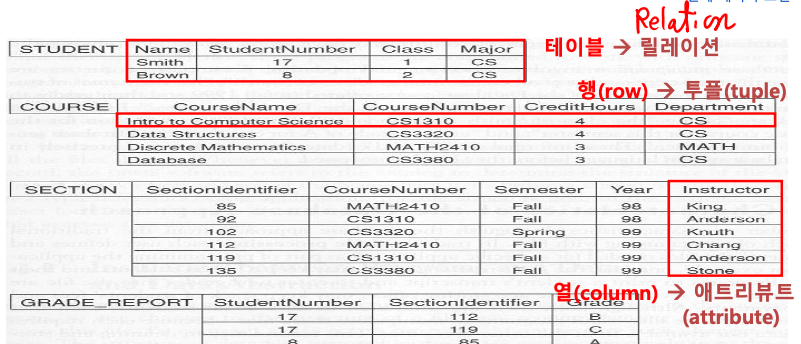
관계 모델의 개념
data를 관계(=Relation =Table)의 집합으로 나타냄- 1970년 IBM 연구소의 Ted Codd가 처음 소개
- 대표적 관계 DBMS
- Open source MySQL, SQLite, PostgreSQL
- Oracle의 Oracle
관계모델 용어
Table = Relation
Row = Tuple
Column = Attribute
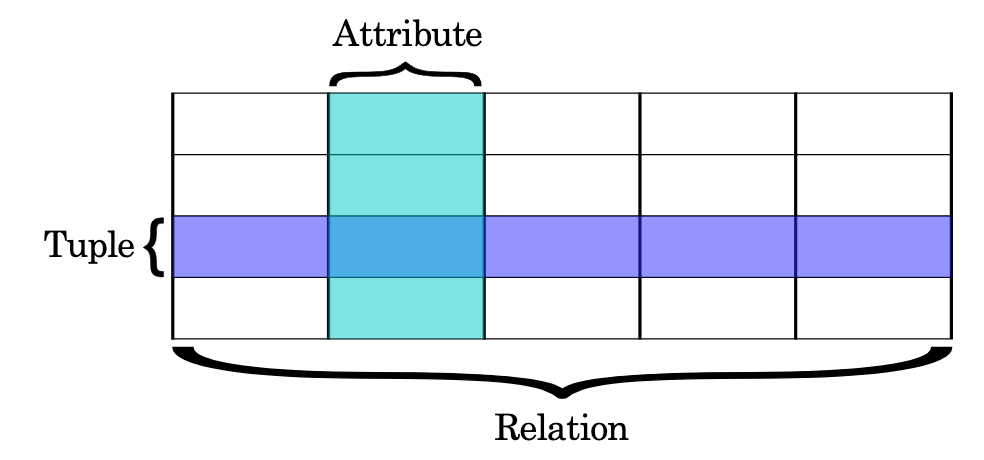 (
(domain
-
domain:
attribute가 가질 수 있는 값들의 집합.
NULL이 들어갈 수도 있다.
각 domain을 위해 data type 또는 format을 명시하기도 함 -
example :
- USA_phone_numbers : 미국에서 사용하는 10자리 전화번호들의 집합
- Names : 개인의 이름들의 집합
- Employee_ages : 특정 숫자 사이의 나이
NULL
NULL은 두 가지 의미르 사용됨- undefined (적용할 수 없음)
ex. Apartment_number는 단독 주택에 적용되지 않음 - unknown (알려지지 않음)
ex. John Smith는 핸드폰이 있지만, 번호는 알지 못함
- undefined (적용할 수 없음)
relation schema
relation schema:
relation 이름 R과 attribute들의 집합으로 로 표기함- relation의 degree(차수) = relation의 attribute 갯수
- ex. STUDENT(Name, SSN, BirthDate, Address) relation의 degree = 4
- domain의 표현 : dom = integer
realation schema의 tuple
- relation schema 의
tuple:
개 값들의 순서 리스트
값 는 dom()의 원소, 또는 NULL
relation instance = 상태
relation 상태 = relation instance:
relation instance 은 특정시점의 상태.
tuple의 집합;
relation의 특성
- relation은 tuple들의 집합(set)으로 정의됨
- set은 중복이 없고, 순서가 없다.
