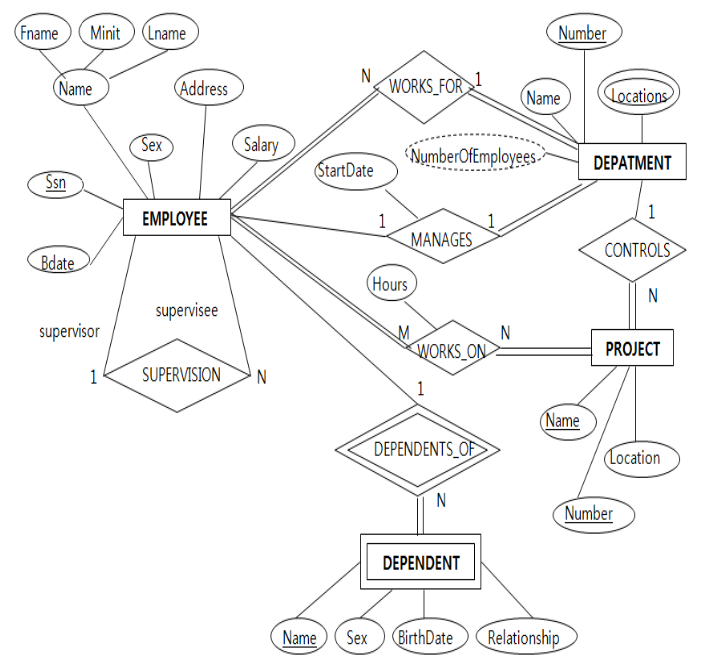
DB 설계 단계 (recap)
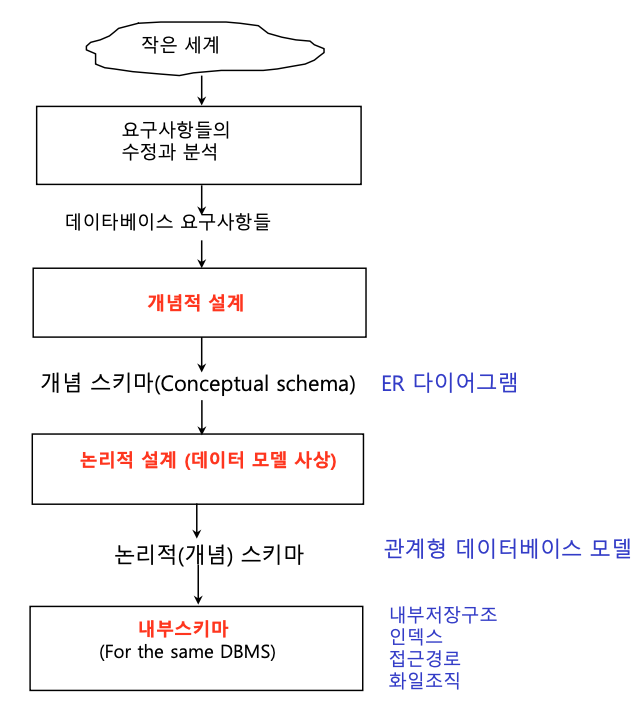
개념적 설계: 말 그대로 conceptual하게 설계.
개념적 설계의 결과 = ER Diagram논리적 설계: ER Diagram을 관계형 DB model로 mapping.
➡️ 논리적 설계를 배울 것이다.
mapping 단계 1 : 정규 entity type
-
관계형 DB는 table들의 집합.
table은 tuple들의 집합.
tuple들은 attribute들의 집합. -
table들끼리는 참조 제약조건에 따라서 서로 참조하고 있다.
