[2021 ICCV] [Simple Review] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Paper Info
- Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
Abstract
-
이 논문에서,
우리는 computer vision을 위해 general-purpose backbone으로 사용될 수 있는
Swin Transformer라고 불리는 새로운 vision Transformer를 소개할 것임. -
Transformer에 language로부터 vision을 적용하는 challenge는
두 domain 간의 차이에서 비롯된다.
예를 들어,
text의 단어들과 비교했을 때,
visual entities 규모의 large variations과 image의 pixel의 high resolution 등의 차이가 있다. -
이러한 차이를 해결하기 위해,
우리는Shiftedwindows를 사용하여 representation을 계산하는 hierarchical Transformer를 제안한다.
Shifted windows 방식은 non-overlapping local windows로 self-attention computation을 제한하여
efficiency를 높이는 동시에 cross-window connection을 허용한다.
이 hierarchical architecture는 다양한 scales에서 modeling할 수 있는 flexibility를 가지며,
image size에 비례하는 linear computational complexity를 갖는다.
1. Introduction
-
computer vision에서 moedling은 CNN이 지배적이었다.
AlexNet에서부터 진화된 CNN architecture들은
greater scale, more extensive connections, and more sophisticated forms of convolution을 통해서 강력해졌다. -
반면 NLP에서의 효과적인 network architecture는 Transformer이다.
language domain에서 큰 성공은 researcher들이 computer visoin에도 적용하도록 이끌었다. -
이 논문에서,
우리는 Transformer가 NLP에서처럼,
그리고 CNN이 vision에서처럼 그렇듯이,
computer vision의 general-purpose backbone으로 기능할 수 있도록 applicability(적용 가능성)을 확장하려고 함. -
language domain에서의 높은 성능을 visual domain으로 전이하는 데 있어서의 주요 challenges는
두 가지 modalities(양식)의 차이로 설명할 수 있다.- Language Transformer에서 처리의 기본 요소로 작용하는 token과 달리,
vision 분야는 scale이 매우 다양할 수 있으며, 이는 object detection과 같은 작업에서 주요한 문제로 부각된다.
기존의 Transformer 기반 model에서는 모든 token이 fixed scale을 가지며,
이러한 속성은 vision application에 적합하지 않다. - image의 pixel resolution이 text 단락의 words보다 훨씬 높다는 점이다.
semantic segmentation과 같은 많은 vision task들은 pixel 수준에서 dense prediction을 필요로 하며,
이는 high resolution image에서 Transformer가 처리하기에 어렵다.
이는 self-attention의 computational complexity가 image size에 따라 quadratic(제곱)으로 증가하기 때문임.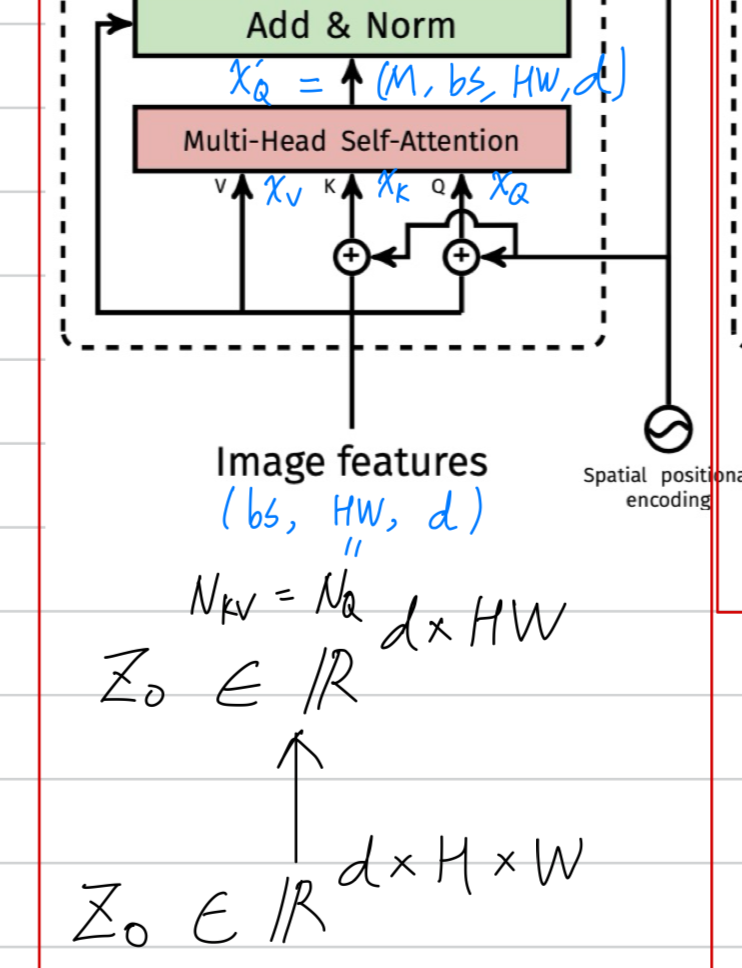
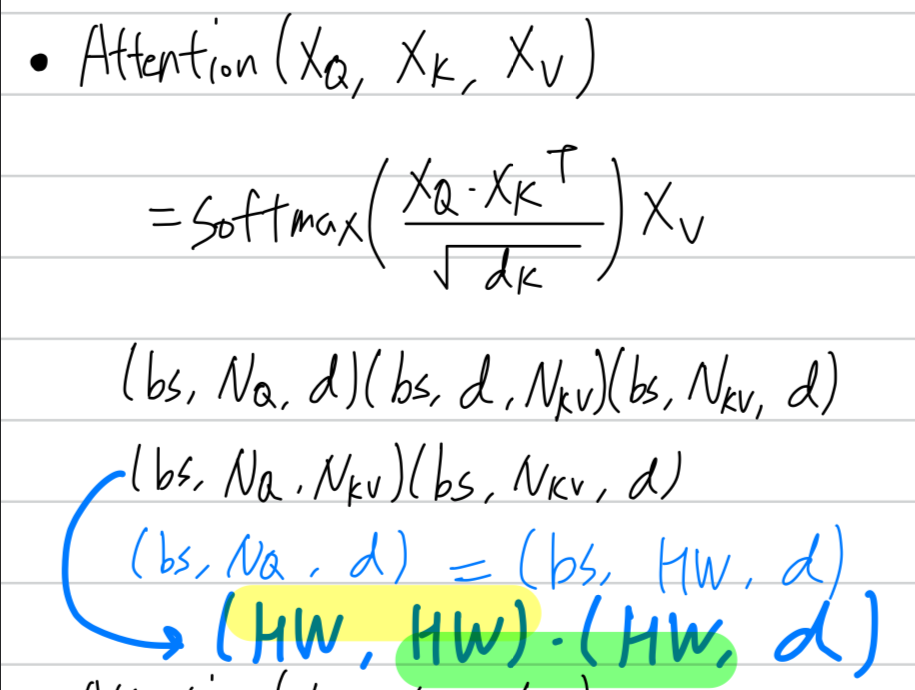
- Language Transformer에서 처리의 기본 요소로 작용하는 token과 달리,
- 위 두가지 문제를 해결하기 위해,
우리는Swin Transformer라고 불리는 general-purpose Transformer backbone을 제안한다.
이 model은 hierarchical feature map을 구성하며
image size에 대해 lienar computational complexity를 가진다.
