector가 edge devices에 적용될 수 있도록
a simple and efficient Neck을 구축하는 것이다.
위의 항목들을 최적화한 조합이 바로 Slim-Neck optimization solution (SNs)이다.
3.1 GSConv
-
최종적으로, 예측 속도를 높이기 위해
input image는 거의 항상 backbone에서 유사한 transformation process를 거친다.
즉, spatial information을 step by step으로 channel로 전달하는 것이다.
각 단계마다 space dimension (the width and height) compression과 channel dimension expansion이 일어나면 semantic information은 일부 손실이 된다. -
channel-dense convolutional(일반적인 convolution)은 각 channel 간의 hidden connection을 최대한 보존하지만,
channel-sparse convolution은 이러한 connection을 완전히 끊는다. -
GSConv는 lower time complexity로 이러한 connection을 가능한 한 많이 보존한다(자세한 내용은 Appendix).
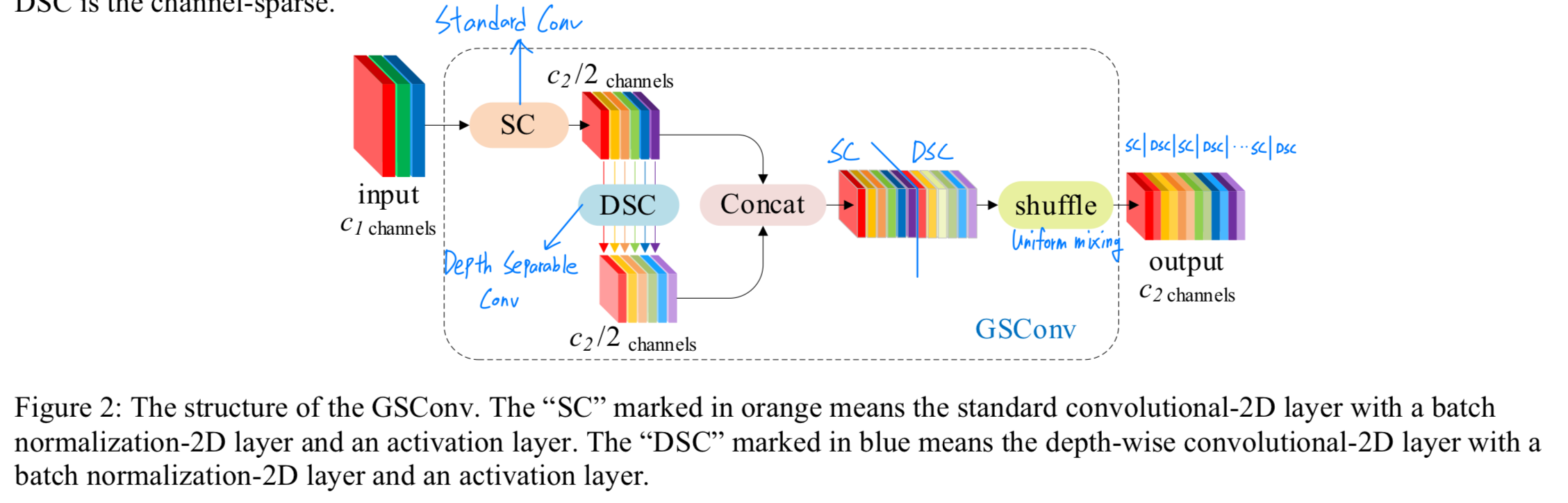
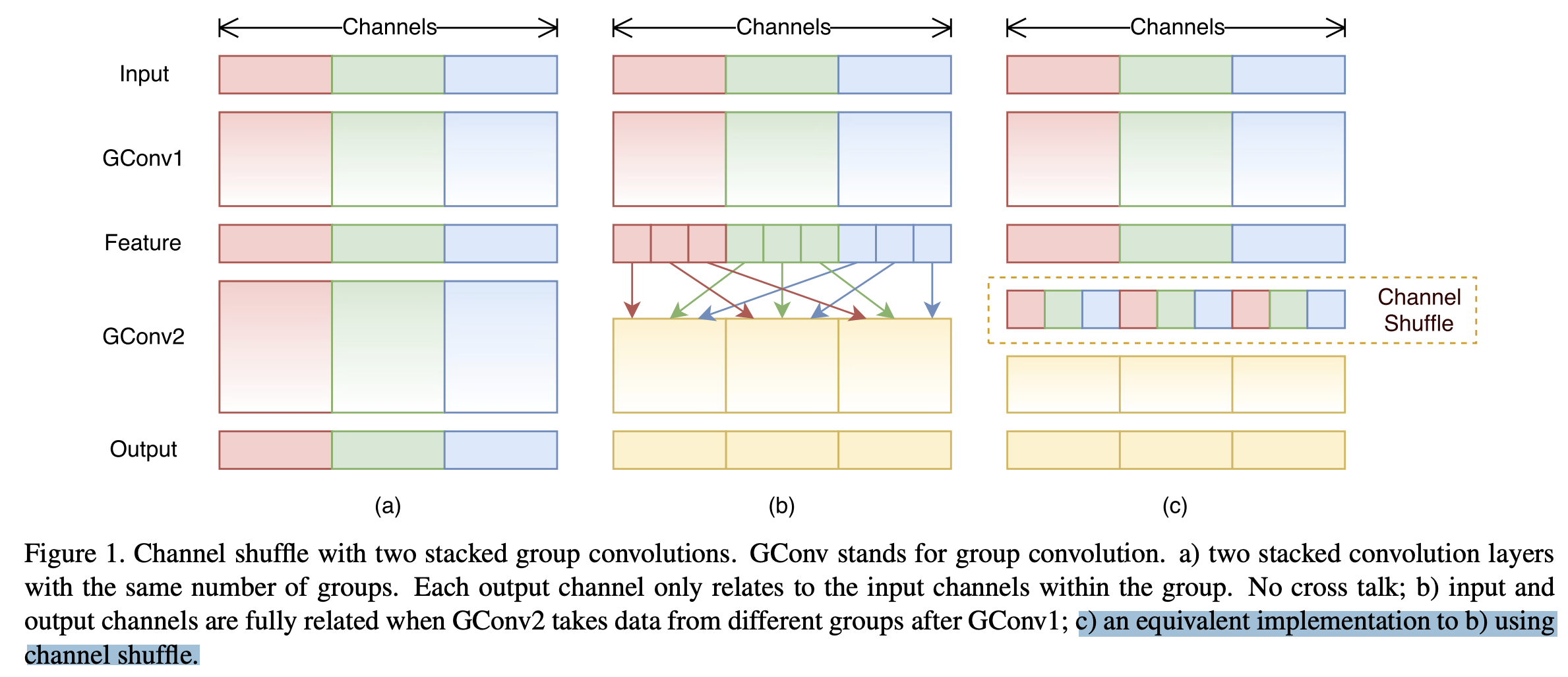
Figure 2에서 볼 수 있듯이, 우리는 shuffle을 사용하여 SC(channel-dense convolution)가 생성한 feature을 DSC가 생성한 특징의 모든 부분에 스며들게 한다.