-
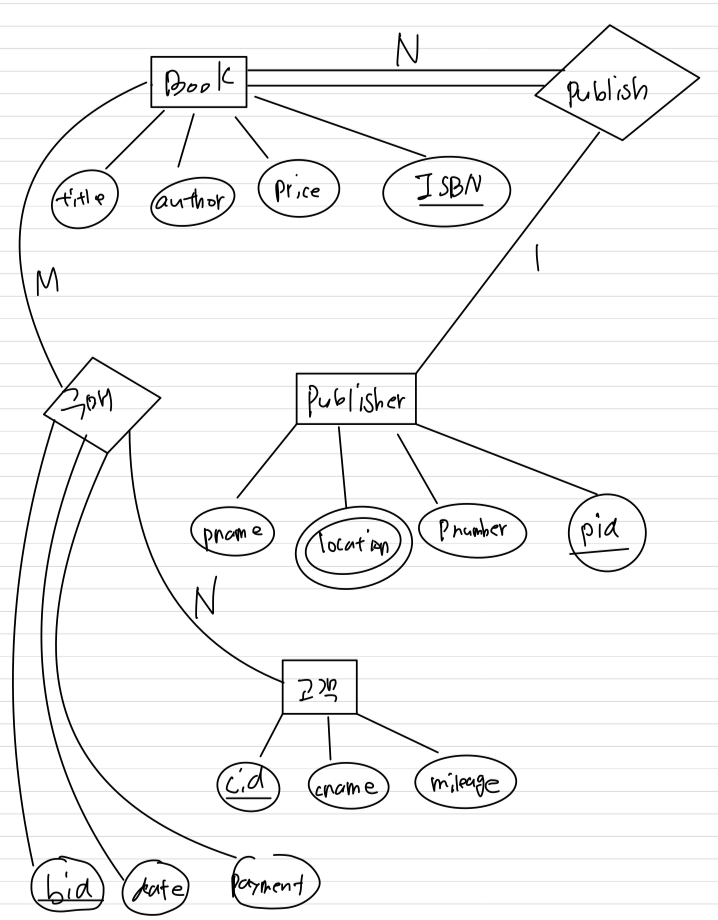
관계형 DB는 table들의 집합인데, 어떤 것을 table로 바꿔야 할까?
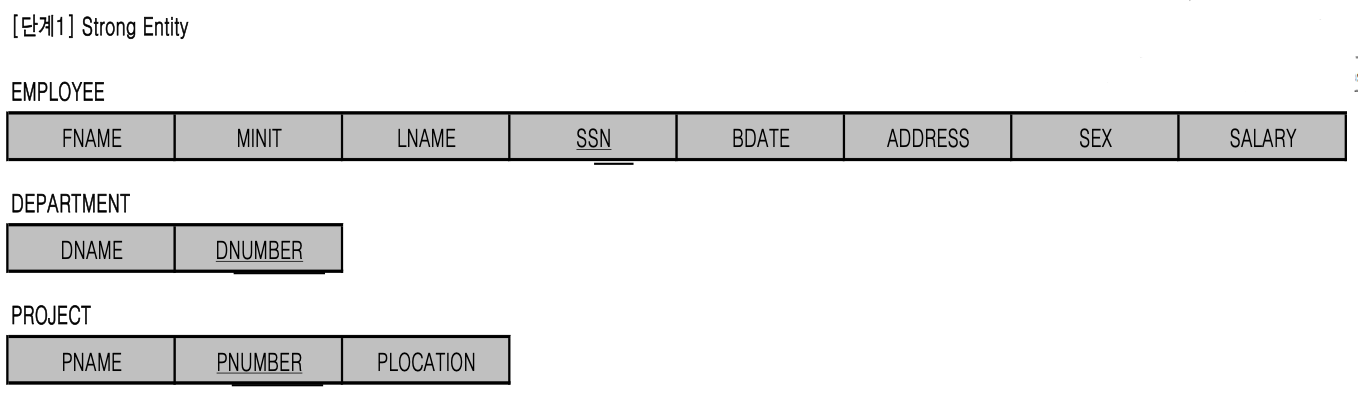
➡️ Entity type(EMPLOYEE, DEPARTMENT, PROJECT, DEPENDENT) 4개인데,
DEPENDENT는 조금 다른 Entity type(Weak entity type)이므로 제외하고
3개의 Entity type(Strong entity type)을
즉각적으로 table로 바꿀 수 있다.