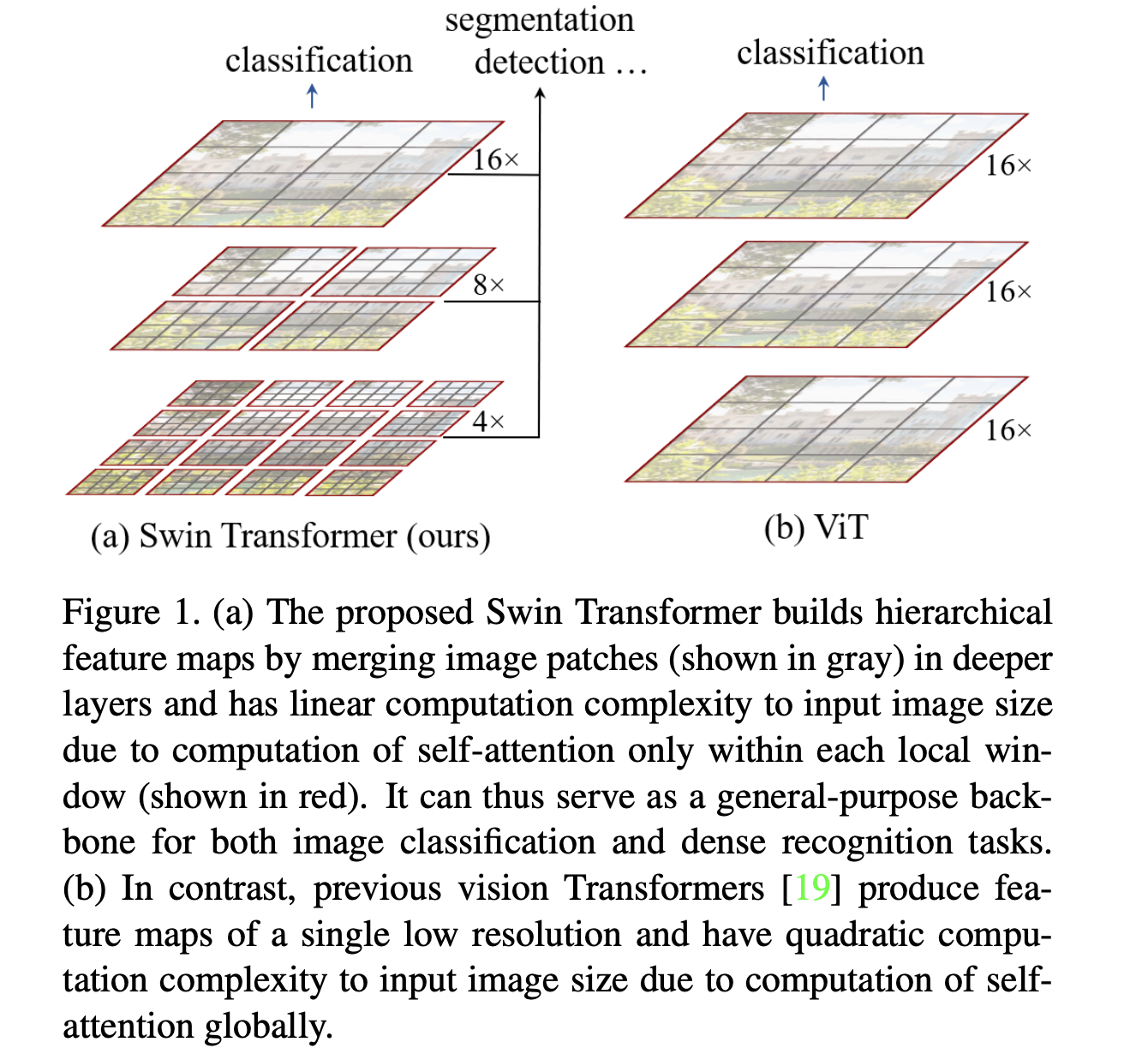
Figure 1(a)에서 설명한 바와 같이,
Swin Transformer는 small-sized patches(회색)에서 시작하여 더 깊은 Transformer layer에서
neighboring patches를 점진적으로 merge하여 hierarchical representation을 만든다.이러한 hierarchical feature map을 통해 SwinT model은 FPN 또는 U-Net과 같은
dense prediction을 위한 고급 기술을 편리하게 활용할 수 있다.
linear computational complexity는 image가 나누어지는 non-overlapping window 내에서
local하게 self-attention을 계산함으로써 달성할 수 있다. (빨간색)
각 window의 patch수는 고정되어 있어 complexity가 image size에 대해 선형적으로 된다.
이러한 장점 덕분에 SwinT는 다양한 vision task를 위한 general-purpose backbone으로 적합하며,
single resolution의 feature map을 생성하고 quadratic complexity를 가진 이전의 Transformer 기반의 architecture와 대조된다.