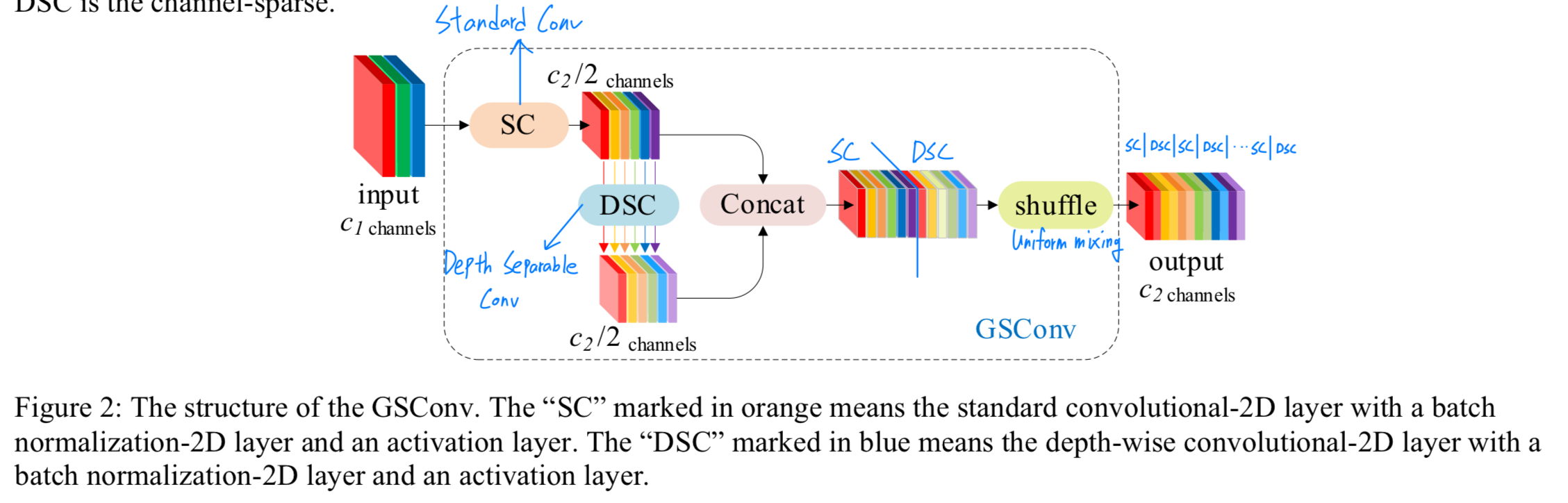 이 shuffle은 uniform mixing을 의미하며, 별다른 추가 작업 없이 SC의 정보가 DSC output에 완전히 섞이도록 하여 다른 channel에서 local feature information을 균일하게 교환할 수 있게 한다.
이 shuffle은 uniform mixing을 의미하며, 별다른 추가 작업 없이 SC의 정보가 DSC output에 완전히 섞이도록 하여 다른 channel에서 local feature information을 균일하게 교환할 수 있게 한다.
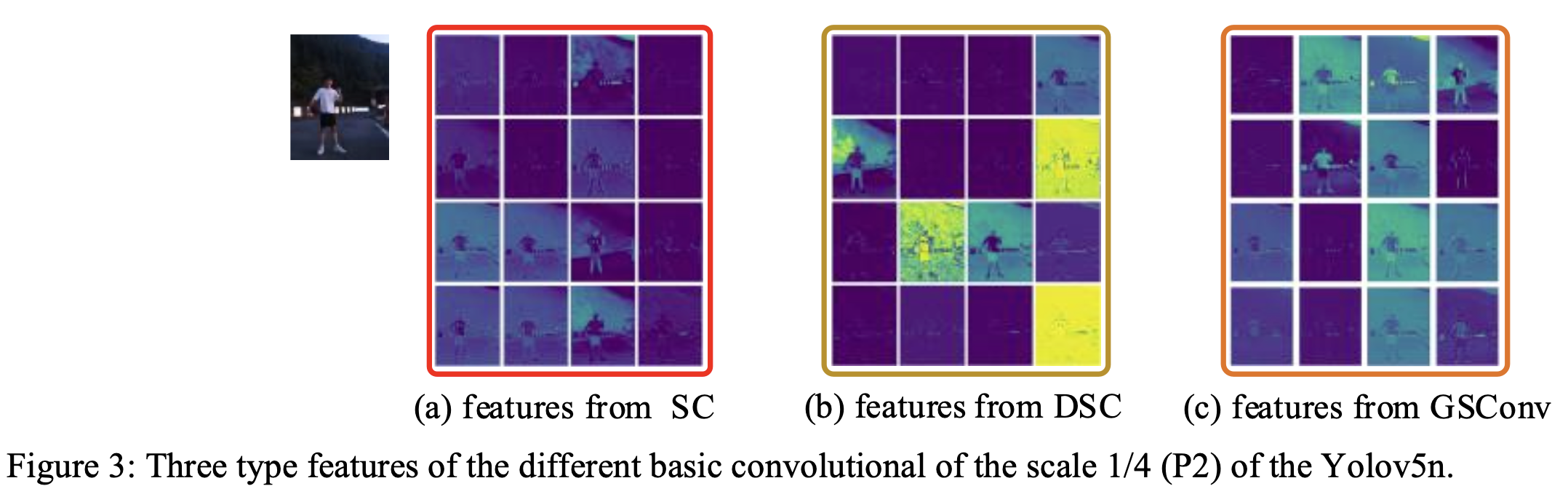
Figure 3은 SC, DSC, GSConv의 visualized features를 보여준다.
GSConv의 texture features는 DSC보다 SC와 더 유사하다.