각각의 Strong Entity type은 attribute들을 갖고 있으니,
attribute들을 전부 table의 attribute로 mapping하면 된다.
단, 주의사항이 있다.
- 복합 attribute인 Name의 (Fname, Minit, Lname)을 모두 별도의 attribute로 만들어줘야 함.
(domain 제약 조건에 의해 하나의 attribute 안에 여러 값이 들어갈 수 없다)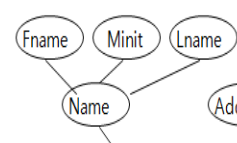
- table은 tuple들의 "집합"이기 때문에, 중복이 있어서는 안 된다.
따라서 key를 지정해줘야 한다.
EMPLOYEE의 key : SSN
DEPARTMENT의 key : DNUMBER
PROJECT의 key : PNUMBER
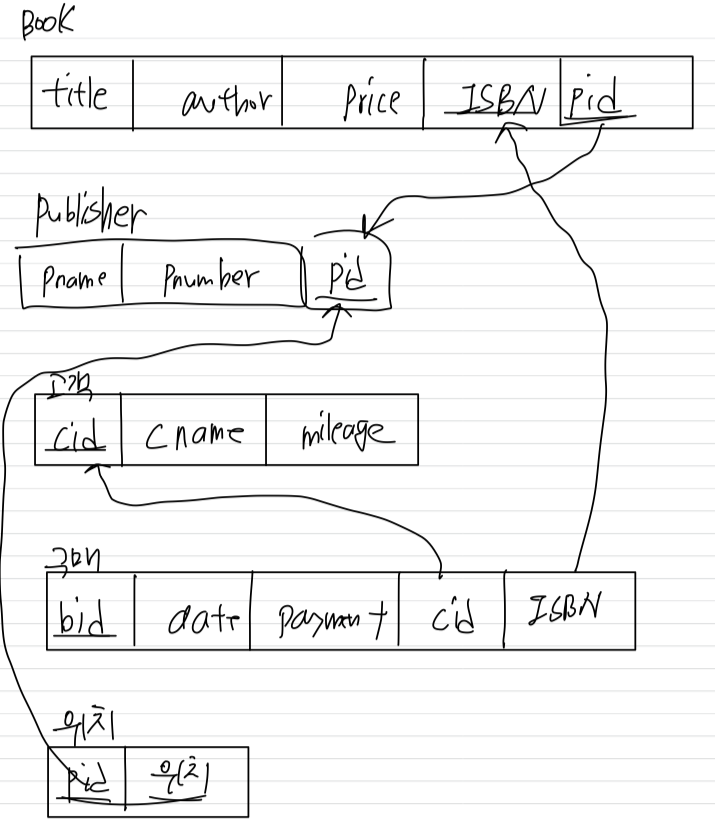
mapping 단계 2 : Weak entity type
-
Weak entity type:
Weak entity type은 Strong entity type과는 달리 key가 없음.
"부분key"를 갖고 있으며, 부분key만으로 구별할 수 없다.
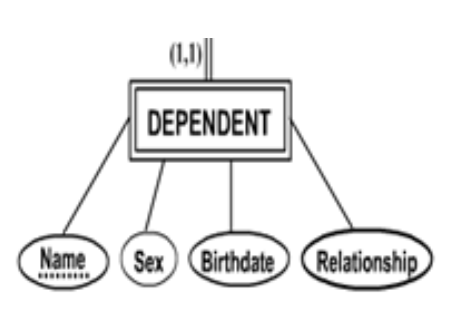
따라서 DEPENDENT를 구별하기 위해서는 EMPLOYEE와 연결하여 구별한다.
따라서 DEPENDENT의 식별 Entity Type은 EMPLOYEE이다.