➡️ 따라서 Tuple 순서가 달라도 구성이 같다면, 동일한 Relation이다.
아래의 두 Relation은 Tuple들의 순서만 다를 뿐, 구성이 같기 때문에 동일한 Relation이다.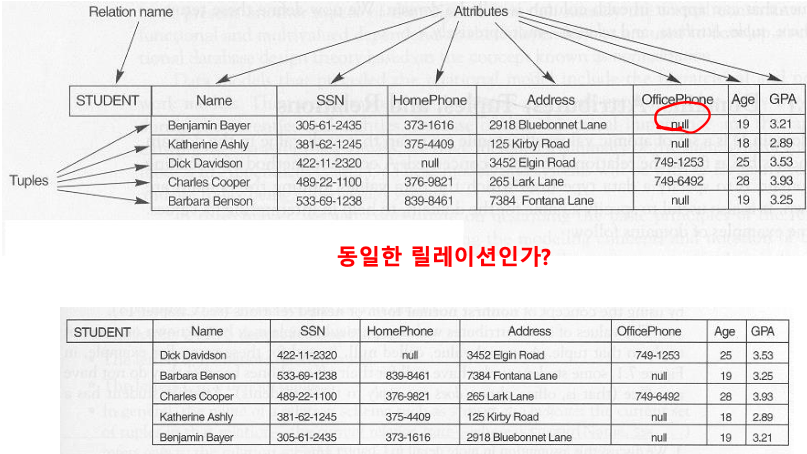
- tuple은 n개 값의 순서 리스트(ordered list)이며, 한 tuple 내에서 값들의 순서는 중요함
- Tuple 내의 attribute값은 atomic value여야 함.
ER model의 다치 attribute나 복합 attribute는 별도의 Relation으로 표현돼야 함.
값이 undefined거나 unknown인 경우에는 NULL이라는 특수 값을 사용함.
- set은 중복이 없고, 순서가 없다.
관계 모델 표기법 요약
-
차수가 인 Relation Schema 은 으로 표기
-
대문자 등은 relation의 이름을 나타냄
-
소문자 등은 relation의 상태(= instance)를 나타냄
-
relation r(R)의 tuple 으로 표기.
여기서 는 attribute 의 값 -
와 는 t에서 attribute 의 값 를 나타냄
-
서로 다른 Relation에서 동일한 이름의 Attribute를 사용할 수 있다
ex. STUDENT, FACULTY, EMPLOYEE Relation이 모두 Name Attribute를 갖는 경우
(STUDENT.Name, FACULTY.Name, EMPLOYEE.Name)
관계 모델 제약조건과 관계형 DB schema
관계 모델 제약 조건:
제약조건은 모든 Relation instance들이 만족해야 하는 조건임- domain 제약조건
- key 제약조건
- null에 대한 제약조건
- entity 무결성 제약조건
- 참조 무결성 제약조건
- 1~4 : 단일 Relation에서 나타나는 제약조건
5: 여러 Relation 사이에서 나타나는 제약조건
1. domain 제약조건
domain 제약조건:
각 Attribute A의 값은 반드시 A의 domain dom(A)에 속하는 원자값이어야 함.
2. key 제약조건
key 제약조건:
Relation은 tuple들의 집합(set)으로 정의되므로, 모든 원소는 중복되어서는 안 된다.
➡️ 중복이 자연스럽게 나타나지 않도록 만들어야 한다.
super key
superkey:
R의 attribute 집합으로서 relation instance에서 어떠한 두 tuple도 동일한 super key값을 갖지 않아야 함.
즉, 임의의 서로 다른 두 tuple t1과 t2에 대해 이어야 함.
