[2020 arXiv][ViT] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
이해에 도움이 된 영상 : https://www.youtube.com/watch?v=bgsYOGhpxDc
Paper Info
- Authors : Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
(Google Research, Brain Team)
subject : arXiv preprint arXiv:2010.11929 (2020).
link : https://arxiv.org/abs/2010.11929
ABSTRACT
-
Transformer architecture가 natural language processing task에서 사실상 표준이 되어가는 동안,
computer vision에 적용하는 것에 대한 한계점은 계속 남아있다. -
vision 분야에서,
attention은 CNN과 함께 사용되거나,
CNN의 일부 구성요소를 대체하는 데에 사용된다.
그러나
우리는 꼭 CNN에 의존할 필요는 없으며,
image patch의 sequence에 직접 적용되는 pure transformer가
image classification task에서 매우 잘 수행될 수 있다는 것을 보여줄 것이다.
1. Introduction
(NLP task에서 Transformer의 장점)
- Self-attention-based architecture(특히 Transformer)는 natural language processing(NLP)에서 선호되는 model이 되었다.
이 접근법은 large text corpus에 pretrain시킨 후에,
smaller task-specific dataset에 fine-tune하는 것이 주요 접근 방법이다.
Transformer의 computational dfficiency와 scalability 덕분에,
전에 없던 size의 model을 train시키는 것이 가능해졌으며,
이 model은 100B 이상의 parameter를 가질 수 있다.
model과 dataset이 커짐에 따른 performance가 saturating된 적도 아직 없다.
(computer vision task에서는 아직 CNN이 우세하다..)
- 하지만 computer vision에서, CNN이 여전히 우세하다.
NLP의 성공에 영감을 받아, 여러 연구에서는 CNN과 유사한 architecture에 self-attention을 결합하는 시도를 하고 있다.
일부의 연구는 CNN을 완전히 대체하기도 한다.
후자의 경우 이론적으로 효율적이지만, 특수한 attention pattern을 사용하기 때문에
현대의 HW accelerator로 확장되지 못했다.
따라서 large-scale image reconition에서는 ResNet과 유사한 architecture가(1, 2) 여전히 state of the art이다.
(우리 연구는 Transformer를 computer vision에 잘 사용해보는 것...)
- NLP에서 Transformer의 성공에 영감을 받아,
우리는 가능한 적은 수정만으로 standard Transformer를 image에 직접 적용하는 실험을 진행했다.
이를 위해,
image를 patch로 나누고 patch에 sequence of linear embeddings을 transformer의 input으로 넣는다.
image patch는 NLP에서 사용하는 tokens(words)와 동일한 방식으로 처리된다.
우리는 supervised 방식으로 image classification model을 학습시킨다.
(Transformer는 충분한 data로 훈련되지 않으면, 성능이 잘 안나온다(?))
-
중간 규모의 dataset인 ImageNet에서 강한 regularization 없이 학습시키면,
이 model은 ResNet보다 몇 percentage point 아래의 accuracy를 낸다.
이것은 실망스러운 결과일 수 있다. :
Transformer는 CNN에 내재된 inductive bias(귀납적 편향)을 가지고 있지 않기 때문에,
translation equivariance이나 locality와 같은 속성이 부족하며,
따라서 충분하지 않은 양의 data로 훈련될 때 generalization이 잘 되지 않을 수 있다. -
그러나 model을 더 큰 dataset(14M~300M images)으로 훈련시키면 상황이 달라진다.
우리는 large scale training이 inductive bias를 능가한다는 것을 발견.
ViT는 충분한 규모로 pretrain된 경우에 우수한 결과를 얻었음.
public ImageNet-21k에 대해 pretrain했을 때 좋은 성능.
정리 :
Transformer는 CNN에 비해 내재된 inductive bias를 갖고 있지 않아서
ImageNet-1k와 같은 중간 규모의 dataset에 대해서는 성능이 떨어짐.