또한 DEPENDENT의 실별 Entity Type의 Key는 ESSN이다.
(예를 들어, 피부양자의 Name이 이형섭인 사람이 많을 수도 있는데 어떤 직원의 피부양자인지 안다면 구별할 수 있다.)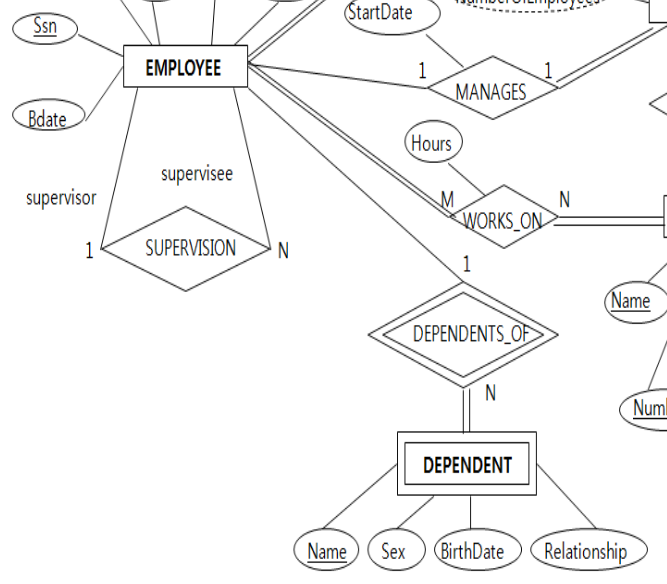
-
따라서 Weak Entity type인 DEPENDENT는
식별 Entity Type과 식별 Entity Type의 key를 갖고 table로 mapping시킨다.

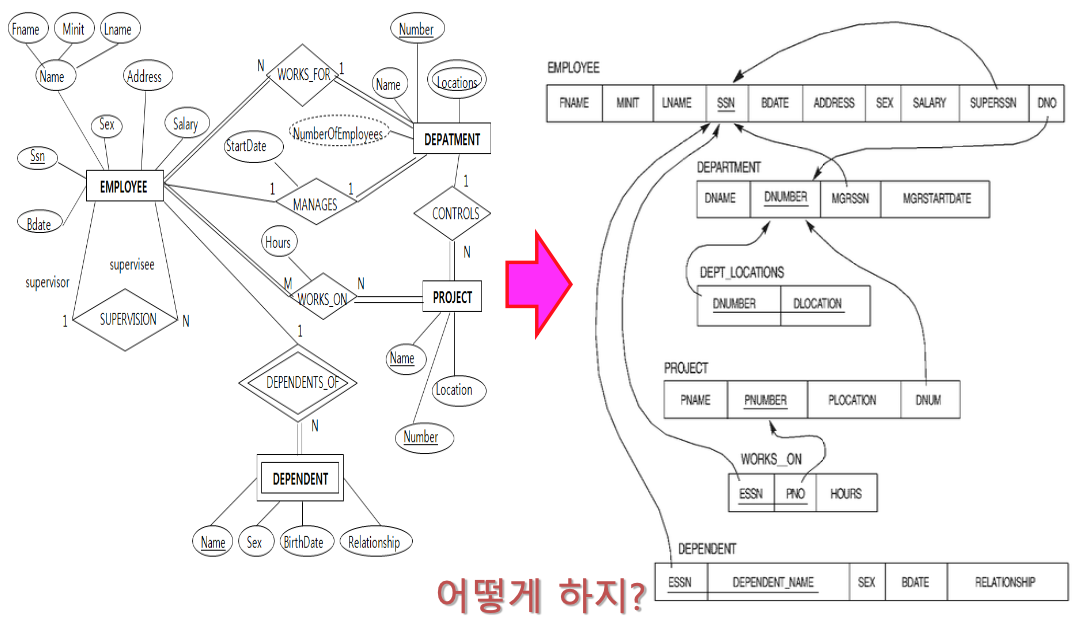
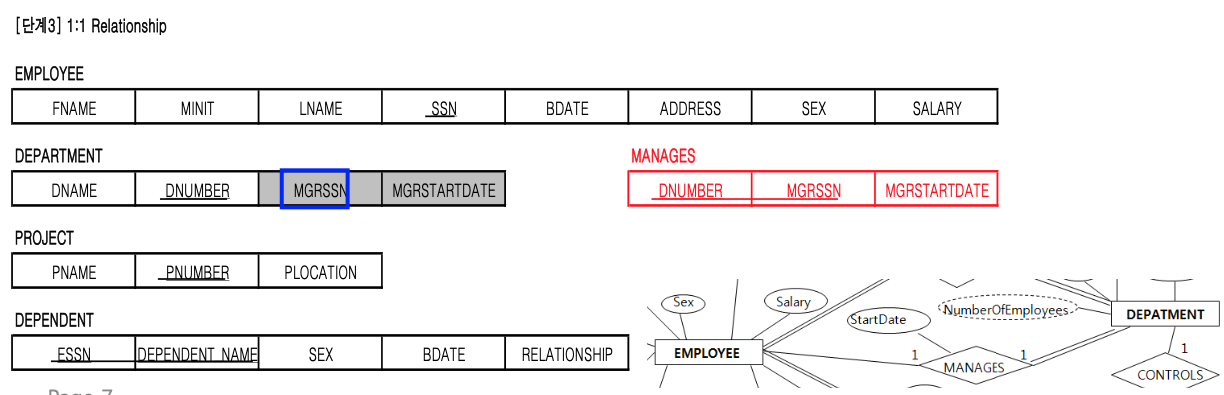
mapping 단계 3 : Relation S와 T의 1:1 관계
-
1:1 관계:
DEPARTMENT는 무조건 1명의 관리하는 직원이 있어야 함. (전체참여)
모든 직원이 무조건 DEPARTMENT를 관리하지 않아도 됨. (부분참여)

-
이처럼 1:1 관계의 Relation들도 Table로 만들어야 한다.
Relation에 참여하는 Entity Type의 key들을 합쳐서 key로 만든다
(EMPLOYEE의 key인 SSN과 DEPARTMENT의 key인 DNUMBER를 합쳐서 key로 만든다)

