[2024 ECCV] (SlimNeckV2) Rethinking Features-Fused-Pyramid-Neck for Object Detection

Info.

Abstract
-
Multi-head detectors는 multi-scale detection을 위해 a features-fused-pyramid-neck을 사용하며, 이는 널리 채택되고 있다.
-
그러나, 이 approach는 서로 다른 hierarchical levels에서 얻은 representations을 forcibly(강제로) point-to-point fused하여 결합할 때, feature misalignment 문제가 발생한다.
-
(그러면 feature fusion을 안하면 어떨까?)
그래서 우리는 features-unfused-pyramid-neck의 effectiveness를 평가하기 위해 independent hierarchy pyramid (IHP) architecture를 design했다.
-
이후, 서로 다른 hierarchies 간 feature fusion으로 인한 영향을 완화하면서도 key textures를 보존할 수 있도록
weight-downscaling factor를 적용한 soft nearest neighbor interpolation (SNI) 기법을 도입했다. -
또한, Extended spatial windows (ESD)에서의 downsampling을 위한 a feature adpative selection method를 제안하여 spatial features를 보존하고,
lightweight convolutional techniques (GSConvE)를 향상시켰다.
1. Introduction
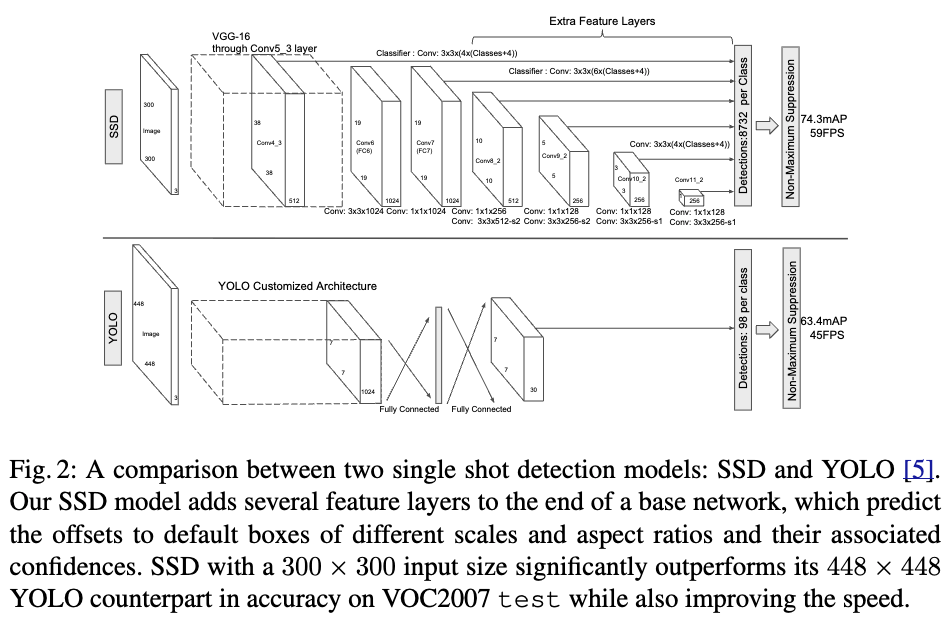
Early DL-based object detection models (YOLO vs. SSD)
(초기 real-time OD YOLO는 multi-scale detection을 고려하지 X)
- YOLO는 the first real-time deep learning-based object detection model이고,
multi-scale detection을 고려하지 않은 간단한 structure이다. (Fig. 1 (b))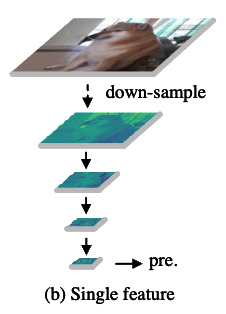
(아래 yolov1 architecture figure 출처: https://arxiv.org/pdf/1506.02640)

(그 이후 SSD는 real-time multi-scale OD를 고려)
- SSD는 RCNN과 YOLO의 강점을 combined하여, the concept of multi-scale detection을 강조함.
구체적으로, SSD는 objects of varying scales을 predict하기 위해
VGG-16 backbone으로부터 feature maps of different scales을 활용하였음.(Fig. 1 (c))
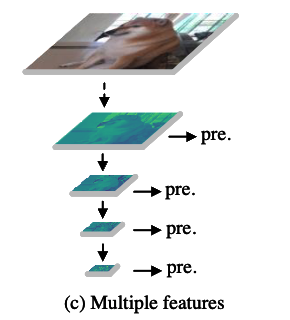
(YOLO vs. SSD)
(그림 출처: https://arxiv.org/pdf/1512.02325)
early deep learning-based object detection models provided an important insight to the field:
the efficient utilization of multi-scale features is crucial for enhancing the overall performance of detectors.
feature pyramid-based multi-scale feature fusion
- SSD 이후로 multi-scale features는 detectors의 성능 향상에 중요한 역할을 한다는 insight가 확립되어,
FPN은 the feature pyramid-based multi-scale feature fusion concept을 제안했다.
FPN은 PANet, ASFF, BiFPN, and FRPN과 같이, multi-scale feature fusion을 강화하는 representative works를 이끌며
real-time detectors의 performance를 향상시켰다.

feature fusion network의 복잡성 증가 문제
- 그러나, 이러한 techniques의 complexity가 증가함으로 인해 추가의 발전이 어려워지고 있다.
FPN 도입 이전에는 structures without fusion에 의존했었다.
FPN의 도입 이후에는 FPN-based paradigms으로 바뀌고 있다.It is important to note that the FPN-like strategy should not be considered an obligatory component for all detectors.
inherent representation biases in feature maps at different hierarchical levels
- FPN-like paradigm 안에서, 서로 다른 hierarchies와 서로 다른 resolutions을 가진 feature maps을
element level (point-to-point)에서 combine하며,
이를 위해 low-resolution이면서 high-level feature maps을 expansion하여 low-level feature map과 resolution을 match하는 작업이 필요하다.
그러나 서로 다른 각 hierarchical levels의 feature maps에는 inherent(고유한) representation biases를 갖는 특성이 있다.
low-level feature maps은 small objects의 representations (local features in small receptive fields)에 유리한 반면,
high-level feature maps은 large objects의 representations (global features in large receptive fields)에 적합하다.
이와 같은 representation bias를 갖는 feature maps을 direct(직접) element-level fusion을 하면,
partial destruction of representations (representations의 부분적 손상)의 가능성이 있으며,
fusion 과정에서 feature misalignment problem이 더욱 심화될 수 있다.
(부가적 기술) we enhance the lightweight conv technique of the GSConv
- FPN의 initial purpose는 단순히 multi-scale detection을 위해 feature fusion의 장점을 활용하는 것뿐만 아니라,
model complexity를 적절하게 줄이는 것도 포함되어 있다.
limited HW resources를 갖는 industries에서는, complex models이 impractical하다는 문제가 제기된다.
따라서, 우리는 GSConv의 lightweight conv technique을 개선하여 real-time detection models을 위한
preferable trade-off between acc and speed를 달성하도록 했다.- 이 저자는 아래 논문(https://arxiv.org/pdf/2206.02424)의 저자이다.
아래 논문은 GSConv로 구성된 Slim-neck을 제안한 논문이다.
저자는 이 논문을 Slim-neckV2(저자의 github repo. 참고)라고 부르며, V1의 GSConv 기술을 더 발전시켰다.