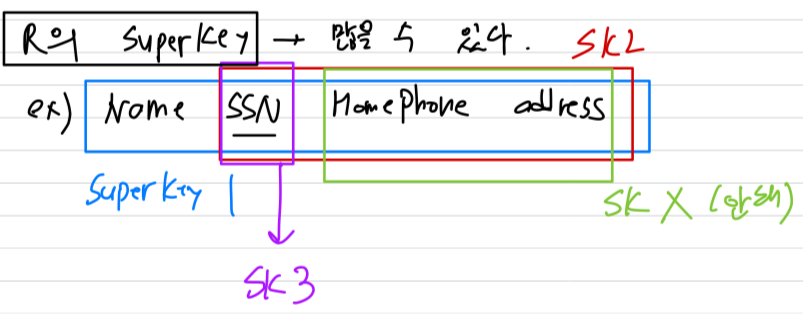
- Super Key는 많을 수 있다.
Key
Key: Super Key들 중에서 최소 attribute 개수를 갖는 Key. (Key Super Key)
즉, Super Key들 중에서 SK를 구성하는 어느 한 attribute라도 빠지면 SK가 될 수 없는 SK를 의미함.Keyattribute의 값은 Relation 내 각 tuple을 유일하게 식별하는 데 이용할 수 있음
- SSN만 Key가 될 수 있다.
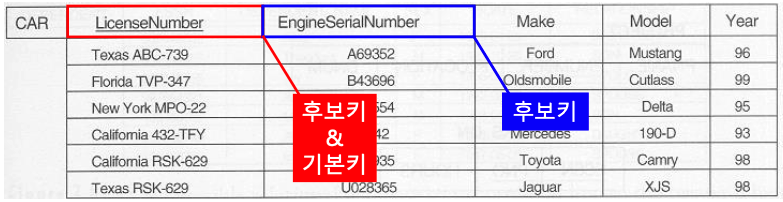
후보키, 기본키
-
후보키(Candidate Key): 하나의 relation 안에서 여러개의 Key를 가질 수 있는데, 이들을 후보키라고 함 -
기본키(Primary Key): 여러 후보키를 가지면 이 중에서 하나를 임의로 선택하여 기본키로 지정함
기본키를 구성하는 Attriute는 밑줄로 표시함
- 기본키를 정하는 이유?
기본키에 맞춰서 DB에 저장해놓으면, 그에 해당하는 index(tree)를 만들어서 빠른 접근이 가능하다.
()
index로 만들지 않는 후보키는 만큼 걸린다
➡️ 따라서 Relation을 만들 때, 반드시 기본키를 정해줘야 함.
- 기본키를 정하는 이유?
3. NULL에 대한 제약조건
- Attribute 값으로 NULL을 허용하지 않는 경우, Attribute는 NULL을 가질 수 없다
기본키(Primary Key)는 무조건 NOT NULL이다.

관계 DB schema
- DB에 속하는 Relation schema들의 집합 와 무결성 제약조건 = IC(entity IC + 참조 IC)의 집합으로 정의됨
- 무결성 제약조건 = Integrity Constraint = IC = entity IC + 참조 IC
- example : Company = {Employee, Department, Dept_locations, Projects, Works_On, Dependent}
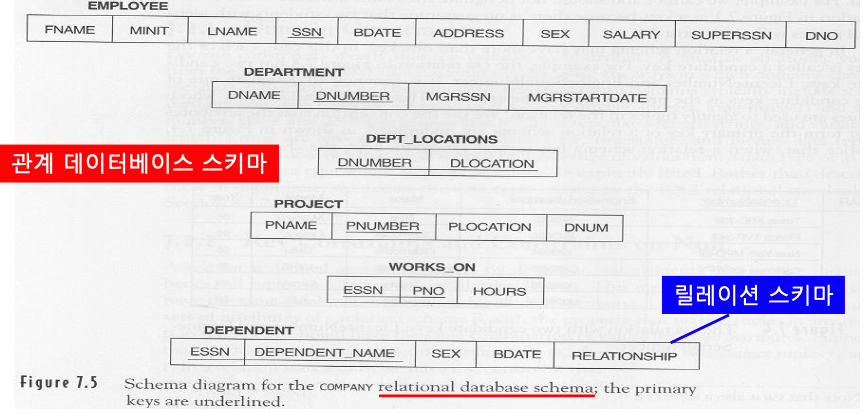
4. entity 무결성 제약조건
Entity 무결성 제약조건:
기본키가 각 tuple을 식별하는 데 이용되기 때문에 어떠한 기본키 값도 NULL이 될 수 없다.