-
하지만사실 MANAGES라는 Relation의 table을 굳이 만들지 않아도 된다.
table이 너무 많아진다면, 사용, 관리하기 복잡하다.
따라서 table을 줄일 수 있다면 줄이는 것이 좋을 것이다.
그래서 더 좋은 방법은
EMPLOYEE나 DEPARTMENT entity type 둘 중 하나에다가
상대방의 key와 MANAGES의 attribute들을 모두 포함시키면 된다.
전체참여하는 entity type(DEPARTMENT)에 합쳐주는 것이 좋다.
만약 부분참여하는 entity type(EMPLOYEE)에 합쳐준다면?
Relation에 참여 안하는 직원들(관리자가 아닌 사람들)의 MRGSSN, MGRSTRARTDATE의 attribute값은 NULL이 될 것이다.
또한 중복되는 값이 많아진다. (?)
따라서 전체참여하는 entity type(DEPARTMENT)에 합쳐주는 것이 좋다.
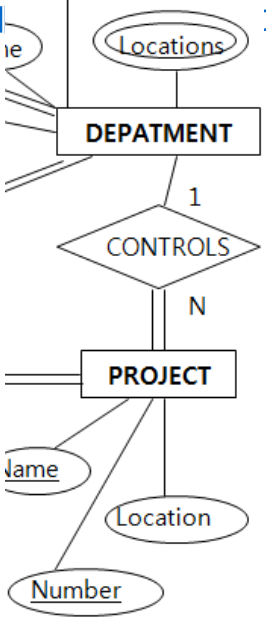
mapping 단계 4 : Relation S와 T의 1:N 관계
-
1:N 관계:
DEPARTMENT가 여러개의 PROJECT를 수행할 수 있다.
