Week 2 | Practical Advice for Using ConvNets
Using Open-Source Implementation
-
You've now learned about several highly effective neural network and ConvNet architectures.
What i want to do in the next few videos is share with you some practical advice on how to use them, first starting with using open-source implementations.
It turns out that a lot of these neural networks are difficult or finicky(까다로운) to replicate
because a lot of details about tuning of the hyperparameters such as learning rate decay and other things that make some difference to the performance.
Fortunately, a lot of deep learning researchers routinely open-source their work on the Internet, such as on GitHub.
If you're already familiar with how to use GitHub, this video might be less necessary or less important for you.
But if you aren't used to downloading open-source code from GitHub, let me quickly show you how easy it is. -
Let's say you're excited about residual networks, and you want to use it.
So let's search for ResNet on GitHub.




 This particular implementation uses the Caffe framework.
This particular implementation uses the Caffe framework.
So if you're developing a computer vision application, a very common workflow would be to pick an architecture that you like, maybe one of the ones you learned about in this course.
And look for an open source implementation and download it from GitHub to start building from there.
One of the advantages of doing so also is that sometimes these networks take a long time to train, and someone else might have used multiple GPUs and a very large dataset to pretrain some of these networks.
And that allows you to do transfer learning using these networks.
Transfer Learning
-
If you're building a computer vision application rather than training the ways from scratch, from random initalization,
you often make much faster progress if you download ways that someone else has already trained on the network architecture and use that as pre-training and transfer that to a new task that you might be interested in.
The computer vision research community has been pretty good at posting lots of datasets on the Internet so if you hear of thing like ImageNet, or MS COCO, or Pascal types of datasets,
these are the names of different data sets that people have post online and a lot of computer researchers have trained their algorithms on.
You can often download open-source ways that took someone else many weeks or months to figure out and use that as a very good initialization for your own neural network.
And usetransfer learningto sort of transfer knowledge from some of these very large public data sets to your own problem. -
Let's take a deeper look at how to do this.
Let's say you're building a cat detector to recognize your own pet cat.
According to the internet, Tigger is a common cat name and Misty is another common cat name.
Let's say your cats are called Tigger and Misty and there's also neither.
 Now you probably don't have a lot of pictures of Tigger or Misty
Now you probably don't have a lot of pictures of Tigger or Misty
so(1) your training set will be small.
So what can you do?
➡️ I recommend you go online and download some open-source implementation of a neural network and download not just the code but also the weights.
There are a lot of networks you can download that have been trained on.
For example, the ImageNet datasets which has a thousand different classes.
So the network migh have a softmax unit that outputs one of a thousand possible classes.
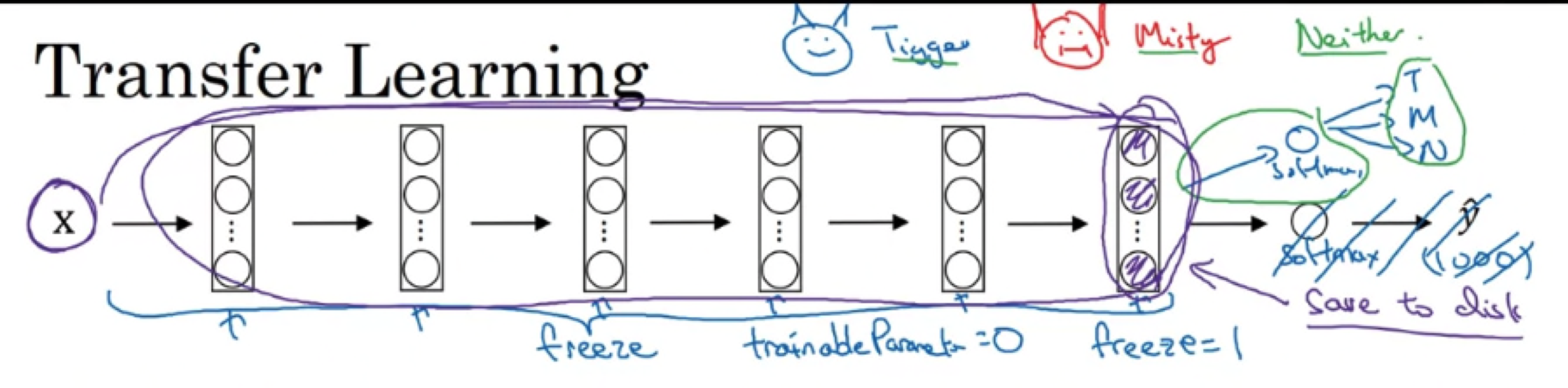
What you can do is then get rid of the softmax layer and create your own softmax unit that outputs Tigger or Misty or neither.