5. 참조 무결성 제약조건, 외래키
참조 무결성 제약조건:
하나의 Relation에 있는 tuple이 다른 Relation에 있는 tuple을 참조하려면
반드시 참조되는 tuple이 그 Relation 내에 존재해야 함.- 하나의 Relation R에서 Attribute F의 값으로 다른 Relation S의 기본키 P값을 참조하는 경우,
F를 R의 외래키(foreign key)라고 함.
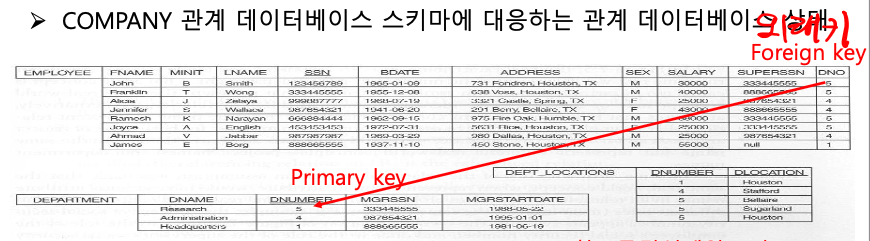
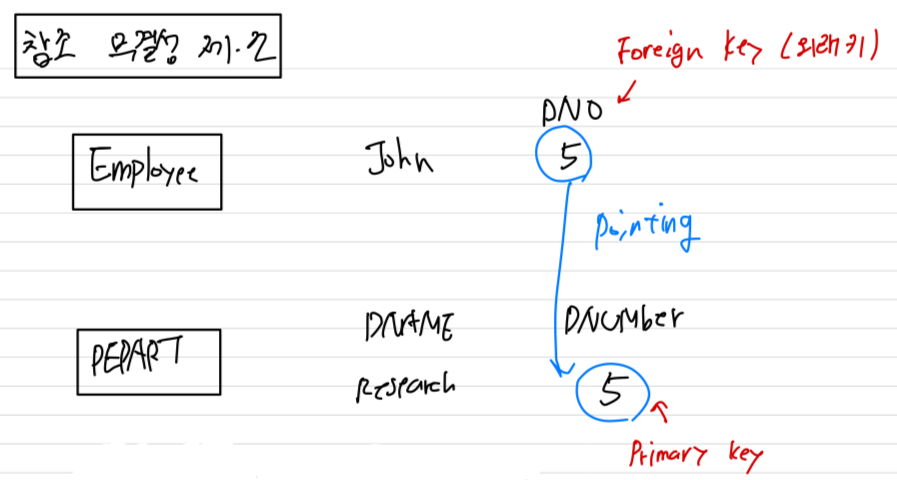
- Table과 Table을 연결시켜줬는데, 왜 그럴까?
➡️ DNO=5인 Employee 많기 때문에 하나하나 update하기 힘들다
따라서 DNO는 DEPARTMENT의 기본키인 DNUMBER의 외래키로 DNO을 지정하여 update를 간단히 하기 위해 table을 연결시킬 수 있다. - Entity 무결성 제약조건에 의해 Key는 NULL이 될 수 없는데,
외래키는 다른 Table의 기본키의 값을 사용하여 pointing하고 있기 때문에 NULL이 될 수 있다.
➡️ 만약 EMPLOYEE Table의 DNO이 NULL일 떄,
의미상으로 해석하자면 아직 그 Employee는 부서가 없다. 가능한 일임.
만약 NULL에 대한 제약조건으로 무조건 부서가 있어야 해서 NOT NULL로 설정했다면, 물론 NULL이 될 수 없지만
일반적으로 다른 제약조건이 걸려있지 않다면 외래키는 NULL값을 가질 수 있다.
- Table과 Table을 연결시켜줬는데, 왜 그럴까?