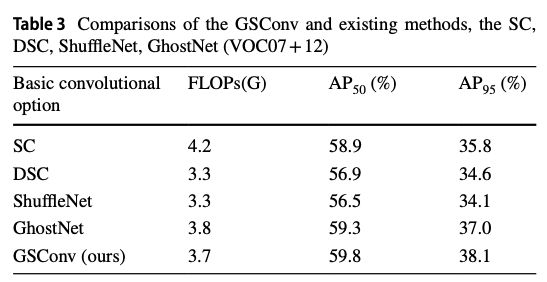
- Table 3는 다섯 가지 basic convolutional methods (SC, DSC, ShuffleNet method, GhostNet method and GSConv)가 model 성능에 미치는 기여도를 비교한 것이다.
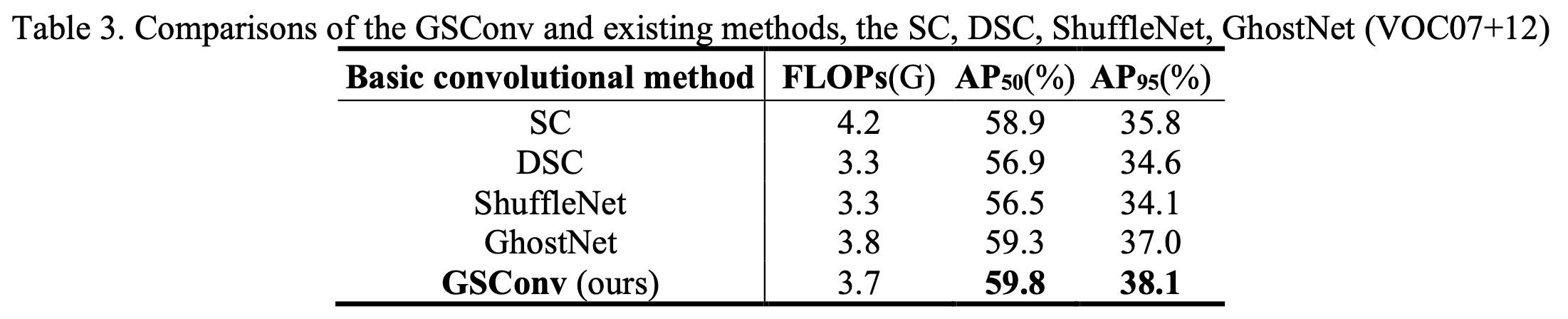
- Table 3는 다섯 가지 basic convolutional methods (SC, DSC, ShuffleNet method, GhostNet method and GSConv)가 model 성능에 미치는 기여도를 비교한 것이다.
-
우리는 GSConv에서 shuffle을 가능한 한 간단하게, 그리고 추가적인 FLOPs 없이 완료하고자 한다.
- 한 가지 option은 transposition 연산을 통해 feature를 균일하게 섞고 원래 size로 reconstruction하는 것이며[14],
이는 추가적인 FLOPs 없이도 가능한 방법이지만 일부 edge devices에서 지원되지 않을 수 있다.
(transposition 연산은 전체 channel을 g개의 group으로 나누고,
나눠진 group 내에서 transpose 연산을 통해 group 내에서 channel 간 위치를 교환한다.
그리고 나서 전치된 차원을 다시 원래의 형태로 재구성한다.)
- 또 다른 option은 linear operations을 shuffle task에 사용하는 것이며,
이는 비용이 적게 들고 표준적이고 모든 convolution 연산이 가능한 device에서 지원된다.
두 shuffle 방식의 성능에 대한 ablation study는 Table 4에 보고되어있다.

- 한 가지 option은 transposition 연산을 통해 feature를 균일하게 섞고 원래 size로 reconstruction하는 것이며[14],
-
GSConv의 장점은 lightweight detector에서 더욱 두드러지며,
이는 DSC layer와 shuffle을 추가함으로써 강화된 nonlinear operation 덕분이다.
하지만 GSConv를 model의 모든 stage에서 사용하면 network layer가 더 깊어지고,
deepr layer는 data 흐름에 대한 저항을 증가시켜 inference time을 크게 늘린다.
(내가 이해한 내용 : GSConv에서 SC도 하고, DSC도 하고, concat해서 shuffle도 함.