-
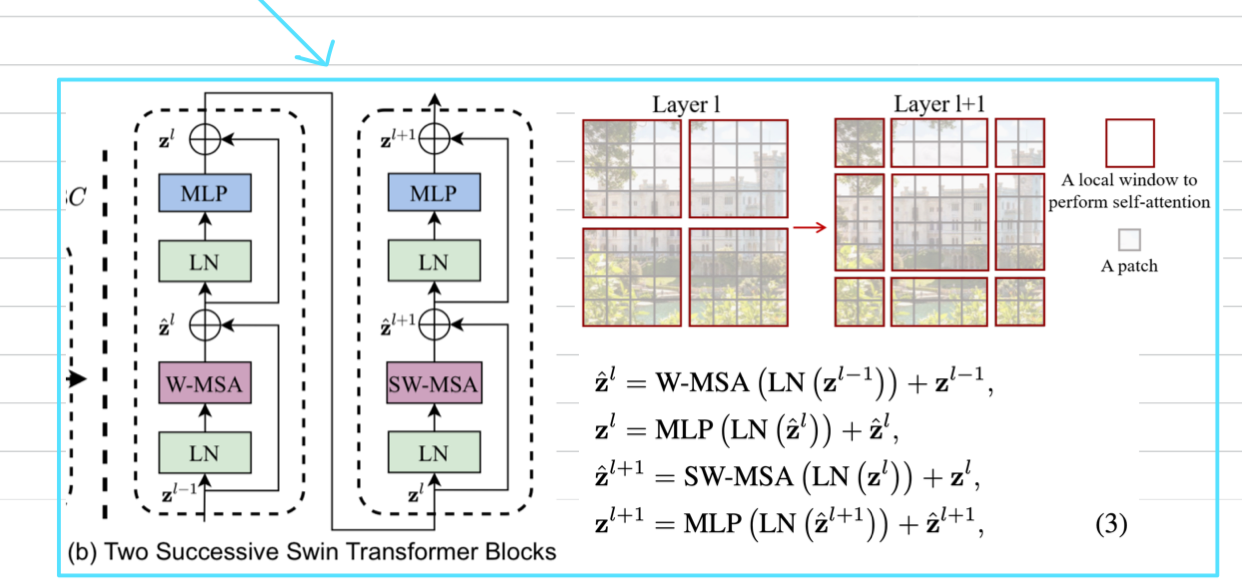
SwinT의 주요 deisgn element는
연속적인 self-attention layer 사이에서 window partition을 shift하는 것이다. (Figure 2)
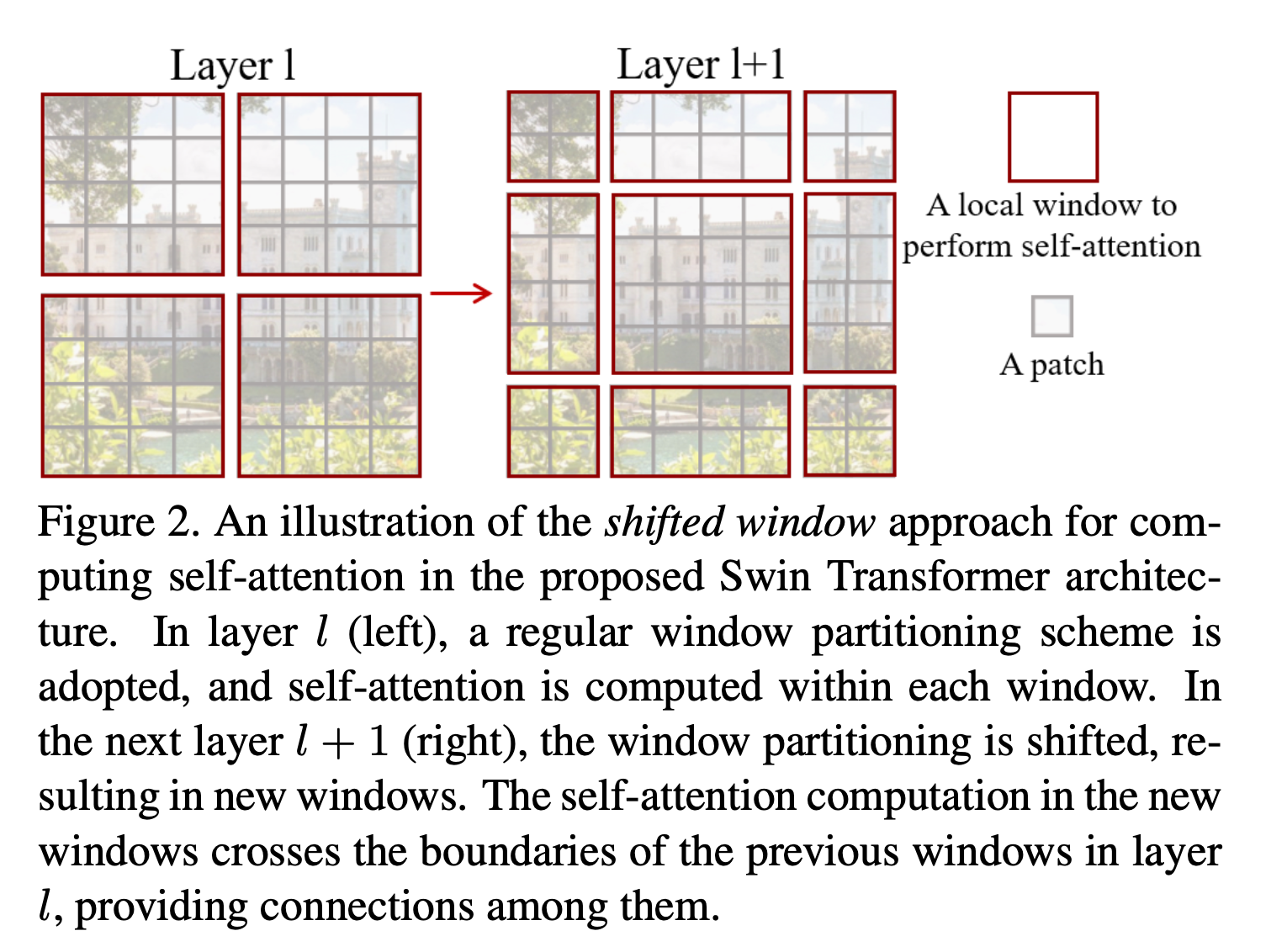 shifted(이동된) window는 이전 layer의 window를 연결하여 modeling power를 크게 향상시킨다. (Table 4)
shifted(이동된) window는 이전 layer의 window를 연결하여 modeling power를 크게 향상시킨다. (Table 4)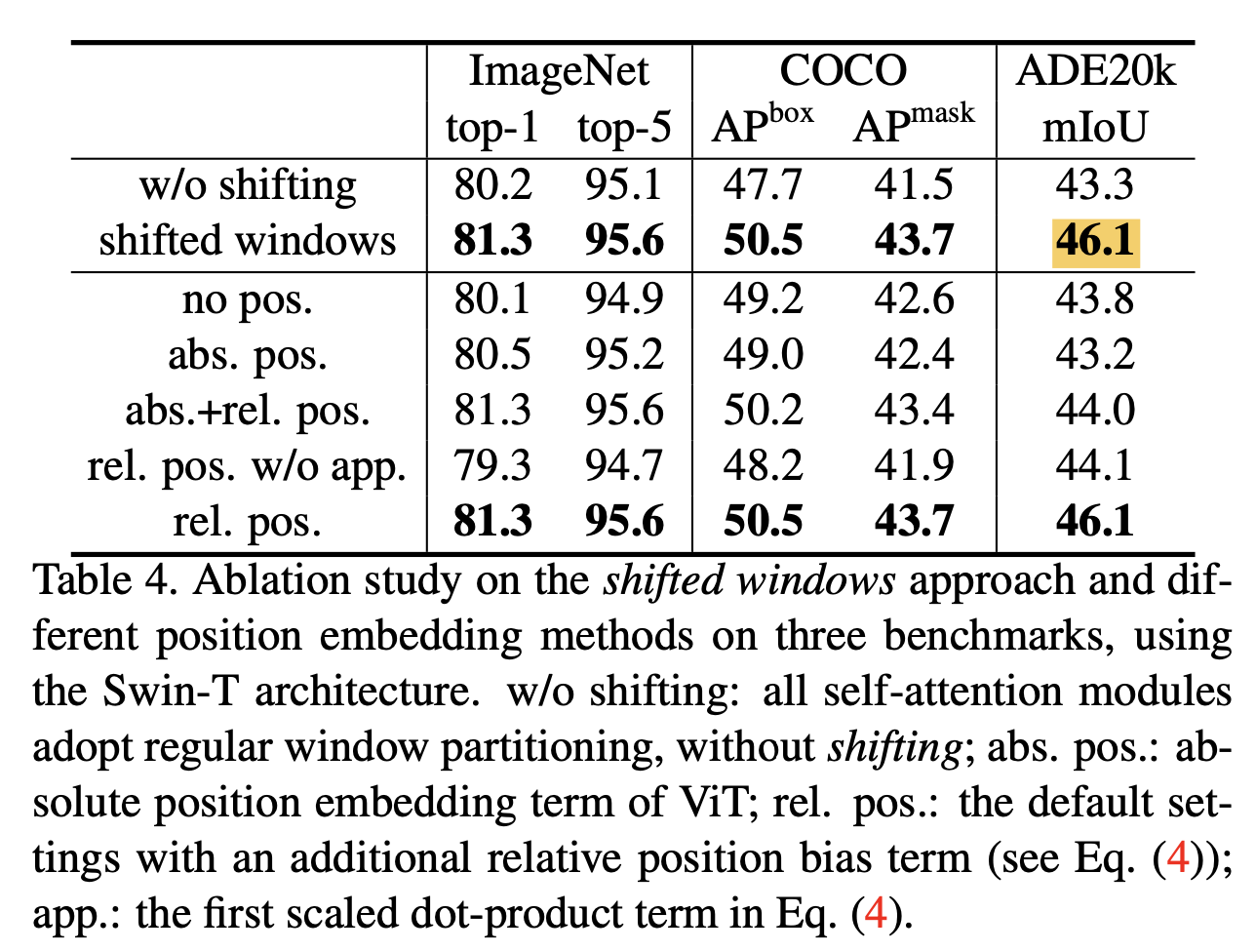 이 strategy는 real-world latency 측면에서도 효율적이다 :
이 strategy는 real-world latency 측면에서도 효율적이다 :
window 내의 모든 query patch는 동일한 key set을 공유하여 HW에서 memory access를 용이하게 한다.
반면, 이전의 sliding window 기반 self-attention 방법은 서로 다른 query pixel에 대해 다른 key set을 사용하기 때문에 일반적인 HW에서 낮은 latency 시간을 보인다.