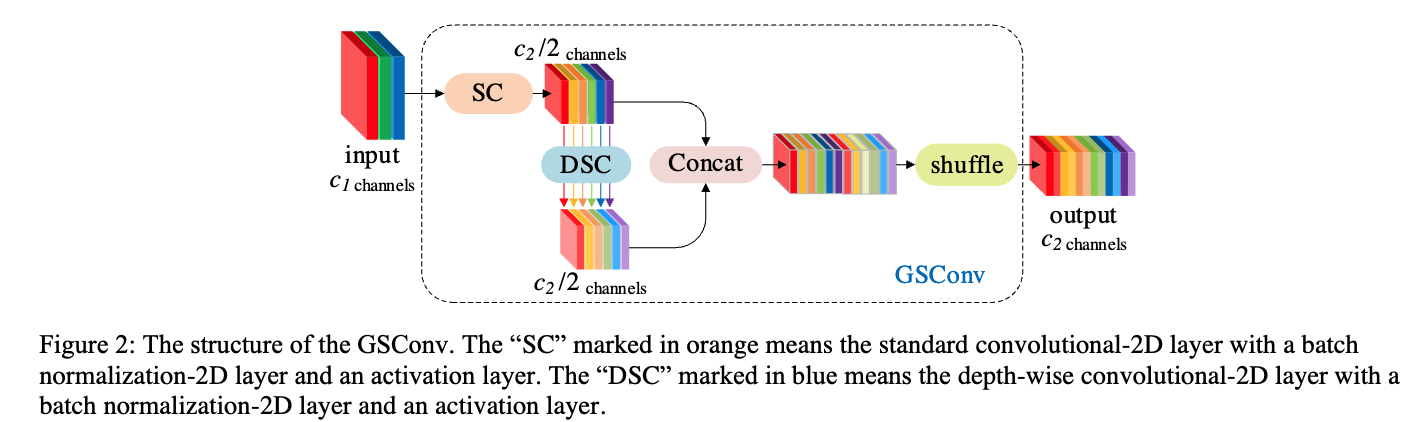


- 이 저자는 아래 논문(https://arxiv.org/pdf/2206.02424)의 저자이다.
Contributions
- The main contributions of this work can be summarized as follows:
- We rethink the effectiveness of FPN-like paradigms for modern real-time detectors based on representation learning
and identify issues with feature misalignment during element-level fusion. - We design an independent hierarchy pyramid architecture (IHP) without feature fusion in the neck to validate our findings.
And the IHP achieves advanced results. - We introduce soft nearest neighbor interpolation (SNI) for up-sampling to mitigate feature misalignment during fusion.
- We provide a feature adaptive selection method in extended spatial windows for downsampling (ESD) to enhance spatial feature retention during the downsampling stage.
This method is plug-and-play and optimizes performance at a low cost. - We simplify and enhance the GSConv lightweight convolution (GSConvE) to offer more cost-effective options for models operating on edge devices with resource constraints.
- We validate our approaches on Pascal VOC and COCO and present the SA solution.
Existing lightweight real-time detection models can be optimized with the SA solution without bells and whistles.
(SA solution은 Secondary features Alignment 줄임말인듯.
SA solution은 IHP, SNI, ESD, GSConvE를 포함하는 듯.)
- We rethink the effectiveness of FPN-like paradigms for modern real-time detectors based on representation learning
2. Related Work
2.1 Multi-head detection and features fusion
(single-scale prediction)
- The first-generation general detection models은 두 가지 main components: the backbone and the detecting-head로 구성되었다.
이러한 model들은 보통 prediction을 위해 final feature maps을 사용했다.
(multi-scale prediction)
- SSD는 the use of multi-level feature maps을 제안했다.
The key advantage of the multi-head detection method는
varying receptive fields를 갖는 feature maps을 사용하여 서로 다른 scales의 objects를 predict하는 ability이다.
(feature fusion method)
- FPN introduced a fusion scheme for multi-level feature maps to enhance detection accuracy,
setting the trend for feature fusion and becoming a common practice.
This led to the development of Backbone-Neck-Head architectures.
More complex variants based on FPN, such as BiFPN [34] and PANet [24], have since been proposed, enabling the use of more features for prediction.
However, as prediction accuracy improved, networks became increasingly complex due to additional fusion layers.
(feature fusion 없는 multi-scale detection 연구의 현실)
- 그래서 몇 연구들은 optimizing multi-scale training strategies or using dilated convolutions to capture multi-scale receptive fields와 같이 multi-scale detection challenges를 위해 new perspectives를 탐구해왔다.
하지만 classification-backbone의 feature extraction 능력이 지속적으로 optimized되고, feature fusion 기술이 발전함에 따라 점차 경쟁력을 잃고 있다.
2.2. Lightweight
- Direct lightweight approaches include reducing the depth (number of layers) or width (number of neurons/filters) of the model, as seen in models like YOLO-fast/tiny/nano [1,14–16,31,35].
However, low-depth networks often suffer from underfitting due to insufficient nonlinear representation capabilities.
Therefore, reducing the number of network layers may not always be a cost-effective way to lighten the model.
3. Secondary Features Alignment Solution (SA)
- Key contents of this work are described in detail in this section.
Specifically, there are the IHP structure to directly demonstrate features unalignment problem by abandoning fusion,
the SNI to alleviate unaligned during features fusion by point-to-point,
the ESD to enhance spatial-features capture during the downsampling stage,
and the GSConvE to improve the performance between the accuracy and speed of lightweight models.
3.1. Independent hierarchy pyramid architecture (IHP)
-
FPN은 real-time detectors에 feature fusion의 realm을 가져다 줬다.
-
하지만, 우리는 point-to-point fusion of different level features로부터 중요한 issue를 확인했다 - partial local features become unaligned.
이러한 fusion process는 unaligned features를 combined할 때 noise를 추가하는 것과 유사하며,
target space와 irrelated (무관한) features가 forcibly (강제로) integrated되면서 spatial disarray가 초래된다.
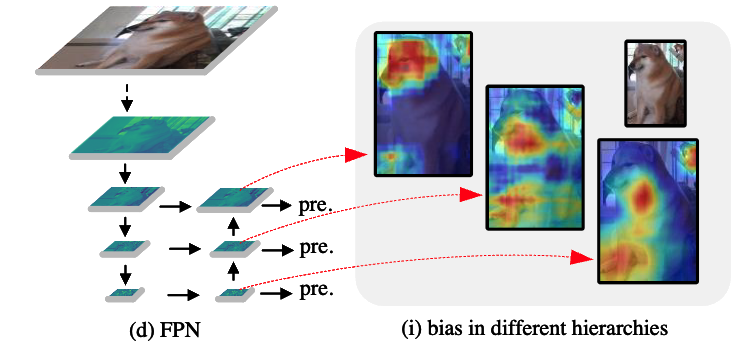
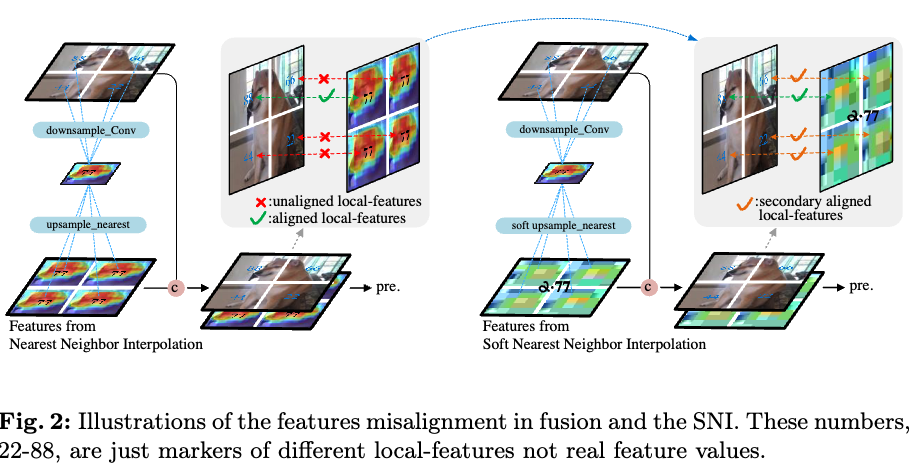
Fig.2에서 보여지듯이 puppy의 머리-feature를 엉덩이 부분에 추가하면, detection head에 입력될 때 정의되지 않은 새로운 breed (종)을 만들어낸다.