In terms of the network, (network 관점으로 볼 때,)
I'd encourage you to think of all of these layers as frozen so you freeze the parameters in all of these layers of the network and you would then just train the parameters associated with your softmax layer.
Fortunately, a lot of people learning frameworks support this mode of operation and in fact, depending on the framework it might have things like "trainableParameter=0".
You might set that for some of these earlier layers.
In others they just say, don't train those weights or sometimes you have a parameter like "freeze=1" and these are different ways and different deep learning program frameworks that let you specify whether or not to train the ways associated with particular layer.
In this case, you will train only the softmax layer's weight but freeze all of the earlier layer's weights.
One of the trick that could speed up training is we just pre-compute that layer,
the features of re-activations from that layer and just save them to disk.
What you're doing is using this fixed-function to take this input any image and compute some feature vector for it and then you're training a shallow softmax model from this feature vector to make a prediction.
 What if
What if (2) you have a larger training set.
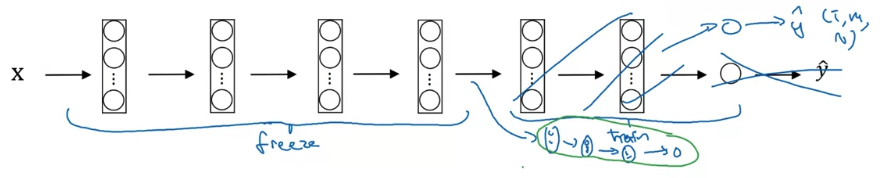
One rule of thumb is if you have a larger label dataset so maybe you just have a ton of pictures of Tigger, Misty as well as neither of them,
one thing you could do is then freeze fewer layers.
Maybe you freeze just these layers and then train these later layers.
Although if the output layer has different classes then you need to have your own output unit anyway.
You could take the last few layer's weights and just use that as initialization and do gradient descent from there
or you can also blow away these last few layers and just use your own new hidden units and in your own final softmax outputs.
But maybe one pattern is if you have more data,
the number of layers you've freeze could be smaller and then the number of layers you train on top could be greater.
 Finally,
Finally, (3) if you have a lot of data,
one thing you might do is take this open-source network and weights and
use the whole thing just as initialization and train the whole network.
Although again if this was a thousand of softmax and you have just three outputs, you need your own softmax output.
The output of labels you care about.
Data augmentation
- Most computer vision task could use more data.
And so data augmentation is one of the techniques that is often used to improve the performance of computer vision systems.
And this is not true for all applications of machine learnign, but it does feel like it's true for computer vision.
Common augmentation method
- Let's take a look at the common data augmentation that is in computer vision.
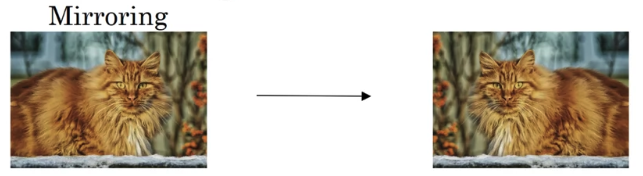 Perhaps the simplest data augmentation method is
Perhaps the simplest data augmentation method is mirroring on the vertical axis,
where if you have this example in your training set,
you flip it horizontally to get that image on the right.
And if the mirroring operation preserves whatever you're trying to recognize in the picture,
this would be a good data augmentation technique to use.