모든 PROJECT는 반드시 DEPARTMENT에 의해 수행되어져야 한다.
-
1:N 관계도 마찬가지로
DEPARTMENT의 key인 DNUMBER와 PROJECT의 key인 PNUMBER를 합쳐서
CONTROLS라는 별도의 table을 만들 수 있다.
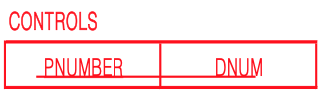 하지만 1:N 관계도 마찬가지로 CONTROLS table을 굳이 만들지 않아도 된다.
하지만 1:N 관계도 마찬가지로 CONTROLS table을 굳이 만들지 않아도 된다.
따라서 전체참여하는 PROJECT에다가 DEPARTMENT의 Key(DNUMBER)를 합쳐준다.
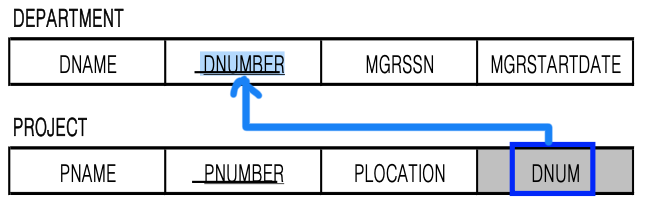 1:N도 마찬가지로
1:N도 마찬가지로
거꾸로 부분참여하는 DEPARTMENT에다가 전체참여하는 PROJECT의 key(PNUMBER)를 합쳐주면,
(1) PROJECT를 수행하지 않는 DEPARTMENT도 있기 때문에 NULL값이 많아질 것이고
(2) 한 DEPARTMENT가 PROJECT를 여러개 관리할 수도 있기 때문에 PNUMBER에는 원자값이 들어가야 하지만 여러 값이 들어가져야 하는 상황이 된다.
- 또 다른 예로 DEPARTMENT와 EMPLOYEE도 1:N 관계이고,
EMPLOYEE 안에서 supervisor와 supervisee의 관계도 1:N이다.
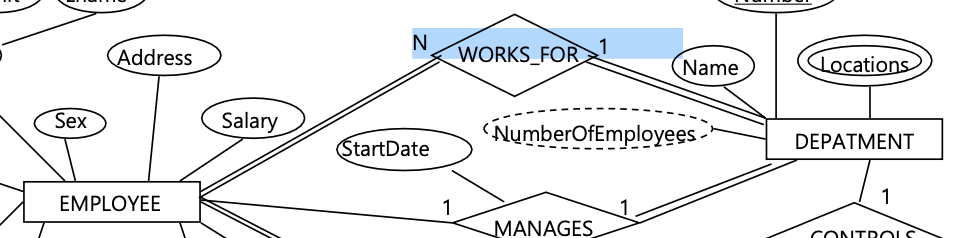
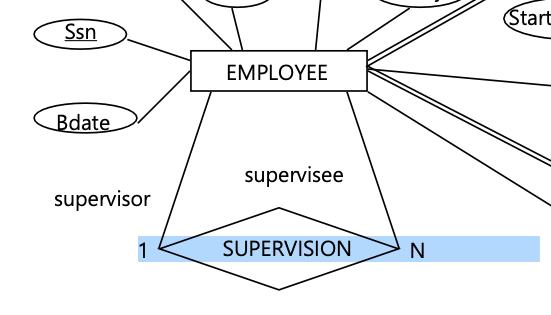 따라서 1:N mapping했을 때 table의 참조 관계는 다음과 같다.
따라서 1:N mapping했을 때 table의 참조 관계는 다음과 같다.