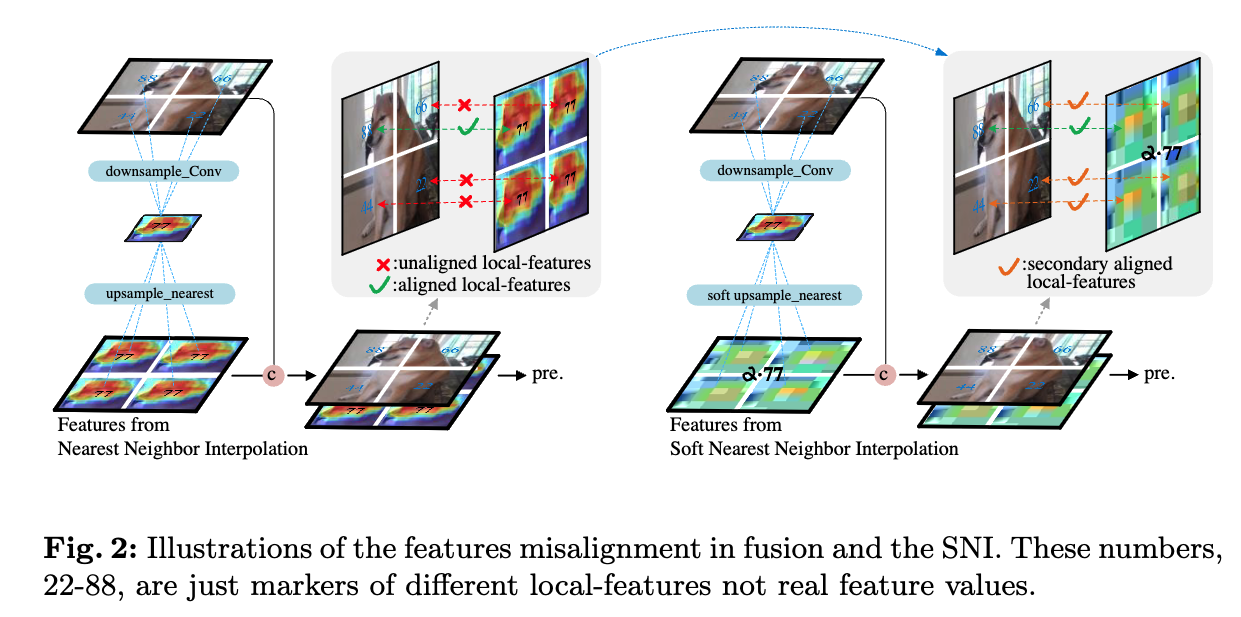
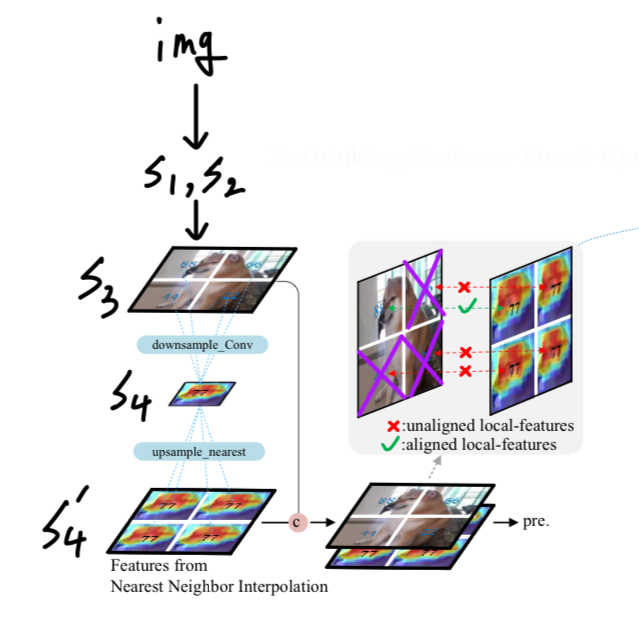
일반적으로, high-level feature maps을 low-level feature maps과 match시키기 위해 nearest neighbor interpolation이 사용 (upsampling)되며,
이후 element-wise addition, channel concatenation, weighted sum 등의 방법을 통해 fusion이 이루어진다.
그러나, downsampling은 nonlinear and irrevisible (비가역적)이므로,
upsampling을 통해 생성된 추가의 features들 간의 spatial features에 inconsistencies를 갖는다
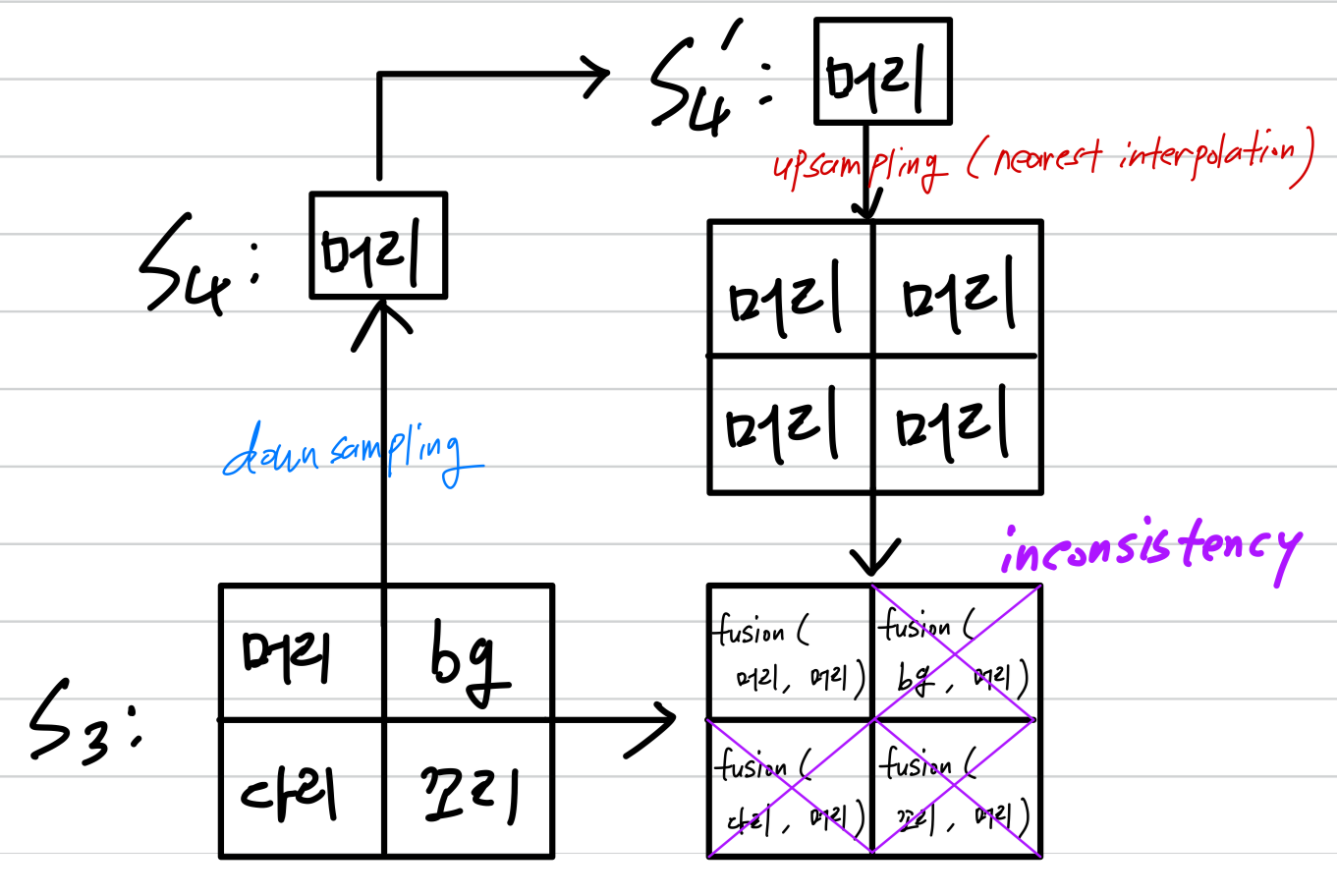
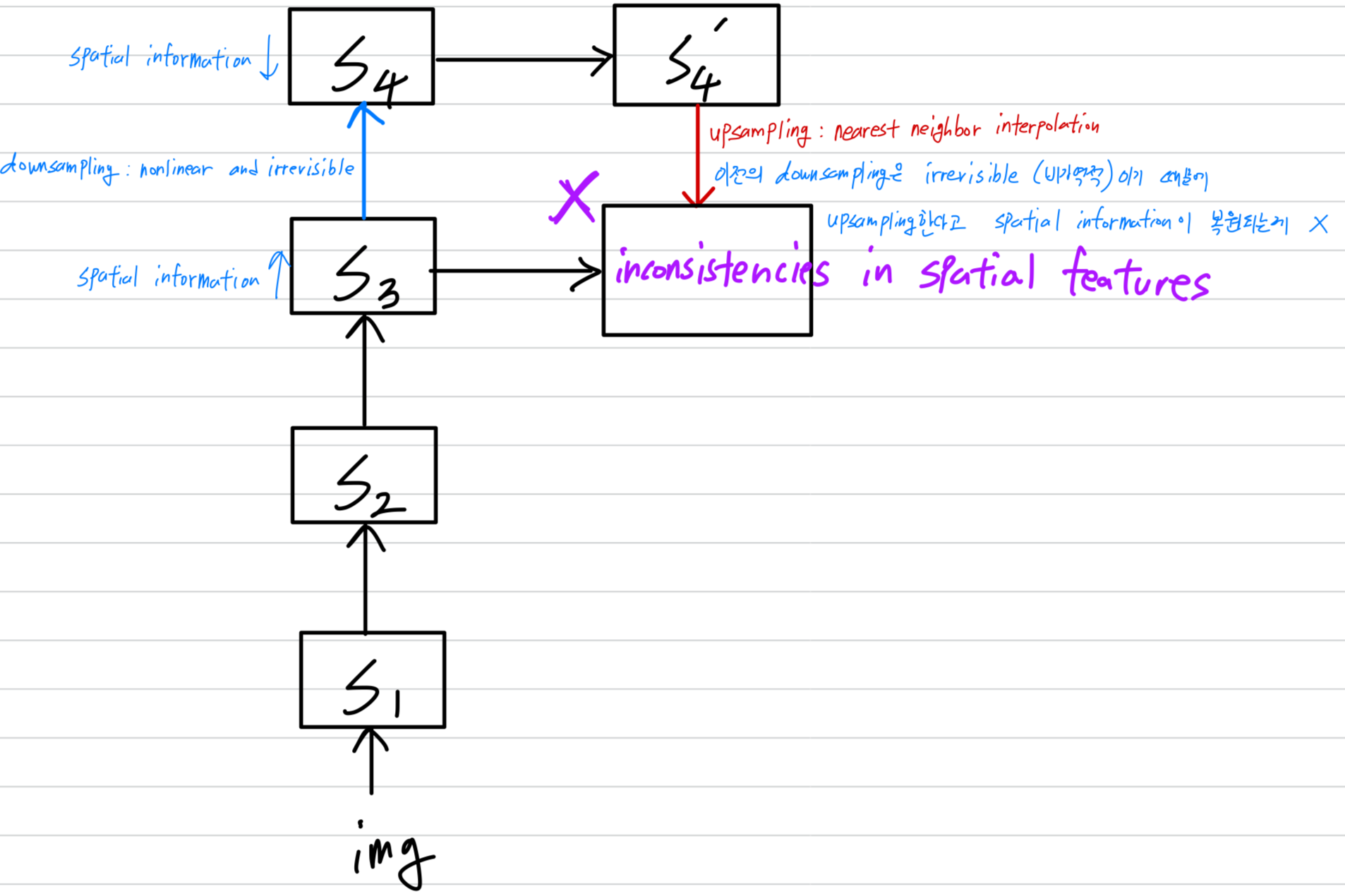
- IHP는 neck에서 모든 feature fusion을 제거하는 approach를 채택하여
근본적으로 feature misalignment problem을 회피하고 구조를 간소화했다.
또한, multi-head detection 방식의 inherent(고유한) benefits을 활용하여
서로 다른 levels의 feature map을 사용하여 다양한 크기의 objects를 직접 예측한다.