우리의 실험은 제안된 shifted window approach가 sliding window 방법보다 훨씬 낮은 latency 시간을 가지면서도 유사한 modeling power를 가지고 있음을 보여준다. (???)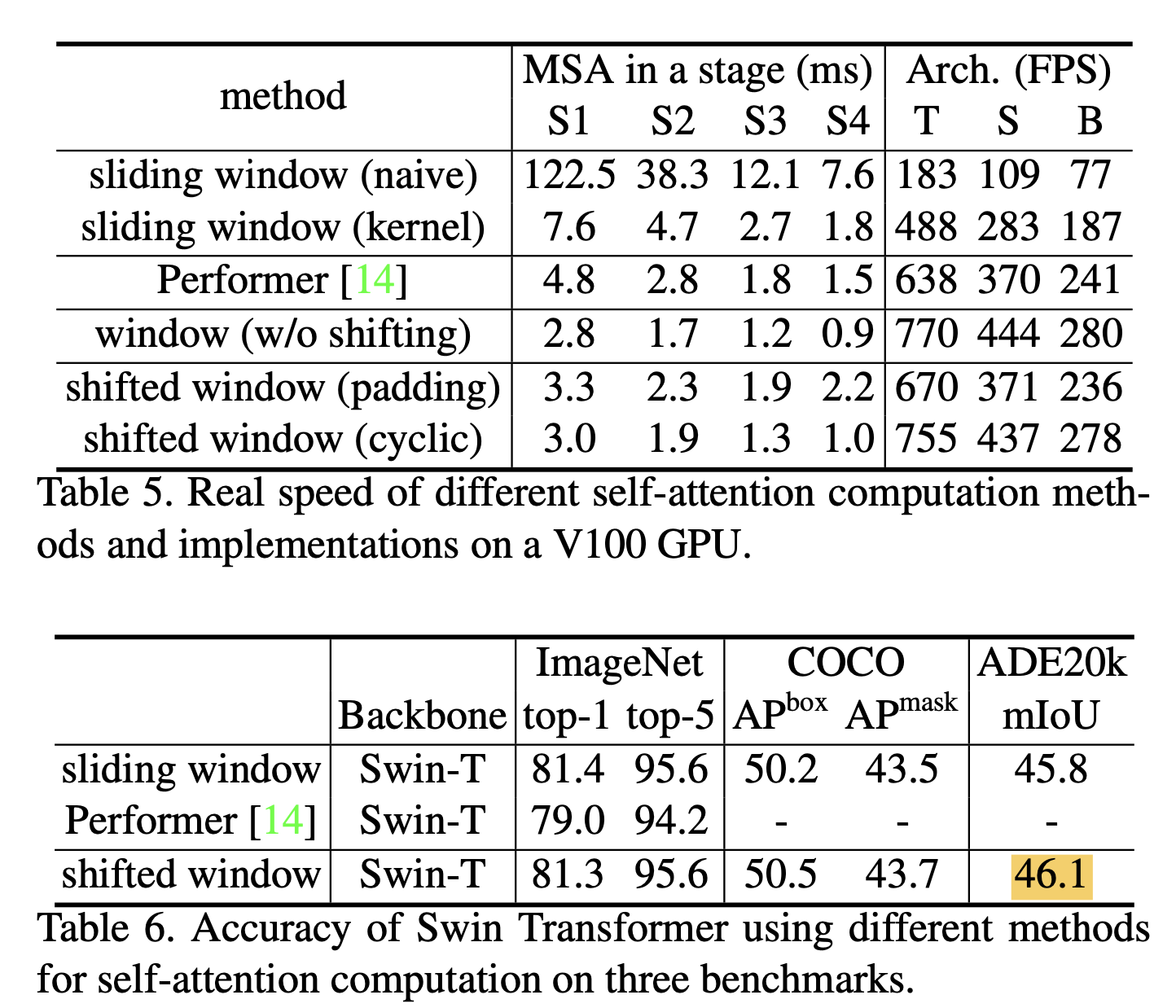
-
제안된 SwinT는 image classification, object detection and semantic segmentation 등 recognition tasks에서 강한 성능을 보인다.
top-1 accuracy 87.3% on ImageNet-1K image classification을 달성, ...
2. Related Work
(skip)
CNN and variants
Self-attention based backbone architectures
Self-attention/Transformers to complement CNNs
Transformer based vision backbones
3. Method
3.1. Overall Architecture
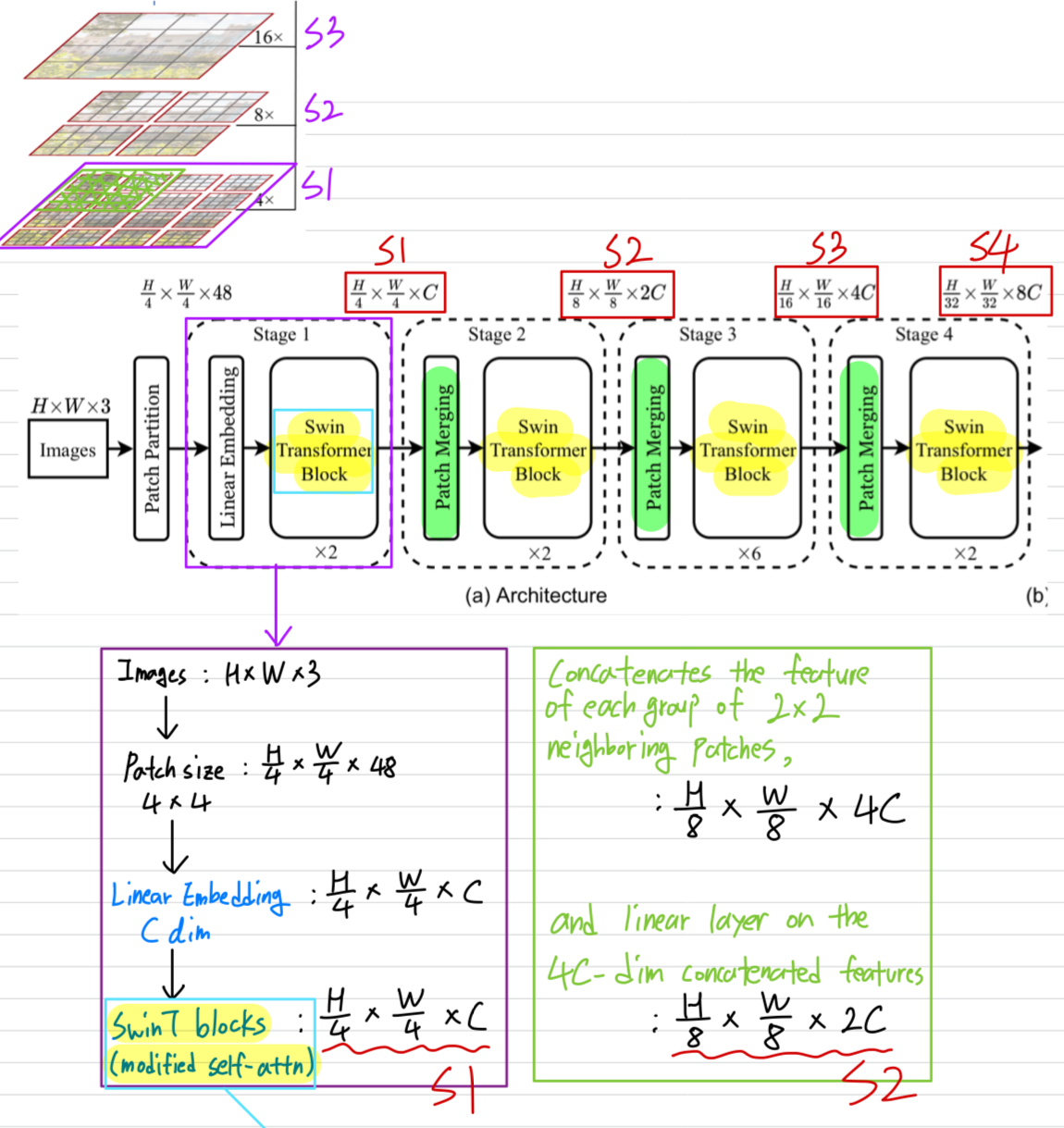
- SwinT archtecture의 overview는 Figure 3(tiny version)에 있다.