- 하나의 Relation R에서 Attribute F의 값으로 다른 Relation S의 기본키 P값을 참조하는 경우,
참조관계 예시
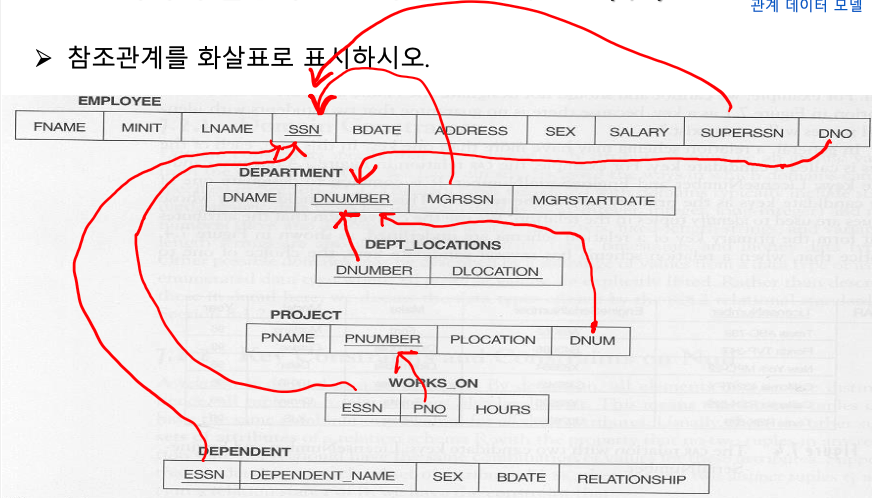
update 연산과 제약 조건의 위반 처리
- 관계모델의 연산 종류
- read
- write
- Relation에 대한 기본 Write 연산
- insert : 새로운 tuple 삽입
- delete : 기존 tuple 삭제
- update : 기존 tuple의 attribute값 변경
➡️write(insert, delete, update) 연산을 수행하는 경우, schema에 정의된 제약 조건을 위반하지 않아야 한다.
제약조건을 위반하면 write를 거부하거나, 위반 사실을 사용자에게 알려 정정하도록 해야 함
1. insert 연산
-
domain 제약조건위반이 발생할 수 있는가?
가능
ex : 원자값이 아니라 여러값을 넣으려 할 때 -
key 제약조건위반이 발생할 수 있는가?
가능
ex : 기존 tuple과 똑같이 중복되는 tuple 삽입 -
NULL에 대한 제약조건위반이 발생할 수 있는가?
가능
ex : NULL이 되면 안되는 attribute에 NOT NULL값을 삽입 -
entity 제약조건위반이 발생할 수 있는가?
가능
ex : key값에 NULL값을 넣으려 할 때 -
참조 무결성 제약조건위반이 발생할 수 있는가?
가능
ex : DNO에 7로 insert한다면, DNUMBER에는 7이 없기 때문에 insert하지 못함
2. delete 연산
-
domain 제약조건위반이 발생할 수 있는가?
불가능
그냥 tuple 하나를 삭제한다면 당연히 여러값이 중복되는 일이 없음. -
key 제약조건위반이 발생할 수 있는가?
불가능
그냥 tuple 하나를 삭제한다면 당연히 여러값이 중복되는 일이 없음. -
NULL에 대한 제약조건위반이 발생할 수 있는가?
불가능
그냥 tuple을 지우는 것만으로 NOT NULL을 넣어야 할 자리에 NULL이 들어갈 수 없음. -
entity 제약조건위반이 발생할 수 있는가?
불가능
그냥 tuple을 지우는 것만으로 key가 NULL이 되지 않음 -
참조 무결성 제약조건위반이 발생할 수 있는가?
가능
ex : 만약 DEPARTMENT의 Research 부서를 날리면, DNUMBER=5를 참조하던 Employee들은 존재하지 않는 Primary key를 참조하게 된다.
- delete 연산이 참조 무결성 제약 조건을 위반하는 경우, 취할 수 있는 3가지 옵션
- 거절
- default값을 참조하게 한다 (또는 NULL)
- cascade delete (연쇄적으로 지움. Research 부서를 지우면 해당 부서였던 Employee 모두 지움)
3. update 연산
- update 연산은 "delete 후 insert" 연산으로 간주할 수 있으므로
insert와 delete의 문제점이 모두 나타남.