그렇지만 ViT를 ImageNet-21k와 같은 큰 dataset에서 충분히 training시킨다면, CNN model(ResNet)에 비해 우수한 성능을 가짐.
2. Related Work
-
image에 self-attention을 단순히 적용하는 것은 각 pixel이 다른 모든 pixel에 주의를 기울여야 한다는 것을 의미.
pixel 수에 제곱 비용이 발생하므로, 현실적인 input size로 확장되지 않음. -
따라서 image processing 맥락에서 transformer를 적용하기 위해 지난 시도에는 여러 가지 방법이 시도되었음.
- Paramar et al.(2018)은 각 Query pixel에 대해 local neighborhoods에서만 self-attention을 적용.
이러한 local multi-head dot-product self attention block은 완전히 convolution을 대체할 수 있음. - 다른 연구 방향에서 sparse transformer(Child et al., 2019)는 image에 적용 가능하도록 확장 가능한 근사치를 사용하여 global self-attention을 수행.
- ...
➡️ 이러한 특수화된 architecture 중 많은 것이 computer vision에서 유망한 결과를 보여줬지만,
HW accelerator에서 효율적으로 구현하기 위해 복잡한 engineering이 필요
- Paramar et al.(2018)은 각 Query pixel에 대해 local neighborhoods에서만 self-attention을 적용.
-
우리의 연구과 가장 관련된 것은 Cordonnier et al. (2020)이다.
이 model은 input image에서 크기가 인 patch를 추출하고 이를 기반으로 full self-attention을 적용한다.
이 model은 ViT와 유사하지만,
우리의 연구는 대규모 pretraining이 순수한 transformer를 state-of-the-art CNNs보다 경쟁력 있게 만든다는 것을 더 나아가 증명함.
또한 Cordonnier et al. (2020)은 pixel 크기의 작은 patch를 사용하며,
이는 model이 small-resolution image에서만 적용 가능하게 만든다.
반면에 우리는 medium-resolution image에서도 처리할 수 있다.
(그럼 high resolution image는 처리하기 어렵다는 것인가?)
3. Method
- model design에 있어서
우리는 original Transformer와 최대한 유사하게 만드려고 했다.
의도적으로 simple setup을 하려는 장점은