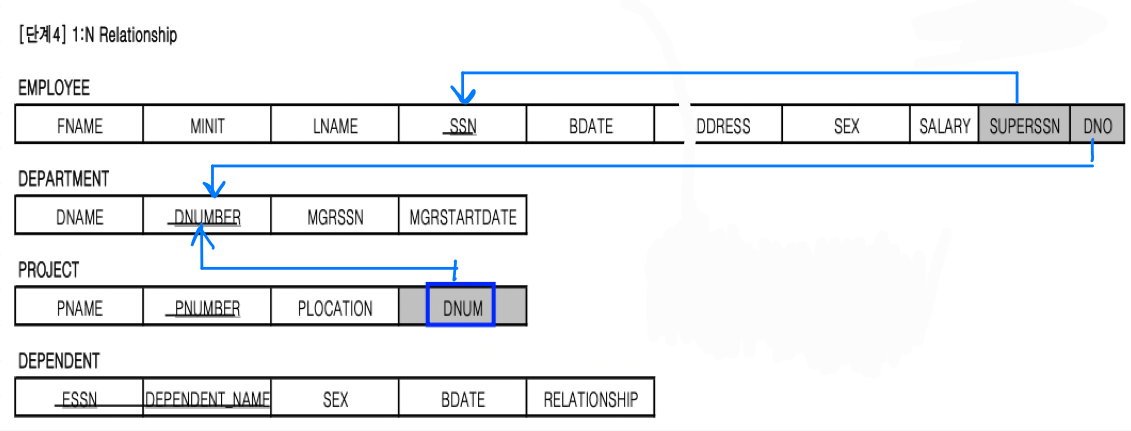
mapping 단계 5 : Relation S와 T의 M:N 관계
-
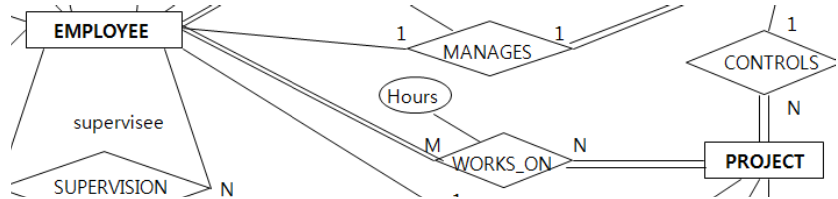
M:N 관계:
한 직원은 하나 이상의 PROJECT를 무조건 참여해야 하고,
한 PROJECT는 무조건 한 명 이상의 EMPLOYEE가 수행해야 한다.
-
이런 경우에는 key를 어느 entity에서 어느 entity로 합쳐야 할까?
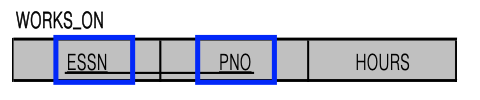
이럴 때는 어쩔 수 없이 양 쪽 entity type의 key(SSN, PNUMBER)를 가져와서
WORKS_ON이라는 table을 만들어줘야 한다.
-
만약 table을 만들지 않고 1:1, 1:N처럼 하면? 문제가 발생한다.
예를 들어 PROJECT에다가 그 PROJECT에서 일하는 EMPLOYEE들을 넣어준다고 했을 때,
table에 N개 만큼의 여유 attribute를 추가로 만들어줘야 하기 때문에 좋지 않은 방법이다.
NULL이 들어갈 수 있기 때문, 공간 낭비이기 때문
반대로 EMPLOYEE에다가 그 EMPLOYEE가 수행하는 PROJECT1 PROJECT2 .... 이렇게 M개 만큼의 attribute를 추가하는 것도 좋지 않은 방법이다.
따라서 M:N 관계일 때는 별도의 table을 만들어야 한다.
mapping 단계 6 : 다치 attribute
-
다치 attribute:
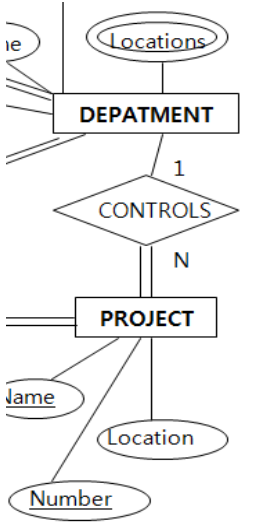
DEPARTMENT가 여러 곳에 위치할 수 있다는 뜻.