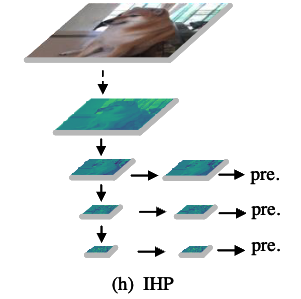
- 중요한 점은 IHP와 SSD architecture 사이에 큰 차이가 있다는 것이다.
SSD는 backbone의 서로 다른 level에서 직접 feature를 사용하여 object를 탐지하는 반면,
IHP는 예측 전에 bottleneck conv module을 도입하여 feature를 filtering한다.
이 approach의 이점은 model이 특정 scale branch에 대한 feature를 독립적으로 학습할 수 있도록 하여, 다른 levels의 feature에 영향을 주지 않는다는 점이다.
backbone의 서로 다른 levels에서 conv block을 직접 stacking하면 level 간 interference (방해)가 발생할 수 있으며,
이는 very deep backbone을 사용한 OD models의 성능이 저하되는 주요 원인일 수 있습니다. (예시 생략)- SSD는 (c)처럼 서로 다른 levels의 feature를 "직접" 사용
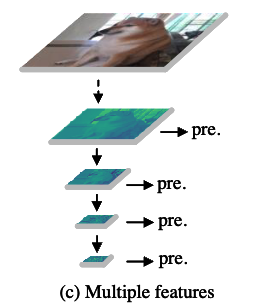
- IHP는 (h)처럼 서로 다른 levels의 feature에 대해 각각 filtering하는 "conv module 도입"하여
서로 다른 branch에 대한 feature를 독립적 학습하여 레벨 간 간섭을 줄이는 것을 목표로 함.