확장 가능한 NLP Transformer architecture와 그 효율적인 구현을 거의 그대로 사용할 수 있다는 것.
3.1 Vision Transformer (ViT)
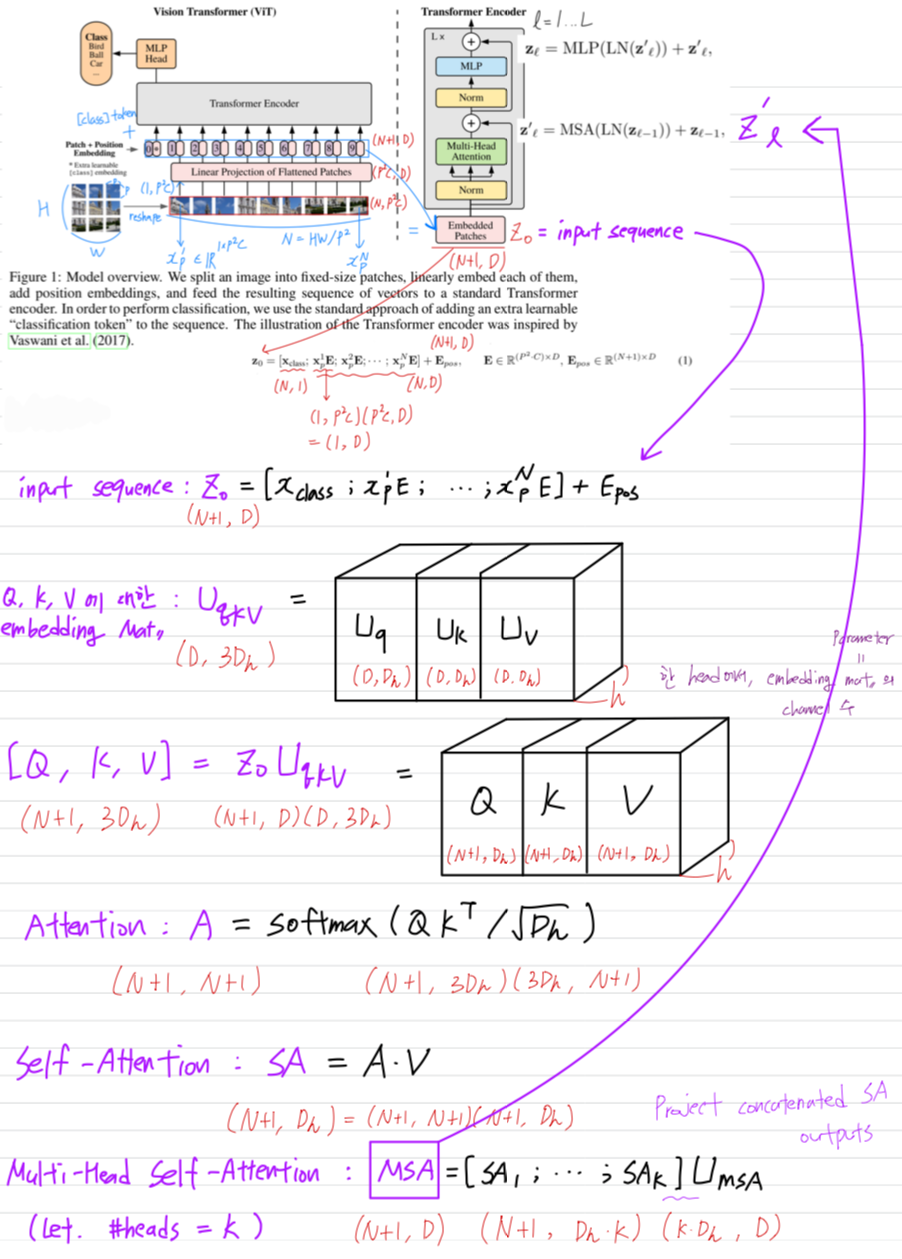
- model에 대한 overview는 Figure 1.에 설명되어 있다.
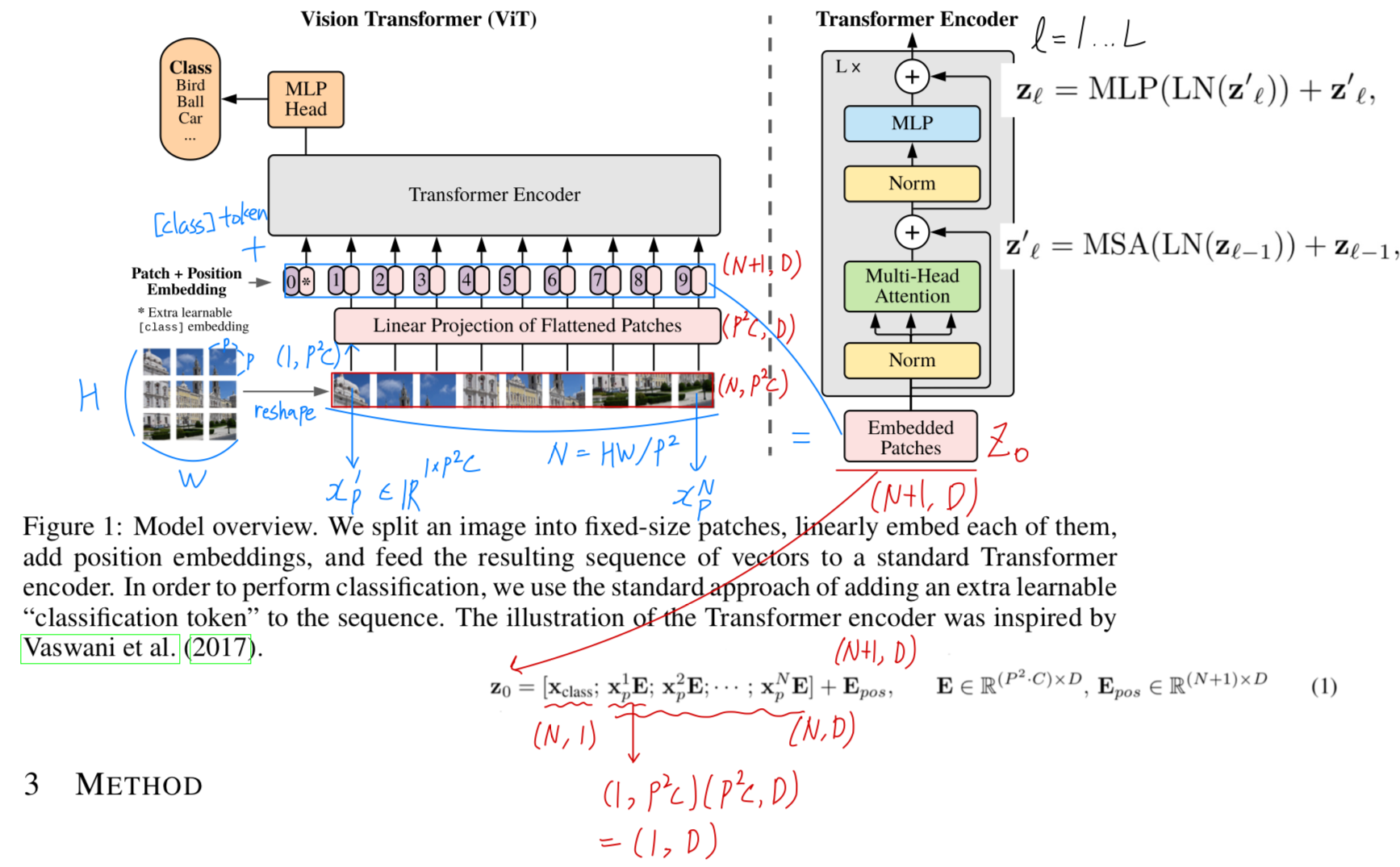 standard Transformer는 1D sequence의 token embedding을 input으로 받는다.
standard Transformer는 1D sequence의 token embedding을 input으로 받는다.
2D image를 다루기 위해서,
우리는 image()를 flattened 2D patches 로 reshape했다.
은 original image의 resolution,
는 channel 수,
는 각 image patch의 resolution,
는 patch 수를 나타내며 또한 transformer의 유효한 input sequence 길이로 작용한다.
Transformer는 모든 layer에서 일정한 latent(잠재적) vector size 를 사용하므로,
우리는 patch를 flatten하고, trainable linear projection(Eq. 1)을 사용하여 차원으로 mapping한다.