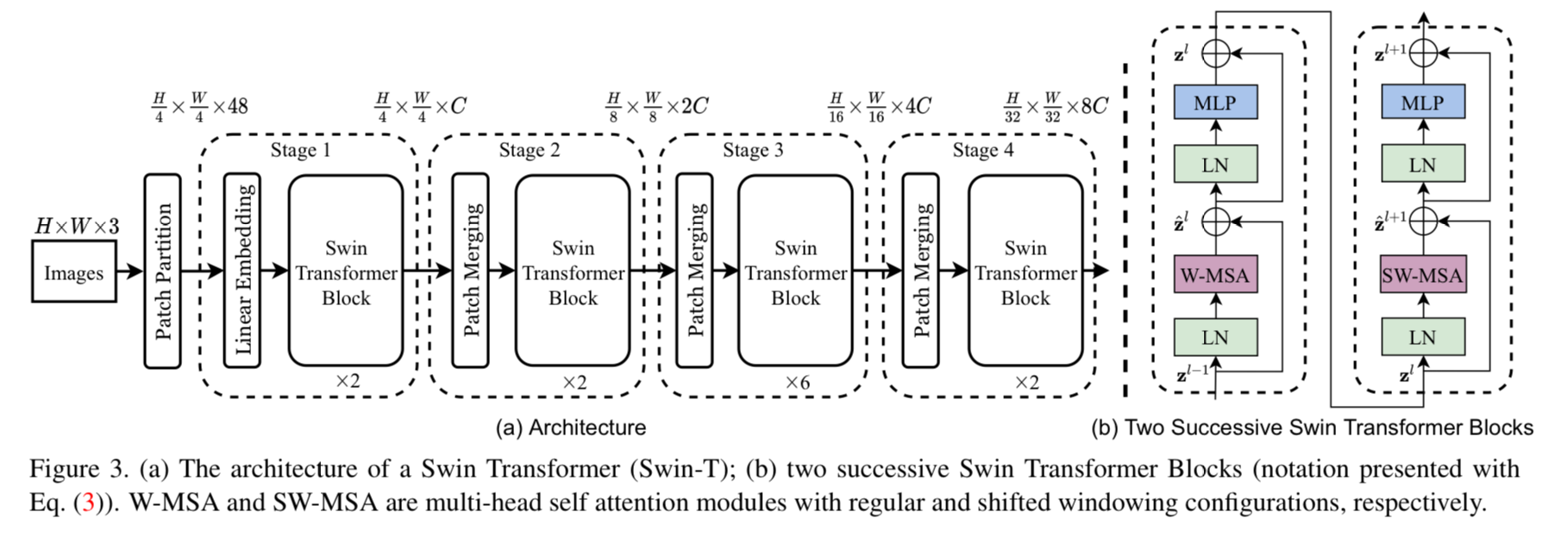
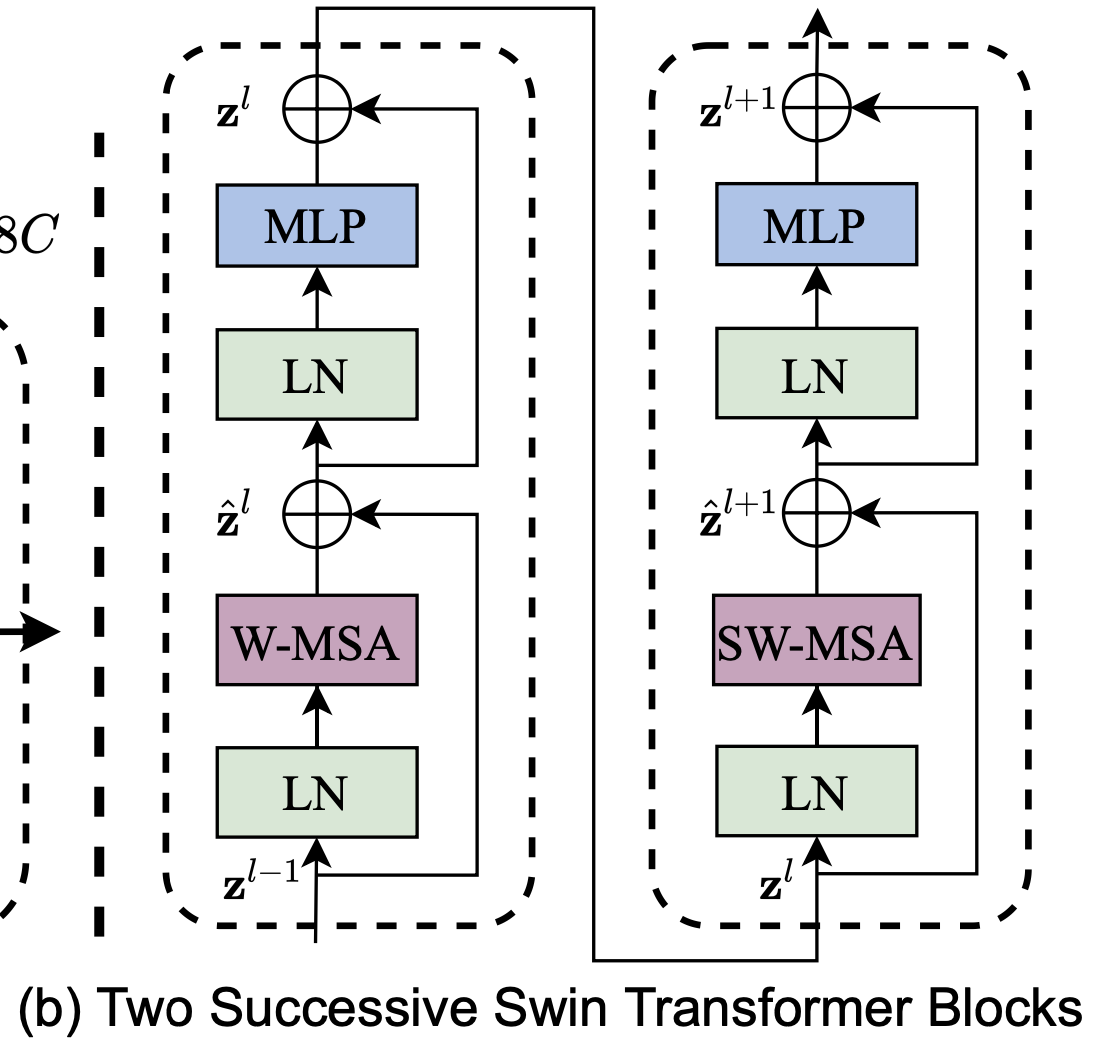
Swin Transformer block
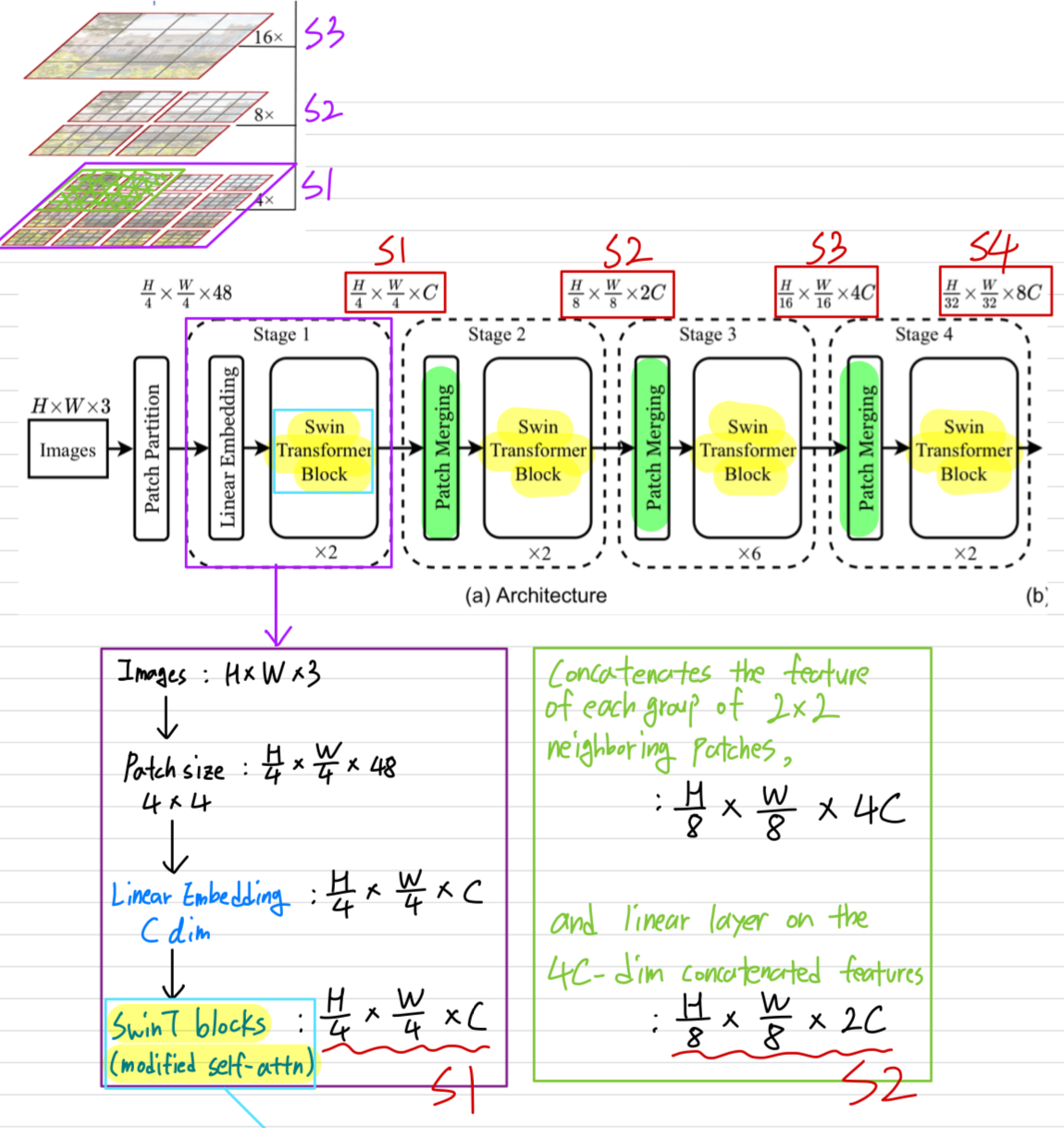
-
SwinT는
Transformer block의 standard multi-head self attention(MSA) module을
a module based on shifted windows(Section 3.2)로만 바꾼 것이다. -
Swin Transformer block은
2-layer MLP with GELU를 따르는 shifted window based MSA module로 구성된다.
LN layer는 MSA module과 MLP layer 이전에 적용되고,
residual connection도 각 module 이후에 적용된다.
3.2. Shifted Window based Self-Attention
- standard Transformer architecture는 global sefl-attention으로 적용한다.
global computation은 token 개수에 대하여 quadratic complexity를 유발하고,
high-resolution image를 represent하기에 어려움이 있다.