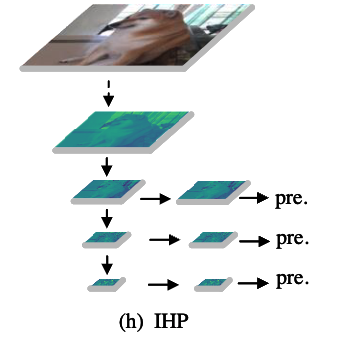
- SSD는 (c)처럼 서로 다른 levels의 feature를 "직접" 사용
-
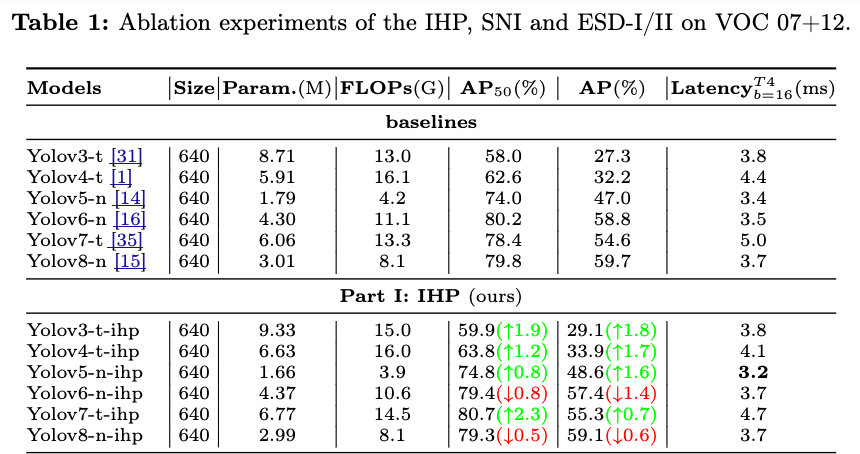
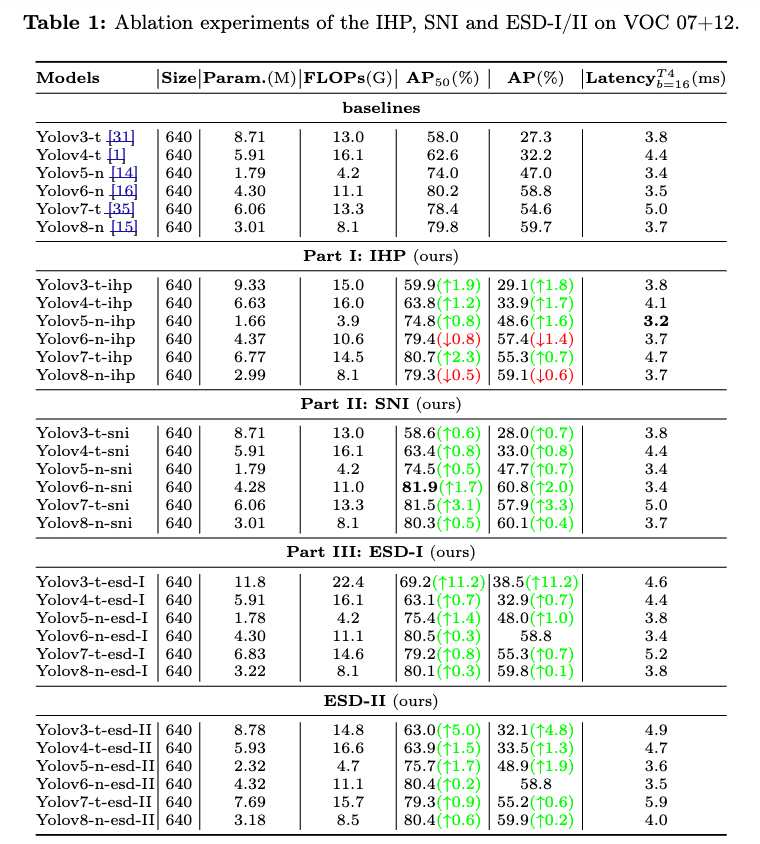
Table 1의 Part I에서, IHP를 적용했을 때 coupled-head YOLOs에서 성능이 향상된 것이 확인되었다.
 일반적인 feature fusion 기법은 prediction을 위한 semantic richness를 강화하는 과정에서 noise를 유입할 가능성을 간과하는 경우가 많다.
일반적인 feature fusion 기법은 prediction을 위한 semantic richness를 강화하는 과정에서 noise를 유입할 가능성을 간과하는 경우가 많다.
반면, IHP는 semantic information을 다소 줄이는 것처럼 보일 수 있지만,
multi-head detection의 장점을 효과적으로 활용하여 misalignment problem 문제를 회피할 수 있다.
이러한 strategic utilization이 IHP가 경쟁력 있는 results를 달성할 수 있었던 key factor이다. -
그러나, IHP는 localization-classification-coupled head detectors (통합형)에서는 긍정적인 성능 향상을 보였지만,
localization-classification-decoupled-head detectors (분리형)에서는 동일한 효과를 얻지 못했다.- coupled-head :
서로 다른 목적, classification과 regression을 동일한 layer를 사용하여 예측.
서로 다른 목적을 가진 작업을 하나의 공유된 layer를 통해 강제로 융합하는 것과 유사함. - decoupled-head:
classification과 regression 작업을 separate branchs를 통해 예측.
중복된 features로부터 유용한 representation을 "독립적"으로 학습.
- coupled-head :
-
Decoupled-head detectors는 coupled-head detectors가 직면하는 주요 문제
(classification and localization tasks의 목표로 서로 다름에도 불구하고 동일한 layer에서 prediction을 수행해야 한다는 한계)
를 극복할 수 있다.
이를 통해 redundant features로부터 beneficial representations을 학습할 수 있으며, 이는 coupled-detector에서는 불가능한 방식이다.
따라서 FPN strategies는 어느 정도 decoupled-head detectors에 적용될 수 있지만,
feature misalignment problem은 여전히 해결해야 할 과제로 남아 있다. (?)
이해가 안되는 점:
feature fusion할 때, feature misalignment를 해결하기 위해 IHP를 썼다.
= 아예 fusion을 하지 않겠다.
coupled에서는 성능이 향상되었다.
= coupled에서는 feature fusion 내 feature misalignment가 성능에 악영향을 주고 있었다.
decoupled에서는 성능이 하락되었다.
= decoupled에서는 feature fusion 내 feature misalignment가 있더라도 성능에 좋은 영향을 주고 있었다.
내가 해석한 결론,
- coupled detectors에서는 feature misalignment가 성능에 안좋은 영향을 끼치고 있다.
head에서 같은 layer로 다른 task를 prediction하기 때문에 feature misalginment는 결과에 악영향을 주기 더 쉽다. - decoupled detectors에서는 feature misalignment가 있더라도 fusion함으로써 semantic information이 더 강화되기 때문에,
이는 head에서 독립된 class and reg branch가 필요한 정보를 알아서 잘 뽑아내어 성능에 좋은 영향을 끼친다.
그래서 feature misalignment in spatial feature가 있더라도 fusion이 필요하다.
3.2. Soft nearest neighbor interpolation (SNI)
-
detection or segmentation models에서,
서로 다른 level의 feature fusion은 보통 nearest neighbor interpolation이나 transposed convolution을 이용한 up-sampling 이후에 발생한다.
하지만 detection or segmentation에서 up-sampling의 결과인 resolution expansion은
generation or super-resolution과 같은 tasks와는 상당히 다르다. -
detection에서, expaneded feature maps은 raw image detail information 보다 abstract high-level semantic features를 represent한다.
Transposed convolution은 increased computation and latency를 유발한다.
the speed of nearest neighbor interpolation을 유지하면서 minimal cost로 feature misalignment problem을 다루기 위해서, 우리는 solution을 탐구한다.
-
Nearest neighbor interpolation은 average unpooling과 유사하지만, "hard" operation으로 간주된다.
우리는 이 연산을 SoftMax가 Max 함수로 변환되는 방식과 유사하게 softening하게 만들어, "hard" feature misalignment issue를 완화하고자 한다.
이를 위해 up-sampling 과정에서 nearest neighbor interpolation에 soft factor 를 도입한다.- 여기서, "hard" operation이란?
high resolution feature map의 각 위치에 대해 가장 가까운 low resolution feature map의 값을 단 하나 선택하여 그대로 복사.
이 과정에서 주변의 다른 값들은 전혀 고려하지 않고, 오직 가장 가까운 neighbor 값으로만 결정됨.
이는 주변 정보를 "soft"하게 통합하는 것이 아니라, 하나의 값을 경계 없이 확장하는 방식.
따라서 upsampling된 feature map에서, 셀 간의 경계에서는 갑자기 값이 급격하게(not soft) 변화.
이러한 급격한 변화는 feature map을 "soft"하지 않게 만들며, 이는 후속 연산 (feature fusion)에서 문제 (feature misalignment)를 유발시킬 수 있음.
(아래 그림 출처)
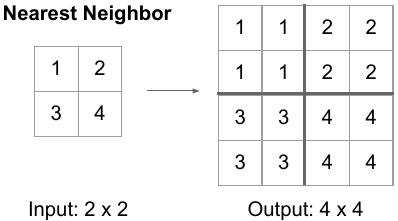
- 여기서, "hard" operation이란?