우리는 이 projection의 output을 "patch embedding"이라고 부른다.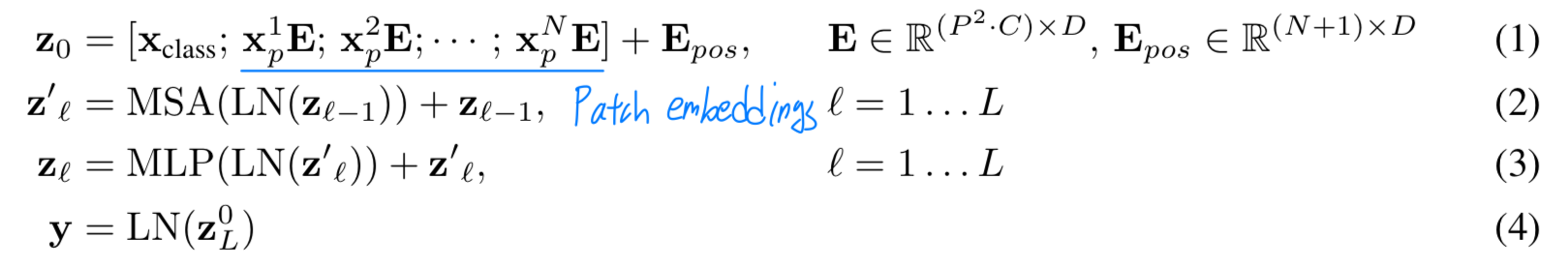 BERT의 [class] token과 유사하게, 우리는 embedded patches의 sequence에 학습 가능한 embedding을 앞에 추가했다. ()
BERT의 [class] token과 유사하게, 우리는 embedded patches의 sequence에 학습 가능한 embedding을 앞에 추가했다. ()
transformer의 encoder의 output에서 이 embedding의 상태()가 image representation인 로 작용한다. (Eq. 4)
pre-training과 fine-tuning 중에서는 모두 에 classification head가 부착된다.
이 classification head는 pre-trainin time에 one hidden layer를 가진 MLP로 구현되고,
fine-tuning time에는 a single linear layer로 구현된다.
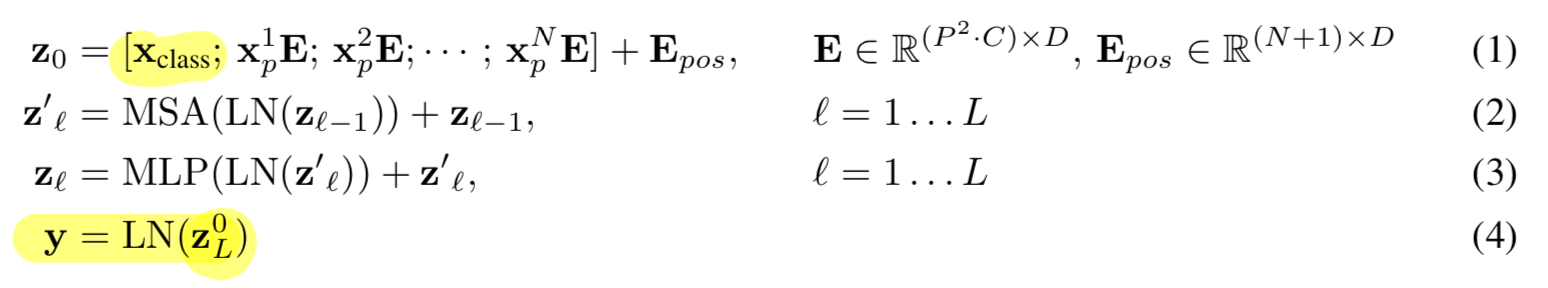 position embedding에 positional information을 추가하여 위치 정보를 유지했다.
position embedding에 positional information을 추가하여 위치 정보를 유지했다.
우리는 2D-aware position embedding을 사용하여 유의미한 성능 향상을 관찰하지 못했기 때문에
standard learnable 1D position embedding을 사용했다. (Appendix D.4)
결과적으로 얻은 embedding sequence()는 encode의 input에 제공된다.

Transformer encoder는 multihead self-attention(MSA)와 MLP blocks이 번갈아 나타나는 layer로 구성된다.
Layernorm(LN)은 각 block 앞에 적용되고,
각 block 뒤에 residual connection이 적용된다.