여기서 PROJECT의 Location은 다치 attribute가 아니고,
DEPARTMENT의 Locations는 다치 attribute인데 왜 그럴까?
DEPART는 여러 위치에 있을 수 있고, PROJECT는 한 곳에서만 수행되기 때문. (client의 요구사항)
-
다치 attribute의 경우, table을 만들 때 빼야 한다.
DEPARTMENT table에서 Locations attribute가 빠진 것을 볼 수 있다.
왜 빼야 할까?
Location1, Location2,.... 처럼 만들어야 할 attribute가 많아지기 때문에 table에서 빼야 하는 것이다.

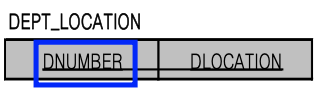
따라서 Location attribute는 별도의 table로 만들어줘야 한다.
이때, 다치 attribute가 속한 entity type의 key(DNUMBER)와 Location을 같이 key로 만들어 준다
(만약 DNUMBER만 key가 되면, 여전히 Location attribute를 많이 만들어줘야 하는 문제가 해결되지 않기 때문이다.)
mapping 단계 7 : n차 관계
n차 관계:
관계에 참여하는 n개의 Relation의 key들로 구성되는 관계 Relation으로 mapping된다.
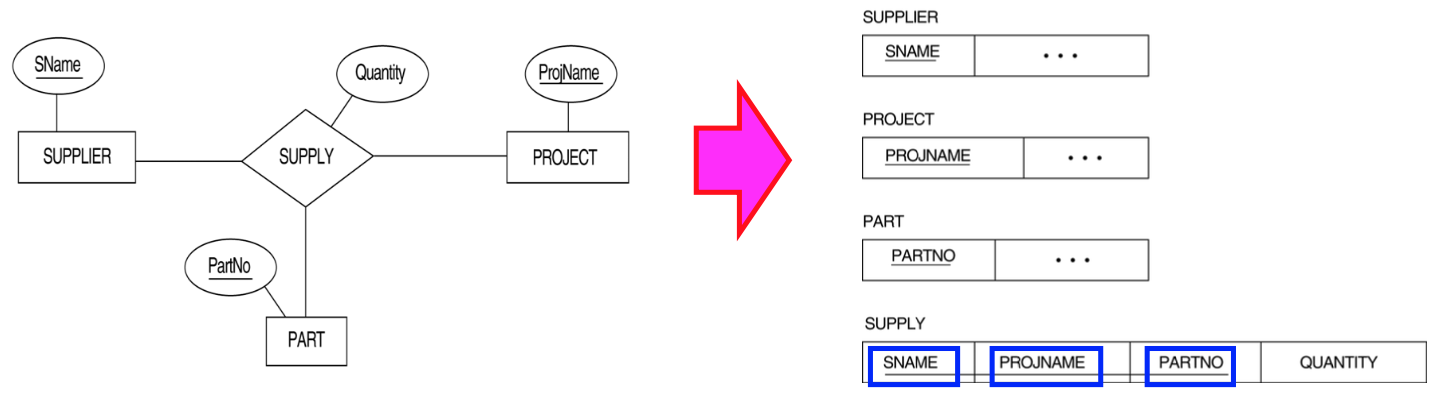 Supply Relation에 참여하는 3개의 Entity type이 있을 때,
Supply Relation에 참여하는 3개의 Entity type이 있을 때,
3개의 Entity type의 각각의 key(SName, ProjName, PartNo)를 합쳐서
별도의 SUPPLY table을 만들어야 한다.
ERD를 Relational DB로 mapping하는 연습