-
Eq. (1)에서, the resolution of the high-level feature maps 과 low-level feature maps 는 and 로 각각 denoted되었다.
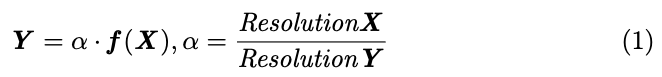
로 represented된 nearest neighbor interpolation operation은 Fig.2.에 나와있다.
-
SNI(Soft Nearest Neighbor Interpolation)은 feature map의 zoom factor에 따라 high-level semantic features가 low-level features에 미치는 영향을 조정한다.
구체적으로, zoom factor가 증가할수록 high-level semantic features가 low-level features에 미치는 영향이 약해진다.
SoftMax와 달리, SNI는 outputs을 probabilities로 변환하지 않으며,
high-level features와 low-level features를 point-to-point fusion 방식으로 융합할 때 additional cost 없이 misalignment를 완화한다. -
SNI는 key textures를 보존하면서 feature weights를 부드럽게 조정하여 서로 다른 hiearchical levels의 features가 fusion될 때,
mutual influence (상호 영향)을 줄이고, 이는 Fig. 3에서 qualitatively(정성적으로) 증명되었다.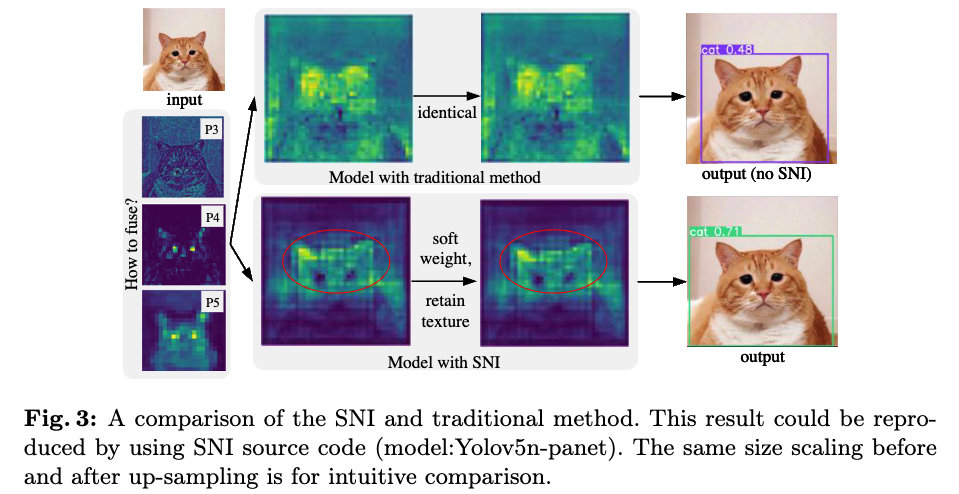
-
이러한 approach는 Secondary (auxiliary) features alignment (SA)를 달성하여 model이 fused representations에서 학습하는 complexity를 낮춘다.
반면, traditional methods는 서로 다른 hierarchical levels의 features를 직접 merge함으로써 representation biases로 인해 unstable competitive effects를 유발할 수 있으며, 이는 model의 learning difficulty를 증가시킨다.
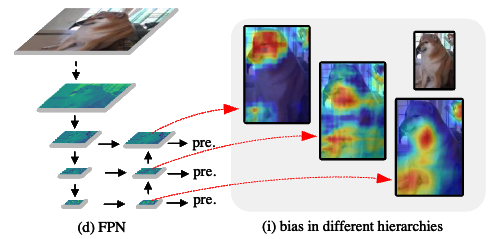
- 예를 들어, Fig. 1 (i)에 있는 세 개의 heatmap을 직접 fuse한다고 할 때,
red 영역이 전체 image를 cover해야 한다고 물으면, 그 답은 'no'이다.
만약 이러한 상황이 발생한다면, 이는 prior feature extraction이 실패했음을 의미한다.
model의 목적은 useful features를 capture and focus하는 것이기 때문이다.
이러한 이유로, FPN-like paradigm을 따르는 model들은 feature를 fusion한 후 predictin 하기 전에 several additional conv blocks을 사용하여 더 filtering해야 한다.
- 예를 들어, Fig. 1 (i)에 있는 세 개의 heatmap을 직접 fuse한다고 할 때,
-
https://github.com/AlanLi1997/rethinking-fpn/blob/main/slimneck_v2/for_yolo/sn2-yolov5-v8/ultralytics/nn/modules.py
코드를 살펴보면, upsampling할 때 interpolation의 upsampling factor가 보통 2이므로
SNI class의 __init__() constructor의 up_f argument의 default값이 2로 설정된 것을 알 수 있다.

궁금한 점:
- interpolation을 nearest 말고, bilinear처럼 좀 더 smooth(soft)하게 upsampling하는 interpolation을 사용하면 완화되지 않으려나?

3.3 Feature adaptive selection in extended spatial windows
-
vision models based on DL에서, feature downsampling은 critical technique이다.
model은 일반적으로 prediction을 위해 low-resolution, high-level feature maps에 의존한다. -
하지만 excessive(지나친) downsampling은 significant loss of spatial details를 유발한다.
최근의 detectors는 일반적으로 downsampling 횟수를 최대 5회 이하로 제한하는 경향이 있으며,
이로 인해 spatial resolution reduction이 배 감소한다.
이러한 경향은 YOLOs 및 Swin Transformer에서도 확인할 수 있다.
일반적인 downsampling 방법으로는 conv와 pooling이 있으며, 대부분의 model은 이 중 하나만 사용한다. -
우리는 spatial information retention(보존) capabilities를 향상시키기 위해
the feature adaptive selection method in Extended Spatial windows for Downsampling (ESD)을 제안한다.
ESD는 two non-linear branches와 one linear branch로 구성된다.
nonlinear branches에서는 a norm conv layer와 extended window max-pooling layer가 local feature capturing을 강화하고,
extended window average-pooling이 global feature capturing을 강화한다.
이후 linear features를 nonlinear features와 merge한다.
-
우리는 lightweight and norm models을 위한 two fusion modes, ESD-1 and ESD-2을 design했다.
이 두 model의 차이는 feature fusion stage에서 발생하며, Fig. 4에 도식화됐다.

- ESD-1: element-wise addition을 사용하여 feature를 merging하며,
computational cost가 낮아 lightweight models에 적합하다.

- ESD-2: learnable linearly adaptive fusion을 사용하여 computational cost가 약간 증가하지만, norm(표준) models에 suitable하다.

- ESD-1: element-wise addition을 사용하여 feature를 merging하며,
-
중요한 점은,
extended window의 local and global features를 simple pooling techniques으로 sampling하여 input information을 상당 부분 preserving할 수 있다는 것이다.
이를 통해 downsampling 시 information loss를 줄이고, 다음 layers가 previous layers의 일부 representations을 학습할 수 있도록 한다.
이는 ResNet의 hidden shortcut connecion을 간접적으로 구현한 것과 유사한 역할을 수행한다.
3.4 Lightweight GSConv enchancement
-
GSConv는 vanilla conv와 depth conv로부터 섞인 features에 의해
depthwise separable conv의 the channel interaction limitations을 다루도록 소개되었다.