이는 작은 detector에서는 괜찮겠지만 큰 detector라면 network depth의 증가를 무시할 수 없음)
이러한 feature map이 neck으로 들어오면 이미 충분히 가늘어졌으며(channel dimension이 maximum에 도달하고 width와 height diension이 minimum에 도달), transformation도 완만해진다.
따라서 더 나은 선택은 GSConv를 neck에만 사용하는 것이다(slim neck + standard backbone).
이 stage에서 GSConv를 사용하여 concatenated feature maps을 처리하는 것이 적절하다 : redundant repetitive information(중복된 반복 정보)가 적으며 압축이 필요 없고, SPP나 CA 같은 attention works에 더 잘 작동한다.
3.2 VoV-GSCSP block
- GSConv의 computational cost는 SC의 약 50%이며, 자세한 내용은 Appendix에 나와 있지만 model learning ability에 대한 기여도는 SC와 비교할 만하다.
GSConv를 기반으로 우리는 GS bottleneck을 도입했으며, 해당 구조는 Figure 4 (a)에 나와 있다.
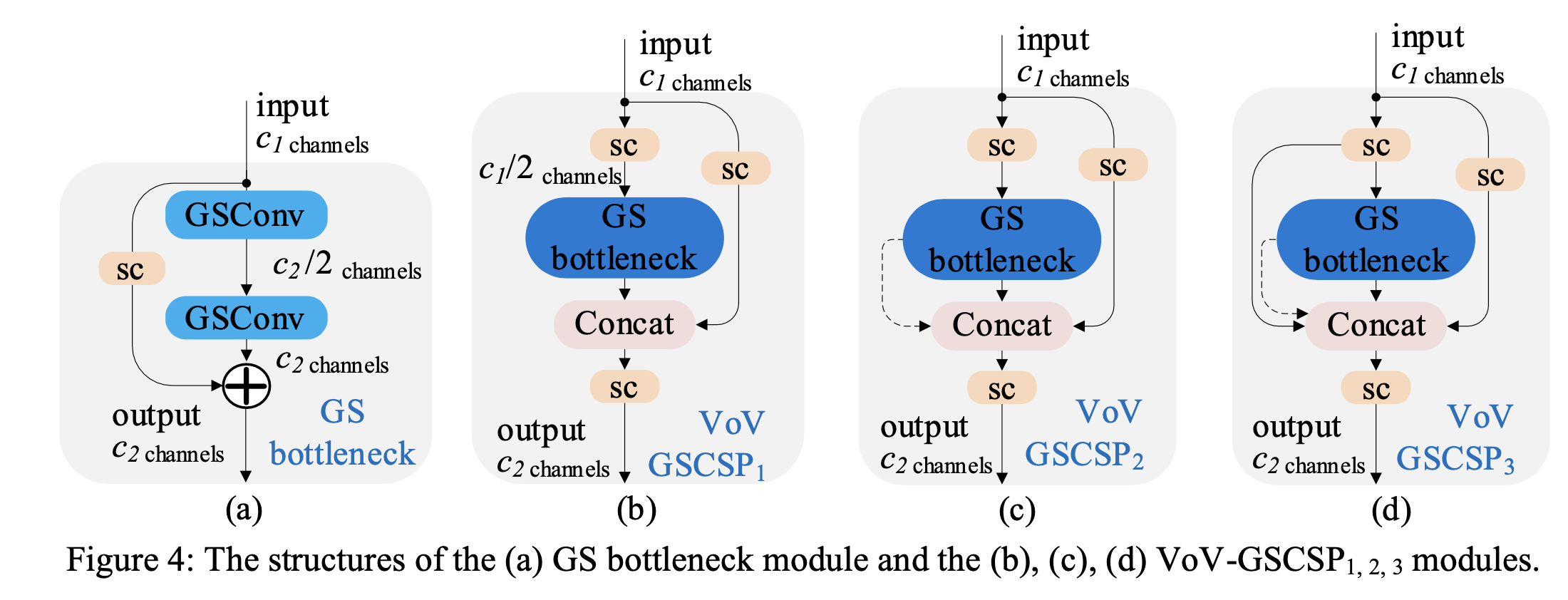 이후 CNN의 learning ability를 향상시키기 위한 일반화된 방법을 조사했고,
이후 CNN의 learning ability를 향상시키기 위한 일반화된 방법을 조사했고,
one-shot aggregation 전략을 사용하여 cross stage partial network(CSP) module, 즉 VoV-GSCSP를 설계했다.