MLP에는 GELU non-linearity를 가진 두 개의 layer가 포함되어 있다.- multihead self-attention details (Appendix A 참고)
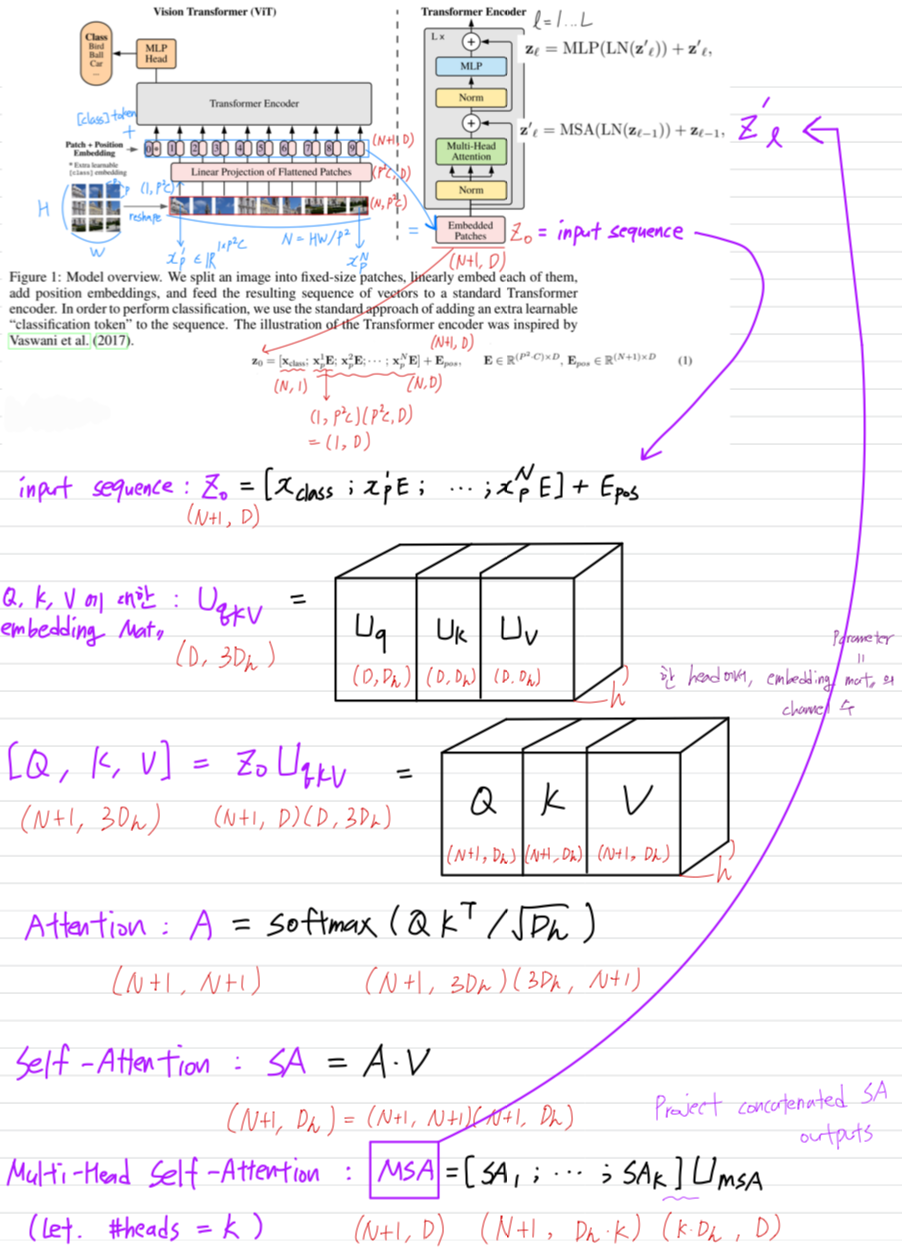
- multihead self-attention details (Appendix A 참고)
Inductive bias
- ViT는 CNN보다 image-specific inductive bias를 가지지 않는다.
CNN에서는 각 layer에 걸쳐 locality, two-dimensional neighborhood 및 translation equivariance이 녹아들어 있다.
ViT에서는 MLP layer만 지역적이고 translationally equivariance를 가지며, self-attention은 전역적이다.