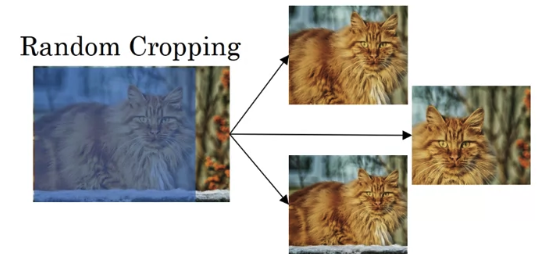
Another commonly used technique israndom cropping.
So given this dataset, let's pick a few random crops.
This gives you different examples to feed in your training sample, sort of different random crops of your datasets.
Random cropping isn't a perfect data augmentation.
고양이와 상관없는 부분을 crop하는 경우도 있을 것이다.
In theory, you could also use things like rotation, shearing, local warping and so on.
And there's really no harm with trying all of these things as well,
although in practice they seem to be used a bit less, or perhaps because of their complexity.
Color shifting
-
The second type of data augmentation that is commonly used is
color shifting.
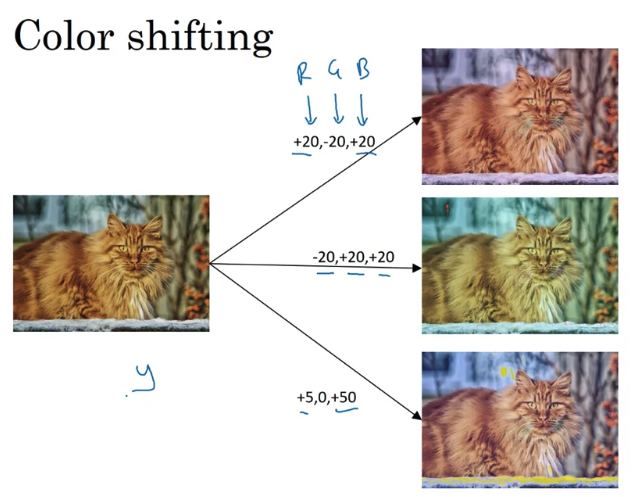 This makes your learning algorithm more robust to changes in the colors of your images.
This makes your learning algorithm more robust to changes in the colors of your images. -
Advanced version : One of the ways to implement color distortion uses an algorithm called PCA(Principles Component Analysis).
The details of this are actually given in the AlexNet paper, and sometimes called PCA Color Augmentation.
If your image is mainly purple(mainly has R and B tints, and very little G),
then PCA Color Augmentation will add and subtract a lot to Red and Blue, where it balance all the greens, so kind of keeps the overall color of the tint the same.
Implementing distortions during training
- You might have your training data stored in a HDD.
And if you have a small training set, you can do almost anything and you'll be okay.
But the very large training set and this is how people will often implement it,
which is you might have a CPU thread that is constantly loading images of your HDD.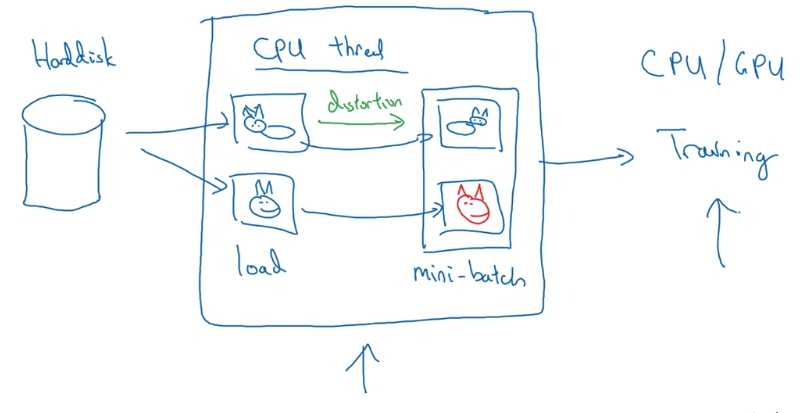 And what you can do is use maybe a CPU thread to implement the distortions such as the random cropping, or the color shifting, or the mirroring, for each image you might then end up with some distorted version of it.
And what you can do is use maybe a CPU thread to implement the distortions such as the random cropping, or the color shifting, or the mirroring, for each image you might then end up with some distorted version of it.