(과거 GSConv 논문 리뷰한 글: https://velog.io/@hseop/Slim-neck-by-GSConv-A-lightweight-design-forreal-time-detector-architectures)
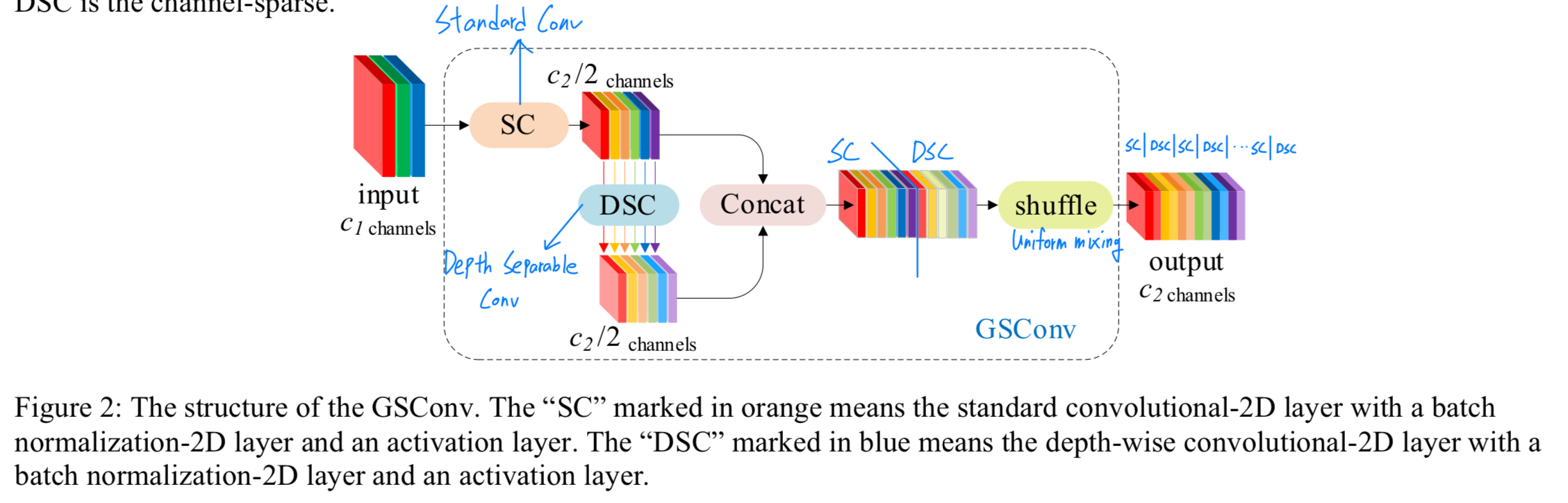
-
GSConvE-1는 norm model을 위해 설계됨.
auxiliary branch에서 intermediate feature maps은 dense linear mappings을 통해 유도되고,
(코드에서 self.cv2의 첫번째 conv layer = 1x1 conv)
output feature maps은 sparse linear mappings에서 발생한다.
(코드에서 self.cv2의 두번째 conv layer = grouped conv)- 이 접근법은 computational cost를 증가시키지 않고 feature richness를 유지시킨다.

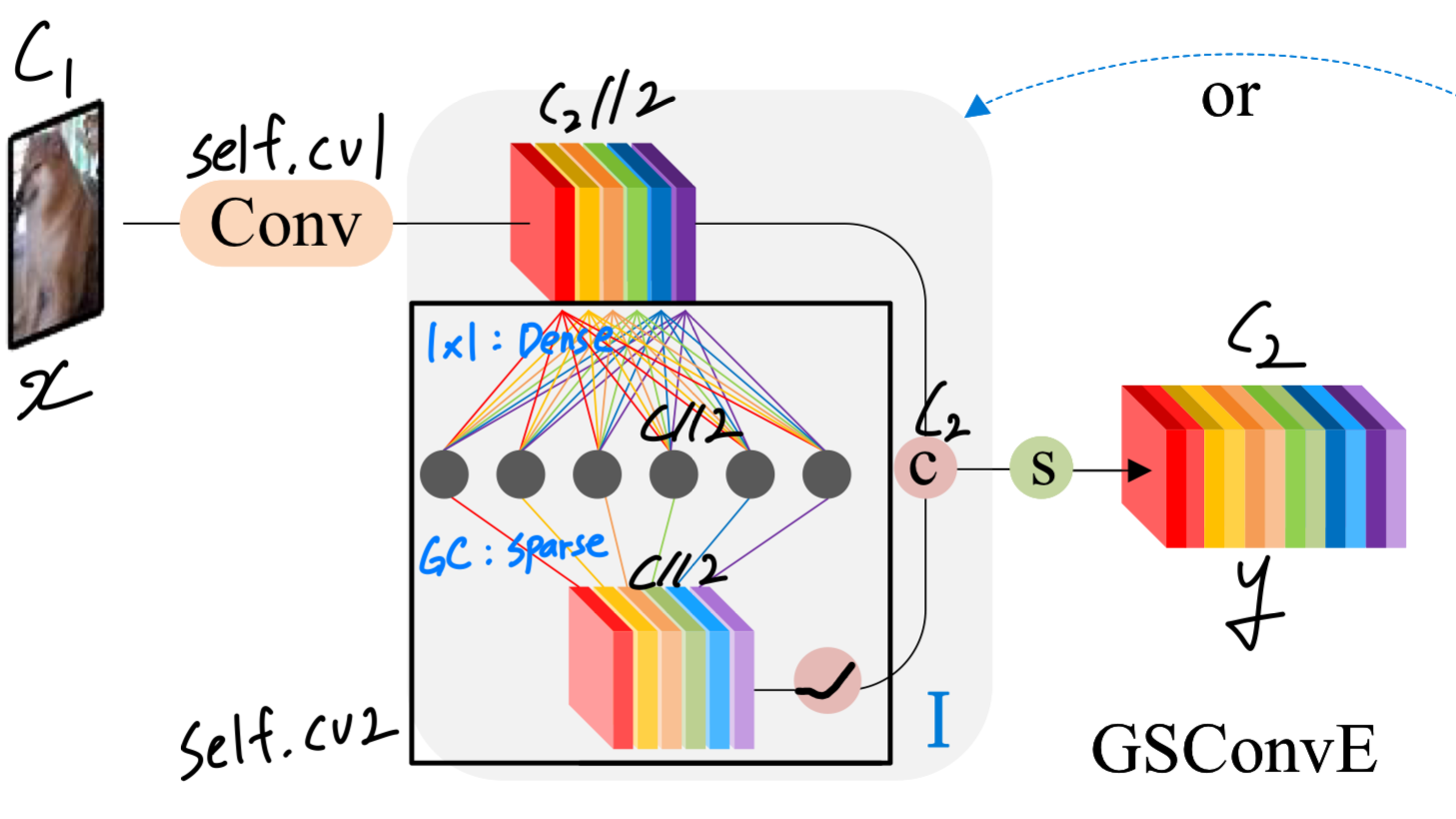
- 이 접근법은 computational cost를 증가시키지 않고 feature richness를 유지시킨다.
-
반면, GSConvE-2은 lightweight model을 위해 설계됨.
이 model은 각각 9x9, 13x13, 17x17 kernel sizes를 사용하는 세 개의 depthwise conv auxiliary branches를 통합함.
larger kernel sizes를 활용함으로써, 이 variant는 fewer layer accumulations을 통해 larger receptive fields and global features를 directly capture할 수 있으며,
FLOPs 수와 layer 수가 줄어든 lightweight model에서 high cost-effectiveness를 제공한다.