Self-attention in non-overlapped windows
-
efficient modeling을 위해서,
우리는 self-attention within local windows computation을 제안한다. -
Window는 image가 non-overlapping(겹치지 않도록)하도록 분할되게 배열된다.
각 window가 patches를 포함한다고 가정할 때,
size patches에서
global MSA module과 window based MSA module은 각각 다음과 같이 계산된다 :
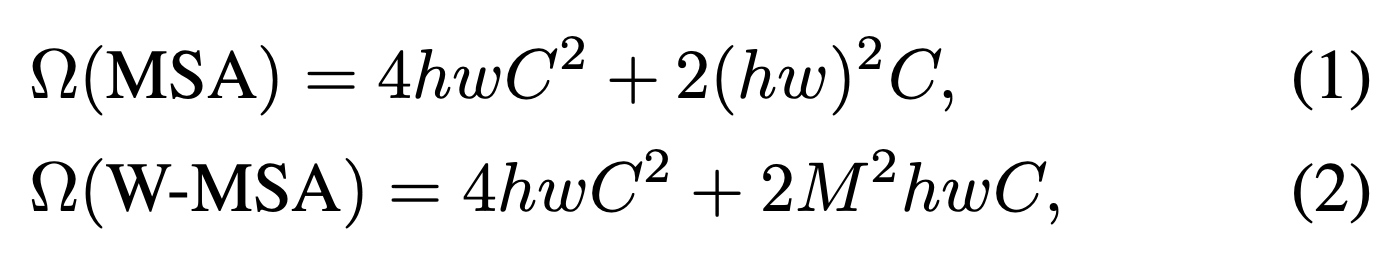 global MSA module은 에 대해 quadratic하기 때문에 큰 에 대해 적용할 수 없는 반면에,
global MSA module은 에 대해 quadratic하기 때문에 큰 에 대해 적용할 수 없는 반면에,
window based MSA module은 M이 고정된 경우 linear하기 때문에 scalable하다.
Shifted window partitioning in successive blocks
-
window-based self-attention module은 window 간 연결이 부족하여 modeling 능력이 제한된다.