Two-dimensional neighborhood structure는 매우 절약적으로 사용된다 :
image를 patch로 자르는 model의 처음 부분에세와
다른 resolution(3.2에서 설명)의 image에 대한 position embedding을 조정하는 fine-tuning time에만 사용된다.
그 외에는 초기화 시 position embedding에는 patch의 2D position에 대한 정보가 없으며,
patch 간의 모든 spatial relation은 처음부터 학습되어야 한다.
Hybrid Architecture
- raw image patch 대신, input sequence는 CNN의 feature map으로부터 형성될 수도 있다.
이 hybrid model에서는 CNN feature map에서 추출된 patch에 patch embedding (Eq. 1)이 적용된다.
특수한 경우로, patch의 spatial dimension을 로 설정할 수 있으며,
이는 feature map의 공간 차원을 단순히 flatten하여 transformer dimension으로 Projection하여 input sequence를 얻는 것을 의미함.
3.2 Fine-Tuning and Higher Resolution
-
일반적으로, 우리는 ViT를 large dataset에 pretrain하고, (smaller) downstream task에 fien-tune했다.
이를 위해,
pretrained prediction head를 제거하고
크기의 zero-nitialized feedforward layer를 붙혔다. -
fine-tuning을 할 때, pre-training할 때보다 higher resolution을 사용하는 것이 종종 유익하다. (Touvron et al., 2019)
high resolution image를 feeding할 때, 우리는 patch size를 그대로 유지시켰고,
이로 인해 더 긴 sequence 길이가 발생했다. -
ViT는 memory 제약에 따라 임의의 sequence 길이를 처리할 수 있다.
그러나 sequence 길이를 임의대로 처리한다면, pretrain된 position embedding은 더 이상 의미가 없을 것이다.
따라서 우리는 pretrained position embedding을 원본 image에서의 위치에 따라 2D interpolation(보간)했다.
이 resolution 조정과 patch extraction은 ViT에 2D image structure에 대한 inductive bias가 수동으로 주입되는 유일한 지점이다.
4. Experiments
-
우리는 ResNet, ViT, 그리고 hybrid model의 representation learning 능력을 평가했다.
각 model의 data 요구 사항을 이해하기 위해 다양한 크기의 dataset에서 pretraining을 수행하고
많은 benchmark 작업을 평가했다. -
model의 pretraining 비용을 고려할 때,
ViT는 대부분의 recognition benchmark에서 우수한 성능을 보여주며 pretraining cost가 낮았다.
마지막으로 우리는 self-supervision 실험을 수행하고, self-supervised ViT가 미래에 유망하다는 것을 보였음.
4.1 Setup
Datasets
4.2 Comparison To State Of The ART
4.3 Pre-training Data Requirements
4.4 Scaling Study
4.5 Inspecting Vision Transformer
4.6 Self-Supervision
5 Conclusion
궁금, 모르는 점
Inductive bias?
- inductive bias(위키백과), 참고자료 :
귀납적 편향(Inductive bias) 또는 학습 편향(learning bias)은
학습 알고리즘에서 학습자가 아직 접하지 않은 주어진 입력의 출력을 예측하기 위해 사용하는 일련의 가정- 일반적으로 model이 갖는 generalization problem에는
불안정하다는 것(brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)가 있다.
model이 주어진 data에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제.
이러한 문제를 해결하기 위한 것이 Inductive Bias이다.
주어지지 않은 input의 output을 예측 가능하도록 model이 가지고 있는 가정들의 집합을 의미한다. - CNN의 경우 Locality(근접 pixel끼리의 종속성) & Translation invaraince(object 위치가 바뀌어도 동일 사물 인식)을 가정하는
inductive bias를 갖기 때문에 image에 적합한 model이 된다. - Transformer는 image에 대해서 CNN보다 inductive bias가 낮다.
- 일반적으로 model이 갖는 generalization problem에는
Layernorm?
GELU?