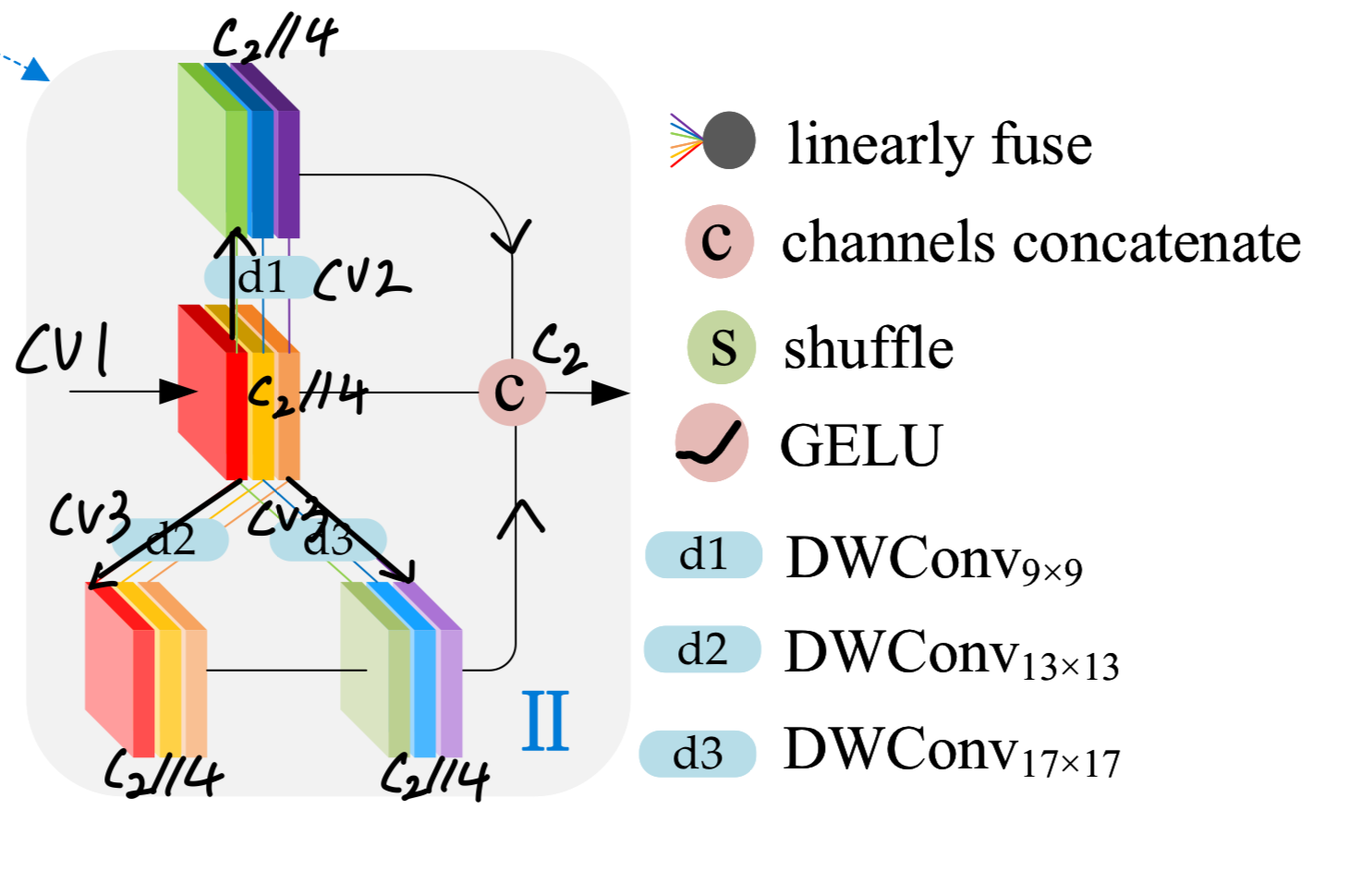
-
실제로 neck에서 GSConvE layer로 대체했음.
왜 neck에서만 했을까?
GSConv 논문에서 classification에서 모든 SC를 DSC로 바꿨더니 단점이 증폭.
또한 detection에서도 backbone을 모두 DSC로 바꿨더니 단점이 증폭.
그래서 backbone에는 SC를 쓰고, neck에서만 DSC를 써서 DSC의 단점을 최소화하고 장점을 효율적으로 활용하는 방향을 제안함
4. Experiments
- popular YOLO models(v3 ~ v8)을 baseline으로 잡음.
4.1. Datasets
-
Pascal VOC 07 + 12을 ablation exp로 사용함.
train&val07+12을 train에 사용.
test07 set을 evaluate에 사용. -
MS COCO dataset은 comparative experiments에 사용함.
train2017 set을 train에 사용.
val2017 set을 evaluate에 사용.
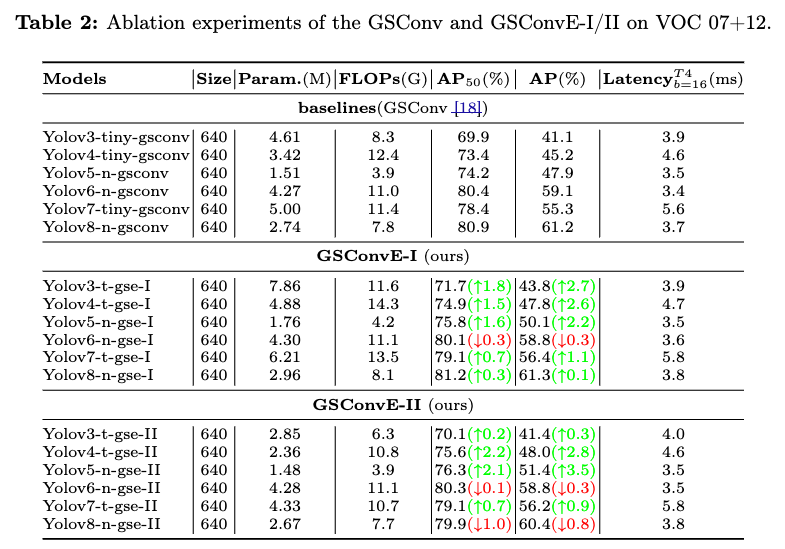
4.2. Ablation studies
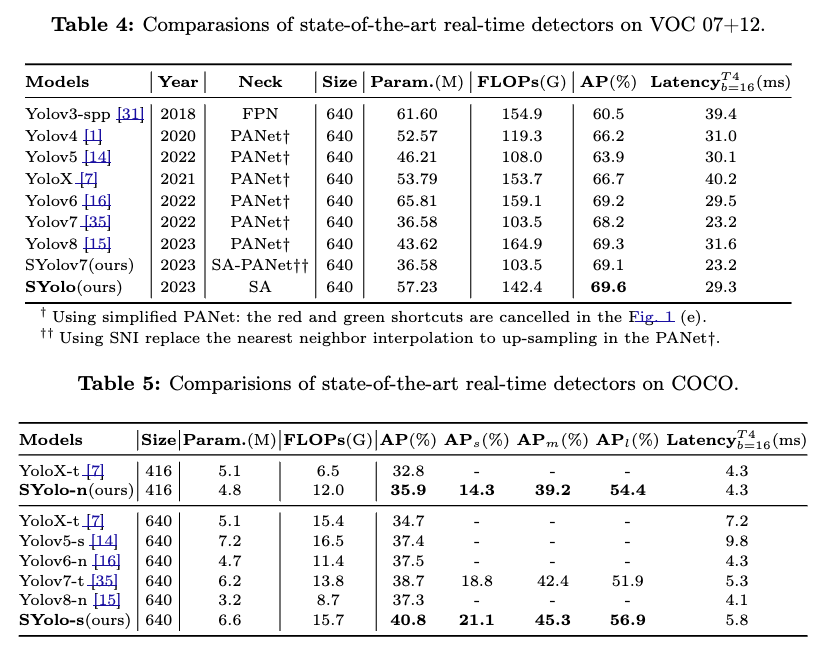
4.3. Comparasion experiments
Critique
Nearest Interpolation는 Transposed Conv에 비해 얼만큼의 computation과 latency가 증가할까?
내 생각으로는 그렇게 많이 증가할 것 같지 않음.
해봤자 보통 2개의 upsampling layer (nearest interpolation)가 있는데,
이 두 개의 layer를 learnable layer로 바꾸는게 더 효과적일 것 같음..
inconsistencies in spatial features 지적하고,
이를 해결하기 위한 Soft Nearest Interpolation 방법의 제안은 좋다고 생각하나,
suboptimal solution이라고 생각이 듦.