non-overlapping windows의 효율적인 computation을 유지하면서 window 간 연결을 도입하기 위해,
consecutive Swin Transformer Block에서
두 개의 partitioning configuration을 번갈아 사용하는 shifted window partitioning approach를 제안한다. -
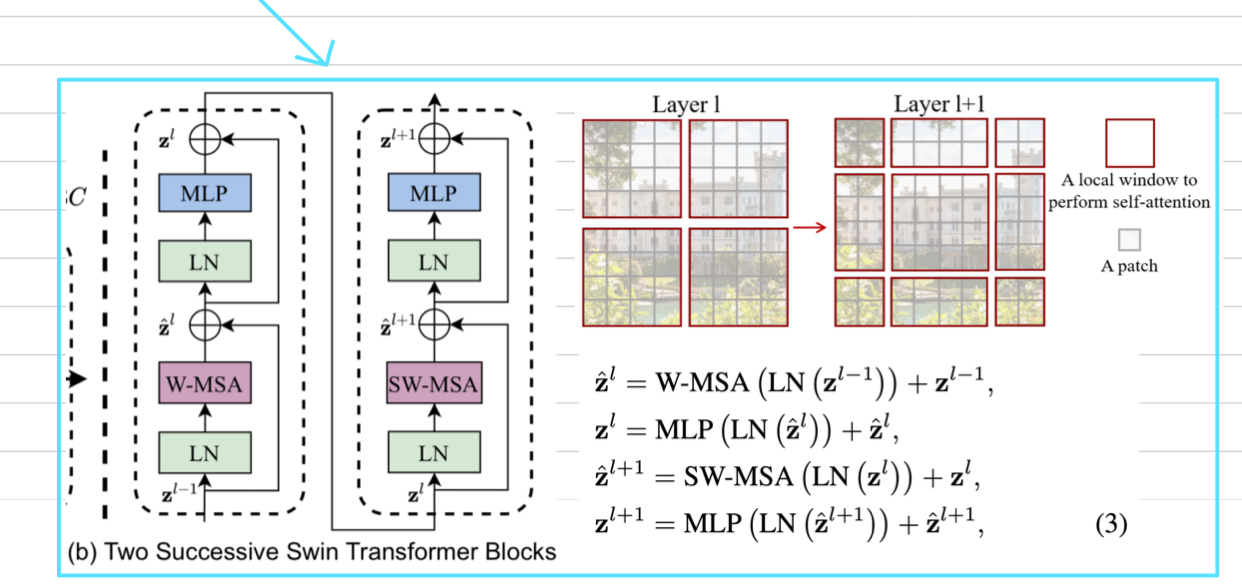
Figuer 2에 설명된 바와 같이,
first module은 좌상단 pixel에서 시작하는 regular window partitioning strategy를 사용하며,
feature map은 size의 window로 균등하게 분할된다. ()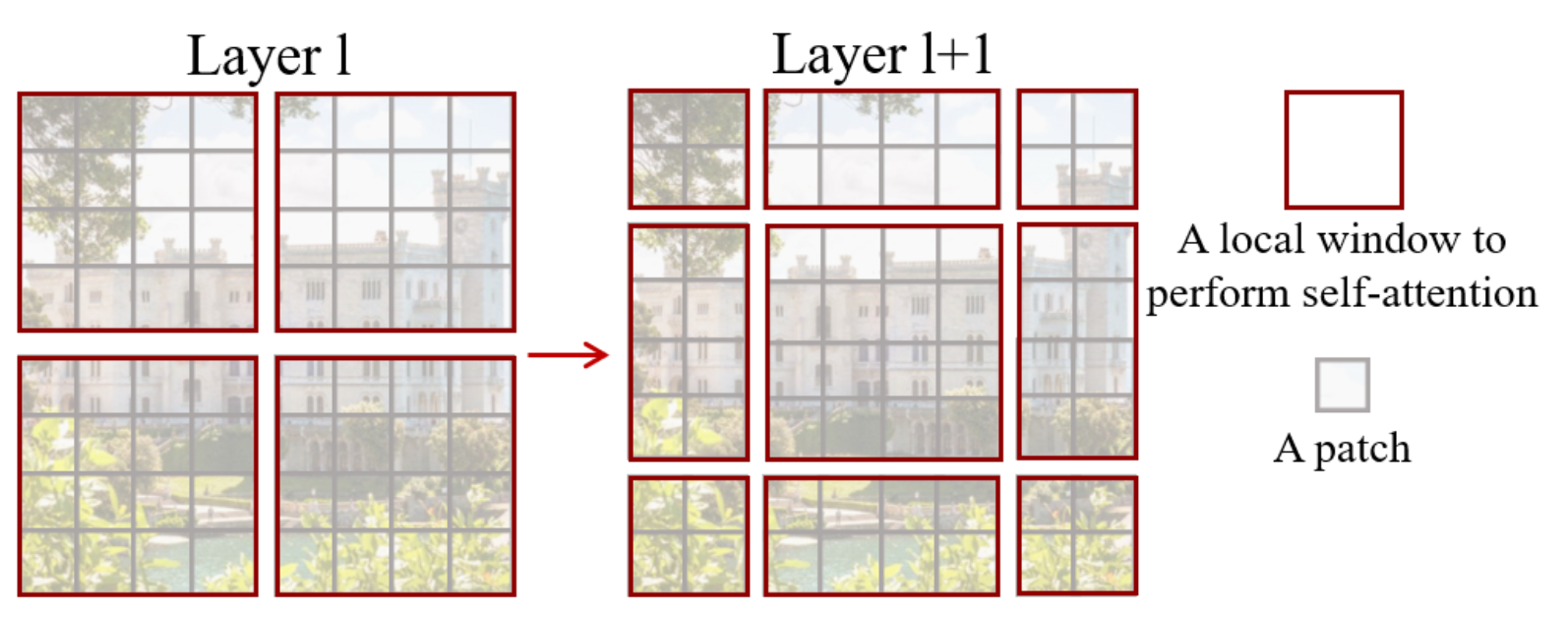 second module은 regular partitioning window에서 pixel만큼 이동한 windowing configuration으로 채택된다.
second module은 regular partitioning window에서 pixel만큼 이동한 windowing configuration으로 채택된다.
이동된 window partitioning 방식을 통해, consecutive Swin Transformer block은 다음과 같이 계산된다.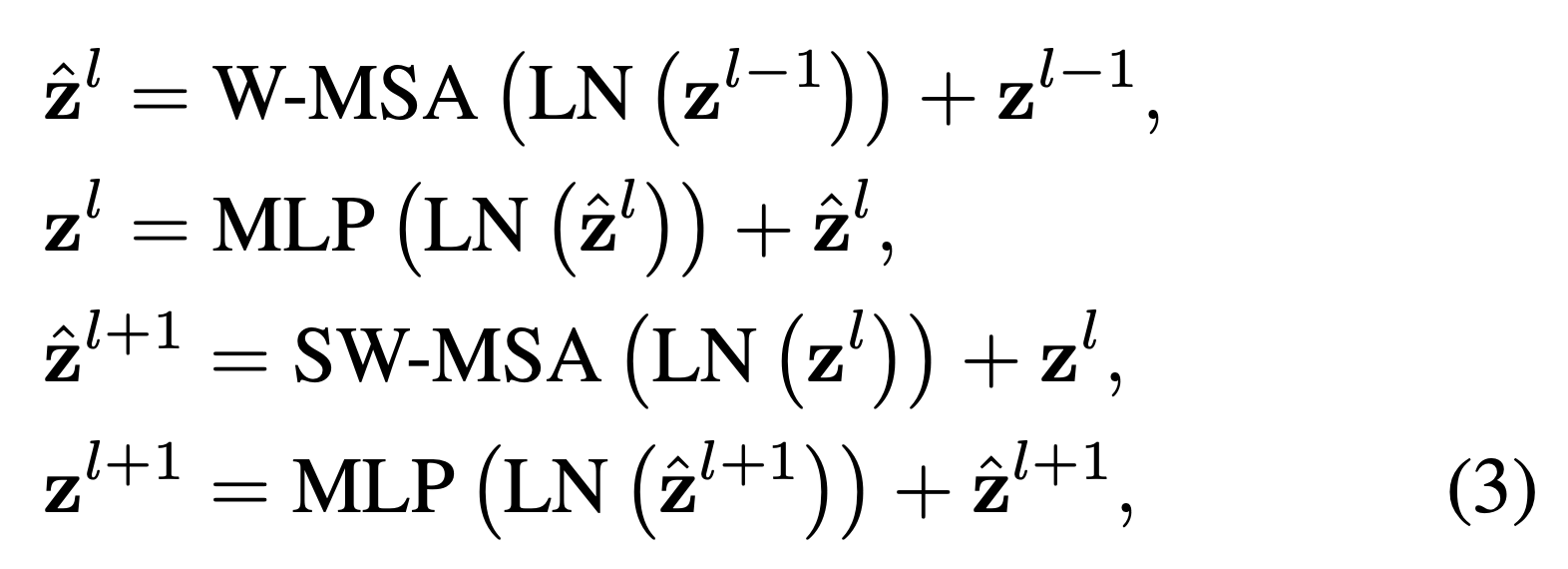 : output features of the W-MSA module for block (first module -> Regular Window Partitioning)
: output features of the W-MSA module for block (first module -> Regular Window Partitioning)
: output features of the MLP module for block
: output features of the SW-MSA module for block (second module -> Shifted Window Partitioning)
: output features of the MLP module for block
Efficient batch computation for shifted configuration
(이해 못함)
-
shifted window partitioning 문제는 shifted configuration에서 더 많은 window가 생성된다는 점이다.