이를 통해 computational complexity와 inference를 줄이면서도 accuracy를 유지할 수 있다.
-
Figure 4 (b), (c), (d)는 각각 VoV-GSCSP의 세 가지 design structures를 보여주고 있으며,
(b)구조는 단순하고 직관적이며 더 빠른 inference가 가능하다.
반면 (c)와 (d) 구조는 더 높은 재사용률을 가지고 있다.
실제로 HW 친화적 특성 때문에 더 단순한 구조(b)가 더 자주 사용된다.
-
Table 5에서는 VoV-GSCSP1, 2, 3의 세 가지 구조에 대한 상세한 ablation study 결과를 보고하고 있으며,
VoV-GSCSP1가 더 높은 performance-to-price ratio(성능 대비 비용 비율)를 보인다.

3.3 Free improvement tricks for lightweight models
-
feature enhancement 기법 및 vision의 attention mechanism은 단순한 구조와 낮은 computational cost로도 detection 성능을 향상시킬 수 있다.
이러한 방법들은 channel 또는 spatial dimension의 특정 features-weights를 강화한다.
예를 들어, SPP(Spatial Pyramid Pooling)은 4개의 parallel branches, 3개의 max pooling operations(kernel size 5x5, 9x9 and 13x13)과 input의 shortcut을 연결하여
더 큰 spatial receptive field를 capture한 후, point-wise conv layer를 사용하여 spatial features-weight를 융합하고 재조정한다.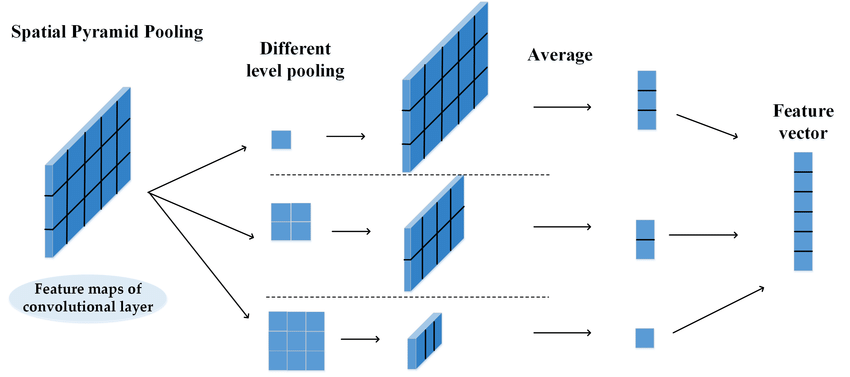
-
제안으로는 backbone의 끝 부분에 attention module을 삽입하여 더 나은 결과를 얻는 것이며,
간단하지만 효과적인 SPP를 직접적으로 head의 초입에 삽입할 수 있다.
그 이유는 shallow networks에서는 low-level semantic information이 넘쳐나기 때문에,
attention module의 information fusion function이 거의 사용되지 않기 때문이다.
이미 풍부한 low-level semantic information을 포함하는 feature를 굳이 융합할 필요가 없다는 것이다.
내가 이해한 내용
구조가 단순하고 계산 비용이 낮은 detector에서 vision attention mechanism을 통해 feature enchancement를 할 수 있다.
이 방법은 channel 또는 spatial dimension의 특정 feature-weights를 강화할 수 있다.
한가지 제안은 backbone의 끝 부분에 attention module을 삽입해야 더 나은 결과를 얻는 것이다.
shallow networks의 경우 맣은 양의 low-level semantic information들이 흐르고 있기 때문에 attention modules의 information fusion 기능이 minimize된다. (너무 의미없는 정보들이기 때문에 fuse할 필요가 없음...)
그래서 그나마 가장 high-level semantic information을 담고 있는 backbone의 끝 부분에 attention module을 삽입하는 해야 효율이 극대화 된다.
4 Experiments and analysis
4.1 Data sets
- VOC07+12
- WiderPerson
- we use the SODA10M [45] to test the real-world performance of these models in a traffic environment.
4.2 Ablation studies
궁금한 점
- GSConv에서 "GS"는 뭐의 약자이지?