And so your CPU thread is constantly loading data as well as implementing whether the distortions are needed to form a batch or really many batches of data.
And so, a pretty common way of implementing data augmentation is to really have one thread, almost four threads, that is responsible for lading the data and implementing distortions,
and then passing that to some other thread or some other process that then does the training.
And often data augmentation and training can run in parallel.
The state of computer vision
- Deep learning has been successfully applied to computer vision, natural language processing,
speech recognition, online advertising, logistics, many, many, many problems.
There are a few things that are unique about the application of deep learning to computer vision, about the status of computer vision. (독특한 특성이 있다)
Data vs hand-engineering
-
You can think of most machine learning problems as falling somewhere on the spectrum between where you have relatively little data to where you have lots of data.
 So for example,
So for example,
i think that today we have a decent(상단한) amount of data for speech recognition and it's relative to the complexity of the problem.
And even though there are reasonably large data sets today for image recognition or image classification.
And there are some problems like object detection where we have even less data.
So if you look across a broad spectrum of machine learning problems,
you see on average that when you have a lot of data you tend to find people getting away with using simpler algorithms as well as less hand-engineering.
So there's just less needing to carefully design features for the problem,
but instead you can have a giant neural network, even a simpler architecture, and have a neural network.
Just learn whether we want to learn we have a lot of data.
Whereas, when you don't have that much data then on average you see people engaging in more hand-engineering.
And if you want to be ungenerous you can say there are more "hacks".
But i think when you don't have much data then hand-engineering is actually the best way to get good performance. -
So when i look at ML applications,
i think usually we have the learning algorithm has two sources of knowledge.- Labeled data :
the pairs you use for supervised learning. - Hand-engineered features / network architecture / other components :
You don't have much labeled data you just have to call more on hand-engineering.
Even though datasets are getting bigger and bigger, often we just don't have as much data as we need.
And this is why this data computer vision historically and even today has relied mroe on hand-engineering.
- Labeled data :
-
But i think historically the computer vision has used very small datasets,
and so historically the computer vision literature has relied on a lot of hand-engineering.
And even though in the last few years the amount of data with the right computer vision task has increased dramatically.
I think that that has resulted in a significant reduction in the amount of hand-engineering that's being done.
But there's still a lot of hand-engineering of network architectures and computer vision.
Fortunately, one thing that helps a lot when you have little data is transfer learning.
Tips for doing well on benchmarks / winning competitions
- Here are a few tips on doing well on benchmarks.
 One is ensembling.
One is ensembling.
What that means is, after you've figured out what neural network you want, train several neural networks independently and average their outputs.
So initialize say 3 or 5 or 7 neural networks randomly and train up all of these neural networks,
and then average their outputs.
And by the way. it is important to average their outputs .
 Another thing you see in papers that really helps on benchmarks,
Another thing you see in papers that really helps on benchmarks,
is multi-crop at test time.
What i mean by that is you'v seen how you can do data augmentation.
And multi-crop is a form of applying data augmentation to your test image as well.
One of the big problems of ensembling is that you need to keep all these different networks around.
And so that just takes up a lot more computer memory.
 So for example, let's see a cat image and just copy it four times including two more versions.
So for example, let's see a cat image and just copy it four times including two more versions.
There's a technique called the 10-crop.
And so what you do is you run these 10 images through your classifier and then average the results.
So if you have the computational budget you could do this.
Maybe you don't need as many as 10-crops, you can use a few crops.
And this might get you a little bit better performance in a production system.
For multi-crop i guess at least you keep just one network around.
So it doesn't suck up as much memory, but it still slows down your run time quite a bit.
So these are tips you see and research papers will refer to these tips as well.
But i personally do not tend to use these method when building production systems even though they are great for doing better on benchmarks and on winning competitions.
Use open source code
 Because a lot of the computer vision problems are in the small data regime,
Because a lot of the computer vision problems are in the small data regime,
others have done a lot of hand-engineering of the network architectures.
And you can use an open source implementation if possible, because the open source implementation might have figured out all the finicky details like the learning rate decay, and other hyper parameters.
And finally someone else may have spent weeks training a model on half a dozen GPUs and over a million images.