이것은 에서 보다 큰 window까지 이동한다.
일부 window는 보다 작을 수 있다.
이러한 경우에 대한 단순한 해결책은 작은 window를 size로 padding하고,
attention을 계산할 때 padding된 값을 masking하는 것이다. -
regular partitioning의 window수가 작을 때,
예를 들어 인 경우,
이 단순한 해결책으로 인한 추가 계산이 크다. (2×2 → 3×3로 증가하며, 2.25배 증가)
여기서 우리는 Figure 4에서 설명한 바와 같이 더욱 efficient batch computation for shifted configuration 방식을 제안한다.
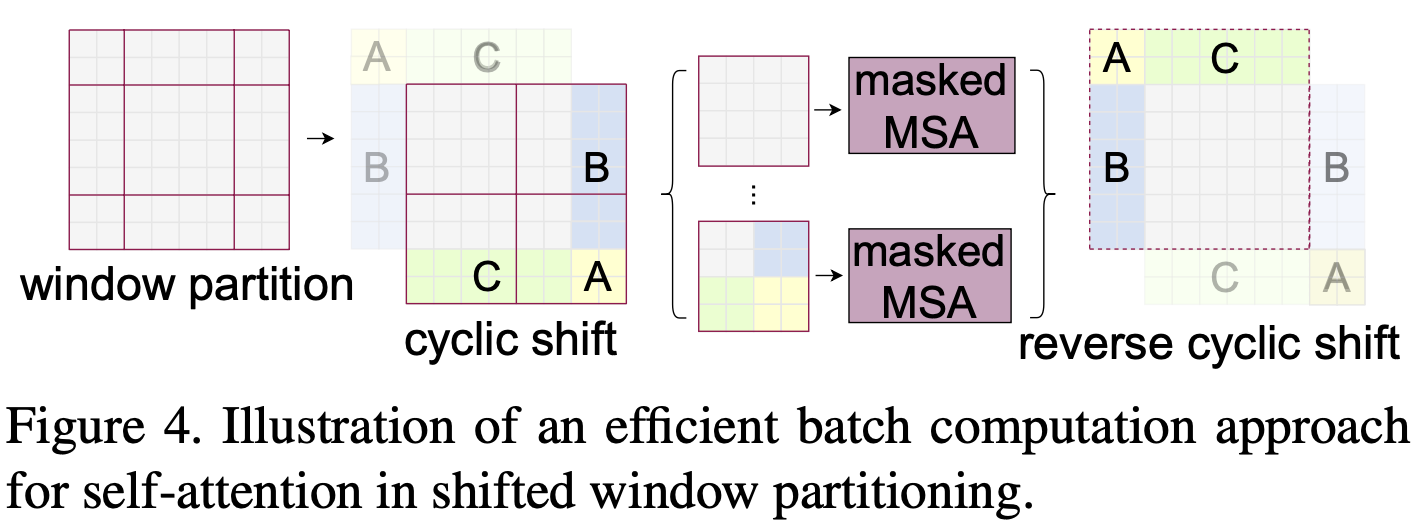 이동 방향은 좌측 상단 방향으로 cyclic-shifting시킨다.
이동 방향은 좌측 상단 방향으로 cyclic-shifting시킨다.
이 이동 후, batched window는 feature map에서 인접하지 않은 여러 sub-windows로 구성될 수 있다.
따라서 각 sub-windows 내부에서의 self-attention computation을 제한하기 위해 masking mechanism이 사용된다.
cyclic-shift를 통해 배치된 window수는 regular window partitioning과 동일하게 유지되므로 효율적이다.
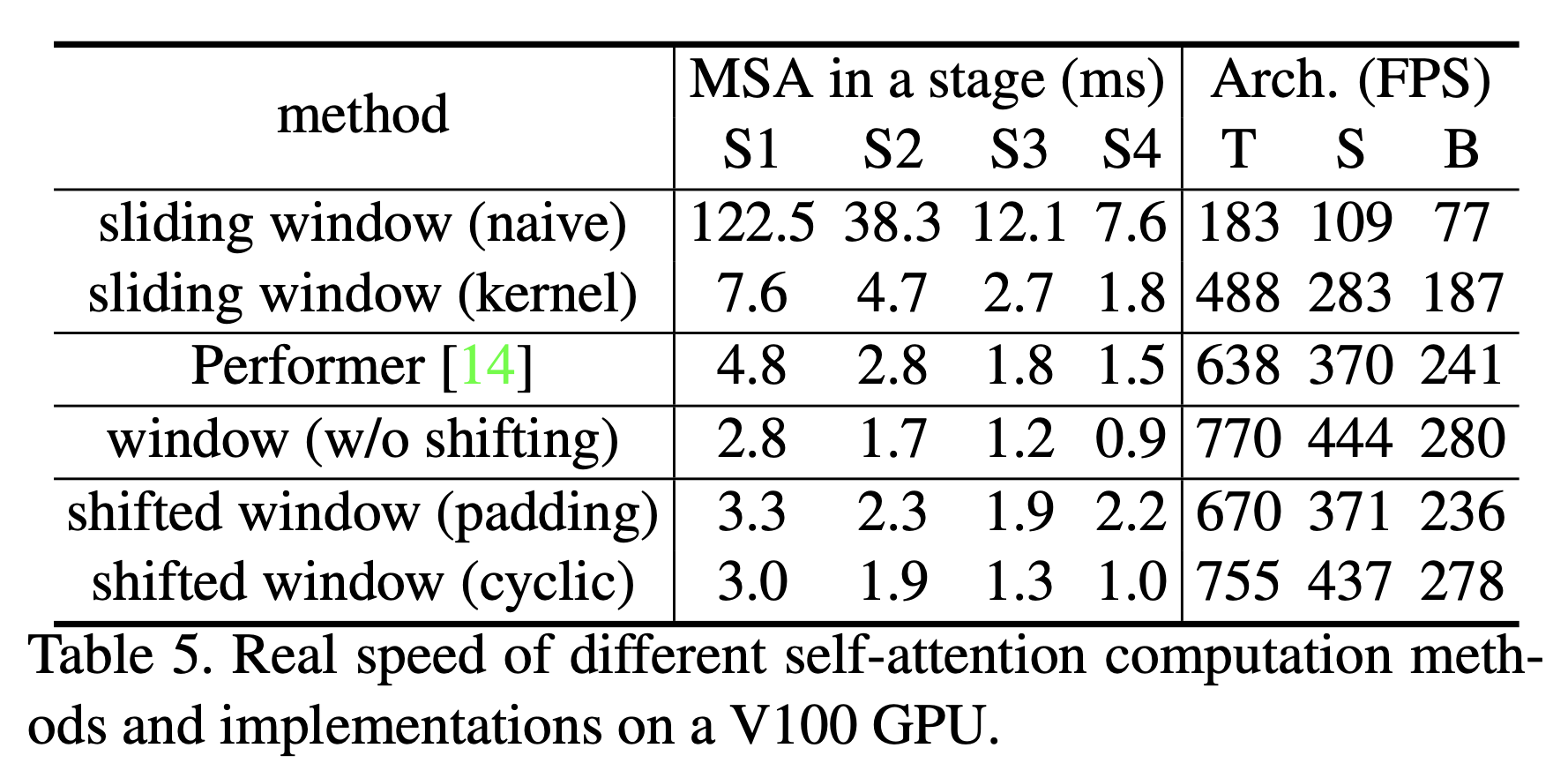
이 접근 방식의 적은 latency는 table 5에서 확인 가능.
Relative position bias
3.3. Architecture Variants
